

Leandro von Werra
@lvwerra
Followers
8K
Following
5K
Media
298
Statuses
2K
Machine learning @huggingface: co-lead of @bigcodeproject and maintainer of TRL.
Bern, Switzerland
Joined March 2019
Super proud of what the @BigCodeProject community achieved. Building the best in class code LLMs in an open and collaborative way is no easy feat and is the result of the hard work of many community members!.

Introducing: StarCoder2 and The Stack v2 ⭐️. StarCoder2 is trained with a 16k token context and repo-level information for 4T+ tokens. All built on The Stack v2 - the largest code dataset with 900B+ tokens. All code, data and models are fully open!.

3
13
78
Jupyter Agents - LLMs running data analysis directly in a notebook!. The agent can load data, execute code, plot results and following your guidance and ideas!. A very natural way to collaborate with an LLM over data and it's just scratching the surface of what's possible soon!
44
438
2K
Evaluation is one of the most important aspects of ML but today’s evaluation landscape is scattered and undocumented which makes evaluation unnecessarily hard. For that reason we are excited to release 🤗 Evaluate!. Let’s take a tour:

12
330
2K
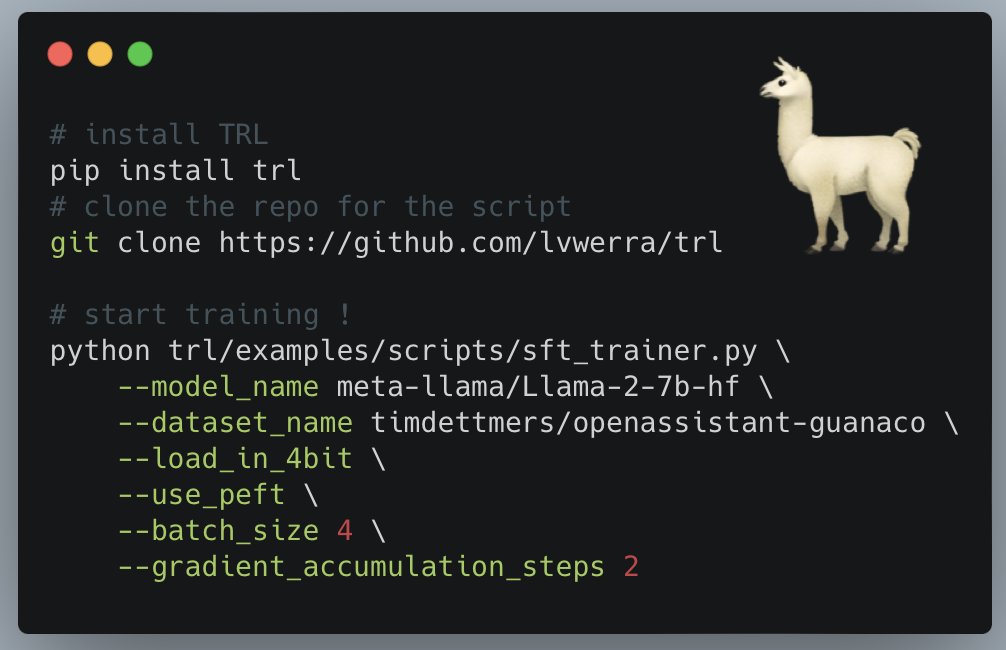
Did you know that you can train all Llama-2 models on your own data in just a few lines?. The script even works with the 70B model on a single A100 GPU thanks to the magic of 4bit and and PEFT!. Learn more: Full script:
18
274
1K
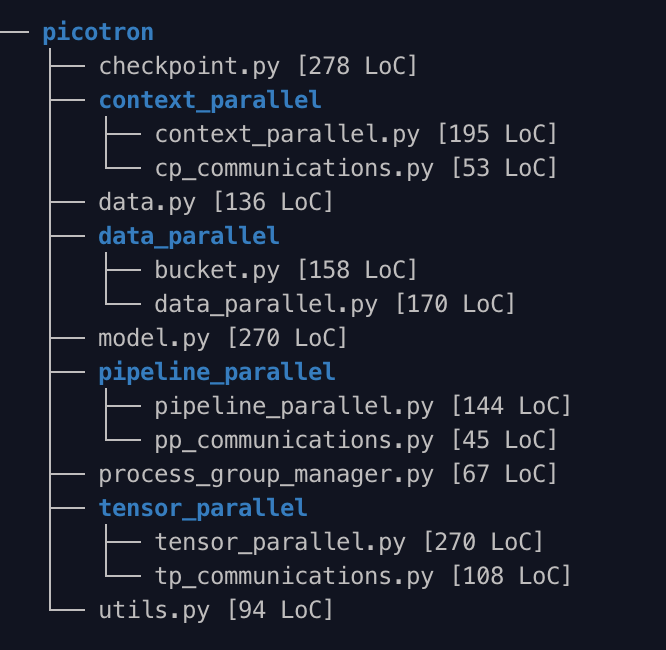
Distributed training is notoriously hard to learn - knowledge is scattered across papers and complex codebases. Enter picotron: implementing all 4D parallelism concepts in separate, readable files totaling just 1988 LoC!
7
183
1K
Our book "Natural Language Processing with Transformers: Building Language Applications with Hugging Face" can now be preordered!. This thread gives an overview of what you can expect by summarizing the content of each chapter:

19
173
1K
Excited to introduce: StackLlama🦙. An end-to-end tutorial for training Llama with RLHF on preference data such as the StackExchange questions!. Blog: Demo: Code: The resulting model is surprisingly fun!🧵

