

Lisa Lee
@rl_agent
Followers
5,942
Following
0
Media
30
Statuses
128
Research Scientist at Google DeepMind. Core contributor to Gemini post-training & multimodal pre-training.
Joined February 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
America
• 1075191 Tweets
Happy 4th
• 875103 Tweets
Labour
• 610827 Tweets
Independence Day
• 523748 Tweets
Reform
• 488385 Tweets
Tories
• 290903 Tweets
#loveIsland
• 217427 Tweets
Tory
• 203913 Tweets
Keir Starmer
• 130811 Tweets
#GeneralElection2024
• 119826 Tweets
Mimi
• 109754 Tweets
Sean
• 103380 Tweets
Mario Delgado
• 74126 Tweets
Maya
• 61849 Tweets
Corbyn
• 54858 Tweets
#TemptationIsland
• 40370 Tweets
Sky News
• 32759 Tweets
Raul
• 32740 Tweets
Andy Murray
• 31305 Tweets
Channel 4
• 26233 Tweets
Luca
• 25227 Tweets
Lib Dems
• 23625 Tweets
Reino Unido
• 20009 Tweets
Matilda
• 18184 Tweets
THE ARCHER
• 15275 Tweets
#ExitPoll
• 12984 Tweets
Joey Chestnut
• 10571 Tweets
GUILTY AS SIN
• 10144 Tweets





















Five years ago, I left Google to pursue a PhD in Machine Learning.
Tomorrow, I'm very excited to join Google Brain as a Research Scientist! Looking forward to meeting everyone :)
My PhD thesis can be viewed at:
Thesis defense:

56
200
3K
Update: I will be a Research Scientist at Google Brain starting this fall!
Super grateful to all of the fantastic researchers I met through the interview process. Thanks for valuable career advice & research chats – I'll take these lessons with me in the next stage of my career!
30
8
1K
Gemini is the most fun project I've worked on in my career.
I feel so lucky to work with incredible teammates in Gemini. We all worked really hard for this public release. Looking forward to more learnings in 2024.
Chat with Bard (running Gemini Pro):
12
34
466

I wrote a Colab tutorial on MaxEnt RL: It implements the graphical model from
@svlevine
's "RL as Inference" tutorial for a simple chain environment. Play around with the reward function to learn different policies using the forward-backward algorithm!
0
54
228
My dog Eevee 🐶 is featured in our recent research paper from Google
@DeepMind
:
Barkour: Benchmarking animal-level agility with quadruped robots
Inspired by dog agility competitions, we introduce a diverse and challenging obstacle course for robotic locomotion. (1/n)
3
22
175

What makes it hard for robots to generalize to new environments?
In our study, we broke down the notion of an “environment” into smaller, more manageable factors of variation, such as lighting or camera placement.
1/n
3
34
141

Our new work is featured in the
@NYTimes
:
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
tl;dr We fine-tune a VLM to predict robot actions directly as text, and see emergent capabilities in the embodied agent.
(1/n)

6
17
105


Video & slides for LIRE workshop @
#NeurIPS2019
are now up:
Check out the Talks and Panel by
@RaiaHadsell
@tommmitchell
Jeff Bilmes
@pabbeel
@YejinChoinka
Tom Griffiths & more.
Thanks to all speakers & presenters for making the workshop a success!



0
28
86
I just started at Stanford this week as a visiting researcher in
@chelseabfinn
's lab, and I'm also still part-time at Google Brain Robotics. If you're around in the area and would like to chat about research, please feel free to reach out anytime! (My office is in Gates)
0
0
75
Our team is hiring!
I only recently joined Dale's team after PhD, but am grateful to be part of a team of super talented & wonderful researchers, with diverse areas of expertise in core ML, reinforcement learning, representation learning, planning, discrete optimization, etc.

