

Shalev Lifshitz
@Shalev_lif
Followers
1K
Following
1K
Media
66
Statuses
1K
a non-artificial intelligence working on scaling artificial reasoning
Toronto
Joined September 2017
As we learn to use compute more efficiently, we will use more compute.
1
2
5

A new replication of DeepSeek's RL results! Here are my notes and some quick thoughts:. Method:.- Uses PPO instead of GRPO (DeepSeek-R1), still works.- Data is 8K (query, final answer) examples from MATH.- Rule-based reward modelling (no neural reward).- Initialize model to


We replicated the DeepSeek-R1-Zero and DeepSeek-R1 training on 7B model with only 8K examples, the results are surprisingly strong. 🚀 Starting from Qwen2.5-Math-7B (base model), we perform RL on it directly. No SFT, no reward model, just 8K MATH examples for verification, the

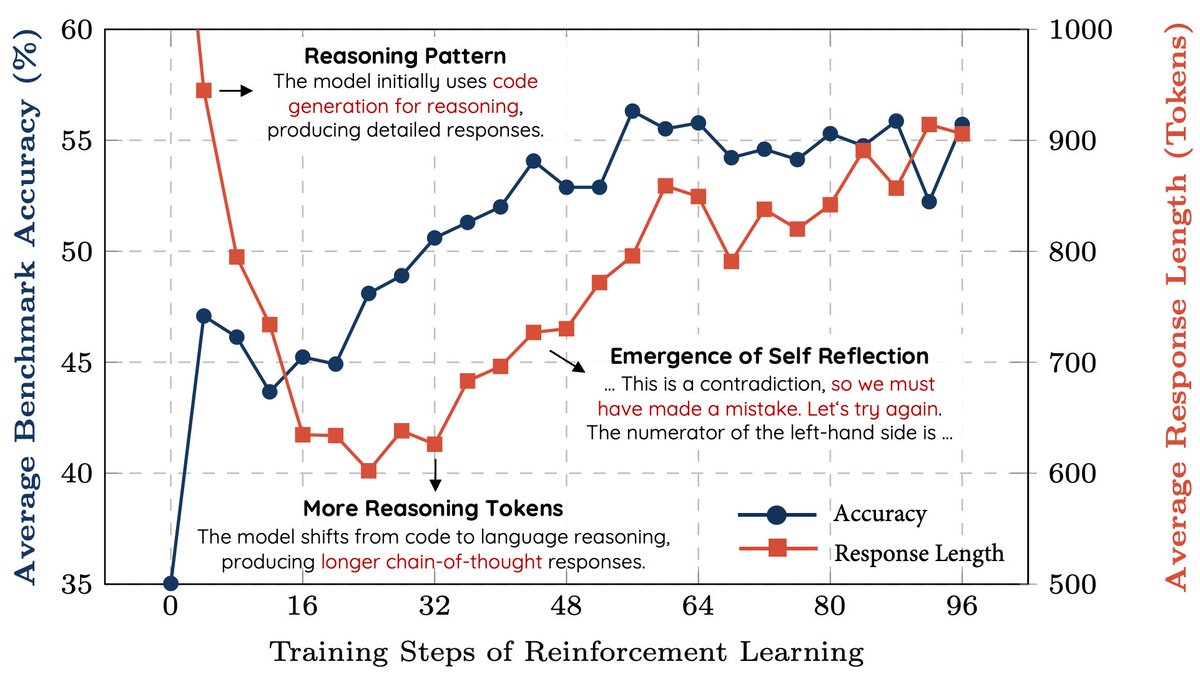
7
50
357
Great to see @geoffreyhinton at the @VectorInst office today. Here @michaelrzhang is presenting his work on qualitative eval of LLMs!. Very cool to have a Nobel Laureate + Turing Award winner around the campus.

4
14
330
My question to @ilyasut at NeurIPS 2024: Do LLMs generalize multi-hop reasoning out-of-distribution?
7
18
293
Absolutely stacked panel at the System-2 Reasoning at Scale workshop at NeurIPS with Josh Tenenbaum, @MelMitchell1, @fchollet, @jaseweston, @DBahdanau, @dawnsongtweets, and. @Yoshua_Bengio (with @nouhadziri moderating). An amazing end to the conference. Will add notes below.

11
24
241
@karpathy This reminds me of a meme @_jasonwei posted a while back! That is, once you play with these models so much you kind of develop your own mini test suite to gain intuition of its performance.

3
9
198
@ilyasut giving a talk at the NeurIPS 2024 Test of Time awards! . Will add more photos below, throughout the talk.

