

Christopher Potts
@ChrisGPotts
Followers
13K
Following
2K
Media
96
Statuses
2K
Stanford Professor of Linguistics and, by courtesy, of Computer Science, and member of @stanfordnlp and @StanfordAILab. He/Him/His.
Joined November 2011
All the screencasts for this course are now freely available on YouTube; if you take the official course, you also get access to an expert teaching team, and I myself do some webinar/discussion events:.

Master the tech transforming AI. Natural Language Understanding taught by @ChrisGPotts starts 8/21 and runs 10 weeks. Course updated to reflect the latest developments in LLMs and generative AI. Enroll now!.@stanfordnlp @StanfordAILab.
5
40
205
According to the first sentence of 100% of the papers I have reviewed this year, large language models have achieved amazing success in recent years. Perhaps we could settle on the abbreviation "Language Models Are Outstanding", so papers could begin "LMAO, but …" to save space.
10
102
825
I'm extremely grateful to @StanfordOnline for making my 2021 Natural Language Understanding course videos accessible and available on YouTube. I've created a version of the 2021 course site with direct links to the YouTube videos:
7
108
603
The remaining lectures from my Natural Language Understanding course are now up: I have highest hopes for the contextual word reps one; I tried to methodically walk through those models with diagrams, to supplement the great tutorials already out there.
6
118
518
For my spring NLP/NLU course, I had a series of conversations with outstanding researchers, aiming to provide students a sense for these people and how they think about the field. The conversations were really rewarding, so I turned them into a podcast:
16
86
413
Sad news: Lauri Karttunen passed away peacefully this morning. Lauri was a towering figure in linguistics and NLP, and a vibrant presence at Stanford in Linguistics, @stanfordnlp & @StanfordCSLI. So many observations and concepts that we all take for granted trace to his work!.
13
66
383
In nervous anticipation of my #ACL2021NLP keynote, I recorded myself giving my talk, and I've posted that version for people who can't attend the live event. The video has high-quality captions, and you don't particularly need video to follow along:
10
72
358
For my Introduction to Semantics and Pragmatics course at Stanford this quarter, I made screencasts of all the content, with high-quality transcripts, and put them on YouTube. All these videos and associated materials are available here:
7
75
302
Stanford has begun posting lectures from my course Natural Language Understanding on YouTube (a few are still to come): I'm actually happiest with the "bake-offs", which don't appear much in the videos but can be found here:
2
102
281
The Linear Representation Hypothesis is now widely adopted despite its highly restrictive nature. Here, @robert_csordas, Atticus Geiger, @chrmanning & I present a counterexample to the LRH and argue for more expressive theories of interpretability:
10
63
290
I'll be asking "Is it possible for language models to achieve language understanding?" at an upcoming @StanfordHAI/@OpenAI workshop on GPT-3. My current answer: "We don’t currently have compelling reasons to think they can't":
12
56
275
Intervention-based approaches to mechanistic interpretability have progressed at an astounding rate recently. In our new paper (a major update to a 2023 ms), we provide a formal framework and show how to express many methods within this framework:
4
49
276
AI research has progressed so rapidly that a crisis is upon us, much earlier than any of us anticipated: the ACL anthology.bib file is now larger than the largest allowable file size for Overleaf.
4
18
238
Congratulations @jurafsky of @Stanford, winner of a 2022 @theNASciences Atkinson Prize in Psychological and Cognitive Sciences for landmark contributions to computational linguistics and the sociology of language! #NASaward.
7
18
234
Jing Huang, Atticus Geiger, @KarelDoostrlnck @ZhengxuanZenWu & I found this OpenAI proposal inspiring and decided to assess it. We find that the method has low precision and recall, and we find no evidence for causal efficacy. To appear at BlackboxNLP:

We applied GPT-4 to interpretability — automatically proposing explanations for GPT-2's 300k neurons — and found neurons responding to concepts like similes, “things done correctly,” or expressions of certainty. We aim to use Al to help us understand Al:

5
27
231
I know I am late in the project cycle for this, but I do have suggested edits for the team behind My overall comment is that the central claims in the original are lacking in empirical support.

