

Sanyam Bhutani
@bhutanisanyam1
Followers
38K
Following
11K
Media
950
Statuses
8K
👨💻 Working on llama models @AIatMeta | Previously: @h2oai, @weights_biases 🎙 Podcast @ctdsshow 👨🎓 Fellow @fastdotai 🎲 Grandmaster @Kaggle
Menlo Park, CA
Joined October 2016
This is the best week of my life 🙏. ✅ Reached Kaggle Grandmaster tier. ✅ My ML Hero & Guru: @jeremyphoward was kind enough to host me for an interview about my journey. I promise to continue creating ML content to the best of my ability & sincerely take up competitions next 🍵.

This week I'm filling in for regular "chai time data science" podcast host @bhutanisanyam1, with a very special interview with a recently-anointed Kaggle grandmaster.
17
12
284
“Transformers from scratch” by Brandon Rohrer 🤖 . This is one of the best write ups, that starts from 0 and explains every single detail of the model architecture. Even if you need a refresher or don’t, I would still highly recommend reading it:.

37
540
2K
Easily the best paper on current State of LLMs! 🙏. A 50 page read but it’s not “just another” survey paper, that only documents facts. The authors actually add very useful commentary capturing all aspects of building Large Language Models. Hence the result is a collection of

39
316
2K
Extremely excited to start working on the llama community officially!. I’ve joined @Meta and will be working in an absolute dream of contributing to the llama community among many other cool things . So how and why did I get here?. The price to big dreams is paid in units of

148
26
2K
An absolute masterclass by World's Top Data Scientists 🙏. The awesome Kaggle Grandmaster Team at NVIDIA shares their winning tips and tricks in this series:.

5
333
2K
Life update: I have moved to Bay Area to work @Meta HQ! 🙏. The flight from India takes a day but my journey was 2 years to get to Silicon Valley: . In 2022, @jeremyphoward gave an advice that took over my mind:. “You should live in Bay Area for a while if you want to meet some

61
41
2K
NotebookLlama: An Open Source version of NotebookLM 🙏. A complete tutorial on building a PDF to Podcast flow using Llama:. - 1B to pre-process PDF.- 70B to convert it to a podcast Transcript.- 8B to make it more dramatic.- Parler and Suno models for TTS.

31
282
2K
Google Colab has now a Subscription model for Power users: . - Faster GPUs.- Longer runtimes.- More memory. It's for $9.99/Month. I know many power users might enjoy it: .
23
369
1K
How to become an expert at any thing 🙏. I rediscovered this gem by @karpathy in my bookmarks today

21
153
1K
My favourite LLM paper is finally open source! 🙏. Running a single Large Language Model agent is easy. Running multiple is hard. Running multiple over days of sustained interactions is really hard. I’ve spent the last 3 days reading through the code of the paper that solved

13
200
1K
This is the best resource to get started in NLP in 2023 🙏. In 2 days, I will be kicking off a weekly study group to learn with everyone:. @_lewtun will kindly join us for an opening AMA.

