
Piotr Nawrot
@p_nawrot
Followers
4,719
Following
239
Media
23
Statuses
305
Intern @cohere , PhD student in #NLProc @Edin_CDT_NLP | Previously intern @Nvidia & @AIatMeta | 🥇🥈@ Polish Championships in Flunkyball
Warsaw
Joined July 2014
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
FEMA
• 1064823 Tweets
روما
• 512439 Tweets
بورتو
• 509847 Tweets
Tina Peters
• 120214 Tweets
Martinez
• 96118 Tweets
Porto
• 95350 Tweets
Manchester United
• 86122 Tweets
Avrupa
• 69299 Tweets
#okanburukistifa
• 65889 Tweets
Ten Hag
• 65358 Tweets
Hoca
• 46364 Tweets
Takım
• 45278 Tweets
Rashford
• 32993 Tweets
Dandadan
• 31137 Tweets
#BJKvSGE
• 29485 Tweets
Samu
• 29373 Tweets
Maguire
• 25091 Tweets
Mert
• 23527 Tweets
Nkunku
• 16528 Tweets
Antony
• 15787 Tweets
Onana
• 15476 Tweets
Mudryk
• 15113 Tweets
Bruno Fernandes
• 14601 Tweets
De Ligt
• 13908 Tweets
#PORMUN
• 12504 Tweets
Dalot
• 12359 Tweets
Veiga
• 11767 Tweets
Szymanski
• 10583 Tweets
بنزيما
• 10434 Tweets
Last Seen Profiles



















Pinned Tweet

The memory in Transformers grows linearly with the sequence length at inference time.
In SSMs it is constant, but often at the expense of performance.
We introduce Dynamic Memory Compression (DMC) where we retrofit LLMs to compress their KV cache while preserving performance

10
73
446

Introducing *nanoT5*
Inspired by
@jonasgeiping
's Cramming and
@karpathy
's nanoGPT, we fill the gap of a repository for pre-training T5-style "LLMs" under a limited budget (1xA100 GPU, ~20 hours) in PyTorch
🧑💻
@EdinburghNLP

8
85
457
DeepSeek-V2's Multi-Head Latent Attention is really impressive. I believe that it carries two significant improvements over GQA:
1) It allows you to compress heads differently - one head could take significantly bigger portion of the compressed latent state than the other. Two

3
58
237
My thoughts on
@OpenAI
's latest coding performance with o1.
First, some perspective on Codeforces ratings:
1400: Rating of a new account
1900: Competitive at the national level, interview whiteboard problems become easy
2200: A real shot at ICPC World Finals, possibly winning a

7
19
198
Short read for ML engineering - "GPU Utilization is a Misleading Metric".
TLDR: "You can get 100% GPU utilization with just IO operations while doing 0 computations - probably a better proxy for DL efficiency is SM efficiency".

2
23
200
Great news!
“Efficient Transformers with Dynamic Token Pooling” has been accepted to
#ACL23
!
We increase the efficiency *and* performance of Transformer LM by jointly segmenting and modelling language.
@PontiEdoardo
@AdrianLancucki
@JChorowski
📜


Can we increase the efficiency *and* performance of auto-regressive models?
We introduce dynamic-pooling Transformers, which jointly perform language modelling and token segmentation.
@p_nawrot
*
@AdrianLancucki
@JChorowski
📜
🧑💻
2
27
92
1
26
145
I'll jump on the hype train and quote Andrej too since I have been tweeting about tokenisers for quite some time now. I believe that Dynamic Token Pooling Transformers () we've authored is a good example of a tokenisation-free network.
Specifically, we

New (2h13m 😅) lecture: "Let's build the GPT Tokenizer"
Tokenizers are a completely separate stage of the LLM pipeline: they have their own training set, training algorithm (Byte Pair Encoding), and after training implement two functions: encode() from strings to tokens, and

380
2K
14K
5
16
137
nanoT5 got accepted to NLP - Open Source Software Workshop at
#EMNLP2023
🎇
You can access the report about the repo here:
More work about efficient methods for LLMs coming soon! 👀
See you in Singapore!

