

Yuhuai (Tony) Wu
@Yuhu_ai_
Followers
23,250
Following
416
Media
41
Statuses
387
Co-Founder @xAI . Minerva, STaR, AlphaGeometry, AlphaStar, Autoformalization, Memorizing transformer.
Stanford
Joined July 2017
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
JIKOOK
• 111389 Tweets
تركيا
• 105086 Tweets
Avusturya
• 79042 Tweets
Eminem
• 77754 Tweets
बालक बुद्धि
• 59790 Tweets
Romania
• 53401 Tweets
TXT CHIKAI OUT NOW
• 52453 Tweets
Gakpo
• 52000 Tweets
TXT WE'LL NEVER CHANGE OUT NOW
• 50537 Tweets
#DOLCEGABBANA
• 37554 Tweets
#DGAltaModa
• 36667 Tweets
Rudy Giuliani
• 33731 Tweets
$ASI
• 31459 Tweets
Tobey
• 27031 Tweets
TRT 1
• 25757 Tweets
Recep Tayyip Erdoğan
• 23340 Tweets
هولندا
• 20084 Tweets
Elmo
• 18539 Tweets
Denji
• 16749 Tweets
チェンソーマン
• 14880 Tweets
Malen
• 13029 Tweets
Carille
• 12362 Tweets
#roened
• 12274 Tweets
Fujimoto
• 12202 Tweets
Hollanda
• 11681 Tweets
Trabalhadores
• 11440 Tweets
オランダ
• 10795 Tweets


















Coming to
#NeurIPS23
now. Will be there until Friday night.
DM me to chat about: reasoning, AI for math, and what we’re doing
@xai
.
Also will be at
#MATHAI
workshop panel discussion on Friday morning. See you there!
121
151
520
Euclidean geometry problems have been my favorite math puzzles since middle school. The most intriguing part of it is the creation of auxiliary lines, which opens a space for imagination and the freedom to explore various diagrams. Once a proof is found, these auxiliary lines

Proud of this work. Here's my 22min video explanation of the paper:
38
170
786
219
191
946
Language models can dramatically improve their reasoning by learning from chains of thought that they generate.
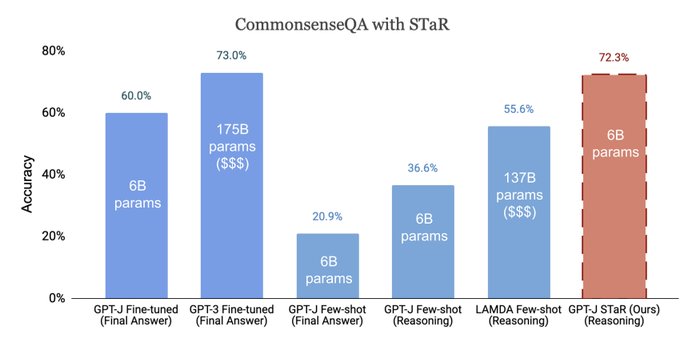
With STaR, just a few worked examples can boost accuracy to that of a 30X larger model (GPT-J to GPT-3).
W.
@ericzelikman
, Noah Goodman
1/
8
93
523
After showing a few examples, large language models can translate natural language mathematical statements into formal specifications.
We autoformalize 4K theorems as new data to train our neural theorem prover, achieving SOTA on miniF2F!
1/
Paper:

5
110
459

Can Neural Networks solve IQ tests? We propose Scattering Compositional Learner (SCL) for RPM Task. SCL improves SOTA from 63.9% to 95.0%. It is even capable of zero-shot generalization and learns disentangled representations!
paper:
(1/n)

7
108
376
How do you make a transformer recurrent?
You just turn the transformer 90 degree, and apply it in the lateral direction!
Now, with recurrence, the context size is infinite!
Let's make the recurrence great again with Block-Recurrent Transformers:


You think the RNN era is over? Think again!
We introduce "Block-Recurrent Transformer", which applies a transformer layer in a recurrent fashion & beats transformer XL on LM tasks.
Paper:
W. DeLesley Hutchins, Imanol Schlag,
@Yuhu_ai_
&
@ethansdyer
1/

