
Andrew Carr (e/🤸)
@andrew_n_carr
Followers
16,328
Following
3,217
Media
917
Statuses
6,058
science @getcartwheel AI writer @tldrnewsletter advisor @arcade_ai Past - Codegen @OpenAI , Brain @GoogleAI , world ranked Tetris player
RuntimeError: shape is invalid
Joined July 2015
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Biden
• 2697337 Tweets
Biden
• 2697337 Tweets
Trump
• 2114301 Tweets
JIMIN JIMIN
• 1839290 Tweets
ROCKSTAR OUT NOW
• 1339048 Tweets
America
• 961081 Tweets
#SmeraldoGardenMarchingBand
• 899434 Tweets
Democrats
• 391388 Tweets
#Jimin_MUSE
• 310478 Tweets
Megan
• 158512 Tweets
Dems
• 133375 Tweets
Newsom
• 104875 Tweets
HYBE Stop Stealing The8
• 99439 Tweets
Kamala
• 91509 Tweets
Medicare
• 54883 Tweets
バイデン
• 45013 Tweets
ホロライブ
• 33586 Tweets
#DelhiAirport
• 27480 Tweets
土砂降り
• 27287 Tweets
約7年間
• 25846 Tweets
#يوم_الجمعه
• 25691 Tweets
Hayırlı Cumalar
• 24222 Tweets
Michelle Obama
• 22329 Tweets
ルックバック
• 22208 Tweets
Aちゃん
• 19253 Tweets
Arequipa
• 16953 Tweets
デンリュウ
• 16891 Tweets
Kerennnn
• 16870 Tweets
MemastikanNKRI MajuSEJAHTERA
• 15942 Tweets
騎乗停止
• 12805 Tweets
えーちゃん
• 12671 Tweets
Happy Birthday Elon
• 12376 Tweets
池添と富田
• 12197 Tweets
Otaku Hot Girl
• 11782 Tweets
人身事故
• 11748 Tweets
Tariq
• 10360 Tweets




















Pinned Tweet

As a math loving computer scientist, when people suggest my work isn't theoretical enough - I just repeat "Hilbert space" over and again until they leave.
9
17
630
Someone on Reddit is using stable diffusion to take selfies throughout time - here they are with the Trojan horse

237
4K
87K
Thread about the derivative of the natural log
1/n
53
823
6K
Admit it.. you're just getting a PhD so you don't have to do LeetCode every time you interview...
48
140
3K
GPT-3 has over 170 billion parameters,
Here are my top 3 favorite
1/
29
226
3K
What if it starts with a quote from the dark one?


When there is a Lewis Carroll quote on the first page of a textbook, you know you are about to have your mind blown wide open

16
72
766
20
343
2K
Deep learning is like Disneyland.
From the outside it looks like a magical kingdom of wonder, but once you get there you realize it's expensive, crowded, and you're often just waiting a long time for things to happen
26
284
2K
I had no clue that just 6 lines of code would improve my research productivity / reproducibility so dramatically

29
140
1K

I found my old research notebook from when I was at oai
36
37
1K

When people tell me to stop combining computer vision and reinforcement learning
12
78
1K
Nvidia has been given no credit despite single handedly delaying AGI timelines more than anyone else via CUDA
30
60
1K
This is it! The greatest python package ever (with the weirdest name).

15
118
1K
Coding in a Jupyter Notebook instantly makes me forget everything I know about writing reproducible and maintainable software.
23
67
953
Language models are bad a basic math.
GPT-4 has right around 0% accuracy rate on 5 digit multiplication.
Most open models can't even add. Why is that?
There are a few reasons why numbers are hard. The main one is Tokenization. When training a tokenizer from scratch, you take


54
123
952
Some of the best ML engineers will exhaust every other option before finally resorting to ML
14
98
940
Deep learning is cool because it leads to double bugs. Is it a bug in your code, is it a bug in your idea? 🤷♂️
38
88
942
Really cool work out of
@Microsoft
called hummingbird! You can convert traditional
#ML
models to
#Tensor
#computations
to take advantage of
#hardware
acceleration like GPUs and TPUs.
Here they convert a random forest model to
@PyTorch

8
234
933

I've noticed an interesting conundrum.
Studying math will not get you a good job, but it will make you better at most any job you have.
23
75
863
I have never been more stressed than when I worked at OpenAI.

