
Silviu Pitis
@silviupitis
Followers
2,326
Following
737
Media
14
Statuses
93
ML PhD student at @UofT / @VectorInst working on normative AI alignment.
Toronto, ON, Canada
Joined April 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#TrappingxLingOrm
• 127372 Tweets
闇バイト
• 124060 Tweets
LINGORM WRITTEN IN THE STAR
• 114605 Tweets
Lamar
• 104127 Tweets
Ravens
• 88265 Tweets
Evans
• 62008 Tweets
Baker
• 57396 Tweets
#IRIAMメンテ中のフォロー祭り
• 47909 Tweets
#Magpasikat2024OgieKimMCLassy
• 40329 Tweets
Chargers
• 35300 Tweets
TEAM McKOL MAGPASIKAT2024
• 31177 Tweets
Bucs
• 28427 Tweets
Godwin
• 28342 Tweets
Francella
• 24306 Tweets
CULLEN FOREVER 18
• 23477 Tweets
ONCE IN A BLUE MOON SONYA
• 23007 Tweets
Cardinals
• 21891 Tweets
Derrick Henry
• 19002 Tweets
ABSENCE MEW SINGLE
• 14544 Tweets
Herbert
• 14518 Tweets
Brandoni
• 14012 Tweets
Jackson 5
• 13201 Tweets
スヤスヤ教
• 13110 Tweets
केंद्रीय गृह
• 11909 Tweets
#ファミマ史上最強の背徳まん
• 11792 Tweets
#HBDayAmitShah
• 11003 Tweets





















Can RL agents generalize to new tasks w/ unseen states?
Our
#NeurIPS2022
paper Model-based Counterfactual Data Augmentation (MoCoDA) augments an agent’s training data w/ new object combos, enabling zero-shot transfer to OOD tasks.
w/
@elliot_creager
@AjayMandlekar
@animesh_garg
1
5
42
Have 2 posters @ The Many Facets of Preference Based Learning workshop today at
#ICML2023
. Please stop by if interested in reward modeling!
1. Multi-Objective Agency Requires Non-Markovian Rewards
TLDR: shows non-Markovian rewards are necessary for agents whose multiple
1
10
39
At
#ICML
through next Monday.
Looking forward to meeting people! Reach out if you'd like to chat AI alignment/governance, reward/value learning, or other stuff LLMs/RL/AGI.
1
1
21
Our paper on Counterfactual Data Augmentation (CoDA) received an outstanding paper award at the Object Oriented Learning workshop
#OOL2020
#ICML2020
! Oral to be streamed *tomorrow* alongside some other exciting work @
w/ Elliot Creager,
@animesh_garg
1
2
20
Some great takes in here. I particularly appreciated the discussions re:
- p(doom) is silly
- alignment is accelerationist
- x-risk positioning on account of power/self-interest


"Notes on Existential Risk from Artificial Superintelligence":
32
70
388
0
3
18
Also, my coauthors will be presenting our work " Calibrating Language Models via Augmented Prompt Ensembles" at the Challenges in Deployable Generative AI workshop today ().
TLDR: We find we can improve LLM calibration (beyond temperature finetuning), in

0
1
15
@SirrahChan
& I are excited to share our
#ICML2020
work "Maximum Entropy Gain Exploration for Long Horizon Multi-goal RL"!
paper:
code:
icml link:
w/ Stephen Zhao, Bradly Stadie, Jimmy Ba

1
1
11
If your experiments use GPT for evaluation (e.g., ), be aware that it sometimes exhibits bias toward one of the options (e.g., option C for multiple choice or option A for A/B choice). To obtain a fair evaluation, randomize the order of the choices.
0
1
7
If you want to learn more, check out the MoCODA paper on arXiv: or see our google site:
…and for those attending
#NeurIPS
2022, we hope to see you at Poster Session 5 on Thursday, December 1.
8/8

0
0
4
With our new Q(s,a) we sample augmented transitions from Q(s,a)P(s’|s,a). Leveraging causal knowledge to augment the training data in this way allows RL agents, even strictly offline RL agents, to generalize to these unseen areas of the state space and solve OOD tasks.

