

Daniel Fried
@dan_fried
Followers
3K
Following
2K
Media
23
Statuses
849
Assistant prof. @LTIatCMU @SCSatCMU; Research scientist at @AIatMeta. Working on NLP: language interfaces, applied pragmatics, language-to-code, grounding.
Pittsburgh, PA
Joined August 2013
I’m excited to release a paper (and model weights!) for InCoder: a generative code model that can infill as well as do left-to-right generation. Project page: .Demo: Paper: . Thread (1/n):
8
123
500
I'm recruiting grad students starting Fall '22! Particular areas of interest: language grounding, interaction, pragmatics, and multi-agent NLP. Want to help people do things with words and computers? Apply to CMU SCS by December 9!
4
69
228
New(ish) preprint: a survey and position paper on the role of *pragmatics* in grounded NLP. People use language in context to achieve goals, and to interact more successfully and efficiently with people, our NLP models should too. Preprint: (1/)

3
38
165
I'm excited to be working on agents at @Meta, along with continuing my work at CMU!.

I am very excited to start working with GenAI team at @Meta, focusing on multimodal LLM agents, joining together with my amazing CMU colleagues Jing Yu Koh @kohjingyu and Daniel Fried @dan_fried!

13
7
167
We built a pragmatic, grounded dialogue system that improves pretty substantially in interactions with people in a challenging grounded coordination game. Real system example below! Work with Justin Chiu and Dan Klein, upcoming at #EMNLP2021. Paper:
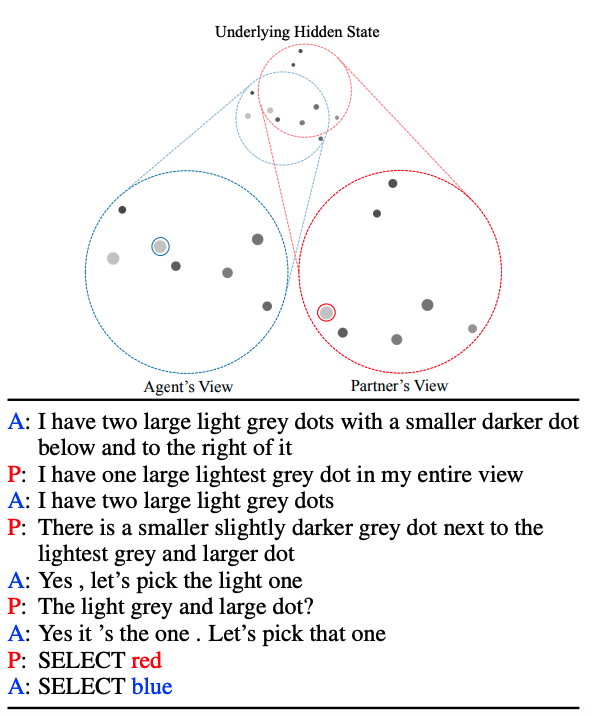
2
30
135
Neural text generation systems sometimes drop content or are underinformative, but can be improved by pragmatic inference methods. #naacl2019 paper by Sheng Shen, me, @jacobandreas and Dan Klein: Helps for summarization (CNN/Daily Mail) and the E2E task!

1
32
127
Upcoming at #acl2020nlp: identifying action segments ("pour milk") in videos of high-level tasks ("make a latte"), with weak supervision: Work with JB Alayrac, Phil Blunsom, @redpony, Stephen Clark, and @aidanematzadeh. (1/4)

2
15
87
I’m very excited about this work on interactively grounding language to rewards (preferences), via pragmatic reasoning and inverse RL. Reward learning can help NLP systems do what people want even in settings the people haven’t yet described (or seen!).

How can agents infer what people want from what they say?. In our new paper at #acl2022nlp w/ @dan_fried, Dan Klein, and @ancadianadragan, we learn preferences from language by reasoning about how people communicate in context. Paper: [1/n]

0
13
64
We built a benchmark to test whether LLMs can optimize Python code (in runtime and memory) through algorithmic rewrites while ensuring the semantics stay correct. I'm excited about the task -- there's a lot of headroom here!.

Can current code LMs generate sufficiently efficient programs? 🤔.More importantly, Can these LMs improve code efficiency without sacrificing correctness?. Check out ECCO, our code-gen benchmark for correctness-preserving program optimizations!.🧵 1/n

2
5
60
Call for papers --- we'd love to see your work on implicit / underspecified language at the UnImplicit workshop @ NAACL 2022!. Apr 14th (extended deadline): papers that haven't yet been reviewed.Apr 21st: papers that already have ARR reviews.

If you are interested in implicit and underspecified language consider submitting to the UnImplicit workshop #NAACL2022! With @meanwhileina, @complingy and Judith Degen as invited speakers. Info:

0
16
59
Send us your papers on LLM agents, and join us at ICLR!.