1
19
96
Tomorrow at
@icmlconf
, together with
@PontiEdoardo
and
@AdrianLancucki
, we'll present an updated version of "Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference".
You can find an updated paper at . Among others - 1) We trained DMC to

7
26
85
No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-based Language Models () accepted to
@NeurIPSConf
!
I'm very proud of this work : )
Big congrats to
@jeankaddour
,
@oscar__key
,
@PMinervini
, and Matt J. Kusner!


📢The costs for training (L)LMs skyrocketed 🚀 in recent years, motivating efficient training algorithms. However, when pre-training BERT and T5 models with a fixed compute budget, we find their gains vanish compared to a baseline with a fully-decayed learning rate! 1/5

2
28
131
5
7
77
Two free medium-compute Mixture-Of-Experts research ideas:
Prerequisite: Mixtral 8x7B is 32 layers, at each layer there are 8 experts, each token is assigned to 2 experts at a given layer.
1) Dynamic Expert Assignment in MoE Models
Every token is assigned to 2*32=64 experts in
5
12
73
So glad to see the community getting interested in tackling tokenization!
For anyone interested in this direction check out ().
We're training a character-level LM that learns how to tokenize the input end-to-end with the model.

if I were starting my research career today and interested in language models, I would become a world expert on tokenization & tokenizers
tokenization is weird, fascinating, and poorly understood, yet ubiquitous and necessary for things like chatGPT to work
6
6
163
1
6
58
For anyone interested in this direction go check out ().
We're training character-level LM which jointly learns how to dynamically segment the characters and to do language modeling.
We get a faster and better model than Transformer-XL baseline!

For anyone interested in future LLM development
One of the bigger unsolved deep learning problems: learning of hierarchical structure
Example: we still use tokenizers to train SOTA LLMs. We should be able to feed in bits/chars/bytes and get SOTA
Related: larger context window
19
76
519
3
9
54
@yoavgo
While working on () we discovered that we're able to retain many metrics including perplexity and many downstream tasks for very high compression ratios. Then we evaluated on MMLU and the score was terrible. From that point on our goal changed to getting
2
1
48
There is fully-e2e network+tokeniser training already ()!
We add dynamic tokeniser to the Transformer-XL and learn jointly to segment characters and do generative language modelling.
In late-Dec we'll be releasing a large-scale follow-up, stay tuned :)

There's a weird reality that we mostly ignore in language modeling. It's the fact that we don't _actually_ train these models end-to-end.
That's because we have the tokenizer! It's actually a really frustrating piece to tune with sometimes small changes mattering a lot and

19
18
232
4
4
44
👨💻Random LLM engineering question👨💻
Is there any difference between these approaches for computing the attention weights?
The former is more widely adopted (correct me if I'm wrong), but the latter is faster if
min(Q_len, K_len) * D_head < Q_len * K_len
which is like always?

5
4
45
Great read (as always) about the KV-Cache compression which very soon will become necessary given that we are able to reason over longer and longer contexts (10M of Gemini).
Also big shout-out to
@Francis_YAO_
for including our Dynamic Memory Compression work in the analysis.

We are in the age of 100K+ context window, but how does the language model attend to 100K tokens exactly?
In this post, we identify the six common attention patterns across layers and heads, aiming to provide a first intuition for kv cache compression.
6
64
357
0
5
41
I came across this blog that digs down into (Transformer) LLM's inference from the hardware side, and I truly believe that it's a must-read for everyone working on efficient Transformers 👏

transformer inference performance is becoming increasingly important and there's not as much lore on it, so here is a lot of lore that i think fully models llm inference performance
6
64
486
0
5
39
Codebase is available at:

0
1
35
Given this pace of long-context development, KV-Cache-Compression becomes increasingly more important for efficient inference.
If you're interested in the topic go take a look at our Dynamic Memory Compression () which works on top of GQA for extra 2x

We've been in the kitchen cooking 🔥 Excited to release the first
@AIatMeta
LLama-3 8B with a context length of over 1M on
@huggingface
- coming off of the 160K context length model we released on Friday!
A huge thank you to
@CrusoeEnergy
for sponsoring the compute. Let us know

