

Orhan Firat
@orf_bnw
Followers
2K
Following
3K
Media
13
Statuses
299
Research Scientist at Google DeepMind
New York
Joined August 2010
🎉👏! this made me feel sentimental- was almost gonna dropout of phd after the 2nd time this got rejected! I was so fortunate to have mentors like @kchonyc and Yoshua convincing me otherwise, and ofc collaborators like @caglarml and @imkelvinxu ambitiously pushing this forward 🥹.

well :) 5 years too late but still happy to receive the best research paper award cc @orf_bnw @caglarml @imkelvinxu

3
11
179
And in a few hours, I will be discussing Gemini’s multilingual capabilities at MRL @mrl2023_emnlp #EMNLP2023 . I will trace our path from M4, PaLM, PaLM 2, and Gemini through the lens of multilinguality; share some lessons learned and open problems. Exciting!.

Are you excited like us for our workshop tomorrow? We hope you are. Check out the updated schedule on our website with location details and full list of papers:
3
8
93
♊️Gemini 1.0 is here 🚀- polymath and polyglot LLM! . Proud to be part of this amazing team!.

I’m very excited to share our work on Gemini today! Gemini is a family of multimodal models that demonstrate really strong capabilities across the image, audio, video, and text domains. Our most-capable model, Gemini Ultra, advances the state of the art in 30 of 32 benchmarks,


6
3
74
Thrilled to be @#ICML2022 in person! ⬇️ Some work we will be presenting around large language models: 1⃣understanding scaling properties under different architecture biases,2⃣ interplay b/w data/noise/architecture and 3⃣ efficient in-context learning w/ sparse models (GLaM-1.2T).
1
3
69
Do massively multilingual translation models (M4) generalize to cross-lingual downstream tasks? Check out Poster #218 today #AAAI2020. Presented by @asiddhant1 with the awesome team Melvin Johnson, @naveenariva, Jason Riesa, @ankurbpn.Paper Poster 👇1/2

2
13
53
Summary of our recent work on multilingual NMT. We mainly studied scaling up the models on two axes simultaneously: number of languages and the size of the neural networks. Several artifacts along the way: . .

New research demonstrates how a model for multilingual #MachineTranslation of 100+ languages trained with a single massive #NeuralNetwork significantly improves performance on both low- and high-resource language translation. Read all about it at:
1
6
45
More on confluencing unsupervised and multilingual MT. Great work with the awesome team: @xgarcia238, @ank_parikh , @adisid01, @Foret_p, @ThiboIbo of @GoogleResearch, #GoogleAI. (1/3).

Check out our multilingual unsupervised translation work! Theory + SOTA results. Led by @xgarcia238 (1/4). 1. Multilingual View of Unsupervised MT - Findings of EMNLP 2020 (). 2. Multilingual Unsupervised MT for Rare Languages ()

1
7
37
First step towards "bit/pixel level", end-to-end neural machine translation. Led by awesome @elmanmansimov and Mitchell Stern @GoogleAI . Let's see where does vision end and language start, or is there even a distinction between the two? Exciting times ahead 🙃.

During summer 2019, together with Mitchell, @orf_bnw, @MiaXuChen, Jakob & Puneet at Google, we worked on an ambitious way of tackling in-image translation (translate text in the image and generate the same image with translated text) using the end-to-end neural approach. [1/2].
0
3
34
More on massively multilingual NMT. This time we analyze the representational similarity across languages, how they evolve across layers and how robust are they. Great analysis and intriguing results are thanks to the great work by @snehaark. More to come, very soon . 🙂.

