
Hao Liu
@haoliuhl
Followers
4,434
Following
162
Media
98
Statuses
268
machine learning, neural networks. @Berkeley_AI
Joined September 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
FEMA
• 1203388 Tweets
Liz Cheney
• 209584 Tweets
#LISAxMoonlitFloor
• 197221 Tweets
MOONLIT FLOOR OUT NOW
• 137932 Tweets
SCJN
• 128619 Tweets
The Boss
• 103770 Tweets
#GHGala5
• 100032 Tweets
Bruce
• 92338 Tweets
Mets
• 69981 Tweets
Happy Anniversary
• 59797 Tweets
Baker
• 51010 Tweets
Brewers
• 42600 Tweets
EL DESTELLO IS OUT
• 34794 Tweets
天使の日
• 33230 Tweets
Falcons
• 29013 Tweets
Mancuso
• 25832 Tweets
Halle
• 24850 Tweets
もちづきさん
• 24728 Tweets
Pete Alonso
• 19614 Tweets
Athena
• 15232 Tweets
Mike Evans
• 14530 Tweets
Bijan
• 13510 Tweets
Phillies
• 11404 Tweets
#ゴンチャのハロウィン準備中
• 10748 Tweets
Milwaukee
• 10479 Tweets
Quintana
• 10036 Tweets




















Pinned Tweet

We are excited to share Large World Model (LWM), a general-purpose 1M context multimodal autoregressive model. It is trained on a large dataset of diverse long videos and books using RingAttention, and can perform language, image, and video understanding and generation.


28
263
1K
As a part of our effort to replicate LLaMA in an open-source manner, we are pleased to announce the release of preview of the 7B OpenLLaMA model that has been trained with 200 billion tokens on the RedPajama dataset.

33
400
2K
New paper w/
@matei_zaharia
@pabbeel
on transformers with large context size.
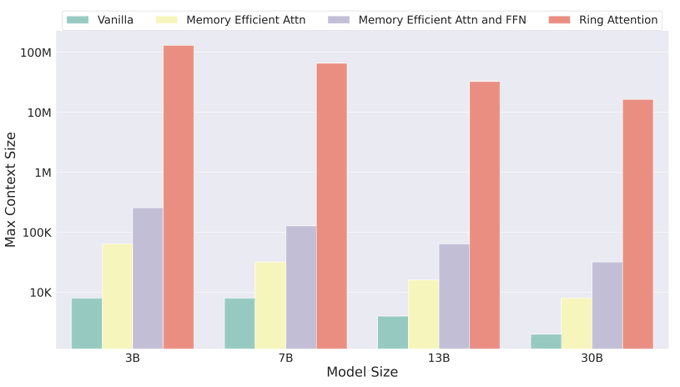
We propose RingAttention, which allows training sequences that are device count times longer than those of prior state-of-the-arts, without attention approximations or incurring additional overhead.

10
179
850
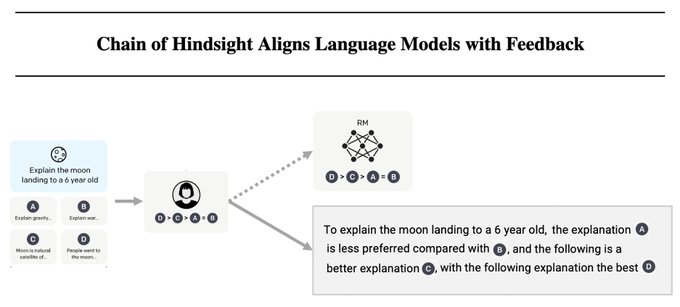
Humans learn from rich feedback in the form of language. Why not turning all feedback into a sentence to train models?
We propose CoH: Just tell models which ones are not good and which ones are better.
Better than SFT and RLHF on summary and dialogue tasks.
13
120
639


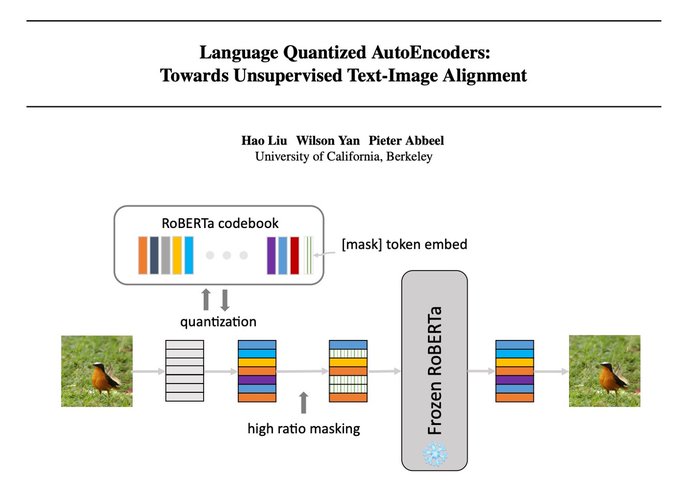
We introduce an unsupervised method to align text and image.
Language Quantized AutoEncoders (LQAE) enables few-shot image classification with GPT3 and linear classification of images based on RoBERTa text features.
paper:
code:
4
83
398
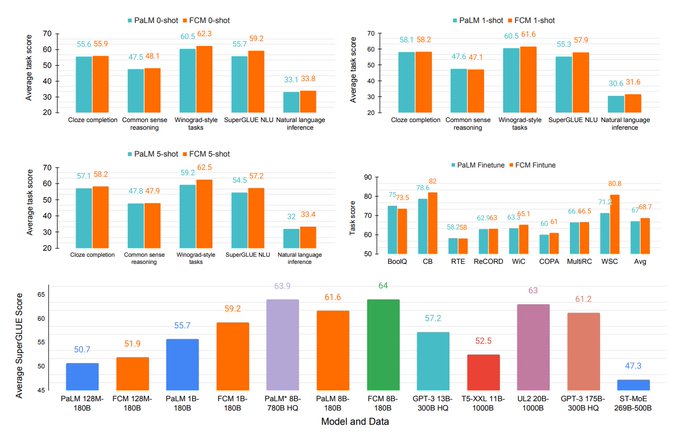
Can language model pretraining be even better?
Our paper shows that by randomly masking input tokens during pretraining, the zero-shot, few-shot, and fine-tuning performance can be significantly improved.
🧵
2
41
302
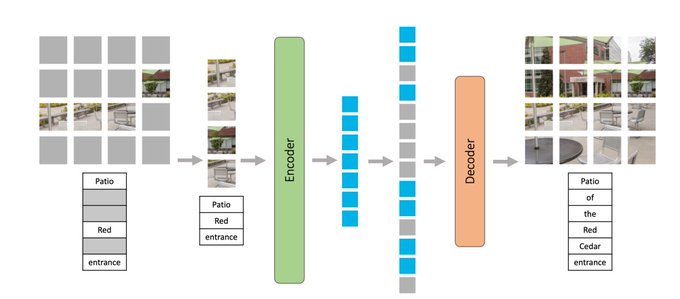
Excited to share M3AE, a simple but effective model for multimodal representation learning.
TLDR: M3AE learns a unified encoder for both vision and language from both paired image-text data as well as unpaired data.
w/
@YoungGeng
Summary thread:
[1/N]
5
38
248
RingAttention's Jax code is available at
In end-to-end FSDP training on GPU (7B params, 8x A100 80G), context expands from 32K to 256K tokens and can reach 16M tokens with 512x A100.
On TPU (7B params, 1024x TPUv4, FSDP), context can reach 8M tokens.