23
222
881

Can we create all the code for training GitHub CoPilot in a (looong) tweet thread? Yes, see how to train CodeParrot🦜, a large GPT-2 model for code, from scratch in this thread! Ready - go!
8
111
539
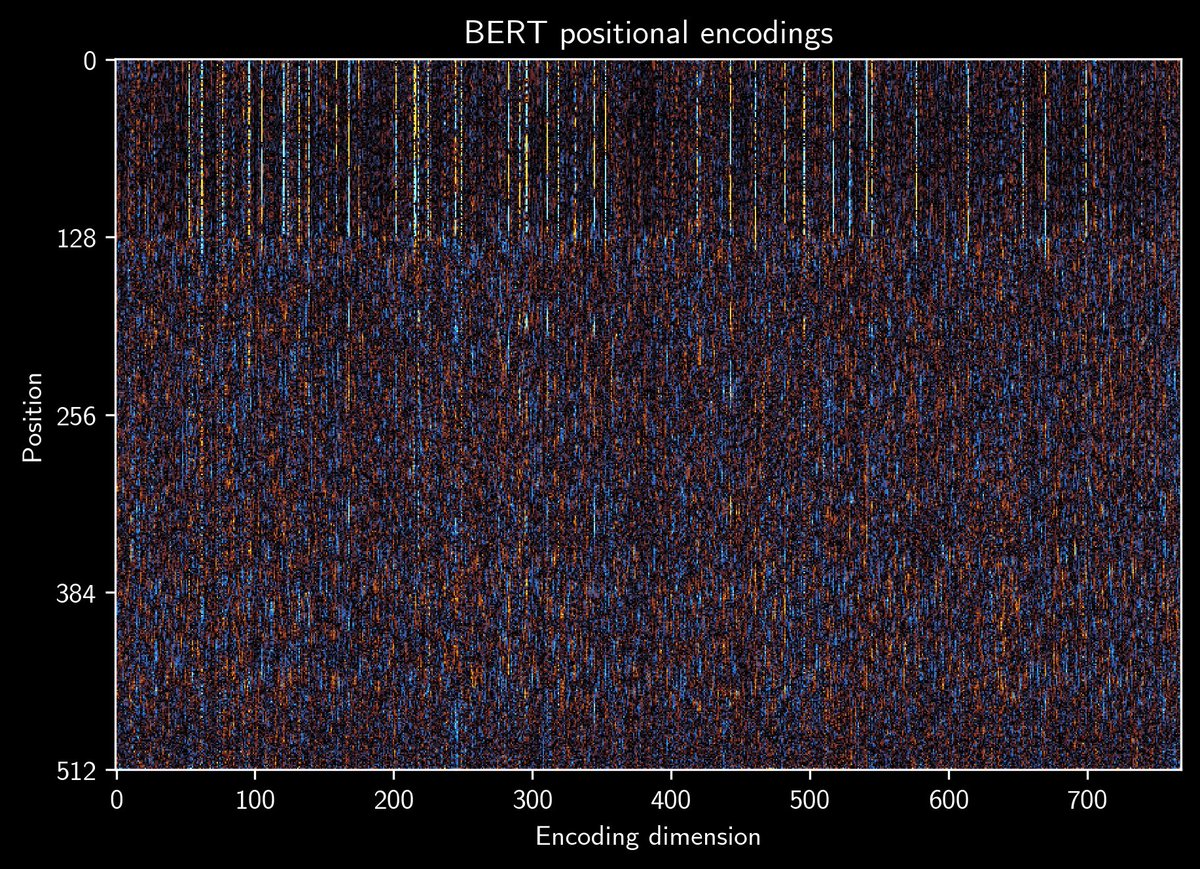
How do models like GPT-2 and BERT represent position of tokens? When visualizing their positional encodings I found an interesting pattern. A short thread:

8
81
517
solving problems using BERT that can be solved by a RegEx is another level of skill issue.

solving problems using LLMs that can be solved by fine-tuning BERT is a skill issue.
14
33
508
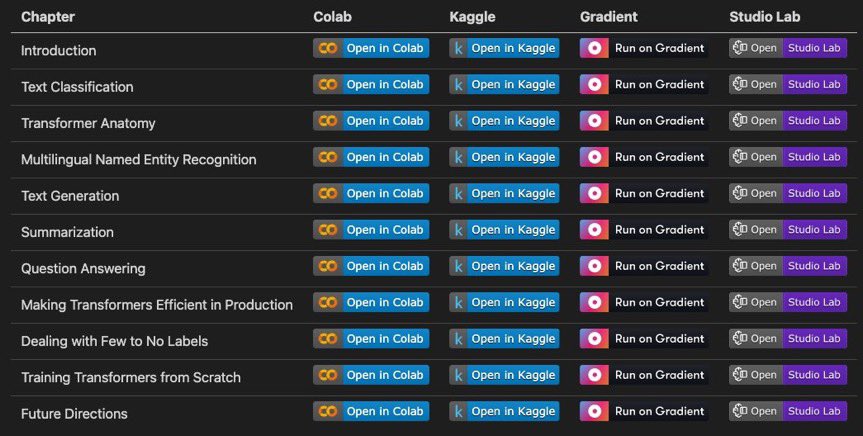
Thanks to @_lewtun all chapters from our book "NLP with Transformers" are now just one click away!. And you can run them on your favourite platform: . - @Google Colab.- @kaggle Notebooks.- @HelloPaperspace Gradient.- @awscloud StudioLab. #transformersbook
3
111
480




Training large (transformer) models can be challenging and sooner or later a big red "CUDA out of memory" slaps you in the face. But there are a few things one can do to scale model training. We updated the docs and in this thread I cover the main tricks:.

7
75
428
The research team at Hugging Face shipped in 2024! 🚢. How? Small teams, big ambitions and a sprinkle of compute. With the goal to do great open science we released models, datasets, tools, educational blogs and more!. A recap:

5
91
440
I built my first python package: jupyterplot! Plot real-time results in Jupyter notebooks. It is founded on @andreas_madsen's excellent python-lrcurve library. Effortless development and publishing with #nbdev by @jeremyphoward and @GuggerSylvain.
7
103
408
Recently, we have been working on preparing a large code dataset for pretraining a large language model - a project we call CodeParrot 🦜. This is a thread about the challenges we faced when creating such a large corpus.

8
64
386
Excited to share my quarantine work of the past couple of weeks: The Transformer Reinforcement Learning (trl) library. Train @huggingface transformer language models with sparse rewards via reinforcement learning (PPO).

4
72
357
The Falcon 🦅 has landed in the 🤗 ecosystem! . Make the most of these truly open source models that stormed to the top of the LLM leaderboard. We show how to host them locally or via endpoints, and how you can fine-tune them on a Colab GPU!. Check it out:
7
87
360
@EugeneVinitsky You could upload it to the Hugging Face Hub, which is free to host and download. It also adds a dataset viewer if it's any common format/modality, but it's git-lfs under the hood so you can upload whatever files format you want. You can either use the `datasets` or.
4
8
366

Companies are currently deciding whether to invest in fine-tuning their own open LLMs (e.g. Llama 2) or to use closed LLMs via an API (e.g. Claude or GPT4). Of course, you can build quick & cheap prototypes with closed LLMs, but fine-tuning on high quality domain data is cheaper

8
64
340
A very underrated architecture tweak to GPT is multi-query attention (MQA): sharing value/key across attention heads saves a lot of memory in the kv-cache. Max generation batch size on a Colab GPU with a 1B model:❗️512❗️ vs 32 (vanilla GPT). Test it here:
7
70
337
Finally upgraded my MacBook to an M1 (Max). I was curious if I could use the GPU to train a Transformer model. TL;DR: It works and training DistilberBERT is roughly 2.5x faster than the K80 you usually get on Colab and 50% slower than a V100! . (Installation steps below)

6
33
331
Excited to finally share what kept us up at night for the past few months: . Natural Language Processing with Transformers. A book about building real-world applications with 🤗 transformers in collaboration with @_lewtun, @Thom_Wolf, and @OReillyMedia.