New EMNLP paper “Investigating Multilingual NMT Representation at Scale” w/ @ankurbpn, @orf_bnw, @caswell_isaac, @naveenariva. We study transfer in massively multilingual NMT @GoogleAI from the perspective of representational similarity. Paper: 1/n
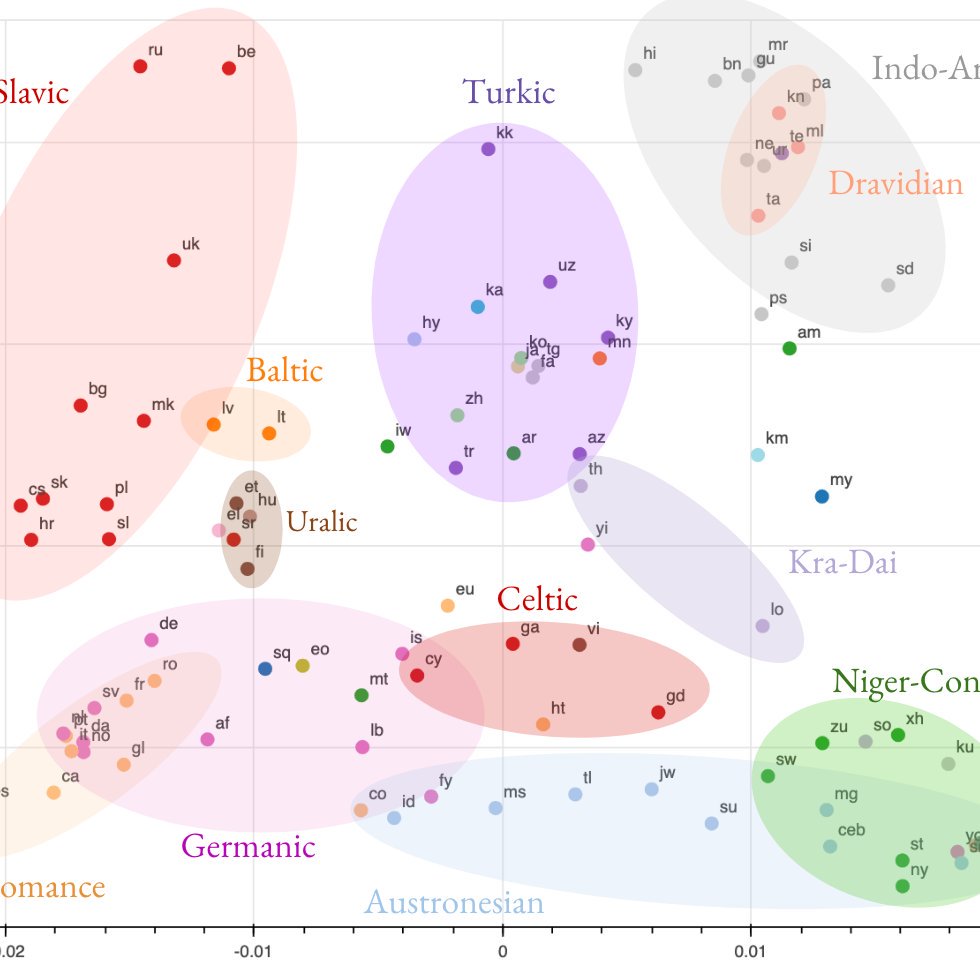
0
9
32
Today we will be hosting a Machine Translation Birds of a Feather Meetup together with @kchonyc at #ACL2021NLP @aclmeeting come say hi 🙂 at Gather Town D&I Session Room, MT Table (bottom left) - 6pm ET.
0
3
29
this!.

Shampoo is out of the bottle! . Preprint: "Second order optimization made practical". We train certain neural nets faster than before. How fast ? It has shown upto ~40% reduction in training time for a Transformer. (@tomerikoriko)

0
3
26
This time not "massively" 😅 … but, adapting Transformer for conditional computation turned out to be very effective and useful, giving us additional knobs to play with and monitor the allocation behavior at inference time . .

Is it possible to serve increasingly large models for practical applications? Please check out our latest paper on how to control the amount of computation utilized by your model at inference ->.Arxiv: with @naveenariva and @orf_bnw. 1/4.
1
2
23
Thanks for the invitation @gneubig, it was a pleasure to attend the lecture and connect with you all 🙂.