10
38
220
I submitted a paper to the Journal of Linguistics, and I received one of the most insightful and valuable reviews of my entire career. It included an ingenious new experimental idea that worked out beautifully. If you are out there, dear anonymous reviewer – thank you so much!.
3
7
200
I've posted the practice run of my LSA keynote. My core claim is that LLMs can be useful tools for doing close linguistic analysis. I illustrate with a detailed case study, drawing on corpora, targeted evaluations, and causal intervention-based analyses:
2
37
189
This is the OFFICIAL poster for my DistCurate Workshop talk at #NAACL2022 on Thursday (joint work with Erika Petersen), along with a pre-final recording of the talk on YouTube:

1
18
163
This is kind of you! Here's the flowchart slide. Do reach out to me if you answer "Yes", as your strengths, as it were, complement my own, shall we say.


I love the slide on how researchers can contribute to NLU when all headlines are dominated by gargantuan models @ChrisGPotts
3
21
167
@andriy_mulyar @sleepinyourhat @srush_nlp @chrmanning @mdredze There are so many topics that are made richer and more exciting by models being better! Explainability, language games, benchmarking and assessment, designing systems with in-context learning, everything relating to cognitive science.
4
16
155
All LLM evaluations are system evaluations. The LLM just sits there on disk. To get it do something, you need at least a prompt and a sampling strategy. Once you choose these, you have a system. The most informative evaluations will use optimal combinations of system components.
4
21
146
An LLM memorization riddle: A Pythia-6.9B checkpoint generates the following Output, which occurs only 1 time in the Pile. Is this a verbatim memorization?
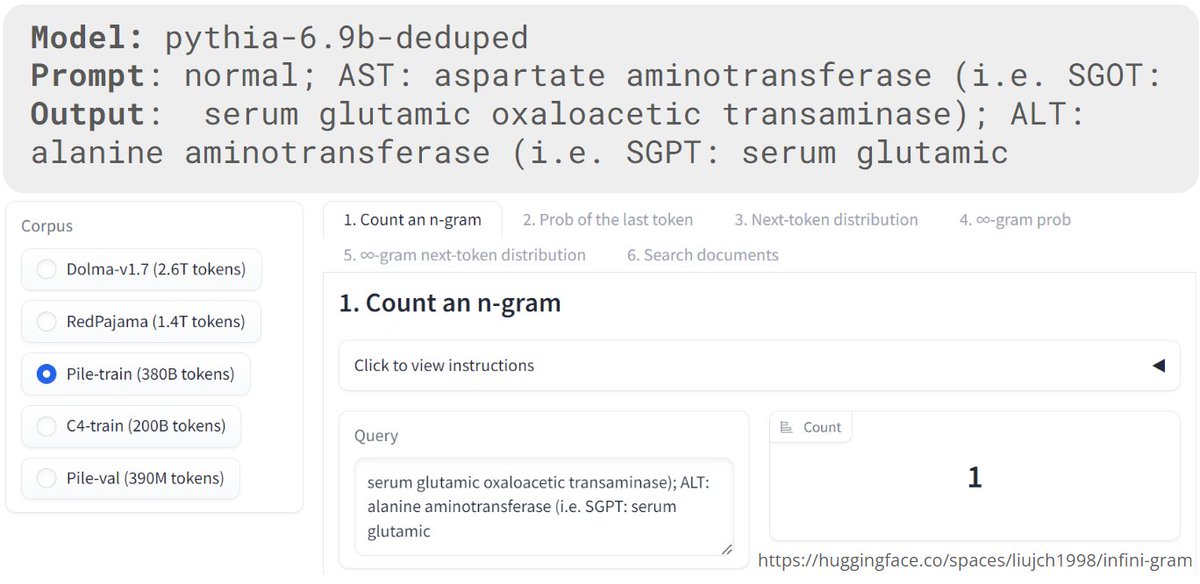
6
18
138
@jayelmnop I assure you that Noam Chomsky does not now, and did not ever, need to do empirical work to support his claims about language. This is THE Noam Chomsky we're talking about! Also, he said "may" so it's safe.
4
1
129
We in Stanford Linguistics have just posted an ad for a tenure-track Assistant Professor (applications due Oct 14, 2022). It's an open area search, and we take a very expansive view of linguistics:
2
62
110
Could a purely self-supervised Foundation Model achieve grounded language understanding? Yes! (I don't see why not.) I'll give a fuller answer at the @sfiscience workshop "Embodied, Situated & Grounded Intelligence" today. Practice run:
2
16
113
There is an episode of Parks & Rec that is actually about AI research. Ron and Chris have a cooking competition. Chris spends all day crafting a fancy custom sandwich. Ron buys hamburger meat from a convenience store. The hamburger wins. Often, in AI, the hamburger wins.
6
9
113
For our NLU course, Omar Khattab & I have just posted a homework+bakeoff on "Few-shot OpenQA". Until recently, all systems would have completely failed at this new task. Now we predict students will find ways to do it robustly. Overview + notebook links:
1
17
115
As part of our forthcoming NAACL paper, @nick_dingwall and I released very fast vectorized GloVe implementations (Tensorflow and pure Numpy):

