
Mihir Patel
@mvpatel2000
Followers
3,725
Following
439
Media
96
Statuses
1,288
Research Engineer @MosaicML | cs, math bs/ms @Stanford
Joined November 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
SEVENTEEN
• 1224152 Tweets
Taylor
• 216490 Tweets
Carat
• 77116 Tweets
FELIP TAKES ON BBPHSTAGE
• 67873 Tweets
#TimnasDay
• 64460 Tweets
オーストラリア
• 60151 Tweets
#サッカー日本代表
• 45425 Tweets
#バナナサンド
• 35695 Tweets
オウンゴール
• 27773 Tweets
最終予選
• 25815 Tweets
ミンギュ
• 25205 Tweets
金木犀の香り
• 23376 Tweets
OHM FOR DEVY
• 21490 Tweets
Zaplana
• 20816 Tweets
うさぎだらけくじ
• 18719 Tweets
ジョシュア
• 18686 Tweets
ドギョム
• 17891 Tweets
スングァン
• 17857 Tweets
كوريا
• 15355 Tweets
Asnawi
• 14631 Tweets
Kamran Ghulam
• 14251 Tweets
Witan
• 13654 Tweets
Shayne
• 13587 Tweets
نعيم قاسم
• 12397 Tweets
#daihyo
• 12124 Tweets
中村敬斗
• 11602 Tweets
Last Seen Profiles





















Gemini is so good. SO much better and SO much faster than GPT-4 🤯. I'm sold -- switching over


88
79
1K
You know your CTO (
@matei_zaharia
) got the dog in him when the company is worth 40B+ and he's still looking at data and labeling

9
27
625
My friends at...
Google Deepmind fear OpenAI
OpenAI fear god
Anthropic fear themselves
16
21
565
TLDR from Google IO: Google is so back.
Incredible suite of releases, including AI in products, new language models, and a host of new capabilities outside of LLMs.
A few highlights I found cool!

10
24
383
Evaluating LLMs is really hard! At
@MosaicML
, we rigorously benchmark models by asking for vegan* banana bread recipes, baking them, and ranking on taste
*we currently do not penalize for responding with non-vegan, but this will change in future

13
27
329
🚨 Announcing DBRX-Medium 🧱, a new SoTA open weights 36b active 132T total parameter MoE trained on 12T tokens (~3e24 flops). Dbrx achieves 150 tok/sec while clearing a wide variety of benchmarks. Deep dive below! 1/N

15
31
307
We're back 😈. Stable diffusion in $50k, and all the code is open source . Plus, this time I finally convinced
@jefrankle
to give me enough GPUs to train it, so we have the model to prove it.

Two weeks ago, we released a blog showing training Stable Diffusion from scratch only costs $160K. Proud to report that blog is already out of date. It now costs 💸 $125K 💸. Stay tuned for more speedup from
@MosaicML
, coming soon to a diffusion model near you!
3
17
206
6
33
288
Two weeks ago, we released a blog showing training Stable Diffusion from scratch only costs $160K. Proud to report that blog is already out of date. It now costs 💸 $125K 💸. Stay tuned for more speedup from
@MosaicML
, coming soon to a diffusion model near you!

How much does it take to train a Stable Diffusion model from scratch? The answer: 79,000 A100-hours in 13 days, for a total training cost of <$160k. Our tooling reduces the time and cost to train by 2.5x, and is also extensible and simple to use.
1
26
119
3
17
206
🚨New🌟blog✍️ on ⏩ maximizing🌙 FLOPS 🚀
Training large models requires maximizing flops/GPU, especially at scale. Excited to share a few of the cool tricks in thread👀. 1/N

6
36
191
Remember when everyone was freaking out about AMD because
@realGeorgeHotz
quit on it? Turns out it works straight out of the box on
@MosaicML
's stack on real LLM workloads, and we have the receipts