We have finished uploading our 23 class videos on Multilingual NLP: Including two really great guest lectures:.NLP for Indigenous Languages (by Pat Littell, CNRC): Universal NMT (by Orhan Firat, Google):
0
2
19

Symbiosis between unsupervised and supervised multilingual MT Join us to chat about the smoothing effect of multilingual MT, self-supervised learning to ingest monolingual data and extending MT models to new languages!. #acl2020nlp.
Please join us to chat about our #acl2020nlp work on using monolingual data to improve massively multilingual NMT, with a focus on low resource and unsupervised languages . QA session at 18:00-19:00 GMT / 14:00-15:00 EDT today. Video:
0
8
17
This is the way.

I am excited about our work on efficiently aligning language models with a reward using Reinforced Self Training (ReST). The best side is that our approach is much more efficient and easier to implement than most other alignment algorithms. See below for more on ReST🧵👇 (1/n)

0
3
15
Great contribution to extremely low-resource mt! Awesome work by @deaddarkmatter et al. 👏👏👏 congratulations 🙂.

#NLPaperAlert: Our work "How Low is Too Low? A Computational Perspective on Extremely Low-Resource Languages" with @cdli_news was accepted at ACL SRW 2021 (@acl_srw). Elated. 📖 Read here: ⭐ Star here: Thread 🔽 \1

0
2
15
#NLProc if you are working on multilingual NLP models, check out our workshop proposal at *ACL.

One of this year's new workshops: Multilingual Representation Learning aims to advance generalization and low-resource NLP by bringing together efforts in understanding and interpreting multilingual models @seb_ruder @alex_conneau @orf_bnw @gozde_gul_sahin @alexandrabirch1.
0
4
13
Great read for the holidays 😍 huge congrats to @snehaark @adityakusupati @Devvrit_Khatri and the team 👏🎉.
Late tweet, but thank you ENSLP #NeurIPS2023 for the best paper award, and @Devvrit_Khatri . for the excellent presentation on behalf of the team @adityakusupati!. Excited to push further on conditional computation for tiny fast flexible models 🚀

0
0
12
There’s also a need to highlight the importance of tools and frameworks that enable large scale research, like Tensorflow Lingvo ( and GPipe, without which this research wouldn’t have been possible.
1
1
11
awesome work by @whybansal !. practical take: "in some cases sub-optimalities in the architectures and data quality can be compensated for by adding an extra constant factor of data.".

How do different interventions to the training setup (e.g. architecture, noise) impact the data scaling laws (or sample efficiency) in NMT? Most do not affect the scaling exponent!. New work from my internship with @_ghorbani @bneyshabur & @orf_bnw! . 1/n

0
1
10
Take 1: Scaling the multilinguality of the model improves unsupervised MT performance. Take 2: In the multilingual setting, a lot of the drawbacks of unsupervised MT vanish (e.g. domain mismatch, lexical dissimilarity and varying quality of the data). (2/3).
1
1
10
Multilingual NMT is known to be very effective for low-resource languages, but comes with high-resource regression. We show what happens when we scale things up: large improvements on low-resource, with high-resource quality on-par with competitive bilingual baselines.

1
0
10
More to come especially in massively multilingual setup, very soon 🙂. (3/3).
0
0
10

2
3
10
tl;dr Massively Multilingual Translation Encoders (MMTE) are obtained as a by-product of massively multilingual MT model. MMTE excels on zero-shot transfer to low resource languages and is competitive with alternatives like mBERT (2/2).
0
1
10
The whole effort builds on top of great prior work on how to train (, how to scale (, how to schedule (, how to generalize ( and many others.
1
1
9
@surafelml @fbk_mt thanks for covering the paper and for the great thread. bit more context: paper was meant to be more of an "open-problems" paper. we are following this with a series of papers addressing each one (summary so far is here: . four down, more on the way 🙂.
1
3
8
"Share or Not? Learning to Schedule Language-Specific Capacity for Multilingual Translation" ( by @BZhangGo @ankurbpn and @RicoSennrich.
1
1
7
2⃣ "Data Scaling Laws in NMT: The Effect of Noise and Architecture".Poster: Thu 21 Jul 6:00 pm EDT.Spotlight: Thu 21 Jul 3:35 pm EDT.Paper: by amazing @whybansal and @_ghorbani et al. (more: .
Some life updates!.- I've started at Google as a Research Scientist.- I now live in NYC.- I'll be at #ICML2022 Tuesday onwards presenting this work . If you're at any of the above (or even o/w), and would like to chat about Life, ML and Everything, feel free to DM me :).
1
1
7