Our team at Google Brain (w/ Dale Schuurmans,
@daibond_alpha
,
@rl_agent
,
@mengjiao_yang
and many others) is hiring a SWE to work on representation learning for reasoning, search & decision making. Apply below if you are interested!
3
14
93
3
9
69
There are many ways to parameterize an RL problem (state/action space, rewards, time freq. & horizon, etc).
Researchers often assume the problem formulation to be fixed, & iterate on algorithm design.
But conversely: How does the design of envs & tasks affect the RL algorithm?
1
5
65
Yo-Yo Ma (
@YoYo_Ma
) playing Bach Cello Suite No. 3 Prelude at the AI for Social Good (
#ai4good
) workshop in Montreal!
#NeurIPS2018
1
10
65

Instead of rewards or demos, can we use weak supervision to accelerate goal-conditioned RL & learn interpretable latent policies?
Excited to share our work from during my visit
@Stanford
& Google, with my amazing collaborators Ben Eysenbach,
@rsalakhu
@shaneguML
&
@chelseabfinn
!

Supervising RL is hard, especially if you want to learn many tasks. To address this, we present:
Weakly-Supervised Reinforcement Learning for Controllable Behavior
with
@rl_agent
, Eysenbach,
@rsalakhu
,
@shaneguML
@GoogleAI
thread 👇

2
59
276
0
11
58
Congratulations & thanks Kamalika (
@kamalikac
) and Russ (
@rsalakhu
) for organizing
#ICML2019
!
And thanks for having us workflow chairs onboard! It was an amazing experience to see the conference come together from start to finish.
@dchaplot
@pliang279

From your ICML2019 Program Chairs with
@kamalikac
. We are done my friends! We hope you enjoyed ICML this year!
And big thanks to all members of Organizing Committee and our workflow chairs for making it a successful conference!

11
17
324
0
6
50
Pics from our
#ICML2018
Workshop on Theoretical Foundations & Applications of Deep Generative Models
Huge thanks to
@ZhitingHu
who put a lot of work into organizing & thanks to speakers for their amazing talks!
with Zhiting,
@andrewgwils
@rsalakhu
& Eric




1
8
50
I'm always grateful for my collaborators & mentors from my PhD, including my thesis committee
@rsalakhu
@ericxing
@chelseabfinn
@svlevine
; intern hosts N.Heess (DeepMind),
@shaneguML
(Google Robotics); friends
@ben_eysenbach
@alshedivat
@dchaplot
E.Parisotto C.Huang &many others.
3
2
50
I'm Workflow Chair for
#ICML2019
with
@dchaplot
. It's been eye-opening to see how much work goes into organizing a major ML conference, and a great honor to work with Program Chairs
@kamalikac
&
@rsalakhu
!
0
3
47
1/ Excited to present two workshop papers at
#NeurIPS
on RL + Navigation, including this paper at the Deep RL workshop (Fri 15:00).
tl;dr We introduce a series of attention operators to disentangle text/visual representations & enable cross-task transfer for embodied navigation.

Check out our poster on 'Cross-Task Knowledge Transfer for Visually-Grounded Navigation' at the
#neurips2018
DeepRL Workshop (Friday, 3pm, Room 220).
- with
@rl_agent
@rsalakhu
@deviparikh
@DhruvBatraDB

0
13
57
1
8
45
I'm excited to present Weakly-Supervised RL for Controllable Behavior at
#NeurIPS2020
today! Stop by our poster @ 9-11 pm PST in Session 7 (Deep Learning) D0-A0.
w/ B.Eysenbach
@rsalakhu
@shaneguML
@chelseabfinn
Paper:
Talk:

Supervising RL is hard, especially if you want to learn many tasks. To address this, we present:
Weakly-Supervised Reinforcement Learning for Controllable Behavior
with
@rl_agent
, Eysenbach,
@rsalakhu
,
@shaneguML
@GoogleAI
thread 👇
2
59
276
0
14
43

RT-2 paper is now on ArXiv:
Videos:
Blog post by
@YevgenChebotar
&
@TianheYu
:
It also appears on the
@NYTimes
podcast Hard Fork hosted by
@KevinRoose
&
@CaseyNewton
(gifted link):

0
9
40
And check out Emilio's other paper titled "Neural Map: Structured Memory for Deep Reinforcement Learning":

Also, check out our poster on LSTM Iteration Networks: An Exploration of Differentiable Path Finding in
#ICLR2018
Workshop at 11am on Monday.
(with
@binarymatroid
, Emilio and
@rsalakhu
)
PDF:
0
5
15
1
1
35