📣 CALL FOR PAPERS 📣.Join us at the #ICLR2024 Workshop on LLM Agents! @iclr_conf . 🙋♂️We welcome both research papers and demos with technical reports. For more details, visit: #LLM #LLMAgents.
2
6
57
Very excited that these models are released! In our evals, these are currently the strongest open-access (weights released) code models, and I'm looking forward to using them in research. Models, demos, paper, VSCode extension, and more:

Introducing: 💫StarCoder. StarCoder is a 15B LLM for code with 8k context and trained only on permissive data in 80+ programming languages. It can be prompted to reach 40% pass@1 on HumanEval and act as a Tech Assistant. Try it here: Release thread🧵

2
7
44
We're excited to release VisualWebArena, with > 900 challenging, visually-grounded examples to evaluate multimodal web agents. Has self-contained web environments, and execution-based evaluation! . And headroom: GPT-4V gets 16% success; people get 89%.

Computer interfaces are inherently visual. To build general autonomous agents, we will need strong vision language models. To assess the performance of multimodal agents, we introduce VisualWebArena (VWA): a benchmark for evaluating multimodal web agents on realistic visually

0
9
39
New paper in Science with an amazing team from FAIR on a strategic dialogue agent for the negotiation game Diplomacy. Especially excited that we were able to encourage the agent to be honest and helpful -- proposing joint plans with its partners, and persuading them to take them.

Meta AI presents CICERO — the first AI to achieve human-level performance in Diplomacy, a strategy game which requires building trust, negotiating and cooperating with multiple players. Learn more about #CICERObyMetaAI:
1
2
41
Super excited about this work on a sampling-free objective for open-ended generation -- uses off-the-shelf models and no training required. Comprehensive human evals, and a bonus pragmatic framing!.

.We propose contrastive decoding (CD), a more reliable search objective for text generation by contrasting LMs of different sizes. CD takes a large LM (expert LM e.g. OPT-13b) and a small LM (amateur LM e.g. OPT-125m) and maximizes their logprob difference

0
3
40
We surveyed the literature on LLM tools to provide a unified perspective, identify tradeoffs in current methods and datasets, and motivate future work!.

Tools can empower LMs to solve many tasks. But what are tools anyway?. Our survey studies tools for LLM agents w/.–A formal def. of tools.–Methods/scenarios to use&make tools.–Issues in testbeds and eval metrics.–Empirical analysis of cost-gain trade-off

0
5
40
Catch my students and collaborators in-person at #ACL2024NLP !. - Mon 8/12 12:45pm (Findings Sess. 1): @uilydna on Evaluating LLM Biases in Persona-Guided Generation.- Wed 8/14 10:30am (Sess. 6): @akhila_yerukola on Generative Evaluation of Intent Resolution in LLMs.
1
6
38
Today at #NAACL2021: from 12-1p PT at the @TeachingNLP workshop, we will be presenting assignments we designed for a grad NLP class at Berkeley. They cover neural structured prediction, run interactively in Google CoLab, and are autogradable. Led by David Gaddy @BerkeleyNLP.
2
3
36
I'm excited about Yiqing's work on a framework for creating code-generation benchmarks from naturally-occurring code, e.g. from GitHub. We use test cases to evaluate! As a proof-of-concept, we create a new benchmark from (subsets of) CodeSearchNet.

(1/7) Do you want to test code generation models on the domains you care about?.Struggling to find existing benchmarks that suit your needs?. Our new work *CodeBenchGen* helps you build execution-based benchmarks based on your selected code fragments! (

0
8
35
When there are multiple ways to solve a task, execution-based evaluation is important to tell if an agent actually did it correctly. We emphasized this, realism, and reproducibility in our new benchmark for language-guided web agents. Led by @shuyanzhxyc and @frankxu2004 !.

🤖There have been recent exciting demos of agents that navigate the web and perform tasks for us. But how well do they work in practice?. 🔊To answer this, we built WebArena, a realistic and reproducible web environment with 4+ real-world web apps for benchmarking useful agents🧵

0
3
35
On Monday at 11:40a PT at #NAACL2021 session 3D: see how modular neural networks for embodied instruction following improve compositional generalization. Work by @_rodolfocorona_, with @colineardevin, Dan Klein (@BerkeleyNLP), and @trevordarrell. Paper:

1
3
35
I'm very excited about Zora's work on benchmarks and methods for using code generation in realistic settings!.
Heading to #EMNLP2023 next week ✈️.If you’re interested in Code Generation🧑💻don't hesitate to check out our two papers!. - ODEX, A challenging benchmark with open-domain coding queries: - API-assisted code generation for tableQA:
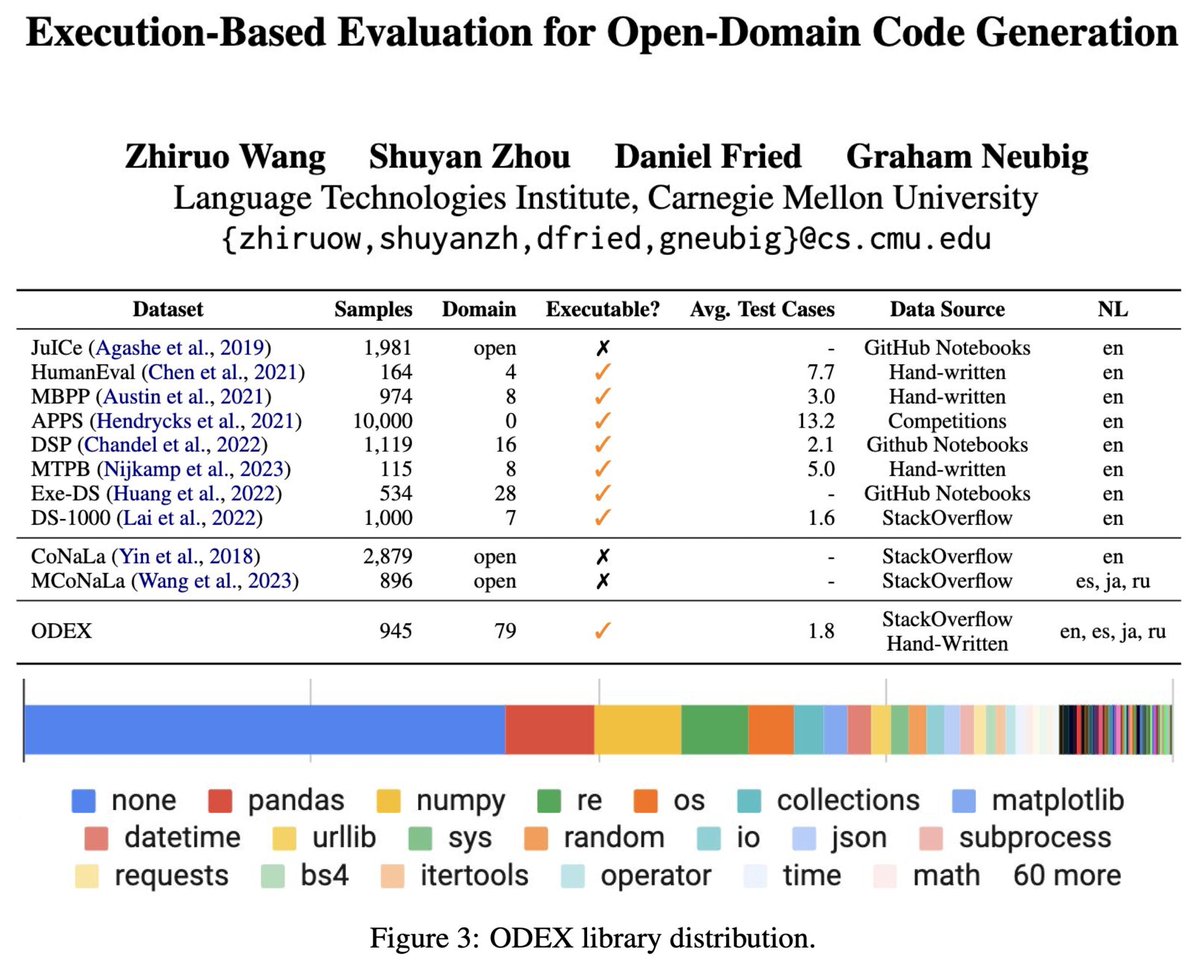
0
3
35
How well can LLMs generate text that represents multifaceted viewpoints and opinions? I'm excited about Andy's work, finding that common RLHF models are steerable at the expense of diversity. Most models still struggle at representing nuanced combinations of traits and stances.

Excited to announce that our work on evaluating LLM biases in persona-steered generation was accepted to the Findings of #ACL2024NLP! We study LLMs’ abilities to be steered towards multifaceted personas reflecting different opinion groups and demographics in generation. (1/9)

0
3
34
If you're planning to pretrain a large generative language model, consider using an infilling objective:.

1/ Introducing FIM our comprehensive study of infilling in decoder-only LMs at @OpenAI. 📄 Main lessons:. 1/ FIM models are strictly superior to regular left-to-right models. They achieve.the same left-to-right evals while learning to infill

0
5
33
Survey for workshops you'd like to see at *ACL next year! We're proposing the 2nd WS on Understanding Implicit and Underspecified Language. Like last year, ( we'll solicit work on a range of challenging lang. phenomena and tasks.
1
11
32
Amazing to me to see how far this line of work on speaker models and speaker-augmented training has come in the last several years: ~3x more successful than our initial work on R2R, and big improvements qualitatively and on harder datasets.

