

Edoardo Ponti
@PontiEdoardo
Followers
2,264
Following
421
Media
51
Statuses
370
Assistant Professor in #NLP at @EdinburghUni and visiting professor @nvidia | PhD @Cambridge_Uni | Humani nihil a me alienum puto
Edinburgh
Joined August 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
FEMA
• 1064823 Tweets
روما
• 512439 Tweets
بورتو
• 509847 Tweets
Tina Peters
• 120214 Tweets
Martinez
• 96118 Tweets
Porto
• 95350 Tweets
Manchester United
• 86122 Tweets
Avrupa
• 69299 Tweets
#okanburukistifa
• 65889 Tweets
Ten Hag
• 65358 Tweets
Hoca
• 46364 Tweets
Takım
• 45278 Tweets
Rashford
• 32993 Tweets
Dandadan
• 31137 Tweets
#BJKvSGE
• 29485 Tweets
Samu
• 29373 Tweets
Maguire
• 25091 Tweets
Mert
• 23527 Tweets
Nkunku
• 16528 Tweets
Antony
• 15787 Tweets
Onana
• 15476 Tweets
Mudryk
• 15113 Tweets
Bruno Fernandes
• 14601 Tweets
De Ligt
• 13908 Tweets
#PORMUN
• 12504 Tweets
Dalot
• 12359 Tweets
Veiga
• 11767 Tweets
Szymanski
• 10583 Tweets
بنزيما
• 10434 Tweets


















Pinned Tweet

2 papers accepted at NeurIPS!
SEA 🌊 Spectral Editing of Activations in LLMs (
@yifuqiu98
)
ZeTT ⛓️💥 Zero-shot Tokenizer Transfer (
@bminixhofer
)
Also, stay tuned for our tutorial on dynamic sparsity with
@andre_t_martins
!

Introducing Zero-Shot Tokenizer Transfer (ZeTT) ⚡
ZeTT frees language models from their tokenizer, allowing you to use any model with any tokenizer, with little or no extra training.
Super excited to (finally!) share the first project of my PhD🧵

30
148
742
1
10
81
I am delighted to share that I will be joining
@EdinburghNLP
at
@EdinburghUni
from 2022 as a lecturer in Natural Language Processing. I am currently recruiting PhD students, so if you are passionate... (1/6)
26
55
399
We scaled sparse fine-tuning (SFT) to LLMs (such as Llama 2) by making it both parameter- and memory-efficient!
(q)SFT instruction tuning performance is often better than (q)LoRA with comparable speed and memory load.
Paper:
Code:
2
70
251
Today I am joining
@nvidia
part-time as a visiting professor
I could not imagine a better place to explore new efficient architectures for LLMs and diffusion
I am looking forward to collaborating with so many talented researchers!
13
4
221
Multitask learning by decomposing tasks into sets of fine-grained skills (discrete, reusable, and autonomous facets of knowledge).
New work with Yoshua Bengio
@sivareddyg
from
@Mila_Quebec
and
@murefil
from
@MSFTResearch
📘:
💻:

3
31
160
I am still looking for PhD students starting in September 2024! The deadline to apply for the CDT in NLP is the 11th of March.
If you wish to do research in modular and efficient LLMs, here are some highlights of my lab's research from the past year ⬇️🧵

Interested in training with future leaders in NLP to engage with the cutting edge of the technical, social, design, and legal aspects of these systems? Then apply for our new Centre for Doctoral Training in Designing Responsible NLP! Deadline 11 March 2024
0
17
52
11
52
153
We connect inaccuracies of merging fine-tuned models to the mismatch between their gradients (through a target model), minimising which directly improves the performance.
New paper with
@ndaheim_
@tmoellenhoff
@IGurevych
@EmtiyazKhan

3
31
116
Do large language models like LLaMA 2 or GPT-4 learn *self-consistent* temporal models based on textual narratives?
Spoiler: not really
pdf:
With
@yifuqiu98
@zhengzhao97
@YftahZ
@annalkorhonen
Shay Cohen

