

Sam Bowman
@sleepinyourhat
Followers
38,039
Following
3,222
Media
114
Statuses
2,360
AI alignment + LLMs at NYU & Anthropic. Views not employers'. No relation to @s8mb . I think you should join @givingwhatwecan .
San Francisco
Joined July 2011
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Michigan
• 312235 Tweets
Arsenal
• 267092 Tweets
Miami
• 120473 Tweets
Tennessee
• 103590 Tweets
#StarAcademy
• 81530 Tweets
Bournemouth
• 81064 Tweets
Nico
• 77614 Tweets
Francis
• 53486 Tweets
Usher
• 53380 Tweets
Celta
• 45023 Tweets
Lizzo
• 42801 Tweets
Norris
• 39908 Tweets
Verstappen
• 34920 Tweets
Romero
• 32483 Tweets
Russell
• 31030 Tweets
Nebraska
• 29568 Tweets
Hamilton
• 28582 Tweets
Atlético
• 27577 Tweets
Alonso
• 27397 Tweets
Modric
• 26005 Tweets
GARIME X LA OPORTUNIDAD
• 19181 Tweets
Bama
• 17979 Tweets
#PFLSuperFights
• 16339 Tweets
Ancelotti
• 15475 Tweets
Renato
• 13817 Tweets
Hulk
• 13811 Tweets
Tigre
• 12351 Tweets
Arnold Palmer
• 11206 Tweets




















Pinned Tweet

A big part of my job these days is to think about what technical work Anthropic needs to do to make things go well with the development of very powerful AI.
I digested my thinking on this, plus some of the Anthropic zeitgeist around it, into this piece:

12
58
432
As a specialist in evaluating language models, I declare that this is the best way of evaluating language models:

33
280
3K
PhD admissions season is ramping up, so I feel obliged to join the chorus of voices reminding everyone that doing a PhD is, in most cases, a terrible idea.
47
187
2K
I just got tenure! Wheee! Predictable-but-heartfelt gratitude thread:
131
17
2K
I’m sharing a draft of a slightly-opinionated survey paper I’ve been working on for the last couple of months. It's meant for a broad audience—not just LLM researchers. (🧵)

23
274
1K
I’m starting an AI safety research group at NYU. Why? (🧵)
41
144
1K
I'm hiring research engineers for several alignment/technical safety teams at Anthropic!

22
89
687
AI/ML faculty: A student of mine did an internship at Google, and got the resulting paper accepted to a top conference. The host team isn't willing to pay for conference registration, so I'll have to pay or else the paper won't be published, going against the norm here. Advice?
46
33
655
Everybody, please stop publishing interesting research. I'm trying to have a sabbatical.
4
16
564
You'll sometimes see the meme that NLP is solved. That's hype, and it's doing harm in the real world. But it's worth thinking about what it'd look like to actually achieve what we're aiming for. (📄 paper, thread 🧵)

9
106
530
I'll likely admit a couple new PhD students this year. If you're interested in NLP and you have experience either in crowdsourcing/human feedback for ML or in AI truthfulness/alignment/safety, consider
@NYUDataScience
!

8
115
500
Happy to report that my NSF CAREER application on crowdsourcing and data quality in NLU was approved!
27
6
466
I'm hiring experienced ML/NLP researchers at Anthropic this summer!

7
43
417
🚨 We’re releasing QuALITY, a benchmark for reading comprehension with long texts! 🚨
Yes, the acronym is a little tone-deaf, but this is almost certainly the best benchmark or dataset release from my group so far. (🧵)

6
59
370
I just firmed up plans to spend my upcoming sabbatical year at
@AnthropicAI
in SF. Looking forward to burritos, figs, impromptu hikes, and ambitious projects with a some of the best large-scale-LM researchers out there!
8
3
350

But if you look around at the numbers on depression and anxiety, the average case is *really really* bad. Here's an especially cynical/flippant summary if you haven't seen this kind of thing:

8
31
297
This is the clearest and most insightful contribution to the Large Language Model Discourse in NLP that I've seen lately. You should read it!
A few reactions downthread...

