
Yilun Du
@du_yilun
Followers
9K
Following
1K
Media
98
Statuses
405
Incoming Assistant Professor at Harvard @KempnerInst + CS. PhD @MIT_CSAIL, BS MIT. Generative Models, Compositionality, Embodied Agents, Robot Learning.
Harvard
Joined September 2012
We wrote a position paper arguing that we should construct large generative models compositionally from smaller ones!. We argue that (1) it enables data/computation efficient learning (2) it enables provable generalization to unseen test distributions.

12
63
407
Super excited to be joining Harvard as an assistant professor in Fall 2025 in @KempnerInst and Computer Science!!. I will be hiring students this upcoming cycle -- come join our quest to build the next generation of AI systems!.
166
39
2K
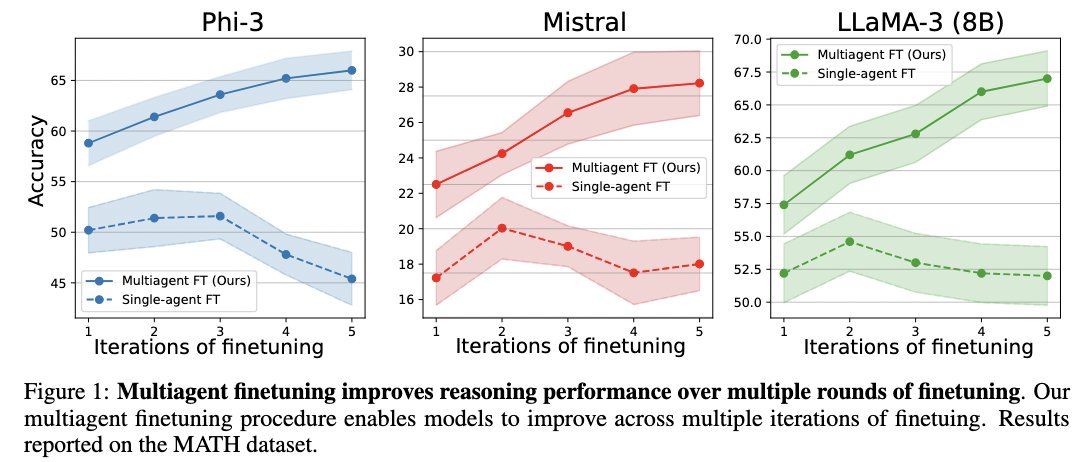
Introducing multi-agent self-improvement with LLMs!. Instead of self improving a single LLM, we self-improve a population of LLMs initialized from a base model. This enables consistent self-improvement over multiple rounds.
28
211
1K
I'm recruiting PhD students this year with interest in machine learning, embodied AI, or AI for science! . If you are interested in constructing fundamental tools to improve Generative AI and exploring how these tools can be used for intelligent embodied agents and science,.
34
164
977
Introducing Decision Diffuser, a conditional diffusion model that outperforms offline RL across standard benchmarks – using only generative modeling training! Decision Diffusers can also combine multiple constraints and skills at test-time. Website:. 1/5
15
134
870
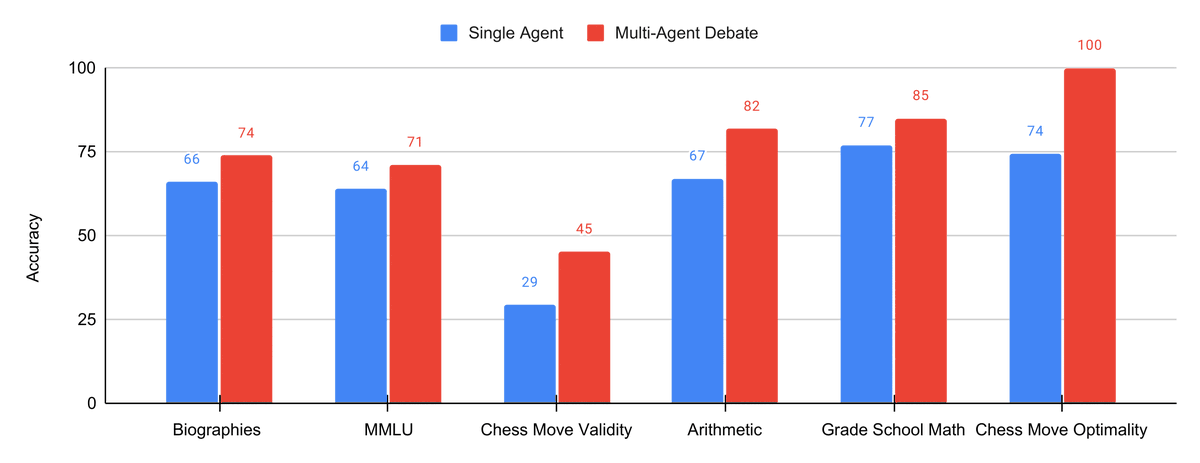
Our new paper on introducing multi-agent debate as means improve the reasoning and factual accuracy of large language models!. Multiple instances of a language model debate with each other over multiple rounds to reach an improved shared answer. (1/5)
20
110
600
Introducing our @icml_conf paper: Learning Iterative Reasoning through Energy Diffusion! . We formulate reasoning as optimizing a sequence of energy landscapes. This enables us to solve harder problems at test time with more complex optimization. Website:.
7
96
598
(1/6). How can we learn to iteratively reason about the problems in the world? In our #ICML2022 paper, we introduce an approach towards iterative reasoning based off energy minimization : . Website: w/ @ShuangL13799063 Josh Tenenbaum @IMordatch
7
75
468
Introducing Streaming Diffusion Policy (SDP)!. SDP allows you to generate actions using a single denoising step, with no distillation!. SDP keeps an action buffer of partially denoised future actions, which is refined over time. Led by @sigmundhh
4
65
427
Monday (March 28th) at 4PM EST @OriolVinyalsML (@DeepMind) will give a in person talk at the @MIT_CSAIL Embodied Intelligence seminar about The Deep Learning Toolbox: From AlphaFold to AlphaCode! Check it out in person in 34-101 and the livestream at:.

