
Zhiting Hu
@ZhitingHu
Followers
3,525
Following
367
Media
59
Statuses
439
Assist. Prof. at UC San Diego; Artificial Intelligence, Machine Learning, Natural Language Processing
San Diego, CA
Joined April 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
FEMA
• 1203388 Tweets
Liz Cheney
• 209584 Tweets
#LISAxMoonlitFloor
• 197221 Tweets
MOONLIT FLOOR OUT NOW
• 137932 Tweets
SCJN
• 128619 Tweets
The Boss
• 103770 Tweets
#GHGala5
• 100032 Tweets
Bruce
• 92338 Tweets
Mets
• 69981 Tweets
Happy Anniversary
• 59797 Tweets
Baker
• 51010 Tweets
Brewers
• 42600 Tweets
EL DESTELLO IS OUT
• 34794 Tweets
天使の日
• 33230 Tweets
Falcons
• 29013 Tweets
Mancuso
• 25832 Tweets
Halle
• 24850 Tweets
もちづきさん
• 24728 Tweets
Pete Alonso
• 19614 Tweets
Athena
• 15232 Tweets
Mike Evans
• 14530 Tweets
Bijan
• 13510 Tweets
Phillies
• 11404 Tweets
#ゴンチャのハロウィン準備中
• 10748 Tweets
Milwaukee
• 10479 Tweets
Quintana
• 10036 Tweets




















Pinned Tweet

Super excited to introduce Pandora, a generative video World Model interactively controllable by language.
#Sora
and
#GPT4
are both powerful. How about fusing them in a single model? 💥
Pandora gives a preview:🔭
> Build a General World Model (GWM) super efficiently by

🔥Introducing Pandora 🌏 🪐
a World Model that generates videos of world states with real-time language control 🎥🕹️
Simulate the world across domains in an _interactive_ way!
check out more
7
75
231
9
58
290
🧠Human brain has internal world model for conscious reasoning
🤖Language model reasoning also need world model!
Reasoning via Planning (RAP) is a new principled framework for this. It prompts LM as WM & reasons w/ MC TreeSearch
Better v ChainOfThought on plan-gen, math, logic


🤖LLMs (autoregressive transformers) are not designed to reason in non-linear structures like humans...
🤔Instead of using it as a straight-minded reasoner, what about regarding it as a world model🌎and planning with it?
Check out our new work: Reasoning via Planning (RAP) 🧵

7
76
375
14
110
504
🔥
#NeurIPS2023
Tutorial🔥
Language Models meet World Models
@tianminshu
& I are excited to give tutorial on machine reasoning by connecting LLMs🗣️ world models🌎 agent models🤖
w/ amazing panelists
@jiajunwu_cs
@du_yilun
Ishita Dasgupta,Noah Goodman

5
71
411
🚨LLM Reasoners 🧠
A library for LLMs to do advanced reasoning, including latest algorithms:
- Reasoning-via-Planning (RAP) 🎶
- Tree-of-Thought (ToT) 🌴
- beam search, and more
All in unified perspective of world models🌎 and reward🥇
More alg & results coming soon!

📣 Introducing LLM Reasoners (), a library for advanced reasoning with LLMs.
Simply define a reward function and an optional world model, and let LLM Reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, etc.

7
139
648
5
72
344
Personal news: I'll be joining
@UCSanDiego
@HDSIUCSD
as an assist. professor in Fall 2021. Looking fwd to joining the amazing colleagues. Huge thanks to mentors/collaborators Eric Xing,
@rsalakhu
,
@tommmitchell
,
@dannydanr
,
@andrewgwils
, Le Song etc for the invaluable support!!
20
4
291
#PhD
#Recruiting
Please RT!
I’m looking for PhD students and postdocs
@UCSanDiego
@HDSIUCSD
, to work on
#ML
/
#AI
/
#NLP
, and build principles, methodologies, and systems of AI agents learning from all types of experiences. More info:

4
119
241
🤯Machine Learning has many paradigms: (un/self)supervised, reinforcement, adversarial, knowledge-driven, active, online learning, etc.
Is there an underlying 'Standard Model' that unifies & generalizes this bewildering zoo?
Our
@TheHDSR
paper presents an attempt toward it
1/

1
45
234
🗣️Language Models
➕
🌎World Models
When the two fascinating models start to interplay with each other, lots of exciting things happen!
🔥Here we use WM to teach LM diverse embodied knowledge and skills. Improve by 64% on 18 tasks, and let GPT-J-6B surpass chatGPT! 🔥