5
68
451
9
41
315
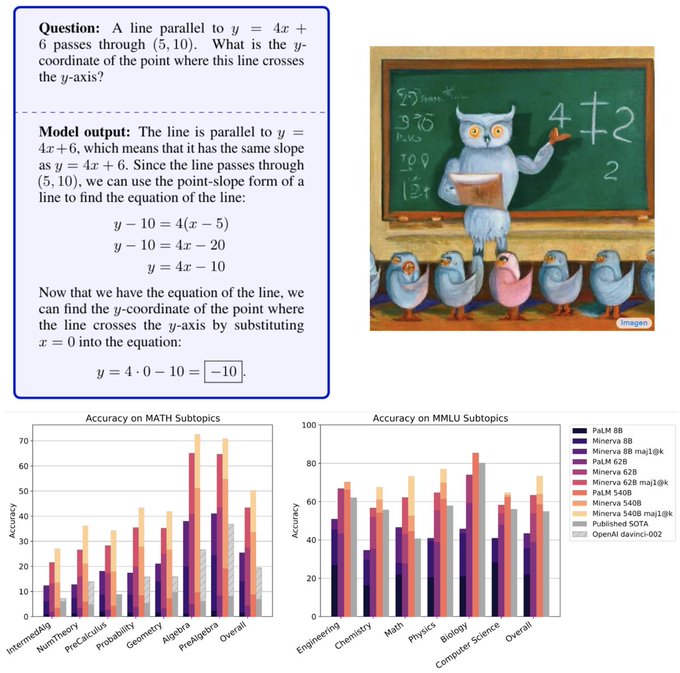
Super excited to share Minerva!! – a language model that is capable of solving MATH with 50% success rate, which was predicted to happen in 2025 by Steinhardt et. al. ()!
#Minerva
1/


Very excited to present Minerva🦉: a language model capable of solving mathematical questions using step-by-step natural language reasoning.
Combining scale, data and others dramatically improves performance on the STEM benchmarks MATH and MMLU-STEM.
108
1K
8K
4
46
243
░J░O░I░N░U░S░

based and 🔓
wanna help accelerate the next Grok?
looking for builders:
— Rust/Jax/Kube infra engineers
— front-end/full-stack engineers
38
89
405
25
15
149
Autoformalization with LLMs in Lean!
@zhangir_azerbay
and Edward Ayers built a chat interface to formalize natural language mathematics in Lean:
Very impressive work!


5
49
193

🚨We are organizing the 2nd MATHAI workshop at NeurIPS!
Check it out if you're interested in AI for math, and machine reasoning in general🤯!
We have a great lineup of speakers & panelists!
See more in call for papers: 👇

3
30
150
Hello
#NeurIPS2022
! I'm at New Orleans and will be here until Thursday morning (Dec 1). Let's brainstorm AI for math, LLMs, Reasoning 🤯🤯!
We'll present 8 papers (1 oral and 7 posters) + 2 at workshops (MATHAI and DRL). Featuring recent breakthroughs in AI for math! See👇
3
18
138
We open sourced Memorizing Transformers () and Block Recurrent Transformers () in Meliad!
Repo link:

Memorizing Transformer's camera ready is released!
Main updates:
1. Adding 8K memory ~ 5X-8X larger model parameters.
2. You can easily turn a pretrained LLMs into a memorizing transformer! (4% of pretraining cost to obtain 85% of the benefit)


4
18
134
2
22
138
Memorizing Transformer's camera ready is released!
Main updates:
1. Adding 8K memory ~ 5X-8X larger model parameters.
2. You can easily turn a pretrained LLMs into a memorizing transformer! (4% of pretraining cost to obtain 85% of the benefit)