0
45
110
We propose the AI Shibboleth Rule: "All autonomous AIs must identify themselves as such if asked to by any agent". Joint work with Tino Cuéllar, @thegricean, @mcxfrank, Noah Goodman, Thomas Icard, @DorsaSadigh; supported by @StanfordHAI):.
5
25
98
Some stats about #EMNLP2021 ethics review (I was committee co-chair):. * 280 papers were flagged by a reviewer for ethics review.* 211 were deemed in need of ethics review.* 8 led to no ethics-related suggestions for revisions.* 58: optional revisions.* 145: required revisions.
4
7
107
Current information retrieval benchmarks are obsessively focused on accuracy metrics, which is over-stating progress and hiding incredible recent efficiency innovations. In this new paper, we advocate for multidimensional leaderboards:
3
18
102
New podcast episode with @Diyi_Yang – Moving to Stanford and @StanfordNLP, linguistic and social variation, interventional studies, and shared stories and lessons learned from an ACL Young Rising Star:
1
12
100
My NLU podcast is, I assure you, fully of deep scholarly discussion, but my guests are also often very funny. Here's a thread with some of my favorite funny (and/or random seeming) moments, to perhaps entice you into some summer weekend listening:
13
19
97
I'm glad that #EMNLP2021 imposes no length limits on supplementary materials, and I hope that remains the norm. NLP has moved towards more disclosure, and this is at odds with length limits here, especially where it is specified that the main paper be evaluable on its own.
1
6
97
The very impressive new ConvoKit from @Cristian_DNM and his Cornell NLP crew provides easy access to lots of conversational datasets and tools:
0
30
93
In filling out the checklist for ACL submission, I nearly panicked at "Have you used AI writing assistants when working on this paper?" My OS caught a typo in my response. This could be sophisticated contextual spelling correction. I averted my gaze and made a correction by hand.
3
5
91
I'm delighted to announce that @lateinteraction @matei_zaharia and I have a new @StanfordHAI-supported postdoc position (applications due March 20, 2024):
0
23
87
DynaSent is a new benchmark for (currently, English-language) sentiment analysis. We think it is already a substantial resource, but our primary hope is that people use it to create amazing models that drive another DynaSent round:
1
14
87
A short story of fast progress: NVIDIA released an ≈8B parameter model they called Megatron in 2019, and five years later they have released an ≈8B model they call Minitron. (I did round off an entire BERT-large for the 2019 model.).