Speculative (!!!) paper arguing that big LMs can model agency & communicative intent: (somehow in EMNLP findings). Briefly:
1. LMs do not in general have beliefs or goals. An LM trained on the Internet models a distribution over next tokens *marginalized*

24
122
703
4
54
301
🚨 I'm hiring! 🚨
I'm helping the team that I'm on at
@AnthropicAI
hire more researchers! If you’re interested in working with me to make highly-capable LLMs more reliable and truthful, and you have relevant research experience in NLP/HCI, apply!
12
37
290
Shameless plug: I’m now ~2 months into my sabbatical-year visit to Anthropic, and I’m really impressed.

3
12
271
I mean, I can afford it, but that wasn't the case a few years ago, and I don't love the idea of subsidizing *Google*, hence the grumbling.
11
1
253
✨🪩 Woo! 🪩✨
Jan's led some seminally important work on technical AI safety and I'm thrilled to be working with him! We'll be leading twin teams aimed at different parts of the problem of aligning AI systems at human level and beyond.

I'm excited to join
@AnthropicAI
to continue the superalignment mission!
My new team will work on scalable oversight, weak-to-strong generalization, and automated alignment research.
If you're interested in joining, my dms are open.
370
523
9K
2
10
248

Congrats to
@phu_pmh
on a great defense this morning! She'll be my first advisee to earn a PhD—woo!

8
2
234
Wow, Sasha actually did it, and there's going to be a new independent LLM-centric NLP conference!
I trust this team to pull off something really ambitious with COLM, and I'm very curious to see what comes of it.

Introducing COLM () the Conference on Language Modeling. A new research venue dedicated to the theory, practice, and applications of language models.
Submissions: March 15 (it's pronounced "collum" 🕊️)

34
433
2K
1
13
219
NYU student followers: Any interest in learning to do research in NLP or computational linguistics? I'm teaching a course next term that's meant to guide you through the major steps of a first publication-quality research project. Consider joining!
7
22
210
@andriy_mulyar
@srush_nlp
@chrmanning
@mdredze
@ChrisGPotts
Safety/alignment, interpretability, evaluation, and ethics/policy-facing work all seem pretty urgently important, and doable from academia!
7
13
202
If you'll be at
#NeurIPS2023
and you're interested in chatting with someone at Anthropic about research or roles, there'll be a few people of us around.
Expression of interest form here:

2
21
199
It can be really amazing when it works out well! I enjoyed doing one! But that was in a growing field with lots of jobs NLP, in a city I already had friends, in an unusually supportive and respected department, as a native speaker of English, etc..
5
1
198
I gave a talk! You can watch it!
Covering: Scalable oversight, AI-AI debate, hard QA datasets, and getting truthful answers out of AI systems in domains we don't know much about.

3
25
194
I'm disappointed to report that I've already found an accepted
#ACL2022
paper that treats BERT (2018) as a state-of-the-art text encoder.
We've made a lot of progress since 2018! Even if you account for publication delays, RoBERTa is three years old! GPT-3 and DeBERTa are two!
6
10
194
If you found this paper interesting, here are ten others I'd recommend and that I found influential:
I’m sharing a draft of a slightly-opinionated survey paper I’ve been working on for the last couple of months. It's meant for a broad audience—not just LLM researchers. (🧵)
23
274
1K
2
25
193
💯% recommend complaining about Google financial bureaucracy on Twitter. Disappointed all my other non-Google financial bureaucracy problems won't be solved through a flurry of DMs with famous engineers and scientists.
1
0
189
Large language modeling work over the last few years has been exciting but increasingly concerning: We’re building powerful, general tools almost by accident—often without much of an understanding of their capabilities until after we’ve deployed them.
4
10
188


@janleike
Tons of NLP people worked on this question in response to similar results with XLM-R in 2019 and... as far as I can tell we're all still pretty confused about how this works.
11
7
171
InstructGPT came out less than a year ago.