Check out our blog post on the Multi-Game Decision Transformer, one of my first projects since starting at Google Brain :)
We study the generalization capabilities of a single Transformer agent trained on many Atari games.
Blog post authored by
@winniethexu
@kuanghueilee

Introducing the Multi-Game Decision Transformer: Learn how it trains an agent that can play 41 Atari games, can be quickly adapted to new games via fine-tuning, and significantly improves upon the few alternatives for training multi-game agents →
8
156
527
0
5
31
My friend
@alshedivat
got a Best Paper award at ICLR 2018! Check out his Oral presentation this Thursday at 10:15am :)

Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments (, tl;dr: agents that meta-learn outcompete agents that don't, ). Best paper award, Thursday May 3rd, 10:15-10:30am, Exhibition Hall A
3
19
61
0
4
30
2/ On the Complexity of Exploration in Goal-Driven Navigation
w/
@alshedivat
@rsalakhu
Eric Xing
R2Learning workshop (Sat 10:15)
#NeurIPS2018
tl;dr We measure the complexity of RL environments by computing expected hitting times in goal dependency graphs.

0
11
31
Check out our
#NeurIPS2023
paper, led by KAIST PhD student Changyeon Kim (
@cykim1006
):
Guide Your Agent with Adaptive Multimodal Rewards
Website:
Paper:
Code:


Excited to share Adaptive Return-conditioned Policy (ARP): a return-conditioned policy utilizing adaptive multimodal reward from pre-trained CLIP encoders!
ARP can mitigate goal misgeneralization and execute unseen text instructions!
🧵👇
1/N
2
9
57
0
3
30
Honored to be featured in Sean Welleck's "The Thesis Review" podcast! Thanks
@wellecks
for the fun conversation & great questions.
Check out other interesting episodes on Deep Learning, NLP, Active Learning, Graphical Models, RL & more at:

Episode 40 of The Thesis Review:
Lisa Lee (
@rl_agent
), "Learning Embodied Agents with Scalably-Supervised RL"
We discuss her thesis work on reinforcement learning, including exploration, weak supervision, and embodied agents, along with trends in RL.

1
6
20
0
2
23
Forgetful Causal Masking makes language models better zero-shot learners
Led by
@haoliuhl
and
@YoungGeng
(
@UCBerkeley
&
@GoogleAI
)
A simple technique can greatly improve zero- & few-shot performance of LLMs on downstream language-understanding tasks. 🧵


Can language model pretraining be even better?
Our paper shows that by randomly masking input tokens during pretraining, the zero-shot, few-shot, and fine-tuning performance can be significantly improved.
🧵
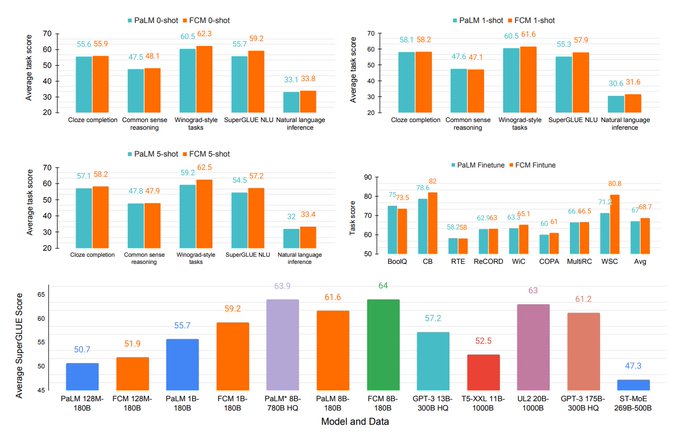
2
41
303
0
4
23
I loved my time at DeepMind in Nicolas Heess's team. Met so many talented & kind researchers and engineers there.
Now, looking forward to exciting collaboration opportunities with old and new colleagues under the same umbrella. :)

The phenomenal teams from Google Research’s Brain and
@DeepMind
have made many of the seminal research advances that underpin modern AI, from Deep RL to Transformers. Now we’re joining forces as a single unit, Google DeepMind, which I’m thrilled to lead!
159
651
4K
0
1
20
Submissions are now open for the ICLR 2024 workshop on Generative Models for Decision Making:
How can we combine generative models and decision making for better exploration, planning, sample efficiency, transfer learning, and alignment with human priors?

