

William Merrill
@lambdaviking
Followers
2K
Following
5K
Media
688
Statuses
1K
Will irl - Ph.D. student @NYUDataScience on the academic job market! https://t.co/Tzmx5uMXEv
New York, NY
Joined October 2011
Today in Quanta Magazine, @benbenbrubaker gives a new overview of our work (w/ @Ashish_S_AI) on the expressive power of transformers with/without CoT.
1
11
54
✨Excited to finally drop our new paper: SSMs “look like” RNNs, but we show their statefulness is an illusion🪄🐇. Current SSMs cannot express basic state tracking, but a minimal change fixes this! 👀. w/ @jowenpetty, @Ashish_S_AI.

24
202
1K
📣 @Ashish_S_AI and I prove that transformers can be translated to sentences in first-order logic with majority-vote quantifiers (FOM). FOM is a symbolic language that can capture computation inside transformers!.

12
97
491
I wrote an introduction to formal languages and automata as they relate to modern NLP (RNNs, transformers, etc.). Check it out on arXiv!.
4
70
324
[1/6] Excited to share a year-long project re: theory of language understanding in LMs w/ .@a_stadt, @tallinzen. TLDR:.Judging entailments (NLI) can be reduced to LMing over "Gricean data"*.∴ Learning distribution (perfectly) => learning semantics .
2
36
258
A Formal Hierarchy of RNN Architectures -- in which we address questions like "what can an LSTM do that a QRNN can't?". Joint work with @gail_w, @yoavgo, @royschwartz02, @nlpnoah, and @yahave #acl2020nlp . Blog: Paper:
2
60
235
Is it possible for GPT-n to "understand" the semantics of English? What about Python?. I'm excited to finally share work formalizing this question! We give formal languages that are *provably* un-understandable by LMs (within our setup, at least).
8
51
230
How do we understand logical reasoning in non-symbolic models like transformers?. 📣New preprint w/ Ashish Sabharwal shows any transformer can be translated to a fixed-size first-order-logic formulae (with majority quantifiers).
2
34
186
📢 Preprint: We can predict entailment relations from LM sentence co-occurrence prob. scores. These results suggest predicting sentence co-occurrence may be one way that next-word prediction leads to (partial) semantic representations in LMs🧵

5
26
163
What inductive biases does training impose on transformers?. We find that T5, RoBERTa, etc. are well-approximated by saturated transformers (simplified attention patterns), and explain how this arises during training. w/ @RamanujanVivek @yoavgo @royschwartzNLP @nlpnoah

1
32
163
🐊📣Still @ NeurIPS?. Come by our poster to hear about how chain of thought/scratchpad steps increase the computational power of transformers. Room 242, 4pm (M3L workshop)

1
27
151
[1/n]📢 More work on the *computational model of transformers* w/ Ashish Sabharwal in TACL. Takeaway: transformers are limited to expressing highly parallelizable functions. (formally, they are in the complexity class uniform TC0).
5
34
150
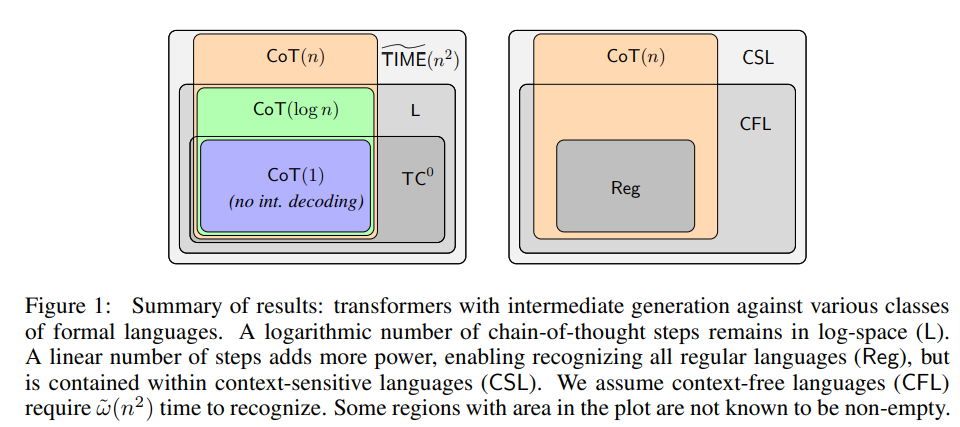
[1/n] How does a chain of thought change the expressive power of transformers?. New work w/ @Ashish_S_AI studies how adding CoT/decoding steps extends the problems solvable by transformers as a fn of the # of steps.