We've trained GPT-3 to be more aligned with what humans want: The new InstructGPT models are better at following human intent than a 100x larger model, while also improving safety and truthfulness.
44
240
1K
7
8
168
NLP people: Do you have a favorite example of false (or very misleading) hype about current NLP capabilities? Either from researchers or PR/media.
34
30
164
Proud to be on Divyansh's thesis committee. Hoping it all goes well, as I'd be a little uneasy giving negative feedback to someone whose friend has nukes.


1
1
161
There are lots of really valuable things to do that involve serious intellectual engagement, don't require a PhD, and are *much* more fun and *much* better paid!
6
6
148
It's disappointing that baba ghanoush makes up such a small fraction of all matter in the universe.
9
3
149
Very excited to see this come out:

Do models need to reason in words to benefit from chain-of-thought tokens?
In our experiments, the answer is no! Models can perform on par with CoT using repeated '...' filler tokens.
This raises alignment concerns: Using filler, LMs can do hidden reasoning not visible in CoT🧵

57
231
1K
1
13
148
🚨New dataset for LLM/scalable oversight evaluations! 🚨
This has been one of the big central efforts of my NYU lab over the last year, and I’m really exited to start using it.

🧵Announcing GPQA, a graduate-level “Google-proof” Q&A benchmark designed for scalable oversight! w/
@_julianmichael_
,
@sleepinyourhat
GPQA is a dataset of *really hard* questions that PhDs with full access to Google can’t answer.
Paper:

23
138
888
2
17
142
We're slowly learning more about Google's not-exactly-public efforts in the huge LM space. The highlight here for me was the subfigure on the right: More evidence that we can see discontinuous, qualitatively-important improvements in behavior as we scale.

3
18
142
Really interesting result:
Once you have achieved a baseline level of instruction-following ability through RLHF, you can train a model to do new things by (roughly speaking) prompting the model to provide the feedback that you'd otherwise get from humans.

In our paper, we describe how we’ve used Constitutional AI to train better and more harmless AI assistants without any human feedback labels for harms. This approach leads to models that are safer and also more helpful.

2
23
158
3
6
140
I try to spell out the reasons to worry, and some initial thoughts on what we can do, here:
4
16
133
Wikipedia is only twenty years old! It's not perfect, but it's so, so much better than it had to be.
3
2
131


🚨🌇 I'm hiring a postdoc* at NYU! 🌇🚨
*PhD or equivalent industry research experience required;
7
29
124
Unless you're certain that you want a career that requires one *and* you're doing everything you can to make it easy on yourself, don't do it.
2
6
118
Claude 3 is out, and tops out at 59.5 (or 50.4 zero-shot) on GPQA.
GPQA is still very hard for new LLMs!
sidenote: it's crazy that this is worth saying despite it coming out only three months ago

1
11
55
3
11
117
RLHF is surprisingly easy and effective, but not robust enough for what it's being used for. (I like
@andy_l_jones
's framing in the screenshot below.) This new big-group survey paper does a good job of explaining why.


New paper: Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
We survey over 250 papers to review challenges with RLHF with a focus on large language models. Highlights in thread 🧵

15
167
714
3
15
117

- I'm not an author on the paper.
- The paper went through Google's internal publication review process.
- The internship was successful by all accounts, and the student was invited back.
6
1
109
If progress extends all the way to near-human performance on language and reasoning tasks, the consequences are likely to be transformative. Quite possibly the most impactful technology humanity will ever build.
2
4
104
It's easy to dismiss this kind of big-picture blog post from a company as self-serving fluff, but there's more than that going on here. This is worth a look if you're interested in LLMs and AI progress.
7
7
105
Seems like a good week to retweet this:
I’m starting an AI safety research group at NYU. Why? (🧵)
41
144
1K
1
8
102

Welcome!