67
259
1K
2
8
34
Do Efficient Training Algorithms / Optimizers really save us compute when training Transformer LMs? 🧐
Check out our latest work where we put some of these to the test!
PS. Thanks to this work I managed to further tune the nanoT5 baseline () 😇
📢The costs for training (L)LMs skyrocketed 🚀 in recent years, motivating efficient training algorithms. However, when pre-training BERT and T5 models with a fixed compute budget, we find their gains vanish compared to a baseline with a fully-decayed learning rate! 1/5
2
28
131
1
9
30
Check out the follow-up work "Efficient Transformers with Dynamic Token Pooling" which improves upon the Hourglass architecture with a learnable module that dynamically segments the input sequence end-to-end with the model:

1
8
26
Amazing work with this single-GPU repo. They fine-tuned a 32K context 3B LLaMA model in under 48 hours on just one A100.
It's crazy to observe this LLM progress!
Great job
@CStanKonrad
@s_tworkowski

0
4
22
Excited about new Transformer Language Model variants that offer joint segmentation and language modeling?
Join us tomorrow for our presentation on "Efficient Transformers with Dynamic Token Pooling" at 11 am poster session at
#ACL2023
.
Can't wait to discuss it with you there
1
7
21
@giffmana
Don't forget that there is already learnable tokenisers trained e2e with the LM :)
Ref:
2
1
20
[2/n]
The core idea of DMC at inference time is that the KV representation of current token is:
- appended to the cache (as in vanilla Transformers); or
- accumulated (weighted-averaged) with the last item in the cache.
At training time DMC operates in a second mode where
1
3
20
I am coming to Singapore 🇸🇬 for
#EMNLP2023
Please drop me a message if you would like to connect or discuss any of the following:
- Trainable tokenisers
- Efficient Transformers
- Any kind of adaptive computation
- Long context modelling
- LLM Scaling
Can't wait to see ya :)!
0
2
19
[5/n]
Finally, as DMC makes independent decisions for each head / layer, it opens a window into the internal mechanisms of the LLM.
We find specific regions of layers that compress the most (so most of the original information is redundant), such as between the middle and the

3
1
19


More evidence that including code in the pre-training mixture is essential!

✨Announcing LongLLaMA-Code 7B!✨
Have you wondered how GPT3.5 obtained its capability?
Are base models of code better reasoners? 🤔
We continue pre-training CodeLLaMA on text & code to improve reasoning 🧠
Bonus: 3x faster inference @ 16K context, using Focused Transformer 🎯

5
56
310
0
0
16
@jonasgeiping
@karpathy
@EdinburghNLP
In nanoT5, we expose (for research purposes) and optimise everything in the training pipeline of T5 except from model implementation.
Among others we use:
- C4 Dataset streaming
- PyTorch 2.0 compile
- TF32 operations
- AdamW with RMS scaling
0
0
16
I wanted to test this idea some time ago.
We know that training on Code improves LLM's CoT and reasoning abilities. Game trajectories are a source of long sequences which require a lot of reasoning and context comprehension to model well.
I'm curious to see the first results!

We Release...
608 B chess moves,
236 B Rubik's Cube moves,
39 B A* moves in ASCII Mazes
... to improve planing abilities of LLMs:
20
94
573
0
4
15
MixEval is a proxy for the Chatbot Arena rankings that has 0.96 correlation at a 6% compute price and time of MMLU evaluation. It’s a mix of benchmarks based on the real user query distribution.
Shout-out to
@NiJinjie
@XueFz
@xiangyue96
- very important project and amazing

How to get ⚔️Chatbot Arena⚔️ model rankings with 2000× less time (5 minutes) and 5000× less cost ($0.6)?
Maybe simply mix the classic benchmarks.
🚀 Introducing MixEval, a new 🥇gold-standard🥇 LLM evaluation paradigm standing on the shoulder of giants (classic benchmarks).

