

Szymon Tworkowski
@s_tworkowski
Followers
5,086
Following
544
Media
19
Statuses
544
research @ xAI | prev. @GoogleAI @UniWarszawski | LongLLaMA | long-context LLMs and math reasoning | scaling maximalist
Palo Alto
Joined November 2021
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Wizkid
• 242906 Tweets
Davido
• 220658 Tweets
FAYEYOKO BTS 1ST FANMEET
• 113034 Tweets
からくりサーカス
• 105539 Tweets
ケンタッキー
• 104195 Tweets
BTS NUNEW 1ST CONCERT EP2
• 101002 Tweets
ニンテンドーミュージアム
• 90217 Tweets
Supreme God Kabir
• 78014 Tweets
WEDance WITH JARLETTE
• 74814 Tweets
#リゼロ
• 55533 Tweets
青木選手
• 51499 Tweets
引退試合
• 50763 Tweets
フォーエバーヤング
• 50596 Tweets
ヤクルト
• 40275 Tweets
青木さん
• 30955 Tweets
Alcaraz
• 28834 Tweets
#Aぇヤンタン
• 24154 Tweets
Cassper
• 21841 Tweets
Shana Tova
• 21630 Tweets
ラムジェット
• 17844 Tweets
שנה טובה
• 16153 Tweets
ダービー
• 14225 Tweets
ジャパンダートクラシック
• 13763 Tweets
SPILL THE FEELS TRACK LIST
• 10960 Tweets




















Pinned Tweet

Introducing LongLLaMA 🦙, an unlimited-context version of OpenLLaMA fine-tuned at 8k & capable of extrapolating to 256k tokens!
We train it using our new Focused Transformer 🎯 technique (FoT). No degradation on short context, drop-in compatibility & Apache 2.0 license 🔥🔥
🧵

37
224
830

✨Announcing LongLLaMA-Code 7B!✨
Have you wondered how GPT3.5 obtained its capability?
Are base models of code better reasoners? 🤔
We continue pre-training CodeLLaMA on text & code to improve reasoning 🧠
Bonus: 3x faster inference @ 16K context, using Focused Transformer 🎯

5
56
310
Honored to win Poland's best CS master thesis prize for my work on long context LLM w/
@PiotrRMilos
🎉
Can't make it to
#NeurIPS2023
😭, but
@CStanKonrad
will present LongLLaMA paper tmr!
Thu 10:45, Poster
#326
, Session 5
Interested in extending context to 256K? Come and say hi!

3
18
71

✈️ Flying to Vienna for
#ICLR2024
! DM me if you want to chat about LLM reasoning, long context or any other topics :)
1
47
99
It’s been a blast to work on Grok 2 & Grok 2 mini with the team & push it to the frontier! 🚀


9
46
211
A glimpse over our recent progress - exciting things to come!
5
3
141


Today at Inflection we are announcing some important updates. A new phase for the company begins now.
Read more here:
69
91
597
3
5
83
Exciting job opportunity! Hiring CUDA engineers 🧙
Join us & run your code on 100k GPUs 🚀

1
5
83
gpus go brrrrr 🧑🍳🧑🍳

how june started & how it’s going
come 🧑🍳 with us at xAI & 𝕏 if you like building & running the biggest computers in the world!


1K
2K
12K
2
0
75
Thrilled to be a first-gen MSc! 🎓 Just defended my thesis on ‘Fine-tuning Large Language Models for Long Context Utilization’ at the University of Warsaw.
Check out our recent work if you’re curious how to extend context of LLaMA🦙 up to 256K and remain efficient at inference!

5
8
66
Extremely lucky to get Focused Transformer (FoT) accepted at
#NeurIPS2023
🎉! It is my first first-author paper at a big conference, which makes this moment even more special🎇
Feel free to check our recent LongLLaMA release using FoT!
Unthinkable with ACL arxiv embargo policy
✨Announcing LongLLaMA-Code 7B!✨
Have you wondered how GPT3.5 obtained its capability?
Are base models of code better reasoners? 🤔
We continue pre-training CodeLLaMA on text & code to improve reasoning 🧠
Bonus: 3x faster inference @ 16K context, using Focused Transformer 🎯
5
56
310
4
13
59
sus🍓🍓
Join us
1
2
52
This is joint work with my awesome collaborators
@CStanKonrad
,
@MikolajPacek
,
@PiotrRMilos
from
@IDEAS_NCBR
, and
@Yuhu_ai_
,
@hmichalewski
from
@GoogleAI
!
Colab:
GitHub:
Checkpoint:

3
4
41
FoT is a simple modification of the vanilla Transformer - instead of increasing context window length in all layers, we access previous windows of the training batch (containing tokens from the current and other docs) in a subset of attention layers called memory layers.