3
19
118
Large language models often generate hallucinated responses.
We introduce Elastic Weight Removal (EWR), a novel method for faithful *and* abstractive dialogue.
📃
💻 +other methods!
🧑🔬
@ndaheim_
@nouhadziri
@IGurevych
@mrinmayasachan

1
19
108
I am looking for PhD students to join my group at
@EdinburghNLP
@EdinburghUni
and work on modular NLP, grounding, and typology!
The deadline for international applicants is Nov 25th for fully funded PhD programmes at CDT NLP and ILCC.
For more info:
1
42
100
A new method for the adaptation of pre-trained models that is modular, expressive, and parameter-efficient: Lottery Ticket Sparse Fine-Tuning
👨🔬 Alan Ansell, me,
@licwu
, and
@annalkorhonen
📄
👩💻

2
25
96
Can we increase the efficiency *and* performance of auto-regressive models?
We introduce dynamic-pooling Transformers, which jointly perform language modelling and token segmentation.
@p_nawrot
*
@AdrianLancucki
@JChorowski
📜
🧑💻
2
27
92
Can open-source LLMs execute *chains of instructions* in a single query? Not so well, we found.
However, they can learn this ability by:
- augmenting examples from public SFT mixtures with chains of instructions automatically
- performing *sequential instruction tuning* on them.

1
21
91
I am attending
#ACL2024
in Bangkok and I am giving a keynote talk at RepL4NLP on Thursday (15 Aug), "Efficiency as an Inductive Bias for Language Models"
Here is a preview with some hot takes and ideas!
0
15
98
Just passed my viva with minor corrections! Many thanks to my examiners, my supervisors
@annalkorhonen
and
@licwu
, and all those who supported me throughout the PhD

16
3
84
Polytropon is now available on the
@huggingface
peft library!
Consider using it for better generalisation when instruction tuning your LLM
Minimal example here (multi-task learning):
Many thanks to
@taosunvoyage
for the implementation!
Multitask learning by decomposing tasks into sets of fine-grained skills (discrete, reusable, and autonomous facets of knowledge).
New work with Yoshua Bengio
@sivareddyg
from
@Mila_Quebec
and
@murefil
from
@MSFTResearch
📘:
💻:
3
31
160
4
13
79
Adaper parameters are all you need in modular LLMs!
You can *build* inventories of experts by clustering tasks based on their LoRA params
You can *reuse* experts by routing zero-shot based on right singular vectors of their LoRA params

Towards Modular LLMs by Building and Reusing a Library of LoRAs
The growing number of parameter-efficient adaptations of a base large language model (LLM) calls for studying whether we can reuse such trained adapters to improve performance for new tasks. We study how to

3
66
275
0
10
73
In our new paper,
@KreutzerJulia
@licwu
@sivareddyg
and I present a method to enhance translation-based cross-lingual transfer (gains up to 2.7 per task and 5.6 per language). Pdf: . Code:
@Mila_Quebec
@CambridgeLTL
@GoogleAI
2
9
62
Our paper on multi-head routing in modular LLMs has now been accepted at
@NeurIPSConf
(), it was fun to work with
@LucasPCaccia
and
@sordonia
!
@EdinburghNLP
@Mila_Quebec
@MSFTResearch


New preprint :
To promote generalisation to new tasks, modular LLMs reuse and adapt previously acquired skills.
We propose a more expressive “multi-head” routing strategy, which achieves consistent gains.
Code:
Paper:
1
14
58
0
14
55
We introduce the idea of zero-shot *tokenizer* transfer
Our vision is to combine your favourite LLM with an arbitrary tokenizer on the fly
This means
- More efficient encoding for non-English text
- Mix experts with different tokenizers
Check
@bminixhofer
's thread for details!
Introducing Zero-Shot Tokenizer Transfer (ZeTT) ⚡
ZeTT frees language models from their tokenizer, allowing you to use any model with any tokenizer, with little or no extra training.
Super excited to (finally!) share the first project of my PhD🧵
30
148
742
0
11
55
We have created XCOPA, a dataset for commonsense reasoning and knowledge transfer across 11 languages (including Quechua and Haitian Creole).
@gg42554
O Majewska
@qianchul
@licwu
@annalkorhonen
Download: Paper:

1
13
53
We have re-opened 2 PhD studentships for *2023/24* at
@EdinburghNLP
(1 home, 1 international), please send me a message by tomorrow if you are interested in this opportunity!
4
22
50
Join us today at 9:20am (Irish time) for
@MML_WKSP
, the first Multilingual Multimodal Workshop at
#acl2022nlp
! We have a fantastic line-up of speakers:

0
10
49
During the workshop on efficient generative AI at
@InfAtEd
,
we discussed methods to reduce AI's energy costs and environmental impact while fostering AI democratisation and scientific discovery.
Here are some lessons I learned from the speakers: 🧵


1
5
47
Corpus-based measures reliably discriminate morphological inflection and derivation cross-linguistically!
@colemanhaley22
is presenting today at
@sig_typ
the first large-scale computational study (26 languages from
@unimorph_
) on this topic


🔥Language-Agnostic Measures Discriminate Inflection and Derivation
🖊️By Coleman Haley, Edoardo M. Ponti and Sharon Goldwater
📽️Talk:
📚Paper:
#SIGTYP2023
0
4
7
2
16
45
The applications for the
@ELLISforEurope
PhD programme are now open! If you'd like to join
@EdinburghNLP
and do research on modular deep learning (parameter-efficient fine-tuning, routing in mixture-of-experts, model merging, ...) or computational typology, drop me a message!

The portal is open: Our
#ELLISPhD
Program is now accepting applications! Apply by November 15 to work with leading
#AI
labs across Europe and choose your advisors among 200 top
#machinelearning
researchers!
#JoinELLISforEurope
#PhD
#PhDProgram
#ML
6
175
418
4
15
44
We retrofit LLMs by learning to compress their memory dynamically
I find this idea very promising as it creates a middle ground between vanilla Transformers and SSMs in terms of memory/performance trade-offs
I'd like to give a shout-out to
@p_nawrot
and
@AdrianLancucki
for the

The memory in Transformers grows linearly with the sequence length at inference time.
In SSMs it is constant, but often at the expense of performance.
We introduce Dynamic Memory Compression (DMC) where we retrofit LLMs to compress their KV cache while preserving performance

10
73
446
0
7
43
Very excited about this line of research! You can find the conclusions "in a nutshell" at the end of the survey, as well as a list of open challenges

In our new survey “Modular Deep Learning”, we provide a unified taxonomy of the building blocks of modular neural nets and connect disparate threads of research.
📄
📢
🌐
w/
@PfeiffJo
@licwu
@PontiEdoardo
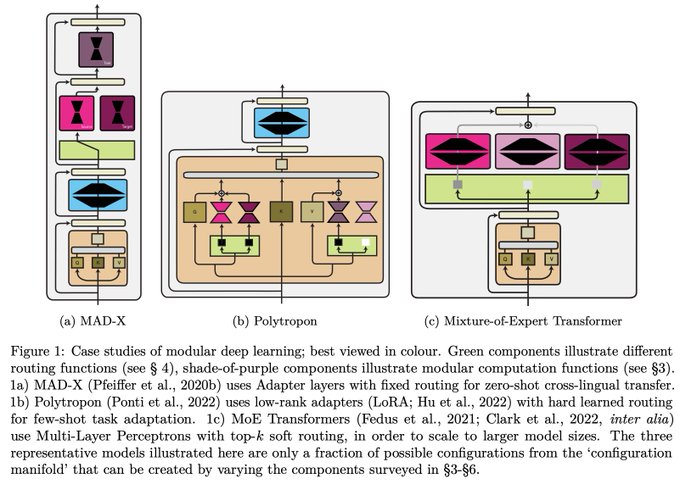
8
97
425
0
4
41
It was fun to meet so many people curious about dynamic memory compression!