Excited to present "A New Path: Scaling Vision-and-Language Navigation with Synthetic Instructions and Imitation Learning". We explore the limits of pure imitation learning for training VLN agents using high quality synthetically generated data. Paper:
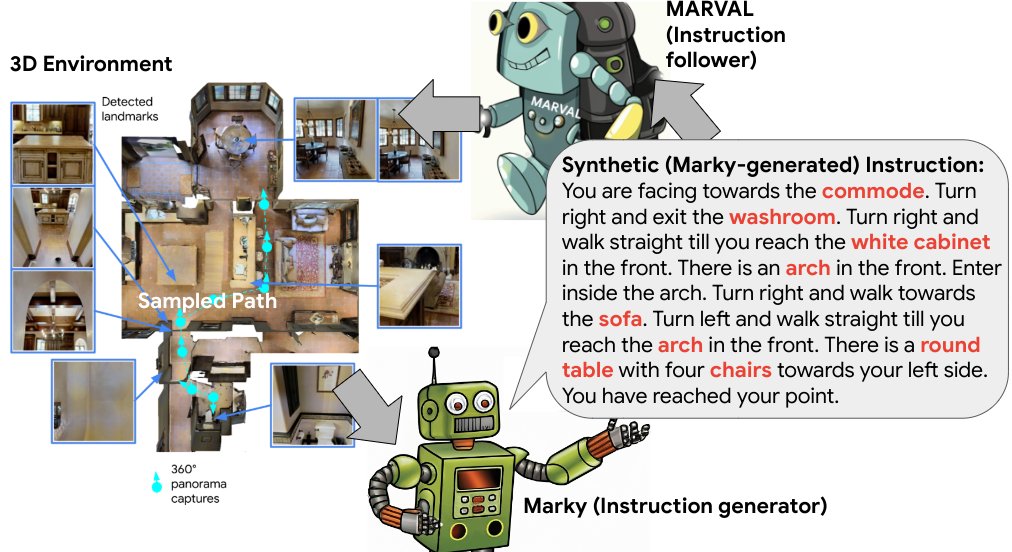
0
3
31
JY's work lifts the capabilities of LLMs to multimodal settings: e.g. contextual image retrieval, in-context style adaptation, and dialogue with images as both input and outputs. Paper: See the thread for more!.
Can we ground LLMs to enable them to process and produce image-text data?. Introducing 🧀FROMAGe: a model that efficiently bootstraps frozen LLMs for images. This enables LLMs to process image-text data and produce coherent image-text outputs. 🧵👇

2
4
30
We'll be presenting our grounded dialogue work Sunday (tomorrow!) at 5pm AST / 4pm Eastern / 1pm Pacific in session 4F, and in the virtual poster session Sunday at 7-9pm AST / 6-8pm Eastern / 3-5pm Pacific. Hope to (virtually) see folks! #EMNLP2021.
We built a pragmatic, grounded dialogue system that improves pretty substantially in interactions with people in a challenging grounded coordination game. Real system example below! Work with Justin Chiu and Dan Klein, upcoming at #EMNLP2021. Paper:
0
3
30
I'm excited for this workshop, and to be giving a virtual talk on our work on Multimodal LLM agents: benchmarks and tree search, at 9:50am Bangkok time Friday! Although I sadly wasn't able to make ACL in-person, hope to catch folks next time.

As ACL kicks off in beautiful Bangkok, check SpLU-RoboNLP workshop with an exciting lineup of speakers and presentations! @aclmeeting #NLProc #ACL2024NLP @yoavartzi @malihealikhani @ziqiao_ma @zhan1624 @xwang_lk @Merterm @dan_fried @ManlingLi_ @ysu_nlp.
3
5
28
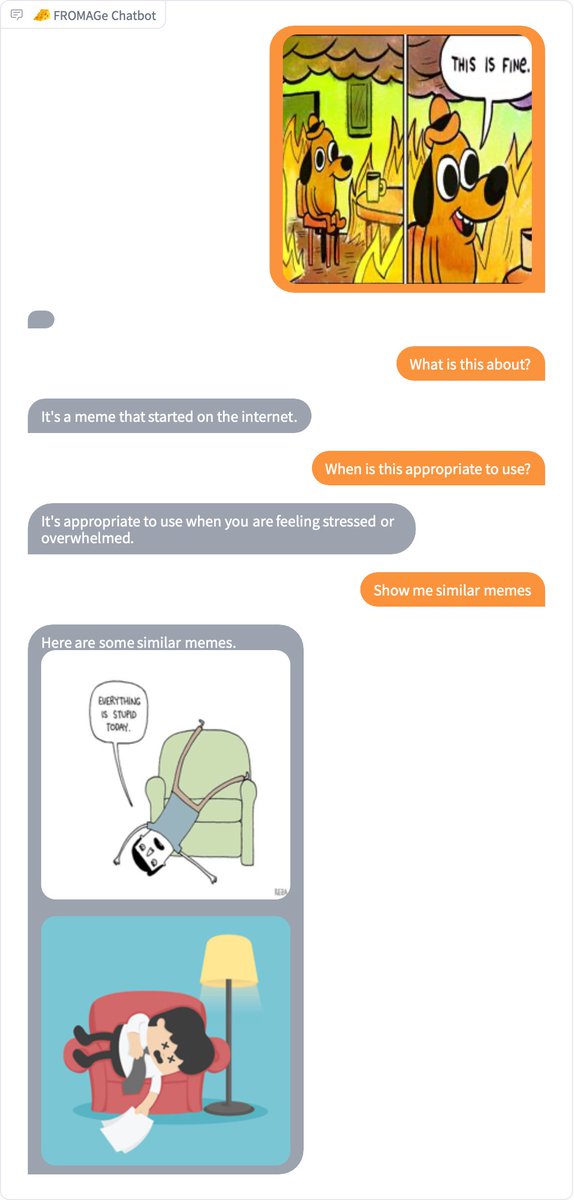
Had some success making spring break plans using JY's new demo:

