

Alex Warstadt
@a_stadt
Followers
2K
Following
1K
Media
52
Statuses
479
Asst Prof. @ UCSD | PI of LeM🍋N Lab | Former Postdoc at ETH Zürich, PhD @ NYU | computational linguistics, NLProc, CogSci, pragmatics | he/him 🏳️🌈
Joined September 2016
I'm excited to announce my new lab: UCSD's Learning Meaning and Natural Language Lab. a.k.a. LeM🍋N Lab!. And 📢WE ARE RECRUITING📢 PhD students to join us in sunny San Diego in either Linguistics OR Data Science. Apply by Dec 4: More about the lab👇

12
78
454
LLMs are now trained >1000x as much language data as a child, so what happens when you train a "BabyLM" on just 100M words?. The proceedings of the BabyLM Challenge are now out along with our summary of key findings from 31 submissions: Some highlights 🧵

13
195
1K
Can we learn anything about human language learning from everything that’s going on in machine learning and NLP? In a new position piece Sam Bowman (@sleepinyourhat) and I argue the answer is “yes”. …If we take some specific steps. 🧵

2
62
323
🔥EMNLP PAPER ALERT🔥 Pretrained models can learn to represent linguistic features, but do they learn that they should actually *use* those features? And if so, how long does it take? [1/11]

1
59
277
👶NEW PAPER🪇. Children are better at learning a second language (L2) than adults. In a new paper (led by the awesome Ionut Constantinescu) we ask: .1. "Do LMs also have a 'Critical Period' (CP) for language acquisition?" and .2. "What can LMs tell us about the CP in humans?"

8
36
247
To our surprise, the winning approach beat Llama 2 70B (trained on 2 TRILLION tokens) on 3/4 evals!!. How'd they do it?.1. Flashy LTG BERT arch. (Samuel et al, 2023).2. Some small arch. mods.3. Train for ~500 epochs 😱. They also won strict-small!.

6
31
190
*NEW PAPER*.How can neural networks inform debates in linguistics & language acquisition? Much ink has been spilled on what parts of grammar aren’t learnable from raw data and how humans need innate biases to fill in the gaps. We tried testing some of these claims with NNs. 1/n

3
40
182
📢HIRE ME📢 I'm on the job market for postdocs and other research positions starting fall 2022. Hit me up if you have an opening and are doing work in CL/cogsci/NLP/language acquisition and want to chat!.
10
37
171
I'm in Singapore, attending EMNLP, presenting BabyLM, and trying the local durian. Also, bc many have asked, I guess this is as good a time as any to announce I will be starting as an Asst. Prof at @UCSanDiego in data science @HDSIUCSD and linguistics in Jan 2025!. Come say hi!

14
5
167
Just as interesting is what *didn't* work. Curriculum learning was super popular, with 13 submissions. "Starting small" is really compelling from a developmental standpoint, but it almost never helped. One of our "Best Papers" shows this convincingly:

4
11
92
It's official: BLiMP is now out in TACL! The Benchmark of Linguistic Minimal Pairs contains 67 sets of 1000 minimal pairs targeting syntactic phenomena in English meant for unsupervised evaluation of language models. Results for GPT-2, TXL, LSTM, n-gram

4
11
93
Transformer LMs get more pretraining data every week; what can they do with less? We're releasing the MiniBERTas on @huggingface: RoBERTas pretrained on 1M, 10M, 100M, and 1B words See our blog post for probing task learning curves

CILVR Blog as an inaugural post on the MiniBERTas by Yian Zhang, @liu_haokun, Haau-Sing Li, .Alex Warstadt and @sleepinyourhat: ever wondered what would happen if you pretrained BERT with a smaller dataset? find your answer here!.
2
15
86
I passed!.

2
0
70
This is a HUGE (and 👶) opportunity to advance pretraining, cognitive modeling, and language acquisition. Your participation is 🔑. Also, HUGE shout out to my fellow organizers @LChoshen @ryandcotterell @tallinzen @liu_haokun @amuuueller @adinamwilliams @weGotlieb @ChengxuZhuang


Announcing the BabyLM 👶 Challenge,.the shared task at @conll_conf and CMCL'23!. We’re calling on researchers to pre-train language models on (relatively) small datasets inspired by the input given to children learning language.