1
7
106
In a few years PhDs won’t be coding much. They’ll have a fleet of agents coding up, running, and tuning their experiments. At that time, the most valuable skill will be deep expertise, as suggested by @RogerGrosse.

@tunguz In all seriousness, PhDs today will have tools so powerful that previous generations won’t know what to think of them. I think it is the most exciting time to be working. Just don’t work in an old way.
8
4
102
🥳 Great news! Our paper STEVE-1 has been accepted at #NeurIPS 2023 as a spotlight!. I'm so proud to have worked on this project with my amazing collaborators @keirp1 @SirrahChan @jimmybajimmyba @SheilaMcIlraith. ✈️ Very excited to present our work in New Orleans! ✈️. Project
7
6
97
The reason I initially got into RL is because the problem setting just seems much more like what AGI would be based on: optimizing for a goal, without basing on human-provided answers. Glad to see RL is making a comeback.

2022: I never wrote a RL paper or worked with a RL researcher. I didn’t think RL was crucial for AGI. Now: I think about RL every day. My code is optimized for RL. The data I create is designed just for RL. I even view life through the lens of RL. Crazy how quickly life changes.
4
1
89
@jxmnop The ‘fast’ operations area of the GPU has lower memory. I recommend reading the first few pages of the Flash Attention paper, it goes into this and explains it super well!.
1
2
77
Genie 2: open-ended *playable* world modelling. Amazing work from the team @GoogleDeepMind! They even show the generalist SIMA agent playing inside of Genie 2. We’re one step closer to the near-infinite training data regime for embodied agents. This is big!.

Introducing 🧞Genie 2 🧞 - our most capable large-scale foundation world model, which can generate a diverse array of consistent worlds, playable for up to a minute. We believe Genie 2 could unlock the next wave of capabilities for embodied agents 🧠.
0
7
39
@xuanalogue One good thing about o1/3 from a safety perspective is that the long CoTs are at least in natural language. If we make the models small enough so that they can’t do much multi-hop reasoning implicitly, this may be helpful from a safety sense.
5
0
33
@DrJimFan Agreed about the GPT-3 comparison, we need to be thinking about a few papers down the line. And regarding world models: I’m still on the fence for LLMs but with video-gen it seems much more clear. Though good science is still needed. @yudapearl had a great question about this a.
1
3
25
It’s crazy watching mainstream media try to explain the DeepSeek results. I just watched CNBC compare the cost of a single training run for DeepSeek-V3 ($5.6M) to OpenAI’s total spend in a given year ($5.4B). Come on… seriously?.
5
2
87
We are in a period of time where there is too little diversity in research, almost everyone is toying around with the same architectures and ideas. We need much more diversity, and academia is much better at this than industry (the freedom to explore much more broadly).
2
4
26
1
2
25
Happy you found our work interesting @_akhaliq, it was great chatting about the impact and future directions of STEVE-1 at ICML today!.

STEVE-1: A Generative Model for Text-to-Behavior in Minecraft. paper page: Constructing AI models that respond to text instructions is challenging, especially for sequential decision-making tasks. This work introduces an instruction-tuned Video
1
6
24
@denny_zhou Agree about RL democratizing reasoning. But I feel that it's not quite RLHF, and just "RL with good SFT warmup", since we're using even less human feedback now (no neural reward model).
3
0
22
Very fortunate to have a talk from Ilya at NeurIPS this year. He sees what others cannot.
0
0
22
I'm in awe at the fact that "openai", "gemini", and "claude" are all the same length. Thank you Deep Learning god for keeping my code aligned and beautiful. 🥹🙏. P.S. Yes, 'gemini' and 'claude' should really be 'gdm' and 'anthropic' or something, but. oh well.

1
0
21
@rm_rafailov I think it is likely to have curated data and synthetic data in pre/mid-training, but I still find it quite impressive that such simple RL works on top. That being said, it does seem the general community on Twitter is starting to think that you only need RL and pre-training on.
1
2
20
@pcastr What about this line of work? (This particular paper is a great one by @akyurekekin).
0
3
18
@karpathy Great work from Google. In a few years, you’ll have AI-generated lessons that can be either listened to or interacted with - and personalized per student. I also wonder what post-podcast interfaces AI might unlock….
1
1
18
It’s hard to overstate the significance of the ‘AI scientist’ line of work to the development of general intelligence. The frontier labs have closed teams working on automating AI research, but this is one of the first major *open* steps in the same direction.