1
1
3
@mengyer
Probably some permutation of: A meta learning algorithm is any algorithm that uses a learning procedure during inference, which learning procedure was fitted/adapted based on similar task instances. “Learning to learn” is too vague.
0
0
3
Key idea:
Form Q(s,a) such that parents of every causal mechanism are in-distribution, even if the entire (s,a) is out-of-distribution. A natural choice for Q(s,a) is the maximum entropy, marginal-matching distribution, as shown below.

1
1
2
Summary thread by Animesh:
Paper:
Code:
Workshop virtual site w/ stream:
Many thanks to the OOL organizers for putting together what promises to be a great workshop!

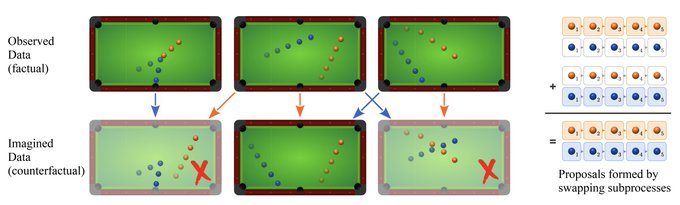
Many dynamic processes, including many in robotics & RL, involve a set of interacting subprocesses, which can be decomposed into locally independent causal mechanisms.
Solution: Counterfactual Data Augmentation (CoDA)
Paper:
w\
@SilviuPitis
E. Creager

1
10
59
0
0
3
Our code release is highly modular/extensible and provides state-of-the-art implementations of MEGA, HER, and common off-policy algorithms for continuous control. Check it out at: .

1
0
2
Poster sessions with
#SirrahChan
& I are Thursday at 9am & 8pm Eastern (6am & 5pm Pacific). Stop by for a chat if you're interested in: goal conditioned RL, sparse rewards and the long-horizon problem, or intrinsic goal setting and multi-goal empowerment!
1
0
2
If there is sufficient experience in underrepresented regions of the expanded support, we can even reweight Q(s,a) toward a uniform or task-prioritized distribution.
Using augmented Q(s,a) differs significantly from standard model-based rollouts (eg Dyna), which start in P(s,a).

1
0
2
@NPCollapse
@egrefen
Can you "solve" safety? It seems like a continual learning problem that isn't separable from increasingly autonomous agents.
Given that others are also on route to autonomous agents, I'm not sure the effect another team working on this has on x-risk. Could it be net beneficial?
0
0
2
We introduced LCMs in our prior work CoDA (NeurIPS '20 ), where augmented data was stitched together from subsamples of real data.
In MoCoDA, we train LCM-based generative models on the real data instead. We can now augment data even when objects interact!

2
0
2
MoCoDA combines a model of past experience with causal knowledge to produce useful OOD samples.
Factorizing the transition dynamics, P(s,a,s’) =P(s,a)P(s’| s,a), we create augmented Q(s,a) with support expanded to new (s,a) where causal knowledge suggests P(s’|s,a) generalizes

1
0
2

Our MEGA and OMEGA agents set achievable goals in sparsely explored areas of the goal space to maximize the entropy of the historical achieved goal distribution. This lets them learn to navigate mazes and manipulate blocks with a fraction of the samples used by prior approaches.
1
0
1
@ESYudkowsky
> There are few or no good uses for AI outputs that require a human to be deceived into believing the AI's output came from a human.
You are assuming that if a human doesn't know whether an output is AI or human generated, that human is "deceived" into believe it is human
0
0
0
@nospotfer
@ml_collective
@JeffDean
why scoff at someone doing something nice? my neurips paper was done on a single 1080ti. these gpus can get a lot done. local development is fast.
1
0
1
@AndrewCritchCA
What if my own outputs are AI modified? How does one enforce a "label" for AI outputs? How weird would it be if generative images or generated text all had an awkward label on them?
Wouldn't some more nuanced protections, based on existing fraud laws, and motivated by similar
0
0
1
0
0
1
@rajammanabrolu
Not that I necessarily disagree in this instance, but how exactly do they think the human learned to give feedback in the first place??
Knowledge can be created through reasoning.
0
0
1
But how do we know which OOD samples are useful?
By making use of a local causal model (LCM), which divides state/action space into local subspaces, each with their own dynamics. Crucially, this tells us which (s,a) will generalize well under the learned P(s’|s,a).

1
0
1