New paper w/
@matei_zaharia
@pabbeel
on transformers with large context size.
We propose RingAttention, which allows training sequences that are device count times longer than those of prior state-of-the-arts, without attention approximations or incurring additional overhead.
10
179
850
3
39
181
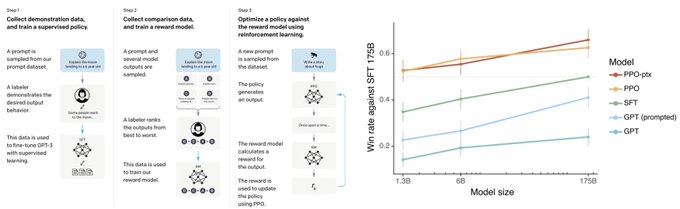
With ChatGPT's mind blowing results, ML community is getting more curious about RLHF.
RLHF outperforms Supervised Finetune (SFT) as shown in InstructGPT.
But RLHF uses an extra large dataset in step 2. Thus, a missing baseline is SFT on both datasets from step 1 and 2.
[1/2]
3
19
175
The code of blockwise parallel transformer is now available.
1
21
109
The possibility of very large context introduces exciting opportunities, such as video-audio-language model, learning from extended feedback or trial-and-error, and AI for science data like gene sequence.
Paper link:
Code link: coming soon

5
6
99
Paper:
Models:
Code:
Website:
This is a joint work with amazing people
@wilson1yan
,
@mateizaharia
,
@pieterabbeel

3
13
92
How to pretrain large language-vision models to help seeing, acting, and following instructions?
We found that using models jointly pretrained on image-text pairs and text-only corpus significantly outperforms baselines.
A 🧵 on the paper InstructRL

3
13
88
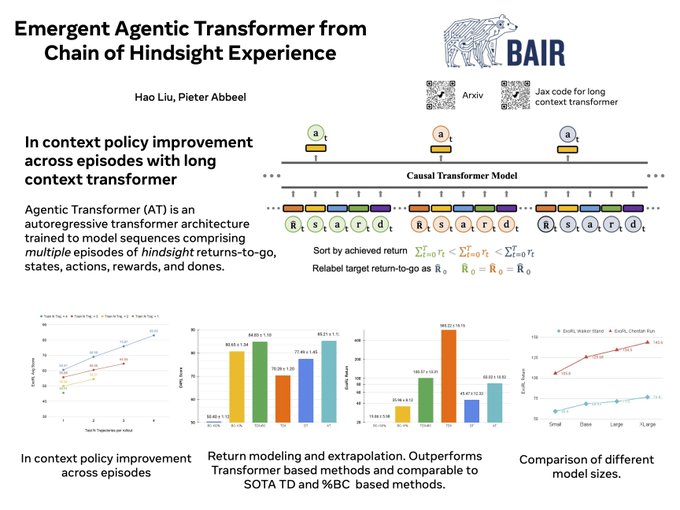
In our
#NeurIPS2022
work, we explore the generality of masked token prediction for generalizable and flexible reinforcement learning.
A 🧵 on the paper
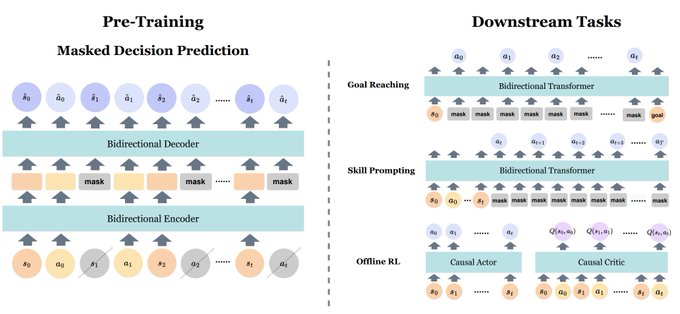
3
21
83
To corroborate with Yann on the importance of having crowd-sourced human feedback datasets, it appears that the absence of such high-quality datasets has became a research bottleneck.
A thread:

Human feedback for open source LLMs needs to be crowd-sourced, Wikipedia style.
It is the only way for LLMs to become the repository of all human knowledge and cultures.
Who wants to build the platform for this?
207
349
2K
1
9
82
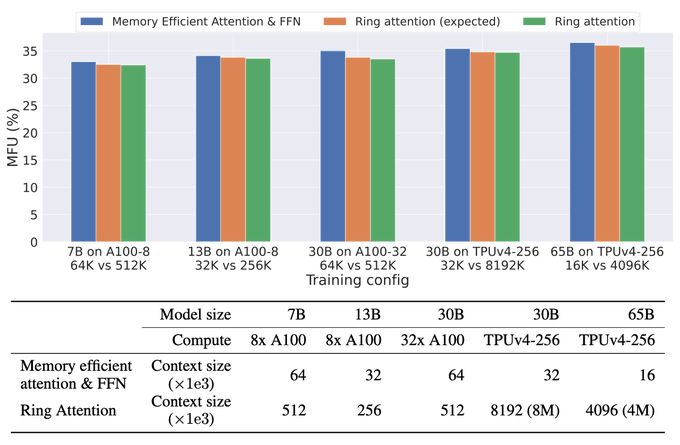
RingAttention lets you scale context length linearly with device count, breaking free from memory constraints. If you could train 4K length on 8 GPU, with RingAttention, you can train at least 32K length with nearly zero overhead
1
7
77
We open-sourced a family of 7B parameter models capable of processing long text documents (LWM-Text, LWM-Text-Chat) and videos (LWM, LWM-Chat) of over 1M tokens, along with the codebase for training and inference. The models are available at .

