

Keiran Paster
@keirp1
Followers
4K
Following
4K
Media
190
Statuses
3K
Introducing OpenWebMath, a massive dataset containing every math document found on the internet - with equations in LaTeX format!. 🤗 Download on @HuggingFace: 📝 Read the paper: w/ @dsantosmarco, @zhangir_azerbay, @jimmybajimmyba!

34
250
1K
Can large language models write prompts…for themselves? Yes, at a human-level (!) if they are given the ability to experiment and see what works. with @Yongchao_Zhou_, @_AndreiMuresanu, @ziwen_h, @silviupitis, @SirrahChan, and @jimmybajimmyba .(1/7)
15
109
429
Which LLMs are generally good at math and which are overfitting to benchmarks?. With the release of Grok, @xai evaluated several closed models on a Hungarian national finals math exam which was published after the models were trained. This means it is impossible to train on or


24
84
551
Meet STEVE-1, an instructable generative model for Minecraft. STEVE-1 follows both text and visual instructions and acts on raw pixel inputs with keyboard and mouse controls. Best of all - it only cost $60 to train!. w/ @Shalev_lif @SirrahChan @jimmybajimmyba @SheilaMcIlraith
11
93
318
We released a beta of our API and we are giving everyone $25 free credits a month until the end of the year to give it a try! . 🔗 The first model available in our API is grok-beta, a preview of our next-gen Grok model (this version has around the same.
9
25
181
Super cool - seems like labeling documents as <good> or <bad> at the beginning of the sequence during pretraining outperforms throwing out the bad data. Lots of parallels to supervised RL / decision transformer as well.

Pretraining Language Models with Human Preferences. Pretraining with human feedback results in much better preference satisfaction than standard LM pretraining followed by finetuning with feedback, i.e., learning and then unlearning undesirable behavior.

4
24
217
We dramatically improved our model in the short time between our sus-column-r and official release, now sitting at the #2 spot overall!. We also doubled the speed of our inference in the last week. The rate of progress at xAI is unreal.

Chatbot Arena update❤️🔥. Exciting news—@xAI's Grok-2 and Grok-mini are now officially on the leaderboard!. With over 6000 community votes, Grok-2 has claimed the #2 spot, surpassing GPT-4o (May) and tying with the latest Gemini! Grok-2-mini also impresses at #5. Grok-2 excels in

5
7
157
APE generates “Let’s work this out in a step by step way to be sure we have the right answer”, which increases text-davinci-002’s Zero-Shot-CoT performance on MultiArith (78.7 -> 82.0) and GSM8K (40.7->43.0). Just ask for the right answer? @ericjang11 @shaneguML
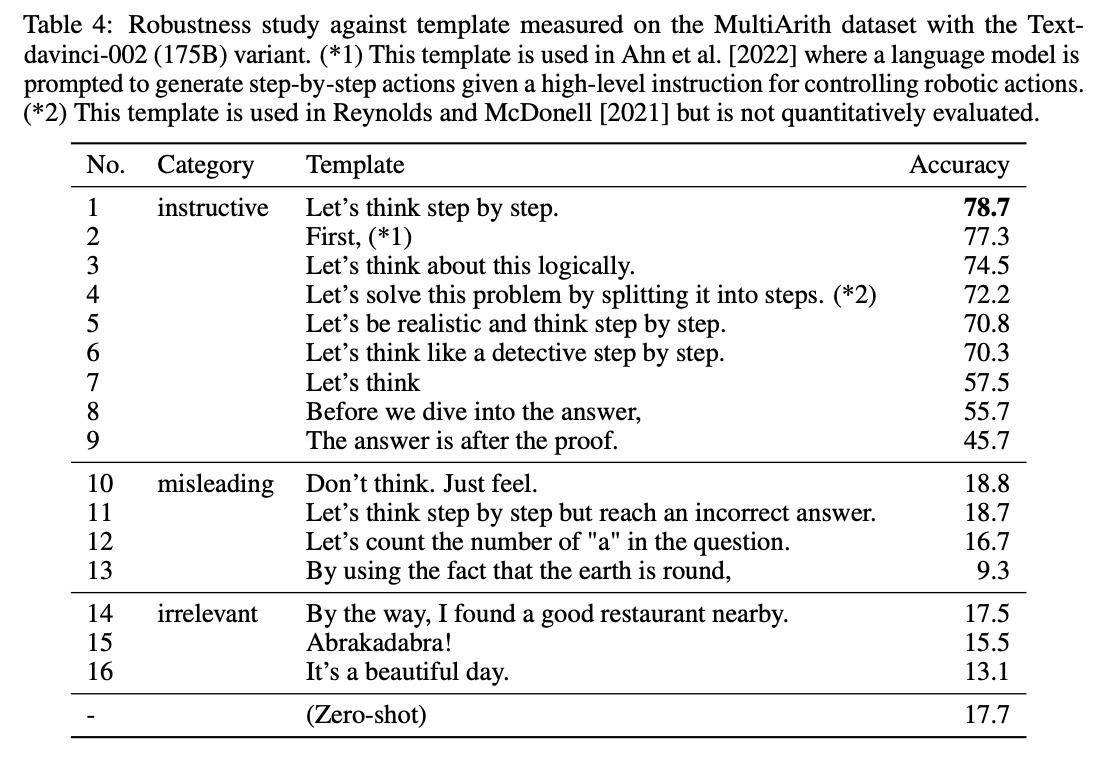