8
77
326
How does a company called Hugging Face make money?. Your best wrong answers only to celebrate the 1000th time the question was asked 🎉.
103
15
322
Anybody can train a custom Mistral model on their own dataset in just a few lines of code with TRL! 🚀. The SFTTrainer supports DeepSpeed for distributed training or PEFT if you are limited by GPU resources. TRL: Full script:

3
71
317
Recently, AlphaCode was released: a large language model pretrained on a GitHub dataset with a dozen programming languages. We release a similar (but larger!) dataset on the Hugging Face Hub! A thread on how to use it and two nice features of the Hub:.
6
73
297
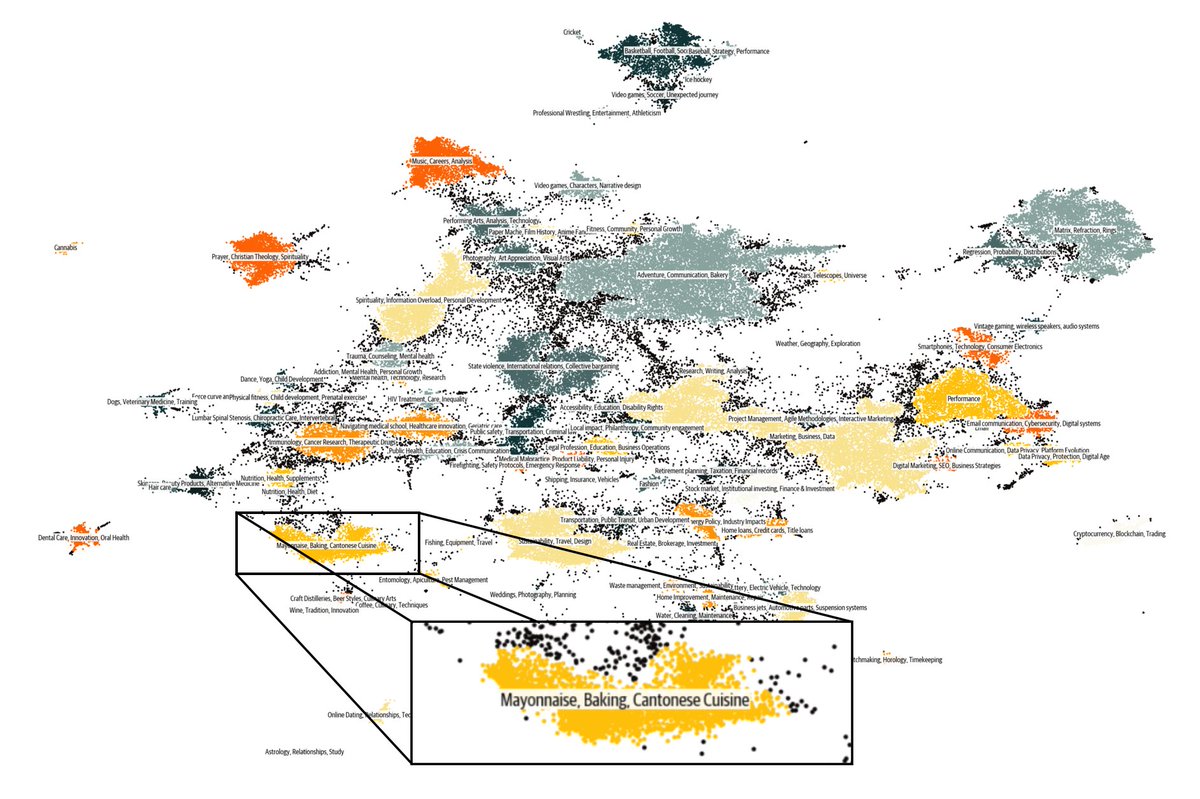
Text clustering at home? Yes, with text-clustering, a tiny smol repo:. The pipeline is fully built on open tools:.1⃣embed with sentence-transformers.2⃣project to 2d with UMAP.3⃣run DBSCAN clustering.4⃣label clusters with Mixtral. Runs in 5-10min and tada:
10
44
280
SmolLM2 is here!💥. The strongest 1B model and matching models twice the size such as Gemma-2, Qwen2.5 or Llama3.2. Huge effort from a smol team going toe-to-toe with the biggest tech labs in the world. and fully open!