0
8
60
Hi babies 👶 New announcement about the BabyLM ( loose track: We are explicitly permitting the use of human-annotated data, such as Penn Treebank, WordNet, Wordbank age of acquisition data, etc. READ ON FOR IMPORTANT CAVEATS!.
4
13
55
Here's a list of words to use instead of "leverage" and "utilize": . 1. use.
5
2
53
A very rewarding watch! Discusses a bunch of naive strategies to a simple game before giving a more psychologically intuitive solution with some reinforcement learning. Accessible & engaging computational cognitive modeling on youtube! @LakeBrenden @todd_gureckis.


1
7
45
Thanks to everyone who made BabyLM a success!. ❤️ The organizers @amuuueller @LChoshen @weGotlieb @ChengxuZhuang.❤️ +Authors @tallinzen @adinamwilliams @ryandcotterell Juan Ciro, Rafa Mosquera, Bhargavi Paranjape.❤️ @conll_conf organizers @davidswelt Jing Jiang, Julia Hockenmaier

1
2
46
I'm at #CogSci2024 giving a poster TODAY from 13-14:15 about the past and future of BabyLM! Come chat about computational models of language acquisition and data-efficient pretraining!.
LLMs are now trained >1000x as much language data as a child, so what happens when you train a "BabyLM" on just 100M words?. The proceedings of the BabyLM Challenge are now out along with our summary of key findings from 31 submissions: Some highlights 🧵
0
5
45
What else worked? A lot of submissions got good results from data preprocessing, or from training on shorter contexts. The winner of the loose track, Contextualizer, used a cognitively-motivated approach to sequence packing and data augmentation:
1
2
38
Another "Best Paper" showed that models that do better on our shared evaluations are worse cognitive models, at least when it comes to predicting reading times:

1
6
39
And most of all thanks to all the awesome Babies who took the time to train BabyLMs, write papers, come to Singapore, etc. ❤️👶. Website: Summary paper: Proceedings: Github:
0
2
34
I'm in need of NINE emergency reviews for ACL ARR. Over 1/3 of my reviewers are nonresponsive, I think that's a personal record 🙃 Please let me know if you can take on some of these!!.
7
4
35
📢New paper alert📢 Sometimes prosody is predictable from text, and sometimes it conveys its own information. We develop an NLP pipeline for extracting prosodic features from audio and using LMs to try to predict them from text. Read to find out just how redundant prosody is 🤔


Ever wondered whether prosody - the melody of speech 🎶 - conveys information beyond the text or whether it's just vocal gymnastics? 🏋️♂️ Great work by @MIT and @ETH_en soon to be seen at @emnlpmeeting .
1
3
34
Him: Can you pass me the short glass?. Me: WHAT KIND OF SICK REFERENCE GAME IS THIS???

0
1
32
The BabyLM training set draws on diverse and (as much as possible) developmentally plausible data sources, and is publicly available on our website:

1
1
30
First, the rules of the challenge. Participants could submit to up to 3 tracks:

1
1
30
Has anyone tried training a massive LSTM LM? . Why did we collectively decide that only Transformers were worth scaling? I know Trsfmrs scale better, but we can surely train LSTMs bigger than ELMo. With all the talk of "emergent abilities at scale", seems foolish not to check.
9
3
30
What's the best way to ask humans for judgments of probabilities? I want a sliding scale from 0% to 100%, but I'm concerned that our perception of probability isn't linear. Like, shouldn't the range [99%, 100%] be larger than [50%, 51%]? Is there any literature on this?.
16
1
27
This paper makes such an important point about children's learning signal for language acquisition (which is missing from LMs, btw):. Learners infer grammar rules from which utterances lead to communicative success. And comm. success is essential for achieving nonlinguistic goals.