2
27
130
oh btw, I'm excited to be joining @NYUDataScience as a PhD student this fall!.

if u go to grad school that’s weird like most ppl don’t do that.
12
2
121
Curious about the circuits inside transformers? 🧐. 📢 Our new work shows how (saturated) transformers can be simulated by *threshold circuits*. Equivalently, this bounds the problems saturated transformers can solve in the class TC0. w/ Ashish Sabharwal, @nlpnoah

1
19
120
❗Just updated for ICML:.- General theorem statements (beyond S4 / Mamba).- Experiments showing SSM extensions *can* solve state tracking.- ♟️♟️Fun analysis of chess state tracking complexity (@ chess heads). Paper: w/ @jowenpetty @Ashish_S_AI.
✨Excited to finally drop our new paper: SSMs “look like” RNNs, but we show their statefulness is an illusion🪄🐇. Current SSMs cannot express basic state tracking, but a minimal change fixes this! 👀. w/ @jowenpetty, @Ashish_S_AI.
3
14
115
Getting excited for the Simons Institute workshop on Transformers as a Computational Model (Sept 23-27)!. I'm thinking of sticking around in the Bay for a couple days afterwards. down to chat/visit groups/etc (lmk if interested!).
0
8
109
Pretraining can be unstable - I did a bit of digging with OLMo checkpoints to try to understand why. Check out my blog post, or, better yet, play around with the fully open OLMo checkpoints yourself!.
5
14
105
“The Expressive Power of Transformers with Chain of Thought” w/ @Ashish_S_AI will appear at ICLR 🇦🇹.

Props to Will Merill @lambdaviking for having already fully formalized my nonsense thoughts. (also for generally writing extremely interesting papers)

6
14
97
If you teach NLP, please keep teaching automata 👇.

⚡️ Speed up LLM inference by 5x. ⚡️. We introduce a new framework, coalescence, that makes structured generation several times faster than standard generation. Coalescence is very flexible, and raises unexpected questions 🧐.

3
7
90
I wrote a blog post summarizing Sequential Neural Networks as Automata.
1
16
80
Stop by "The Expressive Power of Chain of Thought" poster tomorrow!. Wednesday 10:45am #294.
1
15
76
Our NeurIPS paper shows transformers can be expressed in first-order logic with majority quantifiers.=> Extends the theory of the expressiveness and limitations of transformers.=> Provides a "programming language" capturing transformers' computation.
📣 @Ashish_S_AI and I prove that transformers can be translated to sentences in first-order logic with majority-vote quantifiers (FOM). FOM is a symbolic language that can capture computation inside transformers!.
0
16
65
🐊📣 Stop by tomorrow to hear from @Ashish_S_AI and me about:.1) how transformers can be expressed in logic.2) what this means about what transformers *can't* do. Thursday @ 5pm, #1008.

0
10
64
Eagerly anticipating Humanity’s Last Last Exam, Humanity’s Last Last Exam_FINAL, Humanity’s Last Last Exam_FINAL_FINAL, ….

Have a question that is challenging for humans and AI?. We (@ai_risks + @scale_AI) are launching Humanity's Last Exam, a massive collaboration to create the world's toughest AI benchmark. Submit a hard question and become a co-author. Best questions get part of $500,000 in



2
1
67
At ICML? Come check out the Illusion of State poster🪄♟️. Wednesday 11:30 Hall C 4-9 #1013.
✨Excited to finally drop our new paper: SSMs “look like” RNNs, but we show their statefulness is an illusion🪄🐇. Current SSMs cannot express basic state tracking, but a minimal change fixes this! 👀. w/ @jowenpetty, @Ashish_S_AI.
6
9
62
This result acts as an upper bound: transformers can't solve problems that can't be defined in FOM. This reveals some new problems transformers can't solve and provides a handy intuitive test for seeing whether a transformer can do something: try to define the problem in FOM.
1
3
60
I'll be back in Vienna for ICML next week 🇦🇹. Email or DM to chat about theory on transformers/SSMs, pretraining data and methods, anything else. ✨Also I'll likely be on the academic job market this fall!. 🧵of papers ⬇️.
2
5
61
Finally, we were excited to find a minimal change to SSMs that improves their expressive power for state tracking: make the A matrix input-dependent. Empirically, this allows them to learn hard-state tracking just as well as RNNs!