10
63
237
3
5
14
@hunterlightman
@OpenAI
Nice, I must have missed that. I'm very impressed by the IOI results as I mentioned in the post. I don't have a strong opinion (know) how one should interpret the Codeforces result as even if you evaluated the model on some latest contest private simulations to estimate the ELO
0
0
12
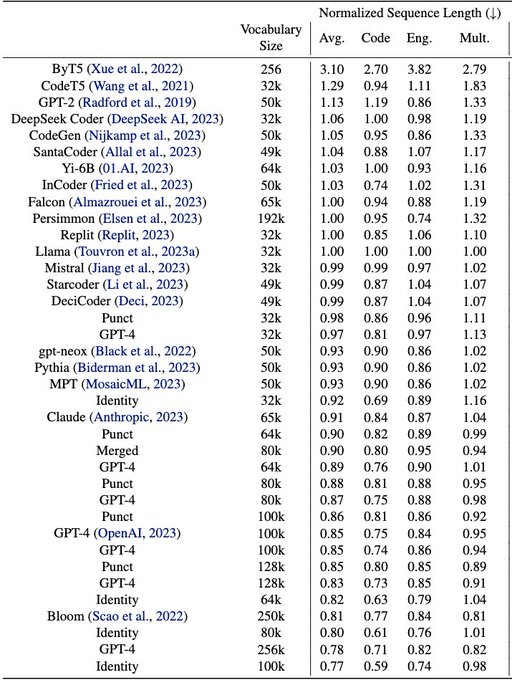
Check tokenizers in your LLMs! Latest findings from
@__gautier__
et al:
1. You can swap tokenizer in your pre-trained base model with little impact on downstreams (via fine-tuning)
2. Vocabulary size has little impact on downstreams.
I wonder if we would reach the same

PSA: Check your tokenizers!
We find most code LLMs fine-tuned from a pre-trained NL model to be suboptimal for code.
Preprint:
This research was done during my internship
@AIatMeta
with
@b_roziere
and
@syhw
1/8
3
37
177
0
1
13
[3/n]
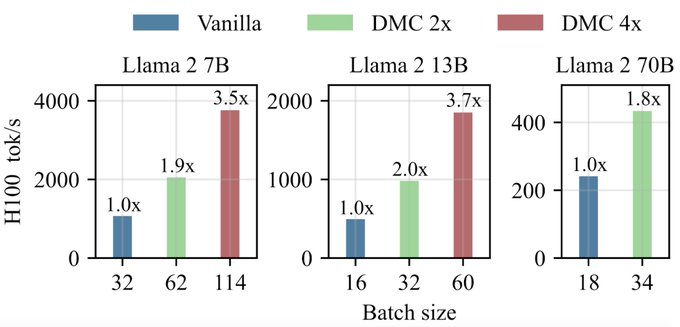
2x and 4x compression of the KV cache preserves (or even increases!) the performance of the original LLM (such as LLama 7B / 13B / 70B) in factuality, commonsense question answering, and coding.
Not only is DMC far superior to GQA, but it can be also compounded with it:

2
2
12
I'm trying to tackle a (impossible?) task of keeping up with the long-context LLM evaluation field and below is a list of recent papers I've found that introduce some new long context evaluation schema / dataset. Please give me a hand to have this list up-to-date, at least for

5
4
13

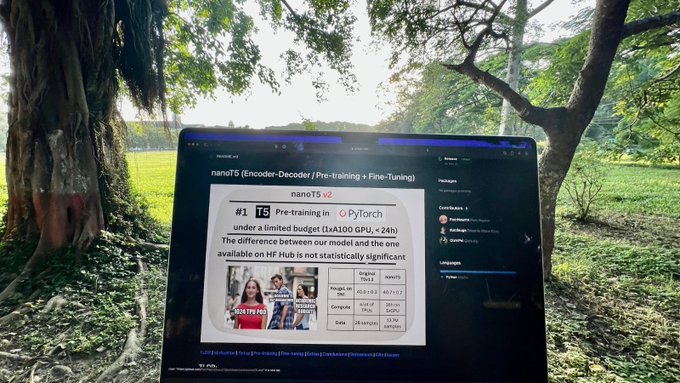
@jonasgeiping
@karpathy
@EdinburghNLP
Despite the continuously increasing size of pretrained Transformers, the research community still needs easy-to-reproduce and up-to-date baselines to test new hypotheses fast and at a small scale.
To the best of our knowledge, there's no repository that reproduces T5 in PyTorch.
0
0
12
It’s common practise to quantise LLMs to {4, 8}-bit to increase throughput/latency at a small cost to model accuracy. I was thinking how quantisation behaves for long-context scenarios (>100k) where there's a lot of tokens to process but e.g. so little values to encode your
3
1
12
@rohanpaul_ai
It looks like we reinvent the same thing every year but with different HPs : )
2020 -
2021 -
2023 -
3
1
12
[4/n]
This translates in practice into reduced latency and boosted throughput: now we can fit in memory much larger batches (x-axis) and/or longer examples!
Thanks to an efficient implementation in Triton, the throughput gains (y-axis) in practice reach the theoretical limits
1
1
11
I wholeheartedly recommend Edoardo as a supervisor!
We have re-opened 2 PhD studentships for *2023/24* at
@EdinburghNLP
(1 home, 1 international), please send me a message by tomorrow if you are interested in this opportunity!
4
22
50
0
0
10
@jonasgeiping
@karpathy
@EdinburghNLP
We make our codebase, configs and [pre-training, fine-tuning] logs publicly available to enhance the accessibility of NLP research. We are keen to hear your suggestions to improve the codebase further.
Thanks to
@PontiEdoardo
for his early feedback!
0
0
11

