

jack morris
@jxmnop
Followers
26K
Following
14K
Media
491
Statuses
4K
getting my phd in language models @cornell_tech 🚠 // former researcher @meta // academic optimist // master of the semicolon
new york, new york
Joined October 2016
📢 New state-of-the-art small text embedding model 📢 . we used a few more tricks to train cde-small-v2, a faster, easier-to-use, and more performant counterpart to cde-small-v1. set a new small-model record on MTEB of 65.6 – better than large models from a lot of companies 🫢.
19
60
498

observations from my first two weeks as a Meta research intern. - research jobs are the same everywhere: no one ever asks me what I’m doing or how I’m spending my time; there’s an implicit expectation to be interested and work hard.- biking to work in the sunshine has noticeably

142
166
10K
most people don't know that lex fridman's bizarre character arc actually started in research. here's the real story:. > around 2018 tesla deploys Autopilot, software that lets the car drive for you on highways. but only as your hands are on the steering wheel.> all research.

“I was really disappointed that Zelensky wouldn’t say a kind word about Putin on my show.”. Maybe because he’s been bombing Ukraine every day for the past three years bro
172
733
10K
openAI: we will build AGI and use it to rewrite the social contract between computer and man. DeepSeek: we will build AGI for 3% the cost. and give it away for free. xAI: we have more GPUs than anyone. and we train Grok to say the R word.
69
413
8K
watched the Attention Is All You Need re-release on IMAX 70mm. so epic



40
517
6K
another incredible thing about deepseek:. all the american AI labs compete to hire the top PhD researchers - but deepseek didn’t compete. deepseek researchers aren’t top PhDs. most are not even PhDs.
295
334
6K


yearly reminder. everything looks exponential from the middle of a sigmoid

91
423
6K
now seems as good a time as ever to remind people that the biggest breakthroughs at OpenAI came from a previously unknown researcher with a bachelors degree from olin college of engineering




66
552
6K

someone finally made leetcode for machine learning, and it's everything we hoped it would be. just solved the first exercise: computing a matrix-vector product without any tensor operations (only python lists allowed).


47
512
5K
apparently deep learning models can tell male from female eyeballs with 87% accuracy but no one knows why:. "Clinicians are currently unaware of distinct retinal feature variations between males and females, highlighting the importance of model explainability for this task"

93
681
5K

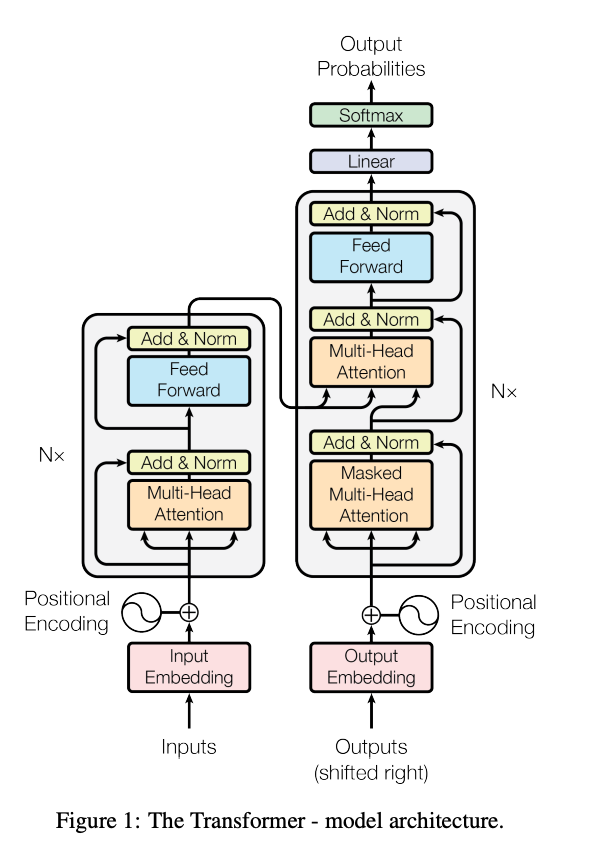
today i found out that this one australian guy has been toiling away making incredibly detailed Neural Circuit Diagrams with the vibe of a 1950s issue of Popular Mechanics, but content fit for the 2020s . behold. the Transformer

24
619
5K
openai: we trained our language model to think. it can do phd-level math. google: we trained a language model to think harder. it can do harder phd-level math. anthropic: we asked our language model if it would act like a bad bad boy. AND IT DID.
40
179
5K
harvey dent Was right


New: Sam Altman has told shareholders that OpenAI is considering becoming a for-profit company that would no longer be controlled by a nonprofit board
132
537
5K
2022:.- oh nooo!!! you can't run language models on cpu! you need an expensive nvidia GPU and special CUDA kernels and–.- *one bulgarian alpha chad sits down and writes some c++ code to run LLMs on cpu* .- code works fine (don't need a GPU), becomes llama.cpp. 2023:.- oh noo!!.
68
322
4K
how I got my first job at google. > be me.> go to college.> great state school, smallish CS program .> google does not recruit here.> that’s ok.> no worries.> build personal website.> start working on cool blog post for site.> write some python code for blog.> confused about.
65
100
4K
still the most compelling Figure 1 i've ever seen. - from "Visualizing the Loss Landscape of Neural Nets" (2017)

46
267
4K
*breathes deeply* ahhhh yes. the boundary of all human knowledge

18
267
4K
it's a baffling fact about deep learning that model distillation works. method 1.- train small model M1 on dataset D. method 2 (distillation).- train large model L on D.- train small model M2 to mimic output of L.- M2 will outperform M1. no theory explains this; it's magic.
254
188
3K
the self-driving battle is more interesting than LLMs rn and for some reason people aren’t talking about it . cars that depend on LIDAR and hard-coded heuristics (waymo, zoox) can drive themselves. cars that rely on neural networks only (tesla) can’t. interesting, isn’t it 🧐.
153
93
3K
We spent a year developing cde-small-v1, the best BERT-sized text embedding model in the world. today, we're releasing the model on HuggingFace, along with the paper on ArXiv. I think our release marks a paradigm shift for text retrieval. let me tell you why👇