50-50 odds I could do this in a few hours. I've heard people get pretty good MFU for LLMs on the
@MosaicML
stack w AMD gpus.
My uninformed take: AMD is aggressively prioritizing PyTorch support (just swap backend), which is why
@realGeorgeHotz
had a brutal time -- custom is hard
2
4
30
11
15
186
I have found a high correlation between researchers and degenerate gamblers.
I would tag the appropriate coworkers but it's the entire team

In AI research there is tremendous value in intuitions on what makes things work. In fact, this skill is what makes “yolo runs” successful, and can accelerate your team tremendously.
However, there’s no track record on how good someone’s intuition is. A fun way to do this is
20
36
469
7
7
188
At
@DbrxMosaicAI
, we (and our customers! we actually make money) train custom LLMs for specific use cases. Today, we're sharing a large part of our infra stack and many of the tricks we use to get reliable performance at scale. (1/N)

2
28
185
🚨Open Source Drop🚨
Databricks is adopting MegaBlocks, and we're releasing the MegaBlocks integration into LLMFoundry. This is a critical component in our Dbrx training stack, and we're super excited to bring MoE training to the community (1/N)

3
34
179
7B, 1T tokens, llama-quality, 65k+ context length variant, chat variant, open source, commercial license
The crazy part is how easy it was.
@abhi_venigalla
wanted it,
@jefrankle
got the GPUs, and someone clicked run. 9 days of us doing normal work and watching the loss go down



MPT is here! Check out our shiny new LLMs, open-source w/commercial license. The base MPT-7B model is 7B params trained on 1T tokens and reaches LLaMA-7B quality. We also created Instruct (commercial), Chat, and (my favorite) StoryWriter-65k+ variants. 🧵
28
159
778
5
22
157


When Noam speaks, the AI world listens. Super cool blog post with a ton of details -- a few things I found interesting (1/n)

Character AI is serving 20,000 QPS. Here are the technologies we use to serve hyper-efficiently. [ ]
32
197
1K
1
10
151
After 5 years in the bay / SF, I'm moving! ✈️
Next stop NYC. Come say hi 👋
9
0
141
Gemma 2 is out with 9b and 27b! A few things I really liked in tech report:
On pretraining:
- GQA (finally lol)
- interleaving global attn w local (but 4k vs. 8k? it feels like it should support longer and was kneecapped...)
- 16x expansion ratio (very wide!)
(1/n)

4
11
139
In SF, AI insiders get invited to EA sex parties
In NYC, AI insiders get invited to Thursday bagels
If you know, you know
14
2
134
I've maintained employee flow significantly impacts technological lead. When OpenAI was a vortex for talent and DeepMind was hemorrhaging talent, OpenAI seemed untouchable and everyone knew what GDM was doing
Flows return to equilibrium though...
3
1
127
Fun collaboration between
@DbrxMosaicAI
and
@PyTorch
team! We've been working hard to scale MoEs and PyTorch distributed to thousands of GPUs, and this is a great summary of a lot of the cool things we've added to PyTorch.
Quick rundown (1/N)

Training MoEs at Scale with PyTorch 🔥
In our latest post, we show how we scale to over three thousand GPUs using PyTorch Distributed and MegaBlocks, an efficient open-source MoE implementation in PyTorch.
Check it out:
0
68
352
4
26
121

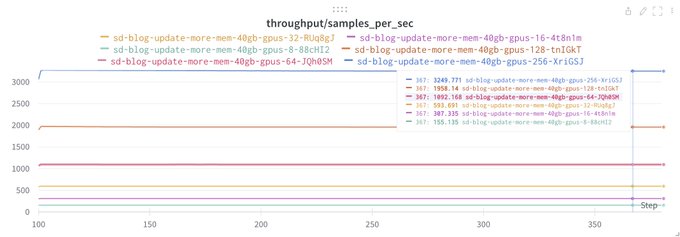
Wanted to release Composer v0.14.0 last night, but my CI/CD cluster got airstriked.
I'll give a little prize if anyone can correctly identify what causes this curve. Hint: It's an intentional artifact of a training algorithm