🤔Humans can learn from embodied experiences in the physical world. Can Language Models also do that?
🔥Check out our new paper about enhancing Language Models with World Models!
👇
1/n

5
68
355
2
48
221
🚩LLM360 — the 1st fully _open_ LLMs
🔥open weight
🔥open training data
🔥open code: data processing, training, eval
🔥open training trajectory: 360 checkpoints - from token 0 to 1.4T
🔥open analysis
Excited to see how this'd fuel research to transparentize LLMs🔍🔍



LLM360: Towards Fully Transparent Open-Source LLMs
paper page:
The recent surge in open-source Large Language Models (LLMs), such as LLaMA, Falcon, and Mistral, provides diverse options for AI practitioners and researchers. However, most LLMs have only

2
95
366
9
51
215
XLNet Pytorch for generation is now ready in Texar-pytorch! Play with XLNet & GPT-2 here. Figs show how XLNet and GPT-2 think of each other (w/ nucleus decoding) — It looks XLNet is looking forward GPT-3 which must be supervised :)


Checkout XLNet Pytorch implementation in Texar-pytorch (alpha), for encoding, classification, regression, (generation coming soon), and composing downstream models in combination of the rich Texar ML modules & functions!
@ZihangDai
@rsalakhu
@quocleix
3
13
110
4
65
207
🔥 The slides (both pptx & pdf) are now available on the tutorial website
💥Thanks all participants & panelists for making it a successful tutorial and discussion!
Also check out the accompanying perspective/review paper:




🔥
#NeurIPS2023
Tutorial🔥
Language Models meet World Models
@tianminshu
& I are excited to give tutorial on machine reasoning by connecting LLMs🗣️ world models🌎 agent models🤖
w/ amazing panelists
@jiajunwu_cs
@du_yilun
Ishita Dasgupta,Noah Goodman
5
71
411
3
33
183
New work connects GAN with Reinforcement Learning under a variational perspective, and stabilizes GAN training w/ off-the-shelf RL techniques
Strongly improves image generation, text generation, text style transfer
paper
code
1/

1
38
160
News🎺:
A "Standard Equation" of ML that unifies many learning paradigms & algorithms, is online!
We hope it can serve as a vehicle🚗 towards "panoramic learning" -- learning AI agents w/ ALL experiences
check out the initial draft
feedback welcomed
1/

2
32
152
⚒️ToolkenGPT
🔥Now any LMs can use massive tools, no finetuning, no prompt length limit
💡Calling a tool is as natural as generating a word token--treat tools as token (“toolken”) embeddings. Expand toolset by plug more toolkens
🤔Can embed millions of tools for LMs in future?

🤔ChatGPT plug-in is impressive, but is "learning tools in the context" the ultimate solution?
Check out our ToolkenGPT (), which can handle massive tools and understand them better with new "toolken" embeddings.
10
29
209
2
21
138
Checkout XLNet Pytorch implementation in Texar-pytorch (alpha), for encoding, classification, regression, (generation coming soon), and composing downstream models in combination of the rich Texar ML modules & functions!
@ZihangDai
@rsalakhu
@quocleix
3
13
110
Sad to be missing
#NeurIPS18
cuz visa (missed ICML18 for the same) But pls come meet my coauthors
Deep Generative Models with Learnable Knowledge Constraints
Hu, Yang,
@rsalakhu
, Liang, Qin, Dong, Xing
Sorry for the dense (but structured:) poster-just wanna make it self-explained

2
17
110
LLM Reasoners have been widely used (800 GitHub stars!🌟) in many projects since its initial release.
Now v1.0 is out -- new _algorithms_, systematic _evaluation_, and _visualization_! 🤩
More SOTA reasoning algorithms are on the way, including LLM reasoning for scientific
Releasing 🔥LLM Reasoners v1.0🔥
🥇Popular library for advanced LLM reasoning
- Reasoning-via-Planning (RAP)🎶
- Chain-of-Thoughts (CoT)⛓️
- Tree-of-Thoughts (ToT)🌴
- Grace decoding💄
- Beam search🔎
🥇Enhances
#Llama3
, GPT4, LLMs on
@huggingface