69
457
3K
shannon invented digital circuit design as a Masters student in 1937. invented information theory ~10 years later. a typical phd student in 2024 ends up writing an esoteric thesis about a corner of the world almost no one will ever know exists. why don't people think big anymore.
226
141
3K
navigated to a file to write a helper function, but the code was already there, written by me, exactly where i was about to write it

9
121
3K
one of the most important things I know about deep learning I learned from this paper: "Pretraining Without Attention". this what I found so surprising:.these people developed an architecture very different from Transformers called BiGS, spent months and months optimizing it and

92
408
3K
the right takeaway from DeepSeek supremacy is that our median AI engineer is just not really that skilled. most-popular libraries are piles of glued-spaghetti python code. rare to see anyone do profiling or performance optimization. massive deficiency of Good Software in AI.
153
180
3K
LLMs run on a surprisingly old tech stack:. gradient descent. ‣ method for finding the minimum of a function. ‣ Cauchy, 1847 (177 years ago). next-token prediction. ‣ core learning task for language models. ‣ Shannon, 1948 (76 years ago). autodiff + backpropagation. ‣.
80
279
3K
TIL that the volume of the unit sphere goes up until a dimensionality of exactly 5, and then tends towards 0 with infinite dimensions. (as a human who experiences the world in three dimensions, i find this very unpleasant)


95
169
3K
back to school this week and back to reminding people that one of the coolest things my advisor did was write a course on how to build PyTorch from scratch. if you want to become an expert on deep learning, can't think of a much better place to start than MiniTorch:

18
221
3K

i think the “TikTok algorithm” is probably just an embedding model that matches video embeddings to user embeddings to recommend content. this is how most state-of-the-art recommenders work. they might be using a huge model, but i doubt it’s anything more complicated.

the tiktok algorithm is, without question, the most valuable piece of software in existence.
134
83
3K
learned something super interesting this week. if you train GPT-2 to multiply, you can't even train it to multiply 4-digit numbers (30% accuracy). but if you use a really clever (and somewhat complex) training scheme, GPT-2 can generalize up to 20-digit numbers (100% accuracy).
51
224
3K
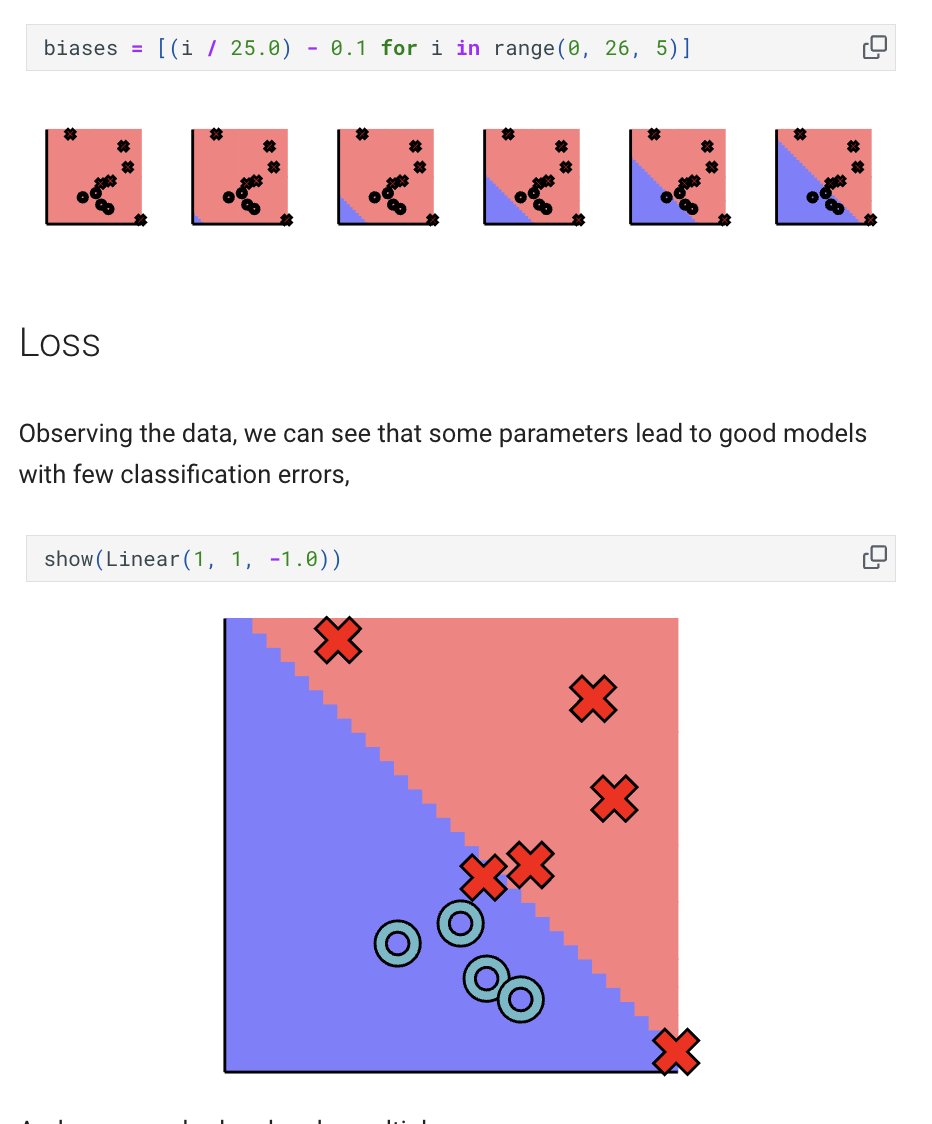
what software was this made with? i don't think you can draw arrows that curve like that w/ Google Drawings
197
64
2K
so DeepSeek R1 seems to be an incredible engineering effort. i'm trying to understand the recipe . seems it's pretty much "run PPO (GRPO) on the model with verifiable math & coding problems". and it turns out that's all it takes? hundreds of people must have tried this before.
93
122
3K
BREAKING: The Nobel Prize in Physics has been awarded to ptrblock for “fundamental contributions to physics”

29
114
2K
i guess DeepSeek broke the proverbial four-minute-mile barrier. people used to think this was impossible. and suddenly, RL on language models just works . and it reproduces on a small-enough scale that a PhD student can reimplement it in only a few days. this year is going to.