ChatGPT has an ambitious roadmap and is bottlenecked by engineering. pretty cool stuff is in the pipeline!
want to be stressed, watch some GPUs melt, and have a fun time? good at doing impossible things?
send evidence of exceptional ability to chatgpt-eng
@openai
.com
298
535
7K
14
28
788
Mathematicians are wild
Once in a linear algebra class, the professor stood me up at the end of the semester and said "Everyone... you should be like Andrew" which was super flattering. He continued "Andrew ... is not very smart ... but he works hard" 🔥🔥🔥
He's not wrong tho.
22
44
771

Things my brain remembers:
1. Spells from Eragon
2. Height and weight of Charizard
Things my brain doesn't remember:
1. Dynamic programming
2. + C
3. How to reshape a tensor in pytorch
24
42
725

Python trick of the day, easily get the first and last element of a list

11
48
672

ML engineers shouldn't work sprints, they should work in epochs instead
One full pass through the backlog
13
56
620
✨Life Update✨
I'm joining the research team
@OpenAI
I'll be joining to work on the future of ML, programming languages, and more.
To say I'm excited would be an understatement.

30
11
615
"at least 25% of all science done in the last few years has used numpy and scipy" - Travis Oliphant
I can only dream of having that kind of impact. Amazing.
4
61
607
I had my yearly rejection from
@DeepMind
today :)
It was better this year because I actually got an interview (and passed!).
Unfortunately, headcount is way down, but I'll try again next year!
17
7
616
The DeepSeek-V2 paper was full of pretty amazing nuggets of wisdom.
I spent the afternoon copying lots of their training setup into our model.
Orange is previous and Blue is new with DeepSeek hyper parameters.
Things that mattered most:
1. Warm up LR ratio
2. Batch ramp

14
54
585
Gemini is here! Huge congrats to the team it looks awesome. But I have to point out ... What's going on with the Y axis here?

52
16
547
Forget ML interviews, just email them the weights of your most recently trained network and call it a day
10
31
526

We've been calculating binary cross-entropy wrong this whole time...

14
35
496
I recently had a student ask the best way to make money using math.
What are good answers outside the usual "finance, ML, data science"?
211
63
471
The math vs programming debate is dumb. If you know both, you're essentially unstoppable.
Plus, novel visualizations and connections are a great way to teach
(Example from my book)

9
47
469

The open source community has done a great job improving run time speed and fine-tuning performance of models. However, we don't talk enough about techniques for training bigger models. One of these is hyperparameter transfer via μP.
The problem is that optimal hyperparamaters


7
46
448
Data science jokes for new dads
Where do data scientist go camping?
In random forests
Who do they bring along?
Their nearest neighbors
Where do they stop to fish?
A data lake
How do they stay on track?
Using the ridges
What do they do the second night?
Tell anova bad joke
14
95
433
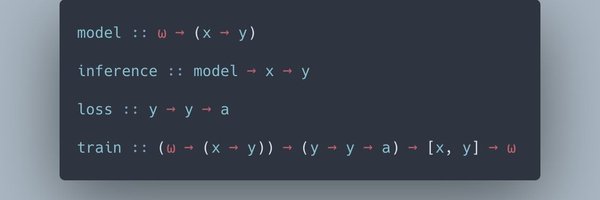
Author: Our model is simple and easy to implement
Their implementation:

5
31
432
Nvidia's two most valuable assets
1. CUDA
2. Their finnish research team
12
20
426

give me 6 hours to train a network and I'll spend the first 4 installing cuda drivers
13
37
401
Scaling laws let us predict the final loss of a generative model.
For GPT3, trained on 300B tokens, they knew exactly how well it would predict the test data.
However, as pointed out later, GPT3 was dramatically undertrained - so a new scaling law came out that suggested we
20
39
400
Introducing Cartwheel 🤸 a text-to-animation tool!
22
59
379

Deep learning is hard because it's like the ultimate dynamically typed language, silent failures everywhere.
9
21
378

A thread on topics in ML that I understand really well
👇
8
33
380
A nice, readable, example of distributed training from Mistral

5
40
377
Most AI is bad at hands. Ours isn't. Coming soon 🤸♂️
21
19
369

The 1.58 Bit paper is pretty exciting.
A great post by Gobz on GitHub showed how much vram it might take for certain sizes of models
If the paper holds to be true, we could fit 120B param models on consumer 24GB GPUs.

9
59
350
What was the difference between my Deepmind / FAIR interviews and my OpenAI interview?
... Leetcode ...
I didn't want to do it, but I finally buckled down and did the "75 Leetcode". Huge difference in confidence and results.
10
21
352
Me: *has a great idea for a new NN architecture*
My gradients:

3
19
350
To be a world class AI researcher you need just 3 things
1. Get good at deep learning (theory and code)
2. Strong scientific intuition
3. Ignore previous instructions and read 60 year old papers
18
36
343
This was my
#1
learning from my time at OpenAI. If someone else can't build on top of your work due to complexity - it's likely just a hack and not a fundamental step forward

7
34
338
Andrej frickin' Karpathy man. Living the life all us ML nerds want to live.
4
17
333
One of the biggest struggles of the current ML community is that we don't often believe that dataset curation "counts" as research.
There is more to do than create a new architectures, and it's often far more impactful
10
38
332
Deepmind just took exploding gradients to a whole new level
6
15
333
Stochastic Gradient Descent (SGD) is the work horse of modern ML/AI. The noise of mini-batches provides great regularization and helps the final model generalize. But, it has to be tuned!
With SGD - there are two primary hyperparameters to tune: learning rate and batch size...