Tomorrow at
@icmlconf
, together with
@PontiEdoardo
and
@AdrianLancucki
, we'll present an updated version of "Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference".
You can find an updated paper at . Among others - 1) We trained DMC to

7
26
85
0
4
41
I am attending
@icmlconf
in Vienna this week, come find me and my co-authors (tagged below) to discuss ideas for efficient / modular / NeSy LLMs!
1
7
39
Really proud of my student Yifu Qiu (co-supervised with Shay Cohen and
@annalkorhonen
), who won the 2023 Apple Scholars in AI ML PhD fellowship! He has a bright future ahead of him.
@EdinburghNLP
@EdinburghUni
@CambridgeLTL
@Cambridge_Uni
0
2
39
Multilingual task-oriented dialogue is authentic if it displays natural fluency 🌊 and familiar entities 🛥️. In Cross-Lingual Outline-based Dialogue (COD 🐟), we set out to achieve exactly this!
💻
📝

3
10
38
"Differentiable Generative Phonology", in collaboration with
@EzraWu
and
@ryandcotterell
, is finally out!
Tired: Asking linguists to posit discrete underlying forms
Wired: learning continuous underlying forms end-to-end
1
12
35
I am crossing Adrian's wall to give a series of invited talks in England!
- 27/5 2 pm
@OxUniMaths
:
- 29/5 noon
@KingsCollegeLon
: Bush House (S) 2.01
- 30/5 5:30 pm
@ucl_nlp
:
- 4-5/6
@CambridgeLTL
1
4
31
Interested in integrating deep learning with symbolic algorithms, knowledge bases, and programmes?
Apply for a 2-year postdoc position with me,
@PMinervini
, and
@tetraduzione
at ELIAI
@EdinburghUni
on gradient-based learning of complex latent structures.

0
15
31
This paper required a Herculean effort, but it was worth it! The aspect that I like the most is that it enables transfer learning along 3 different axes: languages, tasks, and modalities

Voilà IGLUE🧊 The Image-Grounded Language Understanding Evaluation benchmark 📈
IGLUE brings together 4 vision-and-language tasks across 20 languages
And, brr, is it cold outside the Anglosphere 🥶
📄
👩💻
🌐

4
42
167
0
4
29
If you are curious to discover more about Dynamic Memory Compression, I will give a preview during my keynote talk at the MOOMIN workshop
@eaclmeeting
See you on Thursday, March 21st at 9:30 AM!
The memory in Transformers grows linearly with the sequence length at inference time.
In SSMs it is constant, but often at the expense of performance.
We introduce Dynamic Memory Compression (DMC) where we retrofit LLMs to compress their KV cache while preserving performance
10
73
446
0
4
27
The best part is: you can adapt models from
@huggingface
with our SFTs in just 3 lines of code:
from sft import SFT
sft_model = SFT(sft_model_name)
sft_model.apply(pretrained_model)

0
4
27
I am committed to selecting a diverse set of candidates with high potential, as the various communities of speakers around the world should also find representation in the NLP & ML scientific communities
@Khipu_AI
@DeepIndaba
@MasakhaneNLP
(5/6)
1
1
25
We report gains for zero-shot learning on 33 languages and 2 tasks (POS and NER). Paper: . Code: Thanks to all the co-authors!
@licwu
@ryandcotterell
M. Parovic
@roireichart
@annalkorhonen
1
7
23
...about multilingual and low-resource NLP, sample-efficient and modular machine learning, computational typology, or grounded language learning, consider applying to my group! (2/6)
2
0
23
It was lovely to visit the other place again and talk about modular deep learning. Thanks
@oxfordnlp
for the invite!

0
0
25
Given the paucity of annotated data, how can we perform sample-efficient generalization on unseen task-language combinations? Possible solution: a generative model of the neural parameter space, factorized into variables for several languages and tasks. 1/2
1
5
24
Many *fully funded* studentships (from September 2022) are available:
👩🏻🎓12 for a 4-year PhD with integrated study from the NLP CDT:
👨🏿🎓10 for a 3-year PhD from ILCC:
(3/6)
1
5
23
Grammatical markers are implicitly aligned in pre-trained multilingual encoders by encoding the same grammatical functions through the same subset of neurons across languages. This may help explain the "unreasonable" effectiveness of zero-shot cross-lingual transfer.