We reproduced DeepSeek R1-Zero in the CountDown game, and it just works . Through RL, the 3B base LM develops self-verification and search abilities all on its own . You can experience the Ahah moment yourself for < $30 .Code: Here's what we learned 🧵

31
218
2K
the yacine guy becoming popular is strong evidence that the X algorithm rewards *volume* over anything else. the app has RLHF’d him and many others into the same loop.- spend all day on the platform .- reply to every tweet you see.- gain followers.- repeat. I miss Twitter.
112
44
2K
turns out the way paints mix (blue + red = purple) is much more complicated than how light mixes (blue + red = pink). they have to use a little bit of nonlinear modeling to capture this, and "add" paints in this nonlinear latent color space

5
82
2K
chinese ai researchers are incredibly cracked, and driving a lot of open-source progress. > best coding model (Deepseek).> best open-source Multimodal language model (Qwen2-VL).> two of best open-source anything models (Yi-lightning and also Qwen again).
37
190
2K
remember the GPT Store?. a few months ago there was some excitement around "prompt app stores", where gifted prompt-writers could make money by writing magical system prompts and packaging them as "apps". our new research shows these prompts can be easily recovered by just asking

49
187
2K
i have a dictionary of ~350M key-value integers that i want to save to disk. - written as ints to lines of a text file: 3.2 GB.- stored as torch.Tensors in a collections.defaultdict, saved to disk using pickle.dump: 937 GB. lesson learned.
129
44
2K
when you’re a VP at google research you can start your research papers just like spongebob starts his essays




24
94
2K
holy cow . guy who writes (very helpful!) blogs about logistic regression, activation functions, validation sets, et cetera has an h-index of 59. that's higher than almost all the researchers i've ever met. interesting strategy 🤔
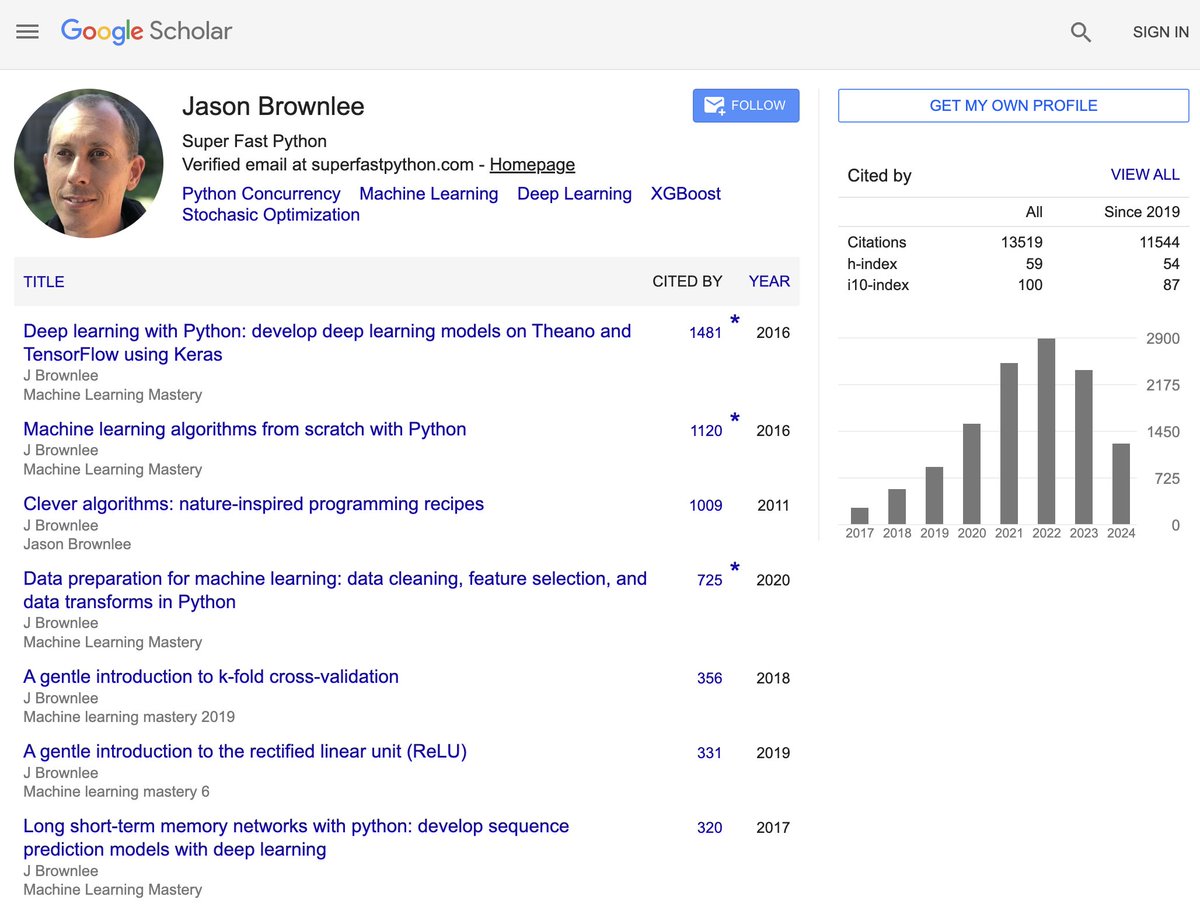