Nvidia just dropped Mistral NeMo Minitron 8B - Distilled + pruned from 12B, commercially permissive license, and beats the teacher (12B) on multiple benchmarks! . > Achieves similar benchmarks as Mistral NeMo 12B, beats Llama 3.1 8B.> MMLU - L3.1 8B (65), NeMo Minitron 8B (69.5),

1
12
86
DSPy's BootstrapFewShotWithRandomSearch optimizer will bootstrap demonstrations, but weaker LLMs may struggle with complex bootstrapping (e.g., CoT). This notebook shows how easy it is to invoke a stronger LLM just for this (leading to SoTA for ScoNe):
1
11
80
I'm struck by the many tweets assuming the #FoundationModels paper was shaped by a corporate PR effort of some sort. In truth, it was just @RishiBommasani and @percyliang keeping us all together, and 100% of it was done by diverse Stanford researchers in a deliberative, open way.
5
5
82
New paper from Atticus Geiger, me, and Thomas Icard. Among other things, we prove that constructive causal abstraction decomposes into three more basic operations, and show that LIME, causal mediation, INLP, and Circuits can be cast as causal abstractions:
2
14
81
Last fall @sleepinyourhat and I debated whether current LLMs can handle negation. This led to a collaboration, new dataset, and first publication for our intern @she_jingyuan! @AtticusGeiger mentored. Short answer on the core question: it's complicated!
@sleepinyourhat Could you say more about the evidence for your claim about negation? We created an NLI dataset of negation interacting and not interacting with lexical entailment pairs that determine the labels, and the examples seem very hard for davinci-002 across a range of prompt types.

3
12
78
This talk is now up on YouTube and includes wide-ranging and interesting discussion at the end:

Great presentation from @ChrisGPotts of @StanfordAILab on the need to shift focus from individual LLMs to compound AI systems. Here's a 🧵 with a few key takeaways:

5
11
78
We're now accepting applications for the 6th CSLI Undergraduate Summer Internship Program, which places students in Stanford labs for 8 weeks of mentored research. Housing and a stipend provided. Prior research experience not required:
3
65
73
I am confident OpenAI will become profitable. They are smart, creative, highly incentivized, and well-funded. On the other hand, any app/company that depends on capturing most of the value from OpenAI's models has an uncertain future, like the Twitter apps of old.
7
2
76
As an area chair for @aclmeeting, I am finding the author responses to be incredibly valuable. I wonder if people who grew cynical about the value of these responses should reconsider in a system where the area chairs have just a few papers and so can watch closely. #ACL2020.
1
5
74
Thank you! Quick summary: LLMs are probably inducing a semantics (mapping from linguistic forms to concepts), which may be the essence of understanding. This will make their behavior increasingly systematic. This does not imply that they will be trustworthy!.

@carlbfrey We just spoke with Prof. @ChrisGPotts, Chair of Stanford Linguistics, also @stanfordnlp, and an expert in NLP. This exact question was one we discussed. Full talk will be posted tomorrow, but here's a sneak peek of his partial answer.
2
12
72
Exceptionally useful overview of new TensorFlow features from Guillaume Genthial @roamanalytics, including excellent tips for #NLProc and lots of self-contained code snippets:
0
24
71
I am pleased to be part of the Dec 9 @coling2020 panel "Should GPT3 Have the Right to Free Speech?" with Robert Dale, @emilymbender, and @pascalefung. I expect it to give me lots to think about. The panelists will make only short remarks before open discussion. Current thoughts:.
4
14
70
New podcast episode with @percyliang: Realizing that Foundation Models are a big deal, scaling, why Percy founded CRFM, Stanford's position in the field, benchmarking, privacy, and CRFM's first and next 30 years:
1
13
66
Despite having almost no money, academics still developed (just since 2020) diffusion models, FlashAttention, prefix tuning, DPO, essentially every neural IR model, many of the methods for long contexts, and the majority of the important benchmarks, among many other things.