You can now try out 🧀FROMAGe on HuggingFace Spaces!. FROMAGe is a model that can process image and text inputs to produce image and text outputs. Try out the demo now: Project page: More cool examples below 🧵👇
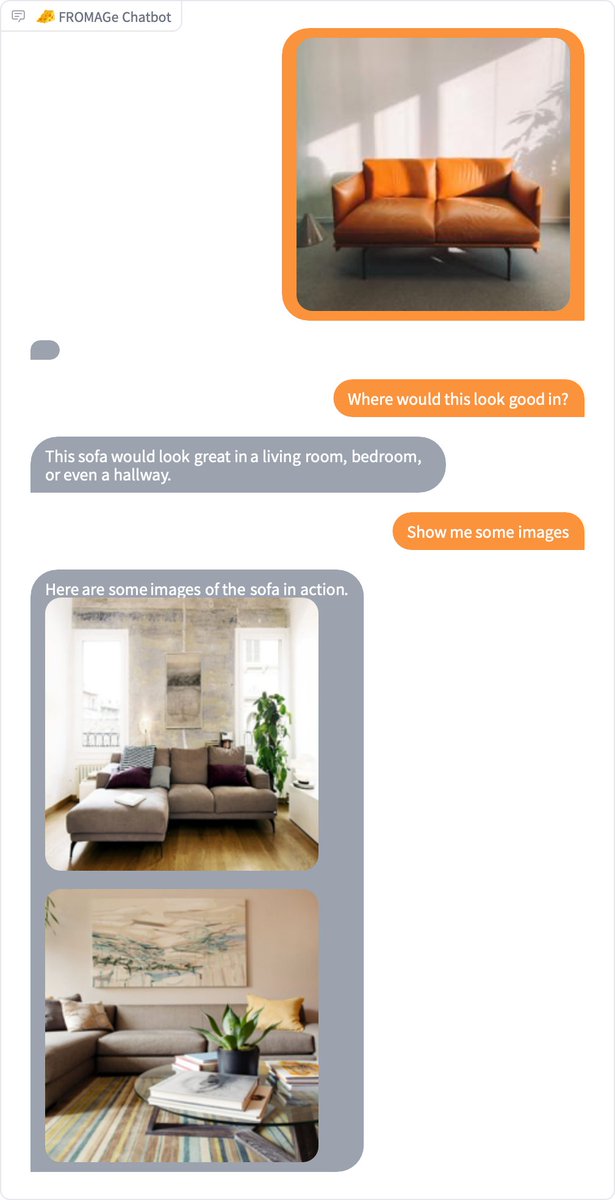

0
3
26
For folks at #NeurIPS23 interested in contextual image generation, @kohjingyu is presenting our work on Generating Images with Multimodal LLMs at poster 2025! . Paper: With @rsalakhu

I'll be presenting the GILL poster ( in 3 hours at 10.45am CT today. Come and talk to us (@dan_fried, @rsalakhu) about grounding text LMs to process, generate, and retrieve images!. 📍 Great Hall & Hall B1+B2 (level 1) #2025.⏰ Wed 13 Dec 10:45am-12:45pm

0
3
29
Inducing *workflows* -- sub-task representations -- from agent experiences leads to huge improvements in task success, and we can do it automatically with pretty simple methods. Very excited about this project led by @ZhiruoW !.
How can we create AI agents that continually improve, learning from past successes?.Presenting 🌟Agent Workflow Memory🌟, which allows agents to induce, learn, and use task workflows from experiences on the fly🪽.Adding AWM to a strong agent improves accuracy by 51.1% on

0
3
25
This Friday at NAACL! Hope to see many folks there, and throughout the conference.
We are looking forward to an exciting line-up of invited speakers at the UnImplicit workshop #NAACL2022 . @complingy @meanwhileina @dan_fried @TalitaAnthonio @microth @rtsarfaty @yoavgo

0
2
24
Looking forward to these amazing speakers on ambiguity, uncertainty, and pragmatics! March 21,
We are looking forward to an exciting line-up of invited speakers at the UnImplicit workshop #EACL2024 . Benjamin Bergen, @malihealikhani and @a_stadt will talk about ambiguity, uncertainty and relevance in language for humans and machines!.

0
0
24
I really liked the discussion of the pragmatics of image generation in this paper! Text and images both serve communicative purposes, and our systems that map from one modality to the other should reflect this.

Text-to-image models have made huge advances this year! However, insufficient attention has been paid to the connection between linguistic and visual meaning. We tackle this important problem in our paper on underspecification in such systems.

1
0
23
Super excited about this work analyzing big LMs for evidence of ToM, and proposing possible directions to help them gain it!.