33
5
109
Any method that ranks "transparency" the same for GPT4, where basically nothing is shared, vs. Stable Diffusion 2, a model I personally have reproduced from scratch, is so flawed it's not even worth discussing


The Foundation Model Transparency Index by
@StanfordCRFM
purports to be an assessment of how transparent popular AI models are. Unfortunately its analysis is quite flawed in ways that minimize its usefulness and encourage gamification
7
34
150
5
7
101
You know it's a crypto winter when a 1500 person hackathon doesn't have a single solana submission for a 4 digit cash prize
You know it's an AI bubble when VCs are paying summer housing for interns because they call it an AI hacker house
12
1
101
This is true -- but not for long. Things are getting exponentially easier
I didn't know how to train 10b a few months ago. Now, it's just plug-in data and play
"What about loss spikes?" Solved, come talk
"What about node failure?" Solved, come talk
Etc

I worry that investment into LLM/generative AI companies is way too exuberant right now, precisely for this reason. I estimate there are <200 people on the planet right now who know how to productively train 100B+ parameter models with startup resources (I am not one of them).
44
70
811
4
6
101
Abhi is a visionary. I've never worked with someone who so clearly can see the future and move us toward it. Internally, we bet a lot on how the world will evolve, and I've only ever beat Abhi once (and barely).
Very excited to see the hardware chapter play out

Advancing AI:
@Databricks
NLP Architect, Abhinav Venigalla, discusses the hardware and software advantages from AMD.
4
21
172
0
6
100
New laptop sticker dropped
Last 1.5 years
@MosaicML
have been absolutely wild. I've learned so much and done so many crazy things
Excited to go even faster
@databricks
. What's next is gonna be way bigger...

2
1
97
Easiest Q to see if someone knows how to train models at scale: ask them about garbage collection
9
2
87
Reading systems books and it's incredible how much ML engineers have forgotten and are rediscovering.
Synchronous only from nccl will be our downfall
5
3
86
Corollary: Google/Facebook get far less credit than they deserve for driving AI innovation via Tensorflow/PyTorch/JAX. Massive $ investments in software made free which are the bedrock of everything in AI

I feel like it’s not obvious to consumers how monumental and expensive regular software is. iOS cost about as much as the Manhattan project (~$20b). Google search cost about as much as the ISS (~$100b).
50
114
2K
1
10
85
Do people tweeting even read papers? The results only go to 32k.... I hate these AGI accounts which are all hype and 0 thought
It's a cool idea, but imo long sequence benchmarks are sorely lacking so it's hard to evaluate. I'd bet good money dilated attention has accuracy cost

More totally-not-evidence that AGI might be soon:
"LongNet is a Transformer variant that can scale sequence length to more than 1 billion tokens"
1 billion tokens is a lifetime of reading for some people
Intuition pump: You can hold a few numbers in your working memory, but

31
67
516
7
6
84
Dataset drop!! Excited to announce the CommonCanvas dataset, a large-scale Creative-Commons dataset is now open-source on Huggingface (1/n)

4
8
82
Empire Strikes Back arc in full swing.
Gemini 2 is going to be unholy levels of cracked


4
3
81
Used to think memorizing constants (eg 1 mol) was a waste of time
I now finally get it. Having numbers (GPU flops, MFU math, scaling laws) in your head doesn't just speed up your work -- it makes actually checking other people's math/claims (which no one does) much easier
4
3
76
Every time I come to NYC I'm reminded
1. How much better a city is w narorw streets and public transit
2. How grateful I am to not work in investment banking / finance
3
0
77
I was often told raising money is often like signing in blood -- you're ride or die till the end.
Turns out you can just leave...? Are the investors not furious? Did something else happen?
Hoping employees who bought the vision didn't get screwed🙏