(1/5)🚀 Our OpenMoE Paper is out! 📄 Including:
🔍ALL Checkpoints
📊 In-depth MoE routing analysis
🤯Learning from mistakes & solutions
Three important findings:
(1) Context-Independent Specialization;
(2) Early Routing Learning;
(3) Drop-towards-the-End.
Paper Link:

5
105
518
0
2
11
@Francis_YAO_
It’s very very true. Right now (at the beginning of the PhD) I feel I need some publications to get minimum recognition, but then, after some amount of conference papers / citations, you should definitely prioritize fun over bigger numbers
0
0
9
Wow, this is huge! Flash Attention is now parallelised over the KV-axis!


0
0
9
Key upgrade in nanoT5 v2:
We've leveraged BF16 precision and utilise a simplified T5 model implementation based on Huggingface's design.
New implementation is easy-to-read and compatible with the HF's checkpoints.
Pre-training is now 2x faster than our previous version. 🚀

1
0
8
@jonasgeiping
@karpathy
@EdinburghNLP
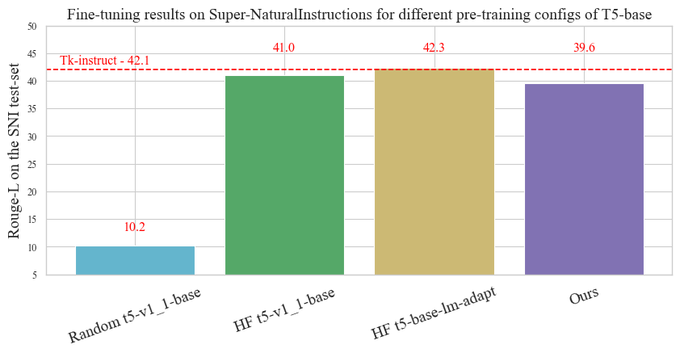
To evaluate our model, we use the popular meta-dataset called Super Natural-Instructions (SNI), which aggregates datasets for many tasks.
We achieve ~40 RougeL on the SNI test set, compared to ~42 RougeL of the original model available on HuggingFace Hub.
1
0
9
@Teknium1
KV-Cache Compression will become crucial very soon :)
The memory in Transformers grows linearly with the sequence length at inference time.
In SSMs it is constant, but often at the expense of performance.
We introduce Dynamic Memory Compression (DMC) where we retrofit LLMs to compress their KV cache while preserving performance
10
73
446
1
0
9
We share the configs, checkpoints, training logs, as well as our negative attempts towards improving pre-training efficiency.
Advanced optimizers like Lion, Sophia, ALiBi positional embeddings, and FP16 mixed precision training didn't yield expected benefits.
2
0
9
@josiahjdavis
@jxmnop
Chech this out :) ().
We're training a character-level LM that learns how to tokenize the input end-to-end with the model.
2
0
9
@jxmnop
I'd really want to agree here with you and live in a world where (almost) all that matters is the data quality but it's not true.
For example, idk if you remember but I told you about this effort of mine towards reproducing T5 pre-training in PyTorch. Me, and some other attempts
1
0
9
What happened to simulating encoder-decoder with decoder-only by fine-tuning autoregressive GPTs to do bidirectional attention over the input (prompt)?
I felt that it was an obvious thing to do as a post pre-training step and everyone was talking about it a year ago at
13
0
9
Let the games begin!
Looking forward to seeing multi-modal rise in 2024.