9
6
60
Love to see more theoretical work comparing the formal capabilities of SSMs and transformers (within TC0)!.

We are excited to share our work on characterizing the expressivity of State Space Models (SSMs) with a theoretical lens, using a formal language.framework, backed up by empirical findings. w/ Yana Veitsman, Dr. Michael Hahn.Paper link :

3
7
52
We draw on theory to formalize hard state tracking problems and formally prove that SSMs, like transformers, cannot solve them. Empirically, SSMs and transformers struggle to learn hard state tracking, but RNNs learn it easily. We also propose a minimal fix.
1
0
46
Thanks to the FLaNN Discord for recently inviting us to talk about this work. Recording: Also, stop by my poster at New England NLP next week!.
1
3
47
This is a good intuition to impart! There is no true “state” in a transformer (unlike DFA/RNN) and the # of state updates is bounded by the depth. We discuss this more formally here (+implications for what sequential stuff transformers can’t do):

One intuition for why Transformers have difficulty learning sequential tasks (eg parity), w/o scratchpad, is that they can only update their “internal state” in very restricted ways (as defined by Attention). In contrast to e.g RNNs, which can do essentially arbitrary updates.
0
7
43
Inspired by formal language theory, we view state tracking as iterated multiplication in a monoid (whose elements represent state updates). The algebraic structure of the monoid determines the complexity of tracking state in a parallel computational model like a transformer.

1
2
39
Our main theoretical result✨ is that linear state-space models (e.g., S4) and Mamba can only express computation in TC0. This means they cannot (exactly) solve hard state tracking problems like permutation composition, code eval, or chess!.
1
4
43
But in practice can SSMs and transformers approximate state tracking in practice despite our worst-case result? We show🧪 this isn’t the case on permutation composition: both transformers and SSMs require depth growing with sequence length, whereas RNNs need just 1 layer.

1
3
42
Was fun working on this!. The cool takeaway imo is that we can characterize the type of reasoning that blank tokens can help with… it’s reduced compared to CoT but experiments show it’s likely more than with no extra tokens.

Do models need to reason in words to benefit from chain-of-thought tokens?. In our experiments, the answer is no! Models can perform on par with CoT using repeated '. ' filler tokens. This raises alignment concerns: Using filler, LMs can do hidden reasoning not visible in CoT🧵

2
4
39
About to fly to Bangkok for ACL!🇹🇭. let's chat about transformer/SSM expressivity, distributional semantics, anything else (email/DM). ⬇️presentations.
2
3
38
In summary, we used theory to pin down “hard state tracking” and showed it poses a problem for current SSMs and transformers. Thus, the state in SSMs is an illusion! We proposed an SSM extension to overcome this and are eager to evaluate its practical viability.

1
0
38
A canonical example of hard state tracking is *permutation composition*, or S5 (cf. Galois). We show “real” state tracking problems (code eval, chess with <source,target> notation) can be reduced to permutation composition. We thus use it to benchmark hard state tracking.

1
3
38
Another contribution: we prove transformers need >loglogn precision to have full expressive power over contexts of length n. With less precision, they cannot implement uniform attention!.We hope this result can guide the development of long-context, low-precision LMs.
1
1
32
Some state tracking problems are known to be fully parallelizable (TC0) while others are inherently sequential (NC1-complete), requiring computation graphs of growing depth. The latter are easy for RNNs but can’t be represented by fixed-depth transformers.
3
1
33
We also see natural implications of this work for understanding algorithms inside transformers ("mechanistic interpretability"). RASP/TRACR are languages for *compiling into* transformers. In contrast, any transformer can be *translated* to an FOM sentence.
1
0
30
🏛️I'll be at COLM Mon, Tues, and maybe Wed. Down to chat about any of my research topics or learn what you're working on! DM/email/etc.
1
1
30
New preprint analyzing the power of uniform attention patterns in transformers in terms of circuit complexity classes. w/ @yoavgo @royschwartzNLP @nlpnoah . Very curious for feedback/suggestions!.
2
10
29
I'll be arriving in Abu Dhabi for EMNLP tomorrow!. Would love to chat about formal semantics and LMs, expressive capacity/inductive biases of NNs/transformers, compositionality, or anything in between!. Will respond to emails, Twitter DMs, carrier pigeons, etc.
4
0
28
Bibliographic notes:.This paper is a substantially revised version of an earlier preprint. The revisions were inspired by @davidweichiang et al.'s related paper:.
1
1
27
You should give this paper a read 👀. They had me at transformers x Myhill-Nerode thm x pretty maps of NYC🗽.