I’m excited to announce that today I’m joining
@Microsoft
as CEO of Microsoft AI. I’ll be leading all consumer AI products and research, including Copilot, Bing and Edge. My friend and longtime collaborator Karén Simonyan will be Chief Scientist, and several of our amazing
1K
2K
16K
3
2
75
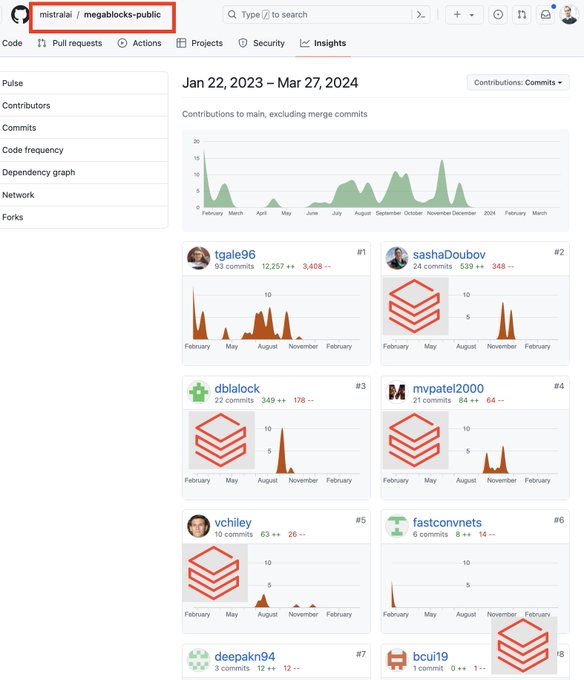
As part of building DBRX, we've constantly been upstreaming changes to public repos. 4 of the top 5 contributors to (the mistral fork of) MegaBlocks are on the team at Mosaic 😀
2
3
76
On Wednesday, we showed how to train Stable Diffusion in <$50k. We got a ton of questions asking for more details, so we've released a deep dive new blog post.
I'll go into the details here and (new!) what we didn't do (but could work 👀) (1/n)

1
7
75
Very interesting to see differences in feature announcement:
- GDM: corpo blog
- OAI: weird rumors for a week
- Anthropic: dude posts docs and it's out

We just rolled out prompt caching in the Anthropic API.
It cuts API input costs by up to 90% and reduces latency by up to 80%.
Here's how it works:
162
356
5K
1
3
74
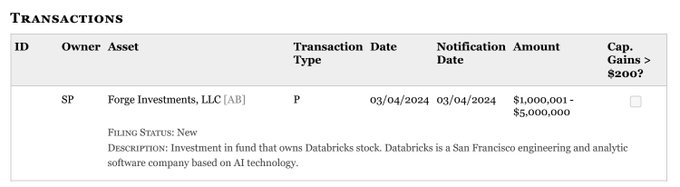
What did she see? 👀

BREAKING 🚨:
Nancy Pelosi just bought $5M of the AI company Databricks
Unfortunately, Databricks is a privately held company and not available to be bought by the public
Sorry people, you don’t have access to this one.
288
2K
14K
3
3
72
Badass move to bring a XX petaflop wafer to a party


The Open Source AI Party of the year is lit 🔥 with community love here in NOLA! Thanks
@irinarish
@togethercompute
@laion_ai
for your partnership in bringing the
#OpenSource
AI community together tonight! 🧡
0
3
37
0
3
70
I've switched back to Google from Perplexity. Was dealing with a... situation and I opened Google first. For a while, my default instinct was Perplexity, but it seems to have flipped back!
Biggest benefits:
- so much faster
- following links to articles at end

6
2
70

I have found ML very similar to finance.
It is very noisy and confusing. If you reason from first principles, you might find a great insight, or it might be Nope! the system does not operate like that at all
Also working on both makes you a lot of money

I think ML discussions are often harmed by first-principles thinking. Images from metallurgy or cooking can be more edifying than math (from the wrong abstraction level).
Eg finetuning vs pretraining. «it's literally same loss!» Uh, yes I guess. And is annealing just melting?

