
Shreyas Kapur
@shreyaskapur
Followers
2K
Following
424
Media
8
Statuses
42
PhD student @berkeley_ai. Previously undergrad at MIT.
Berkeley, CA
Joined June 2012
My first PhD paper!🎉We learn *diffusion* models for code generation that learn to directly *edit* syntax trees of programs. The result is a system that can incrementally write code, see the execution output, and debug it. 🧵1/n
116
615
6K
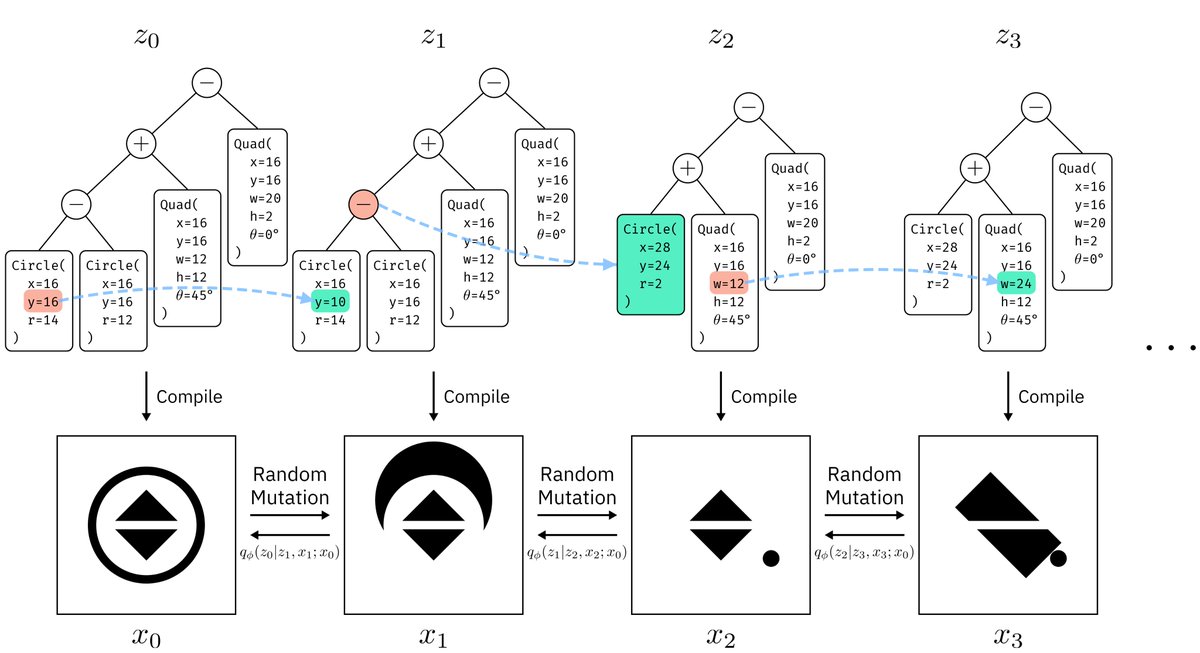
We develop an analogous version of “noise” for syntax trees inspired by the computer security literature on fuzzing🎲. And we teach our model to reverse this noise⏪. 2/n
4
10
265
We managed to get part of our project running in the browser,. Website🌎: Paper📄: Code🖥️: Thanks for my wonderful collaborator @jenner_erik, and advisor Stuart Russell!. n/n 🧵.
6
13
247
I had a lot of fun working on this. I didn't believe that a chess playing neural net could learn to do look-ahead just in its weights, so I was definitely the non-believer in this project.

♟️Do chess-playing neural nets rely purely on simple heuristics? Or do they implement algorithms involving *look-ahead* in a single forward pass?. We find clear evidence of 2-turn look-ahead in a chess-playing network, using techniques from mechanistic interpretability! 🧵
3
15
216
Our implementation works on a given context-free grammar. Here is an example of our model diffusing a smaller “SVG”-like language. 4/n
5
6
204
A model that *edits* code makes it really easy to combine it with a search algorithm🔎. 3/n
1
5
189

We show how our approach outperforms previous methods, including rejection sampling a Vision-Language Transformer that is specifically trained on these tasks (CSGNet in this figure). 6/n