1
3
31
📄
We show that LMs suffer from the "distraction issue" i.e. struggle to handle multiple documents in one context. Our Focused Transformer training objective (FoT) alleviates this by attending to tokens from the same doc (positive) and other docs (negative)

1
0
30
Never thought prompt engineering could be this fun until
#PromptIDE
! Check it out!
Announcing the xAI PromptIDE
The xAI PromptIDE is an integrated development environment for prompt engineering and interpretability research.
It accelerates prompt engineering through an SDK that allows implementing complex prompting techniques and rich analytics that
visualize
1K
1K
9K
2
14
27
Unlike prior work focusing on position encodings, we follow and achieve extrapolation by simply keeping positionals constant for memory tokens, while leaving the local context intact. This makes LongLLaMA backward compatible with LLaMA inference code.

1
1
27
@Yampeleg
In our Focused Transformer paper we propose a contrary view, which means packing multiple examples in one context can be beneficial if you optimize for long-context capabilities. This is because the model learns to ignore irrelevant tokens in context.

1
3
24
Surprisingly, we observe that apart from expected gains in multi-document settings, FoT (d=2) also improves perplexity on long, single documents, compared to training on just positive documents (d=1). We find this important, as the amount of long-context training data is limited.

4
0
21
We improve GSM8K from 13% to 17% after 35B tokens without in-distribution training.
We also publish Focused Transformer code for long-context pre-training, used in LongLLaMA!
GitHub:
HF (checkpoint):
arXiv:
1
2
20
Colab:
HF:
Code:
We also announce LongLLaMA-v1.1, a 3B base model trained for 5B 32K context tokens with our FoT method: We improved long-context and code (12% HE pass
@1
) capabilities
1
3
19
#ACL2023
is over!
It was so exciting to talk LLMs with y'all!
I hope that some of these insights will shape the future of large language models. Hopefully see you at
#NeurIPS2023
!

0
3
18
📄
We show that despite poor performance in solving competitive programming problems, LLMs exhibit a strong capacity in describing and explaining solutions. We try to disentangle the contribution of reasoning and coding in solving these problems by LLMs.
2
1
16
Thanks to using Focused Transformer (FoT), our inference is > 3x faster than the baseline at 16K tokens. We only use long-range attention in a subset of layers (3 out of 32). It is only 10% of the vanilla attention FLOPs. See by
@harmdevries77
for details

1
2
15
We obtain exactly the same HumanEval perf as CodeLLaMA, and improve MMLU from 37.2% to 40% (scoring setup, no CoT) and gsm8k-py from 23.4% to 24.9%. We also outperform LLaMA2.
SFT could unleash the full potential of this model; stay tuned for instruct version - coming soon!

1
1
12
LongLLaMA-Instruct was initialized from LongLLaMA-v1.1 32K and fine-tuned with context of just 2048(!) for 0.07 epochs. We observe that despite short-context fine-tuning, we don't lose the long-context capabilities of the base model (see by
@Francis_YAO_
).

1
2
12
As indicated by , current LLMs are no good at solving competitive programming problems outside of their training distribution, achieving a very low rating of 392 reported by
@OpenAI
, corresponding to barely 5th percentile of human competitors (avg. ~1450)

I suspect GPT-4's performance is influenced by data contamination, at least on Codeforces.
Of the easiest problems on Codeforces, it solved 10/10 pre-2021 problems and 0/10 recent problems.
This strongly points to contamination.
1/4


80
688
4K
1
0
12
CodeLLaMA is a great model, but apparently, it degrades GSM8k from 42.2% to 32.7% at 34B size. Is there a reason for not using a more balanced mixture during fine-tuning, instead of 85% code? I feel like the community might close this gap very soon :)

CodeLlama -- a version of Llama2 that was fine-tuned for code tasks is live now. Available in 7B, 13B and 34B.