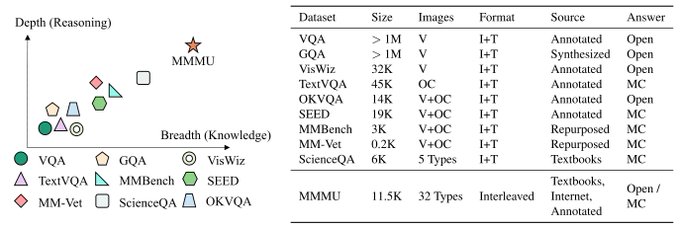
🚀 Introducing MMMU, a Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI.
🧐 Highlights of the MMMU benchmark:
> 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks
>


19
184
747
0
2
8
@jonasgeiping
@karpathy
@EdinburghNLP
We start from the randomly initialised T5-base-v1.1 (248M parameters) implemented in HuggingFace. Next, we pre-train it on the English subset of the C4 dataset.
With several ablations, we choose the most optimal choice of LR Scheduler / Optimizer / Batch Size for our hardware.

0
0
8
Is it because of low precision (fp8 / bf16) operations and arithmetic underflow and we get better precision if we multiply/add larger numbers and normalise them in the end?
I evaluated both approaches with the most recent flash-attention and they're (+-eps) equal.
0
0
7
Don't miss hottest NeurIPS gem on long context LLMs!
Honored to win Poland's best CS master thesis prize for my work on long context LLM w/
@PiotrRMilos
🎉
Can't make it to
#NeurIPS2023
😭, but
@CStanKonrad
will present LongLLaMA paper tmr!
Thu 10:45, Poster
#326
, Session 5
Interested in extending context to 256K? Come and say hi!

3
18
71
0
1
7
@liyucheng_2
@OpenAI
Not really, roughly speaking:
- You need to solve 5-6 tasks in 2 hours timeframe
- Tasks get harder and are worth e.g. 1/2/3/4/5/6 points.
- The amount of points you can get for a task decreases with the time of submission - the earlier the more points you get.
- Every incorrect
1
0
6
New PEFT method based on sparse fine-tuning that allows you to push the limits to what you can fine-tune on your local GPU.
(you have one in a lifetime opportunity to be the first person to post this hot news to your corporate papers channel on Slack so that you can reorganise
We scaled sparse fine-tuning (SFT) to LLMs (such as Llama 2) by making it both parameter- and memory-efficient!
(q)SFT instruction tuning performance is often better than (q)LoRA with comparable speed and memory load.
Paper:
Code:
2
70
251
0
0
6
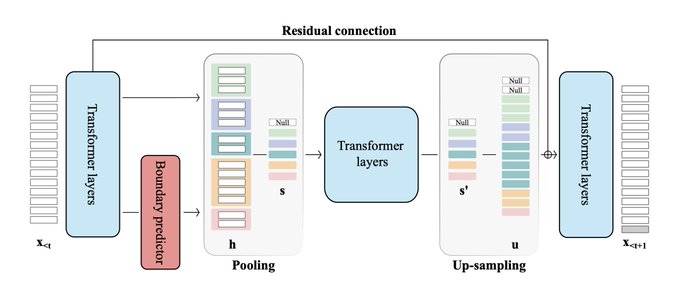
@karpathy
I've just come across this Tweet, so sorry for the late reply, but you can check this work () where we propose the LM-variant which starts with characters and learns to segment the sequence dynamically (variable groups) and e2e as it goes through the model.
0
0
6
@andrew_n_carr
Take a look at () where we add trainable "input-conditioned tokeniser" to the Transformer-XL and get generative model which jointly learns to segment characters and do language modelling.
Feedback welcomed and soon we'll release a large-scale follow-up :)
1
0
5
@picocreator
@jefrankle
@srush_nlp
My co-authors and I are currently exploring the middle ground in between SSMs and full Attention via Dynamic KV-Cache compression - - it would be great to know what you think about it :)
1
0
5
We test different pre-training durations: 4, 8, 12, 16, 20, and 24 hours. Result?
A sweet spot at 16 hours! It has comparable performance to the original model trained on 150x more data! Time & Compute-efficient, and no compromise on quality.

