

Zheng Yuan
@GanjinZero
Followers
870
Following
2K
Media
30
Statuses
556
NLP Researcher. The author of RRHF, RFT and MATH-Qwen. Focus on Medical & Formal & Informal Math & Alignment in LLMs. Prev @Alibaba_Qwen, Phd at @Tsinghua_Uni
Joined August 2013
I test MATH 500 test set on GPT-4-0409-turbo. Compared to previous GPT-4-turbo. I found the chain-of-thought answer style does not change too much while the performance improves a lot (especially on the hardest LEVEL 5 problems).

18
35
306
I test gpt-4-0125 on MATH test (It does not output \\boxed, hard to parse. I test 71 problems). The accuracy is 54/71=76%, stronger than the first GPT-4 (42.5%), and it’s same as PRM rerank 1860 times of last year’s GPT-4 (78.2%). There are two features of gpt-4-0125’s output. 🧵.
4
20
109
Claude 3 and Gemini show losses improve significantly on code with extreme long context. That shows code dependent on contexts more than texts. Maybe we can see some repo level code generation this year using such long context.


4
19
100
This paper shows strong performance with selective language modeling (just mask some unuseful tokens during pretraining!)

1
14
90
ChatGLM3-6B, Qwen-72B, Skywork-13B, Yi-34B, Deepseek-coder-33B, Baichuan-200k, Lingowhale-8B. Sooo many pretrained models this week.
2
10
82
Can a small LM help in both decoding acceleration and quality? . We introduce **Speculative Contrastive Decoding**, a easy technique improves the decoding speed and quality by making the best of the distribution from a small LM. Arxiv: [1/2]

4
11
65
10^3!Got lots of citations last year. Don’t know if I can get 10^4 in my life.

12
0
51
Too many LLMs. How about using them all based on their expertise? . We introduce **Zooter**, a reward-guided query routing method. ✅ Comparable performance to reward model ranking multiple models.✅ Much fewer computation overhead. Arxiv: [1/2]

1
10
49
🔥Check our paper on Math reasoning of LLM. Augmentation math problems is useful during math SFT, and we find:. ✅Augmented data is helpful for in-domain and has similar efficiency like human written . ❌Augmented data helps little on OOD.

3
13
40
This is god damn strong.

DeepSeekMath. Pushing the Limits of Mathematical Reasoning in Open Language Models. paper page: DeepSeekMath 7B has achieved an impressive score of 51.7% on the competition-level MATH benchmark without relying on external toolkits and voting techniques,
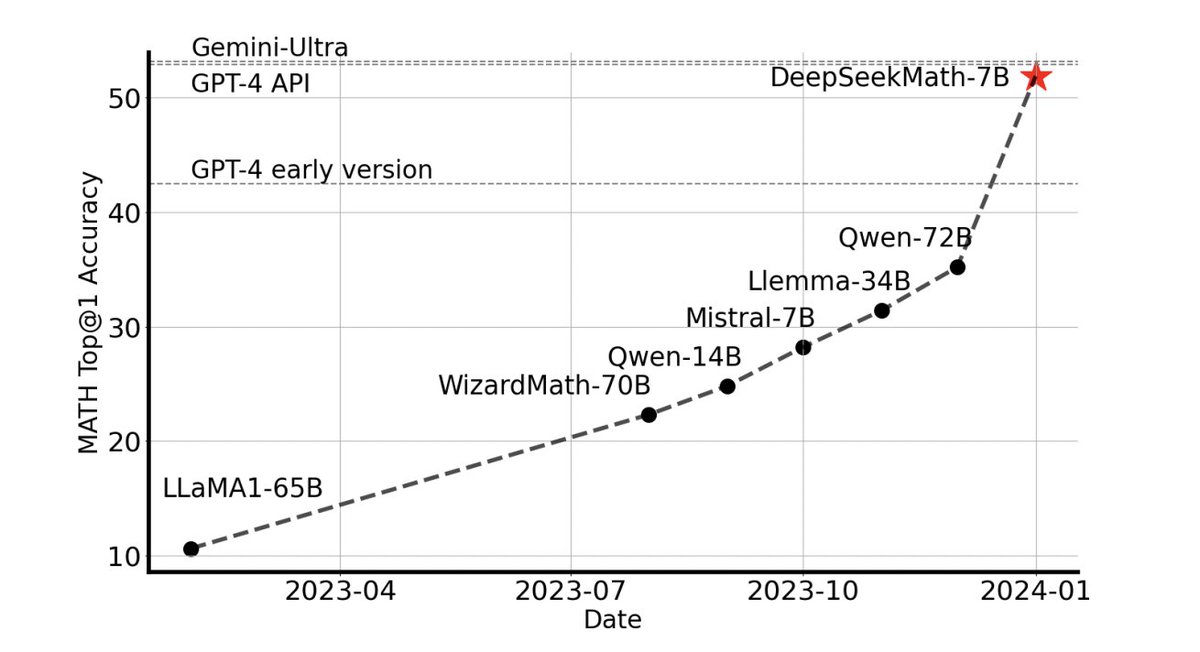
2
2
33
@_lewtun I am one of the author in Qwen, I am sure no test set leakage in math related benchmark.
6
1
25
I will be at NeurIPS 2023 in person on 12-15 Dec and have a poster about RRHF rank to align human preferences on 13 Dec poster Session 3 (. Will also attend math & instruction following workshop. Feel free to any talk!.
0
4
27
Thanks for tweeting our paper!.
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models. paper page: Mathematical reasoning is a challenging task for large language models (LLMs), while the scaling relationship of it with respect to LLM capacity is