Have you ever wondered whether large neural networks like GPT3 acquire💭Theory-of-Mind-like abilities🧠? And whether they could achieve human-like🤝🏼social intelligence👥 just by reading insanely large amounts of text? . We find they don't have Theory-of-Mind and examine why🧵.
1
2
23
Highly encourage chatting with Evan if you're interested in communication and programs! . I'm also very excited about the paper--we prove a surprising property of RSA over binary lexicons, and use this to speed up pragmatic program synthesis by 100x. Validated in human study too!.

will be at #ICML2024 presenting this work! . come chat w/ me about cogsci informed code-generation and instruction-following/agentic dataset curation. dm is open.
0
2
22
Bonus example: bidirectional Chinese <-> English technical jargon translation (not at all recommending using this as a translation system! but it's fun to see) (12/11)

3
0
20
I think that key strengths of LLM agents are that they can explore, act in parallel, and decouple generation from verification. JY's work shows that model-agnostic search gives substantial benefits (28-40% relative increase) for LLM agents on realistic web tasks:.
LLM agents have demonstrated promise in their ability to automate computer tasks, but face challenges with multi-step reasoning and planning. Towards addressing this, we propose an inference-time tree search algorithm for LLM agents to explicitly perform exploration and
0
4
21
Really enjoyed reading this paper -- modeling and conveying uncertainty in LLM outputs, with lots of fun bonuses -- dynamic programs, combinatorial optimization, MBR, and making the acronym work without needing to capitalize random letters!.

LLM-based assistants can speed up software development, but what should they do when they aren't sure what code to write? We're excited to share R-U-SURE, a drop-in system for adding uncertainty annotations to code suggestions!. Read our paper here:

0
1
19
Super excited about Freda's work on making code generation more semantics-aware. Substantial improvements over likelihood-based decoding, and could be used as one component of mixed modality interaction with code models (NL, sample inputs, edits. ).

Late post but let’s do this! Happy to share our #EMNLP2022 work on translating natural language to executable code with execution-aware minimum Bayes risk decoding.📝Paper: 📇Code: 📦Data (codex output):(1/n)

0
6
20
And thanks to the amazing folks at @HuggingFace, including @LucileSaulnier, @lvwerra, @narsilou, and @psuraj28 for helping us release the models and demo! (11/11).
1
0
18
I'm excited about Akhila's work as a step toward allowing LLMs to use language non-literally (pragmatically): beyond recognizing intents, models should respond appropriately.

Humans often use non-literal language to communicate –like hyperboles for added emphasis or sarcasm to offer polite criticism with humor.AI systems should be able to decipher the real intent behind these words, and respond appropriately!.📜 #ACL2024 main🎉.
0
0
18
I'm excited about the possibilities for evaluating social intelligence in dialogue interactions with LLMs that this work enables!.

Excited to share that Sotopia ( has been accepted to ICLR 2024 as a spotlight 🌠!.Sotopia is one of the unique platforms for facilitating socially-aware and human-centered AI systems. We've been busy at work, and have follow-ups coming soon, stay tuned!.
0
1
18
Terry coordinated a huge annotation effort to produce this benchmark. It contains challenging coding tasks involving a wide range of libraries, with execution-based tests. Still lots of headroom between people and the strongest LLMs!.

In the past few months, we’ve seen SOTA LLMs saturating basic coding benchmarks with short and simplified coding tasks. It's time to enter the next stage of coding challenge under comprehensive and realistic scenarios! . -- Here comes BigCodeBench, benchmarking LLMs on solving

0
0
19
We want this benchmark to be helpful for practitioners: what types of code generation tasks does RAG help on? What knowledge sources to use? Which retrievers are best? Excited about @ZhiruoW and @AkariAsai 's work on this!.
Introducing 🔥CodeRAG-Bench🔥 a benchmark for retrieval-augmented code generation!.🔗- Supports 8 codegen tasks and 5 retrieval sources.- Canonical document annotation for all coding problems.- Robust evaluation of retrieval and end-to-end execution
0
2
19
We train a decoder-only Transformer using a causal-masking training objective (from CM3, , so the model learns to generate files in arbitrary orderings. This teaches it many code tasks: docstring generation, type prediction, variable renaming, etc. (2/n)

2
1
17
Looking forward to the lineup of talks, papers, and panel discussions at tomorrow (Friday)'s ALVR workshop on language grounding (images, video, embodied control. ): . Program: .Papers: Zoom link: #NAACL2021.
0
6
16
Unlike past work, our model's training data consists of only permissively licensed code from online sources: GitHub, GitLab, and StackOverflow. We focus on Python and JavaScript, but include 28 languages in total. (3/n)

2
0
15
Being a postdoc with Mike at FAIR was awesome!.