17
205
952
1
5
11
Thrilled to be spotlighted in an interview with
@AICoffeeBreak
presenting my work at
#ACL2023
! Dive into the dialogue at 1:26 to catch my spicy 🌶️ insights on LLMs for code👨🏻💻, competitive programming, and the "understanding" of these models. Don't miss it!

We summarized the
#acl2023nlp
Toronto conference for you with some poster recordings and author interviews! 👇
🎬
Featuring
@s_tworkowski
@jasivan_s
@kundan_official
@ebugliarello
@leoduw
@_florianmai
@franz_nowak
@PaulDarm
@MoritzPlenz
and
@JayAlammar
👏

0
23
54
0
4
10
The base model is fine-tuned from OpenLLama v2 and released on a fully commercial Apache 2.0 license. We used a combination of OpenOrca and for SFT. We open-source the code to facilitate efficient instruction tuning on your own data
1
5
11
Using insights from designing our prompt for the backward reasoning process, we propose a structured prompt that boosts the solve rate of these models just from problem statement to code (the original task, without golden explanations in the input) from 6.1% to 9.1% for pass
@10
.

1
0
11
In human evaluation, we observe gpt4 is better than gpt3.5 at understanding the main idea, but there's still a long way to go. We hypothesize our backward explanations could be useful to improve model's forward reasoning process with techniques such as


Language models can dramatically improve their reasoning by learning from chains of thought that they generate.
With STaR, just a few worked examples can boost accuracy to that of a 30X larger model (GPT-J to GPT-3).
W.
@ericzelikman
, Noah Goodman
1/
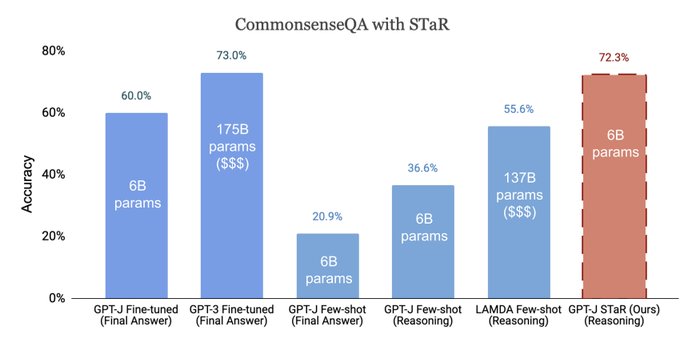
8
95
532
1
0
11
Instead of solving the problem directly just from its NL description as LLM input (NL to code), we study the backward process of extracting the idea from a correct code solution. We show that our extracted rationales can significantly boost the solve rate of LLMs on CodeContests.

1
2
11
The session is happening now! For those who missed the poster 😉

1
1
10
The Focused Transformer and LongLLaMA are joint work with my amazing collaborators
@CStanKonrad
@MikolajPacek
@Yuhu_ai_
@hmichalewski
@PiotrRMilos
! Stay tuned for future releases of larger models (7B, 13B) fine-tuned for more long-context tokens!
0
3
10
LongLLaMA-Code was done with a small amount of 35B pretraining tokens (mix webtext & code) to improve reasoning
While still exploratory, these results suggest base models of code are a promising avenue for enhancing reasoning capabilities
@Francis_YAO_
[]

1
1
10
How do math LLMs perform beyond academic benchmarks 🤔? Check it out!

Which LLMs are generally good at math and which are overfitting to benchmarks?
With the release of Grok,
@xai
evaluated several closed models on a Hungarian national finals math exam which was published after the models were trained. This means it is impossible to train on or


24
84
559
0
3
8
Finally a 7B long-context model that you can actually run in an academic budget (single free Colab GPU)?
Try to chat with it about papers & code!

🎇Introducing LongLLaMA-Code 7B Instruct 🦙!🎇
A step towards an open-source alternative for Claude 2.
Run in 🆓 Colab (8bit).
🗨 Answers questions about 📑 papers and >_ code.
SOTA 7B reasoning :
🎓 GSM8K: 65% 🐍 PoT 0-shot, 42% std CoT 8-shot setting.
>_ 37%: HumanEval

3
44
261
0
2
9
@Francis_YAO_
Perplexity/LM loss gains (compression) seem pretty clear, e.g. from Memorizing Transformers paper, and context could be seen as an additional scaling dimension. Imo it's harder to quantify benefits from application of LCLMs, due to lack of reasonable downstream benchmarks 🤔

0
0
9
In the colab demo we try to feed the entire Focused Transformer paper into context and ask questions about it, achieving reasonable results. In the same colab, we also provide a chat interface to interact with the model!