2
61
206
0
18
105
Tutorial just started! A packed room



🔥
#NeurIPS2023
Tutorial🔥
Language Models meet World Models
@tianminshu
& I are excited to give tutorial on machine reasoning by connecting LLMs🗣️ world models🌎 agent models🤖
w/ amazing panelists
@jiajunwu_cs
@du_yilun
Ishita Dasgupta,Noah Goodman
5
71
411
1
12
100
New work “Progressive Generation of Long Text” — a super simple “non-monotonic” use of monotonic language models (eg. GPT2, BART) for generating coherent long text (1000 tokens)
paper:
code:
1/4

2
14
79
🚨Oral presentation at
#NeurIPS2023
today by Shibo
@Ber18791531
ToolkenGPT is a way for LLMs to interact with the world🌎 via extensive plug-n-play tools⚒️
Two key takeaways:
🥇capture tool semantics by learning embeddings
🥈call the tools simply as generating words

⚒️ToolkenGPT
🔥Now any LMs can use massive tools, no finetuning, no prompt length limit
💡Calling a tool is as natural as generating a word token--treat tools as token (“toolken”) embeddings. Expand toolset by plug more toolkens
🤔Can embed millions of tools for LMs in future?
2
21
138
1
13
72
It's interesting to see how Sora triggers so much discussion on world models🌎
Does Sora understand Physics? Is Sora a world model? It's not a True/False question. The real questions are:
❓How capable is video (pixels) to represent the world?
❓And how efficient is it?
❓So

Modeling the world for action by generating pixel is as wasteful and doomed to failure as the largely-abandoned idea of "analysis by synthesis".
Decades ago, there was a big debate in ML about the relative advantages of generative methods vs discriminative methods for
120
233
2K
6
15
76



We're organizing
#NeurIPS2019
workshop on Learning with Rich Experience: Integration of Learning Paradigms, w/ an amazing lineup of speakers! Deadline: Sept 11
w/
@andrewgwils
@chelseabfinn
@rl_agent
@Lianhuiq
Taylor Berg-Kirkpatrick
@rsalakhu
& Eric Xing
0
16
47
Thrilled to receive the
#SoCalNLP2023
award!
Shoutout to
@kaiwei_chang
@robinomial
@jieyuzhao11
and all
@socalnlp
organizers for the amazing event at UCLA!!
🥚Easter egg: next year
#SoCalNLP
is heading to UC San Diego. Looking fwd to it already!
#NLProc

Next, we have
@Ber18791531
et. al’s amazing work, that also won an award at
#SoCalNLP2023
! 👏🏼

1
2
10
0
4
48
The paper “transfers” an off-the-shelf _reward_ learning algorithm to learning _data_ manipulation
It’s a powerful idea--transferring solutions to problems in one context to problems in another. Used in learning structured knowledge , improving GANs/VAEs

#NeurIPS2019
paper on Learning Data Manipulation: Learning to augment and re-weight data for improved training, especially in low data regime or in presence of imbalanced labels.
w/t Zhiting Hu, Bowen Tan et. al.
1
68
272
1
11
47
The full schedule of the ICML2018 workshop “Theoretical Foundations and Applications of Deep Generative Models” is released: . Come join us on Saturday 8:30 - 18:00 & Sunday 8:30 - 12:30 @ Room A5!



0
14
42
Consistency and controllability are two foundation capabilities of a World Model.🌏
> Consistency is to generate consistent videos (or other modalities) to correctly describe the world. This requires understanding of how the world works -- physics, spatiotemporal dynamics,
3
8
41
#EMNLP2022
Discrete pompt is more robust, interpretable, and transferrable-across-LMs than soft prompt
But optimizing discrete prompt is difficult.
Now you can do so efficiently and neatly with Reinforcement Learning! Checkout *RLPrompt*:

#EMNLP2022
RLPrompt uses Reinforcement Learning to optimize *discrete* prompts for any LM
w/ many nice properties:
* prompts transfer trivially across LMs
* gradient-free for LM
* strong improve vs manual/soft prompts
Paper
Code

3
22
171
0
7
40
Really excited about the
#ACL2024
outstanding paper award to our work on Multi-Modal Theory-of-Mind evaluation!
Congrats to
@chuanyang_jin
and
@tianminshu
who led the work!
Check out more:
-
-
🥳Our work on Multi-Model Theory of Mind evaluation won the
#ACL2024
Outstanding Paper Award!
How well can machines 🤖 form a coherent mental picture🧠of humans from vision-language observations?
Can machines understand humans' goals and beliefs?
Our MMToM-QA shows models
0
14
29
0
10
43
Our ICML18 workshop: Theoretical Foundations and Applications of Deep Generative Models.. Having great speakers coming! Please consider submitting your work, and participating to share your thoughts!
Call for Participation: ICML 2018 workshop on Theoretical Foundations and Applications of Deep Generative Models.