8
69
384
Introducing Video Language Planning!. By planning across the space of generated videos/language, we can synthesize long-horizon video plans and solve much longer horizon tasks than existing baseline (such as RT-2 and PALM-E). (1/5)
7
48
289
Excited to share the launch of Pika 1.0! I've been working on some research projects with the team, and its such a talented, ambitious, and amazing group of people! Super recommend checking out! :).

Introducing Pika 1.0, the idea-to-video platform that brings your creativity to life. Create and edit your videos with AI. Rolling out to new users on web and discord, starting today. Sign up at
7
20
281
Introducing an approach to directly ground video generation models to policy execution without needing any action labels!. Our approach uses a generic goal-conditioned exploration procedure to learn a policy that works across robots / embodiments!
2
46
271
Our work on UniSim ( got an outstanding paper award!. Roughly 6 months before Sora, we showed how text-conditioned video models can be interactive simulators of the real world, enabling us to simulate long-horizon plans and train RL policies on robots.

Announcing the #ICLR2024 Outstanding Paper Awards:. Shoutout to the awards committee: @eunsolc, @katjahofmann, @liu_mingyu, @nanjiang_cs, @guennemann, @optiML, @tkipf, @CevherLIONS.
22
14
251
How can we discover, unsupervised, the underlying objects and global factors of variation in the world? We show how to discover these factors as different energy functions. Website: .w/ @ShuangL13799063, @yash_j_sharma, Josh Tenenbaum, @IMordatch. (1/4)
5
45
235
A major challenge to constructing foundation models for decision making is data scarcity. We present a “compositional foundation model”, which addresses this by composing existing foundation models, each capturing a sub-part of decision making. (1/4)
4
39
223
Can text-to-video generation help decision making? . Introducing UniPi, which acts by synthesizing a video of what it will do:. UniPi can generate diverse videos/actions across many environments (and combinatorially generalize!):. (1/6)
9
45
216
I'll be at @iclr_conf next week! . Happy to chat about generative models, compositional models, robot learning and embodied agents. I'll be presenting VLP ( showing how we can generate long-horizon video plans by combining VLMs + videos + search.