3
1
42
7
4
69
I used to think finance people were boring, but apparently my quant friend competes at math competitions with David Beckham's son cheering him on?? Is math... so back?
3
1
66
Watching
@dylan522p
breakdown satellite photos at ICML ES-FOMO is incredible.... Wild to see how well you can predict cluster build out for each frontier lab.
Please hold, scale incoming
2
1
65
Great tooling is such an accelerant.
In the middle of a convo, I was able to completely change our parallelism scheme, launch a job, and have a detailed profile showing CPU/CUDA/communication ops in <5 min to immediately see bottlenecks.
This is how you move fast 🚀
3
1
60
ICML was a blast! A mini award series for my favorite parts of the conference (1/n)

3
2
59
Me: Can we implement mixtral from scratch for fine-tuning?
@jefrankle
: We have mixtral at home (transformers)
Mixtral at home (transformers):

1
2
59
Everyone dunking on Google for not adopting LLMs but... search has actually gotten really good?
Was googling for travel blogs, hit some generated results. Spits out cool itineraries, adjacent map updates in real time as you click through itinerary, etc 🤯

3
2
56
Heart goes out to all the brilliant people at
@OpenAI
who aren't involved in and can't control this mess. Godspeed
1
1
54
So many people asking why GPT-4o is free ("why would I pay now?") don't get it. It's all about more data collection for next generation. OpenAI doesn't care about revenue, just more data and compute
12
3
52
1st time I rode a Waymo I was amazed and filmed the whole thing. 2nd time I was excited but didn't record. 3rd time I was just on my phone the whole time
Amazing to see as everyone focuses on genai, self-driving is finally here and working
2
2
52
Had a great time at ICML! Met amazing people and learned a ton. Till next time Hawaii! 🛫

2
1
52
They call it mid training cause the good engineers are on pretraining and the good researchers are on after training
4
1
52

Interesting to see how much publishing draws talent. Was at a dinner on Tuesday and people were asked if they had to leave their current role, which frontier team they'd be most excited to join.
3/8 said Meta, specifically
@ArmenAgha
's team
2
4
52
Hidden upside of cultivating waterloo power at
@DbrxMosaicAI
is how much clout I have with my Canadian cousins. It's the little things like not saying the 2nd t in Toronto
2
5
51
Every ML engineer goes off about building Nd parallelism but all I want is reliable checkpointing and someone who knows networking to get reliable upload/downloads
1
2
48
@Suhail
A few science ones I like: Scaling laws (Kaplan et al), chinchilla (deepmind) for LLM sizes. instruct gpt (openai) for rlhf. Alibi for large context length future. Switchformer for MoE, which imo will become much bigger
2
1
46
ML is not a Popperian science. You can prove something works, but it is very very hard to prove something doesn't work -- maybe you're just doing it wrong!

lmao at everyone gleefully sharing the model collapse paper which a) is a repeat of the curse of recursion one from 6 months ago, b) has already been shown not to hold in realistic settings, c) is belied by every frontier lab using synthetic data. but yeah have fun with that lol
5
4
134
6
1
47
@jefrankle
@landanjs
Now, with
@MosaicML
, it's absurdly easy. Here's the loss curve from the week. I launched the runs and didn't have to mess with the ongoing runs once, including when things broke during my Saturday brunch with
@vivek_myers
. It crashed, identified failure, restarted by itself 🤯

1
5
44
Few things more fun than being a research engineer. I get to run massive workloads (64-256 GPUs training Stable Diffusion from scratch) with fun system problems to make it go fast, and the (brilliant) research scientists deal with all the painful convergence mumbo jumbo
4
0
44
For the first time, there's a clear scenario for which it seems Gemini is straight up better than GPT.
Tides are turning?

Gemini 1.5 Pro - A highly capable multimodal model with a 10M token context length
Today we are releasing the first demonstrations of the capabilities of the Gemini 1.5 series, with the Gemini 1.5 Pro model. One of the key differentiators of this model is its incredibly long

195
1K
6K
3
0
41

Built a fun text adventure game where a LLM is the storyteller, and every action is evaluated on a likelihood / dice roll D&D style at the
@scale_AI
hackathon!
Forgot how enjoyable it is to just build fun mini projects

4
2
42
On language.
Pros:
- New Gemini 1.5 Flash! 7% the cost of GPT-4o (1/10th cost of Pro)
- Gemma 2. More open source AI models!
- PaliGemma. New vision-language model,
@giffmana
and team keeps cookin
- Gemini Nano on-device
Cons:
- No benchmarks?