Thanks a lot to
@Yuhu_ai_
,
@MarkusNRabe
and Delesley Hutchins for their hard work of updating our ICLR paper on retrieval-augmented language modeling, aka "Memorizing Transformer"!
Here is a short thread on why we think this is important.
🧵 1/n
4
41
233
4
18
134
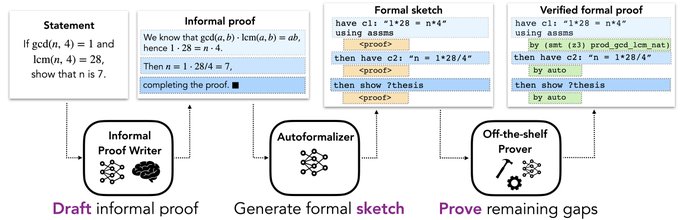
In May, we discovered that LLMs can autoformalize theorem statements:
In June, we showed that LLMs can solve challenging math problems with Minerva.
Now, we show LLMs can turn its generated informal proofs into verified formal proofs!🤯
What's next?😎


Large language models can write informal proofs, translate them into formal ones, and achieve SoTA performance in proving competition-level maths problems!
LM-generated informal proofs are sometimes more useful than the human ground truth 🤯
Preprint:
🧵
8
152
662
2
29
123
Excited to share this new work, which sheds light on the understanding of pre-training via synthetic tasks.
We did three experiments that iteratively simplify pre-training while still retaining gains.
Paper:
W. Felix Li,
@percyliang
.
1/

2
20
112
We discover that you can teach LLMs to solve longer problems *only* via in-context learning, instead of fine-tuning.
This is mind-blowing🤯🤯! -- that certain skills are hard to be encoded in model weights, but much easier to be acquired from the context.

🆕📜We study large language models’ ability to extrapolate to longer problems!
1) finetuning (with and without scratchpad) fails
2) few-shot scratchpad confers significant improvements
3) Many more findings (see the table & thread)
Paper: []
1/

4
40
239
2
16
105
We’re excited to announce the MathAI workshop at ICLR 2021 : On the Role of Mathematical Reasoning in General Artificial Intelligence. Now accepting submissions!
Submission Link:
Deadline: Feb 26, 11:59PM PST
1
17
94
Quanta magazine covers our two works on large language models for mathematical reasoning: Autoformalization and Minerva.
Together, they show a path how to improve reasoning capabilities of large language models for the future.

1
13
48
Can neural network agents prove theorems outside of the training distribution? We perform a systematic evaluation along 6 generalization dimensions with INT: an inequality theorem proving benchmark:
Joint work with Albert Jiang, Jimmy Ba,
@RogerGrosse
.
0
7
46
If you use K-FAC you only need to do 1 update (ACKTR), but if you use first order optimizer, you need to do 320 updates (PPO). AND 1 update by K-FAC still wins. This is what we (with
@baaadas
) find by comparing ACKTR vs. PPO vs. PPOKFAC.

0
12
38
The next figure shows a perfect translation of a grade school math problem by PaLM. This is remarkable because such a statement is completely out-of-distribution – no formal mathematicians are interested in formalizing grade school math problems ;)
4/

1
7
37
Compared to the 1st MATHAI workshop 1 year ago, the number of submissions this time almost doubled! Glad to see the field is growing rapidly 🙌
Also there are many mind-blowing works 🤯🤯 Stay tuned!
🚨👇Reminder that the submission deadline for the MATH-AI workshop at
#NeurIPS2022
is tomorrow -- Sep 30, 11:59pm PT.
Submit your recent works (e.g. ICLR submissions) if they are about Math&AI, reasoning, algorithmic capabilities!
0
4
20
1
3
36
Two papers in
@ICLR18
:
1. Short horizon bias in meta-learning optimization:
2. RELAX:
One invited to workshop:
3. Exploration in Meta-Reinforcement Learning

0
3
35
Our finding hence shows a very surprising capability of these models. They learned very general and transferable knowledge that allows them to work with low-resource formal language.
12/
1
5
33
Never focus too much on your short term reward, the optimal strategy in the long run might be completely opposite. Don't be fooled by short horizon bias. Both in life and meta learning.
0
17
35
Epic night with
@TheGregYang
@jimmybajimmyba
@ChrSzegedy
@PiotrRMilos
@s_tworkowski
@WendaLi8
@ericzelikman
@MarioKrenn6240
and many friends!!
#NeurIPS2022

4
2
33

Now, let the examples do the talking!
See the figure attached – Codex perfectly formalizes an IMO problem! It handles the negation “there is no function” by proof-by-contradiction. It understands the phrase “into itself” and correctly formalizes the co-domain of f.