23
142
2K
okay what. 99.99% chance there's a bug in my code, but.0.01% chance i just solved text retrieval

60
33
2K
recently read one of the most interesting LLM papers i've ever read, the story goes something like this. > dutch PhD student/researcher Eline Visser lives on remote island in Indonesia for several years.> learns the Kalamang language, an oral language with only 100 native.
34
206
2K
when GPT-3, a 175B param model, dropped in 2020, everyone started preparing for the next generation of 1T models, and 10T after that. but 4.5 years later, the trillion-parameter models never came. we’re still squarely in 50-150B territory, just training our models better and.
127
57
2K
here is my meticulously curated (and highly biased) summer paper reading list 📚:. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2020).╰╴ LoRA: Low-Rank Adaptation of Large Language Models (2021).╰╴ Ring.
26
266
2K
from 2017–2020 i was learning ML. i didn't publish any research (and hadn't yet); i just trained a lot of tiny models and read a paper every single day. i maintained a giant spreadsheet with notes about each paper along with random thoughts. was a great way to learn


50
119
2K
tinygrad is running the funniest goodhart around right now. they're obsessed with talking about how their library uses fewer lines of code than pytorch, so their codebase is growing horizontally instead of vertically. some parts are borderline unreadable to humans


70
48
2K
i'm a little late to the party here but just read about the NeurIPS best paper drama today. you're telling me that ONE intern.> manually modified model weights to make colleagues' models fail.> hacked machines to make them crash naturally during large training runs.> made tiny,.
56
51
2K
An amazing mystery of machine learning right now is that state-of-the-art vision models are ~2B parameters (8 gigabytes) while our best text models are ~200B parameters (800 gb). why could this be? philosophically, are images inherently less complicated than text? (no right?).
359
113
2K
> be google researcher.> exec says we need to beat mistral 7b.> “reclaim the narrative".> train 7b model.> run eval. check plots.> cant do it. maybe with 8b.> exec says no dice.> “we'll look like chumps".> ok.> maybe we can tie embeddings and linear_f, save some params.> not

24
91
2K
this is the name of the paper:."Human Side of Tesla Autopilot: Exploration of Functional Vigilance in Real-World Human-Machine Collaboration" (Fridman et al., 2018). i'm sure it's still out there somewhere.
13
43
1K
the transformer architecture might be the most important invention of the 21st century. for years people talked about exploding and vanishing gradients,.optimizers, learning rate schedules, etc. none of that matters much anymore thanks to transformers. computers just learn now.
63
80
1K
TIME Magazine has rightly named famed deep learning pioneer ptrblock as the most influential person in Artificial Intelligence.

27
53
1K
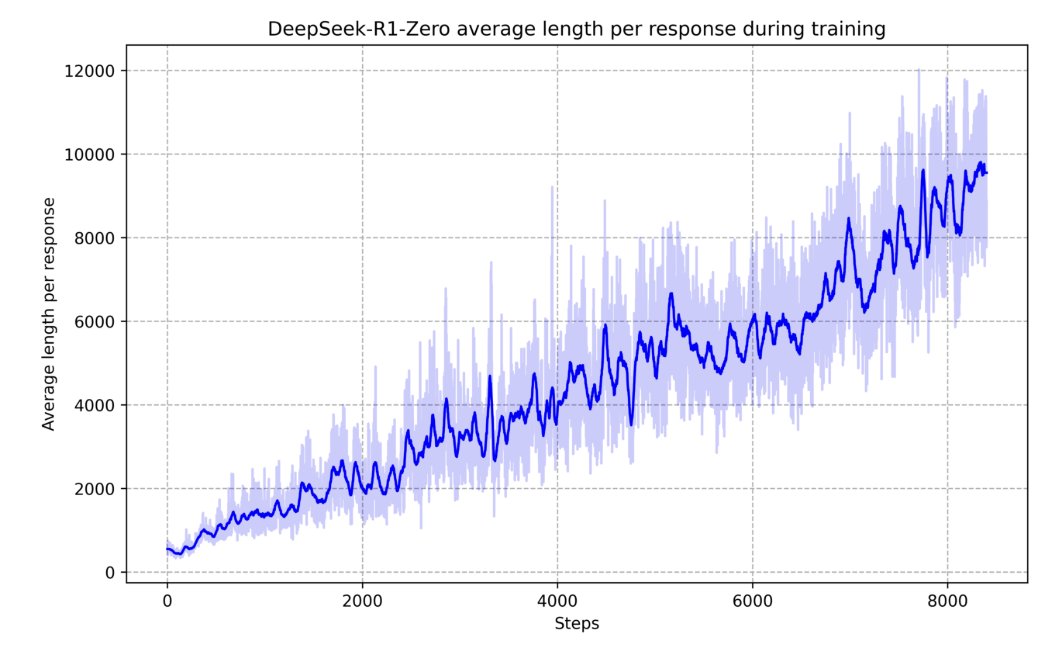
with o1 and now R1, models are now generating tens of thousands of tokens to solve hard problems. o3 is likely generating hundreds of thousands or millions of tokens. apparently the tokens for solving one task in ARC-AGI with the slowest o3 model cost over $3000. this is why i
72
113
1K
New Research:. a lot of talk today about "what happens" inside a language model, since they spend the exact same amount of compute on each token, regardless of difficulty. we touch on this question on our new theory paper, Do Language Models Plan for Future Tokens?

20
142
1K
most important thing we learned from R1? that there’s no secret revolutionary technique that’s only known by openAI. no magic optimization, new data sources, or crazy novel MCTS variant. just great engineers precisely.applying known machine learning techniques at scale.
39
110
1K
finally published our latest research on text embeddings!. TLDR: Vector databases are NOT safe. 😳 Text embeddings can be inverted. We can do this exactly for sentence-length inputs and get very close with paragraphs.