4
4
41
There's a lot of companies brute forcing impressive model training. Few are building the tools to make it scalable and repeatable.
This is how we get crazy things like replit training sota code models with 2 people, Stable Diffusion 2 <$50k with 3 people, etc

It feels like what is happening with Mosaic mirrors what happened with OpenAI. A huge amount of effort focused on tool building unlocks rapid iteration
3
3
46
2
1
41
Wow! Google open sourcing models now? Things are really shipping 🚀. New SOTA 7b

2
2
40
2 out of the 3 best researchers I know are 2 out of the 3 best engineers I know

People often ask if ML or software skills are more the bottleneck to AI progress. It’s the wrong question—both are invaluable, and people with both sets of skills can have outsized impact. We find it easier, however, to teach people ML skills as needed than software engineering.
107
316
4K
3
0
39
The real magic is how easy this was.
@vitaliychiley
clicked run and loss curves went down. Every now and then it moved clusters but that's about it 🤷♂️.
Many people train models. Few make it easy, repeatable, and affordable. Now we can all cook🧑🍳

3
2
38
@abhi_venigalla
@jefrankle
To be clear, there was an absurd amount of work building our open source stack and as well as our amazing platform product. A ton of people did incredible work.
We built this to help everyone train, fine-tune, and deploy LLMs

2
4
38
I harp on this a lot, but the takeaway here is how easy it was. It took
@abhi_venigalla
<1 hour. Everything works out of the box (Mosaic's stack on PyTorch, PyTorch on AMD). Low switching costs will drive adoption, and that's what everyone else (Cerebras, Habana) needs
Remember when everyone was freaking out about AMD because
@realGeorgeHotz
quit on it? Turns out it works straight out of the box on
@MosaicML
's stack on real LLM workloads, and we have the receipts
11
15
186
2
3
38
LLMs are moving beyond pure research to the real world. It's no longer minimize training cost at optimal performance, it's minimize training + inference cost (+ w * inference latency?) at optimal performance. Big fan of what
@BlancheMinerva
and
@AiEleuther
are working on

Recently I’ve been harping on how “compute optimal” and “best for use” are completely different things. This plot from
@CerebrasSystems
shows that really well: their compute optimal models trained on the Pile out-preform Pythia for fixed compute but underperform for fixed params

10
43
269
2
2
38
One of the most insane things I heard when I started at Mosaic was
@abhi_venigalla
telling me we're going to go to 32->16->8->4->1 bit precision over the next few years, and the real blocker is hardware support.
I laughed, but as with most things Abhi says, I'm now convinced...

@karpathy
Super excited to push this even further:
- Next week: bitsandbytes 4-bit closed beta that allows you to finetune 30B/65B LLaMA models on a single 24/48 GB GPU (no degradation vs full fine-tuning in 16-bit)
- Two weeks: Full release of code, paper, and a collection of 65B models
39
193
1K
4
0
37
Few joys as great as meeting someone who uses your open source work and tells you they love it
1
1
36
"pierrestock changed the title Mixtral-8x7B support Support new model 6 hours ago"


magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%%3A6969%2Fannounce&tr=http%3A%2F%%3A80%2Fannounce
RELEASE a6bbd9affe0c2725c1b7410d66833e24
588
2K
10K
0
0
37
Engineering on calls suck. Research on calls monitoring massive XXbillion parameter models are so much fun. Gonna be a crazy week...
3
2
36
Grandma taking WhatsApp groups by storm after learning to make pictures of Krishna w Stable Diffusion on
@playground_ai
1
0
34
Convinced the best way to improve frontier models for my use cases it to tweet examples of bad behavior. Then, some poor engineer can grind out thousands of synthetic examples of my problem and bake it in next time 🥳

Can you tikz draw the Acropolis?
Claude Sonnet 3.5:

0
2
23
2
0
35
@natfriedman
@TheSeaMouse
You're right! All the links on the bottom are wrong 🤔 I only checked the twitter one. Awkward...
3
0
19
0
1
34
This stuff is super cool but not the right direction imo. No one should be serving 175B param models in production
Hint: solve chinchilla scaling laws = gpt3 quality (or any value) subject to cost minimization. The answer is a LOT smaller than 175B...