5
26
202
Check out neural descriptor fields!. We present a self-supervised method to obtain SE(3) equivariant descriptors of 3D shapes. These descriptors enable us generalize pick and place demonstrations to arbitrary novel SE(3) poses and objects instances. (1/6)
4
23
175
Check out generative manifold learning!. We show how to capture the manifold of any signal modality (including cross-modal ones), by representing each signal as a neural field. We can then traverse the latent space between signals and generate new samples!
2
33
175
Check out our work on recycling diffusion models!. We show how to combine different diffusion models together, to form new probability distributions which can solve a variety of new tasks– without any need for training!. Webpage:. (1/7)
2
40
164
I'll be at #NeurIPS2024 this upcoming week! I'll be helping present diffusion forcing ( and few-shot task learning (. I'm also recruiting PhD students this year -- happy to chat about potential opportunities at the conference!.
4
12
166
I’ll be at @NeurIPS2023 and will also be looking for academic jobs!. Happy to chat about generative AI, robot learning, embodied AI, video models and foundation models for decision making!. I’ll also help present the following set of papers:. (1/8).
2
4
135
Introducing a way to convert synthesized robot videos to robot execution without using any action labels!. We also release a codebase (with pretrained models) for text-to-video generation. Train your own models for robot control in only 1 day with 4 GPUs!
1
22
125
Introducing Video Adapter!. Our approach enables high quality, customized video synthesis with a small model and limited data. Videos are made by composing a smaller model with a pretrained one – requiring only black-box access to the large video model.
3
15
122
Great work led by @BoyuanChen0!. My favorite part is that we break sequence-level diffusion models into a composition of per-transition models. This allows for much more data-efficient learning, trajectory stitching, and the simulation of infinitely long sequences!.

Introducing Diffusion Forcing, which unifies next-token prediction (eg LLMs) and full-seq. diffusion (eg SORA)! It offers improved performance & new sampling strategies in vision and robotics, such as stable, infinite video generation, better diffusion planning, and more! (1/8)
0
10
116
Excited to share our recent work on Neural Acoustic Fields (NAF) at @NeurIPSConf !. In a similar way to how NeRF can synthesize novel views in a scene, NAF is a neural field that simulates sound at any location in a scene. Project Page and Code:.

A new machine-learning model simulates how a listener would hear a sound from any point in a room. “I think this work opens up an exciting research direction on better utilizing sound to model the world,” Yilun Du says.

3
15
110
While video models can generate stunning visuals, lots more work is needed to really make them effective world models. Problems like object persistence, compositionality, action following and accurate physics are all current issues with current models.

Curious whether video generation models (like #SORA) qualify as world models?. We conduct a systematic study to answer this question by investigating whether a video gen model is able to learn physical laws. Three are three key messages to take home: .1⃣The model generalises
2
6
114
🚨 Exciting News! 🚨. We're thrilled to announce that the Safe Generative AI Workshop at NeurIPS 2024 is now accepting paper submissions! 🎉. Topics include but are not limited to: Large Multimodal Model/LLM/RLHF/Reinforcement Learning/Generative Models related AI safety. 📅.
1
10
102
I'll be presenting our work on composing diffusion models @icmlconf and will also be looking for faculty positions this upcoming year! . My research focuses on generative models, robot learning, and embodied agents. Would love to chat at the conference if thats a good match!.
Check out our work on recycling diffusion models!. We show how to combine different diffusion models together, to form new probability distributions which can solve a variety of new tasks– without any need for training!. Webpage:. (1/7)
1
13
97
Large video models will revolutionize physical decision-making!. In past work, we’ve shown how this enables us to construct universal policies (, world simulators ( and long horizon planners (!.

Video generation will revolutionize decision making in the physical world like how language models have changed the digital world. Interested in the implications of video generation models like UniSim and Sora? Check out our position paper:.
1
10
94
Check out our work on applying diffusion to data driven control (#icml2022 long talk)! . We cast trajectory optimization as conditional sampling on a diffusion model. This enables test time adaptation (through conditioning) to tasks such as planning, block stacking, and RL.