1
9
61
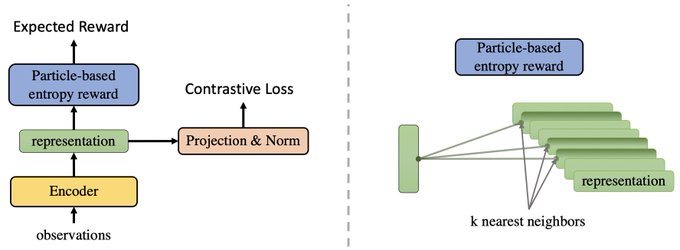
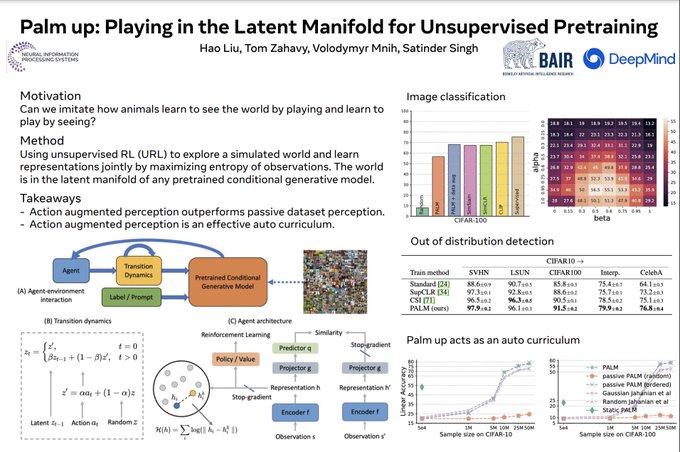
Does interactive learning help developing better perception than learning from static datasets?
In our
#NeurIPS2022
paper, we propose a method based on unsupervised RL that matches SOTA SSL methods, without using data augmentation.
A 🧵 on the paper:
2
10
57
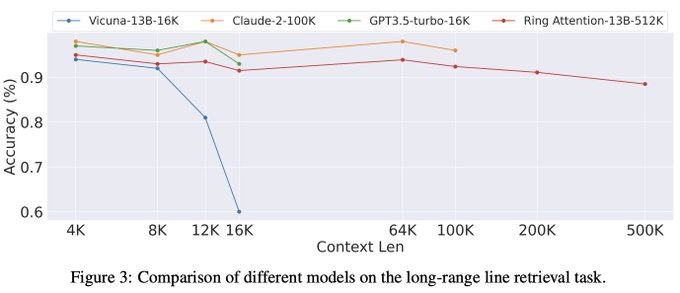
We applied RingAttention to finetune a 512K context chatbot on conversations. On the long-range line retrieval task, GPT3.5-turbo-16K and Claude-2-100K demonstrate competitive accuracy within short context lengths. However, they cannot handle extended context lengths.
1
3
45
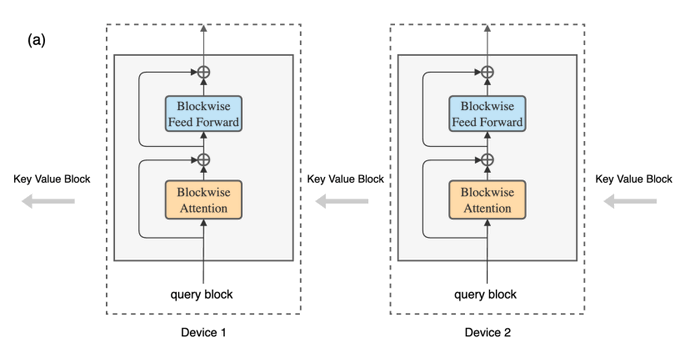
We use the original Transformer's architecture but rearrange the computation. In a ring of devices, each device stores one query block, while key-value blocks rotate through the devices for computing attention and feedforward.
1
2
45
We are currently focused on completing the training process on the entire RedPajama dataset.
This should give us an apple-to-apple comparison between the original LLaMA and our OpenLLaMA.
Please stay tuned for when this will be available!
2
1
44
We evaluated OpenLLaMA using lm-evaluation-harness from
@AiEleuther
. Comparing with original LLaMA(1T tokens) and GPT-J(500B tokens), OpenLLaMA(200B tokens) exhibits comparable performance across a majority of tasks, and outperforms them in some tasks.
1
3
44
Motivated by examining how LLaMA's data curation contributes to its exceptional performance and creating a fully open-source version of LLaMA, we decided to replicate LLaMA with identical training hyperparameters and model configuration as the original.
1
3
40
Many thanks to
@_akhaliq
for sharing our arxiv paper :)

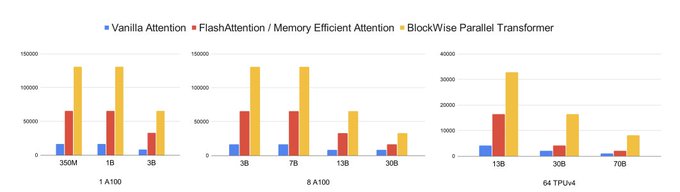
Blockwise Parallel Transformer for Long Context Large Models
present a distinct approach, Blockwise Parallel Transformer (BPT), that leverages blockwise computation of self-attention and feedforward network fusion to minimize memory costs. By processing longer input sequences

0
20
101
2
2
38
We train OpenLLaMA on cloud TPU-v4 pod using data parallelism and FSDP/Zero3 to balance throughput and memory usage. Overall we reach a throughput of over 1900 tokens / second / TPU-v4 chip in our training run. The training loss can be seen in the figure below.
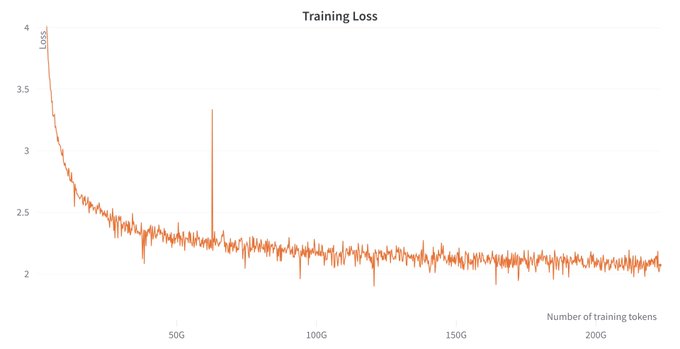
2
4
39
We train OpenLLaMA on the RedPajama dataset curated by
@togethercompute
, which is an open reproduction of LLaMA dataset containing 1.2 trillion tokens and roughly match the number of tokens as LLaMA.
You can find more details in Together's blog .

1
4
38
This is a joint work with amazing collaborators
@carlo_sferrazza
and
@pabbeel
.
Check out the paper and code for more details. The code supports fairly large-scale training/finetuning too.
Paper:
Code:
1
3
38
Just a quick note on training FLOPs w/ exact attention: Scaling context doesn't mean a quadratic increase in FLOPs per dataset. For GPU-rich, 4K -> 10M context on a 175B model incurs 150x FLOPs per dataset. For GPU-poor, we can use 8 GPU to expand context by 8 times with 2x cost.
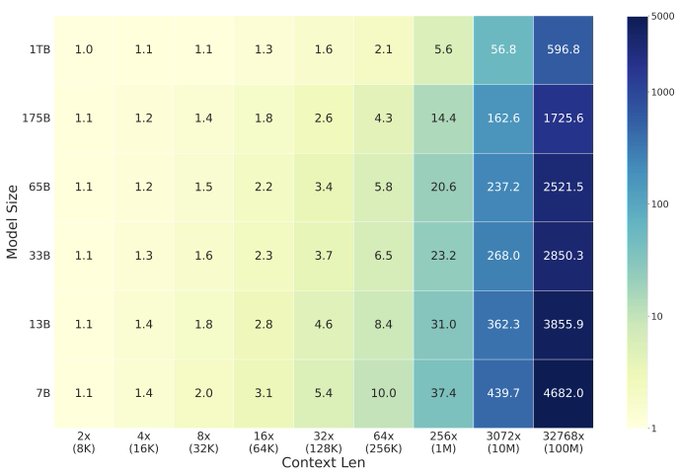
1
3
38
Some thoughts on the work led by my amazing collaborators
@denisyarats
and
@brandfonbrener
.
With diverse data, many problems in RL just go away.
Bitter lesson strikes again.
ExORL could be very useful for future offline and unsupervised RL research.


