
Vik Paruchuri
@VikParuchuri
Followers
11,055
Following
176
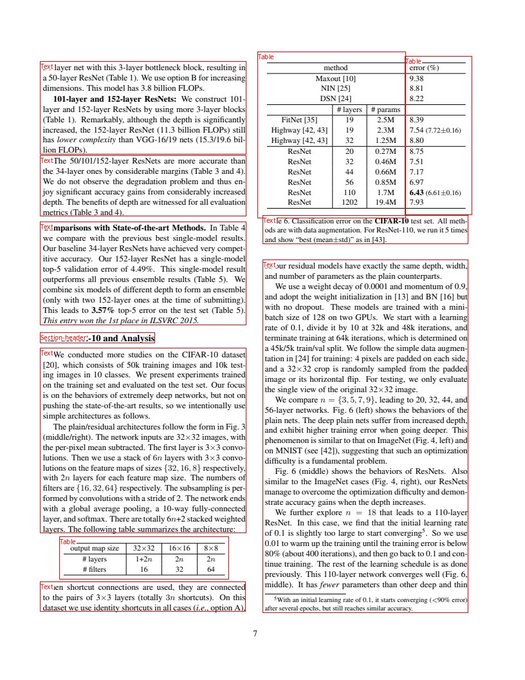
Media
90
Statuses
1,419
Open source AI. Past: founded @dataquestio
Oakland, CA
Joined June 2012
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Walz
• 2235112 Tweets
Minnesota
• 765653 Tweets
Your Season By NuNew
• 395097 Tweets
Shapiro
• 328128 Tweets
ホロライブ
• 280393 Tweets
Minneapolis
• 268231 Tweets
Adrián Marcelo
• 207892 Tweets
SEVENTEEN
• 206550 Tweets
National Guard
• 173795 Tweets
LISA FEAT ROSALÍA
• 170413 Tweets
Best K-Pop
• 115443 Tweets
Olmo
• 113293 Tweets
George Floyd
• 102283 Tweets
#VineshPhogat
• 90009 Tweets
#WonderFOURyearswithTREASURE
• 86294 Tweets
Pennsylvania
• 84829 Tweets
#빛나는_트레저_4번째_생일축하해
• 84813 Tweets
#wrestling
• 64646 Tweets
#TamponTim
• 57027 Tweets
Dora
• 43493 Tweets
Serbia
• 34194 Tweets
Kursk
• 28288 Tweets
Mil Veces
• 21015 Tweets
Jokic
• 19279 Tweets
対象2作品
• 18011 Tweets
Go for Gold
• 16780 Tweets
Evandro
• 14787 Tweets
Sky Brown
• 12911 Tweets
Messer
• 12064 Tweets
Manchin
• 11300 Tweets
Nabers
• 11034 Tweets
ハルヴァロ
• 10803 Tweets
Suécia
• 10152 Tweets
Last Seen Profiles





















Announcing surya - a multilingual text line detection model for documents. It gives you accurate line-level bboxes and column breaks.
Find it here - .