3
14
100
Following up on my previous post, I hand-graded held-out* math exams from the recently released Qwen 72B and DeepSeek 67B Base/Chat. It seems like they perform similarly to Claude 2!. DeepSeek 67B: 37%.GPT-3.5: 41%.Qwen 72B: 52%.Claude 2: 55%.DeepSeek 67B Chat: 56%.Grok-1: 59%

2
17
73
Very fun to watch people speculate this week about our sus model ඞ.
Woah, another exciting update from Chatbot Arena❤️🔥. The results for @xAI’s sus-column-r (Grok 2 early version) are now public**!. With over 12,000 community votes, sus-column-r has secured the #3 spot on the overall leaderboard, even matching GPT-4o! It excels in Coding (#2),

4
0
69
Super happy that OpenWebMath was accepted to ICLR 2024! When we first submitted the paper to the conference, I was very unsure whether it would get in. In my experience, academia has a strong preference towards works with clever ideas, lots of math, and fancy algorithms or.
6
5
56
Here's some more in-depth info on the different stages in the OpenWebMath processing pipeline:. Prefiltering: We apply a simple prefilter to all HTML documents in Common Crawl in order to skip documents without mathematical content to unnecessary processing time. This reduced our


0
8
56
Searching for the right prompt? APE makes it easy to find a prompt that works for your language modeling task. Try our official release:.Colab: GUI: GitHub:
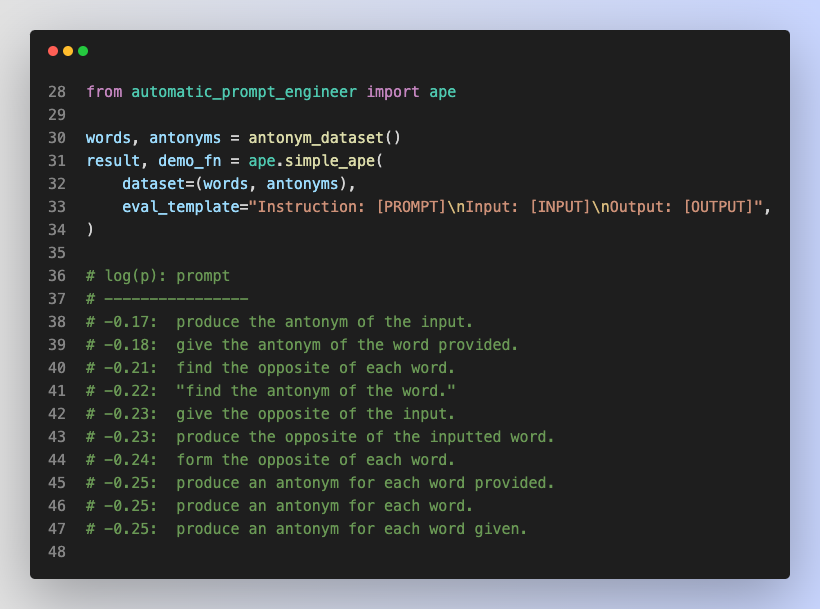
5
8
50
Heading back to Toronto after spending the fall at Google hosted by @HarshMeh1a and working with amazing Blueshift and Gemini teammates! It's a really fun time to work on LLMs and I hope to be back soon!