0
1
23
The performance is much stronger than every other models. Although its name is still gpt-4. But it has evolved a lot like other open source LLMs.
2
1
25
The most interesting paper I read this year.

Genie: Generative Interactive Environments. abs: project website: This paper from Google DeepMind introduces an 11B foundation world model called Genie, trained on unlabelled Internet videos of 2d Platformer games. Genie has three

0
6
21

(2) They will try to find the misunderstanding of itself and try to fix it. This does not need a further interaction between user and GPT.

1
1
19
Scaling is all u need! Very similar to our observation in previous math sft scaling law and
Common 7B Language Models Already Possess Strong Math Capabilities. Mathematical capabilities were previously believed to emerge in common language models only at a very large scale or require extensive math-related pre-training. This paper shows that the LLaMA-2 7B model

1
2
17
I built the math related parts in Qwen. Trying to approach Minerva!.

Qwen-14B (Alibaba). The most powerful open-source model for it's size. And the longest trained: 3T tokens. Comes in 5 different versions:.Base, Chat, Code, Math and Vision. (And is even trained for tool usage!). Opinion: You should consider it as your new "go-to". ---.Paper:

0
0
14
Glad to be accepted by ICLR. Great job. @KemingLu612 @yiguyuan20.
📢 Check out our latest paper - 🏷️#INSTAG: INSTRUCTION TAGGING FOR ANALYZING SUPERVISED FINE-TUNING OF LARGE LANGUAGE MODELS! . 🔍 We propose 🏷️#INSTAG, an open-set fine-grained tagger for analyzing SFT dataset. 🔖 We obtain 6.6K tags to describe comprehensive user queries.

1
1
13
(1) They will list a step-by-step plan and calculate it step-by-step.

1
0
12
If we can improve gsm8k from 30-80 on 7B last year, maybe we can also improve math from 50-80 this year.
This is god damn strong.
2
1
10

Yesterday I also saw a math reasoning paper work on iteratively generate new data for boosting. I believe using reward model ability inside the self model is a scalable way for improvement.

🚨New paper!🚨.Self-Rewarding LMs.- LM itself provides its own rewards on own generations via LLM-as-a-Judge during Iterative DPO.- Reward modeling ability improves during training rather than staying fixed. opens the door to superhuman feedback?.🧵(1/5)

1
1
7
Find this guy @KemingLu612 at nips instruction following workshop who do a lot on QWen alignment, instag(, and zooter(.


0
0
8
This is the real thing AI should do.

From accelerating drug discovery to enabling personalized medicine, global healthcare organizations are turning to Claude for solutions to some of their biggest challenges.