45
175
1K
anybody who tells you to learn AI by reading a textbook is gatekeeping. there simply isn't a textbook out there that covers this stuff. goodfellow Deep Learning is outdated (one subsection on language models!). and the ML textbooks (bishop and murphy) are not really relevant.
98
48
1K
tired of paying OpenAI for GPT-4 API? the NYC Department of Small Business Services has your back!. the NYC small business chatbot is powered by GPT-4, so equally capable. just have to ask it information about operating a business in New York City first.



31
101
1K
when my code is getting too slow, i just run it a couple times and ctrl-C on the slow part, see where in my code it stops me. i call it the poor man's profiler.
45
45
1K

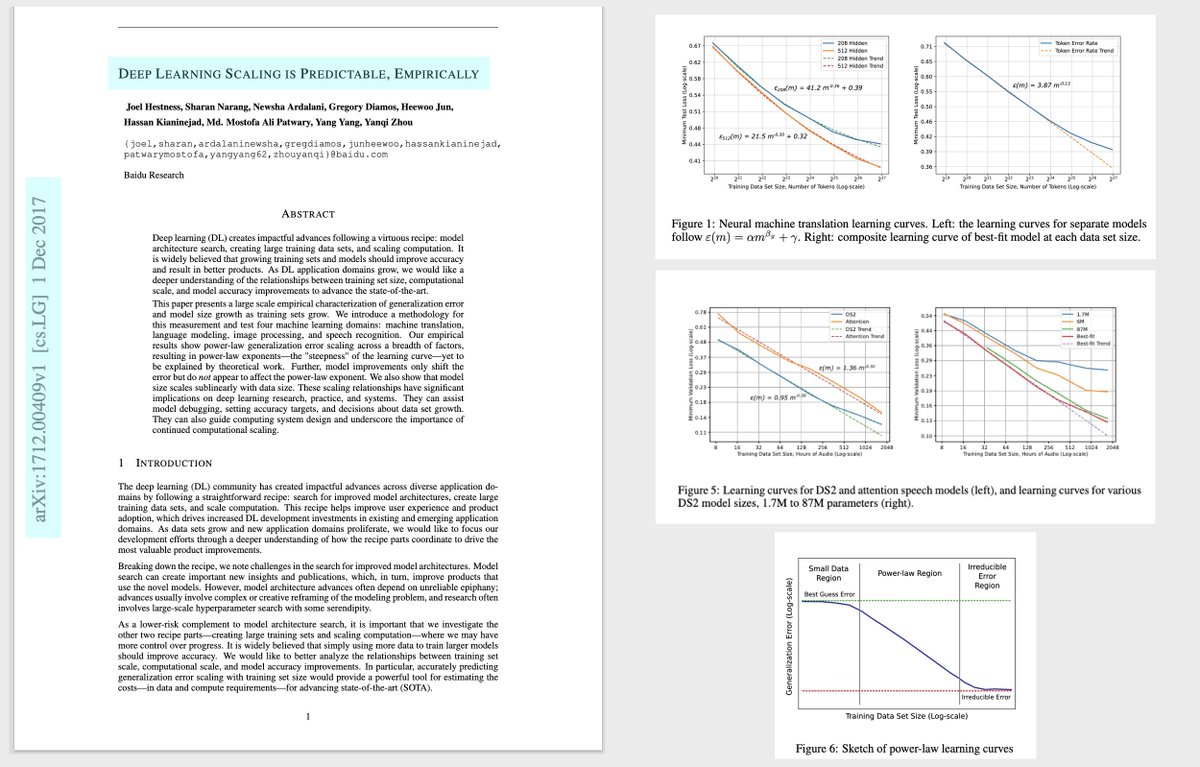
most people don't know that the original research on scaling laws came from Baidu in 2017 – not OpenAI in 2020. they characterized the effects of model params and dataset tokens on loss. also tested on images, and audio. they just used LSTMs instead of Transformers, and didnt
25
132
1K
if huggingface builds superintelligence they’ll probably just open-source it and make it installable like ‘pip install agi’.
37
80
1K
this google guy made big headlines two years ago. funniest part: he was duped into empathizing with *LaMDA*, an extremely primitive language model by 2024 standards. undertrained on low-quality data, no RLHF/DPO, etc. if he talked to the latest Gemini he would simply combust

73
42
1K
say what you will about mistral, tweeting exclusively download links to new models with no context is unbelievably cool

18
61
1K
things you definitely do NOT need to understand to be an expert on LLMs:.- linear regression.- bias variance trade off.- most probability distributions (Gaussian Bernoulli poisson etc.).- RNNs.- LSTMs.- CNNs.- higher-order calculus (beyond first derivatives + chain rule).-.
75
45
1K
Telling younger researchers about what it was like to be getting interested in AI when BERT and GPT-2 came out

38
37
1K
Honestly the Gemini release made me really sad. “Gemini beats GPT-4 at 32-shot COT” (read: not straight up) is exactly what a PhD student would say if their model wasn’t as good as they’d hoped. what’s so special about GPT-4? is it people? systems? data? some kind of blind luck?.
73
30
1K
man, the huggingface team is *cracked*. two days after i released my contextual embedding model, which has a pretty different API, @tomaarsen implemented CDE in sentence transformers. you can already use it. implementation was not at all trivial; those people just work fast

19
100
1K
startup idea: Ramanujan AI.premise: humans all have similar brain structures, but only one in a billion is a true genius.hypothesis: maybe this is true for LLMs too.Step 1: train a billion 7B llama models from scratch w random initializations.Step 2: search through to.
83
37
1K
some people will hate me for saying this, but my conclusion from moving to san francisco this year to do AI research was this: you don’t need to move to san francisco to do AI research. there’s certainly a higher concentration of people who speak fluent AI, and more people.
37
40
1K

curious if anyone knows where Google went wrong with TensorFlow? . it's bad software, fundamentally broken. when I was an AI resident I found ~5 bugs within tensorflow core in around a year. but how does a failure like this this happen? so many smart people work there.