1
2
18
EcoRL workshop
@NeurIPSConf
brings together exciting talks & papers to discuss: "How does task design influence agent learning?"
I'm personally excited about the step towards data-centric understanding of RL, complementing today's algorithm-centered view.

Starting 8:10 ET, we will have
@ShaneLegg
Co-Founder & Chief Scientist
@DeepMind
with a thought-provoking talk titled “Artificial What?” : (). Submit questions for
@ShaneLegg
at: for the Live Q&A following the talk.
1
0
10
1
1
18
Blog Post:
Gemini 1.0 Capabilities:
Technical report:

0
0
17
This work was done with wonderful collaborators at Google
@DeepMind
.
Check out our blog post, co-authored by Ken Caluwaerts and Atil Iscen:
Blog Post:
Paper:
Website:
(6/6)
1
3
17
Come check out our ICML Workshop next week!
Excited about our 2-day
@icmlconf
Workshop on Theoretical Foundations and Applications of Deep Generative Models with Zhiting Hu,
@andrewgwils
,
@rl_agent
& Eric Xing, on Sat Jul 14th, 8am - 6pm @ A5
Check out the program, posters, & terrific speakers!
0
23
86
0
3
16
Thanks Russ for being an amazing advisor to all of us!
1/3: 2021 has been an incredible year: 5 of my PhD students (some co-advised) have graduated this year.
It's a privilege to have worked with such talented people!
Devendra Chaplot, Lisa Lee, Emilio Parisotto, Shrimai Prabhumoye & Hubert Tsai
Check out their theses/papers here:
2
9
177
1
0
15
Instruction-Following Agents with Jointly Pre-Trained Vision-Language Models
Paper:
Code:
w/
@haoliuhl
*
@kimin_le2
@pabbeel
from
@berkeley_ai
@GoogleAI
We showcase the importance of a jointly pre-trained encoder for grounded RL:

How to pretrain large language-vision models to help seeing, acting, and following instructions?
We found that using models jointly pretrained on image-text pairs and text-only corpus significantly outperforms baselines.
A 🧵 on the paper InstructRL
3
13
88
1
2
15
サンフランシスコからこんばんは!日本語で初めてのツイートです。
リサと申します。子供の頃、大阪府豊中市で中豊島小学校の生徒でした。今はGoogle Brainで人工知能の研究をやってます。日本にいる大切な友達と連絡を取り続けるように、ずっと日本語を練習続けてきました。
よろしくお願い致します。
0
0
12
@jeffclune
@AdrienLE
@Joost_Huizinga
@joelbot3000
@kenneth0stanley
Cool work, there was a similar paper submitted to ICLR about revisiting interesting states:

1
2
11
Learning a stationary reward function via gradient descent to match the expert state density. This reward can be reused for solving downstream tasks & behavior transfer across dynamics.
#CoRL2020
Project led by Tianwei Ni, Harshit Sikchi, Yufei Wang &
@the_tejus
from CMU!

Can we extract reward functions when only expert state density/samples are given? Our
#CORL_2020
paper derives an analytical gradient to match general f-divergence!
Equal contribution work with coauthors T. Ni, Y. Wang,
@the_tejus
,
@rl_agent
, B. Eysenbach
1
2
14
0
0
10
These results suggest that tackling harder factors (e.g. new camera poses) may be more important to closing the generalization gap than other factors (e.g. new backgrounds).
We hope these results serve as a guide for future data collection and model design in robotics.
4/n

1
1
8
Paper, demos & blogpost are available at:
Thanks to the awesome team
@GoogleDeepMind
including
@QuanVng
@TianheYu
@YevgenChebotar
@peteflorence
@IMordatch
@xiao_ted
@xf1280
@brian_ichter
@ayzwah
@ryancjulian
@svlevine
@chelseabfinn
@hausman_k
(3/3)