1
4
32

I’m curious to find out how far we can push Minerva to theorem proving!
In the long run, I am expecting a great synergy between a strong natural language math model and an autoformalizer () to tackle challenging mathematical theorems!
3/

1
2
32
We propose STaR, a Self-Taught Reasoner. We start with few-shot prompting to generate the rationale for all the problems in the dataset.
We collect rationales that lead to the correct answer, and fine-tune the LLM further.
6/

1
0
29
1. The formal math data is very scarce. The whole Isablle proof script is only about 180MB. 2. There is almost zero aligned data between natural language and formal mathematics, whereas docstrings for language like Python are broadly available.
1
6
29
I'm glad to share that LIME is accepted at
#ICML2021
! One of the things I like about our publishing process is that there is always the next conference :) If you truly believe in your paper, then it will be published sooner or later! Just keep polishing 🛠️🛠️

@yaringal
We had a paper rejected with 8,7,6,6, with thorough reviews and lots of discussion.
The one-sentence reason for rejection -- that training on data is the wrong way to instill knowledge in an algorithm -- feels like something out of AAAI 1993.
14
24
201
2
2
29

Yeah I am stunned by this. Don't know what to think of it. We have worked so hard on this. Getting rejected by just one sentence meta-review, overriding all decisions made by the reviewers, just seems so crazy and unfair.
@yaringal
We had a paper rejected with 8,7,6,6, with thorough reviews and lots of discussion.
The one-sentence reason for rejection -- that training on data is the wrong way to instill knowledge in an algorithm -- feels like something out of AAAI 1993.
14
24
201
1
0
26
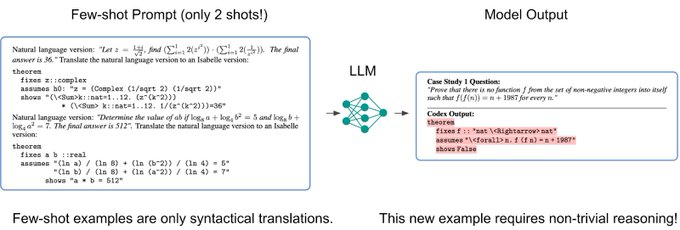
We show two randomly chosen few-shot examples in the prompt, from latex to formal math (Isabelle). Note that these two examples are merely examples of syntactical translations, without much sophistication in reasoning or natural language understanding.
2/

4
4
24
Why is this surprising? People know large language models can turn natural language descriptions into code. However, the existing known successes are limited to commonly used programming languages (e.g., Python). Formalizing mathematics is different for at least two reasons.
10/
1
4
25
We use Codex to formalize 3908 MATH problems. We then run expert iteration on these autoformalized statements. This allows us to achieve a new state of the art on the miniF2F theorem proving benchmark.
This is the first proof-of-concept of practical autoformalization!
7/

1
3
23
Most amazingly, Minerva shows an insane ability to generate logically consistent step-by-step solutions purely in natural language!
See more here:
2/

3
1
23
Can the model learn to formalize such problems if the prompt contains an example that explains the concept? We find if we add a tangentially related problem, then the model can formalize the “linear function” perfectly!
6/

2
3
22
Lastly, big thanks to my collaborators:
@AlbertQJiang
,
@WendaLi8
,
@MarkusNRabe
, Charles Staats,
@Mateja_Jamnik
,
@ChrSzegedy
!!!
1
3
23
Let’s also look at a failure case as well – in this case Codex fails to formalize the concept of “linear function”. It made up a name: linear f.
5/

1
4
22
🚨👇Reminder that the submission deadline for the MATH-AI workshop at
#NeurIPS2022
is tomorrow -- Sep 30, 11:59pm PT.
Submit your recent works (e.g. ICLR submissions) if they are about Math&AI, reasoning, algorithmic capabilities!