82
406
3K
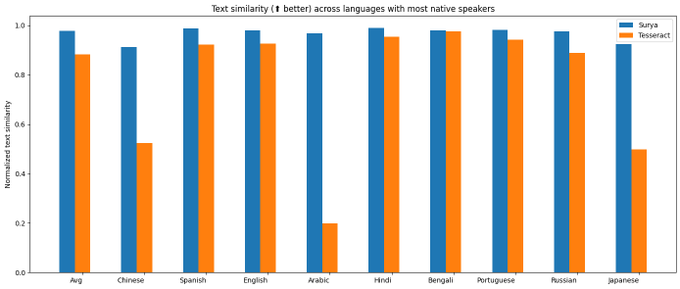
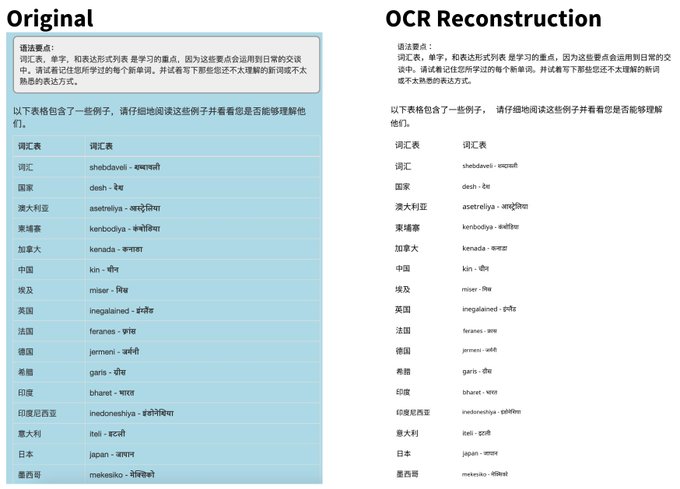
Announcing surya OCR - text recognition in 93 languages. It outperforms tesseract in almost all languages, often by large margins.
Find it here - .
39
253
2K
I'm starting a company, Datalab:
- Task-specific models that outperform frontier LLMs and existing tools
- Examples: my projects marker and surya (25k GH stars) with task-specific arch
- Goal: Train models, open source as much as possible, do hosted inference and on-prem
57
67
1K
I wrote a blog post on going from not knowing anything about deep learning last year to training state of the art OSS models - .
Hope it helps you.
tldr; read the deep learning book, implemented papers + taught, built open source tools

27
157
1K
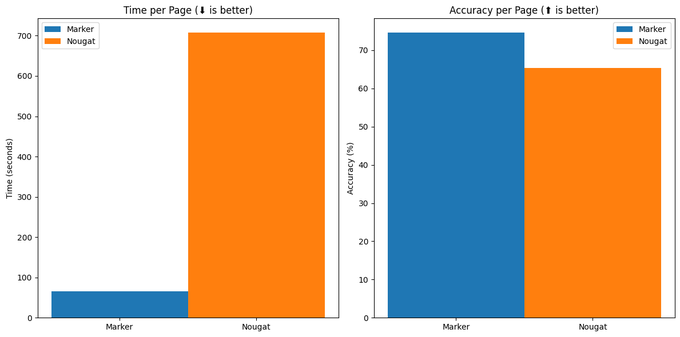
I'm excited to ship marker - a pdf to markdown converter that is 10x faster than nougat, more accurate outside arXiv, and has low hallucination risk. Marker is optimized for throughput, like converting LLM pretrain data.
Find it here - .
25
129
935
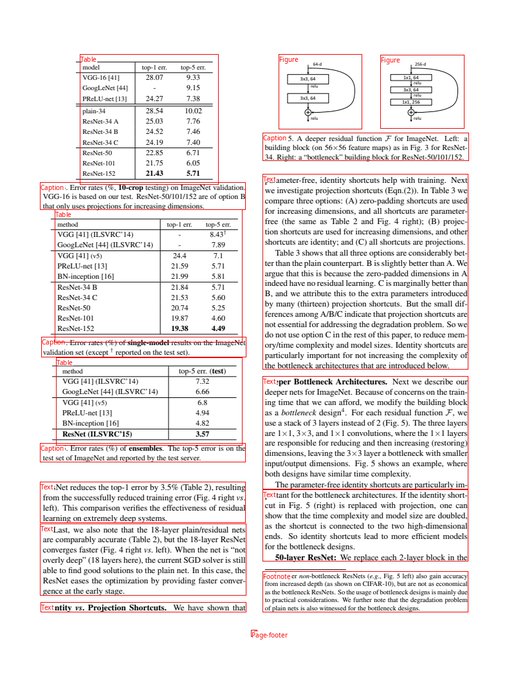
Cool to see a 500M param model I trained myself do better than Google cloud vision, Claude, and GPT-4V on this task. (look at the thread for the results)
It's a relatively narrow one (OCR), but feels nice to see that small open source models still have a place.