Jason Weston and I are looking to co-host a postdoc at FAIR! The topic is flexible within NLP as long as everyone's excited. Apply at:
0
1
15

Send us your papers on underspecified / implicit / ambiguous / pragmatic language! First deadline: December 18th.
📢The third💡UnImplicit💡 workshop on Understanding Implicit and Underspecified Language will be collocated with EACL 2024 in Malta! .Co-organized with @alisawuffles @sandropezzelle @EliasEskin @dan_fried.Submission deadline: 18th of Dec.Website:
0
3
14
Work with awesome collaborators @ArmenAgha, @realJessyLin, @sidawxyz, @Eric_Wallace_, @fredahshi, @ZhongRuiqi, @scottyih, @LukeZettlemoyer, and @ml_perception at @MetaAI, @BerkeleyNLP, and @TTIC_Connect (10/n).
1
0
13
JY's latest work finds that the freeze-and-fuse approach also works with LLMs and image generation models (here, OPT-6.7B and Stable Diffusion), producing a generative model of interleaved images-and-text. It's trainable using only image captioning data, in 2 days on 2 GPUs.
Excited to share GILL🐟 — a method to fuse LLMs with image encoder and decoder models!. GILL is one of the first approaches capable of conditioning on interleaved image-text inputs to generate image-text outputs. Paper: Website:

0
2
11
Chen's work shows real risks to multimodal web agents: up to ~75% of the time, an adversary can subvert a SOTA agent to carry out adversarial behavior (e.g. choosing a targeted product, leaving a positive review) just by making small changes to a single image in a webpage.

GPT-4V/Gemini is now used to build autonomous multimodal agents 🤖, but can you trust them to shop for you? Our latest work reveals new safety risks in these agents. We show that attackers can manipulate agents to repeatedly execute targeted adversarial goals (e.g., always
0
1
12
@DanielKhashabi @jhuclsp Re: code models, might be out of scope but I really like these two HCI papers on Copilot: . Complement the GitHub study nicely, and maybe have general takeaways for interacting with LLMs.
1
1
12
Lots to explore further here, e.g., iterative decoding, fine-tuning the model, and interactive code generation via editing & language. Looking forward to seeing what people do with the model :) (9/n).
1
0
10
@xwang_lk I hear some groups set hard internal deadlines 1 or even 2 weeks before. Or collaborate with a company that does this 😅.
3
0
9
And at the @vigilworkshop today from 3-3:45p PT, @_rodolfocorona_ and I will give a talk showing how modularity improves neural systems for embodied instruction following and grounded collaborative dialogue, covering work in @trevordarrell's and the @BerkeleyNLP group. #NAACL2021.
0
1
10
One of my favorite parts of Zora's work here shows that the functions induced by her method make programs easier and faster for humans to verify! Tasks include Table and Visual QA.
Do you find LM-written programs too complex to understand?.Do bugs often pop up in these solutions?. Check out *TroVE*, a training-free method to create accurate, concise, and verifiable solutions by inducing tools.🔗:
0
1
9
InCoder can insert text at arbitrary locations in a file, which lets us tackle many use cases in a zero-shot manner, e.g., 1) rewriting regions of code, (4/n)


1
0
9
@ryandcotterell @xtimv Generative cons. parsing needs big beams - we went up to 2000 in and didn't do larger because it was too slow, but performance was still increasing. Mitchell would have code for the Choe and Charniak system, and RNNG is here:
0
0
9
This is today! 8:30am-5pm Pacific. Excited for our papers, speakers, and breakout discussions! . Schedule: .Room: 701 Clallum at NAACL.Virtual: #NAACL2022.
We are looking forward to an exciting line-up of invited speakers at the UnImplicit workshop #NAACL2022 . @complingy @meanwhileina @dan_fried @TalitaAnthonio @microth @rtsarfaty @yoavgo
0
2
9
@yoavgo I also like @jacobandreas's discussion of semantics vs pragmatics in neural reps in Section 4 of
2
0
9


And (through infilling and StackOverflow training) 5) zero-shot language-guided interactive code editing. See our paper ( and appendix for many more examples! (8/n)

1
0
8

Standard likelihood-based and ppl-based reranking for code generation actually degenerates as the # of samples increases. Tianyi's approach (MMI-like) fixes this: consistent, often large gains across six datasets and seven models. Easy to implement with prompting!.

🧑💻Code review is an important practice in software development. We take this idea into code generation and propose Coder-Reviewer reranking. Our method reranks via the product of a coder model p(code|instruction) and a reviewer model p(instruction|code).

0
2
8
Saujas's work on interactive program synthesis uses pragmatic reasoning (amortizing RSA into a base seq2seq model) to substantially improve interactions with people, *without* using any training data from people.

Neural program synthesizers usually interpret examples literally – finding a program that’s just consistent with the given examples. However, users informatively select examples to illustrate a desired program. How can synthesizers make use of this informativity?