Can we do model-based RL just by treating a trajectory like a huge image, and training a diffusion model to generate trajectories? Diffuser does exactly this, guiding generative diffusion models over trajectories with Q-values!. 🧵->
1
5
91
Excited to share our work at NeurIPS on how to effectively learn new tasks from very few demonstrations!. We invert demonstrations into the latent space a compositional set of generative models, allowing us to quickly learn new tasks substantially different than training tasks.

Learning new tasks with imitation learning often requires hundreds of demos. Check out our #NeurIPS paper in which we learn new tasks from few demos by inverting them into the latent space of a generative model pre-trained on a set of base tasks.
4
10
93
We're organizing a workshop on compositional learning at @NeurIPSConf!. Compositional generalization remains a huge problem in current models which often fail to generalize to unseen environments. Submit your work in this area to our workshop!.

🚀 Call for Papers! 🚀. Join us at the NeurIPS 2024 Workshop on Compositional Learning: Perspectives, Methods, and Paths Forward. We're seeking innovative research on:. 1. Perspectives: In which contexts, and why, should we expect foundation models to excel in compositional.
1
10
92
Excited to share our work on compositional world models!. Existing videos models are limited to actions seen at training -- by building models compositionally, we can simulate new actions never seen at training.

#ICML Introduce RoboDreamer:. - A compositional world model capable of factorizing video generation by leveraging the inherent compositionality of natural language!. - Flexible to specify multimodal goals, such as image, language, and sketch!.
0
6
91
Tomorrow (4/28) 4pm ET, @LukeZettlemoyer . from UW and @MetaAI will be giving a talk at the Embodied Intelligence Seminar @MIT_CSAIL on scaling large language models and their downstream use!. Live-streaming from: , co-hosted with @EpisodeYang!

0
14
90
We're hosting a workshop on Multi-Agent AI! . Consider your work in this area to the workshop! (Deadline November 30th).

📣Call for Papers: MARW @RealAAAI 2025. Join us for the 1st Multi-Agent AI in the Real-World Workshop! . If you are excited about AI Agents, please submit your research paper on AI Agent systems for any applications. Website: Deadline: November 25.
1
12
86
Introducing UniSim, a generative model trained to be an interactive simulator of the world!. We can train robot policies only on generated interactions, and deploy them on the real robot (with no need for any expensive / unsafe real world interaction)!.
Introducing Universal Simulator (UniSim), an interactive simulator of the real world. Interactive website: Paper:
2
9
83
We show how to use NeRF on dynamic scenes and video processing! Given noisy images in a video, we can denoise and refine images. We also capture the underlying RGB, depth, and flow. Website: Work with Yinan Zhang, Koven Yu, Josh Tenenbaum, @jiajunwu_cs
2
8
83
Video data provides rich information about physical interaction -- checkout out the following survey describing the various ways we can leverage video information for intelligent robots!.

⚡️“Towards Generalist Robot Learning from Internet Video: A Survey” ⚡️. Collecting robot data is hard. In our new survey, we review methods that can leverage large-scale internet video data to help overcome the robot data bottleneck: See more below👇

1
11
81
We've added how to use composable diffusion to compose text-guided 3D shapes from Point-E (@unixpickle)!. Make interesting hybrids of 3D shapes using the demo below!.

Compositional Visual Generation with Composable Diffusion Models – ECCV 2022 @nanliuuu @du_yilun Antonio Torralba, Joshua B. Tenenbaum. We present Composable-Diffusion, an approach for compositional visual generation by composing multiple diffusion models together.
1
9
79
Today (5/5) 4pm EDT, Ruslan Salakhutdinov @rsalakhu from CMU @SCSatCMU @mldcmu will be giving a talk at the Embodied Intelligence Seminar @MIT_CSAIL.on building autonomous embodied agents!. Live-streaming from: , co-hosted with @EpisodeYang!

0
9
78
Excited to share our new benchmark for detailed video captioning!. Existing video generative models are handicapped by the availability of detailed text descriptions. We curate a new video captioning benchmark 20x more detailed than prior datasets! .