Introducing The AI Scientist: The world’s first AI system for automating scientific research and open-ended discovery!. From ideation, writing code, running experiments and summarizing results, to writing entire papers and conducting peer-review, The AI




2
0
15
Thought I entered the matrix today at the @GoogleDeepMind booth when I saw 100 people all wearing headphones and looking at a screen.

2
0
17
STEVE-1 follows text and visual goals in Minecraft while using only raw pixels and keyboard/mouse controls! Very excited to finally share this work!. w/ @keirp1, @SirrahChan, @jimmybajimmyba, @SheilaMcIlraith.

Meet STEVE-1, an instructable generative model for Minecraft. STEVE-1 follows both text and visual instructions and acts on raw pixel inputs with keyboard and mouse controls. Best of all - it only cost $60 to train!. w/ @Shalev_lif @SirrahChan @jimmybajimmyba @SheilaMcIlraith
1
7
14
@jparkerholder Really amazing work! We can finally combine open-ended agents and open-ended world models. We’re getting closer to the near-infinite training data regime.
0
2
16
Superintelligence is next, the long term:.- agentic (current models are barely agentic).- reasoning. seeing some early signs, unpredictable, chess AIs are unpredictable to best human chess players. We’ll have to deal with LLMs that are unpredictable. - self-awareness.
0
2
14
@johnschulman2 Seems like this comes from the long CoT SFT warmup that happens before RL (including the synthetic reasoning data that is a part of pre/mid-training). Unless there's something about these words or the way they are used in natural text that causes them to emerge through pure RL,.
1
0
14
I loved this quote from @cong_ml (co-first-author of The AI Scientist) in today’s AI papers of the week space hosted by @iScienceLuvr and @arankomatsuzaki: . “This is the ‘Will Smith eating spaghetti’ moment of AI science. This is the worst it will ever be.”. Well said @cong_ml,
1
0
12
@DrJimFan It’s being used as a no-op (or one-op) in the current demonstrations, but it can also be used as an action taking agent, and I have to assume they are testing this internally. Formula to convert Sora to an action-taking agent: Condition on past frames from an embodied agent’s.
4
2
12

Hominids have a different slope (ie, scaling law) between body mass and brain mass (note, axes are log scale!), compared to other animals. An example from nature

1
0
12
@RogerGrosse Thanks for sharing, fascinating read. Truly ahead of his time. Great quote from the paper: "It is sometimes worthwhile to take science fiction seriously.".
0
0
11
Looking forward to the future of post-training at Anthropic now that John has joined the team!.

I shared the following note with my OpenAI colleagues today:. I've made the difficult decision to leave OpenAI. This choice stems from my desire to deepen my focus on AI alignment, and to start a new chapter of my career where I can return to hands-on technical work. I've decided.
0
1
11
Its been way too long since I saw my two-legged thumb friends and 4-armed spider friends. Brings me back.

🚨 New reinforcement learning algorithms 🚨. Excited to announce MaxInfoRL, a class of model-free RL algorithms that solves complex continuous control tasks (including vision-based!) by steering exploration towards informative transitions. Details in the thread 👇
0
1
11
Why do similar words like "wait" and "alternatively" appear in both o1 and r1 CoTs?. I think either:.1. The pre-RL SFT data is coming from similar sources. 2. Different sources are generating similar pre-RL SFT data (for example, maybe the deepseek team saw the few published o1.
There are some intriguing similarities between the r1 chains of thought and the o1-preview CoTs shared in papers and blog posts (eg . In particular, note the heavy use of the words "wait" and "alternatively" as a transition words for error correction and.
5
0
11
Remember when 5-6 years were bullish timelines?.

Yann LeCun says AGI will not happen in the next 2 years - it will take 5-6 years if everything goes well because the history of AI shows that people keep underestimating how hard it is
0
0
11
Excited to be in Hawaii this week to present our recent work STEVE-1 at ICML 2023! STEVE-1 is an instructable agent that can accept any text instruction and act using raw keyboard/mouse controls. By treating policy learning as a generative task, we show that it’s possible to

2
0
11
100% recall for needle-in-a-haystack retrieval over 11 HOURS of audio? This just gets better and better….

Audio haystack. For audio, Gemini 1.5 Pro achieves 100% recall when looking for different audio needles hidden in ~11 hours of audio.

0
0
10
This is such an important point and a huge question mark. How many jobs can be automated with a 1% error rate? If AGI = automating most economically valuable work, the this question is imperative.