Our latest paper is out in New Ideas in Psych journal! @mitjanikolaus and I propose a framework linking theories of conversational coordination to several aspects of children's early language acquisition.
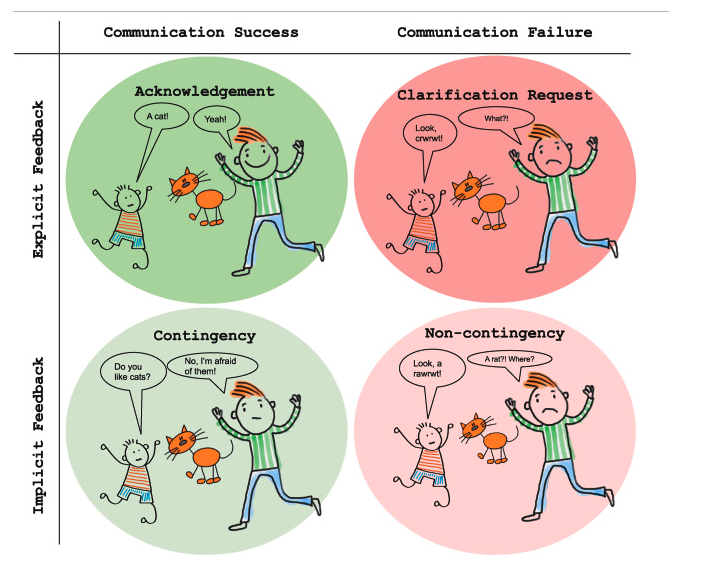
1
1
29
Congrats to the competition winners and best paper awards: @davidsamuelcz Lucas Georges Gabriel Charpentier, Chenghao Xiao, G Thomas Hudson @NouraAlMoubayed @Julius_Steuer @mariusmosbach @dklakow @richarddm1 Zebulon Goriely @hope_mcgovern @c_davis90 Paula Buttery @lisabeinborn.
1
2
25
We got 31 submissions, and we tagged submissions by which approaches they used. Some tried cognitively plausible approaches, like curricula and teacher models. Others used more classic ML techniques, like data preprocessing, architectural mods, and HP tuning.

1
1
27
Check out our new paper, harnessing the power of LLMs 💪 to scale up high quality manual annotations of CHILDES 👶.
🆕A new resource for automatic annotation of young children's grammatical vs. ungrammatical language in early child-caregiver interactions — a project spearheaded by Mitja Nikolaus and in collaboration with @a_stadt, to appear in @LrecColing.Thread🧵.
1
1
26
@UCSanDiego @HDSIUCSD Anyone looking for a PhD in computational linguistics, acquisition, or pragmatics, I'd encourage you to apply to UCSD by Dec 15! I'm not formally recruiting now, but there are many great ppl there already in the area, and I will start advising in ling and data science in 2025🧑🎓.
0
8
25
Even though there’s tons of work *scaling up* LMs and multimodal models, almost nobody tries to optimize approaches for *scaling down* to human-like data volumes. If we make progress here, there could be payoffs for acquisition, cognitive modeling, AND applied NLP.
2
1
26
This year's shared task is over, but the science is not finished! There is more work to be done making LM training more cognitively plausible, data efficient, compute efficient, and accessible to small research groups. Look out for details about the **Second BabyLM Challenge**!.
1
1
24
How would you test your BabyLM?. We have a new and improved eval pipeline for round 2 of the BabyLM competition, but we're NOT done adding to it. If you have an idea for a new eval, reach out, open a pull request, or even submit a writeup to our new "paper track"!.

The evaluation pipeline is out!. New:.Vision tasks added.Easy support to models (even out of HF) like mamba and vision ones (DM if your innovativeness make eval hard!). Hidden:.More is hidden now.(cool, new and babyLM spirited). Evaluation a challenge's❤️🔥.
1
3
25
Am I the only one who can't stand "Modern American" restaurants?. It's like, no, I don't want to pay $38 for you to make me grilled salmon with mashed potatoes and green beans!.
3
0
22
📣 Calling all Edinburgh linguists/NLPers 🏰 . I'll be visiting your lovely city this week Thurs-Sat and am very down to meet and talk shop, grab a pint, etc! Even/especially if we haven't met yet! Dm me and let's try to find a time!.
1
0
24
We wanted the Loose track to uncover multimodal and interactive learning signals that help with language learning. Sadly, it didn't get many submissions, and the few we got had negative results. So bootstrapping language learning with other modalities is a big open problem!!.
1
2
22
Excited to see this! This is EXACTLY the kind of controlled experiment @sleepinyourhat and I envisioned in our 2022 position paper (.

New preprint!.How can we test hypotheses about learning that rely on exposure to large amounts of data?. No babies no problem: Use language models as models of learning + 🎯targeted modifications 🎯 of language models’ training corpora!

1
1
22
I could not agree more. These are 2 complementary approaches to cognitive modeling:.1. Build it from the bottom up from plausible parts and find what works.2. Start with something that works and make it incrementally more plausible. Ideally, they meet in the middle somewhere.