It's weird how we live in an age of miracles with respect to AI/ML, and yet when I want to extract some text from a screenshot the best (very bad) option is tesseract, last updated ~7 years ago.
67
33
838
22
55
855
Better data = better AI. That's why I've spent the last 3 months on:
- Marker - fast, accurate PDF to markdown (5k GH ⭐️s)
- Texify - SOTA math to LaTeX OCR
- Libgen to txt - get 3TB of HQ data
- Textbook quality - HQ synth data
Find them at .
24
97
835
I'm training a text line detection model for a document OCR pipeline.
It could also be useful on its own, but I'm not sure. Is anyone interested in a standalone release?
It works for every language I tried - it detects text bboxes and column breaks. ~2 second inference per

80
50
783
I'm tweaking my line detection model to get it ready for a Github release. This was a fun test case. It's not really designed for newspapers, so I was surprised this worked

54
47
726
I've shipped most of the models + libraries I wanted in the last few months:
- PDF to markdown - marker
- Text line detection, OCR in 93 languages, layout analysis, reading order - surya
- Equation to LaTeX
- PDF text extraction
Find them on Github - .
10
67
717
Are you a "rockstar" programmer? Someone made a keyboard just for you.
http://t.co/A4lt2KJuid

33
806
651
Announcing surya reading order! It predicts the order that a human would read a document in.
It's useful for RAG, accessibility, and text extraction. It works on a variety of documents, layouts, and languages.



19
87
668
Announcing surya layout! It detects tables, images, figures, section headers, and more. It works with any language, and a variety of document types.
Find it here - .
Thanks
@LambdaAPI
for sponsoring compute.


23
90
645
I can't get over
@ylecun
tweeting that surya was nice. Lifetime achievement unlock.
My next steps are:
- Improving old/scanned doc performance
- Seeing if I can do anything about rotations
Then on to the next recognition part! Here's the repo - .

12
40
626
Announcing texify - an OCR model that turns inline and block equations into markdown/LaTeX. It's more accurate at this than nougat and pix2tex.
Find it here - .
8
86
548
I spent a week improving the performance of surya (OCR, layout), and marker (PDF -> markdown).
OCR is now 2.2x faster, layout 1.35x, and marker 1.2x. Accuracy is the same as before (SoTA for open source/their task, see repos for details).

20
54
545
The biggest barrier to GPT-quality open source LLMs is data.
If you want 1TB of quality data, here's my repo that will convert libgen nonfiction to txt format - .

13
85
513
I made pdftext, a small tool that extracts text like pymupdf, but with an Apache license (mupdf is AGPL). It can pull out blocks and lines or plain text.
Find it here - .
14
54
488
I'm open sourcing my code to generate high quality synthetic textbooks.
Here's the repo - .
The quality is the highest I've seen in any open dataset.

5
68
474
Marker v2 is out! The main new features:
- Extracts images/figures
- Better table parsing
- Pip package install
- Can be used commercially
- Improved OCR with more languages
- Better ordering for complex docs
Get it here - .
15
59
469
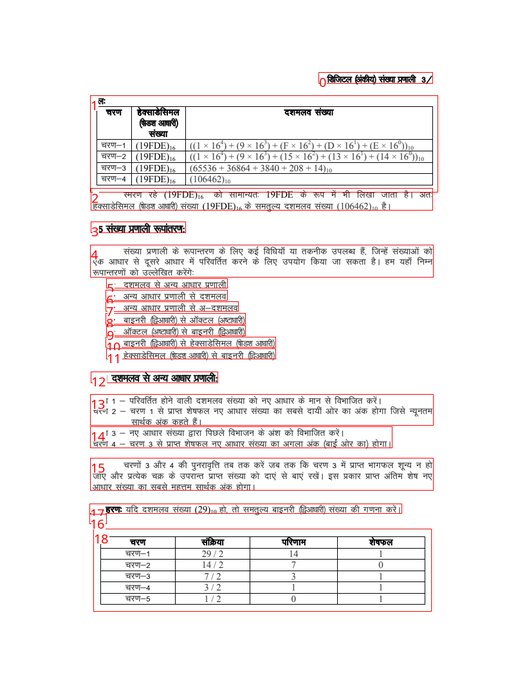
Surya () has been updated with a new model checkpoint that is far better on scanned/old docs.
It works even with blurry/rotated complex layouts, like this one:

13
34
428
I just released new surya layout and text detection models:
- 30% faster on GPU, 4x faster on CPU, 12x faster on MPS
- Accuracy very slightly better
- When I merge this into marker, it will be 15% faster on GPU, 3x on CPU, 7x on MPS

6
41
424
Surya () didn't work well on scanned/rotated docs, so I decided to spend a couple of days on it this week.
I'm making good progress. It's still training, hopefully will have something out tomorrow.

16
22
379
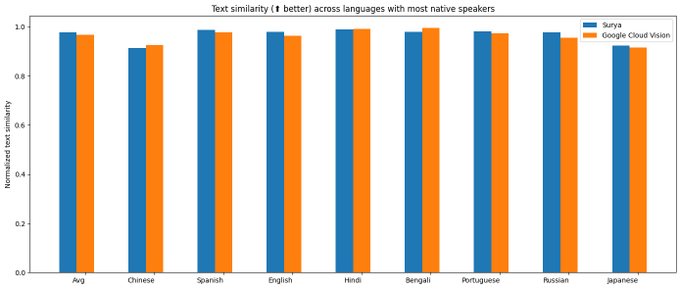
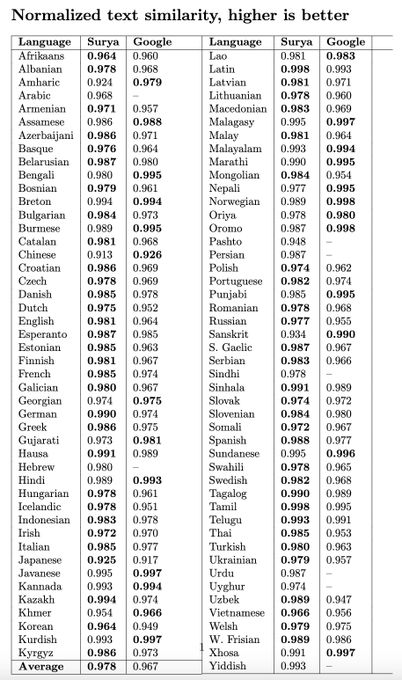
I benchmarked surya () against Google Cloud OCR, and it looks competitive. Pretty nice for an open source model I trained myself.
12
36
346
I think my layout model will be good to ship this week. What do you think? There are some minor issues, but working on them.



42
12
331
I'm going to release my reading order model next week. I had to change the architecture to perform better with complex layouts.
It seems to be working, though (see the image). There are mistakes, but it's only 20% trained, and still improving.

15
18
304
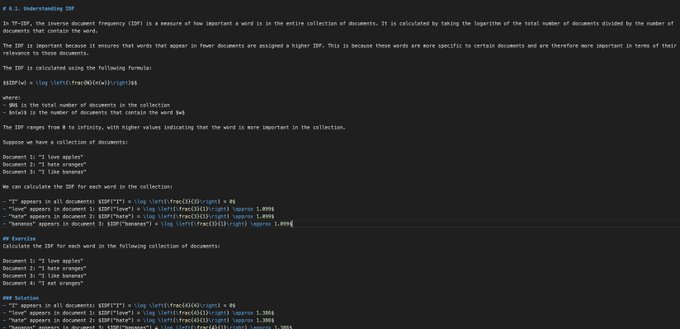
Textbooks generated with finetuned mistral + search and wikipedia RAG are surprisingly good. They seem close to GPT-3.5.
See samples here - , and here - .
Working on a bigger set now! Please let me know if you can sponsor.
3
51
300
Working on a reading order detection model. Still early in training, but output is starting to look decent. Hoping to release next week.
14
27
295
I have a beta version of a hosted API for marker and surya up at . It does OCR, layout + reading order, and PDF -> markdown.
Averages 40 seconds to convert a 50 page PDF to markdown.
8
25
280
I've generated 70M tokens of extremely high quality synthetic textbooks - , using retrieval and gpt-3.5.
Seriously, the quality is 💯.
I'm generating 1B tokens, but will use llama for $$ reasons. Please DM if you can sponsor compute or credits.