🚨Call for Papers🚨 Submission to the
#NeurIPS2022
MATH-AI Workshop will be due on Sep 30, 11:59pm PT (2 days after ICLR😆). The page limit is 4 pages (not much workload🤩). Work both in progress and recently published is allowed. Act NOW and see you in
#NewOrleans
!🥳🥳🍻



0
9
26
0
4
20
This is also a fundamentally iterative process. With a better model, it can generate better rationales, and that can be used to train a better model.
7/

1
0
20
Join us to work on reasoning with large language models!
🔥Internship Opportunity on Improving the Reasoning Capabilities of Massive Language Models🔥: solving challenging problems in areas such as mathematics, science, programming, algorithms, and planning.
Please see the following link for more info:
1
28
105
0
5
20
STaR shows many possible future directions. In general, any tasks that has an input and an output can be augmented with intermediate rationales.
Tasks that require multiple steps of reasoning can benefit from it the most, such as theorem proving, program synthesis etc.
10/
1
1
19
We further explore if the model can handle more advanced mathematics beyond competition problems. We find these models are surprisingly good at turning formal statements into natural language as well!
8/

1
3
18
In addition, for those problems the model answered incorrectly, we give the model a hint -- tell the model the right answer, and ask it to provide a justification.
8/

2
0
18
We see the model makes a jump in reasoning. Going from the definition, "for all x, if x in A -> x in B", to a more concise and abstract phrase "A is a subset of B". Also the same for "finite intersections" and "arbitrary unions". See examples in the figures!
9/

1
5
17




I’ve been working with Blueshift on reasoning with LLMs. It’s an amazing team with an ambitious goal, and a group of super smart, talented people.
🔥Opening in our team – Blueshift🔥
We are looking for a research engineer interested in extending the capabilities of large language models.
Learn more about the role & apply here:
Learn about our team:
Please retweet :-) 🙏
2
25
83
0
3
16
Excited to share this new work! We trained a GNN-based branching heuristics for model counting. It generalizes to problems of much larger sizes, achieving improvement over SOTA by orders of magnitude.


Can neural network agents improve wall-clock performance of propositional model counters? We present Neuro#, a neuro-symbolic solver that can do that:
Joint work w/
@gilled34
,
@Yuhu_ai_
,
@cjmaddison
,
@RogerGrosse
, Edward Lee, Sanjit Seshia, Fahiem Bacchus
0
3
18
0
1
16

A new work with Emilio and other CMU collaborators. The goal is to meta learn exploration. Instead of using a single agent to explore, which would result in a long horizon problem, we have multiple agents explore simultaneously, sharing findings from one to another.

0
0
15
@ericzelikman
Human reasoning is often the result of extended chains of thought.
We want to train a model that can generate explicit rationales before answering a question.
The main challenge: most of the datasets only contain a question answer pair, but not the intermediate rationales.

1
0
14
Check out:
Paper link: (ArXiv will follow tonight)
Google blog post:
Sample explorer:
4/
1
0
14
Great work!!

Autoformalization with LLMs in Lean... for everyone!
The chat interface for autoformalizing theorem statements in Lean built by myself and
@ewayers
is now publicly available as a vs-code extension.


7
30
162
0
0
12
Last but not least, if you are interested in AI for math / reasoning / LLMs, come visit the MATH-AI workshop on Dec 3:
🚨We are organizing the 2nd MATHAI workshop at NeurIPS!
Check it out if you're interested in AI for math, and machine reasoning in general🤯!
We have a great lineup of speakers & panelists!
See more in call for papers: 👇
3
30
150
0
1
13
Lastly, I want to thank my amazing collaborators, Eric Zelikman
@ericzelikman
, and Noah Goodman for this exciting work!
11/
2
1
13
If we can collect the instructions used by humans to fix the formalization, that'd be very valuable.
@XenaProject
@TaliaRinger
.
Autoformalization with LLMs in Lean!
@zhangir_azerbay
and Edward Ayers built a chat interface to formalize natural language mathematics in Lean:
Very impressive work!
5
49
193
1
1
13
"Exploring Length Generalization in Large Language Models" accepted as an *Oral presentation*! We discovered that certain skills are hard to be encoded in model weights, but much easier to be acquired from the context.
5/ 10
We discover that you can teach LLMs to solve longer problems *only* via in-context learning, instead of fine-tuning.
This is mind-blowing🤯🤯! -- that certain skills are hard to be encoded in model weights, but much easier to be acquired from the context.
2
16
105
1
0
12
We performed experiments on the arithmetic problem (from Nye et al.), and CommonsenseQA. On CQA, STaR with GPT-J attained 72.3%, which was on par with the result obtained by GPT-3 (73%), finetuned to directly output the final answer.
9/