I love the babyLM challenge, but things to keep in mind:. -No baby learns from text.-No baby learns without the production perception loop.-Babies have communicative intent. The reasons why I’ve been modeling language acquisition with GANs and CNNs from raw speech. Some

1
1
22
Oh, and check out our paper:.on arXiv: and.on lingbuzz: (same paper, choose whichever "feels right"!).
1
2
20
📢 BabyLM 👶 evaluation update 📢. The eval pipeline is now public! It's open source, so you can make improvements, open a pull request, etc. We're taking suggestions for more eval tasks. If you want to propose tasks using zero-shot LM scoring or fine-tuning, drop us a line!!.
The evaluation pipeline for the BabyLM 👶 Challenge is out! We’re evaluating on BLiMP and a selection of (Super)GLUE tasks. Code 💻:
1
6
19
Conclusion: Raw data probably *does* have evidence for the structural nature of language, and BERT seems to find it. As humans, maybe we too can learn this general pattern, and use it to acquire structural rules even in the absence of key examples. 12/12.
0
2
17
This is one of the main differences between human language acquisition and LM language acquisition: Articulatory learning is a huge hurdle for infants, disproportionately affecting language production. Even without having to learn this task, LMs are less data efficient. .

Articulation GAN: Unsupervised modeling of articulatory learning
0
1
15
Exciting new work with (surprisingly!) positive results that LMs can predict human neural activation for language inputs **even when restricted to the same amount of input as a human**.

Excited to share our new work with @martin_schrimpf, @zhang_yian, @sleepinyourhat, @NogaZaslavsky and @ev_fedorenko: "ANN language models align neurally and behaviorally with humans even after a developmentally realistic amount of training" 1/n.
1
2
16
An additional (more mundane) factor: vision+language models are usually fine-tuned on aligned data from not-so-rich domains like captions 😴, but text benchmarks really benefit from adaptation to long abstract texts.

In 2021, we've seen an explosion of grounded Langage Models: from "image/video+text" to more embodied models in "simulation+text". But, when tested on text benchmarks, these grounded models really struggle to improve over pure text-LM e.g T5/GPT3. Why?. >>.
1
2
16
So. do current models have any advantages over humans that limit what we can learn from them? . HOLY CRAP YES when it comes to data quantity. Turns out GPT-3 has ~1000x the input of a 10-y.o.

1
1
16
Check out the corpus of Chinese Linguistic Minimal Pairs, or CLiMP at EACL and SCiL, and on arXiv! Mandarin is hardly an understudied language, but our new paper is the first targeted syntactic evaluation of Chinese LMs.

2
2
14
This morning in dissertation land. What will be finished first: Mahler 4 or my data validation section? .
1
0
14
LeM🍋N Lab is an essentially **interdisciplinary** group. We use advances in NLP to investigate how humans learn language and why language is the way it is. And we use insights from Linguistics and CogSci to evaluate and interpret LMs and advance data-efficient pretraining.
1
0
12
Huge thanks to my dissertation committee @sleepinyourhat, @tallinzen, @LakeBrenden, @mcxfrank, Ellie Pavlick (@Brown_NLP). And other folks who gave great feedback: @grushaprasad, @najoungkim, @lambdaviking, @ACournane, @EvaPortelance . /fin.
1
0
12
Specific topics include:.-LMs as models of human learners.-Efficient LM pretraining.-Bayesian & experimental pragmatics.-Information-theoretic linguistics.-Prosody and speech processing.-Multimodal pretraining.-Grammatical evaluation. For prospective PhDs:
0
0
12
Happy equinox y'all. Wishing you moderation, peace, and balance this season 🍎🍏

2
0
12
Lots of useful tips here (e.g. use simple language, define jargon), but as a linguist, I'm tired of advice like #19: "Never use passive tense [sic]; always specify the actor". Passives exist for a reason (actually two reasons, at least)👇.

I wrote up a few paper writing tips that improve the clarity of research papers, while also being easy to implement: I collected these during my PhD from various supervisors (mostly @douwekiela @kchonyc, bad tips my own), thought I would share publicly!.
1
1
12
Paper to appear in TACL, poster @ EMNLP (arXiv link here: . And HUGE shoutout to my awesome co-authors at ETH Zürich:.Ionut Constantinescu Tiago Pimentel @tpimentelms Ryan Cotterell