7
51
279
My reading order model is getting close to being release-ready. (it may not be immediately obvious, but this is a hard doc to order properly)
Working on fixing just a few remaining issues.

19
14
262
I'm working on a layout analysis model. Hopefully will ship in the next 2 weeks.


13
17
260
I released marker last week - .
Within 72 hours, marker got to
#1
on HN, with 700 votes, and was starred 3.4k times on Github.
I didn't expect this kind of response - thank you so much for the support!

5
25
248
An update on surya text recognition - I'm happy with the data/architecture, and I'm ready to scale up training.
Here are some results from a (very) early checkpoint. Left is original, right is OCR (Malayalam)


9
24
246
I'm building a dataset of high quality synthetic textbooks for pretraining. Here's a 4M token preview - . The quality is incredibly high (it really surprised me).
8
38
237
I've been generating additional textbooks! is up to 115M high quality tokens, and is up to 85M.
I'm seeing promising humaneval results with models trained on this data.

2
35
217
As
@jeremyphoward
shared yesterday, I'll be joining
@answerdotai
! I'm excited to work with such a strong team.
Before I start, I'm going to finish some in-progress work:
- Integrate surya with marker
- Commercial version of marker
- Launch an API for both
9
8
213
Libgen to txt now supports marker for pdf -> markdown.
Turn libgen rs nonfiction into 3TB of high quality markdown. AI labs are using this data to train LLMs - now you can, too.
Full instructions and usage are here - .
1
32
204
Marker is now faster! 7x on MPS, 3x on CPU, and 10% on GPU. Due to a more efficient architecture for 2 models.
Marker converts pdfs to markdown very effectively. I hope the speedup will let people create more high-quality datasets.

3
22
198
I built a dataset of every package on pypi. The quality of code is high, and I'm finding it great for finetuning and pretraining - .
I cleaned extra leading comments, and rendered notebooks, so this data should be ready to use.