0
22
96
0
4
36
Reasoing via Planning (RAP):
- "Combining AlphaGo-style search and LLM"
- "Add world models … natively" :)

@ylecun
I agree, the fear of "AGI achieved by Q*" is nonsense. Combining AlphaGo-style search and LLM is an effective way to tackle specific domains like math and coding with groundtruth signals. But we do need novel ways to add world models and embodied agent capabilities natively to
13
19
320
0
6
33
🔥Excited that Redcoast won the
#NAACL2024
best demo runner up!
Redcoast is a super easy-to-use tool ☕️ for automated distributed training of
#LLMs
, diffusion, reinforcement learning, meta-learning, etc.
Users just write three functions (collate, loss, predict), and Redcoast






2
7
34
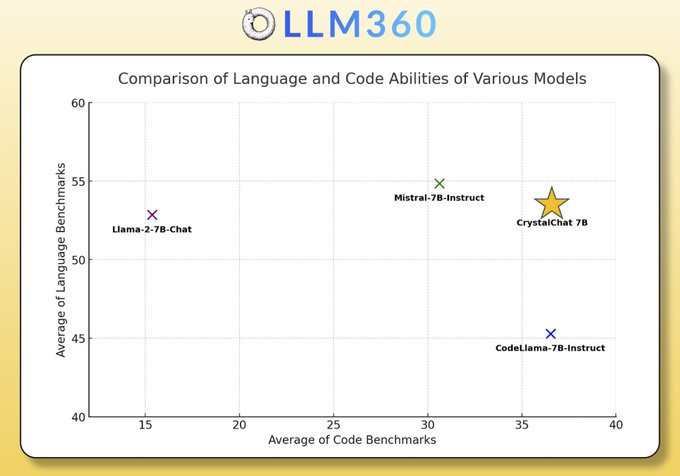
🔮CrystalChat-7B
🔥 best balanced capabilities in language and code v.s.
- Mistral-7B-Instruct
- CodeLlama-7B-Instruct
And don't forget its most facinating feature:
as part of
@llm360
, it's _fully_ open!

1/3 We are releasing CrystalChat 🔮 — a top-scoring 7B chat model, fully open source!
As always, CrystalChat is released under Apache 2.0, along with all training data, checkpoints, and implementation details.
Grab the model here:
4
34
159
0
6
27
For more discussions -- I'll be giving a tutorial at
#aaai2024
tmr (Tuesday) morning with
@tianminshu
:
Language Models meet World Models
It's an extended version of the
#NeurIPS2023
Tutorial:

🔥
#NeurIPS2023
Tutorial🔥
Language Models meet World Models
@tianminshu
& I are excited to give tutorial on machine reasoning by connecting LLMs🗣️ world models🌎 agent models🤖
w/ amazing panelists
@jiajunwu_cs
@du_yilun
Ishita Dasgupta,Noah Goodman
5
71
411
0
8
29
Optimizing pages-long expert-level prompts automatically 👇
It's fascinating that _prompt optimization_ can be formulated as a _planning_ problem:
- Treat the LLM as a world model🌎
- We want a prompt, as a plan trajectory, that thrives in this world
- So we do strategic
"With long context LLMs comes long prompts"👇
People typically just write 1- or 2-sentence quick prompts when using an LLM for a task.
How to create 1- or 2-page long prompts to boost performance?
🔥PromptAgent automatically writes long prompts for you!🔥
Without need of the

0
9
24
0
8
27
Super excited to release Texar-PyTorch v0.1
An ML library integrating the best of TensorFlow into PyTorch - replicating many useful TF modules & designs to enhance PyTorch, incl. data, model & training. See how Texar-Pytorch builds a Conditional-GPT2 1/5

1
5
26
Texar is nominated as a best (demo) paper candidate
#acl2019nlp
. Key features of Texar as a toolkit for ML & NLP/text generation: 1) Two versions (TF, PyTorch), mostly same interfaces; 2) Rich pretrained models (GPT2, BERT, XLNet…), unified interfaces, rich usage; 1/2