New paper: How can you tell if a transformer has the right world model?. We trained a transformer to predict directions for NYC taxi rides. The model was good. It could find shortest paths between new points. But had it built a map of NYC? We reconstructed its map and found this:

0
0
24
I’ll be at ICLR next week! 🇦🇹. Reach out if you’d to talk about transformers and state-space models, training dynamics, etc.
2
0
25
In Zürich Airport, ears perked for something cross-serial👂.
2
0
23
Our paper on the form/meaning debate has been updated thanks to discussions & outside input!.v2 better reflects how understanding can be hard for an *LM*, but easy for a human. Thanks to Mark-Jan Nederhof and many others who shared their thoughts.
1
2
24
RIP Drago. In the classes I took and TA'ed with him, Drago was a passionate, kind, and funny teacher and mentor. Gone too soon indeed.

The #AI community, the #computerscience community, the @YaleSEAS community, and humanity have suddenly lost a remarkable person, @dragomir_radev - kind and brilliant, devoted to his family and friends. gone too soon. A sad day @Yale @YINSedge @YaleCompsci #NLP2023


0
3
23
@_jasonwei @OpenAI I'm not sure what you mean by compositionality, but this example is a clear failure on the level of basic Shakespearean grammar. The subject/verb agreement is realllllly off (Should be: thou seekest, I know, shall guide).
0
0
23
And, copying link again for our paper since the arXiv preview didn't render above:.
0
0
21
Today I learned: the context-sensitive languages are closed under complement. Via a fun, indirect argument that takes us away from the Chomsky hierarchy and into computational complexity (1/n).
1
2
22
#nlphighlights Podcast Ep. 129:. @nlpmattg and I talk with guest @ShunyuYao12 about transformers' ability to process hierarchical structure in language. Thanks to Shunyu for joining us for this fun and informative discussion!.
2
8
22
@_jasonwei So emergent phenomena are an empirical fact (and an interesting one, I agree). But it's a big jump to assume arbitrarily complex (~human-level) reasoning can emerge in transformers. Provably, transformers can only implement express shallow reasoning:
2
0
20
Also see here for more details on the algebra behind the paper:
1
0
22

Aug 14 poster: We show sentence co-occurrence prob's from LMs encode information about entailment, illustrating a connection between pragmatics and distributional learning of semantics .w/ @zhaofeng_wu Norihito Naka, Yoon Kim, and @tallinzen .
📢 Preprint: We can predict entailment relations from LM sentence co-occurrence prob. scores. These results suggest predicting sentence co-occurrence may be one way that next-word prediction leads to (partial) semantic representations in LMs🧵
0
4
19
+1, the limitations of LMs workshop was fun and timely. thanks to the organizers and other speakers!. I spoke about complexity-theoretic limitations of transformers (vid will appear eventually). no photo of me in Bielefeld, but did get a pic of another William


I had a great time yesterday speaking about testing the limits of LLMs with Construction Grammar at a workshop on LLM limitations organised by @SAIL_network! .Thanks again to Özge Alacam, @bpaassen1, and @MichielStraat for inviting me, and @lambdaviking for the fun company!

1
0
19
The @SimonsInstitute workshop has been fun so far! Excited for one last day tomorrow.

Will Merrill sharing some updates on his research characterizing the expressivity of transformers at @SimonsInstitute




0
0
18
[2/n] This implies a list of problems transformers cannot solve (under assumptions in footnotes):

4
1
18
Next week, I'll be giving a lightning talk at the NYC @GenAICollective about my work using complexity theory to analyze the limitations of transformers!. Tuesday, September 10, 6:30 PM.
0
3
19
Check out this poster if you’re interested in theoretical insights on the reasoning power and limitations of transformers! 👀.

Our poster on "Tighter Bounds on the Expressivity of Transformer Encoders" has been rescheduled to Wednesday at 11am! Exhibit Hall 1 number 228 #ICML2023

0
4
17
Forget GPT-4o, I'm just waiting for Chicha San Chen NYC to open😔.
1
0
17
Thanks to Meryl for covering our recent work on semantics and language models on the CDS blog!. The paper proves entailment prediction can be reduced to language modeling, and shows how to extract entailment from an “ideal” LM. Check out the blog to learn more!.