8
28
192
I'm excited to release a 400m token synthetic programming textbook dataset - .
This is a mix of GPT-3.5 (great quality), and finetuned llama (good quality).
It was generated with the textbook quality repo - .
2
14
173
A timeline of
@DataCamp
2017-2020:
- CEO sexually harassed an employee
- The company covered it up
- After years of community pressure, the CEO stepped down
- They just BROUGHT THE CEO BACK 🤦🏾♀️
This is a repeated and ongoing failure of leadership and ethics.
7
46
155
Expectation: Data science is all about ML and deep learning.
Reality: It's 80% storytelling and data acquisition + cleaning. And these parts are actually quite interesting (I promise!)
4
32
133
I'm amazed by the quality of RAG-augmented books from finetuned mistral. The writing is higher quality than 34b codellama, but it does make subtle mistakes (see math below).
Mistral -
Codellama -
1
15
131
If you want to learn data science, don't start with a list of technologies. Start with a project you want to build, and work backwards,
3
26
126
I've improved my synthetic textbook generator in collaboration with
@ocolegro
- . The books are now longer and a lot more detailed!
Here's a preview - . (the programming books were generated with this technique)
1
18
122
@Yampeleg
Thank you! I have a finetuned model that can generate similar quality to GPT-3.5. Just need compute credits to scale to 1B+ tokens 🙏🏾 .
LLM credits (OpenAI or other) are also nice!
Dataset is here, btw -
4
14
116
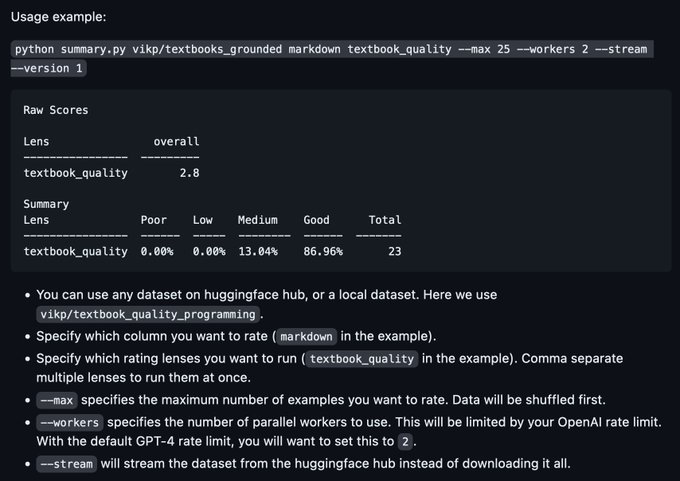
Excited to ship classified - a quality rater for LLM pretraining and instruct data - .
It can stream datasets from HF hub, or from disk.
It uses GPT-(4/3.5) now, but custom classifier training and dataset filtering are coming soon.
7
19
114
I have a very early commercial usage preview of marker on the dev branch.
This removes layoutlm and pymupdf, and swaps in new models I trained.
I'd love some help testing it. You can find it here - .
10
10
100
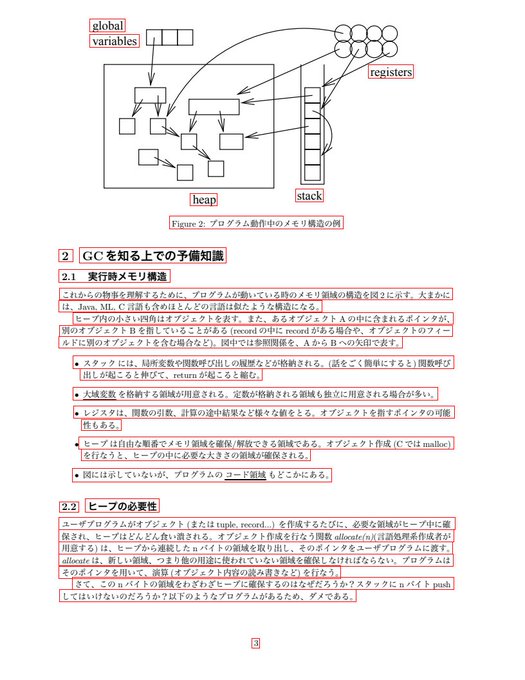
Surya was trained on a diverse set of documents, including scientific papers. It works with every language that I've tried.
It should work with good quality scanned documents as well due to image augmentation.
2
9
98
If you're learning data science, it can be exciting to jump straight to machine learning. But data cleaning, data visualization, and SQL will take up most of your time in entry-level roles. Don't neglect those skills.
3
12
96
@1littlecoder
Note: this is a thin wrapper around marker - - but strips out the marker commercial license.
Please see the marker repo for details about licensing.
5
7
96
My synthetic code textbook dataset is now up to 8M tokens - . The quality is still very good.
Going to try to get to 100M tokens in the next few days.
2
17
91
@sterlingcrispin
@peterthiel
Too many people are fine-tuning generalist models, and too few people are building pipelines of models for specific tasks. I think niche data + pipeline will beat generalist models.
5
3
87
Text detection is step 1 in building a GPU-accelerated OCR model that is more accurate than tesseract. Step 2 is to build the text recognition system - I'll be working on that in the next couple of weeks.
4
6
88
Also, thank you
@jeremyphoward
- I joined with the mutual understanding that we'd see if there was a fit.
When it was clear there wasn't (I want to train/open source models), Jeremy was very gracious. It's hard to find people who genuinely want you to
0
5
86
Ok - looks like I will be releasing this one standalone) Note that this is just the text detection (drawing bboxes around the text). I'll be working on text recognition (turning the bboxes into text) next week
7
1
78
After this, I can integrate layout + OCR + reading order from surya into marker, and make marker commercially usable! ()
4
2
77
At
@dataquestio
, we aren't flashy. We don't raise $$ from investors. What we do instead is build the best way to learn data science.
Students who finish >10 courses see an avg $16.6k salary boost, and we've created $103.9M in total salary gains. And all it costs is $49 a month.
3
12
75
I'm a self-taught data scientist. When I looked for jobs, I got rejected many times for not having credentials.
It was crushing. But I realized that the rejections only mattered if they stopped me from trying. Don't let them stop you.
0
9
58