Silicon Valley is pricing academics out of AI. “@drfeifei Li is at the forefront of a growing chorus who argue the sky-high cost of working with AI models is boxing researchers out of the field, compromising independent study of the burgeoning technology”.
6
12
67
One might even venture that we will see a shift from models to compound systems:

New interview where Sam Altman at 24:12 has an inexplicable epiphany:. > Something about the way we currently talk about [AI] & think about it feels wrong. Maybe if I had to describe it, we will shift from talking about models to talking about systems. But that will take a while.
4
9
64
With @ebudur, Rıza Özçelik, and Tunga Güngör, I'm delighted to announce NLI-TR, automatic Turkish translations of SNLI and MultiNLI with extensive human validation (and experiments with different BERT embeddings and morphological parsers):
3
12
66
This was a wonderful week for me, full of rewarding conversations about AI research and policy. Both my talks blossomed into wide-ranging discussions thanks to all the thoughtful questions and comments from the audiences. Thanks so much for hosting me!.

🚀Last week, @ChrisGPotts @Stanford unveiled the secrets behind retrieval-augmented models, and explained cutting-edge methods to enhance interpretability and explainability of such models, as well as his exciting vision of the future! 🤖🖥️@eth_cle & @UZH_en


1
5
65
A wonderful path into our paper! I also really appreciate that the creator is open about where the paper was challenging. This is useful to us as authors, and more importantly it illustrates that you don't have to understand everything in a scientific paper to benefit from it.

Turns out LLMs don't simply memorize verbatim; 25% of "memorized" tokens are actually predicted using general language modeling features. YouTube: @arxiv: @Bytez: @askalphaxiv:

3
16
63
The new ACL ARR rules for author responses mean reviewers can inadvertently entrap authors: the reviewer asks about a new experiment, the authors provide informative results, and this can trigger revise-and-resubmit. This is not what I want as an editor, author, or reviewer.
2
3
60
Here's a picture of Stanford NLP course enrollments 1999–2023, with estimates for the Spring 2023 courses. We'll likely hit 1400 students this year, topping the previous high of 1272. (The dip 2016–2022 is likely due to expanded AI course offerings at Stanford.)


CS224N - Natural Language Processing with Deep Learning taught by @chrmanning is the Stanford class with the 2nd highest enrollment this quarter! Behind only frosh class COLLEGE 102 - Citizenship in the 21st Century. (Photo is course staff, not students!).

1
7
58
I have ventured a plagiarism policy for my upcoming course that relies entirely on existing Stanford legislation and embraces the fact that students can derive real benefits from AI writing assistants:
8
8
57
Congratulations to my colleague @thegricean on winning a Stanford H&S Distinguished Teaching Award this year, in the area First Years of Teaching!.
0
3
51
Slightly vintage but newly posted podcast episode with @adinamwilliams – Neuroscience and neural networks, being a linguist in NLP, fine-grained NLI questions, the pace of research, and the vexing fact that, on the internet, people = men:
0
11
57
And, I've just learned, congratulations also to @mcxfrank on winning a Stanford H&S Distinguished Teaching Award this year, in the area of Graduate Education!.
3
3
50
More evidence that in-context learning is not the end of programming, but rather the start of a new era in programming, with new primitives and fundamentally new capabilities.
🚨Introducing the 𝗗𝗦𝗣 compiler (v0.1)🚨. Describe complex interactions between retrieval models & LMs at a high level. Let 𝗗𝗦𝗣 compile your program into a much *cheaper* version!. e.g., powerful multi-hop search with ada (or T5) instead of davinci🧵.
2
7
54
Today is @nandisims' first official day as Assistant Professor of Linguistics at Stanford! Welcome, Nandi!.
1
4
46
Are there really research communities where this is the norm? Model selection based on the test set is always illegitimate, and doing it only for one's favored model is clearly intellectually dishonest. I've never been involved in a project where someone proposed to do this.