(1/n) 📸Want to train a better video generation model? You need a better video captioner first! Check out AuroraCap! Trained on 20M+ high-quality data, it’s more efficient at inference. #lmms #videogen.🔗Homepage:

0
7
80
Excited to share our work on compositional generative inverse design!. By composing different generative models together we design systems at test time much more complex than the examples seen in the training dataset:.

Excited to announce that my group has two papers accepted at .@iclr_conf.#ICLR2024, one as spotlight!. 1. [Spotlight] Compositional generative inverse design: .2. BENO: Boundary-embedded Neural Operators for Elliptic PDEs:

1
9
71
Excited to present our research/code on neural energy-based models for proteins at #ICLR2020! Our model learns directly from crystallized protein structures. Fun project at @facebookai w/ @joshim5 Jerry Ma @alexrives @rob_fergus. 👇Thread (1/7).
1
22
70
Can cognitive science inform object discovery? Using infant cues of motion/foveation, we show how to discover 3D objects from videos that can be used for physical reasoning @iclr_conf .Poster:5/4 5-7pmPST.Website:w/@realkevinsmith,@TomerUllman,@jiajunwu_cs

1
11
72
How do we steer behavioral cloning policies to the intents of human users?. Introducing a training-free method that allows us to directly specify and steer policies to ad-hoc user intents at execution time!.

Want your robot to clean the kitchen your way? 🧹✨. 🔗. Introducing Inference-Time Policy Steering: a training-free method that lets you specify where and how to manipulate objects, so you can guide non-interactive policies to align with your preferences!
0
9
71
Check out our new paper on EBM training! We show a neglected term in contrastive divergence significantly improves stability of EBMs. We also propose new tricks for better generation. Website: .With @ShuangL13799063 Josh Tenenbaum, @IMordatch . (1/4)
2
7
70
Cool work showing how we integrate slow/fast learning systems to get video models with memory!.

🎬Meet SlowFast-VGen: an action-conditioned long video generation system that learns like a human brain!.🧠Slow learning builds the world model, while fast learning captures memories - enabling incredibly long, consistent videos that respond to your actions in real-time.

2
5
69
Check out our #NeurIPS2020 spotlight on compositional generation! We compose independently trained generative models on seperate datasets together to generate new combinations without retraining. Paper: Website: Thread(1/3)
1
5
68
Excited to share our work on constructing a 3D generative world model that can generate language, images and actions!. This enables us to imagine, plan and execute tasks across many environments.
Introduce 3D-VLA, a 3D Generative World Model!. Humans use mental models to predict and plan for the future. Similarly, 3D-VLA achieves this by linking 3D perception, future prediction, and action executions through a generative world model.
0
5
64
By formulating generative modeling as an EBM, we can get substantial flexibility in both the generation procedure and the ability to generalize to new generative modeling problems. We talk about the benefits of EBMs in:.

Q* Leaked info:. Source: An unspecified PasteBin.(L-I-N-K in next post).Can't confirm the authenticity as it's from unknown source but you can have a look. Q* is a dialog system conceptualized by OpenAI, designed to enhance the traditional dialog generation approach through the

1
5
65
Cool work on combining diffusion models together!.

🧵(1/5) Have you ever wanted to combine different pre-trained diffusion models but don't have time or data to retrain a new, bigger model?. 🚀 Introducing SuperDiff 🦹♀️ – a principled method for efficiently combining multiple pre-trained diffusion models solely during inference!
0
4
64
We'll be presenting NeuSE at #RSS2023!. Highlights:.- NeuSE encodes 6DOF poses of objects as learned "latent pointclouds".- Is a new neural representation for SLAM, that is cheap / fast.- Enables localization / mapping by closed form transform computation between object latents.

NeuSE: Neural SE(3)-Equivariant Embedding for Consistent Spatial Understanding with Objects . abs: .project page:

0
12
62
Excited to share recent work showing that by interpreting a LM as a EBM, we can design de novo proteins that fold in the real life!.