1
3
127
These languages are small, and we only show this approach on a fairly narrow inverse-graphics task. In the future, we hope to show that this approach may potentially work more generally with languages with loops and variables. 8/n.
1
1
124
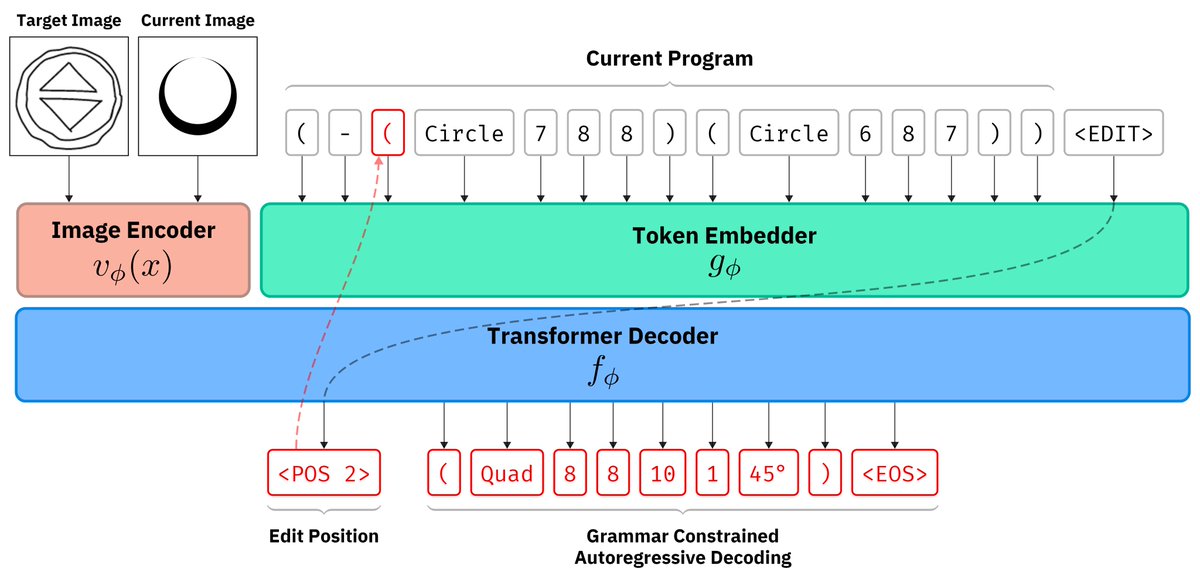
Of course, our architecture is also a Vision-Language Transformer that is trained to edit code via tree diffusion. 7/n
2
2
126
@sdtoyer 😂I'm glad you asked Sam! We've been working on a modern, functional, and performant library for graphics and diagrams in Python called iceberg,.
2
2
60
@anwesh_bh Yes absolutely that's a problem. The tree diffusion approach we propose allows us to collect a very rich dataset of "edits" to train a model. here you can click on "add noise".
2
0
27
@realmrfakename Yes! It can start from a randomly initialized program and edit its way to a target image, guided by search.
1
0
14
@chiaralalalah You should really check out @aaron_lou's excellent work on language modeling,

Announcing Score Entropy Discrete Diffusion (SEDD) w/ @chenlin_meng @StefanoErmon. SEDD challenges the autoregressive language paradigm, beating GPT-2 on perplexity and quality!. Arxiv: Code: Blog: 🧵1/n
1
1
7
🐱🐱🐱✨✨✨.

🪴Should the leaves of a plant be considered separate or part of the whole?. Answer: it really depends! Points can, and should, belong to multiple groups. With GARField, points can belong to multiple groups, with physical scale 📏 as an extra dimension.
0
0
4
Shots fired.

DeepMind is investing heavily in learning to play video games. Congrats! Hope this transfers someday to non-simulated worlds.
0
0
3
It's still impressive to see Facebook use a pure CNN approach against MCTS, if only they combined the two :P.
0
0
2
@EmilevanKrieken In our current mutation scheme, the expression can get longer or shorter at roughly the same probability, so not sure about the limiting distribution. Anecdotally we noticed that if we noise the program some number of times, the programs resemble just random programs.
0
0
1
@dxwu_ More parameters is the new norm in DL, it's so cool to see theory that pins this down!!.
0
0
2
@EmilevanKrieken I think it has a lot of synergies with GFlowNets (which we mention in the paper) and one of our baseline methods (REPL Flow) is a mix between Ellis et. al. reimagined as a GFlowNet.
1
0
3
@hackpert Considering the studies done to compare convnets with brains, I think convnets do emulate a very small but crucial part of a brain.
0
0
1
@InglfurAri As mentioned, the DSLs used are small. The x, y, w, h values snap to a pretty coarse grid. We also limit the max number of objects that can be placed.
1
0
1
"Ultramicroscope does not render the actual colloidal particles visible but only observe the light scattered by them." - NCERT.
0
0
1
Wohoo :)

So for the first time, I met a twitter follower in real life whom I didn’t already know (well) before at IRIS Fair! It’s pretty brilliant.
0
0
1