We are delighted to announce the list of papers that have been nominated as candidates for ACL 2019 Best Paper Awards! Check the list at
#acl2019nlp
1
34
167
1
4
25
Nice discussion. There could be a slightly more general perspective on "retrieval":
LLM generating each token can be seen as "retrieval" -- its last layer produces a latent vector. The vector is used to compare w/ word embeddings to "retrieve" the most similar word as the next

Over the last two days after my claim "long context will replace RAG", I have received quite a few criticisms (thanks and really appreciated!) and many of them stand a reasonable point. Here I have gathered the major counterargument, and try to address then one-by-one (feels like
35
88
511
0
4
25
Come stop by our poster (Wed 9am PT):
- A unifying variational perspective of GANs
- Stabilizing GAN training with off-the-shelf Reinforcement Learning techniques
paper:
code:
#NeurIPS2020
paper/code: "free lunch" for stabilizing your
#GAN
training & improving image/text generation
With a unifying perspective of GANs, RL & inference, we can easily import the stabilized RL algo
#PPO
to stabilize GAN.
Also importance sampling to stabilize discriminator
0
5
20
0
10
23
#Texar
now supports GPT-2 language models. Using GPT-2 on Texar is as simple as creating a TransformerDecoder instance and loading pre-trained weights. Texar supports many operations, like: (1/2)




1
5
22
Come join us for tmr (Sunday) morning’s CVPR workshop “Towards Causal, Explainable and Universal Medical Visual Diagnosis" (8:30am-12:00pm) at Hyatt Beacon B Room (4th floor of Hyatt Regency, right next to the Convention Center).


1
4
22
Check out
#K2
, a fully-open 65B LLM released by
@llm360
Matching the performance of
#Llama2
70B,
#K2
is among the most powerful LLMs made fully transparent!
Over the past 6 months,
@llm360
has made open a series of LLMs across different tiers, all with open weights,
Please welcome K2-65B🏔️, the most performant fully-open LLM released to date.
As a blueprint for open-source AGI, we release all model checkpoints, code, logs, and data.
About K2:
🧠65 billion parameters
🪟Fully transparent & reproducible
🔓Apache 2.0
📈Outperforms Llama 2 70B
6
146
492
0
4
21
Blog article introducing Texar, an open-source general-purpose text generation toolkit:
We will keep posting news, latest research, tutorials, and other information related to Texar on the Medium page:
0
7
22
Besides delving deeper into each learning paradigm, it’s also beneficial to look broader--studying connections bw Algs, combining best & enabling new capability (eg ingesting rich supervisions). Submit ur work in this line to
#NeurIPS2019
workshop --
3
6
21
#NeurIPS2020
paper/code: "free lunch" for stabilizing your
#GAN
training & improving image/text generation
With a unifying perspective of GANs, RL & inference, we can easily import the stabilized RL algo
#PPO
to stabilize GAN.
Also importance sampling to stabilize discriminator
New work connects GAN with Reinforcement Learning under a variational perspective, and stabilizes GAN training w/ off-the-shelf RL techniques
Strongly improves image generation, text generation, text style transfer
paper
code
1/
1
38
160
0
5
20
Come join the
#NeurIPS2019
workshop on Learning with Rich Experience. Note the location: West 208+209.
Look fwd to the super exciting talks by
@RaiaHadsell
@tommmitchell
JeffBilmes
@pabbeel
@YejinChoinka
& TomGriffiths, and the contributed presentations:

0
6
20
Our work Connecting the Dots b/w MLE and RL won the best paper on
#ICLR
workshop Deep RL meets Structured Prediction (happening now @ R02). Joint work w bowen, zichao, Russ
@rsalakhu
, Eric

Looking forward for our
#ICLR2019
workshop on Deep RL Meets Structured Prediction! Thanks to our amazing invited speakers
@jhamrick
,
@AnimaAnandkumar
,
@gneubig
, and
@Mo_Norouzi
! Also featuring contributed talks by
@ZhitingHu
,
@wouterkool
,
@zafarali
, and Osbert Bastani!
3
6
42
1
1
20
#Texar
now supports pretrained BERT models. Using BERT on Texar is as simple as creating a TransformerEncoder (fig) and loading the pretrained parameters. Then you can build downstream models for both text understanding & generation tasks. Example here:

1
5
18
Schedule for the upcoming
#CVPR2019
workshop "Towards Causal, Explainable and Universal Medical Visual Diagnosis" is out (Jun 16, Sun). Looking forward to the amazing speakers: Russ
@rsalakhu
, Devi
@deviparikh
, Dina
@dina_katabi
, Le Lu, & Deva Ramanan
1
5
17
This is our 2nd recent study of connecting the concepts of 🤖Language Models and 🌎World Models
Check out the other one:
🗣️Language Models
➕
🌎World Models
When the two fascinating models start to interplay with each other, lots of exciting things happen!
🔥Here we use WM to teach LM diverse embodied knowledge and skills. Improve by 64% on 18 tasks, and let GPT-J-6B surpass chatGPT! 🔥
2
48
221
1
3
16
#NAACL2021
Progressive Generation of Long Text with Pretrained LMs
Generating 1000-token text by converting left-to-right language models (GPT-2, BART) into progressive generators
Nice work by
@LTIatCMU
student Bowen!
paper
code

New work “Progressive Generation of Long Text” — a super simple “non-monotonic” use of monotonic language models (eg. GPT2, BART) for generating coherent long text (1000 tokens)
paper:
code:
1/4
2
14
79
1
4
16
@srush_nlp
We have a new work at
#ICML2024
to learn latent auto-encoding for text. It improves VAEs and other DGMs quite a bit:
The idea is to augment diffusion with parameterized encoder-decoder (e.g., pretrained LLMs)
Or in an alternative view, it replaces the

4
4
17


Fascinating idea of formulating LLM divergent thinking as sampling reasoning paths _proportional_ to reward functions (instead of just _maximizing_ reward)

💡Divergence thinking💡 is a hallmark of human creativity and problem-solving
🤖Can LLMs also do divergent reasoning to generate diverse solutions🤔?
Introducing Flow-of-Reasoning (FoR) 🌊, a data-efficient way of training LLM policy to generate diverse, high-quality reasoning
7
68
240
0
2
16
Our
#NeurIPS2019
workshop on Learning with Rich Experience (LIRE) is now accepting late-breaking submissions! Due next Monday 09/30.
@andrewgwils
@chelseabfinn
@rl_agent
@Lianhuiq
@rsalakhu
Besides delving deeper into each learning paradigm, it’s also beneficial to look broader--studying connections bw Algs, combining best & enabling new capability (eg ingesting rich supervisions). Submit ur work in this line to
#NeurIPS2019
workshop --
3
6
21
0
6
16
Towards Grounded, Explainable Vision + Language Models by
@deviparikh
!

0
5
16

BERT shares the key idea and almost the same model/learning objective with our recent work <Text Infilling>. BERT emphasizes that *text representation learning* should model both left and right context. Text Infilling emphasizes that *text generation* should also model both.

1
2
12
Super excited to announce Texar, an open source toolkit led by CMU and Petuum, aiming to support a broad set of text generation tasks like machine translation, dialog, summarization, content manipulation, etc. More details on .
@mldcmu
@LTIatCMU
@PetuumInc

1
9
13
Awesome! We once evaluated text generative models by training classifiers on real & model-synthetic data; observed certain improvement (vs classifiers on only real data). The real datasets were small though (). Great to see systematic studies here on images


Evaluating generative models is hard! We propose Classification Accuracy Score from classifiers trained on generated data:
-Accuracy of 43% when trained purely on BigGAN samples (vs 73%)
-Naive data augmentation doesn't work (yet!)
Paper:
cc
@SumanRavuri

3
69
245
0
2
13
Welcome
@SnowflakeDB
Arctic to the family of fully open LLMs! ❄️❄️
❄️Congrats to
@SnowflakeDB
for openly releasing Arctic!❄️
Arctic is available to all with an Apache 2.0 license!
Great to see LLM360 member
@AurickQ
and the whole Snowflake AI Research’s team's amazing contribution to the open-source LLM community!
2
3
16
2
1
13
DON’T MISS the exciting panel by our fantastic speakers, 17:05
@West
208+209!