4
43
280
Training language models with reinforcement learning and human feedback has gained more traction with InstructGPT, GopherCite, or the latest research from Anthropic. With TRL you can, too! Happy to release TRL 0.1.0 with some major improvments! 🎉🎉🎉.
5
58
261
Great news: The Zephyr team releases the Alignment Handbook! 🎉. It includes the full code to fine-tune your own models with their success recipe and builds on top of TRL. Along with it the required models and datasets are also released!🔥. Check it out:.
6
47
259
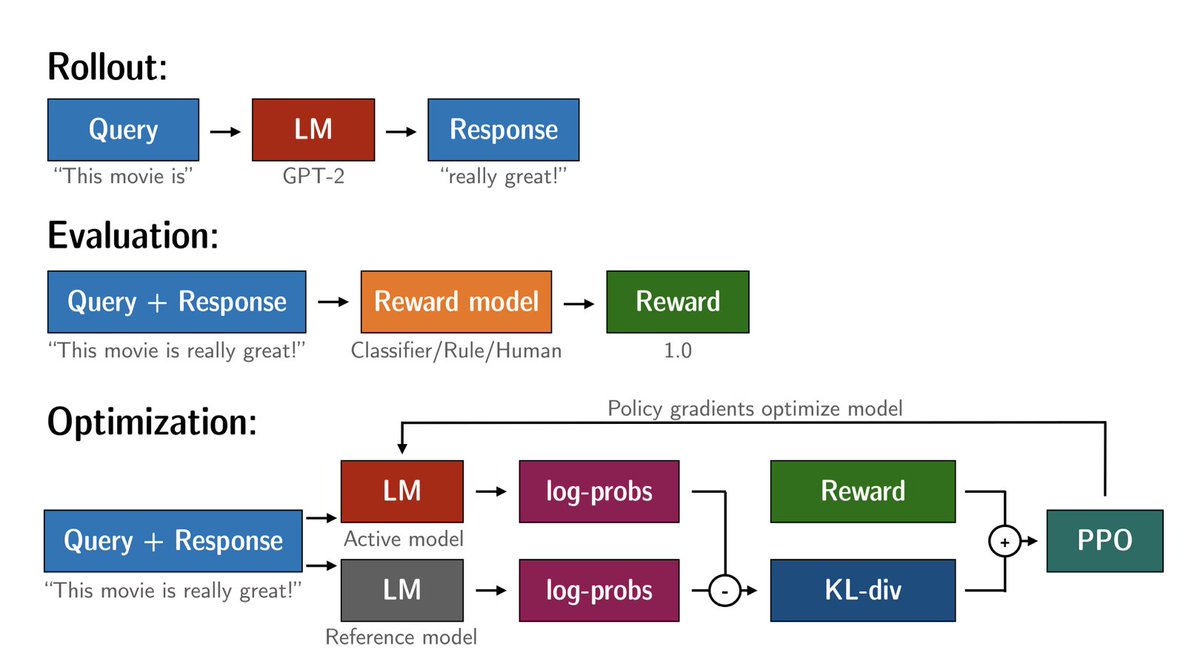
With the ChatGPT wave rolling over twitter I also want to celebrate that the TRL library crossed 500 stars⭐️🎉. If you want to play with reinforcement learning for language models (the tech behind ChatGPT) yourself checkout the repo&library:.
4
40
247
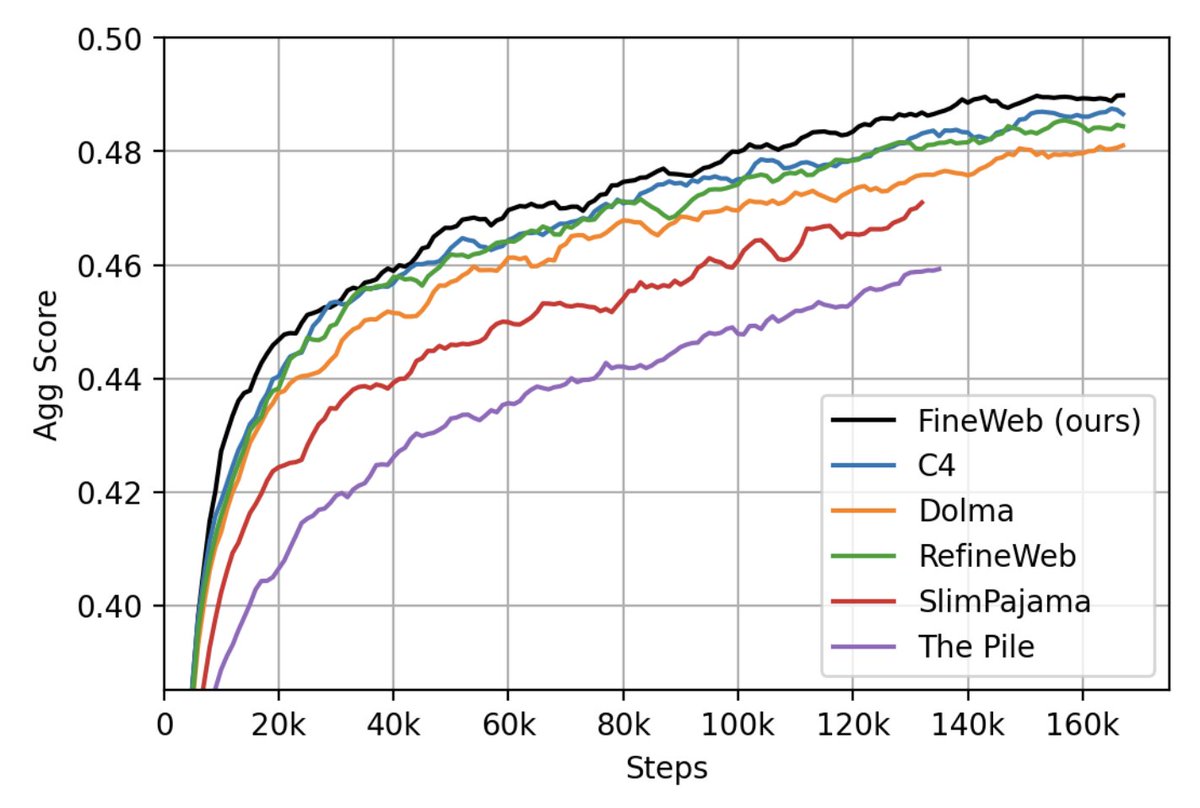
We released 🍷FineWeb: 15T high quality tokens from the web. It's the best ready-to-use AND the largest pretraining dataset. Outperforms all other datasets in our 350B token ablations but scales to much longer training runs due to its sheer size!.


We have just released 🍷 FineWeb: 15 trillion tokens of high quality web data. We filtered and deduplicated all CommonCrawl between 2013 and 2024. Models trained on FineWeb outperform RefinedWeb, C4, DolmaV1.6, The Pile and SlimPajama!
3
52
240
Is the complicated RL part in RLHF really necessary for fine-tuning LLMs on human preference data? The new DPO method challenges that view!. DPO is now integrated into TRL and we used it to train StackLlama-2!. Read more about it in the blog post:.
7
55
203
Google releases Gemma: a state-of-the-art 2B and a 7B model trained for 2T and 6T tokens respectively! 🚀. They release both a base and an instruction tuned model which can be used for commercial applications. You can fine-tune it in just a few lines:

2
30
193
Releasing TRL==0.2.0! 🚀. Training language models with RL (e.g RLHF) is now easier than ever:. New accelerate backend (multi-GPU support!), support for decoder and encoder-decoder models, weight sharing, shiny new docs (and logo), reworked examples!. 🧵:

5
44
189
Not much is known about the pretraining data of Code Llama but there is some good evidence the @StackOverflow was part of it. Found some breadcrumbs while working on a demo with a hello world example: Suddenly the model started generating a discussion between two users.

8
42
179
Tokenizing 200k texts with @huggingface‘s FastTokenizers: <20s. Drawback: not enough time to get a fresh coffee 🙂.
4
19
171
Why would any company release a strong LLM for free? . This is @ServiceNow (mkt cap ~$160Bn) stock price since the release of StarCoder. Only required a small amount of compute and a handful of people while building up a lot of valuable know-how fast. It's not a zero-sum game!
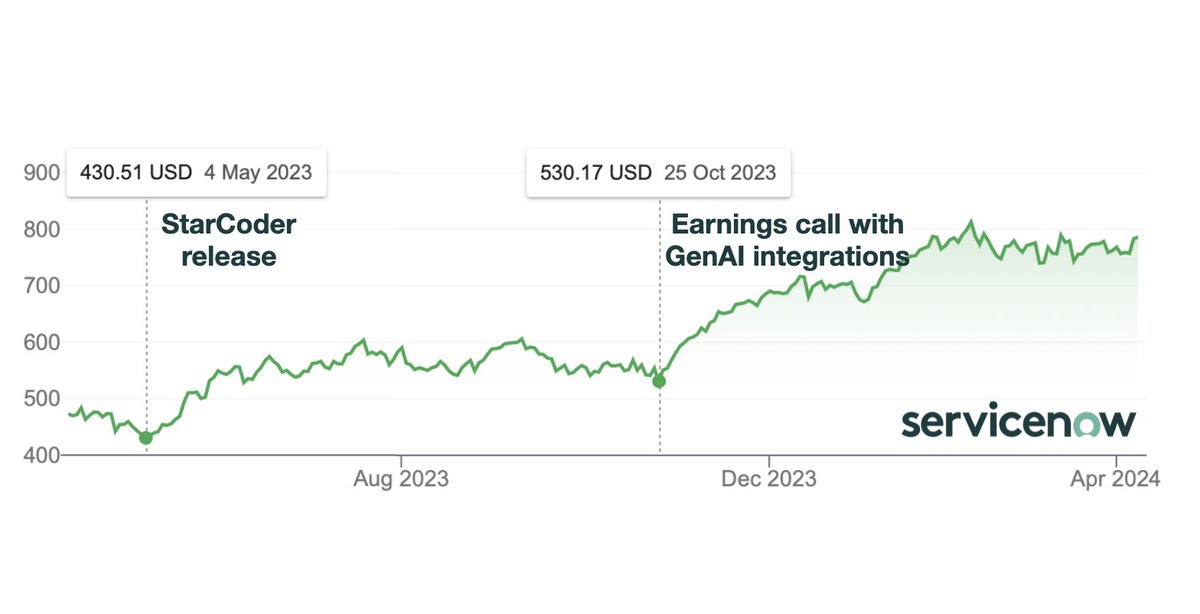
9
30
163
Finding the right code snippet solving your problem is a super useful skill. @novoselrok made this much easier with a new tool: And on top he wrote an excellent in-depth guide to how to build a search model with transformers:.