0
0
8
not-clever-than-me

It seems like OpenAI might actually be testing two models!. "im-a-good-gpt2-chatbot". "im-also-a-good-gpt2-chatbot"
0
1
6
@yuntiandeng @KpprasaA @rolandalong @paul_smolensky @vishrav @pmphlt Our paper show the scaling law of augmented dataset amount vs performance on gsm8k.
1
1
6
Congratulate @kakakbibibi another work from us to investigate SFT data. We investigate data scaling curve for code, math, general abilities and how data composition influences each. We propose a dual-stage SFT to maintain math and code ability and have good general ability.

👏👏Excited to share our paper:. 🧐How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition. 📎 🤩From a scaling view, we focus on the data composition between mathematics, coding, and general abilities in SFT stage.

1
3
6
Too many LLMs. How about using them all based on their expertise? . We introduce **Zooter**, a reward-guided query routing method. ✅ Comparable performance to reward model ranking multiple models.✅ Much fewer computation overhead. Arxiv: [1/2]
0
1
6
📈 We use tags to define complexity and diversity and we find that the complex and diverse SFT dataset leads to better performance! .🎯 We use #INSTAG as a data selector to choose 6K samples for SFT. Our fine-tuned TagLM-13B outperforms Vicuna-13B on MT-Bench.

1
1
5
LLMs seem just do imitation on cot instead of real thinking.

Some initial insights and I might be wrong. Obviously, LLMs are learning math in a different way than human beings. Humans tend to learn from textbooks and generalize better than LLMs. It seems to me that LLMs do need way more training data to actually understand math.
0
0
5
Zooter is a little encoder transformer which routes a query to an expert LLM. 🧪 We select six 13B models as candidates and experiment on different tasks. 👍 Zooter outperforms the best single model on average and ranks first on 44% of tasks, even surpassing RM ranking. [2/2]

0
0
5
Really love this work!.

🔥Excited to share our latest work: .Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations. With Math-Shepherd, Mistral-7B fine-tuned on MetaMATH achieves accuracy rates of 89.1% and 43.5% on GSM8K and MATH, respectively. Paper:
1
0
5
It includes gsm8k rft as additional training dataset 🤗.

Introducing: StarCoder2 and The Stack v2 ⭐️. StarCoder2 is trained with a 16k token context and repo-level information for 4T+ tokens. All built on The Stack v2 - the largest code dataset with 900B+ tokens. All code, data and models are fully open!.

0
0
5
VLLM will generate new tokens for LLM pretraining.

Finally, the top 1 vision feature is transcribing the text in image into text. -- you know that there are so many high-quality textbooks that are not yet digitalized, many of the are simply a scan. So you guess where the data for training the next generation model will be

0
1
5
Thank you tweeting our zooter! Zooter distills supervisions from reward models for query routing and inferences with little computational overhead.
Routing to the Expert: Efficient Reward-guided Ensemble of Large Language Models. paper page: The complementary potential of Large Language Models (LLM) assumes off-the-shelf LLMs have heterogeneous expertise in a wide range of domains and tasks so that

0
1
4
Through our experiment, we find that the acceleration comes from decoding the “easy” tokens while the quality benefits from the contrastive elimination of systematic erroneous tendencies in “hard” tokens. [2/2]

0
0
4
The reason is trivial: the distribution of MATH query is very different from GSM8K and augmented GSM8K. This tells us we can augment **every** benchmark to improve all downstream performances or pre-train a better model since augment a benchmark may not help another one.

0
0
4
🔗 Check out our models and codes here: 🔗 Try our online tagger here:
2
0
4
Handsome.

@jeremyphoward @rasbt @Tim_Dettmers @sourab_m Now @KemingLu612 is telling us how Qwen was built the winning A100 base model

0
1
4


Cite bunch of our paper ^_^.

Data Management For LLMs. Provides an overview of current research in data management within both the pretraining and supervised fine-tuning stages of LLMs. It covers different aspects of data management strategy design: data quantity, data quality, domain/task composition, and

0
0
4
Math is a good domain for researching how synthetic data can be used for LLM.

Would an AI that can win gold in the International Math Olympiad be capable of automating most jobs?. I say yes. @3blue1brown says no. Full episode out tomorrow:. "Math lends itself to synthetic data in the ways that a lot of other domains don't. You could have it produce a lot
0
2
4
So happy to find math reasoning SFT improves so fast.