18
118
942
CS 324 Notes are a LLM Book! 🙏. The Large Language Model course notes are a crispy book covering the foundations. Perfectly structured like an onion, starting at an overview & then levelling up. It’s Mixture of Expert section is one of the best:.
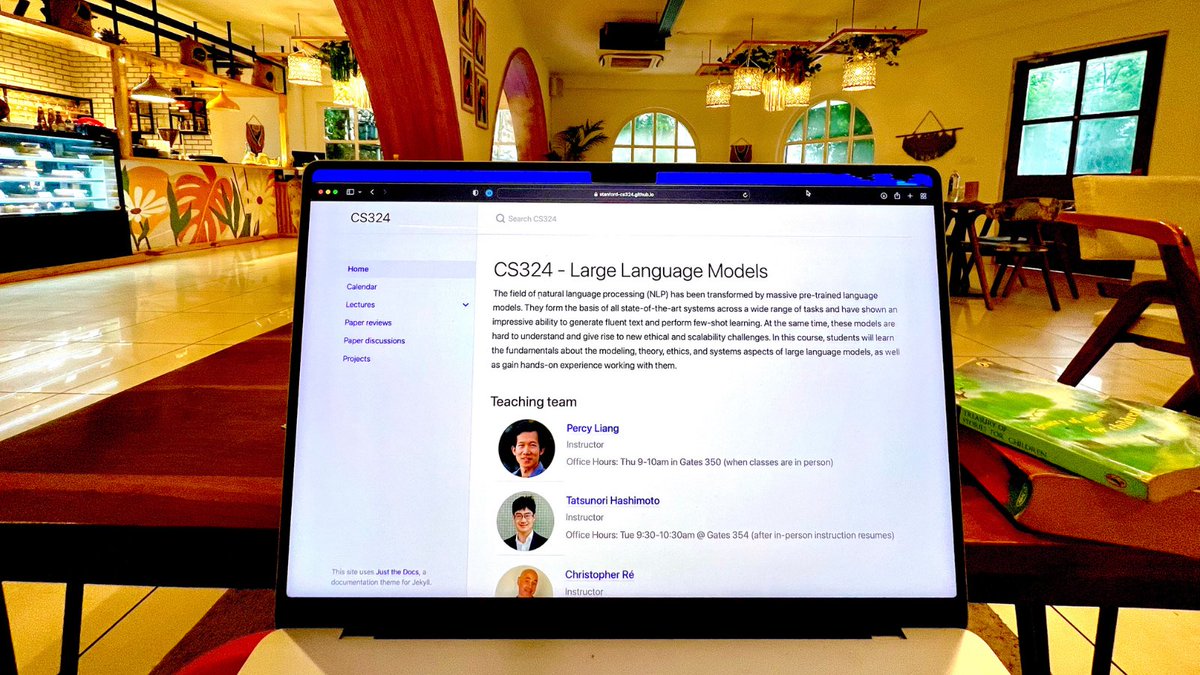
9
224
908
The best summary of Transformers and it’s evolution 🙏. I found @giffmana’s slides from 2022 to be the best “pocket reference” on the topic. Many posts have covered Transformers however this one also covers the state of field before and how it got adopted to different domains.

11
155
888
Best tutorial on setting up LLMs locally! 🙏. @Rob_Mulla made an end to end video teaching how to install, run with GUI and connect a Large Language Model to your own data on your own machine. All open source, running offline:.

13
160
881
Watching “State of GPT” by @karpathy is the best 40 minutes you will spend this week 🙏. I actually found it really helpful for filling a lot of my knowledge gaps:. - Comparisons against human brain and LLM brain. - Why prompting works and why is it helpful to ask a model to “be

17
120
817
Officially wrapping up the @kaggle Top Solutions Series 🙏. I’ve hosted over 25 videos sharing and explaining tricks, secrets of Kagglers for all domains of machine learning. The series is quite complete & I’m graduating to more challenges:.

13
172
809

The best tutorials on building LLM powered applications 📚 . @GregKamradt is an incredible teacher of @LangChainAI:. ✅ Top down & applied series.✅ Amazing teaching style.✅ Very practical examples.

20
155
777
Papers I’ve read in the last month! 🙏. I’m currently writing a LLM roadmap along with my notes. If anyone is interested in reviewing and providing early feedback-please reach out!

82
31
751
MAJOR personal update: . I’ll be starting my work in a full time role @h2oai today as a Machine Learning Engineer and AI Content Creator! . I’m really excited to be a part of a team of many of my “ML Heroes” and THE best kagglers. Recap on my ML journey:.
72
59
728
Arxiv Chat: Chat w the latest papers 🙏. I made a really simple demo that makes it easy for me to understand the latest papers. The whole app is <100 lines of code:. ✅ @LangChainAI for the main logic.✅ @h2oai Wave for the UI.✅ ChatGPT for asking Qs
27
91
716
Implementing LLaMA from scratch! 🙏. This implements a LLM in the style that Karpathy implemented nanoGPT. Even though it focuses on LLaMA-1, it’s a refreshing code first read. Perfect for a Sunday crispy read:.