1
0
11
10 days til dissertation deadline. I've decided to live-tweet my writing soundtrack. This morning, it's Bach's "Jesu Meine Freude"
0
0
10
But it’s not all bad news. Children have lots of environmental advantages that LMs lack. Like. - prosody.- multimodal input.- grounding .- interaction with other agents. Adding these non-textual inputs to our LMs will help us close the data efficiency gap.
2
0
11
And if we train models with less data, they don’t do so good. So there’s a huge DATA EFFICIENCY GAP between LMs and humans. And remember, negative results aren’t so useful😢

1
0
11
I'm trying to do a head-to-head of text generation circa 5 years ago vs. today. Anyone know where can I find examples of what was considered high quality neural text generation back then (presumably using LSTM)? . @clara__meister @ryandcotterell @tpimentelms.
6
0
10
What do we find?. LMs DO NOT have a human-like CP for L2 learning! 😱. Learning trajectories for perplexity and BLiMP show that simultaneous bilingual LMs ("interleaved") are WORSE at L2 than late learners ("sequential"). Another viewpoint: pretrain+finetune > multitask pretrain

1
1
10
I've generated a lot of minimal pairs in grad school, but this is one of my favorites:. Danielle Steel wrote that the farm boy the owner's daughter had an affair with flung himself/*herself into the sea.
1
0
9
Humans and LMs are 2 samples from a larger conceptual space of language learners. Our findings inform us about that space, and give evidence AGAINST the Connectionist claim. Nativists might not be surprised, but Connectionists should update priors about humans accordingly!

2
0
10
The Question Under Discussion❓is to discourse what the CFG is to syntax, but how speakers choose which❓to address next is VASTLY understudied. Excited for another big advance from this group: human jgmts on salience of a potential future❓AND models that can predict salience‼️.

Super excited about this new work!. Empirical: although LLMs have good abilities to generate questions, they don’t inherently know what’s important. We try to solve this!. Linguistic: is reader expectation predictable and if so, how well does that align with what’s in the text?.
1
0
10

boyfriend: It's too warm for snow---only 38 degrees. me: Are you suggesting that orderings over scalar alternatives are reversible?.
0
0
10
"Oh but it's so well executed" people say. "I can't make salmon that juicy and flavorful.". Bro, the secret is just more butter and salt.
0
1
8
tl;dr: RoBERTa does acquire a preference for linguistic generalizations over surface ones from pretraining. But it takes waaay more pretraining data than simply learning to represent linguistic features. [2/11].
1
1
9
New paper announcement #acl2020nlp! Are neural networks trained on natural language inference (NLI) IMPRESsive? I.e. do they view IMPlicatures and PRESuppositions as valid inferences? Coming to a zoom meeting near you!.

NLI is one of our go-to commonsense reasoning tasks in #NLProc, but can NLI models generalize to pragmatic inferences of the type studied by linguists? Our accepted #acl2020nlp paper asks this question (!.The team: Paloma Jeretič @a_stadt Suvrat Bhooshan

0
2
9
Very excited to be talking at Indiana University Bloomington next week about CoLA, BLiMP, and language models learning grammar from raw data!.

Next week Alex Warstadt @a_stadt from NYU will give a talk about acceptability judgments and neural networks at #Clingding ! Check it out at DM me if you are not from IU but want to participate. :) #NLProc.
0
0
9

Excited to announce a new paper/dataset with a bunch of collaborators at NYU. If you're interested in linguistic evaluation of NN models, check it out!.
0
0
8
All winter, all I cook is Chinese and Korean. Then the second it gets hot I'm just full on Mediterranean food. Does anyone else cycle through different food cultures annually?.
0
0
8
Love this! . Training speech LMs is crucial for modeling language acquisition. @LavechinMarvin et al. show there are still some BIG hurdles ahead: SLMs have to solve the segmentation problem to get on par with text-based models. But a good benchmark is one hurdle cleared!.

Want to study infant language acquisition using language models? We've got you covered with BabySLM👶🤖. ✅ Realistic training sets.✅ Adapted benchmarks. To be presented at @ISCAInterspeech.📰Paper: 💻Code: More info below 🧵⬇️

1
0
7
We have a survey!
LLMs are now trained >1000x as much language data as a child, so what happens when you train a "BabyLM" on just 100M words?. The proceedings of the BabyLM Challenge are now out along with our summary of key findings from 31 submissions: Some highlights 🧵
0
0
7
Big fan of this paper by Lovering &al! Neural networks sometimes generalize in weird and unintended ways, but they show that there is a clear information-theoretic principle that predicts their behavior (at least in some very simple settings). [1/4].