1
0
11
Instead, we ask: can we leverage large language models(LLMs)’
pre-existing knowledge to improve its reasoning?
5/
1
0
11
People need RELAX!

RELAX! Our new gradient estimator handles discrete variables and black-box functions. Now going to try hard attention, latent graphs, and more RL problems. by amazing students
@wgrathwohl
@chlekadl
@Yuhu_ai_
@geoffroeder

3
151
447
0
4
11
@iandanforth
Hi Ian, thanks for pointing out the Abstraction and Reasoning Challenge. We will take a closer look to see if our model fits!
1
0
12
1
0
12
@ChrSzegedy
@MarkusNRabe
@spolu
@jessemhan
@GuillaumeLample
@f_charton
@AlbertQJiang
@WendaLi8
@DanHendrycks
would love to see you there!
1
0
11
Many thanks to all of my students / collaborators
@AlbertQJiang
@cem__anil
@ericschmidt
@JinPZhou
@s_tworkowski
, Felix Li, Imanol Schlag,
@WendaLi8
, Michał Zawalski, mentors
@ChrSzegedy
@percyliang
@bneyshabur
, and wonderful teammates at N2formal, Blueshift for a fruitful year!
1
0
10
LLMs autoformalize natural language mathematics into formal math code, the first proof-of-concept for autoformalization🤯:
1/10
After showing a few examples, large language models can translate natural language mathematical statements into formal specifications.
We autoformalize 4K theorems as new data to train our neural theorem prover, achieving SOTA on miniF2F!
1/
Paper:
5
110
459
1
0
11
This idea is straightforward, and we were surprised that no one has tried before. Then we realized it is not trivial to make it work.
1
0
10
Fun fact: Hu et. al. () found that most of the previous successful neural methods exploited a short-cut solution. After removing the dataset bias, those methods suffered a lot (e.g., CoPINet went from 91.4% -> 46.3%). SCL was not affected at all.
(4/n)
1
0
11
One solution is to use human labels [Rajani et al. ]. But this is costly and hence not scalable. In addition, the model cannot improve beyond human labels.
3/

1
0
10
Our code for "Understanding Short-Horizon Bias in Stochastic Meta-Optimization" is released at .
0
5
10
Into the future, we believe it may be possible to develop synthetic tasks that outperform natural pre-training on some downstream tasks: the complexity of existing natural data is fixed, while in some sense the complexity of fully synthetically generated data is infinite.
10/
2
1
10
SCL is designed to discover the compositional structures of the data. In RAVEN, It learns to discover the compositions of objects, attributes, and relationships. The figure shows an example where SCL learns the concept of “size”.
(2/n)

1
0
10
Camera ready version on short-horizon bias, to appear in
#iclr2018
. It tells you why you should always start with aggressive learning rate and then decay. Meta-optimization is hard because the objective is biased. A fantastic collaboration with
@mengyer
,
@RogerGrosse
and Renjie.