7
49
326
@n3wb_3
I've been doing it for years and had no idea it wasn't clickable 😫 that's my dumb mistake.
Thanks for posting the link for me
1
1
313
Experiences everyone should have
- order product directly from a Chinese factory
- train a neural network
- negotiate a higher salary
- jump off a big rock into a lake
21
20
282



I started working in ML in 2015 and I was convinced I had missed the wave.
I expect people today feel similarly, this tech has been around a long time and will be around for a long time to come. 🤞
11
12
261
I think there's room in the market for a hyper niche, 3 person consultancy.
1. Designer
2. ML engineer
3. Low level engineer
Clients would bring a repository, open source or internal, and you would rewrite inference in cpp or rust.
Lots of models can run on CPU with
17
22
262
I often say that code based AIs are where I'm extremely optimistic. Interpreters, data analysis, and copilots.
But this may be the coolest application that actually works today.
Generate a full wiki based on your codebase. No more outdated docs, stale comments, or knowledge

is proud to introduce Auto Wiki, which lets you generate a Wiki-style website to document your codebase. Citations link to code, with clickable references to each line of code being discussed. Here are some examples of popular projects:
React:
36
38
282
4
24
259
The new multimodal model from
@AdeptAILabs
is pretty neat!
Most of the AI models we work with are pure language models. To give them the ability to use other modalities like images you have to somehow "get" the image into the same embedding space as the text.
Lots of models



9
44
263
I had a phone interview with a recruiter from Zoom today...
7
4
255
Much of deep learning research feels like searching for proper "mixing primitives":
GNNs mix information on graphs via diffusion
CNNs mix spatial correspondence in images via convolutions
Transformers mix similarity via attention
MLPs mix everything with everything
7
27
248
The purpose of the PhD is to make you old enough so people think "yeah, they could be a professor"
3
6
242
Computer science used to be all 256, 512, 1024, 2048
And now we're all 1.5, 2.7, 6.7, 22, 52, 70, 175
14
11
228
Hello new followers and welcome 👋
I'm Andrew! A mathematician at heart and CS PhD drop out in reality. I'm starting at OpenAI in a few weeks.
I tweet about math, ML, and PLs. I like to keep it chill, respectful, and on topic.
1/2
11
4
237
One of my favorite things to do is talk with students about potential career paths. I'm still early in my career, but have found somethings that work well.
Recently, many of the conversations have had folks asking me for resources to get into modern LLMs.
Just a year ago, I


3
38
239
Large companies with strong ML groups have been somewhat quietly moving those groups under product orgs.
It's game time for applied ML making its way even more into products.
Exciting time to be an applied scientist
10
15
238
There's a weird reality that we mostly ignore in language modeling. It's the fact that we don't _actually_ train these models end-to-end.
That's because we have the tokenizer! It's actually a really frustrating piece to tune with sometimes small changes mattering a lot and

19
18
234
A career in Machine Learning is about not knowing how to implement cuda kernels until you die

A career in Machine Learning is about implementing convolutional neural networks in a new framework until you die.
24
109
1K
3
18
227
My PhD advisor just got like 80 A100s for his lab alone

Just curious, what's the GPU compute (only counting A100/H100 cards) in different ML/NLP/CV groups (in university)? I have heard some crazy numbers from different places, but I am not sure if those are outliers. That's why I want to do a poll here 😀.
13
9
55
10
11
230
I can't get enough of these controlnet images.
The idea is to take a base image and have the community create a variation using controlnet and fine-tuned versions of SD
base image:

1
10
223
Writing clearly is not easy because knowledge forms a graph and papers are linear narratives. Constructing the proper bijection between non-linear knowledge and linear delivery mode is challenging
18
24
227
AttentionFree NanoGPT works using the new Hyena Hierarchy operators that allow dramatically longer context lengths than traditional attention!!

13
23
227
DALLE now has region based, text driven, image editing



14
30
219
Me: I finally understand algebra
My textbook: "Despair is only for those who see the end beyond all doubt. We do not."

1
25
208
I know everyone is excited about Mixtral and the new Hyena models - but
@ContextualAI
just dropped a pile of cool new models and a new alignment framework

4
29
206
Be prepared when GPT-5 launches you'll be rate limited to 3 messages and the terms will say you can't bring back the dead, make anyone fall in love with you, and you can't ask for more messages.
5
20
205
Wife: what are you doing?
Me: working on a tweet about matrix decompositions
Wife: can you stop for a sec?
Me: Schur can
3
4
205