5
157
714
I'll say this out loud since no one does. I studied CS at college, it didn't make me a better programmer. Practising Programming makes you a better programmer, not studying it. If you're starting your ML Journey,trust me a "CS background" won't be as helpful as practising code.
35
86
700
Run 13B model on an iPhone! 🤯. Just finished reading @Tim_Dettmers’ amazing work on SpQR. SpQR unlocks 3.35 bit quantisation which lets us run 33B models on 3090s and 13B models on an iPhone. Here are my notes from the paper:. - Quantisation is basically like compressing the

29
111
688
Insanely detailed notes on Training LLMs! 🙏. @StasBekman has shared his field notes on training foundational models. These are insanely detailed, cover a lot of gotchas and caveats. A crispy read with well documented code, in depth discussions:.

6
127
682

If you're looking for the best resources to prepare for ML interviews in 2020,. Here's a wiki from the @fastdotai forums:. Also, all contributions are welcomed!

6
154
670
"Start by learning the basics really well [. ] Most advanced research projects require you to be excellent at the basics [. ] @AndrewYNg always told me to work on thorough mastery of these basics" .Read the complete interview w @goodfellow_ian @hackernoon:
4
184
643
NLP for absolute beginners 🙏. @jeremyphoward kindly shared the Stanford materials which are incredibly high signal resource for NLP. Here’s another tutorial teaching you the absolute NLP basics upto how to make a submission on Kaggle, by Jeremy himself!.

3
139
638
We can now train a 7B model from scratch on a single GPU! 🤯. DeepSpeed Chat: a framework offering insane optimisations and speed ups for training RLHF models:. ✅ Efficient and more affordable.✅ Insane Scalability.✅ Easy to use scripts.

9
115
605
Simulating a software company with LLMs! 🚀 . Remember the 25 agents living in a simulation? This does the same but for a software company. ChatDev asks the questions around effectively getting Large Language Model agents collaborate on writing entire code bases:. - Writing a
30
120
612
I'm tea-ry eyed. I can't believe this :'). I've reached the @kaggle Grandmaster tier today! Thank you so much everyone!🍵. My sincerest gratitude to @jeremyphoward for introducing me to Kaggle and to @vopani for pushing me to pursue it! 🙏.
63
15
597

The definitive guide to RAG in production! 🙏. @GokuMohandas walks us through implementing RAG from scratch, building a scalable app. It now has updated discussion on embedding fine-tuning, re-ranking and effectively routing requests. I think this is easily the most complete

12
91
568
Outperforming LLMs with 2000x smaller models! 🚀. “Distilling Step-by-Step!” is an incredible paper showcasing the promise of using CoT prompting with LLMs to generate steps of logical thinking and high quality labels that can produce great smaller models:. ✅ Outperforms both

8
115
557
My favourite LLM blogs! 🙏. For your weekend learning, here’s an opinionated list of my favourite Large Language Model educators. Pick any or all of their articles and read them cover to cover

16
82
557
The Deep Learning book study group 🙏. Starting this Saturday, we will be going through the Bible for understanding the basics of DL 📚.

12
51
539
Combining Knowledge Graphs and LLMs! 🙏. To my surprise, this paper is extremely detailed around training strategies of building such models and goes beyond “just prompting” ChatGPT and GPT-4. In fact, I realised after reading-it doesn’t even mention these models in most of the

22
79
538
This is just surreal! . I just won the @hackernoon Contributor of the year award for 2 categories! 🙏🍵. - Machine Learning.- Tutorial.


43
30
535
CS 25 has a great roadmap of LLM papers! 🙏. Transformers United has great guest lectures spanning the foundations of Large Language Models. An underrated aspect of the course is the curated list of papers on every topic. Perfect for your weekend reads:.

8
121
538
I finally got my copy of Deep Learning w Python by @fchollet! 📚. I couldn't be more excited about this 🙏. I'll be starting a reading group on Jan 8, and Francois has kindly agreed to join for an AMA! 🍵. Please send your Qs around Keras/the book as here!. Links TBD Soon!