Excited to share our new
#NAACL2022
paper: "Same Neurons, Different Languages: Probing Morphosyntax in Multilingual Pre-trained Models". (1/4)
In collaboration with
@PontiEdoardo
@ltorroba1
@ryandcotterell
@IAugenstein
#NLProc

5
30
159
2
9
21
A little gem from my student
@p_nawrot
: nanoT5, or how to pre-train T5 on 1 GPU, in less than 1 day, in Pytorch.
Now it is more important than ever to keep research accessible and reproducible.
He conceived the idea and executed it all by himself, quite a remarkable feat!
Introducing *nanoT5*
Inspired by
@jonasgeiping
's Cramming and
@karpathy
's nanoGPT, we fill the gap of a repository for pre-training T5-style "LLMs" under a limited budget (1xA100 GPU, ~20 hours) in PyTorch
🧑💻
@EdinburghNLP

8
85
457
0
7
19
Fantastic work from my student
@yifuqiu98
:
- the first metric to measure hallucinations in generated text for *any* language
- an empirical study of how cross-lingual transfer amplifies hallucinations
- a new method of "soft filtering" / loss weighting to promote faithfulness

[1/5] Our paper "Detecting and Mitigating Hallucinations for Multilingual Summarisation" is currently available on Arxiv!
📃
💻
🤝
@YftahZ
@annalkorhonen
@PontiEdoardo
and Shay B. Cohen
0
12
36
0
3
19
Meet me at
@eaclmeeting
! At 11:15 I am presenting Polytropon, a method for multi-task modular adaptation of LLMs
The code is part of a 🚨new repo for multi-task transfer learning 🚨developed with
@LucasPCaccia
@murefil

0
0
17
@tallinzen
If anything, there is increasing evidence to the contrary. For instance, LLMs lack self-consistent world models as they believe contradicting timelines to be true:
0
1
15
For any enquiry, feel free to reach out to me via email or talk to me virtually at
#EMNLP2021
(and attend our team's best paper award presentation!). I hope there will be a chance to meet some of you and discuss exciting research directions! (6/6)
0
0
13
Third (and last) paper at
#EMNLP2018
(actually TACL):
@dasgerz
and
@licwu
carefully explaining our novel Language Modeling architecture with output matrix refinement

0
2
15
Are you working on Natural Language Understanding? Then have a look here:
@CambridgeLTL
has just released the post-specialised word embeddings for GloVe, fastText, and SGNS. Pre-trained models to specialise new (cross-lingual) WEs are also available!

0
6
14
Do not hesitate to reach out if you are interested!

The school of informatics at the University of Edinburgh and DeepMind are offering an ML PhD scholarship for students who identify as gender/racial/ethnic minorities in 2022/23. See thread for details. (1/n)
4
77
235
3
2
13
Code and paper to adversarially propagate and zero-shot transfer semantic specialization of word embeddings, to appear in
#emnlp2018
: Huge thanks to all co-authors
@licwu
@gg42554
@nikola_mrksic
Anna Korhonen
#NLProc
0
3
14
By the way,
@AlanAnsell5
(the first author) is graduating from
@Cambridge_Uni
and will be on the job market soon.
He did amazing research on PEFT and multilingual NLP, make sure to reach out to him if you have a position open!

We scaled sparse fine-tuning (SFT) to LLMs (such as Llama 2) by making it both parameter- and memory-efficient!
(q)SFT instruction tuning performance is often better than (q)LoRA with comparable speed and memory load.
Paper:
Code:
2
70
251
0
1
13
Don't miss the tutorial at
@emnlp2019
with
@licwu
,
@gg42554
, and me for the latest developments in semantic specialization (knowledgeable unsupervised pretraining, cross-lingual transfer, and more). Registration is now open:
0
3
13
Ensuring that language technologies are globally equitable is ever more important.
I am looking forward to collaborating on this
@ERC_Research
grant!

Absolutely thrilled to receive an ERC Advanced Grant to study how to make language technologies globally more equitable. Thanks to the amazing team
@roireichart
@licwu
@anna_barford
@PontiEdoardo
@CambridgeLTL
- and to colleagues & friends for support!
#ERCAdG
@ERC_Research
5
4
42
0
0
13
Fantastic new work from
@nouhadziri
: data-centric + modelling solutions can remove most hallucinations from knowledge-grounded dialogue and increase its quality (e.g. abstractiveness)!