The potential of SFT is still not fully unlocked!!!!! Without using tools, without continue pre-training on math corpus, without RLHF, ONLY SFT, we achieve SOTA across opensource LLMs (no use external tool) on the GSM8k (83.62) and MATH (28.26) datasets:

0
0
3
Now we have Arxiv version with a bibtex lol.
Qwen Technical Report. paper page: Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce Qwen,

0
0
4
Let’s see how strong the math can be.

1. Vision + function calling.2. Dec 2023 cutoff.3. *Huge* improvements across the board in our evals (particularly in math!).
0
0
3
respect!.

0
0
3
@StringChaos @WenhuChen Totally agree. I think the most effective tokens are SFT tokens and the less are pretrain tokens in scaling parameters. It is very interest to know how syn/rl tokens scaling parameters. Very interested to know why formal domains easier?.
2
0
3
@keirp1 Their math shepherd paper is a very good start point of building prm. I very like that paper.
0
0
3
@doomslide @iammaestro04 @teortaxesTex @QuintinPope5 Translation is so hard but worth taking effort. LEAN and natural language are reasoning in different granularity. So many obvious things need to be proved by LEAN tactics.
1
0
3
With scaling law predictions.

@generatorman_ai Better data engineering.Scrapping textbooks.Codex as a distinct target.More serious attitude to getting to a commercially viable product.Not even a moment's hesitation about it being more than experiment.
0
0
3
RRHF accepted by @NeurIPSConf.
We just released the weights of our RRHF-trained Wombat-7B and Wombat-7B-GPT4 on Github and Huggingface.
0
0
2
While we find such augmentation, have little help for MATH dataset.

1
0
3
respect.

Announcing C4AI Command R+ open weights, a state-of-the-art 104B LLM with RAG, tooling and multilingual in 10 languages. This release builds on our 35B and is a part of our commitment to make AI breakthroughs accessible to the research community. 🎉.

0
0
3
beast.

Blackwell, the new beast in town. > DGX Grace-Blackwell GB200: exceeding 1 Exaflop compute in a single rack. > Put numbers in perspective: the first DGX that Jensen delivered to OpenAI was 0.17 Petaflops. > GPT-4-1.8T parameters can finish training in 90 days on 2000 Blackwells.



0
0
3
Want see someone successful using PPO (with a reward model) to improve math reasoning.
I got a crazy theory about RLHF that I would like to debate about. No nice way to put it:.I am not sure RLHF was used for training GPT-3.5 and GPT-4. Please change my mind. Arguments:. -----.Supervised learning can go much farther than anyone thought it could. RLHF was never.
1
0
1
@KemingLu612 @yiguyuan20 Another problem is long data means long responses means better alignment performance.
0
0
2
Start reading….

ICLR submissions are online: Looks like there's:.- ~700 with diffusion in it, .- less than 100 with nerf,.- ~900 LLM.- ~100 chatgpt (8 bard, 16 claude) .- vs ~170 llama (yay).- ~200 clip (but not "clipping").- ~200 NLP.- ~750 vision(!?)

0
0
2
umm.

FYI the new code diffusion model paper by some people at Microsoft claims ChatGPT-3.5-turbo is 20B params.

2
0
2
@rosstaylor90 If people are comparing aligned models, I think it is fair to use expert iteration.
1
0
2
0
0
2
@sytelus @Francis_YAO_ @_akhaliq 1. r_ij means j selected paths after rejecting with k=100, usually it has like 5 paths. 2. Exactly.
0
0
2
Looks like pipimi


i see the chat volume is down this evening . wishing you all a Happy Valentine's Day 😊

0
0
2
looks like diffusion decoding.

0
0
2
0
0
2
We obtain new open-source SOTA on GSM8K by evolving queries from GSM8K which makes LLaMA2-7B obtains 68.4 accuracy.

1
0
2
@polynoamial @OpenAI My plan for improving MATH is iteratively improve policy model and reward model by RL.
0
0
1
This problem also appears in the test set of MATH benchmark. It’s time for LLMs to solve this problem now.

When I was in middle school I qualified for Nationals at MathCounts. and I remember distinctly watching @ScottWu46 (CEO of Cognition), absolutely destroy in the Countdown round. That was when I realized I was very very good at math, but I was not Scott
0
0
1