22
28
511
A 50 page book on LLM Agents! 🙏. This is my new favourite survey paper. It reads like a perfect book on the why we need different techniques to make Large Language Model agents work and how different papers approached it.

9
95
519

The most detailed and practical write up on applying LLMs! 🙏. This reads like a survey paper but written for the industry and applications. @eugeneyan is known as the best NLP writer for a reason. It’s the most comprehensive overview of patterns on building Large Language Models
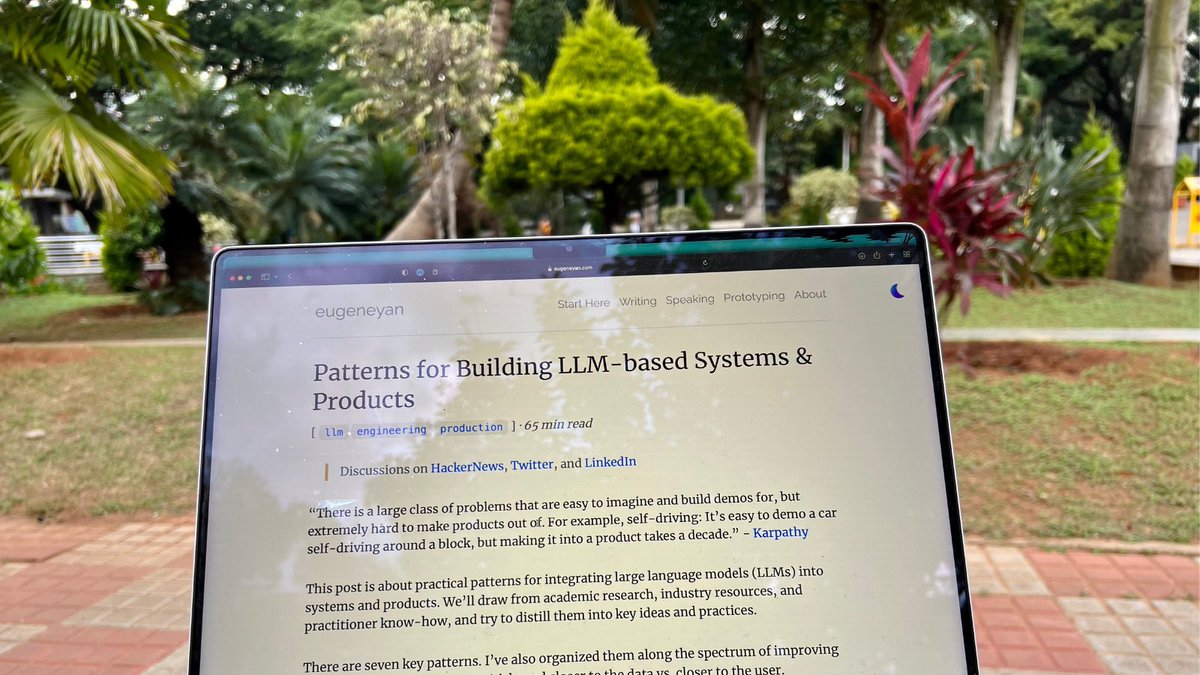
7
96
500
CS 25: Transformers United! 🦾. One of the best courses covering concepts of Transformers in the context of LLMs along with applications and secrets to building these models. My favourite part is the guest lectures from the best of our field!.

7
108
487
After all the travelling, I’ve invested my remaining savings into more 3090 GPUs for Kaggle 🙏

30
13
487

A masterpiece on applying LLM agents! 🙏 . MetaGPT paper is a golden treat on effectively applying Large Language Model agents. It takes inspiration from how humans work. Here’s my summary:. - Assembly line: Every agent has a role assigned to it. - Software Engineering: The above