📢 Excited to share our new work 💥
FaithDial: A Faithful Benchmark for Information-Seeking Dialogue
📄
🌐
👩💻
joint work w.
@sivareddyg
,
@PontiEdoardo
,
@ehsk0
,
@ozaiane
, Mo Yu, Sivan Milton
#NLProc
2
18
60
1
2
12
I have just accepted an offer for a position as an
#ML
/
#NLP
Engineering Intern at
#Apple
in Cupertino, California. Looking forward to this new adventure! (And curious to admire Norman Foster's
#applepark
)
1
0
12
You can easily load XCOPA from
@huggingface
's dataset library:
from datasets import load_dataset
xcopa = load_dataset('xcopa')
It contains extremely under-documented languages like Southern Quechua and Haitian Creole.
1
1
11
Come and meet me at the
#EMNLP2020
Q&A session (6B) about XCOPA, a novel multilingual dataset for common-sense reasoning.
When? Nov 17, 9:00 UTC (tomorrow!)
Data and leaderboard:
1
2
11
To keep the memory load proportional to the PEFT size instead, we alternate among:
1) updating deltas wrt LLM weights
2) dropping old indices based on their magnitude of change
3) growing new indices based on newly introduced criteria: AG and MA
This alternation is inspired

1
1
10
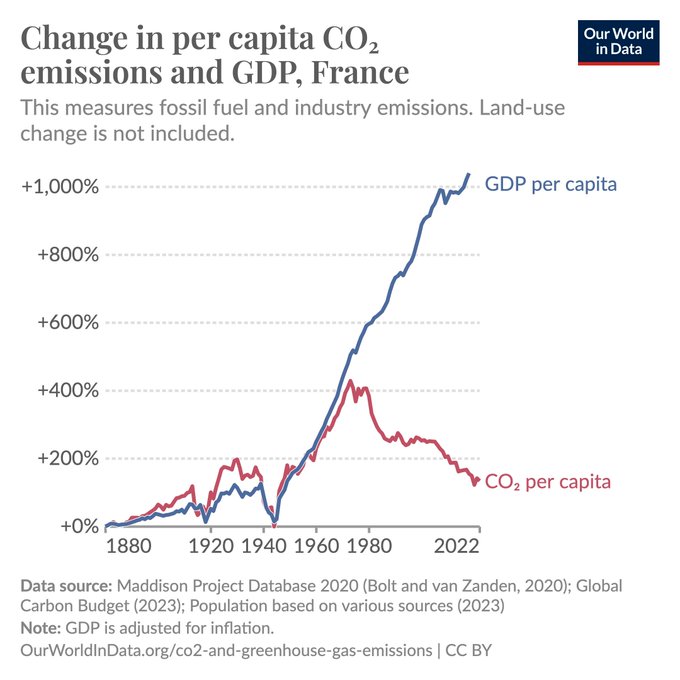
This is the path that Italy should have followed, too. It's not too late to correct course.

Until 50 years ago, CO₂ emissions developed in lockstep with economic growth in France.
Since the early 1970s, the opposite has been true: emissions declined as people in France got richer.
158
944
5K
0
1
10
Momentum Approximation (SFT-MA) for even higher memory efficiency
- reuses approximate momenta from efficient optimizers like
@_arohan_
's SM3
- performs a dot product between row-wise and column-wise weight statistics
- selects the arg top-k subset of indices for growth
MA is

1
1
9
We compare different methods to learn an auto-regressive boundary predictor:
- end-to-end (Gumbel)
- supervision from subword tokenizers (Unigram)
- data boundaries (Whitespaces)
We also propose a new segmentation method based on the entropy spikes of the model’s prediction.