@Shalev_lif There are not many problems where a 1% error rate will be acceptable. Problems that have that property (for example reading long docs where compliance rates are already low) will crack.
4
1
9
@fchollet @polynoamial Search as an idea is fully general, but most implementations are specialized. The interesting thing about o1 is that it discovers truly general search techniques (ie, backtracking) via train-time RL. @polynoamial mentioned this recently.
1
1
8
0
0
7
Wow! Congratulations to @HopfieldJohn and @geoffreyhinton who have just been awarded the Nobel Prize in Physics for their foundational work re: neural networks!. @geoffreyhinton now holds both an ACM Turing Award *and* a Nobel Prize in Physics. What an amazing achievement! I.

BREAKING NEWS.The Royal Swedish Academy of Sciences has decided to award the 2024 #NobelPrize in Physics to John J. Hopfield and Geoffrey E. Hinton “for foundational discoveries and inventions that enable machine learning with artificial neural networks.”

5
0
7
The trend these days is doing more inference during training and more training during inference.
1
0
8
Ironically this probably gives the work even more attention. New strategy unlocked?.


1
0
7
AGI itself is a flawed term that we should move away from. More concrete notions like “automating x% of remote workers”, “saving x-type workers y hours each week”, “increasing productivity by x%”, and other economically driven definitions are much more meaningful and useful. AGI.

o1 is "better than most humans at most tasks" because, yes, humans exist exclusively in amnesic disembodied multi-turn chat interfaces.
1
0
7
Exciting advancement by Google DeepMind with the newly introduced Robotic Transformer 2 (RT-2)!. Main idea: train a single agent on 1) web-scale text/image data and 2) robot data, to create a single Vision-Language-Action (VLA) model. This VLA model can directly output actions to

0
1
6
As you scale things up, tiny hacks matter less, what matters more is matrix multiplication and ReLU.
1
0
7
At the announcement of the 2024 Nobel Prize in Physics this morning, @geoffreyhinton was asked about the future impact of AI on our civilizations. Here's what he said:. "I think it will have a huge influence. It'll be comparable with the industrial revolution, but instead of.
1
1
7
Abstraction is difficult to see inside an LLM, but neural nets can speak out about their abstractions.
1
0
7
@nathanbenaich @twentybn @muellerfreitag Yup, it's timing but also now the tech is really getting there and making it possible. Really excited for the future of Fei-Fei's company, she's awesome!.
0
0
7
@elonmusk It’s been interesting to see the distribution of opinions on 1047 among researchers. For those unaware: lots of AI researchers are in favour of regulation, but there’s been criticism that 1047 hurts open-source too much (though a recent change in 1047 tries to address this).
1
1
7
@AnthropicAI @github Nice! Claude has been my go-to coding assistant (other than copilot). Happy to finally be able to use it with copilot. Thanks for the hard work!.
0
0
7
0
0
7
Future benchmarks may need to have a compute price, to account for the efficiency of inference-time algorithms.
0
0
7
@DrJimFan Ah oops, I misinterpreted that too. Thanks for the clarification! Still extremely impressive and hopefully we get this level of truly autonomous capability in 2024.
0
0
1
@Deepneuron *If* we think AI will eventually be able to do almost all economically valuable work, this I guess we need an economy-scale data centre to power it!.
0
0
6
The relief when your method successfully transfers to a new benchmark.

0
0
6
@gadgetKarens @EugeneVinitsky Hahaha this made me laugh. @EugeneVinitsky seems like you have an AI friend.
0
0
6
@inductionheads @rm_rafailov It's more that the important moves must have a high-enough probability as to be sampled enough to be reinforced during RL. In other words, the good moves need to be common enough so that they happen during training.
0
0
6
Extra important question:.Does Qwen-2.5-Math-Base have synthetic reasoning / long CoT data in pre/mid-training ? If so, should we still call the Zero model a “cold start”? This is all very new so the community still has to figure out these details. But this is an important.
Assuming a base model was trained with synthetic long reasoning during pre/mid-training, and then RL is applied, is it right to view this as RL with no SFT?. In other words, is this a cold start?.
1
0
6
The general consensus among top folks has been that math will be solved first, then code. Seems right. We'll get ASI in math and code before we get AGI for everything else.
1
0
6
Interesting theory paper on hallucinations. "By establishing the mathematical certainty of hallucinations, we challenge the prevailing notion that they can be fully mitigated.". [2409.05746] LLMs Will Always Hallucinate, and We Need to Live With This (.
0
0
6
Current AIs aren't curious! They seldom ask questions to learn more. Why is it important for AI to ask questions?. For one, it can help prevent hallucinations: ie, by asking follow-up questions instead of generating responses with high uncertainty. But more importantly: how do