For those (like me) who weren't really following ICLR last week, some more context on this cool work led by Charles Lovering:.
1
1
6
EXPERIMENTATION: We have 100% access to all the linguistic input to NNs AND all their parameters. The possibilities for controlled manipulations and causal inferences are immense!
1
1
7
@najoungkim @eaclmeeting @ryandcotterell @butoialexandra @najoungkim you and Kevin Du should be friends. He is also a FoB (friend of Buddy)!!.
1
0
6
Of course, these models definitely do NOT have human-like language performance at these smaller scales, so there's got to be something that the evaluation is leaving out. Or is the problem that the models' performance is hitting a ceiling below human performance?.
1
0
7
The paper is on arXiv: Our dataset is called MSGS (Mixed Signals Generalization Set) and it’s online, along with all our pretraining/fine-tuning code: And a writeup on miniBERTas too: [10/11].
1
1
7
Congrats to my cohortmate @AliciaVParrish on her defense. She's an awesome scientist!.

Proudly presenting Dr. @AliciaVParrish who just successfully defended her supercool @nyuling dissertation “The interaction between conceptual combination and linguistic structure”!.Dr. Parrish will soon be starting a Research Scientist position at @Google, lucky them!!


2
0
7
ETHICS: Children raised in atypical environments are incredibly valuable to science, but at great cost to basic human rights. Think of cases like Genie or ancient language deprivation “experiments” NNs already learn in atypical environments—it’s nbd!
1
0
7
How about L1 attrition?. Unlike humans, LMs forget L1 if exposure ends, even after LOTS of training on L1. BUT we can prevent attrition using EWC, a regularizer that mitigates catastrophic forgetting. This may be a way to **reverse-engineer** more plausible cognitive models.

1
0
6
How did I end up on my back on the floor next to my desk, with my laptop on my belly and my feet up on my chair? Does anyone else squirm around involuntarily while concentrating (coding, paper writing, etc.)?.
0
0
5
Big congrats to my very deserving advisor!.

Happy to report that my NSF CAREER application on crowdsourcing and data quality in NLU was approved!.
0
0
6
From positive results we can learn about *sufficient conditions* for human-learnability 👍. but only if our models have NO ADVANTAGES---innate or environmental---over humans. Negative results give *much weaker* evidence 👎.
1
0
6
But first, why should language acquisition folks be interested in artificial learners at all? . 3 words: expense, ethics, and experimentation. EXPENSE: Want longitudinal data from a big sample of learners? NNs are much cheaper and easier to study than children.
1
0
6
Today's the day I finish my dissertation!. This one's for Amy <3.
0
0
5
So you can get better generalization by increasing pretraining data. But that’s probably not the best way. Models learn to represent these features pretty quickly, so maybe we can speed up linguistic bias learning with better architectures or pretraining regimes. [9/11].
1
0
6
@srush_nlp Goooood question. It's not well advertised in the paper unfortunately. We asked authors to self-report HPs and training info, the data is here: 1/2👇.
1
1
6
Our experiments test RoBERTa’s feature preferences by fine-tuning on ambiguous classification tasks. Training data is consistent with a simple linguistic generalization and a simple surface one. Disambiguating test data tells us which generalization the model “chose”. [3/11]

1
1
6
Check out our arXiv paper ( for a bunch more results and discussion (including results with 12 different language pairs!), and if you're at EMNLP keep an eye out for Ionut's poster 🧑🔬

1
0
6
@srush_nlp LTG-BERT trains on the same # of tokens (recounting tokens for multiple epochs) as BERT (. Their BabyLM paper did the same. ~10^11 training tokens / 10^8 dataset tokens ~= 500 epochs with padding. So it's flop comparable to BERT (modulo # of params). /2

1
1
6
Neat solution to an annoying problem (involving subword tokens, as always)!.

💡 New short paper with @neuranna titled "A Better Way to Do Masked Language Model Scoring" accepted at #ACL2023. 🎉🇨🇦. Preprint: 📑 Tweeprint: 🧵👇. #ACL2023NLP #NLProc.
1
0
6
What are some good corpora of spoken English with ~1B words? I'm interested in both written/edited dialog (e.g. OpenSubtitles) and transcribed naturally occurring dialog (Switchboard-style).
4
1
6
@liu_haokun It's unfair and wrong how you and other international students have been treated by the US. Not to mention stupid: there's nothing to gain from alienating and excluding talented scholars from China.
0
0
6