Can language models learn meaning just by observing text? CDS PhD student William Merrill (@lambdaviking) and CDS Assistant Professor of Linguistics and Data Science Tal Linzen (@tallinzen) explore the question in a recent study. Read about it on our blog!.
0
2
15
Tomorrow at 12:15!.
Aug 14 poster: We show sentence co-occurrence prob's from LMs encode information about entailment, illustrating a connection between pragmatics and distributional learning of semantics .w/ @zhaofeng_wu Norihito Naka, Yoon Kim, and @tallinzen .
0
0
15
Historical context is hard to get without a lot of experience or clear exposition (this), but it can provide a broader perspective beyond the daily arXiv buzz. glad to see mention of the Stupid Backoff paper about "large language models" c. 2007:

It's not the first time! A dream team of @enfleisig (human eval expert), Adam Lopez (remembers the Stat MT era), @kchonyc (helped end it), and me (pun in title) are here to teach you the history of scale crises and what lessons we can take from them. 🧵

0
2
16
Interested in foundational questions about the computational/linguistic abilities of neural nets?. Check out our website/join our weekly remote talk series 🍮.
1
1
14
The coolest thing about GPT4 is I now have something to practice my broken Icelandic with.
1
0
14
I'll be at NeurIPS next week! Looking forward to chatting about the computational power + limitations of transformers, as well as other fundamental questions about LMs. Reach out if you'd like to chat! DMs open.
1
0
14
Thanks to Stephen for a great overview of our recent work on the reasoning limitations of transformers!.
In a recent #NeurIPS-accepted paper, CDS PhD student William Merrill (@lambdaviking), with @Ashish_S_AI at AI2, reveal the hidden limitations of transformer LLMs like #ChatGPT and how to detect their "hallucinations.". . #datascience #hallucinations.
0
1
14
Took a look today and this is very interesting stuff! The lower-bound direction is particularly cool: showing how LTL and counter-free automata can be simulated in a transformer through B-RASP.
New preprint! Dana Angluin, I, and Andy Yang @pentagonalize show that masked hard-attention transformers are exactly equivalent to the star-free regular languages.
1
2
13
The whole "SAT solver" thing seemed cool too but then I realized it was the boring kind of SAT.
2
0
11
@egrefen @sleepinyourhat +1 the general sentiment that nothing mystical is happening in our paper: our choice of task is strongly motivated by theory + intuition about what synthetic tasks filler tokens could help on.
1
0
11
@zouharvi (and it may still fail even then; Geiger et al. 2019). Or consider getting rid of the outer parentheses altogether.
1
0
11
This result also solidifies the idea that (fixed-precision) transformer computation is "shallow": it can only next a finite number of quantifiers (wrt input length), rather than recursing arbitrarily deep like a Turing machine.
2
3
11
[4/n] Our result suggests a *Parallelism Tradeoff*: parallelism makes transformers scalable but limits the complexity of their forward pass. Fundamentally serial computation must be broken down into a "chain" of parallelizable steps à la Scratchpad/CoT.
1
1
12
Any Merrills interested in a replication study?.

it took us two months to have this preprint archived. can you guess why? . a fun project led by Won Ik Cho and Eunjung Cho!. [Cho, Cho & Cho, 2023].
1
0
12
Second, formal analysis of transformers, showing limits on the functions they can express (w/ Ashish Sabharwal, @nlpnoah):.
0
3
11
@srush_nlp Agree with the post that there is a distinction (and often implicit conflation) of behavioral and mechanistic induction heads. Having a behavior definition seems more natural to me, followed by specific computational implementations of that def (eg on a transformer) 🧵.
1
2
11
[2/6] Specifically, the following relationship holds between text frequency and sentence entailment:

1
0
10
@Ashish_S_AI Also always excited to talk about state-space models and state tracking . (Accepted at ICML 🇦🇹 w/ @jowenpetty @Ashish_S_AI).
1
1
11

@CFGeek @sir_deenicus I’ve worked a lot on analyzing non seq2seq transformers using circuit complexity. with realistic precision they are in tc0 - far from Turing complete!. We’re currently working on extending the analysis to seq2seq transformers, which sounds a bit like what you’re suggesting.
2
0
10
* Gricean speaker = speaker who attempts to convey information efficiently to a listener. Think rational speech acts. This is a decent first-order model of human speech acts, but it would be interesting to see how extending it changes the theory!.
1
1
9
Does anyone have references for understanding the scaling of model size (# params) vs. context size (# tokens) for large language models? Are there standard/"optimal" ways to scale these in tandem? Or is context size bottlenecked by memory, etc. in practice, not scaling laws?.
1
0
9