0
40
161
Working with nbdev ( is such a great experience!. Finally breaking the cycle of starting to code in notebooks, then exporting the code to a library, and finally writing documentation. Awesome job @jeremyphoward & @GuggerSylvain!.
2
27
168
Sharing data with 🤗datasets has recently become a matter of a few lines. Here's an example where Alice shares some interesting data with Bob via the 🤗 Hub. 👩💻-->🤗-->👨💻. Since 🤗datasets also works with Pandas this is a great way to share your favourite DataFrames.

5
27
160
Introducing TextEnvironments in TRL 0.7.0! . With TextEnvironments you can teach your language models to use tools to solve tasks more reliably. We trained models to use Wiki search and Python to answer trivia and math questions!. Let's have a look how🧵

7
36
166
Nemotron-340B was trained on 768x8 H100s. What this actually looks like: each square is a GPU and each color block highlights a model instance. The model was trained with TP=8, PP=12, DP=64 (shades indicate PP stages) such that one model instance requires 96 GPUs.

4
26
147
One of the most interesting aspects of code generation models such as Codex or CodeParrot🦜 is the evaluation. Metrics such as BLEU or ROUGE metrics don't work well for that task. Let's see why and then build an evaluation script in the process!

2
19
129
With NEFTune you can boost the performance of supervised fine-tuning, especially on noisy instruction datasets! . We added NEFTTune to TRL so you can use it with just one additional line in the SFTTrainer:

3
33
128
With the release of ChatGPT we thought it is a good time to write a blog explaining how RL from human feedback works and what the current state of this exciting new field is. Collaboration with @natolambert and @carperai folks @lcastricato and @Dahoas1.
1
31
125
Training language models like CodeParrot🦜requires a large datasets. After first training experiments with CodeParrot🦜we realized that duplicates in the dataset had a strong impact on performance. Let's see what it takes to deduplicate a large (~200GB) dataset with🤗datasets.

2
21
125
Checkout the code and super detailed video walkthrough!. Code: Video: Work lead by @Haojun_Zhao14 and @FerdinandMom!.
1
25
126
Or watch how the model solves the Lokta-Volterra equation and plots the results and refines them. Try it out:
5
22
124
The full pipeline from processing web scale datasets to pretraining and evaluating LLMs on large GPU clusters is now possible in probably <1000 LoC 🚀. In the last few weeks we released three libraries that we hope will enable everyone to build amazing datasets and strong LLMs!

4
22
114
It's beautiful to see how far you can get with a 360M model (5x smaller than GPT-2!) with a few tricks:. - curate the pretraining data for educational content.- choose well tuned hyperparameters.- and latest: add simple conversations to the SFT mix. Result: 🤏SmolLM
3
23
114
Meta Llama3 is out - almost identical architecture as Llama2 but trained for. 15 trillion tokens!🚀. Chatting with the instruct model or fine-tuning the base model on a custom dataset is as easy as one command!. Read more about it in the blog post:

2
24
109
A few weeks back @harmdevries77 released an interesting analysis (go smol, or go home!) of scaling laws which @karpathy coined the Chinchilla trap. A quick thread on when to deviate left or right from the Chinchilla optimal point and the implications.🧵

1
27
107
Falcon 180B model was just released: it beats Llama 2 as well as ChatGPT and is on on par with Palm2-L 💪. It trained on 3.5T tokens on 4k GPUs totalling in 4x the compute of Llama 2 🔥. Blog: Model: Demo:

3
17
106
With today's release of 🤗Evaluate (0.2.0) we are adding three more evaluators (QA, NER, Image classification). This make it a matter of a few lines of code to evaluate any (model, dataset, metric) triplet🎉. Really excited about this! Let's take a tour!

2
20
104
It's been a wild year part 1: TRL went from a pet project to train transformer with PPO to 7k stars with 100+ contributors!. Now there is also SFT, DPO, IPO, DDPO (diffusion!), and with PEFT and accelerate you can both train on small hardware and at any large scale. 🚀🚀🚀

5
17
107
One frequent feedback we get on the paper version of our book is that color would add to the reading experience. We invested a lot of time to create the figures and thanks to @OReillyMedia we released ALL of them in the book's repository. A thread with a few of my favourites:

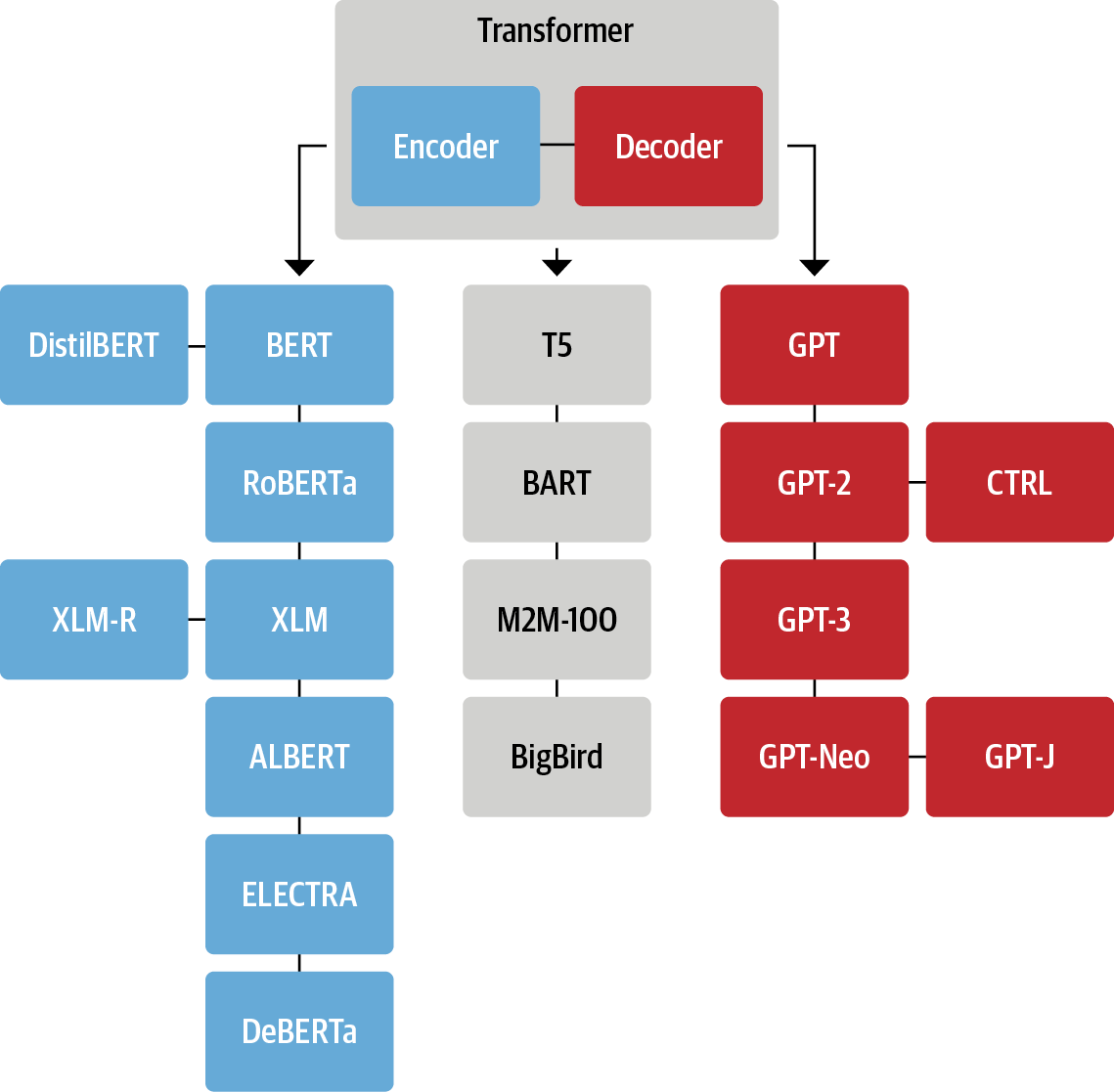


2
18
102
We are hosting a reading group on Discord about how to apply transformers to your use-cases and how to participate in open-source!🤓. Every two weeks we go through chapters of the Transformers book and discuss how to contribute to open-source. Join here:

2
18
105
I had a blast last Wednesday at the RL Meetup Zürich talking about leveraging the @huggingface transformer library in combination with reinforcement learning to fine-tune language models. In case you are interested the talk is now online:.
5
25
99
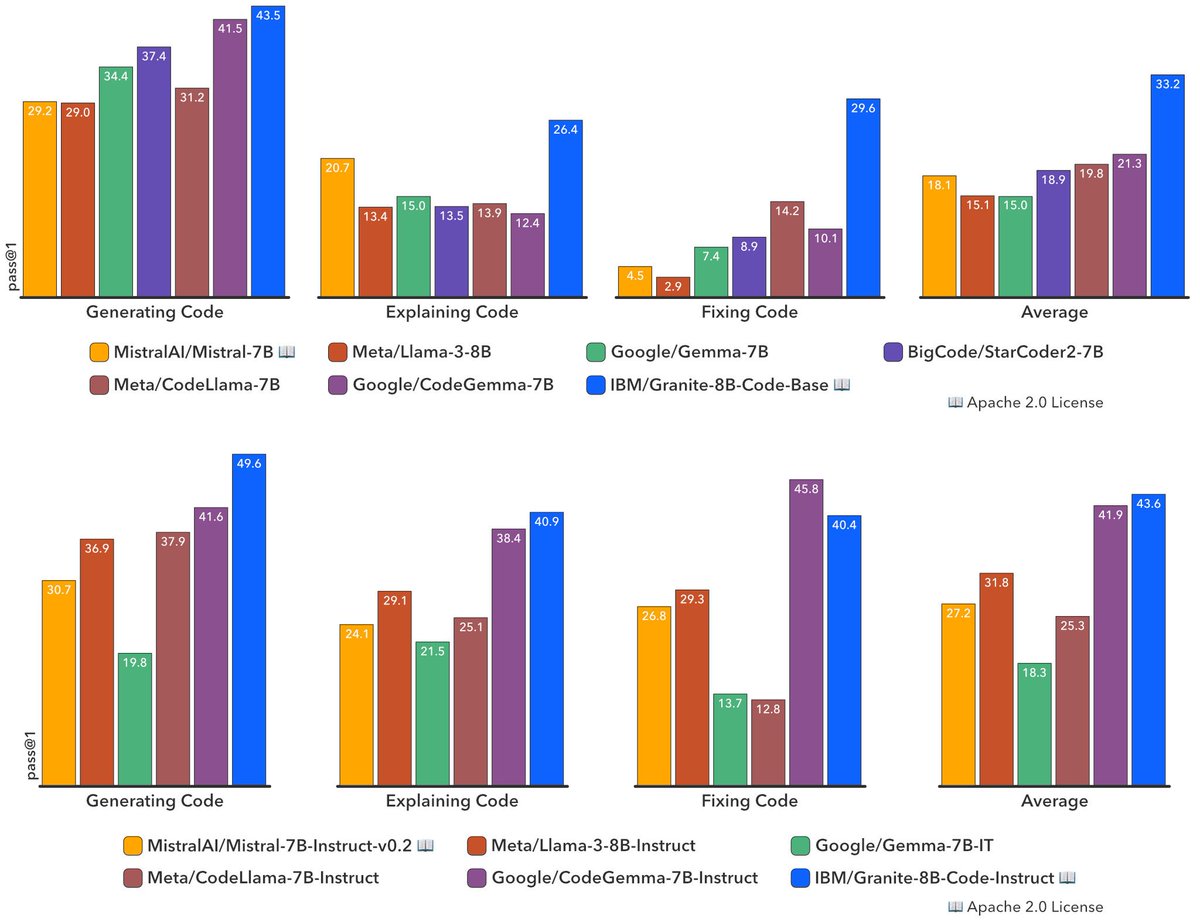
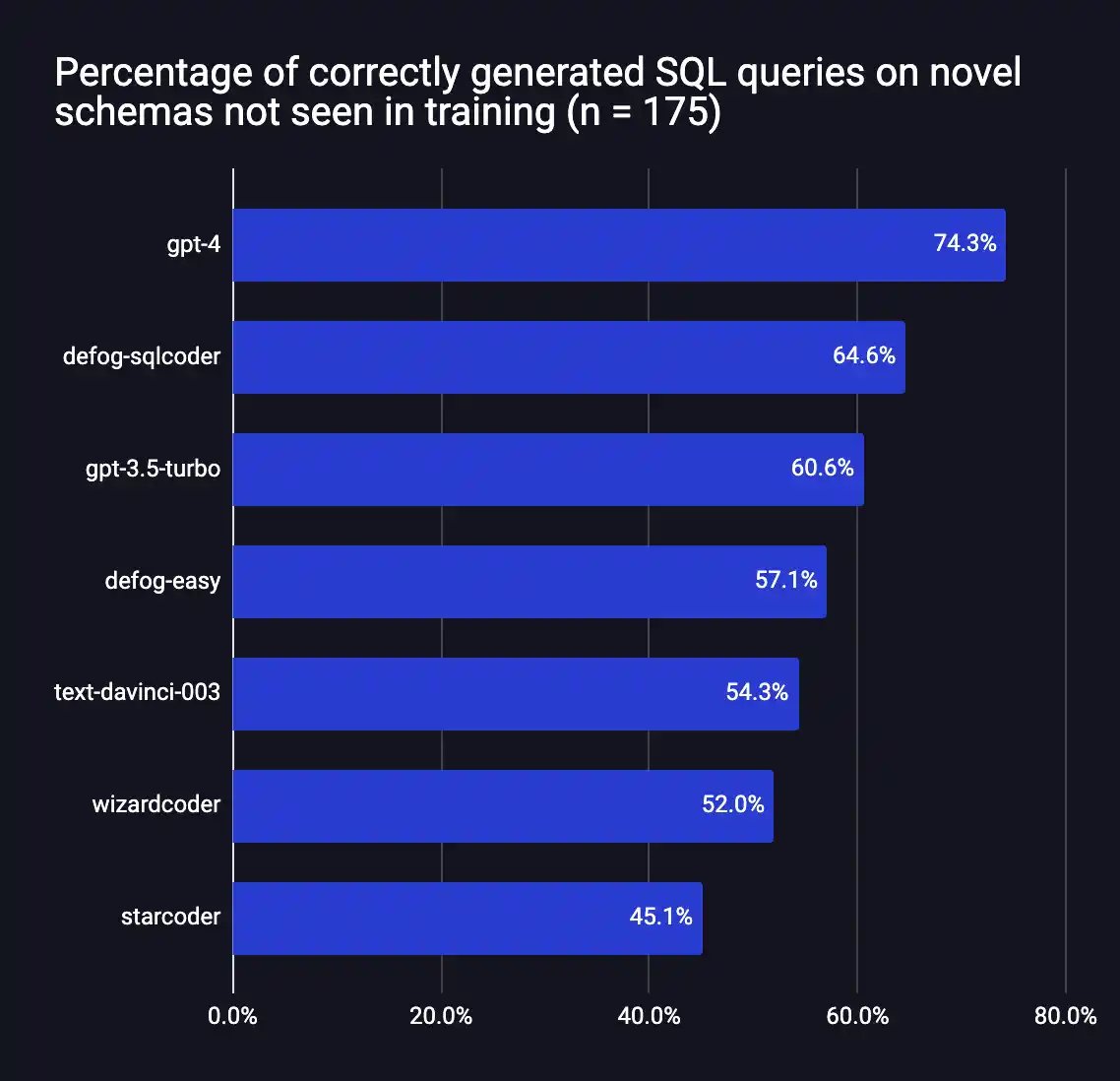
The code family is expanding extremely fast: Welcome SQLCoder!. Since I made this graphic two weeks ago there have been three new awesome code models. @deci_ai's small and powerful DeciCoder, @Muennighoff et al's OctoCoder trained on commits and now @defogdata's SQLCoder🚀