1
5
44
Proud to introduce Llemma, the first models trained on OpenWebMath (part of the 55B mathematical tokens in ProofPile II). Llemma serves as a platform for future research on quantitative reasoning and is a very powerful base model for mathematical tasks!.

We release Llemma: open LMs for math trained on up to 200B tokens of mathematical text. The performance of Llemma 34B approaches Google's Minerva 62B despite having half the parameters. Models/data/code: Paper: More ⬇️
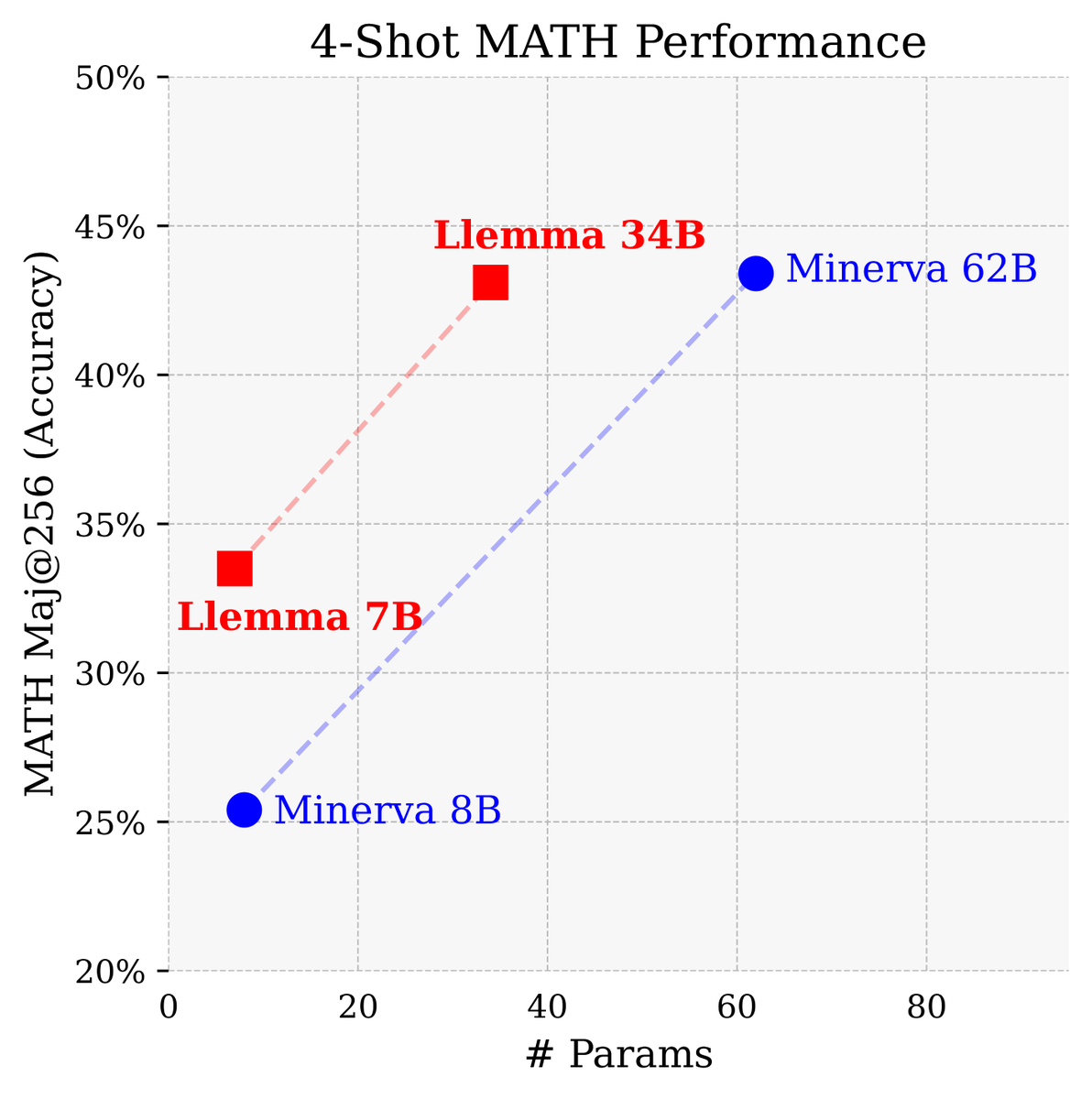
2
9
44
We know that LLMs can improve their performance on reasoning tasks by prepending “Let’s think step by step” to the model’s answer. We used APE to automatically optimize this phrase to increase the likelihood of the model producing correct reasoning.
Searching for the right prompt? APE makes it easy to find a prompt that works for your language modeling task. Try our official release:.Colab: GUI: GitHub:
1
5
46
DeepSeekMath seems like a next generation Llemma/Minerva-type model, with insane performance. They use a really clever trick to iteratively gather more high quality webpages from Common Crawl (bootstrapped from OpenWebMath)!.