1
1
9
This was an amazing project primarily done by Jierui Li from UT Austin, with my help & advised by Yingying Wu and Raymond Mooney. Acknowledgements to
@IDEAS_NCBR
for making the in-person presentation possible. For me, the project was huge fun, bringing back NOI and ICPC memories
1
1
9
LongLLaMA v1.1 shows competitive performance on long-context retrieval tasks (see
@nelsonfliu
), without degradation after instruction tuning. Also, the short-context performance on downstream tasks improves due to instruction tuning: 55% vs. 53% on lm-eval

1
1
8
Exploring the roots of the famous "6ND" formula, I stumbled upon this insightful post by
@DBahdanau
about LLM training compute estimation 👉 . Still on point!
Wondering what >64k contexts/flashattn bring to the table 🧐, does FFN still dominate attention?

1
1
7
@ayaka14732
Great work! How does this compare to EasyLM that I’m currently using to finetune llama models in jax?

2
1
7
0
0
7
This is a joint work with my amazing collaborators
@CStanKonrad
@PiotrRMilos
@hmichalewski
! Many thanks also to
@p_nawrot
and
@Francis_YAO_
@S_Jaszczur
for helpful suggestions!
1
2
7
arXiv:
HF:
Blogpost: coming soon! 🔥🔥

1
3
5
@GoogleAI
@MLCommons
Excellent initiative! Hope the evaluation will avoid common pitfalls, e.g. the ones described in
0
2
6
I'm presenting this paper on explaining competitive programming solutions with LLMs at 1:30pm (in 10min) in the big poster hall
#ACL2023
- number 24, drop by and say hi!
0
2
6
@Francis_YAO_
There are very few evaluation datasets for long-context LLM. shows comparison between open-source and Claude, which is pretty miserable - still a long way to go for OSS 🤔, but developing a leaderboard like MT Bench for LCLM would be immensely useful!

0
0
5
@JohnGal43951639
@Yampeleg
The memory overhead from longer context is much smaller than for standard models since we only access k/v from the extended context in a tiny fraction of layers (3 out of 26). With a simple trick we fit 32K context into a colab GPU (see the HF repo):
0
0
5
Nothing works better for chilling out than google recalling your compute in the middle of training, 2 days before a planned release. You can just watch netflix or write some codeforces round 🤣


Nothing works better for concentration than renting high cost compute.
You've to use every minute well.

1
0
12
2
1
4
Our model is also significantly faster at inference due to only having a subset of layers (3/26) attend to tokens beyond the local context window. LongLLaMA-Instruct is a competitive 3B model you can run on a colab or locally and use as a long-context chatbot (see colab demo!)
1
0
4
Best poster design at the entire
#EMNLP2023
😎, not mentioning the awesome technical contribution that
#nanoT5
has made, check it out!


1
0
4
0
0
3
Kudos to
@PiotrRMilos
@CStanKonrad
@Yuhu_ai_
@marek_nomagic
@MikolajPacek
@LukeKucinski
and others for making that happen!
1
2
3
@haozhangml
How about OpenLLaMA by
@younggeng
? The trajectory was published along with reproducible source code.
0
0
2
@4evaBehindSOTA
@p_nawrot
@CStanKonrad
The FoT pretraining code is written in JAX; we're planning to release it after LongLLaMA v2 release - stay tuned :))
No plans to implement Focused Transformer pretraining in PyTorch, so if you'd like to learn, doing this could be a great exercise and useful for the community!
1
0
3
@PiotrRMilos
I just feel lucky there are conferences allowing to put papers on arXiv and make an impact way before acceptance, which is not true for some other conference 😉. Thanks a lot for the entire team for the extremely hard work!
@CStanKonrad
@MikolajPacek
@Yuhu_ai_
@hmichalewski
0
0
3
Special thanks to
@keirp1
for providing immensely valuable suggestions about the pre-training data! 🧡
0
5
3
@QQ21619296
@labmlai
@PyTorch
@UniWarszawski
@OpenAI
@GoogleAI
@hmichalewski
@lukaszkaiser
@Yuhu_ai_
@ChrSzegedy
You can see further efficiency improvements after more complex shortening is applied in the follow up work by
@p_nawrot
:)