133
53
1K
apparently people who use chatGPT a lot are subconsciously training themselves to get really good at detecting AI-generated text.

People often claim they know when ChatGPT wrote something, but are they as accurate as they think?. Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯

45
48
1K
guess it turns out that langchain was just a fad –. something that we all tried and appreciated, but eventually lost our zeal for, such as tamagotchis, silly bandz, cup stacking, etc.
75
28
1K

unpopular opinion: training open-source LLMs is a losing battle. a complete dead end. the gap between closed models like GPT-4 and open models like LLAMA will only continue to widen as models grow bigger and require more resources. no one is building particle colliders at home.
248
55
916

the incredible blog post that got me interested in language models

22
55
933
fewer than 100 people deeply understand both (i) transformers and (ii) the GPU programming model. want to learn machine learning? gain some esoteric systems knowledge; spend some time really learning CUDA.
60
26
904
class tonight. send me your most scrutable visualizations of Transformers
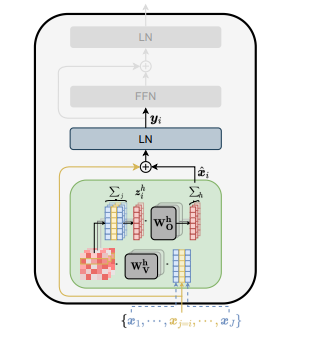

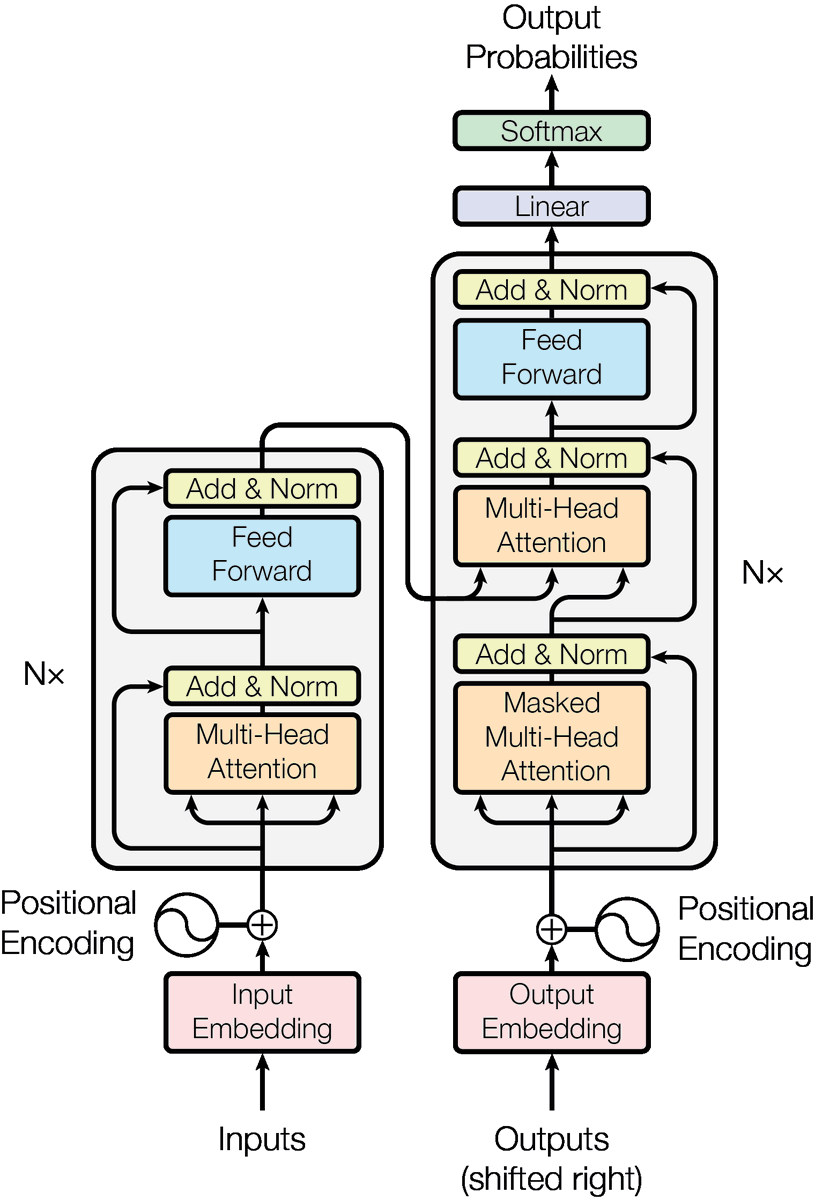
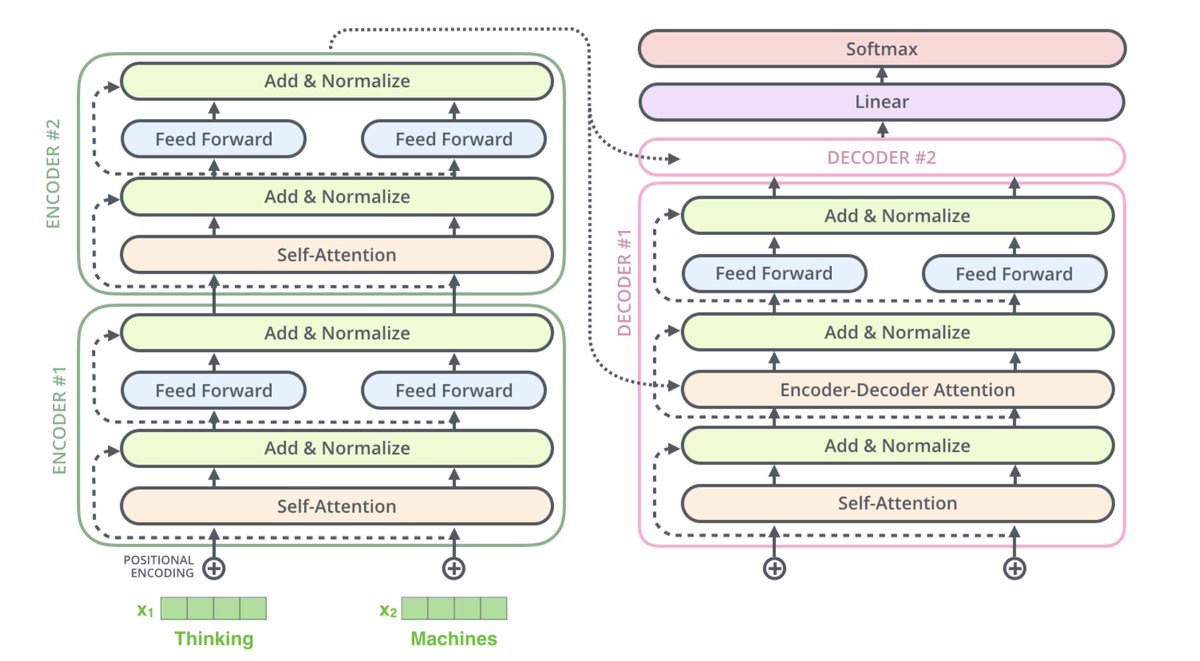
40
63
862
Introducing TextAttack: a Python framework for adversarial attacks, data augmentation, and model training in NLP. Train ***any @huggingface transformer*** (BERT, RoBERTa, etc) on ***any @huggingface nlp classification/regression dataset*** in a single command.