When I first got into data science, I had impostor syndrome, and I dealt with insecurity by not engaging with people, or acting like I knew everything. This was a mistake. The best way through it is to humbly engage with people - I've learned a lot more this way!
0
7
55
Open source AI is very important to me, and will be a core part of this company.
You can find my current projects here - .
Hosted inference, which launched last month and has decent traction, is here - .
1
3
54
Benchmarking was a little tricky, since surya generates line-level bboxes, and tesseract generates word level. Most datasets are also word-level. I decided to benchmark using doclaynet.
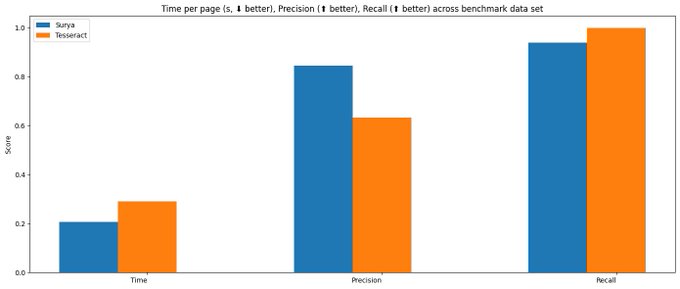
1
2
52
I used to work in a UPS hub. I once thought I'd work there my whole career (until my boss told me they wouldn't promote me).
The fact that I've been able to find my own path, and that I'm able to help others do the same with
@dataquestio
, is something I never take for granted.
3
5
48
@kevinsxu
This is a good thing - most architectural changes don't make a big difference (the training data does). This makes Yi compatible with all the existing llama inference tools. They also acknowledged the issue and will rename - .

1
4
45

Last year, I built Endless Academy - - a site for AI-generated personalized courses.
It has potential, and I'd love to see it grow, but I don't have the time. I'm looking for someone who's interested in taking it over.
4
7
45
I'm planning to make this part of surya -
3
0
44
Surya is built on some amazing open source work, including:
- transformers from
@huggingface
- segformer from
@nvidia
- CRAFT from the
@official_naver
team - an amazing paper and team
Thank you to everyone who makes open source AI great.
1
1
43
The niches where I'd train task-specific models (like OCR) have large enterprise demand.
These models will be faster/cheaper/more customizable than existing tools and frontier LLMs. This is by fitting model architecture and data to a specific task.
3
2
40
I'm also planning to work on other PDF-related projects soon, like table/image detection/extraction, and reading order detection.
I will be porting all of these into marker (), my pdf to markdown converter, to improve accuracy.
2
3
40
1/ In this thread, I'll discuss
@LambdaSchool
, a bootcamp that charges 17% of your pre-tax income for up to 2 years (ISA).
tl;dr Lambda is much more expensive than the average bootcamp, and has similar outcomes. 75% of Lambda students could pay an avg of $9k less elsewhere.
3
9
38
A summary of 90% of management books:
1. Build trust
2. Build culture
3. Share context
4. Create process, but not too much
5. Give honest, caring, feedback
6. Delegate, but don't micromanage
7. Set actionable goals
8. Hold people accountable
9. Be a mentor
10. Solicit feedback
2
11
34
I'm excited to start shipping again tomorrow. Stay tuned for:
- General purpose OCR model
- Open version of layoutlmv3 (or vgt)
- Commercial version of marker
- Better support for non-European languages
5
4
37
I'm very excited about this direction - it's so much fun to understand a use-case, then find just the right architecture/data to make a SoTA model.
If you're interested in working together in some way (partner, collaborate, invest, etc), feel free to ping me!
3
3
38