1
0
4
@tancool_
@jxmnop
I think that Dynamic Token Pooling we’ve authored is some “real example” of tokenisation-free Transformer that works with autoregressive language models - .
In this work we predict the segmentation of a character-level sequence :)
Let me know if you have
Can we increase the efficiency *and* performance of auto-regressive models?
We introduce dynamic-pooling Transformers, which jointly perform language modelling and token segmentation.
@p_nawrot
*
@AdrianLancucki
@JChorowski
📜
🧑💻
2
27
92
0
0
4
PS. I know that it's a point-wise operation, but we're at this stage where we optimise everything during LLM training and it's the largest tensor in the graph :)
0
0
5
@arthurmensch
Why there's no comparison to Command R+ on multilingual performance? I believe that Llama is much weaker than Cohere's model according to multiple sources.
0
0
5
lol

the winning comment i got from an ACL review for a scaling paper was "what has FLOPS got to do with NLP".
optimising for paper acceptances is like RLHF with a shitty reward model.
just like how one doesn't pretrain on garbage data, one should not read conf reviews.
4
0
39
1
0
4
@haileysch__
Take a look at Dynamic Memory Compression:
It combines with GQA and works on top of pre-trained LLMs. We're now adding more baselines to camera-ready version for ICML but the results so far are very promising for DMC when compared to other methods.
The memory in Transformers grows linearly with the sequence length at inference time.
In SSMs it is constant, but often at the expense of performance.
We introduce Dynamic Memory Compression (DMC) where we retrofit LLMs to compress their KV cache while preserving performance
10
73
446
0
0
4
I came up with both of these ideas more than a half year ago and I didn't have time to act on them ever since. I'm occupied with other projects so I think that sharing them is a right choice as someone could get inspired by them and decide to explore them further.
I would be
2
0
4
@serendip410
Hey! I would love to connect to discuss Efficient Inference, KV Compression, and evaluation. Let me know if you're free tomorrow or Thursday.
0
0
3
Also in terms of reproducibility we open-sourced our code and there's already been some successful attempts to reproduce our results based on work that cites us! :)
0
0
3
We train on characters but bytes are also possible. Increased input length is not a problem because similarly to Google's hierarchical Hourglass we compress the input to obtain BPE-like compression.
Read more in the original post:
Can we increase the efficiency *and* performance of auto-regressive models?
We introduce dynamic-pooling Transformers, which jointly perform language modelling and token segmentation.
@p_nawrot
*
@AdrianLancucki
@JChorowski
📜
🧑💻
2
27
92
0
0
3
@khodaless
why vector quantisation and not regular tokenizer or the approach i mention in the post? - i might not be getting what the problem is but you can also take a look at this -

1
0
3
@teortaxesTex
@andrew_n_carr
There was also Google's Hourglass () doing the same thing as MegaByte
0
0
3
@anpaure
@liyucheng_2
@OpenAI
Hmmm, I mean, firstly most often input generator and validator are completely distinct programs. Secondly, validator is often of suboptimal complexity so you can't check the maximum inputs. Thirdly, and most importantly, writing those programs and testing takes time so most often
1
0
3
Must read for everyone working on model efficiency!
Frontier model like Gemini now has 2M context length, unlocking unprecedented applications. Yet such long context is prohibitively expensive.
In this paper, we discuss challenges in to reduce the inference of 1M to be **as cheap as 4K**
6
41
212
0
0
3
@MSFTResearch
Consider using nanoT5 () for the encoder-decoder models. It provides you with an optimized training pipeline and a simple model implementation!
2
0
3
@arankomatsuzaki
@haileysch__
One drawback of MLA (and GQA) that remains unsolved is that every token has the same Compression Ratio while different tokens carry different amount of information but this could be solved by Dynamic Memory Compression ().
0
0
3
@kohjingyu
Hey! Would you like to catch up for a chat about grounding and efficiency tomorrow?
0
0
3
@fouriergalois
A true multi-modal follow-up is my goal for 2k24, but at the same time can't express how excited I am for what's coming up soon because it is a very important milestone.
Can't say more now haha, but I'm glad that there are people waiting :)
0
0
2
@andrew_n_carr
More (+ very nice GIF) in the original post:
Can we increase the efficiency *and* performance of auto-regressive models?
We introduce dynamic-pooling Transformers, which jointly perform language modelling and token segmentation.
@p_nawrot
*
@AdrianLancucki
@JChorowski
📜
🧑💻
2
27
92
0
0
2