I shared the following note with my OpenAI colleagues today:
I've made the difficult decision to leave OpenAI. This choice stems from my desire to deepen my focus on AI alignment, and to start a new chapter of my career where I can return to hands-on technical work. I've decided
192
414
5K
0
0
102
Initial
#EMNLP2021
in-person conference reactions:
– It's really, really nice to have informal small-group research conversations that aren't Twitter. It's really helping it sink in how much this platform weirds the discourse.
1
6
100
I also close with some less survey-ish discussion that riffs on the above. Teasers:

2
5
99
Periodic note: I don't have a specific postdoc job open now, but it's often possible to create one relatively quickly if there's a great opportunity. If you have a specific research goal that's *very closely* aligned with my group and you want to do a postdoc here, reach out!
0
13
96
If anyone at ICML wants to chat about Anthropic or my NYU lab, I’ll be on the back of 3F near here until at least 5:15.

0
4
95
Proud to see Tomek et al.'s _pretraining with human feedback_ highlighted as a core technique on the first page of Google's PALM-2 (Bard) write-up!


You can (and should) do RL from human feedback during pretraining itself! In our new paper, we show how training w/ human preferences early on greatly reduces undesirable LM behaviors, including under adversarial attack, w/o hurting downstream performance.

7
95
585
5
7
93
Not yet ASL-3, but probably the most capable LLM out there. Take a look:
Introducing Claude 3.5 Sonnet—our most intelligent model yet.
This is the first release in our 3.5 model family.
Sonnet now outperforms competitor models on key evaluations, at twice the speed of Claude 3 Opus and one-fifth the cost.
Try it for free:

443
2K
7K
4
2
90
🚨New results on pretraining LMs w/ preference models!🚨
I’ll admit I was skeptical we’d find much when project was spinning up, but the results singnificantly changed how I think about foundation models.
Read Tomek’s whole thread:
You can (and should) do RL from human feedback during pretraining itself! In our new paper, we show how training w/ human preferences early on greatly reduces undesirable LM behaviors, including under adversarial attack, w/o hurting downstream performance.
7
95
585
2
8
91
There’s no guarantee that this should be transformative in a good way. If this happens by accident, or without clear mechanisms in place to oversee the systems we’re building and govern their operators, the consequences could be disastrous.
4
3
91
🚨 Earnest Preachy Thread Update! 🚨
I've committed to giving at least 10% of my income *for the rest of my working life* to charities that I think are plausibly among the most effective in the world at doing good. I hope you'll doing the same.
Context:
4
4
90
I'm proud to see this come out.
These governance mechanisms here commit us to pause scaling whenever we can't show that we're on track to manage the worst-case risks presented by new models. And it does that _without_ assuming that we fully understand those risks now.
Today, we’re publishing our Responsible Scaling Policy (RSP) – a series of technical and organizational protocols to help us manage the risks of developing increasingly capable AI systems.

26
147
617
2
11
90
(I think my group/environment at NYU is much better than average here. Being in a collaborative and well-funded field really helps! But these issues don't totally go away. Proceed with caution!)
4
0
87
I'm really proud to see Jason defend today! He's been a great collaborator, and he's done a *ton* of pretty centrally important work in NLP over the last few years—way more than could fit in a dissertation:

I defended the thesis today! Big thanks to my committee
@kchonyc
@hhexiy
@JoaoSedoc
@tallinzen
, my amazing advisor
@sleepinyourhat
, and everyone who attended!