2
0
6
A major issue with current LLMs is that they often don’t ask questions when they are unsure about something, whether that be facts, user intent, etc. We must train these systems to ask questions, not just answer them.
1
0
5
@DrJimFan Agreed. We can’t just train a domain-specific IDM on every domain. We’re moving down the hierarchy of core pieces needed for generalist embodied agents:.— Semantic understanding and high level planning with text actions: a general VLM. — Low level dynamic planning: a general.
0
1
4
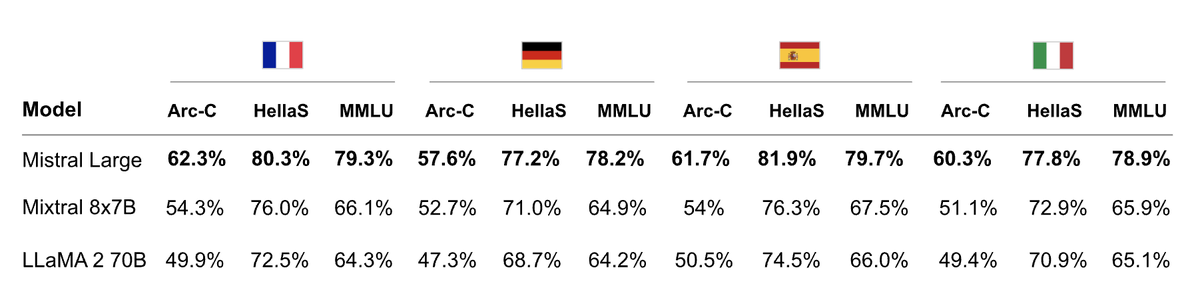
Huge developments, especially with the chat interface for everyday users. Mistral is shaping up to be a major competitor!.

Today, we are releasing Mistral Large, our latest model. Mistral Large is vastly superior to Mistral Medium, handles 32k tokens of context, and is natively fluent in English, French, Spanish, German, and Italian. We have also updated Mistral Small on our API to a model that is

0
0
5
Very excited to have Zhijing join @UofTCompSci and @VectorInst!.

Happy to announce that I'm joining as an Asst. Prof. in CS at UToronto @UofTCompSci+@VectorInst in Fall '25, working on #NLProc, Causality, and AI Safety! I want to sincerely thank my dear mentors, friends, collabs & many who mean a lot to me. Welcome #PhDs/Research MSc to apply!.
1
0
5
2024 is going to be exciting.

Introducing Eagle-7B. Based on the RWKV-v5 architecture, bringing into opensource space, the strongest.- multi-lingual model . (beating even mistral).- attention-free transformer today . (10-100x+ lower inference). With comparable English performance with the best 1T 7B models

1
1
5
We are going to have “superintelligent” AI that can make scientific breakthroughs in certain domains (ie, math) before we have “AGI” in all domains.
0
0
5
Ilya’s new company just raised $1B. I’m excited. It’s hard to overstate Ilya’s brilliance.

SSI is building a straight shot to safe superintelligence. We’ve raised $1B from NFDG, a16z, Sequoia, DST Global, and SV Angel. We’re hiring:
0
0
5
@DrJimFan We’ve exhausted a lot of the text on the internet at this point, so the 10s if not 100s of TRILLIONS of tokens on YouTube are key for future LLM/VLM training. And merging with something like Sora (maybe directly, maybe through a dynamic prompting layer) is a key next step.
1
1
5
@OpenAI should make it possible to upload .py files to o1! GPT-4o accepts .py files, but o1 doesn't. Why?

1
0
5
@DrJimFan Very exciting times indeed. 2023 was an AI culture shock. As the dust settles, 2024 will reveal the practical path towards truly generalist agents.
0
0
4
@DrJimFan Yup, and I've been hearing that some companies are training code models on commit histories and their changes. Will usher a new way to code for sure.
0
0
5
This is me leading up to conference deadlines. I get out of bed, into my chair, and keep coding where I left off, trying to solve some problem I couldn’t figure out before I went to sleep. Not very sustainable though 😅 (turns out breakfast is important).


1
0
5
@arankomatsuzaki Personalized AI that knows your paper preferences, what your working on, is a semi expert in your field, and can even suggest ideas related to the papers and your current research. It’s coming….
1
0
5
@deliprao We did the same thing with AlexNet for years in computer vision, I don’t see a real problem as it’s always good for newcomers, and to pay respects to those who built the foundations of our work.
0
0
5