11
84
479
Personal Update Thread on The @GoogleAI Residency:. Earlier this year I got a life-changing email. My Google AI Residency application had made it to the final interview rounds! This spring, Google flew me out to NYC where I gave my "On-site" interviews.
15
44
455
"Machine Learning doesn’t have to be a black box anymore. What use is a good model if we cannot explain the results to others. Interpretability is as important as creating a model.". A neat kernel on "Intrepreting Machine Learning models" by @pandeyparul.
5
99
434
I'm super excited to share that I've joined @weights_biases! 🍵. I've been a fan of their community since the early days, I'm really looking forward to contributing to it further. Please expect study groups, events, Kaggle deep dives, and much more! 🙏 .
55
20
435
The mindset of "Completing an online course" isn't right: . It's not a college degree-hacking your way to completion shouldn't be the goal and def won't be helpful. Take your time, even build a project midway: Gaining knowledge & building Projects/Solving Prob should be the goal!.
12
54
429
Incredible recap of key Transformer concepts! 🙏. What I really like about this write up is it covers 30 key papers and flows really well as a recap. @lilianweng has written so many incredible posts, this one captures all key architectural concepts:. - Transformer basics:

7
73
430
Great tutorial on Deploying Deep Learning Models On Web And Mobile (Along with a working demo!) by @reshamas and Nidhin P. They've used the library, but the tutorial can be used to create a web and mobile app using any framework.
1
104
424
The most underrated LLM Cookbook! 🙏. @OpenAI’s guide is an incredibly underrated resource. My favourite bit is the practical advice and guides sprinkled throughout the examples. It also has the highest quality code of many learning resources. The examples cover all important

4
80
417
GitHub GPT: Understand any repository! 🚀 . Here is a demo where I played with connecting GPT-4 to any repository. The main logic is <20 lines of code:. ✅ @LangChainAI for the main logic.✅ @activeloopai for storing embeddings.✅ Simple App that runs in the terminal
14
60
418
I’m in happy tears to awarded “Top GenAI Scientist” award by @AnalyticsVidhya 🙏. I feel really honoured by the recognition. Will make this one count!

31
9
415
A truly open source assistant chabot: GPT4All-J 🙏. A new model based was shipped to the GPT4All family. This one permits commercial usage and is completely open source:. ✅ Model weights.✅ Training logs.✅ Training dataset.
6
93
402
Another great roadmap of LLM papers! 👌 . CS224n has a really good curated list of papers to read for Large Language Models. I would recommend starting with the papers before the slides and lectures:.

1
70
401
The NLP study group is back after a break 🙏. Today, I’ll explain and summarise the BloombergGPT paper. This was an incredible read since the authors have kindly shared a fair bit of model details along with the reasons for their architectural choices:.

5
46
403
A perfect intro to open source LLMs! 🙏. The course by @asangani7 is now my top recommendation for getting started with Large Language Models:. - Just enough theory for a whole picture. - Teaches prompting, special tokens and conversational agents. - Perfectly abstracts the
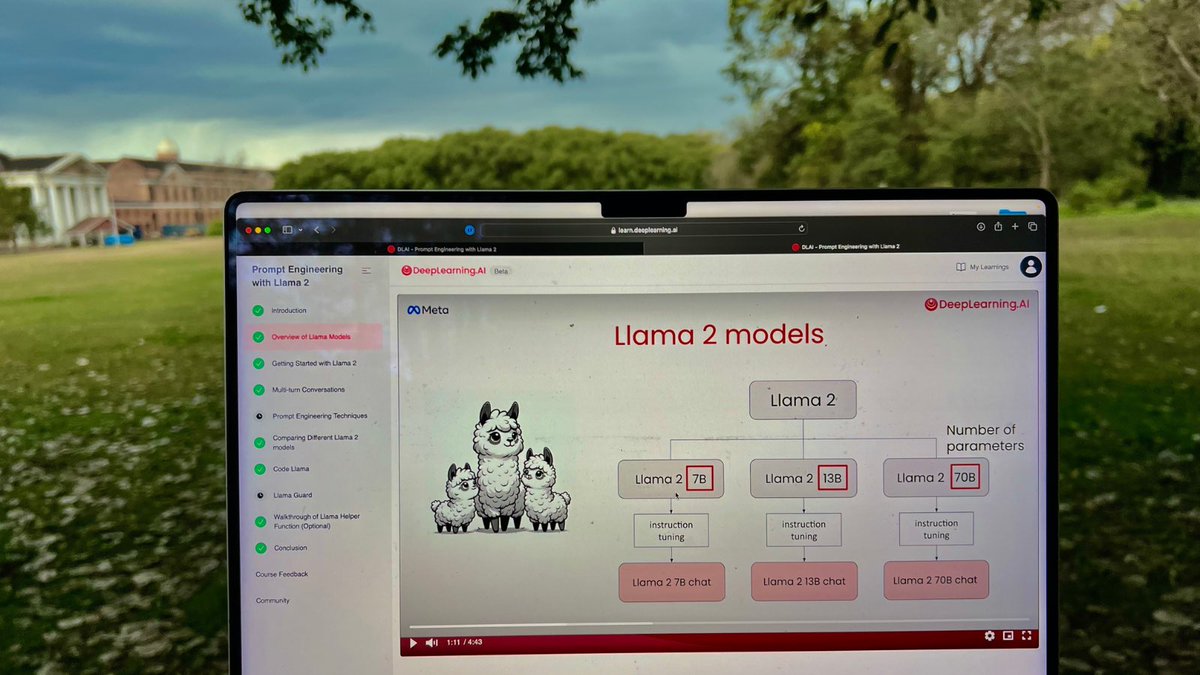
0
52
332
I’m writing a guide on building Multi-GPU machines! 🙏. Over the past few years, I’ve spent a lot of time learning how to build ML servers. I’ve decided to write a guide on the topic. What questions/topics would you want covered?. TIA!