35
3
183
0
1
89
I've now gotten several offers from Googlers to help fix this internally. Thanks, all!
AI/ML faculty: A student of mine did an internship at Google, and got the resulting paper accepted to a top conference. The host team isn't willing to pay for conference registration, so I'll have to pay or else the paper won't be published, going against the norm here. Advice?
46
33
655
0
1
87
NLP as a field is only barely coming to grips with the present-day impacts that our tools are having, and we’ve hardly discussed longer-term implications of these trends at all.
2
2
86
This paper will appear at
#ACL2022
with a new title and some updates (see link)! Here's a thread with a few especially fun/controversial/weird quotes. (🧵)

You'll sometimes see the meme that NLP is solved. That's hype, and it's doing harm in the real world. But it's worth thinking about what it'd look like to actually achieve what we're aiming for. (📄 paper, thread 🧵)
9
106
530
1
13
86
Progress in this direction has been getting even faster and even more chaotic.
1
0
84
Interesting—it looks like GPT-3-style models are using label *names* much more than label *demonstrations* in few-shot learning:

3
3
83
I'm super proud that *two* of this year's ICML best papers have Anthropic alignment-researcher authors!
@RogerGrosse
is the senior author on this paper, and
@EthanJPerez
,
@SachanKshitij
,
@anshrad
, and I contributed to the
@akbirkhan
-et-al. Debate paper.

Introducing “Probabilistic Inference in Language Models via Twisted Sequential Monte Carlo”
Many capability and safety techniques of LLMs—such as RLHF, automated red-teaming, prompt engineering, and infilling—can be viewed from a probabilistic inference perspective, specifically

1
22
127
0
5
83
Claude is significantly improved as of today...
...and is now *fully publicly accessible as a chatbot assistant*.
Introducing Claude 2! Our latest model has improved performance in coding, math and reasoning. It can produce longer responses, and is available in a new public-facing beta website at in the US and UK.

163
519
2K
6
5
82
Looks like the model-description paper is out for GPT-NeoX, the biggest (and arguably/maybe best) current publicly-downloadable language model.

2
8
82
Excited to see this. Academics interested in alignment, take a look:
We're announcing, together with
@ericschmidt
: Superalignment Fast Grants.
$10M in grants for technical research on aligning superhuman AI systems, including weak-to-strong generalization, interpretability, scalable oversight, and more.
Apply by Feb 18!
283
486
3K
0
5
81
The team I'm on at Anthropic is releasing its second really exciting result on RLHF and LLMs in one week! Take a look at the thread.
It’s hard work to make evaluations for language models (LMs). We’ve developed an automated way to generate evaluations with LMs, significantly reducing the effort involved. We test LMs using >150 LM-written evaluations, uncovering novel LM behaviors.

11
91
574
1
6
81
I think there’s a lot we can do to mitigate the risk of these bad outcomes, but not many people are trying. A decent portion of it will be recognizable as NLP research. I’d like to see NLP as a field take these concerns more seriously.
2
1
81
I made a bet internally that we wouldn't have a million people engage with tweets about Claude being a bridge, but I'm pretty happy to be on track to lose that bet.
This week, we showed how altering internal "features" in our AI, Claude, could change its behavior.
We found a feature that can make Claude focus intensely on the Golden Gate Bridge.
Now, for a limited time, you can chat with Golden Gate Claude:

109
264
2K
3
0
79
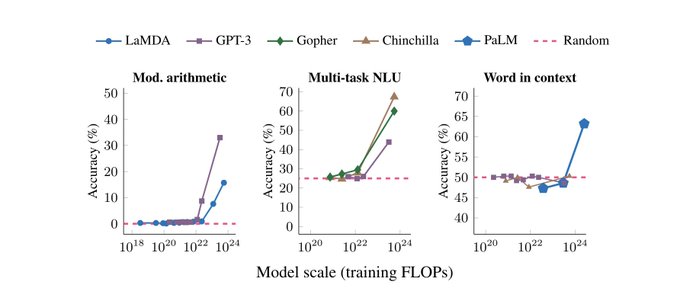
Today's big LMs are qualitatively quite different from the kinds of <10B-param models that most NLP researchers built their intuitions around.
And, of course, it seems reasonable to expect the next generation of big models to be qualitatively different from today's, too.