Come join the
#NeurIPS2019
workshop on Learning with Rich Experience. Note the location: West 208+209.
Look fwd to the super exciting talks by
@RaiaHadsell
@tommmitchell
JeffBilmes
@pabbeel
@YejinChoinka
& TomGriffiths, and the contributed presentations:
0
6
20
0
1
11
A nice Youtube video explaining RLPrompt:
(seems like an awesome Youtube channel summarizing interesting NLP works with quick videos)

#EMNLP2022
RLPrompt uses Reinforcement Learning to optimize *discrete* prompts for any LM
w/ many nice properties:
* prompts transfer trivially across LMs
* gradient-free for LM
* strong improve vs manual/soft prompts
Paper
Code
3
22
171
0
4
11
Super interesting workshop on "Machine Learning for Data"
@icmlconf
For ML-automated data operations (labeling, synthesis, selection, augmentation), and challenges in quality, bias, security, privacy, …
Submission deadline: June 10


0
0
10
New work “Toward Unsupervised Text Content Manipulation” . Language is rich with variation—given a data record, there are diverse possible ways of saying the same data, with different word choices, expressions, transitions, tones, etc (i.e., writing style).
1
5
11
🚨New efficient Reinforcement Learning for text generation!
For various emerging apps:
* Generating _prompt_ to control pretrained LMs
* Generating _adversarial_ examples
* Learning w/ _negative_ text
* Training from scratch
Nice work by
@LTIatCMU
student
@HanGuo97


Excited to share our latest work with Bowen Tan
@waterluffy
Eric Xing
@ZhitingHu
!
Tldr, a new NLG formulation from soft Q-learning perspective, with app. such as learning from noisy data, text attacks, prompt generation.
Paper
Code

5
26
118
0
1
10
Controllable text generation leads to richer/better attacks for LLM safety
📢Introducing ❄️COLD-Attack⚔️, a unified framework for controllable jailbreaking of LLMs.
Thanks to the controllability, COLD-Attack enables new jailbreak scenarios that are hard to detect🧐:
1⃣revising a user query adversarially with minimal paraphrasing
2⃣inserting stealthy

5
48
236
0
0
9
We present a standardized formalism of the objective function to characterize the learning of any model with any experience:
eg. data, constraints, rules, reward, adversaries, other models, evolving interacts
It results in a succinct equation of the objective, w/ 3 terms:
2/

1
0
9
Big congrats to the authors of Pollux/AdaptDL
@AurickQ
and to the CASL (Composability, Automatic and Scalable Learning) open source consortium

0
0
8
Paper:
pdf:
It's a (substantial) extension to the earlier version we presented last year:
12/12
News🎺:
A "Standard Equation" of ML that unifies many learning paradigms & algorithms, is online!
We hope it can serve as a vehicle🚗 towards "panoramic learning" -- learning AI agents w/ ALL experiences
check out the initial draft
feedback welcomed
1/
2
32
152
0
0
9
The
#ICLR
workshop of _Machine Learning for IoT_ is happening now!
0
1
4
Thank you Martin
@ziqiao_ma
for the nice lecture! We learned a lot.

Excited to guest a lecture on “Connecting Language to the World: Towards Language Grounding to Vision and Embodied Agents” at UCSD. 😇
Thanks Prof.
@ZhitingHu
for hosting!

2
3
61
0
1
7
Mingkai has been making amazing works like the unified framework for language generation evaluation
Looking forward to more exciting results coming from him!
0
1
7
Check out our great speaker lineup! Kirsten Grauman (
@KristenGrauman7
), Nicholas Lane, Pradeep Natarajan (
@AmazonScience
), Thomas Plotez (
@thomasploetz
), Russ Salakhutdinov (
@rsalakhu
), Dawn Song (
@dawnsongtweets
), Eric Xing (
@ericxing
), and Heather Zheng (
@heatherzheng
)
1
0
6
New
#ACL2019
work "Target-Guided Open-Domain Conversation" . Going beyond chit-chat, we impose conversational goals on open-domain chat agents--the agent needs to chat engagingly with user and *proactively guide* the conversation to a given target subject.
1
1
6
@BlancheMinerva
Ah you're right! I somehow had a wrong impression. Bloom/Pythia etc opened similar artifacts earlier, and LLM360 is a fresh addition to these nice efforts.
1
0
6
Learning w Rich Experience: Integration of Learning Paradigms. Due Sept 11
Don't miss the incredible speakers
@pabbeel
JeffreyBilmes
@YejinChoinka
TomGriffiths
@RaiaHadsell
@tommmitchell
w
@andrewgwils
@chelseabfinn
@rl_agent
@Lianhuiq
TaylorBerg-Kirkpatrick
@rsalakhu
EricXing
1
2
5
Automatic prompt tuning & generation for controllable text generation
How to🤔? Make it a Reinforcement Learning problem
One (unexpected!) use case of the algorithm is prompt generation for controlling pretrained LMs via an RL formulation with "prompt" as action and "outcome of prompted outputs" as reward. Empirically, this seems to be more effective/efficient than recent steered decoding methods.