1
1
9
A group of researchers from
@AIMS_Next
AMMI has devised a promising research project on modelling text and speech in 10 Ghanaian languages. Are you aware of any source of funding (in addition to
@LacunaFund
) they could apply to for this project?
1
5
9
@kroscoo
@LrecColing
Bonus: pay a visit to the Egyptian museum, it's considered the 2nd most important collection in the world after Cairo
0
0
9
How well do neural models generalise to new image domains, concepts, and languages?
Check out MaRVL, a benchmark for grounded language learning created to better reflect the world's cultural and linguistic diversity.
🌐
Is multimodal technology mature enough to be used around the world?
We introduce MaRVL, a multilingual and multicultural dataset for vision-and-language reasoning!
@hardy_qr
@PontiEdoardo
@sivareddyg
@nigelhcollier
@delliott
🗣️
#EMNLP2021
🌐

2
7
61
0
0
8
SFT (bottom) scatter-adds a sparse matrix to the LLM pre-trained weights
LoRA adds a low-rank matrix (top).
While more expressive and composable, the memory needed for SFT (DiffPruning, FISH Mask, Lottery Ticket) previously scaled with the model size.
This made SFT

1
0
8
Let's talk research over a glass of wine if you're curious about my lab's recent work on dynamic memory compression, sparse fine-tuning, mixtures of adapters, and zero-shot tokenizer transfer!
Thanks to
@ShiweiLiu9
@zhengyuan_nlp
@oanacamb
@annalkorhonen
for the invites!
0
0
6
@NandoDF
My lab proposed an auto-regressive Transformer architecture that dynamically merges tokens in intermediate layers
Promising for multimodal data as 1) tokenizer-free, 2) discards uninformative bits, 3) can learn abstractions at different granularities
Can we increase the efficiency *and* performance of auto-regressive models?
We introduce dynamic-pooling Transformers, which jointly perform language modelling and token segmentation.
@p_nawrot
*
@AdrianLancucki
@JChorowski
📜
🧑💻
2
27
92
0
0
8
A fantastic lineup of speakers to discuss the future of efficient generative AI at
@InfAtEd
!
We are excited to announce that on May 24th and 25th,
@InfAtEd
will host the *International Workshop on Efficient Generative AI*
The event will feature invited talks, panels, posters, and networking sessions.
Website and programme:
1
6
19
0
4
8
LT-SFT achieves large gains over adapters (such as MAD-X) in zero-shot transfer to unseen and low-resource languages, including African and American languages
@MasakhaneNLP
@AmericasNLP

1
0
7
⚠️The application deadlines are fast approaching!
📅26 November 2021 for international / EU applicants
📅28 January 2022 for UK applicants
(4/6)
1
0
7
0
1
7
Finally, our latent-skill model helps interpret the relationships among tasks, as the allocation matrix corresponds to an explicit hierarchy of tasks.

0
1
6
In ordering events, even SOTA GPT-4 lags behind human performance *and* TemporalBART, a small-scale LM fine-tuned on abundant data for this task
Still, conversational tuning of LLaMA 2, instruction tuning with Alpaca, and RLHF are broadly helpful to temporal reasoning
1
1
6
In particular, we learn end-to-end how to 1) allocate subsets of latent skills to multiple tasks; 2) specialise an inventory of parameter-efficient model sub-networks towards individual skills; 3) combine these to dense pre-trained or randomly initialised models.

1
1
6
I am in Hong Kong for
@emnlp2019
, feel free to get in touch if you are interested in few-shot (multilingual) learning, Bayesian neural models, or semantic specialization: I'd be curious to hear your opinions! On a related note, I have a couple of talks on these topics tomorrow 👇
1
1
6
How to suppress negative (or encourage positive) behaviours with EWR?
- Create task vectors as the change between (anti)experts fine-tuned on behaviour exemplars and initialisation
- Subtract (or add) the task vectors from a pre-trained model, weighted by their Fisher Information

1
0
6
The gains from dynamic pooling Transformers do not vanish with higher numbers of layers.
Hence, they hold promise to further facilitate scaling in language models.