0
1
7
Check out our full paper at:
This work was led by Annie Xie (PhD student at Stanford), and w/ Ted Xiao (
@xiao_ted
) & Chelsea Finn (
@chelseabfinn
).
6/6

0
1
7
Using a custom-built quadruped robot, we train two strong baselines:
1. Individual specialist skill policies trained via on-policy RL and large-scale parallel simulation.
2. A single, generalist Transformer-based policy trained by distilling the specialist policies. (3/n)
1
1
6
The generalist Locomotion Transformer policy automatically infers which skill to use, such as walking or slope climbing, from its terrain and proprioceptive observations.
It predicts low-level locomotion actions, conditioned on velocity command & environment observations. (4/n)
1
0
6
Also visited
@Mila_Quebec
. It's a nice collaborative space for research in machine learning and AI. Thanks
@zhu_zhaocheng
and
@zdhnarsil
for the tour!

1
0
6
My PhD advisor's origin story :-)
1/4 I was watching
@geoffreyhinton
interview w/t
@pabbeel
- it reminded me of a couple fun stories about Geoff and how he got me into deep learning.
Back in 2005, I was not thinking about PhD & had a good career as ML engineer. One morning, on my way to work I bumped into Geoff.
13
43
605
0
0
6
0
0
2
7B and 2B models based on Gemini, both pre-trained & fine-tuned checkpoints, are now publicly available.
Technical report:
Opensource codebase for inference and serving:
HuggingFace:


Introducing Gemma: a family of lightweight, state-of-the-art open models for developers and researchers to build with AI. 🌐
We’re also releasing tools to support innovation and collaboration - as well as to guide responsible use.
Get started now. →

134
535
2K
1
0
6
The Barkour course consists of four obstacles in a 5m x 5m area, testing a diverse set of skills while keeping the setup within a small footprint.
The scoring system is inspired by dog competition rules, with penalties for skipping/failing obstacles, or moving too slowly. (2/n)
1
0
5
EcoRL Workshop will resume at 10 am PT for Session 2!
Link:
Submit questions for Live Q&A w/ our speakers:
- Benjamin Van Roy
@Stanford
-
@WarrenBPowell
@Princeton
-
@yayitsamyzhang
@UCBerkeley
FAIR
@UTAustin
- Tom Griffiths
@Princeton
-
@Mvandepanne
@UBC
1
1
5
We report the performance of the learned policies, which can complete the Barkour course at roughly half the speed of a dog.
Additionally, state-of-the-art RL methods fail to learn a single policy to complete the course, underscoring the complexity and value of Barkour. (5/n)

1
0
4
Surprisingly, most combinations of factors do not have a compounding effect on generalization performance. For example, generalizing to the combination of new table textures & new distractors is no harder than new table textures alone (which is the harder of the two factors).
3/n

1
1
4
We also provide a simulated robot environment with 19 tasks and 11 factors of variation, to facilitate more controlled evaluations of generalization:
5/n
1
1
4
We then independently evaluated generalization to each factor and found a pretty consistent ordering of difficulty across different datasets, models, and even between sim vs. real setups:
2/n

1
1
4
Then at 1:10 pm PT, join us for a Live Panel Discussion with:
- Joelle Pineau
@Mila_Quebec
- Tom Griffiths
@Princeton
-
@pyoudeyer
@MSFTResearch
@FlowersINRIA
-
@jeffclune
@UBC
moderated by
@shaneguML
.
EcoRL Workshop:
0
0
2
Emergent capabilities include:
- Generalization to novel objects
- Symbol understanding ("move apple to Google")
- Human recognition ("move apple to Taylor Swift")
- Semantic reasoning ("pick land animal", "pick object that is different", "move banana to the sum of 2+1")
(2/n)
1
0
2
InstructRL is much simpler yet outperforms prior SOTA across a wide range of visual manipulation tasks.
We found that InstructRL can generalize to unseen instructions, and can even understand longer, detailed step-by-step instructions to solve the task better.

0
0
1
@shaneguML
@GoogleAI
@OpenAI
@johnschulman2
Congrats Shane! We'll miss you at Brain, but looking forward to your future endeavors.
0
0
1