Language models understand natural proteins. But can they generalize beyond, to design completely new proteins from scratch?. New preprint: A 🧵
0
8
60
Cool work showing how we can accelerate video generation to real time speeds! Could open up lots of real world use cases of video policies and simulations.

Real-Time Video Generation: Achieved 🥳. Share our latest work with @JxlDragon, @VictorKaiWang1, and @YangYou1991: "Real-Time Video Generation with Pyramid Attention Broadcast.". 3 features: real-time, lossless quality, and training-free!. Blog: (🧵1/6)
1
9
58
Excited to share our work on implementing iterative reasoning through looped computation!. This enables near perfect length generalization on certain tasks while being much more efficient than generating long chains of reasoning.

🚀 Excited to share our latest research on Looped Transformers for Length Generalization!. TL;DR: We trained a Looped Transformer that dynamically adjusts the number of iterations based on input difficulty—and it achieves near-perfect length generalization on various tasks!.🧵👇

2
3
55
We will be hosting a workshop on compositional learning at #NeurIPS2024 in West Meeting Room 118-120!. Come for an exciting set of talks, posters, and panel discussions!.
🚀 Call for Papers! 🚀. Join us at the NeurIPS 2024 Workshop on Compositional Learning: Perspectives, Methods, and Paths Forward. We're seeking innovative research on:. 1. Perspectives: In which contexts, and why, should we expect foundation models to excel in compositional.
1
4
56
A survey on generative models in robotics led by the awesome @thepythagorian!. We overview the recent trends in this area, how to effectively get these models to generalize to settings without demonstrations, and directions of future work!.

Dear Ladies and Gentlemen,. We are releasing a new survey on Deep Generative Models for Robotics 🐣. We tackle timely challenges for robot learning such as what generative models should you use or how to improve the generalization capabilities of BC.

0
7
56
For video models to be effective world simulators, they need to be finely controlled given detailed action descriptions. Cool work on compositional video generation showing one way to add more control!.

Introducing Vico for compositional video generation! 🎥✨ Vico treats the diffusion model as a flow graph, ensuring accurate reflection of input tokens and effectively capturing compositional prompts. paper:page:#AIGC #Diffusion




1
9
54
We're hosting a ICLR workshop on generative models for decision-making!. Generative models provide exciting new perspectives on solving decision-making settings such as planning, exploration, and inverse RL. Submit your papers about this below:.

🚨 The call for papers for our #ICLR2024 workshop on Generative AI for Decision Making is out! 🚨. We welcome both short (4 pages) and full (9 pages) technical or positional papers. Details: 1/3.
1
6
47
We’re recruiting new tenure-track faculty in the Harvard Kempner Institute and computer science this year!. Apply here:.

NEW: we have an exciting opportunity for a tenure-track professor at the #KempnerInstitute and @hseas. Read the full description & apply today: .#ML #AI

0
3
46
Overall, the aim of our lab is to construct intelligent embodied agents in the physical world. We believe that building generative models of the world is crucial part of this goal, and that there are fundamental algorithmic advancements necessary to effectively construct such.
3
1
45
Our work on learning manifolds of arbitrary signals (images, shapes, audio, audiovisual) will be presented at .@NeurIPSConf poster session.4:30 PM PT 12/9 Thu:. Please stop by if you have any questions!