1
5
43
Why is this a big deal? One year ago, Google published Minerva 🦉, a powerful LLM capable of impressive mathematical reasoning. One of the key ingredients in Minerva is a closed dataset of every math document on the web, something that isn’t available to the academic community.
1
3
43
Do Decision Transformers work in stochastic 🎲 environments? Not out of the box, but with a small change (condition on return -> condition on average return), they can! Here’s how. Paper: .with @SheilaMcIlraith and Jimmy Ba
1
6
42

We’re excited to see the types of models that can be trained using OpenWebMath!. Read our paper: Code available at: Download the dataset:

1
4
34
OpenWebMath is a huge step towards open LLMs that can do quantitative reasoning since we now have an equivalent dataset that is openly accessible!.
1
0
31
Heading to NeurIPS in New Orleans Tuesday-Sunday!. I'll be presenting:.- STEVE-1 (spotlight!).- OpenWebMath (Oral @ MathAI workshop).- Llemma (MathAI workshop). DM me if you want to chat about reasoning or what it takes to get from today's LLMs to AGI.

2
3
31
Heading to ICML tomorrow through Sunday. I'll be presenting our work on instruction-tuning generative models for Minecraft (STEVE-1) at the ILHF and SPIGM workshops. These days I'm working mostly on LLMs x Reasoning. DMs are open if you want to chat!.
2
2
30
With over 200B HTML documents in Common Crawl, finding mathematical documents on the web is like finding needles in a haystack. We use a complex pipeline with five steps: prefiltering, extraction, filtering, deduplication, and manual inspection.

1
0
30
I’m traveling to New Orleans ✈️ to attend NeurIPS next week! Please reach out if you would like to meet up! . I'll be presenting three papers investigating the relationship between sequence modeling and optimal decision-making.
2
2
31


The dataset includes 14.7B tokens from all popular reference websites (Wikipedia, nLab), forums (MathHelpForum, MathOverflow), blogs (Wordpress, Blogspot), and more! Curious how we processed Common Crawl at scale to mine for mathematical documents? See the 🧵 below!.
1
0
29

One of the most interesting parts of our pipeline is the MathScore classifier - trained to predict whether a document contains LaTeX symbols based only on the surrounding English words. This is a powerful tool that lets us find documents even when math isn’t in a common format.

1
0
27
Excited to share our work on learning latent world models that track the controllable aspects of an environment: With Sheila McIlraith and Jimmy Ba (1/9)
2
8
24
We found that even small models trained on OpenWebMath far surpass the performance of those trained on prior math datasets and also surpass the performance of models trained on over 20x the amount of general-domain data! 🚀

1
0
24
@_akhaliq Thanks for sharing! Please see our thread for more information:
Can large language models write prompts…for themselves? Yes, at a human-level (!) if they are given the ability to experiment and see what works. with @Yongchao_Zhou_, @_AndreiMuresanu, @ziwen_h, @silviupitis, @SirrahChan, and @jimmybajimmyba .(1/7)
0
3
24
Our method is heavily inspired by unCLIP, the method behind DALL•E 2. STEVE-1 combines a policy trained using supervised learning (like Decision Transformer) to achieve goals given in the MineCLIP embedding space, and a prior which translates text into these MineCLIP embeddings.

1
3
25
It turns out that when we endow language models with the capability to try out different generated prompts before deciding on one, the performance of their prompts skyrockets to human-level! 🚀 .(3/7)
1
1
24

The Grok button is one of my favorite new features. If you see a post that confuses you or you have questions about, hit the Grok button.

2
0
20

Interestingly, we found that the same tricks that benefit generative text-to-image models like DALL•E 2 and Stable Diffusion, namely classifier-free guidance and careful prompt engineering, have a significant effect on the performance of STEVE-1!