57
37
386
Efficient Deep Learning course! 👌 . The lectures cover various techniques relevant to LLMs. Happy Sunday learning:.

1
55
387
AutoAgents: Autonomously generate LLM agents for any goal! 🤖 . This tries to solve the need for strong prompting and role definition by autogenerating agents. The code is sparsely documented but readable:.
11
82
383
The best NLP lectures! 🙏. @chrmanning’s latest CS224n lectures are finally live! . The 14 hours of new content covers Large Language Models, Interpretability, and some crispy framework tutorials:.

4
76
384
My next goal:. I will spend at least 500 hours this year competing on @kaggle 🍵. If I fail to do it, I will not drink chai for an entire year and giveaway all my GPUs 🙏.
43
11
377

The definitive guide to Multimodal deep learning! 🙏. Since the GPT-4 demo, multimodal has become one of the coolest domains in our field. This is a 240 page no-nonsense book to the domain, it starts from the basics of individual modalities upto the key details of the domain.

5
72
377
The Interview with @kaggle Grandmaster and Senior CV Engineer @LyftLevel5: Vladimir Iglovikov @viglovikov just got published @hackernoon. The Grandmaster has really been kind enough to share *ALL* of his secrets, you can find all of them here:
8
86
367
Very practical course on applying LLMs! 🙏. @HamelHusain had mentioned that langchain makes for a great cookbook of cutting edge ideas. This course is a refreshingly applied one teaching how to use @LangChainAI to build different applications. My favourite part is it’s