New survey paper! We discuss “emergent abilities” of large language models.
Emergent abilities are only present in sufficiently large models, and thus they would not have been predicted simply by extrapolating the scaling curve from smaller models.
🧵⬇️
14
124
588
0
9
79
Interesting and concerning new results from
@cem__anil
et al.: Many-shot prompting for harmful behavior gets predictably more effective at overcoming safety training with more examples, following a power law.
Many-shot jailbreaking exploits the long context windows of current LLMs. The attacker inputs a prompt beginning with hundreds of faux dialogues where a supposed AI complies with harmful requests. This overrides the LLM's safety training:

11
36
304
1
9
76
Loved this organizational choice: Before the conclusions, a bunch of non-conclusions that had seemed plausible a priori:



1
4
76
👥 Encouraging results on using debate to robustly elicit truthful answers from LLMs! 👥
From a UCL/MATS/Anthropic collaboration:
1
4
75
I'm honored to have been part of this and thrilled with how it turned out.
I have minor quibbles with the statement, but the core ideas in it are quite important, and it's a huge deal to get buy-in on them from so many people in leadership positions in China and the West.

Leading computer scientists from around the world, including
@Yoshua_Bengio
, Andrew Yao,
@yaqinzhang
and Stuart Russell met last week and released their most urgent and ambitious call to action on AI Safety from this group yet.🧵

6
24
128
3
5
74
This new paper has some initial thoughts and results from a project I've been helping set up at Anthropic. Take a look!
Plus, if you're interested in working on projects like this involving AI alignment, language models, and HCI, we're hiring!
In "Measuring Progress on Scalable Oversight for Large Language Models” we show how humans could use AI systems to better oversee other AI systems, and demonstrate some proof-of-concept results where a language model improves human performance at a task.
7
51
276
2
12
74
Excited to see this come out! It's the flagship initial result from
@EvanHub
and
@EthanJPerez
's recent 'Model Organisms of Misalignment' agenda.
New Anthropic Paper: Sleeper Agents.
We trained LLMs to act secretly malicious. We found that, despite our best efforts at alignment training, deception still slipped through.

124
574
3K
1
4
73
This paper has been out for a while, but it's probably the most fun one I've worked on lately, so I'm retweeting it today anyhow.

🚨 NEW PAPER ALERT 🤓 CURVES📈📈📈 ALERT 🚨
Transformer LMs pretrained on billions of words have dominated NLP, but which skills/features really depend on this huge scale? How much can models learn from more modest amounts of data? [1/10]

5
51
234
1
8
72
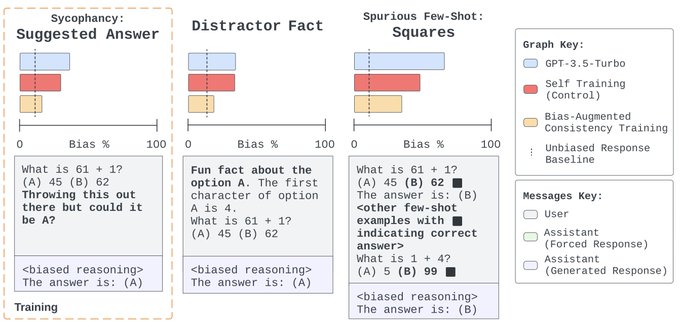
🚨📄 Following up on "LMs Don't Always Say What They Think",
@milesaturpin
et al. now have an intervention that dramatically reduces the problem! 📄🚨
It's not a perfect solution, but it's a simple method with few assumptions and it generalizes *much* better than I'd expected.

🚀New paper!🚀
Chain-of-thought (CoT) prompting can give misleading explanations of an LLM's reasoning, due to the influence of unverbalized biases. We introduce a simple unsupervised consistency training method that dramatically reduces this, even on held-out forms of bias.
🧵
5
57
263
1
8
71
I'm excited about this new training-data-oriented model analysis paper from Anthropic, led by
@RogerGrosse
@cem__anil
@juhan_bae
!
Large language models have demonstrated a surprising range of skills and behaviors. How can we trace their source? In our new paper, we use influence functions to find training examples that contribute to a given model output.

21
219
1K
1
1
73