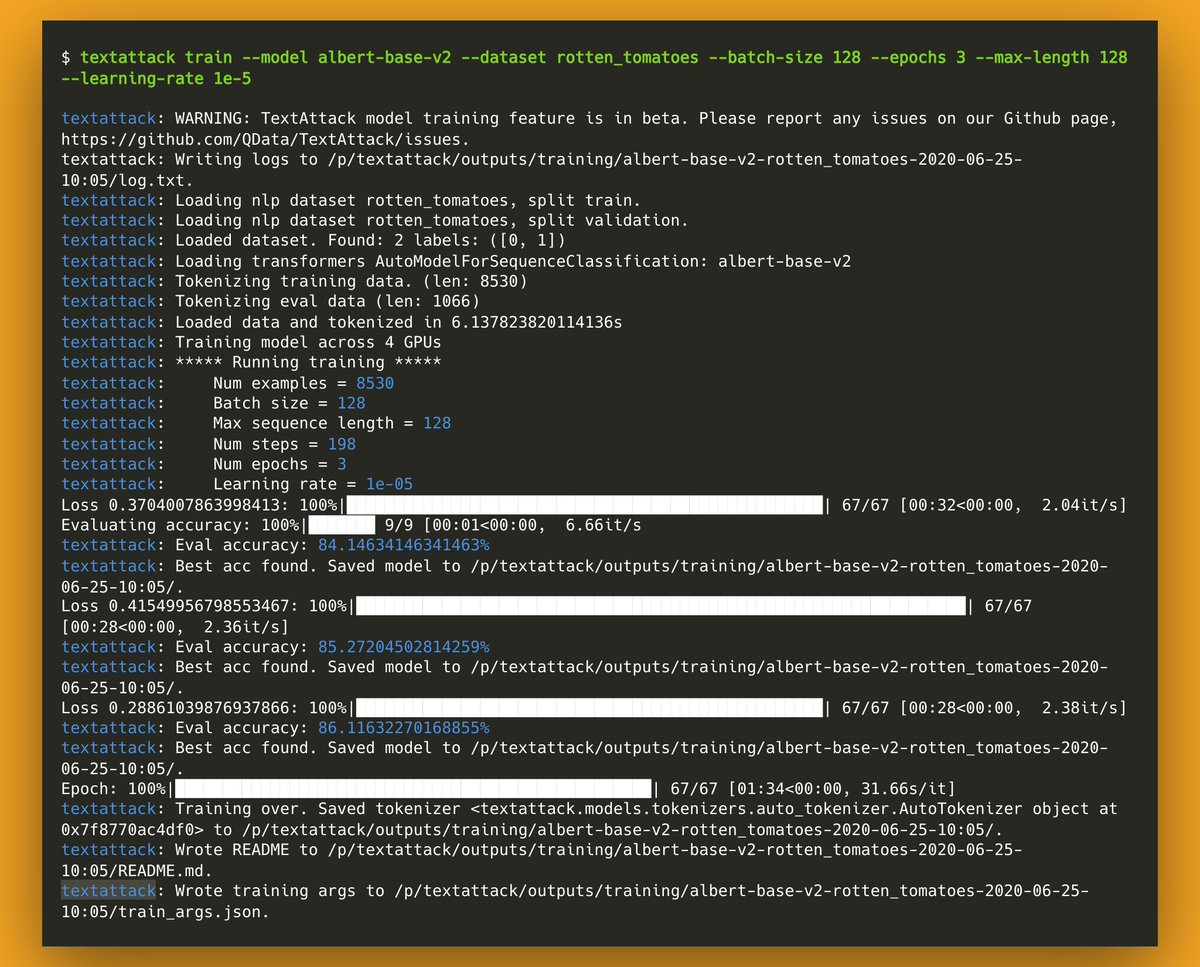
12
209
851
my face after eight hours of trying to visualize what 1000-dimensional space looks like