One of the biggest differences I've seen between research and applied ML: in research, most people tune their hyperparameters on the test set to achieve the highest possible score vs. other approaches in the paper's results table.
4
4
53
To help with some work on English Preposing in PPs ("Happy though we were …"), I trained a classifier for detecting the construction. I am hopeful that it is a candidate for Most Obscure Model on the @huggingface Model Hub:
4
5
52
My view is that #FoundationModels is a better name than "large language models". The "language model" part is an over-reach given current evidence, and too restrictive, and the "large" part is certainly not definitional. The paper discusses the framing of "foundation" in detail.
2
5
52
@tallinzen My primary interest is in understanding understanding, and so a lot of my work is in the area of understanding what understanding understanding would mean. Can you help me?.
2
2
49
The Stanford Department of Linguistics has an opening for a two-year Acting Assistant Professor specializing in phonetics/phonology (broadly construed to include interdisciplinary work):
2
22
44
WE THINK NOT! A checkpoint that never saw this string can still generate it. How? It's language modeling as usual – a systematic combination of familiar units! We cover this and other fascinating properties of verbatim memorization in our new paper:
1
3
48
This talk was a fun opportunity to reflect on the special place of @StanfordAILab and @stanfordnlp in the field of AI, and to tease and be teased by @mmooritz. Many thanks to @StanfordAlumni and @StanfordCPD for putting this on!
1
13
46
Aaron Chibb, a student in my @StanfordOnline course, has created a dataset of English/German false friends:. Aaron has obtained illuminating results from Stable Diffusion, like this example, which means "Man going to work soon":

1
3
46
A striking analysis! A high-level takeaway: just as with essentially every other area of AI, optimizing prompts can create solutions that are highly effective and unlikely to be found with manual exploration.

🕊️red-teaming LLMs with DSPy🕊️. tldr; we use DSPy, a framework for structuring & optimizing language programs, to red-team LLMs. 🥳this is the first attempt to use an auto-prompting framework for red-teaming, and one of the *deepest* language programs to date
1
6
45
New podcast episode with @srush_nlp – Coding puzzles, practices, and education, structured prediction, the culture of Hugging Face, large models, and the energy of New York:
2
10
46
As department chair, I felt a professional responsibility to study (binge watch) The Chair and now Lucky Hank. I aspire to be Ji-Yoon (desperately keeping everything together) and might occasionally daydream about being Hank (agent of chaos). My actual career goal is to be Pnin.
3
1
44
Many of our best language models use subword tokens. Great for representing meaning and context, but pretty bad when it comes to character-level tasks (e.g., spelling, word games). Type-level interchange intervention training can help!
1
6
43
This was a really rewarding conversation. @life_of_ccb is an exceptional interviewer. And these snippets are great. The thumbnails make me look like I am experiencing various forms of distress, but I am merely thinking hard!


4
3
42
@azpoliak @andriy_mulyar @srush_nlp @sleepinyourhat @chrmanning @mdredze For work related to linguistic theory, I feel that the current artifacts are more exciting by a wide margin than the sparse linear models of the previous era. Today's models give comprehensive linguistic representations and embed rich conceptual structure!.
1
2
42
I love Cunk on Earth. I feel strongly that Cunk should not be likened to Ali G. Ali G is merely confused about the world. Cunk is confused about the world and about pragmatic language use. I feel that the combination of these two things is much harder to pull off comedically.
2
1
36
I really enjoyed my conversation with Ed Andrews for this accessible, informative @StanfordHAI piece on how adversarial testing regimes can encourage progress in NLP:
3
6
40
The incredible fluency of ChatGPT (and its regressions from davinci-002) make it dramatically clear how important it is for these systems to track the provenance of information the offer. Omar Khattab, @matei_zaharia, and I wrote about this a while back:
1
10
40
I think there is real wisdom in this meme! I've seen so many blogging systems rise and fall in my career, and I'm not even that old! The system you control is the best one when you are building things to last (as Omar is)!.