0
0
7
Cool work by Hyunwoo Kim et al. at #ICLR2020's #BAICS2020 on using computational pragmatics (RSA) to make persona-based dialogue systems more consistent:

0
3
7
Our assignments: And lots of amazing looking teaching resources from other folks at the workshop too!
1
2
7
@hllo_wrld I'm curious how much of this is due to the contrastive training of CLIP and gets fixed by richer text reps (Image, Parti?). There was a thread on this but I'm having trouble finding now.
1
0
7
@yoavgo I'm sympathetic to the view that you can view (types of) semantics as pragmatics with the context (that produces pragmatics) "marginalized" out. I think a lack of semantics-equivalent reps might make generalization to other types of context hard.
2
0
7
@moyix For computing perplexity/loss, people do all of these. Performance will generally be best the more overlap in the chunks, but big losses in efficiency. One approach is to use disjoint chunks for a fast eval (e.g. during training) and max overlaps (context len - 1) for final evals.
2
0
6
Vote for workshops you'd like to see at EACL-ACL-EMNLP-NAACL! We're proposing the 2nd Advances in Language and Vision workshop, We've got a great set of speakers and will solicit a breadth of work in NLP and CV. You can vote here:

We are organizing the 𝟐𝐧𝐝 𝐖𝐨𝐫𝐤𝐬𝐡𝐨𝐩 𝐨𝐧 𝐀𝐝𝐯𝐚𝐧𝐜𝐞𝐬 𝐢𝐧 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐚𝐧𝐝 𝐕𝐢𝐬𝐢𝐨𝐧 𝐑𝐞𝐬𝐞𝐚𝐫𝐜𝐡 (𝐀𝐋𝐕𝐑 𝟐𝟎𝟐𝟏) and have a Stella list of confirmed speakers: Vote if you are interested!

0
2
6
I had a lot of fun working on this with @NickATomlin, @_jennhu, @996roma , and @aidanematzadeh --- and thanks to many more folks for discussions and feedback (see the acknowledgments)!.
0
0
6
@davidschlangen For several embodied language datasets (R2R, IQA, EQA), @_jessethomason_ et al found baselines can do surprisingly well without vision (or language!): And we found similar results even for (at the time) SOTA VLN models on R2R:
2
0
5
This is a series of work led by @kohjingyu, together with @rsalakhu , @rclo8103, Lawrence Jang, Vikram Duvvur, @mingchonglim, Po-Yu Huang, @gneubig, @shuyanzhxyc, and @McaleerStephen . Benchmarks: .Search methods:
0
0
5
@EugeneVinitsky My go to is often rejection sampling if the constraint usually isn't violated, or use a stop token if constraint expressible as one (e.g. period or other ending punct). More generally, constrained decoding (, but hard to implement on top of GPT-3 API.
1
1
5
I love the task design! Really nice work by @futsaludy et al. on designing and working with Turkers to elicit language with complex referential generation and interpretation, inference, and planning. Useful ref. annotations too:
1
1
5
@jacobandreas @gneubig @sidawxyz @futurulus This one from McDowell and Goodman at ACL this year is also exciting: learn a neural base semantics while training through the RSA procedure
0
0
5
@universeinanegg I think you can do these with models trained with the causal-masked objective from and although you wouldn't get (possibly beneficial) model combination effects since the forward and backward LM are the same model.
1
0
4
@shaneguML @FelixHill84 @tallinzen @_jasonwei @kchonyc @Cambridge_Uni And looks like it was 2014 - I found the email announcement :).
0
0
4
@shaneguML @FelixHill84 @tallinzen @_jasonwei @kchonyc @Cambridge_Uni I remember a question about whether the attention mechanism was like a soft version of one of the IBM models (it was a good question I think!).
1
0
4
@jacobandreas @yoavgo @yoavartzi This is my view too, although I'd add that even with modern LMs, to use them well (for pragmatic goals!) it matters a lot whether the LM can explicitly condition on a context or not. I see a lot of modern methods (e.g. controllable gen, RLHF) as trying to surface these latents.
1
0
4
0
0
4
@WenhuChen @suchenzang These requirements seem low to me -- when we've run recently we typically do 98% accept rate and >5000 (or sometimes > 10000) accepted jobs, and in my experience even this is often not enough to get quality annotations (often need a separate qualification job too).
1
0
4
@zacharylipton @MSFTResearch @SCSatCMU Thanks this means a lot! Really looking forward to it. We'll have to see if your experience still trumps my age in racquetball too.
0
0
4

We take a task-oriented approach to categorizing context (common knowledge, discourse, the visual and embodied world…) and pragmatic roles (resolving ambiguity, forming conventions…). Our categories complement classic linguistic taxonomies. (3/).
1
0
3
Lots of room for improvement on this task! I suspect better visual representations (e.g. object or pose-centric) would help a lot, and allow more expressive models of task structure. Would be interesting to pursue connections to script induction and skill/option discovery. (4/4).
0
0
3
This is an awesome and pedagogical (and fun!) tutorial -- lots of cool connections too for folks who have worked on semantic parsing or code generation.
want to get into program synthesis but don't know how to started? I wrote a minimalist intro to modern program synthesis that can help you -- from problem formulation to generating code by fine-tuning llm on huggingface.
0
1
3
0
0
3
The setting is OneCommon (Udagawa & Aizawa '19, 20): a two-player dialogue game, where each player sees some part of an underlying board with dots, but doesn’t know what the other player can see. They have to talk to each other to discover and agree on one dot they both share.
1
0
3