Surya has limitations, including:
- It is specialized for document OCR. It will likely not work on photos or other images. It will also not work on handwritten text.
- Performance on scanned documents can be hit or miss.
- It doesn't work well with images that look like ads or
1
1
36
Find it here - .
By combining reading order with OCR and text detection in surya, it's easy to turn entire documents into readable plain text. Even complex ones like newspapers or magazines.

3
4
35
The model was trained from scratch, so it's okay for commercial usage. See the repo for more details and dual licensing.
1
1
35
@adithya_s_k
It looks like you copied all of my code out of the marker repo, but split it across several of "your" commits - . You then removed my commercial usage license.
Other code seems copied, too like your florence-2 code is from here -
3
0
34
Ok - now on to the text recognition part :) I think I have a good plan, hopefully will have news next week.
1
0
33
I hope you find this useful! Please join the Discord - - if you'd like to discuss surya.
If you do try surya out, please let me know how it went for you. I've tried it across a range of images, but there are so many edge cases.
2
1
33
Surya uses a modified segformer architecure from
@nvidia
. I found that by changing some of the shapes in the decoder, I could cut inference RAM usage to 1/4 of the original without a performance degradation.
1
1
33
We announced scholarships for underrepresented groups
@dataquestio
. Here's why:
- Data skills unlock economic opportunity + widely distributing them keeps the field ethical
- Some groups have been excluded due to systemic bias
- Scholarships help level the playing field
1
14
31
Surya () already supports line detection , and I'm excited to have it do full end to end OCR.
The final model should support ~90 languages (all major languages in use today).
2
1
31
I want to spend the rest of my career working towards a world where only what you can do matters - not the logo on your degree, who you know, or what you look like.
0
2
29
One lesson that was hard for me to learn is that the success of those around me doesn't diminish my own.
It actually enhances it by building a stronger network.
Don't hoard knowledge. Help the people around you. Not only is it the right thing to do, it also helps you.
1
7
27
I just uploaded a new model checkpoint for texify , a math OCR tool.
The recognition quality is incredibly good. Left is the selected region of a PDF page, right is detected and rendered Markdown/LaTeX.

2
3
29
The benchmark is calculated by % coverage of predicted bboxes by references (precision), and vice versa (recall). Anything over a .5 threshold is a hit. There is a small penalty for overlapping multiple reference boxes in precision.
1
2
28

I'm planning to make it part of surya - . After training an ordering model, surya will be able to sort text properly, and extract tables/images.
0
0
28
Based on my experiences as a solo technical founder growing
@dataquestio
to 30+ people, I wrote a guide on quickly improving your management skills - .
This is how I went from having no idea what I was doing to kind of knowing what I'm doing :)

4
3
27
The best way to raise money for a startup is to get people to pay you for what you're making.
3
6
27
You can find surya here - .
Coming soon:
- Merge this into marker for a significant speedup
- Work on a more efficient OCR architecture (hoping for similar speedups)
- Table parsing and OCR heuristic improvements in marker
2
1
26
After I start, I'm planning to continue working on OSS data tools/models.
Early ideas are:
- Decode images from any language and doc type into markdown (like nougat, but faster/more general)
- A single chat model that can do OCR, layout analysis, reading order, etc
1
0
26
A cooperative machine learning contest that anyone can participate in:
#machinelearning
#DataScience

0
21
24
My next project is reading order detection. I will then be porting all of these into marker (), my pdf to markdown converter, to improve accuracy, and allow commercial usage.
1
0
25