6
59
360
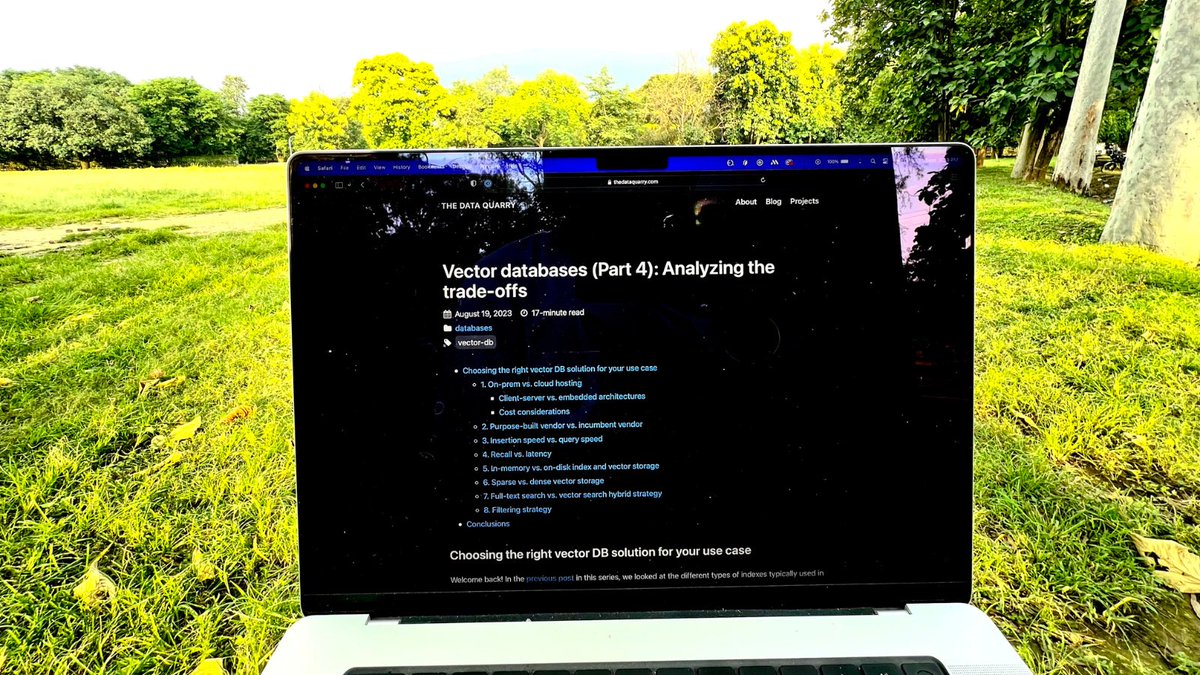
The most comprehensive series I’ve read on Vector databases! 💾. Most of us got exposed to vector dbs via Langchain or llamaindex documentation. However, There’s a lot of nuance and options to select from when building Large Language Model apps. @tech_optimist has written a 4
9
58
362
If you’re interested in diving into ML research & understanding more papers this year:. The Deep Learning book is an incredible resource teaching the basics & math behind DL. I’ve created a 5 part series explaining chapters here:.

4
54
360
Terrific tutorial on fine-tuning LLMs to your own data 👨🔬. Tomas Bratnic has shared a really crispy write up on creating a Cypher generating LLM:. ✅ All Open Source tools.✅ Walkthrough of setup.✅ Detailed steps on how to solve this @h2oai LLMStudio.
5
65
355
Masterclass of Pythonic Thinking: PyTudes 🤌. Its the highest quality resource for learning “the Pythonic way” and problem solving. The large number of problems cater to everyone at all levels. Every revisit, there’s something new to learn.
3
72
352
Today is a glorious day for @kaggle community! 🍵. Kaggle legend: @sudalairajkumar has conquered all categories and become the newest 4x Grandmaster! 🙏

11
19
352
“A cookbook of Self-Supervised Learning” @ylecun et al👩🍳👨🍳 . SSL is the tasty sauce behind a lot of the success in Language models, Computer Vision and beyond. It permits working with limited data by allowing you to include unlabelled data in your workflow. Hence becoming “the

5
63
336
Weekly @kaggle Top Solutions Study group 🙏. Starting this Sunday, I will be going through top solutions of recently ended competitions that might be relevant to the ongoing ones:.

4
58
325
NLP with Transformers Study Group 🤗 . Starting next week, I’m hosting a study group on the absolute gem book by @huggingface team 🙏. @_lewtun has kindly agreed to join the kickoff session. I can’t think of a better way to learn NLP:.

10
48
329
This really helped me understand why LLMs work! 🙏. - Why next word prediction is powerful. - Why prompting works. - What we know about emergence. Thanks @_jasonwei for the gem:.