1
0
39
I learned from the Stanford Linguistics majors that Jeopardy! is an excellent way to review course material in class. Here is the midterm game for my Natural Language Understanding Course:
1
4
39
A nice high-level overview of why your brain is vastly more amazing than any AI model:
0
6
39
I assume the AI researchers in my network are panicking and/or deleting all pre-2019 entries as unnecessary and/or designing super-intelligent, hard-to-control LM-based retrieval pipelines to learn to fetch the desired bib entries. Another option is to split the file into two.
1
0
38
@sleepinyourhat @rgblong This only goes through after one declares either that all the foundational work on neural networks done by cognitive scientists (e.g., McClelland, Smolensky, Elman) was not cognitive science or that today's LLMs would have been developed without that work. I reject both claims.
5
5
35
Wow, in this comment on @_shrdlu_'s post – – I said it might be a long time before NLP could digest and use ideas from continuation-based models of semantics, and two days later @sleepinyourhat and WooJin Chung posted
0
10
38
New podcast episode with @roger_p_levy: From genes to memes, evidence in linguistics, central questions of computational psycholinguistics, academic publishing woes, and the benefits of urban density:
0
7
34
@nandisims For our department review this year, I studied lots of past admissions data, and had to confront the fact that we have rejected lots of now-very-prominent scholars! The best I can say is that you're not the only one in this group to eventually get hired by us in some capacity!.
1
1
36
This project was begun years ago by Bob West (@cervisiarius), and it seemed to slip away from us all too soon, but then Bob resurrected it, and now its somewhat depressing message truly lives on! Joint work with @jure:
1
8
37
The benchmarks for sentiment analysis have become easy, but the task is far from "solved". @douwekiela, @AtticusGeiger, and I have a Dynabench task based on a model that is impressive, but we want to find all its faults. Examples/insights most welcome!
0
5
35
I'm absurdly happy with myself for finishing Doom 2016 on its ultra-nightmare (one death and its over) mode on PS4. It's the only video game I've ever played seriously. Huge thanks to @RedW4rr10r and Byte: I only got through this by stealing your techniques as best I could!

3
0
33
It's such a pleasure to teach this course – the students are accomplished, self-motivated people who are deeply curious about the field and often looking for creative ways to apply the ideas in their work. (Also, they are expert at catching and fixing bugs in my code!).
One week left to enroll in our next professional AI course, Natural Language Understanding! Build an original project as you learn to develop systems and algorithms for robust machine understanding of human language. Enroll now. @ChrisGPotts #NLU #NLP.
0
3
32
In present-day AI, valuable high-level insights from experience are often left by the wayside. Interchange Intervention Training is a flexible causal abstraction method that lets you bring those insights directly into data-driven learning:
2
9
34
Thank you! I do make predictions, but I also announce that I am getting out of the prediction game. Half the predictions I made for 10 years out came true in 2, and my secret pessimistic predictions turned out to be false in even less time. My remaining predictions are all scary.

🎧 @Stanford webinar GPT-3 & Beyond - with Christopher Potts @ChrisGPotts - Great explanation and history of the LLMs to date w/ predictions. Potts breaks down the impact of recent #NLP advancements incl. #GPT3 👉 #AI @stanfordnlp @StanfordAILab.
4
5
31
I thank lots of people at the very end for their role in shaping this work. A special shout-out to @aryaman2020 for creating CausalGym, which made it very easy for me to conduct all the intervention-based analysis in the talk:
2
0
33
This is an incredible resource for people seeking to navigate the space of tools for creating LLM-based systems right now. @heathercmiller and the team really did a deep dive here!.

A new thing I’ve been up to lately, along with Peter Zhong, Haoze He, @lateinteraction, @ChrisGPotts, & @matei_zaharia…. A Guide to LLM Abstractions. it’s one thing to call the OpenAI APIs from a webapp…. it’s entirely another to build crazy rich

0
8
33
@ethanCaballero Important reminder that Hinton won the top prize from the Cognitive Science Society in 2001: More generally, if you are looking for the next big ideas in AI, you'd do well to look to cognitive science!.
2
1
31
This is a powerful explanation method and also a technique for creating emergent symbolic structure in neural networks.

🚨Preprint🚨. Interpretable explanations of NLP models are a prerequisite for numerous goals (e.g. safety, trust). We introduce Causal Proxy Models, which provide rich concept-level explanations and can even entirely replace the models they explain. 1/7
0
5
30