Check out generative manifold learning!. We show how to capture the manifold of any signal modality (including cross-modal ones), by representing each signal as a neural field. We can then traverse the latent space between signals and generate new samples!
1
10
45
Excited to share our #NeurIPS Oral work showing how the latent space of a large pre-trained 3D diffusion model can be evolved (in combination with MCMC sampling to construct soft robots!.
#NeurIPS23 Even wonder when Generative AI be useful for designing real-world robots. Excited to share our oral paper DiffuseBot!. Diffusion models and Differentiable Physics are all you need! 😀😀😀😀. Project page:
2
7
44
We'll be hosting the 2nd workshop on Foundation Models for Decision Making @NeurIPSConf 2023!. Consider submitting your work on planning / LLMs and VLMs / LLM Agents / video-decision making / RL to the workshop!.
0
7
44
Some interests in our lab at the moment include EBMs, compositional models / decentralized decision making, reasoning, and world models. However, we’re looking for creative PhD students and you are welcome/encouraged to propose any of your own directions!.
1
2
43
Yeah that’s a good question! We tried this here: and here (where the diffusion model can be seen as the gradients of an energy model) — it appears you can match standard RL performance.
1
3
40
Excited to share Composable Diffusion at #ECCV!. We present an approach towards compositional visual generation with diffusion models which explicitly composes multiple different diffusion models together to generate an image. Code + Models + Paper: .
Compositional Visual Generation with Composable Diffusion Models – ECCV 2022 @nanliuuu @du_yilun Antonio Torralba, Joshua B. Tenenbaum. We present Composable-Diffusion, an approach for compositional visual generation by composing multiple diffusion models together.
2
10
40
We find that multiagent debate can also enable two different instances of language models (chatGPT and Bard) to cooperatively solve a task they individually cannot. (4/5)

2
8
39
Introducing a new method for learning robot policies!. Policy learning is formulated as optimizing a trajectory of actions subject to task constraints (such as collision avoidance and goal completion). Each constraint is learned with a diffusion model, which we jointly solve!.

Our #CoRL2023 paper shows that by composing the energies of diffusion models trained to sample for individual constraint types such as collision-free, spatial relations, and physical stability, it can solve novel combinations of known constraints. (🧵 1/N)
0
3
40
By self-improving a population of language models, each trained on its own generated responses, we are able to maintain diversity of responses across LLM models, allowing us to observe consistent gains over multiple rounds of self-improvement.

1
0
36
Our population of LLMs consists of a set of generator LLM models and a set of critic LLM models. Each generator LLM model generates a separate possible response to a question, while separate specialized critic LLM model check each response and determines the correct one.
1
3
32
Excited to talk about video models as world models at the panel at the Language Models meet World Models tutorial!.

🔥#NeurIPS2023 Tutorial🔥. Language Models meet World Models. @tianminshu & I are excited to give tutorial on machine reasoning by connecting LLMs🗣️ world models🌎 agent models🤖. w/ amazing panelists @jiajunwu_cs @du_yilun Ishita Dasgupta,Noah Goodman.

0
2
30
I’m at #CVPR2023 this week and will be presenting our work on novel view synthesis / scene reconstruction from two widely separated images!. Please stop by our poster session Tuesday afternoon or reach out if you are interested in generally chatting!.

Methods such as PixelNeRF can synthesize novel views given few input images. However, they are limited to simple scenes and small baselines. In our CVPR paper, we present a method for high-quality novel view synthesis given only two distant observations:.
1
2
29
We’re looking for reviewers for our Safe Generative AI workshop at NeurIPS!. Please fill out the form below if you are interested in reviewing:.

🚨 Exciting News! . We're thrilled to announce that the Safe Generative AI Workshop at NeurIPS 2024 is now accepting paper submissions! . Submission Deadline: 04 Oct, 2024 📷 . Workshop Dates: December 14-15, 2024 📷 .Submission Details: Format: 4-8 page manuscripts

0
5
29
We find that both increasing the number of agents in multiagent debate or the number of rounds of debate both improve performance. (3/5)

2
0
27
Excited to share work showing how we can construct compositional world models over the beliefs of an agent to enable embodied agents to collaborate!.
The ability to infer others' actions and outcomes is central to human social intelligence. Can we leverage GenAI to build cooperative embodied agents with such capabilities?. Introducing 🌎COMBO🌎, a compositional world model for multi-agent planning!.
0
2
26
Robot learning has lots of heterogeneity from different sensor modalities (depth/tactile/rgb) and data modalities (simulation/real/human videos). We illustrate how we can learn and combine information from all these sources by composing policies together!.

How to deal with the vastly heterogeneous datasets and tasks in robotics? Robotic data are generated from different domains such as simulation, real robots, and human videos. We study policy composition (PoCo) using diffusion models. project website:
0
2
27
Check out our work on Point-Voxel Diffusion (PVD)! PVD is able to probabilistically complete different shapes from a single (real) depth image. Also obtain SOTA performance on shape generation.