Currently, Offline RL data is collected under the same reward that is used for evaluation, not ideal...
@brandfonbrener
and I propose an alternative approach – ExORL, that uses Unsupervised RL & relabeling to construct datasets for Offline RL.
paper:
1/10
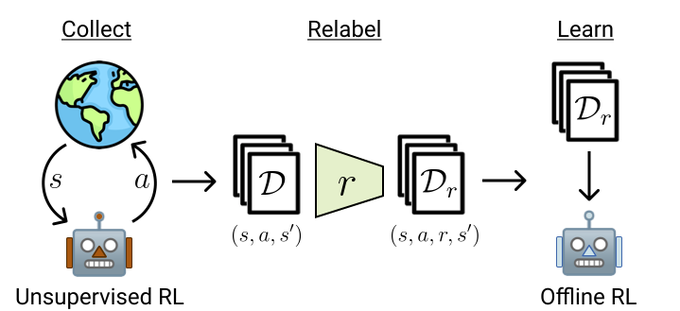
4
31
154
2
12
37
RingAttention sets new records. It can handle sequences device count times longer than previous bests: >16M context with 30B model on TPUv4-512 (512 times longer), >16M for 13B on 32x A100 (32 times longer), and >2M for 13B on 8x A100 (8 times longer).
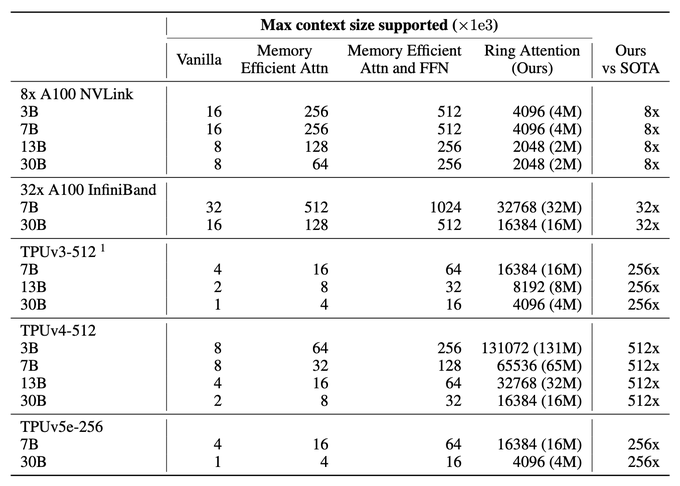
1
2
34
This open source project wouldn't be possible without the diligent efforts from
@younggeng
.
We’d welcome any feedback and contributions!
3
2
34
As we compute attention, each host sends key-value blocks to the next host while receives key-value blocks from the preceding host.
If block size is larger than a threshold, the communication of key-value block is fully overlapped by the computation of attention and feedforward.
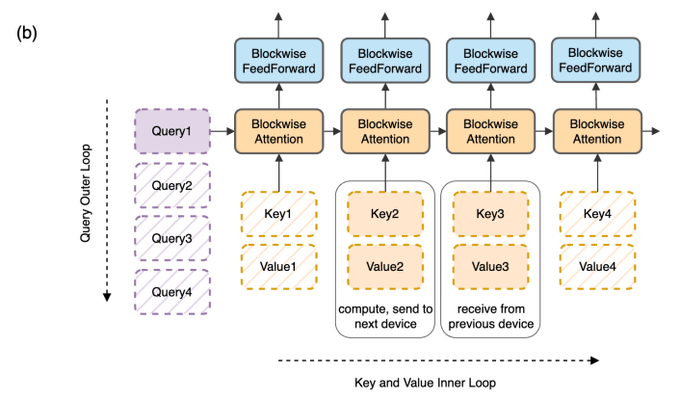
1
0
33
With RingAttention, each device's memory requirement is linear with the block size instead of the entire sequence. Here, b is batch size, h is hidden dimension, n is number of head, s is sequence length, c is block size.
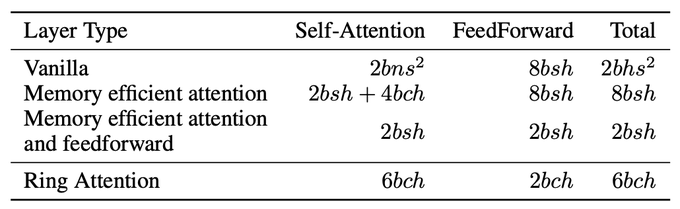
1
1
33
We expect that the performance of OpenLLaMA, after completing its training on 1 trillion tokens, will be enhanced even further.
The current release is only a preview of what the complete OpenLLaMA release will offer.
1
1
31
We curated a very large dataset of diverse long videos and texts and proposed a two-stage training to enable large context world model on video and language. We expand Llama2's context progressively from 4K to 1M on language and video to manage compute cost.
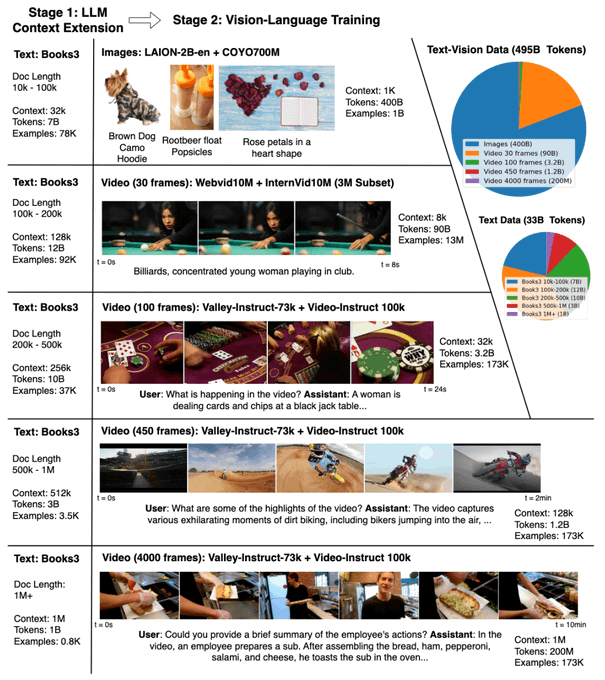
1
2
31
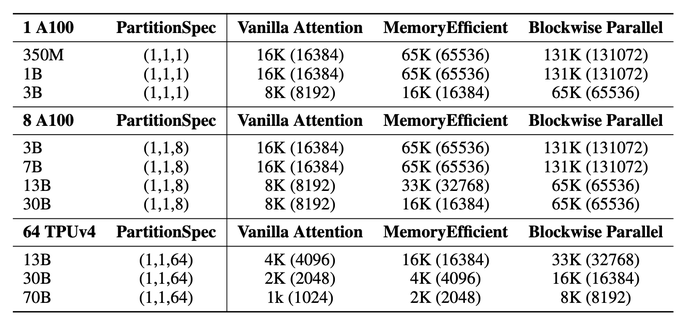
@pabbeel
14/ We are excited to see what's next: what new capabilities will emerge from being able to train longer context large Transformers?
Check out the paper for more details, full code will be released soon.
Paper:
1
4
22
Current approaches on modeling the world are mostly restricted to short text or image sequences, limiting their understanding about parts of the world that are hard to represent in texts or short clips, and are unable to process complex long-form language and visual tasks.
1
0
27
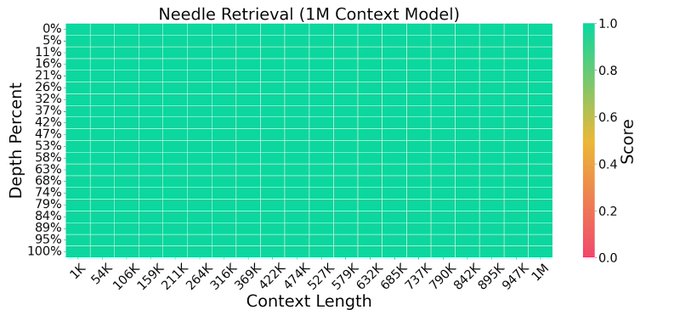
By expanding context on long-form books and model-generated QA data. LWM achieves near-perfect accuracy on the popular needle retrieval task, outperforming GPT4 and Gemini Pro.
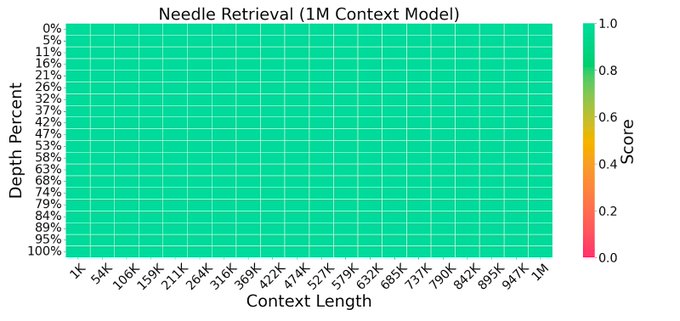
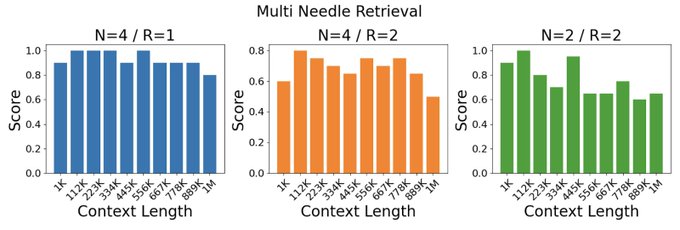
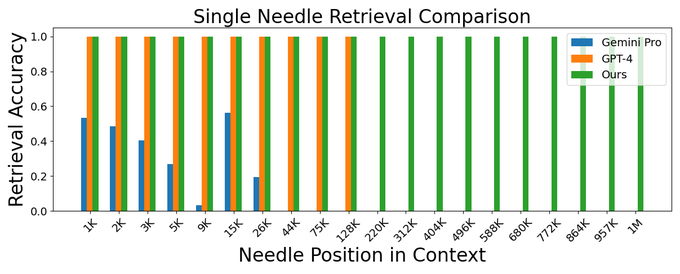
1
3
25
RingAttention requires only a ring topology which is very minimal and supported on GPU and TPUs. The minimal block size is determined by FLOPs/unidirectional bandwidth and can be easily met with using efficient blockwise attention and ffn on each device.