We just open-sourced SQL Coder, a 15B param text-to-SQL model that outperforms OpenAI's gpt-3.5! When fine-tuned on an individual schema, it outperforms gpt-4. The model is small enough to run on a single A100 40GB in 16 bit floats, or on a single
1
17
96
The power of building tools, datasets, and models in the open: the community can build on top of it and everyone profits! . Exhibit A: since the release of 📑The Stack and ⭐️StarCoder research groups from academia and industry have trained models on top BigCode's releases.
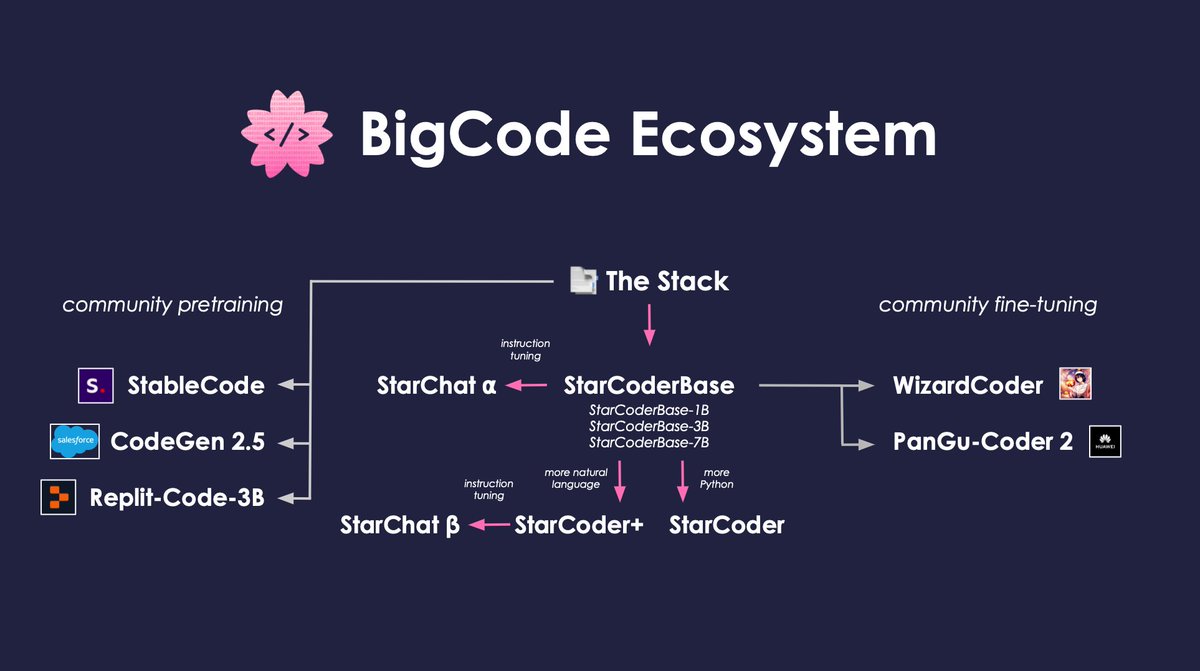
2
25
86
Our book about NLP with Transformers is taking shape and we are working on the final chapters. We would love to know what you want to see covered in the book. If you had to choose one topic that the currently available resources don't cover well what would it be? Let us know!.
Excited to finally share what kept us up at night for the past few months: . Natural Language Processing with Transformers. A book about building real-world applications with 🤗 transformers in collaboration with @_lewtun, @Thom_Wolf, and @OReillyMedia.
5
14
85
There is an incredible Chrome extension by @JiaLi52524397 that let's you use StarCoder in Jupyter Notebooks. It uses previous cells and their outputs to make predictions. As such it can infer your DataFrames columns from the cell outputs or interpret your markdown text!