1
39
326
Am I doing @karpathy and chill right? . Cafe overlooking Himalayas, tasty breakfast and lecture rewatch 😋🙏

19
2
316
This is THE BEST CAREER ADVICE for Data Science that I’ve ever read: . IMO @kaggle forums often have write ups/advice of *much* higher quality than most of the blogposts out there. I’d highly recommend reading all of @ryan_chesler’s write ups on Kaggle.
0
67
317
A hands on guide to train LLaMA with RLHF 🤗 . It’s one of the most complete tutorials on the topic with detailed explanations around why and how to follow the fine-tuning approaches.
2
76
319
The first open source Financial LLM! 🚀. BloombergGPT was the first proprietary financial LLM. This week, we witness the first open source one. FinLLM takes a “data centric” approach towards finance by building on top of multiple APIs/resources. Here’s an overview of its

4
46
313
The next 30 days, everyday w/o exception, I will:. - Wake up at 4 AM.- Workout for 2 hr.- Kaggle for 3 hr.- Move onto other tasks after 10 AM . Extra rules:.- No 📱before 5 PM.- No Emails before 12 PM . I'll post a video announcing the micro-resolution tom
22
15
316
🧵 Top Kaggle solutions always feature many great insights and hidden details: . I spent the past two days reading top solutions from the recently ended Great Barrier reef competition. There were many fascinating tricks shared, my short summary. TL;DR👇.
4
49
309
Last year, @HamelHusain (re) taught me a super power 🙏. “If you sincerely spend 3 hours everyday learning a new topic. In 6 months, you’ll be really far ahead”. This is something we learned in @fastdotai that Hamel reminded me when I expressed my imposter scare of LLMs

6
41
312
My 15 day LLM Study Vacation! 🚀 . The plan for next 2 weeks:. ✅ Hike/Visit a Himalayan mountain daily with a paper to read.✅ Build 15 @LangChainAI apps.✅ Finish catching up on LLM research

21
12
310
I just sat for 5 minutes straight smiling and trying not tear up after today's interview. It's done. I was able to record enough interviews to complete my dream goal of publishing 2 episodes-every Sunday and Thursday, at 9AM PT. No exceptions in 2020.

20
9
310
An extremely crispy intro to Vector Databases! 🙏. Have you watched those wired videos explaining concepts at incremental levels of detail?. @helloiamleonie done the same for Vector Dbs. She teaches the topic using Feynman technique, in 3 levels of detail.

5
52
302
The hardest challenge I’ve done! 🙏. Last week, I completed 200 days of writing everyday about Large Language Models. After ~2k hours of learning, I’m ready to make crispy videos:.

17
15
303
I'm really excited to share the interview with my and @fastdotai family's greatest ML Hero: @jeremyphoward. Not adding any Tweet introductions this time 🍵. Audio: Show Notes: Video:
11
59
302
If you're looking for a code first NLP course 👨💻. There is an NLP course by @fastdotai covering 🕵️♂️. - What is NLP.- Topic Modelling.- Sentiment Classification.- Regex.- LM.- RNNs.- Transformers.- Bias & Ethics. Blog: YT Playlist:
5
63
294
Strong LLM blog recommendation! 🙏. For any practitioner interested in Large Language Models, this is the best blog. @eugeneyan is magical at combining industrial patterns, experiments & research ideas very clearly . His weekend exp are my fav read:.

3
39
301
This is my favourite type of tutorial! 🙏. Remember the awesome fastai tutorials that share only the necessary theory and quickly dive into applying it?. @Sentdex teaches us QLoRA in the exact manner by applying it to give llama-2 more personality.

6
42
300
150 interview with ML heroes 🙏. I’ve actively hosted interviews with the best Kagglers, Researchers and practitioners from 2019-22. The questions discuss the guest’s journey and approach in a timeless and educational way:.

5
48
284
Huge congratulations to @pandeyparul on becoming the 1st Woman @kaggle Kernels Grandmaster from India. And to the best of my knowledge, 2nd one in the world. Although, I really hope she won't stop sharing her amazing kernels with us🍵.

4
22
284
2022 Goals:. 1 Workout for 350 hours. 2 Compete on @kaggle for 200 Hours. 3 Write 3 Kaggle Kernels. 4 Host 50 meetups & interviews @weights_biases . 5 Spend 500 hours reading. 6 Write 4 High-Quality @PyTorch blogposts. 7 Publish 1 Open Source Repo.
11
15
285