1
1
24
LWM opens up exciting possibilities for the development of more capable AI systems that understand both textual knowledge and multimodal world and solve a wide range of problems.
Paper:
Code:
Website:
4
1
25
Upon close inspection, the RLHF datasets' conversations (e.g., HH dataset) have a substantially worse quality and diversity than ShareGPT.
So Koala already captures a good distribution via SFT on ShareGPT, further RLHF/CoH/SFT on the HH dataset deteriorates model performance.
2
0
23
@pabbeel
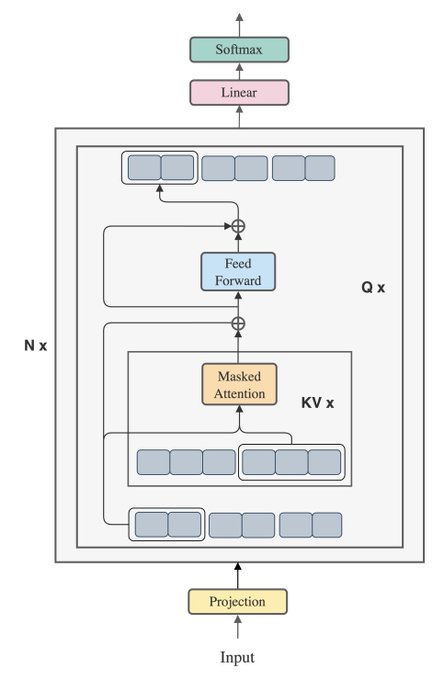
2/ Our method, the Blockwise Parallel Transformer, leverages blockwise computation of self-attention and fused feedforward to minimize memory costs.
We use the same model architecture as the original Transformer, but with a different way of organizing the compute.
1
1
20
Interestingly while our model generated text outputs are not interpretable to human, LLM can successfully do few-shot learning from them. This suggests LQAE and BERT-like model generated text tokens contain patterns that can be successfully captured and leveraged by powerful LLM.

2
4
20
Thanks
@ak92501
for tweeting so fast!
Multimodal Masked Autoencoders Learn Transferable Representations
abs:
the Multimodal Masked Autoencoder (M3AE), which learns a unified encoder for both vision and language data via masked token prediction
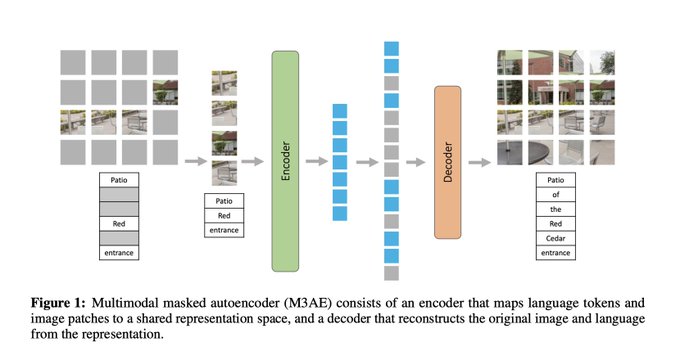
1
26
173
0
3
20
After training the 1M context language model on a large dataset of diverse visual and language sequences with masked sequence packing and RingAttention, LWM can perform language, image, and video understanding and generation.
LWM can do text-to-image generation.


1
0
20
How to learn from all feedback without RL?
Our idea: Humans learn from rich feedback in the form of language.
Given that LLM is already powerful, why not turning all feedback into a sentence and train model to follow the feedback?
We propose chain-of-hindsight (CoH):
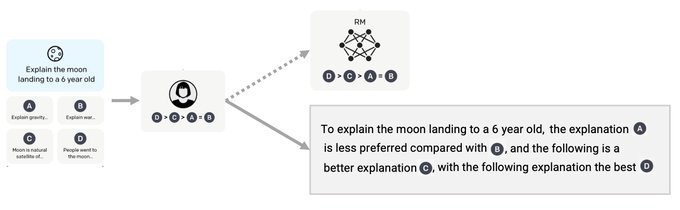
1
1
20
Heading to
@NeurIPSConf
now. I'm thinking about generalization of language models and interactive agents. Please say hi if you're into about these too.
I will be presenting BPT & LQAE posters, plus EAI and RingAttention in workshops.
1
0
17
LWM can answer questions based on over 1 hour long YouTube video, while GPT-4V and Gemini Pro Vision struggle.