0
0
6
@TonyZador
Brilliant paper! The core idea is reminiscent of Konrad Lorenz's 'Behind the Mirror'. In AI, the inductive bias can also be conceived as a prior over neural parameters . E.g. for learning languages (to appear at
@emnlp2019
):
0
2
6
Two outstanding papers at
#ACL2023NLP
from
@EdinburghNLP
, congratulations to all the authors!
Congratulations to
@nikita_moghe
,
@tomsherborne
, Matthias,
@alkoller
,
@iatitov
,
@alexandrabirch1
, and Mark for your ACL 2023 Outstanding Papers!! 🚀🧑🎓
Extrinsic Evaluation of MT Metrics ()
Compositional Generalization without Trees ()
1
15
81
0
0
6
Joint work from Olga Majewska*,
@erazumovskaia
*, me,
@licwu
, and
@annalkorhonen
. 🍒🍰 We are also presenting a tutorial on multilingual dialogue at
#ACL2022
, don't miss it!
0
2
6
We can’t probe temporal grounding directly as LLMs are incapable of action or perception.
So we probe LLMs on textual tasks that require an implicit temporal model:
- commonsense knowledge about events
- ordering events along a timeline
- self-consistency in the temporal model

1
2
6
This is, I believe, one of our main contributions: most SOTA methods for removing hallucinations in a single repo!
As baselines, we adapt a series of techniques to faithful dialogue generation and we offer their first systematic comparison
Task Arithmetic, CaPE, Quark, DExperts, and CTRL are all available in our repository!
We welcome external contributions and plan to add more techniques
0
0
4
0
0
6
Inflection and derivation are crucial comparative concepts; yet, their definition is contentious.
Linguists proposed several criteria: e.g., Plank (1994) lists 28, which yield contradictory results.
@haspelmath
even argued that their distinction carries no theoretical weight.

1
2
5
[3/3] Towards Modular LLMs by Building and Reusing a Library of LoRAs
@LucasPCaccia
Towards Modular LLMs by Building and Reusing a Library of LoRAs
The growing number of parameter-efficient adaptations of a base large language model (LLM) calls for studying whether we can reuse such trained adapters to improve performance for new tasks. We study how to
3
66
275
0
0
5
Tomorrow I am giving a talk on AI and language at my alma mater
@unipv
, in a conference hosted by
#CollegiodelMaino
. If you are in Pavia, hope to see you there!

Giovedì si terrà la conferenza “Prospettive dell’Intelligenza Artificiale”, che si pone l’obiettivo di mettere a confronto punti di vista applicativi diversi dello stesso fenomeno, ormai attualissimo, dell’
#IntelligenzaArtificiale
#CollegiodelMaino
#unipv
0
2
4
0
0
5
@nathanbenaich
We had a similar finding with Dynamic Memory Compression: the KV cache in deeper layers can be compressed to a high degree without degrading performance -very fascinating!
2
0
6
In natural languages, units of meaning (such as words) vary in size.
Our model predicts their boundaries, average-pools representations in the same unit, and processes them more efficiently.
For a shortening factor K of the input length, attention complexity reduces by K^2.
1
0
6
@karpathy
A solution would be to swap tokenizer on the fly to avoid glitch tokens.
We've just released our work on zero-shot tokenizer transfer which (coincidentally) does exactly this!
Introducing Zero-Shot Tokenizer Transfer (ZeTT) ⚡
ZeTT frees language models from their tokenizer, allowing you to use any model with any tokenizer, with little or no extra training.
Super excited to (finally!) share the first project of my PhD🧵
30
148
742
0
0
6
@VeredShwartz
H is a legitimate note in the German notation, and is equivalent to B. This is how Bach wrote his name as a motif in the Art of Fugue 😉
1
0
5
@nouhadziri
Also, it contains the largest-scale audit of gold-standard benchmarks to date, revealing that e.g. 71.4% of turns in Wizards of Wikipedia are hallucinated. Even worse, language models tend to not only 🦜 but even amplify this noise.
0
0
5
We train linear and MLP classifiers on these features and recover most (86% and 90%, respectively) of the classes of the constructions in
@unimorph_
(which we take to reflect the intuitions of linguists on what constitutes inflection and derivation)

1
0
5
@v4rmer
@EdinburghUni
@johannesbjerva
@aautech
@CompSciAAU
@EdinburghNLP
It was truly a pleasure to host you
@v4rmer
! And thanks to
@johannesbjerva
for making your visit possible
0
0
5
A simple modification of
@jefrankle
and
@mcarbin
's algorithm to find "winning tickets" allows for composing (rather than pruning) pre-trained models with sparse, real-valued masks that represent different facets of knowledge (languages, tasks, ...)

1
0
4