0
2
19
0
2
5
It's appealing to see that a succinct equation of the objective function recovers a wide range of known algorithms in distinct paradigms (supervised, unsupervised, active, reinforcement, adversarial learning, etc)
The equation consists of three terms:
2/

1
0
5
* Sample generation or completion
* Greedy / (top-k) sample / Gumbel-softmax / beam-search / your-customized decoding
* Training / fine-tuning in (un)conditional settings
* Perplexity evaluation
etc
Checkout example code/demo here: . (2/2)

2
5
4
Besides, the overall formalism is agnostic to the type of model p, meaning that you can plug in and train arbitrary 'model' for your task, eg
- Transformers
- pretrained models
- discrete/soft prompts
- symbolic knowledge graph (eg. )
- world model
8/
1
0
5
Correction: there are indeed earlier LLMs (e.g., GPT-J/Bloom/Pythia) at a similar level of openness, as shown in the table. LLM360 is a fresh addition to these great efforts. Look forward to more openness and transparency in this realm!
0
0
5
@cwizprod1
LM is a type of world model because language itself is a representation of the world. The thing is how to make the WM explicit and help reasoning.
LM has limited knowledge of the world (ie., a limited WM). So another topic is to teach LM more. One of our attempts here:)
🗣️Language Models
➕
🌎World Models
When the two fascinating models start to interplay with each other, lots of exciting things happen!
🔥Here we use WM to teach LM diverse embodied knowledge and skills. Improve by 64% on 18 tasks, and let GPT-J-6B surpass chatGPT! 🔥
2
48
221
1
0
4
We go beyond traditional data-to-text tasks by controlling both content and writing style of generation—we want the output to describe a given data record, meanwhile following the writing style of a reference sentence. Check out the paper for dataset/methods. Code coming soon
0
1
4
Paper link:

1
1
3
0
0
4
It turns out that, by choosing appropriate experience f, divergence D, and weights alpha/beta, the equation recovers many of the most popular algorithms precisely as special cases, ranging from MLE, active learning, to posterior regularization, to policy gradient, to ...
5/

1
1
4
@MichaelTontchev
ToT is a nice work! We discuss connect/diff in RelatedWork
Both r tree reasoning. ToT use depth/breath-first search; RAP use MontoCarloTreeSearch, balancing exploration-exploitation in more pincipled way
This's enabled by introducing WM & reward, etc
0
1
4
@gneubig
@hiroakiLhayashi
Nice work! Aspect-based summarization is of great practical use.
We also have a (preliminary) work in
#emnlp2020
: "Summarizing Text on Any Aspects" w/ knowledge weak supervisions:
0
0
4
0
0
4
1) Experience function to encode arbitrary types of experiences
2) Divergence term to measure model fitness
3) Uncertainty term to control complexity
Different choices of the components (and weights) lead to diverse existing & new algorithms
3/

1
0
3
On data part, Texar-PyTorch replicates best practice of for easy processing, batching, iterating + efficiency w/ buffered shuffling, caching, lazy-loading.
It also replicates TFRecord to ingest arbitrary complex data dataset, eg, image+caption+label 3/5

1
0
3
0
0
3
Read more about Texar-PyTorch features & how easily you can customize any of the above modules for your project, either you're an ML novice or expert
More resources:
5/5
1
0
3
For discriminator, the perspective induces importance re-weighting that downplays low-quality fake samples, leading to significantly more stable training for discriminator (and thus generator).
Fig: lower variance in G and D losses throughout training
3/

1
0
3
The formalism also opens up exciting open questions/opportunities for future, eg:
-Theoretical guarantees of improvement when adding new experience in learning
-From standardization to automation: how to automatically search for new algorithms
-Learning w/ dynamic experience
5/
2
0
3
Co-organizers: Xingyu Zhang,
@YuanYuan_MIT
,
@TRahmanRifat
,
@chloe_yang3
, Ke Sun,
@yingcheng_liu
,
@bradjc5
,
@ZhitingHu

0
0
3