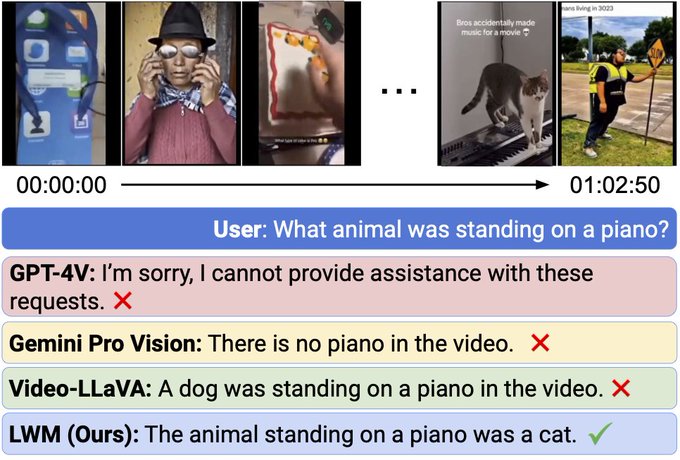

3
1
17
LWM can do video generation from text prompts.
See website for more video examples:


1
0
17
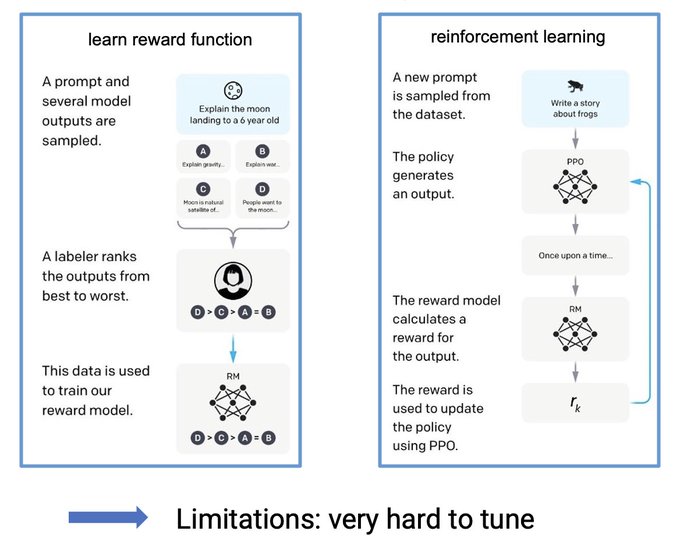
The techniques behind ChatGPT are Supervised finetuning (SFT) and reinforcement learning with human feedback (RLHF).
SFT is simple and scalable but cannot use negative feedback.
RLHF uses all feedback but is very complex and very hard to tune.
Can we go beyond SFT and RLHF?
1
1
16
We propose masked sequence packing such that each image and text pair only attends to tokens within the pair. Mixing images, texts, and video with standard sequence packing, widely used in current approaches of language model training, leads to very suboptimal model performance.
1
0
16
We propose model-generated QA to address limited long-text data at this stage: We split documents into fixed chunks for our short-context model to generate QA pairs per chunk. Then, we construct long-context examples by merging adjacent chunks and appending QA pairs to the end.
1
0
16
In this work, we propose LWM to model complex million-length language and visual sequences. We curated a large, diverse dataset and utilized RingAttention to scalably train on it. We discover challenges and propose masked sequence packing and model-generated QA to address them.
1
1
16
@pabbeel
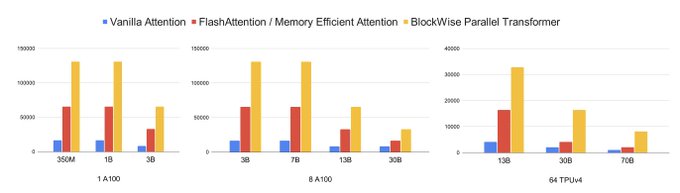
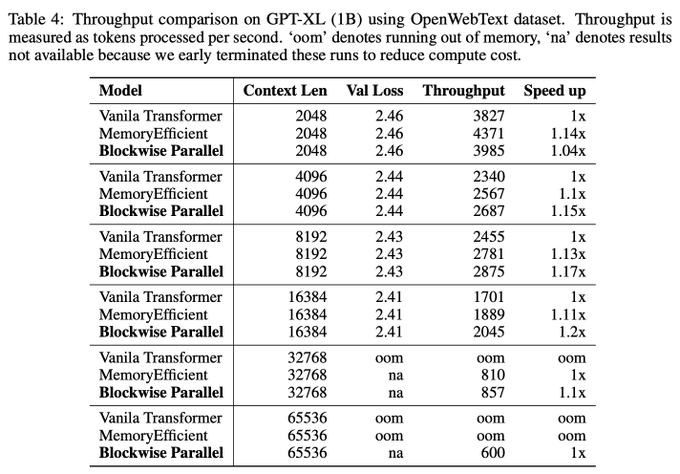
12/ In terms of speed, using high-level Jax operations, BPT enables high-throughput training that matches or surpasses the speed of vanilla and memory efficient Transformers. Porting our method to low-level kernels in CUDA or Triton will achieve maximum speedup.
1
0
15
We found that vision-language training needs to mix images, videos, and pure texts together. Without pure texts (e.g. openllama v2 mix), model overfits to vision; without images, video generation has low visual quality since videos often have lower visual quality than images.
1
1
16
This baseline, improved SFT, should outperform SFT due to more human labeled data.
But how much does RLHF still outperform improved SFT?
Having an answer is helpful in understanding and improving results. It would be great if this baseline could be included in the future.
[2/2]
0
0
15
To conclude:
CoH is a simple framework for aligning language models with feedback. The idea is turning all feedback into a sequence to train models.
The real world offers many different forms of feedback, which present interesting opportunities for learning in the future.

1
1
15
💡 We took inspiration from Ng (
@AndrewYNg
) & Jordan 2002, which showed that classifiers trained with a generative loss can outperform classifiers trained with a discriminative loss. Our work can be seen as lifting it into today’s context of training deep NNs.
[3/N]
2
2
15
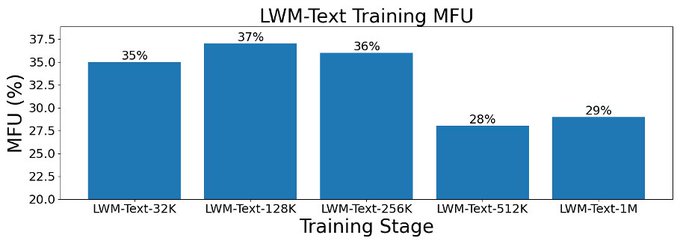
This work provides a highly-optimized, open-source implementation with RingAttention, masked sequence packing, model-generated QA, and other key features for millions-length vision-language training. We have good MFUs even at very large context sizes.
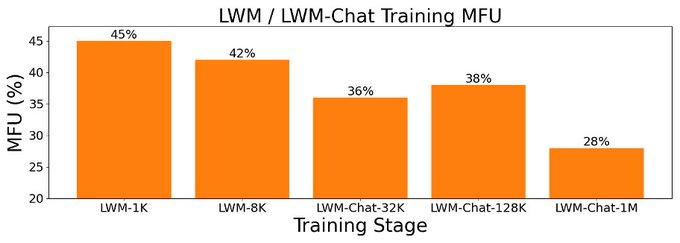
1
1
15

The Jax implementation has been released
Some additional features added:
-Predicting discretized image tokens from VQGAN as output (similar to BEiT).
-Training on a combination of paired image-text data (e.g. CC12M) and unpaired text data (e.g. Wikipedia)