Check out our work 3D Shape Generation and Completion through Point-Voxel Diffusion (PVD)! PVD probabilistically and diversely completes partial shapes from (real) depth scans and achieves SOTA on shape generation. w/ @du_yilun and @jiajunwu_cs.Website:
0
3
27
Even when given a single round of self-improvement, our approach is able to significantly outperform other methods in self-improvement across a set of benchmarks.

2
0
27
Our paper on unsupervised learning of compositional energy concepts will be presented at the .@NeurIPSConf poster session. 8:30 am PT 12/9 Thu: . Please stop by if you have any questions!.
How can we discover, unsupervised, the underlying objects and global factors of variation in the world? We show how to discover these factors as different energy functions. Website: .w/ @ShuangL13799063, @yash_j_sharma, Josh Tenenbaum, @IMordatch. (1/4)
0
4
25
Work done with amazing collaborators @ShuangL13799063 , Antonio Torralba, Joshua Tenenbaum, @IMordatch. We’re sharing code at and additional results may be found in paper at . (5/5).
2
0
25
We prompt each model/agent with the same initial question, and ask each agent to iteratively critique and update their responses given the responses of other agents. We find this improves performance across a set of different reasoning and factuality benchmarks. (2/5)
1
2
24
Check out our latest work showing how we can extend NDFs to manipulate multiple objects to have specified relations!.

A system for performing *relational rearrangement*, that achieves both generalization and data efficiency:. R-NDFs enable 6-DoF rearrangement of unseen object *pairs*, presented in arbitrary initial poses, using just 5-10 task demonstrations.
0
1
23
Introducing an approach to leverage dense 3D correspondences (scene flow) to implicitly encode camera poses and directly learn 3D scene representations directly from raw video -- no camera poses required!.
Introducing “FlowCam: Training Generalizable 3D Radiance Fields w/o Camera Poses via Pixel-Aligned Scene Flow”! We train a generalizable 3D scene representation self-supervised on datasets of raw videos, without any pre-computed camera poses or SFM!. 1/n
0
1
21
Check out our recent paper on continual learning! We show that swapping cross entropy with an energy based objective, we can significantly reduce catastrophic forgetting.

Energy-based models are a class of flexible, powerful models with applications in many areas of deep learning. Could energy-based models also be useful for continual learning?. Yes! Work led by @ShuangL13799063.
0
2
22
Why deep learning? The Atom Transformer takes a step exploring generative biology, which proposes that the design principles used by nature can be learned from data and harnessed to generate new molecules. Generalization to harder problems is a direction for future work (6/7)

2
6
19
We’ll be presenting the Decision Diffuser paper today at @iclr_conf in the RL oral track from 3-4:30 and at poster 105 from 4:30-6:30!. Please stop by if you have any questions!.
Introducing Decision Diffuser, a conditional diffusion model that outperforms offline RL across standard benchmarks – using only generative modeling training! Decision Diffusers can also combine multiple constraints and skills at test-time. Website:. 1/5
0
2
21
@chris_j_paxton @Shalev_lif These are interesting directions! One thing I find interesting is generalization -- how can we get diffusion planners to solve tasks very different than tasks seen at training?. We have some work on adaptive computation which also might be interesting:
1
1
19
Check out our new work on composing different large pretrained models together! We illustrate how we can generalize EBM composition ( more broadly across different large pretrained models to solve diverse tasks (reasoning, generation, manipulation, VQA).
How can we utilize pre-trained models from different modalities? We introduce a unified framework for composing ensembles of different pre-trained models to solve various multimodal problems in a zero-shot manner. @du_yilun @IMordatch, Antonio, and Josh.
0
0
16
How can we construct embodied policies that generalize in the real world? .We show how large scale language pretraining can be used to construct compositional embodied policies.
Can pre-trained language models (LM) be used as a general framework for tasks across different environments?.We study LM pre-training as a general framework for embodied decision-making. @xavierpuigf @du_yilun @clintonjwang @akyurekekin Antonio Torralba @jacobandreas @IMordatch
0
0
18