0
1
3
Amazing initiative with COLM 🎉! One more step for inclusivity could be making the location accessible to all 🌍. It'd cut down on the visa hassle 🛂 that often plagues U.S. conferences (e.g.
#NeurIPS2023
) . Any thoughts on the potential location? 🙂

Introducing COLM () the Conference on Language Modeling. A new research venue dedicated to the theory, practice, and applications of language models.
Submissions: March 15 (it's pronounced "collum" 🕊️)

34
434
2K
1
3
3
@KujoJot32604166
The current state is roughly here:
We are working towards better pretraining data for long-context, and very likely to release something new in Oct/Nov :)
1
0
2
@OfirPress
Do they finetune at 100k actually? I thought they finetune until 16k and then try to extrapolate, but maybe i misread sth
0
0
2
Finally! 🎉🎉🎉

ACL has removed the anonymity period.
This means that ACL submissions can be posted and discussed online at any time, although extensive PR is discouraged.

5
86
353
0
0
2
@tugot17
@dylan522p
@mvpatel2000
@abhi_venigalla
Pretraining data mixture for llama2 is not public ig, but it doesnt seem to be qualitatively better than llama1, given it’s perf / train tokens. I think mistral used much more code in the mixture, which is likely to help reasoning benchmarks (although still speculative)
0
0
2
0
0
1
@AlbertQJiang
Congrats!! The base model seems very strong, looking forward to the community's creativity in doing SFT :)
1
0
2
@tongshuangwu
@kgashteo
太好了!Rarely seeing „xD” being used here (it is very popular in my home country), curious where you learn that from :)
0
1
2
@atgambardella
Wish I could motivate myself to study Mandarin 2h daily.. typically it’s 30min at most, extremely good job on your side and fingers crossed you master Japanese!
1
0
2
@4evaBehindSOTA
@p_nawrot
@CStanKonrad
The code would have been much more performant in pytorch (flashatt etc), its just compute constraint that I only have TPU compute to pretrain on, so pytorch is not useful for me, but def would be for the community!
1
0
1
@Francis_YAO_
@denny_zhou
I tried to reproduce zeroscrolls gpt4 results but unfortunately it seems difficult. :(
0
0
1
@minimario1729
@terese14711217
@AICoffeeBreak
My suspicion is that openai’s gpt has already seen multiple epochs of solutions (based on its pre-cutoff solve rate) & unclear amount of epochs of editorials. You can check out our work to see how gpt-generated editorials/rationales could boost performance.
1
0
1
@Yampeleg
Specifically, in Figure 6 we study what happens if we train the model on multiple examples, compared to just same example. Perplexity on long, single documents gets better for a model that can sould see multiple unrelated examples in context, which we find quite surprising.
1
0
1
@zhu_zhaocheng
Pretty much, im interested in learning mandarin these days :) just seen in what context my friends use the fake smile and do the same myself hhh
0
0
1
@artificial_bug
@CStanKonrad
@abacaj
Also really excited about the possibilities of running this on a free colab instance :) make sure to check out our work 😀
0
0
1
@KujoJot32604166
Also, we are working on an instruction-tuned version of LongLLama-Code 7B. This is supposed to be relased early Oct, and from preliminary results we expect it to be pretty good :) stay tuned!
0
0
1
@atgambardella
rn on my side it’s mostly memorising basic vocab and learning to distinguish between tones hhh but I hope I can start listening to some comprehensible input/read simple stuff soon like I did with European languages
1
0
1
@dylan522p
@mvpatel2000
@abhi_venigalla
You mean training time flops? I guess they have much higher quality data than llama2 so I wouldn’t be too surprised if they do even 2x better in terms of training flops for achieving same downstream perf :p
2
0
1
@laion_ai
I dont think it can compare even to gpt3.5 in terms of math/coding/reasoning performance. Looking forward to their paper and gsm8k & humaneval numbers. Given their data mixture, is not looking promising ngl :))
2
0
1
@abacaj
I totally agree with that - training data is the most important for long context utilisation. I hope some upcoming ICLR submission will discuss this question!
0
0
1