Excited to share M3AE, a simple but effective model for multimodal representation learning.
TLDR: M3AE learns a unified encoder for both vision and language from both paired image-text data as well as unpaired data.
w/
@YoungGeng
Summary thread:
[1/N]
5
38
248
0
1
14
LLMs are in-context and multi-task learners after unsupervised learning on broad data.
But how to learn from ubiquitous feedback in the real world?
ChatGPT and InstructGPT show amazing results by learning from human feedback.
1
1
14
Starting with the 1M context language model, we train on mixed formats: images, videos, and texts in diverse formats (text-image, image-text, video-text, text-video, etc.) using autoregressive prediction. Essentially in an any-to-any prediction manner with multiple modalities.
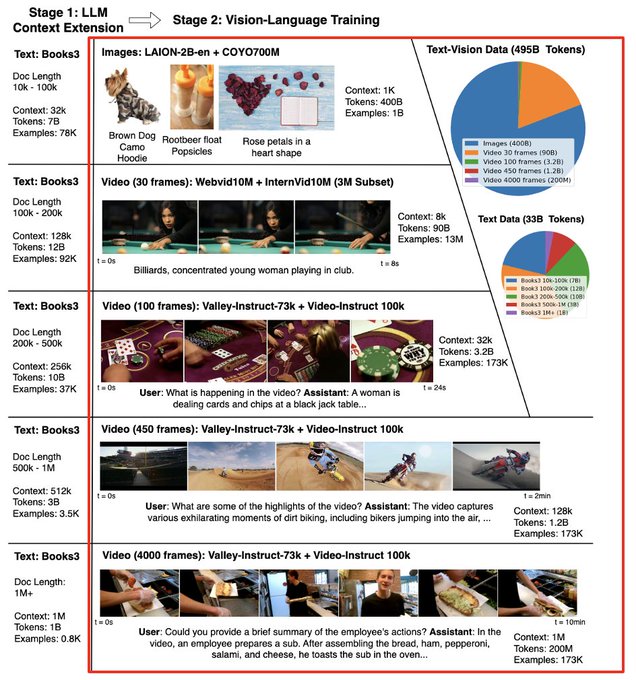
1
0
14