56
33
844
if you have language model weights on your computer, you also are in possession of powerful compression software. just put the finishing touches on gptzip, a little personal project for compressing strings with language models. compress text w/ hf transformers, 5x better rates
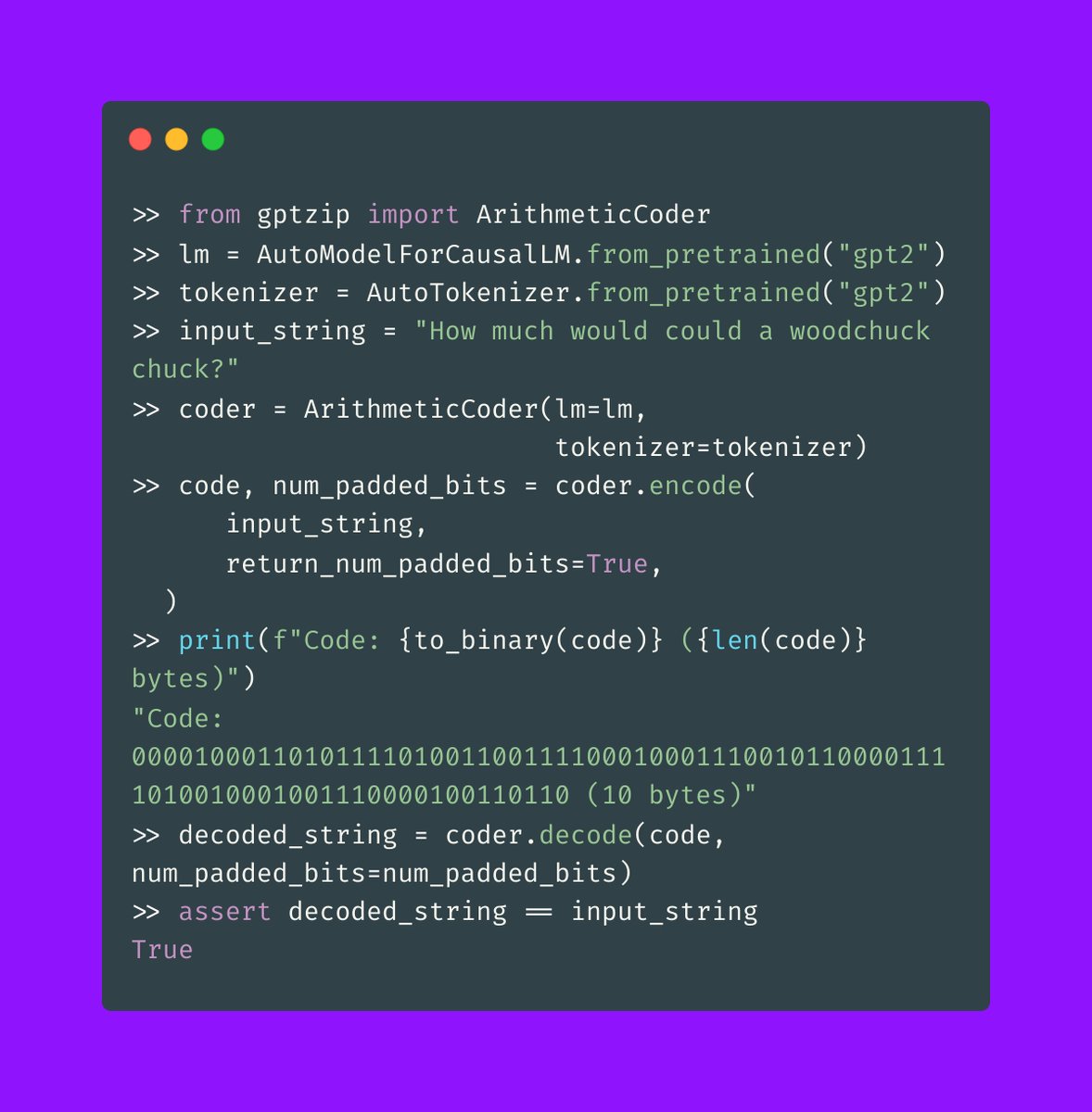
35
58
865
prompt optimization is such a hard problem, and the algorithms are dumb. the fact that they work at all is baffling, and people don't talk about it enough. for those who don't know, the prompt optimization problem is argmax_{x} ℓ(y | x; θ) where x is some prompt and ℓ is the.
42
67
847
things always look exponential when you’re standing in the middle of a sigmoid

29
69
820
a year or so ago there was a blip of excitement about running LLMs locally, on your laptop or something; now it doesn’t feel like many people are doing that. why not? too slow, too much loss in quality from quantization? or turns out the APIs are actually convenient enough?.
187
23
837
one day the history books will write about the role this man played in the development of AGI

12
64
808
fun research idea: Latent chain-of-thought / Latent scratchpad. it's well-known that language models perform better when they generate intermediate reasoning tokens through some sort of 'scratchpad'. but there's no reason scratchpad tokens need to be human-readable. in fact,

54
76
804
Seen a lot of evidence that GPT-4 crushes Gemini on all the head-to-head LM benchmarks. here's my theory about what went wrong:. - chatGPT released.- google execs freak out.- google consolidates (integrates Deepmind, Brain).- google assembles a giant team to build a single giant

43
41
775
I turned down a job at google research to do a PhD at Cornell right before chatGPT came out and I don’t regret it at all. I see it like this. Do you want to work with a large group on building the fastest & fanciest system in the world, or in a small group testing crazy theories.

As PhD applications season draws closer, I have an alternative suggestion for people starting their careers in artificial intelligence/machine learning: . Don't Do A PhD in Machine Learning ❌. (or, at least, not right now). 1/4 🧵.
13
21
770
funny little story about Extropic AI. >been curious about them for a while.>have twitter mutual who is an engineer/researcher for this company.>often tweets energy-based modeling and LM-quantumhype mumbojumbo.>last winter, i wanted to get to the bottom of this.>meet up with.

Update on our progress towards building the ultimate substrate for Generative AI
33
16
775
move over meta, the true biggest benefactor of open source machine learning is CHANEL.

TIL scikit-learn, an open-source ML library, has only one Platinum sponsor and it is . Chanel?

5
40
766
the story of entropix is a sad one; a cautionary tale . over 3k github stars, tens of thousands of likes & replies on X; unfortunately it is not real. turns out you can vaguepost your way to the top with plots that look good! with numbers that seem high! and as long as you.
52
18
783