3⃣ "GLaM: Efficient Scaling of Language Models with Mixture-of-Experts" .Poster: Thu 21 Jul 6 pm EDT.Spotlight: Thu 21 Jul 3:30 pm EDT.Paper: by stellar Nan Du, @iamandrewdai, @bignamehyp et al. (more: .
1
1
6
"Gradient Vaccine: Investigating and Improving Multi-task Optimization in Massively Multilingual Models" ( by @MrZiruiWang, Yulia Tsvetkov and Yuan Cao.
1
0
6
@kchonyc @LiuQunMTtoDeath @tarfandy @emjotde oh wow!!! debugging zero-shot nmt at the lobby . bar hopping at temple bar . dl4mt session2 . rnns . a lot.has changed in 5 years 😶🤔😃.
0
0
4
@M2lSchool @mmbronstein @gaiarubera @MarcRanzato thank you for the invitation and organizing it in the first place 🙂.
0
0
4
Indeed studying the problem using a massive open-domain dataset has its own challenges, with the most pronounced being the heavy data imbalance across language pairs. We provide practical recipes to mitigate the issue, and exciting future directions.

1
0
5
I wouldn't miss this chance to connect with Behnam, i've been learning a lot from him!.

I'm going to try having in-person @ml_collective meetings when I’m on #workation:. I'm in #istanbul for a few weeks. If you are in #istanbul and you like to chat about AI research, career choices, travel, etc., you can book an in-person meeting here:.
0
0
5
There is still a long way to go. So expect more to come very soon 🙂.
0
0
4
@yoavgo @ehudkar @Eric_Wallace_ depth seems to be crucial for (parallel) transfer (i.e. multilingual MT), checkout last section of supplemental here:
1
0
2
The 2nd multilingual representation learning workshop ( started accepting submissions, checkout👇.
MRL is expecting your submissions! If you have your ARR reviews by the end of this week, send them to our workshop and have the chance to participate in a great event with an excellent line of speakers and meet a large community of scientists working on multilinguality.
0
2
3
0
0
3
Incredible to see cross-capability transfer at scale—the confluence of massive multilinguality, stellar reasoning, deft coding, sharp math, exceptional vision, audio, and more, all skillfully coming together and unlocking new capabilities.
0
0
3
Btw, still very much relevant to large models, tying back to “massively” 🙂 and domain/task routing.
0
0
3
This further enabled us to study the transfer capability, depth-width trade-off and trainability challenges of very deep models, on massively multilingual (massive) NMT and image classification (3/4).
1
0
3
… Very exciting direction from both efficiency and interpretability perspectives: train a single model and control its behavior depending on the available computation budget, expected quality or let the model decide itself. .
1
1
3
And if you are interested in studying LLMs empirically or theoretically; faculty/postdoc looking for a visiting position, SWE/RS/rSWE looking for a full-time position, PhD student seeking an internship, please reach out!.
0
1
3
@CohereForAI @GoogleDeepMind @ahmetustun89 Thanks for having me; it was great to meet and chat with all of you 😊🙏.
0
0
2
0
0
2
With novel batch-splitting pipeline-parallelism, GPipe achieves almost linear speedup with the number of devices and allows us to train massive neural networks to study vision and nlp problems at scale (2/4).
1
0
2
on trainability of very deep models, investigating the internal representations, cross-lingual down-stream transfer, adapting to specific languages and domains, dynamics of the transfer. .
1
0
2
@alvations @wellformedness Thanks @alvations for the mention 😊 tho not sure how innovative my definition was (emphasizing the interplay between variables in end-to-end learning). On data (X) totally agree, but formulation is challenging. Perhaps poking active learning/learning to learn in a similar vein. .
0
0
1
@elmanmansimov @awscloud @AmazonScience congrats Elman, both for your dissertation and position at Amazon 🙂 we should catch up sometime.
1
0
1