It's so over, "FlexGen runs
OPT-175B up to 100× faster on a single 16GB GPU"
Faster than deepspeed offloading


21
157
1K
4
1
33
For example, every time you have a senior researcher leave big AI labs, a huge amount of research direction knowledge transfers. Research is hard to produce and easy to take with you!
My guess is Anthropic will scale and vortex next... but will equilibrium soon
0
1
33


Really interesting to see
1. Anthropic release models with simple announcements instead of hype days (developer day, IO)
2. Strong commitment to privacy while still building great models. Will resubscribe just for this

Spotted this at the bottom of which is a much more clear statement on privacy than I've seen from most other model providers

5
34
309
0
3
31
50-50 odds I could do this in a few hours. I've heard people get pretty good MFU for LLMs on the
@MosaicML
stack w AMD gpus.
My uninformed take: AMD is aggressively prioritizing PyTorch support (just swap backend), which is why
@realGeorgeHotz
had a brutal time -- custom is hard
@AMD
Lisa Su and all her execs should spend 2+ hours every day having to install ROCM Drivers + AMD on a fresh PC. They *all* have to start deep learning projects and try to get SOTA on some LLM task using their own multi-AMD gpu rigs
4
2
89
2
4
30
I'll be at ICML! Come say hi if you're interested in performance engineering, ML infra, open source, or if you just wanna hang :)
0
1
29
Ok this is really fun. The website is sick

Today, we’re excited to release the first step in our mission to build real time multimodal intelligence for every device: Sonic, a blazing fast (🚀 135ms model latency), lifelike generative voice model and API.
Read and try Sonic

43
164
823
1
1
29
I'm really excited about this project. This is one of the biggest models ever with shared granular checkpoints and data which makes it an incredible foundation for research. This kind of openness is super critical to helping advance the field.

OLMo is here! And it’s 100% open.
It’s a state-of-the-art LLM and we are releasing it with all pre-training data and code. Let’s get to work on understanding the science behind LLMs. Learn more about the framework and how to access it here:
29
347
1K
0
1
29
If OpenAI was trying to upstage Google IO, IO completely blew it out of the water.
With that said, OAI still seems to be crushing benchmarks, and I'm disappointed Google didn't have an updated model with better numbers.
4
2
29
My biggest ineffective altruistism: donating to live music on public transit
Safe, clean subways with music in New York are such a wonderful experience
1
0
28
On assistants and agents.
Pros:
- Mindblowing demo with assistant. Crazy vision-language skills, really cool uses. Feels like what Humane and co aspire to be
Cons:
- Slower than GPT-4o? Hard to tell...

We’re sharing Project Astra: our new project focused on building a future AI assistant that can be truly helpful in everyday life. 🤝
Watch it in action, with two parts - each was captured in a single take, in real time. ↓
#GoogleIO
221
1K
4K
1
1
28
In Ticket to Ride, it's often advantageous to draw lots of train cards and then build routes in bursts -- it lets you get more locomotives (by drawing from deck vs. board) and hides your intentions longer.
Been collecting cards for months. The first route was built today.
2
1
28
Character serves in 8-bit, but instead of quantizing or doing quantize aware training, they purely train in int8! This gives 8-bit training for A100s (which don't have FP8). Incredibly impressive. (2/n)
2
0
28
Excited to be at PyTorch conference! Come say hi :)
Attending the PyTorch Conference? There's several talks and posters on Distributed Training. Folks from IBM, Meta, Databricks and more explore distributed LLM training with native PyTorch components and libraries!
Come join us in September for the following talks! 🧵 [1/6]
1
8
75
0
1
27