Proud to be part of this incredible journey with @LoubnaBenAllal1, @lvwerra & the amazing team! 🎉 StartCoder has this unique capacity to incorporate jupyter text/output. Experience it for yourself here: Or
2
21
78
We released evaluate==0.3.0🎉🎉🎉. A few highlights:.- text2text evaluators (incl. translation and summarization)!.- new bias metrics!.- configure dataset splits and subsests in the evaluator!. Special thanks to contributors @mathemakitten & @SashaMTL♥️

0
17
75
The FineWeb tech report is out!🍷. Find all the details involved in building a high quality pretraining dataset for LLMs including the new super strong FineWeb-Edu subset with 1.3T tokens. [built with the beautiful @distillpub template by @ch402 et al]

2
13
77
Excited to announce that trl has a new home: . 🚀. It started as a pet project a few years ago and recently became much more active with so many contributors. With the transfer we'll move full steam ahead to make RL and RLFH more accessible for everyone!

0
14
73
This week's release of 💫StarCoder was the culmination of 6month incredibly hard work from a lot of collaborators in @BigCodeProject. It's great to see people are enjoying it and already using it for various things. It is also in fine company among trending models on the Hub!

1
10
71

Took some time to reflect on the past 1+year of the @BigCodeProject: Here are a few of my learnings from leading it during this time and some ingredients I think are important for a successful open collaboration in ML. What is BigCode?.BigCode is an open scientific collaboration.
1
18
69
Turns out you can also use the trl library to tune GPT-2 to generate negative movie reviews 😈. Experiment by @mrm8488 and model available on @huggingface models.
2
15
66
The closed models via API vs. developing in-house models discussion is reminiscent of the situation with software a few decades ago: buy off the shelf products or hire developers to build custom software. These days every large company is either a software company or at least.
1
12
61
One consequence of the plot is that as you go left you need to pay with data but gain inference efficiency and as you go right you gain data efficiency but pay with inference cost. For example at the critical model size (1/3 model size, 100% overhead) you need 6x more data! 🧵.

There is a fascinating recent trend of training *smaller models for longer* w.r.t. Chinchilla optimal predictions. Best explanation I've seen of this? This new blog post by @harm_devries (with collaborators of the @BigCodeProject):. Clearly these are only

3
7
64
We are releasing CodeParrot🦜 v1.1! We trained the original model for an additional 30k steps and observe continuous improvement on HumanEval. The model has now seen 40B code tokens which is still far off the 300B+100B of Codex and the 590B of AlphaCode.

3
14
59
I am really excited to see that @OpenAI keeps pushing AI safety at the interface of NLP and RL using human feedback. If you want to take a @huggingface transformer model for a spin check out the TRL library.

We've used reinforcement learning from human feedback to train language models for summarization. The resulting models produce better summaries than 10x larger models trained only with supervised learning:
1
20
61
Slides here: Inspired by the nice talk from @Thom_Wolf earlier this year and updated with some material we are working on right now:.
0
9
60
In my opinion one of the most underappreciated features of the 🤗Hub is that you can add model performance metrics to the model card by simply adding tags to the model's Readme that even links to @paperswithcode🤯. Check out an example here:

0
15
60
The wild part is seeing a Google tutorial of the project that you worked on in a public library to get into NLP a few years ago.

Join Googler Wietse Venema for a deep dive into fine-tuning open models using Hugging Face Transformer Reinforcement Learning (TRL) using GKE. TRL is an #OpenSource library that provides all the tools you need to train LLMs, developed by @huggingface ↓
4
3
58
Eventful day: Evaluation on the Hub launched, CodeGen released in Transformers, and BLOOM model training reaches 100% 🔥.
1
2
55
Working on the index of the upcoming transformers for NLP book I've realised that we come across:. 45 model architectures.29 datasets.11 evaluation metrics. I did not expect that many - maybe we went a bit overboard😂 By the way you can now preorder it at:

2
7
57

Have you ever played Taboo but ran out of cards or wanted to create custom cards? Look no further!. I have fine-tuned @OpenAI's GPT2 with the great @huggingface library to generate new Taboo cards. A few handpicked examples (none of them are in the training set):


2
15
53
Roughly 10% of BLOOMs training data has been code. So it is pretty good at coding🙂. Since it is multilingual you can even prompt it in arabic!


Pretty cool!! 0.155 Pass@1 is also pretty cool for a non-explicit code model.
2
13
55
Something oddly satisfying about running . `. , num_proc=60)`. and watching the CPU go brrr for 10min (rather than waiting 10h)

7
4
53
Just bumped the github-code dataset to v1.1! . Changes:.- add Scala and TypeScript.- fix issue with deduplication pipeline. Also added some high level statistics of the dataset. A short thread about the deduplication bug and Python hashing:

5
6
48
I often think about this quote from Jonathan Ive: . “When our tools are broken, we feel broken. And when somebody fixes one, we feel a tiny bit more whole.”. This is so true for software. Using great tools makes every project way more fun and feels like having superpowers.

1
7
48
Who needs a Random Number Generator if you can just try to render a Jupyter notebook on GitHub?.
2
1
45
Models trained on public code should be open!. Software Heritage released a statement on training code LLMs on their database with 3 principles:. 1. Resulting models should be open.2. Transparency and attribution for training data.3. Opt-out mechanism.
0
11
45
It's been a wild year part 2: Just before the start of the year with @BigCodeProject we released The Stack and started training StarCoder. And this was just the starting point for many community projects that built cool models on top of it! . There is more to come very soon! 👀

1
9
45
If you are curious in what it takes to train a large language model on such a dataset checkout the Transformer book. CodeParrot 🦜 has a dedicated chapter!. It will come out in early 2022 but you can already access it in the early release (online):
1
3
45
With Reinforcement Learning from Human Feedback one can tune language models to better align with what humans expect. You can use the same technique to also condition language models to create positive or negative comments about movies (or switch)! .

5
9
46
„With four parameters I can fit an elephant, and with 175bn I can make him write front-end code.“.- John von Neumann (2020).
0
2
44
Next week I'll be at NeurIPS! It's the first time I'll go to a big ML conference - any tips and tricks?. Also message me if you'd like to meet and grab a coffee!.
6
1
45