1
3
10
Going back to my hometown and give a talk at 2050 Yunqi Conference!
2
0
10
I was told many cool people are at MATHAI workshop😎

Math-AI workshop starting at room 293-294 with
@lupantech
@wellecks
@Yuhu_ai_
@HannaHajishirzi
@percyliang
#NeurIPS2022
#NLProc

0
4
28
0
2
10
Minerva attains grades higher than average high school students and surpasses timeline prediction by 3 years:
3/10
Very excited to present Minerva🦉: a language model capable of solving mathematical questions using step-by-step natural language reasoning.
Combining scale, data and others dramatically improves performance on the STEM benchmarks MATH and MMLU-STEM.
108
1K
8K
1
0
9
Great opportunity to work on LLM reasoning with amazing people!
If you are interested in solving challenging multi-step reasoning problems with LLMs, join us!
We have an opening for a Research Scientist position at Blueshift!
Learn more about the role & apply here:
Learn about our team:
1
10
63
0
1
9
"Fast and Precise: Adjusting Planning Horizon with Adaptive Subgoal Search" accepted to DRL workshop:
10/10

Subgoal search is an appealing class of methods to solve complex tasks by considering intermediate subgoals that advance towards the goal. Is it beneficial to vary the subgoal distance (and how)? Turns out the answer is yes:
A thread:
1/8
2
7
18
1
0
9
Another solution is to use in-context learning to induce rational generation [Nye et al. , Wei et al. ]. But few-shot performance significantly underperforms finetuning.
4/

1
0
8
A very cool work on natural language theorem proving from
@wellecks
et. al.!
It's nice to see lots of observations are shared between informal and formal math proving: the importance of premise selection, failure cases etc.
Looking forward to combine the best of both worlds!

New paper:
Theorem proving in natural mathematical language- the mix of symbolic and natural language used by humans- tests reasoning and plays a central role in mathematical education.
Can language models prove theorems & help us when we're stuck? 1/N


3
61
212
1
1
9
Looking forward to our discussion on Mathematics and AI tomorrow at
#ICML2022
!

We're also very excited to be hosting a panel discussion on the nexus of AI and Mathematics from 3:45-4:30pm ET featuring
@Yuhu_ai_
@PetarV_93
@TaliaRinger
and
@ibab_ml
!
1
2
7
1
4
8
Extrapolating to more difficult problems via equilibrium models:
9/10
🆕📜When can **Equilibrium Models** learn from simple examples to handle complex ones?
We identify a property — Path Independence — that enables this by letting EMs think for longer on hard examples.
(NeurIPS) 📝: []()

3
35
116
1
0
9
Happening now!
ICLR virtual site:
Gather town:
Schedule:
Accepted papers:


We’re excited to announce the MathAI workshop at ICLR 2021 : On the Role of Mathematical Reasoning in General Artificial Intelligence. Now accepting submissions!
Submission Link:
Deadline: Feb 26, 11:59PM PST
1
17
94
0
0
7
Very nice work! Automating prompt engineering for the win!

APE generates “Let’s work this out in a step by step way to be sure we have the right answer”, which increases text-davinci-002’s Zero-Shot-CoT performance on MultiArith (78.7 -> 82.0) and GSM8K (40.7->43.0). Just ask for the right answer?
@ericjang11
@shaneguML


3
14
101
0
1
9
By learning compositional structures, it can even generalize to unseen analogies. E.g., After learning (“color”, “constant”), and (“size”, “progression”), the model can generalize to (“color”, “progression”).
(3/n)
1
0
7
LLMs are not good at premise selection in theorem proving due to limited context window. Thor addresses this by combining symbolic AI (sledgehammer) to achieve SOTA:
6/10
Language models are bad at retrieving useful premises from large databases for theorem proving, mainly because they're limited by a small context window. We use symbolic tools to overcome this difficulty, boosting proof rates from 39% to 57%.
Thor:
1/

3
12
56
1
0
8
Three experiments iteratively simplify pre-training, shedding light on the understanding of pre-training via synthetic tasks.
8/10
Excited to share this new work, which sheds light on the understanding of pre-training via synthetic tasks.
We did three experiments that iteratively simplify pre-training while still retaining gains.
Paper:
W. Felix Li,
@percyliang
.
1/
2
20
112
1
0
8
We recently worked on extracting datasets for training neural theorem provers for Lean. Our model can prove 35.9% test theorems.
Check out the following Demo! We created a tool for querying a 3B GPT model when writing math proofs in VS code.
#InteractiveNeuralTheoremProving

1
1
8