@HlibIvanov
@matei_zaharia
@pabbeel
Stay tuned! We are interested in training / finetuning large context LLM/VLM with RingAttention.
2
1
13
Better summarization.
CoH outperforms SFT and RLHF on summarization benchmark.
CoH achieves higher scores (left fig) and generates summary that is significantly more preferred by human evaluation (right table) than SFT and RLHF.
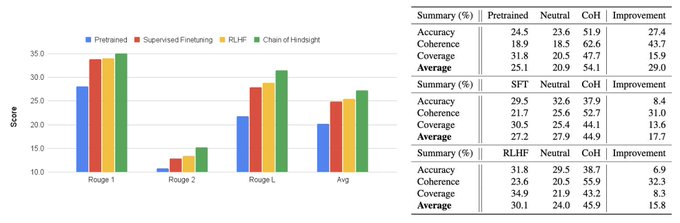
1
0
13
Better dialogue.
CoH outperforms SFT and RLHF on dialogue benchmark from AnthropicAI human preference dataset.
CoH achieves higher accuracy at classifying which dialogue is preferred (left fig) and is substantially more preferred by human (right table) than SFT and RLHF.
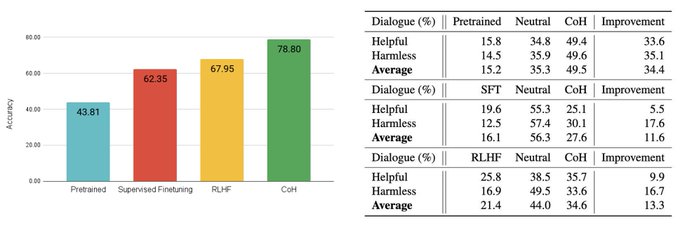
2
0
12
CoH just consists of a likelihood function and is simple to implement.
It comes with several advantages:
1. More natural type of feedback
2. More natural form for training procedure
3. More effective experimental results
CoH outperforms RLHF and SFT in a wide range of tasks.
1
0
12
At inference time:
CoH uses positive feedback guides the model to generate the desired outputs, such as "generate a good and informative summary".
Since CoH has seen different comparisons, it can follow follow-up instructions such as "generate a better summary".
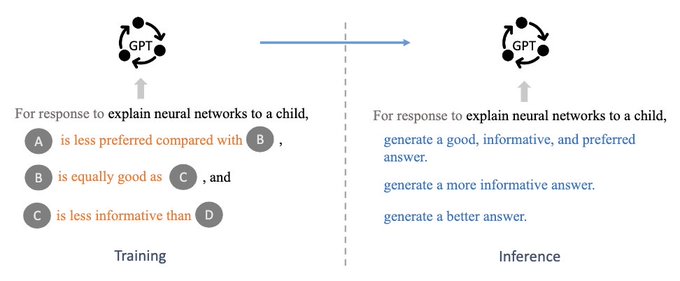
1
1
11
Our method, Forgetful Causal Masking(FCM), combines masked language modeling (MLM) and causal language modeling (CLM) by masking out randomly selected past tokens layer-wisely using attention mask.
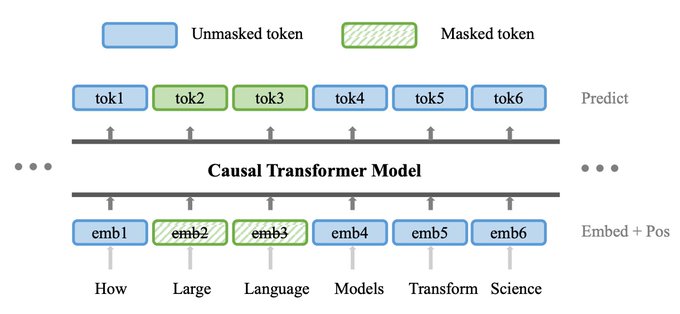
1
2
10
Better controllable generation.
CoH is better at following multi-round instructions than the second best RLHF, for instance "Generate a good summary", "Generate a shorter and more precise summary".
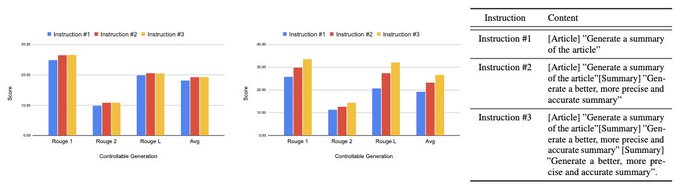
1
0
10
The idea is to encode image as sequences of text tokens by directly quantizing image embeddings using a pretrained BERT codebook. We then apply random masking followed by a BERT model, and have the decoder reconstruct the original image from BERT predicted text token embeddings.
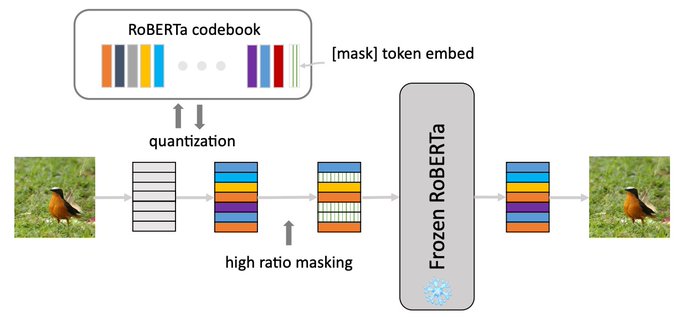
1
1
8
Properties of FCM
1. no extra compute cost
2. simple to implement and works
3. scales well to larger models
Applying FCM to PaLM trained on C4, it improves zero-shot SuperGLUE performance from 55.7% to 59.2% (1B model) and 61.6% to 64.0% (8B model).
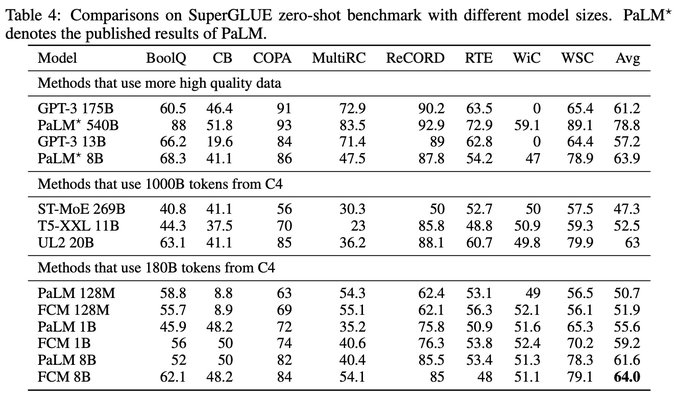
1
0
8
During training time:
CoH randomly samples one or multiple model outputs and use them to form a sentence consists of both positive and negative feedback in the form of comparison, such as "The following is a bad summary" and "The following summary is better".
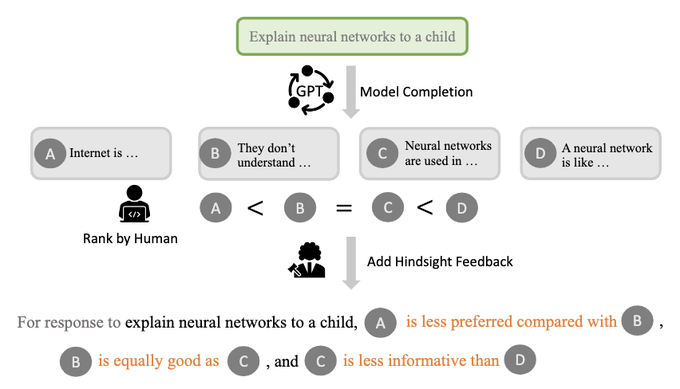
1
1
8
The links of great work mentioned above: Alpaca(), Vicuna(), AlpacaEval(), MTBench().
0
0
8
🌈 Concurrently,
@jimwinkens
et al. ,
@sangwoomo
&
@BunelR
et al. showed that contrastive learning(e.g. SimCLR) improves OOD detection of classifiers!
However, HDGE's contrastive loss term doesn't rely on data augmentation.
[9/N]
2
0
8
Thanks for the attention.
Check out the paper for more details. We are excited to apply this technique to improve large language models and beyond.
All comments and feedback are welcome.
1
0
8
Our largest 8B model matches the score of PaLM with an average score of 64%, despite the fact that PaLM is trained on a much larger dataset (780B tokens) of high-quality conversation and webpage data, while ours is trained on the smaller C4 dataset (180B tokens).
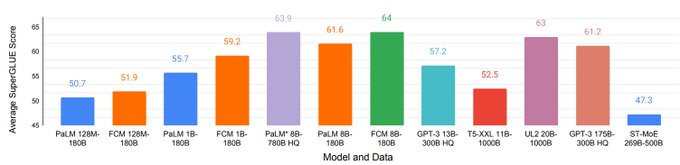
2
0
8
📝 Due to its flexibility and scalability, M3AE is especially suitable for learning from extremely large-scale datasets, and we envision that such pre-trained models can be broadly applicable in many practical downstream tasks, such as visual reasoning and RL.
[10/N]
1
0
7
Just like prior AI breakthroughs which are based on open and high quality datasets (thanks ImageNet/Atari/Wikipedia), in order to advance research on language models, we probably also need crowd-sourced human feedback datasets that are built with open source models.
1
1
7
A higher masking ratio than normal is necessary for good downstream performance, as standard language denoisers such as BERT commonly use a masking ratio of 15%, where LQAE performance is highest at around 50% masking ratio.
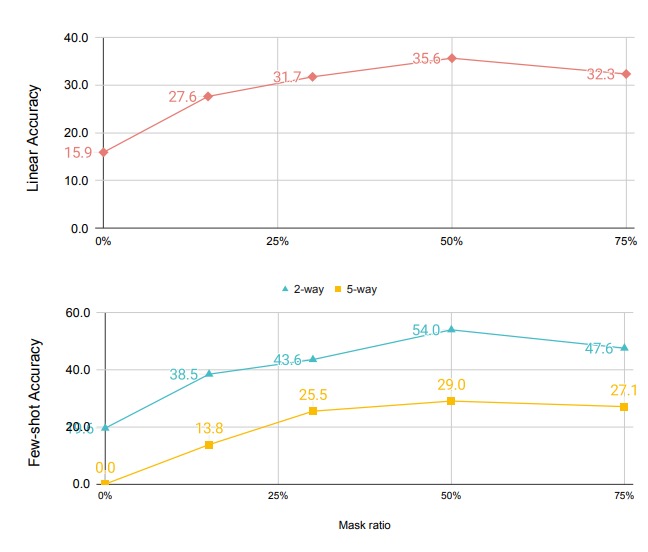
2
0
7
In Feb, we proposed CoH, a SFT based alternative to RL-based RLHF.
We were excited to see that such a straightforward conditional training appears to outperform RL-based RLHF on public human feedback dataset such as Anthropic's HH dataset.
Humans learn from rich feedback in the form of language. Why not turning all feedback into a sentence to train models?
We propose CoH: Just tell models which ones are not good and which ones are better.
Better than SFT and RLHF on summary and dialogue tasks.
13
120
639
1
0
7
🔋 We find that HDGE significantly improves the out-of-distribution detection(OOD) over standard cross-entropy training, prior generative models, prior energy-based models & prior contrastive learning! Our ablation study shows that hybrid training is crucial to performance.
[8/N]


1
0
6
💡We find that that Multimodal Masked Autoencoders (M3AE) trained purely via masked token prediction, without using modality-specific encoders or contrastive learning, can learn transferable representations for downstream tasks.
[2/N]
1
1
6
Thanks to the free MLM training, not only FCM improves zero-shot learning, it also improves finetuning performance, from 67.0% to 68.7% (1B model) and 81.0% to 82.5% (8B model).
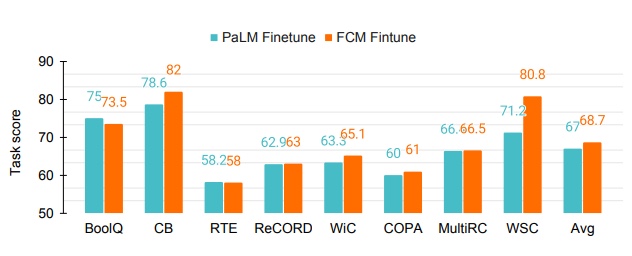
1
0
6
This is a joint work with amazing collaborators
@WilsonYan8
and
@pabbeel
Check out our paper and code for more details:
paper:
code:
1
0
6