1
1
20
We formulate prompt engineering as a black-box optimization problem guided by LLMs: we use LLMs to generate candidate prompts, to evaluate their performance, and to iteratively propose new ones. We call our solution Automatic Prompt Engineer (APE). (4/7)

1
3
20
Really cool. Minecraft is a really complex environment with a lot of possibilities for AI research that was notoriously hard for RL due to hard exploration, but adding 70k hours of unlabeled video lets an RL agent get all the way to finding diamonds! 💎⛏.

Introducing Video PreTraining (VPT): it learns complex behaviors by watching (pretraining on) vast amounts of online videos. On Minecraft, it produces the first AI capable of crafting diamond tools, which takes humans over 20 minutes (24,000 actions) 🧵👇
0
2
18
Another banger paper from @aahmadian_ and @CohereForAI.

PPO has been cemented as the defacto RL algorithm for RLHF. But… is this reputation + complexity merited?🤔. Our new work revisits PPO from first principles🔎. 📜. w @chriscremer_ @mgalle @mziizm @KreutzerJulia Olivier Pietquin @ahmetustun89 @sarahookr

0
1
17
@xai Thanks to @agarwl_ for pointing out that question 14b on the exam was not transcribed correctly and @WenhuChen for suggesting to try the Llama-2 version of MAmmoTH-7B. These issues are now fixed on the Huggingface page and I also updated the figure.

0
6
17
More information on our processing pipeline:.
Here's some more in-depth info on the different stages in the OpenWebMath processing pipeline:. Prefiltering: We apply a simple prefilter to all HTML documents in Common Crawl in order to skip documents without mathematical content to unnecessary processing time. This reduced our
1
0
17
So many really exciting papers submitted from my lab to ICML this year!!🌴.
1
1
16

Another interesting prompt found using APE: rather than ask GPT to translate to Spanish directly, ask it to pretend as if it's using Google Translate for stronger performance!.

Neat result from applying automated prompt generation on translation. Referencing "Google Translate" in the prompt improves the performance of the model.

0
1
14
2) Use GPT insert-mode to generate 500 candidate prompts that start with "Let's".3) Find the prompts that maximize the likelihood of correct reasoning. (I forgot to include a few arguments in the prev tweet so here's an updated code snippet.).(2/2)

2
0
13


I'll be presenting ESPER at the Decision Awareness in RL (DARL) workshop at #ICML this Friday! Come stop by the poster (Hall G, 4:30 and 7pm) or ping me if you want to chat!.
Do Decision Transformers work in stochastic 🎲 environments? Not out of the box, but with a small change (condition on return -> condition on average return), they can! Here’s how. Paper: .with @SheilaMcIlraith and Jimmy Ba
0
1
12
Interestingly, while prior work suggests instruction induction might be an emergent ability in larger models, we find APE’s performance scales smoothly w/ more parameters. Smaller models (even w/o instruction fine-tuning) perform quite well. (7/7)

1
0
11
@realGeorgeHotz @tiktok_us Why do we need a separate, custom model for each user? Seems to me like a model trained on everyone and conditioned on some user information would be better.
2
0
11
Large language models can be instructed to infer prompts from demonstrations (Honovich et. al. 2022). However, the performance of these automatically-generated prompts often fall short of those authored by humans. (2/7)


1
0
11
In our experiments, APE generates human-level prompts from demonstrations in 19 out of 24 instruction-induction tasks, nearly doubling the performance vs. prior work (greedy) and matching the performance of the human-authored prompts. (5/7)

2
0
11
Like the boosting methods that dominate on tabular datasets, an ensemble of prompts can be selected by iteratively adding new prompts that cover the weaknesses of previous ones. Clever way to make prompt ensembles that cover all possible types of qs.

Boosted Prompt Ensembles for LLMs. -Construct a small set of few-shot prompts that comprise a "boosted prompt ensemble'".-Examples chosen stepwise to be ones previous step's ensemble is uncertain of.-Outperforms single-prompt output-space ensembles.

0
0
10
@GanjinZero Also this model already gets 85% pass@64 and 80% pass@16. So the problem is reduced to creating a verifier that can select the correct answer out of a quite small pool of candidates.

1
1
10
RT and Follow to win a Championship Thresh skin code (already used in NA). Good luck!.
18
75
8
@DynamicWebPaige @Minecraft Thanks Paige! I really think finetuning VLMs is the future for generalist agents and we are lucky that such strong foundation models already existed for Minecraft. In the near future (using Gemini?) such agents will probably be possible in all sorts of other domains, so it's an.
1
1
8
Strong 2B model trained on OpenWebMath with a ton of training details shared:.

🌟Meet #MiniCPM: An end-side LLM outperforms Llama2-13B. 🏆It is similar to Mistral-7B in the comprehensive rankings and the overall score surpasses Llama2-13B,Falcon -40B and other models. GitHub:Huggingface: #MiniCPM


0
1
9
@_akhaliq Thanks for sharing! See our thread for more info:
Meet STEVE-1, an instructable generative model for Minecraft. STEVE-1 follows both text and visual instructions and acts on raw pixel inputs with keyboard and mouse controls. Best of all - it only cost $60 to train!. w/ @Shalev_lif @SirrahChan @jimmybajimmyba @SheilaMcIlraith
0
0
8
@WenhuChen My intuition is that the further away your data is from your eval format (instruction-following CoT or chat format), the more compute it takes to extract useful information from the dataset.
1
2
8
We also experiment with using APE to generate prompts that steer an LLM towards helpful/truthful answers to questions on TruthfulQA. APE finds prompts that are both truthful and informative at a higher rate than our baseline prompt. (6/7)


1
0
8
@joshm @arcinternet I suspect many of the features other than the "find" command would work well with very small 7B models like Mistral 7B (that could even be run locally at some point in the future). Maybe switching models would save a significant amount of money for you guys.
0
0
7
@jordancurve @xai For GPT-4, I referred to the score posted on the website - I didn't grade that one myself.
0
0
7
Just seeing this result for the first time this morning. crazy. I guess this shows why MineCLIP embeddings make good goal representations.

STEVE-1 surprisingly also works with visual prompts taken from real life videos, thanks to using MineCLIP's embedding! See🧵👇. Such a fun project with @Shalev_lif @keirp1 @jimmybajimmyba @SheilaMcIlraith. (Credits to @CorruptCarnage and Soil Television for the source videos)
0
0
8
@ericjang11 @shaneguML How we did it:.1) Gather a dataset of questions and correct reasoning steps by using "Let's think step by step" for all datasets in and remove incorrect answers (like in .(1/2).
1
1
7
@GanjinZero Yeah I bet 80%+ on MATH is doable this year esp with RL. The challenge to me is improving math ability in a way that generalizes much more broadly to novel questions.
2
0
7
We are excited to present "Large Language Models Are Human-Level Prompt Engineers” (APE) at the FMDM workshop (Dec 3rd) as an oral presentation (starting at 1:45pm CST) and at the ML Safety workshop (Dec 9th).
Can large language models write prompts…for themselves? Yes, at a human-level (!) if they are given the ability to experiment and see what works. with @Yongchao_Zhou_, @_AndreiMuresanu, @ziwen_h, @silviupitis, @SirrahChan, and @jimmybajimmyba .(1/7)
1
0
6
I still get emails from Veggie Grill but I can’t go since they aren’t in Canada 😞😔😟😕🙁☹️😣😖😫😩🥺😢😭.
0
0
6
Come check out my talk on GLAMOR at 11:45 PST (2:45 EST) at the Deep RL Workshop @NeurIPSConf. And say hi at the poster session (room B, poster B6) if you have any questions!.

@keirp1 is giving a talk on this paper at 2:45 pm EST today as part of the @NeurIPSConf Deep RL Workshop.
0
0
6

This is the coolest demo to me. LLMs don't just work as chatbots, they can code up the right GUI on the spot for each situation!.

Gemini’s reasoning capabilities mean it can understand more about a user’s intent, and use tools to generate bespoke user experiences that go beyond chat interfaces. Here’s what that looks like in action. ↓ #GeminiAI
0
0
6
Clever tokenization means that transformer sequence models can now dominate even driving trajectory prediction!.

"Trajeglish: Learning the Language of Driving Scenarios" w/ @xbpeng4 @FidlerSanja . Discrete sequence modeling for controlling interactive agents in self-driving simulation. @nvidia @VectorInst @UofTCompSci @SFU . 1/6
0
1
6
So our free will is basically at most one coin flip on average per word?.
2
0
5
@arankomatsuzaki A bit curious how they compared to VPT since this environment seems significantly easier than the one VPT uses (blocks break in one click).
1
0
5



Check out my new @Pebble app! It puts League of Legends esports in your timeline! http://t.co/NyfvGeiszA.
1
2
4