

Alex Nichol
@unixpickle
Followers
9,406
Following
398
Media
970
Statuses
5,647
Code, AI, and 3D printing. Opinions are my own, not my computer's...for now. Husband of @thesamnichol . Co-creator of DALL-E 2. Researcher @openai .
Joined September 2011
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
オリンピック
• 683524 Tweets
Christians
• 400909 Tweets
#บัสซิ่งไทยแลนด์EP7
• 256354 Tweets
花火大会
• 222787 Tweets
#พรชีวันep1
• 177758 Tweets
1M LOVE LINGORM
• 133813 Tweets
Endrick
• 128477 Tweets
グラブル
• 117351 Tweets
スポーツ
• 114780 Tweets
Itália
• 77181 Tweets
YOKOFAYE WATCH BLANK
• 73795 Tweets
Judo
• 67382 Tweets
永山選手
• 66384 Tweets
#SixTONESANN
• 49478 Tweets
柔道の審判
• 48515 Tweets
Darlan
• 42559 Tweets
#青島くんはいじわる
• 34549 Tweets
Leclerc
• 34367 Tweets
#ジェルくん誕生祭2024
• 31791 Tweets
Arabia
• 30122 Tweets
反則負け
• 28979 Tweets
Checo
• 23734 Tweets
柔道の判定
• 23261 Tweets
ハンドボール
• 20692 Tweets
コラボガチャ
• 20009 Tweets
Equi
• 19948 Tweets
男子バスケ
• 16425 Tweets
Irak
• 16386 Tweets
クラフトワーク
• 14976 Tweets
Babiarza
• 12670 Tweets
ガルリゴス
• 12184 Tweets
girl in red
• 10959 Tweets
タルマエ
• 10370 Tweets





















Luckily, years of Deep Learning research have honed my ability to sit in front of a graph and refresh every few seconds.
12
183
2K
Super excited to release Shap-E, our latest work on 3D generative modeling.
Paper:
Code/models:
26
181
807
Happy to share a cool hobby project I've been working on for the past few weeks: predicting attributes of cars from images.
Blog post:
Github:
Gradio demo:

27
70
625
GPT-4o is a huge step forward for image generation. Not only is it amazing at rendering text and following captions, it also provides a very natural way to iteratively edit and compose visual concepts. 1/8



20
56
451
There is a new 3D generative model in town: Genie by
@LumaLabsAI
. This model is surprisingly good and insanely fast! As someone who has worked on 3D generative modeling, here are my observations and guesses about how this system works (without any insider info):
5
34
315
♡

4
7
278
Super excited to share our work on DALL-E 2 pre-training mitigations!

21
42
231
Now anybody can tinker with and explore the current SOTA generative image models! We have released model weights for our paper "Diffusion Models Beat GANs on Image Synthesis":

3
34
234
Agent finally learning to beat the 10th floor! A few more days of training and I'll probably be ready to submit this. Whole thing is rewritten in PyTorch now, no more anyrl-py or TensorFlow.
6
30
201
Vacation project: convert trained scikit-learn models into Torch modules.

3
31
197
I'm still not convinced that large-scale RL is anything other than "smoothed-out search distilled into a small model". 1/5
10
29
190
My theory for why Python is so popular for deep learning: Python is so slow that the CPU basically looks like a GPU--you need vec ops or special kernels just to get good perf. Python devs were used to this from the start (e.g. numpy) so GPU frameworks felt natural.
11
15
174
So they initialized the carpet at x_T and forgot to run the diffusion sampling chain...?

7
8
167
Blog post and code up for my solution to the Obstacle Tower Challenge.
Blog:
Code:

12
42
162




Super excited to release VQ-DRAW, a new kind of discrete VAE!
Paper:
Code:
Blog:

4
37
153
Finally released our new, extremely simple meta-learning algorithm!
4
33
146
I am very surprised that this 13B parameter model has been released! Very awesome

1
19
141
I've been working through the Bayesian Flow Networks paper a bit. Here are a few of my thoughts and tips to readers...
2
8
132
I tried JAX this weekend, and made a cool project with it: texture mapping with VAEs.

2
18
128
TIL that matrix multiplications are rather inefficient on my 6-year-old NVIDIA Titan X, achieving only 25% occupancy even with optimized kernels. I noticed this while writing my own matmul kernel in pure PTX, where I bumped up against some annoying hardware constraints. 1/6
4
3
126
Finally got decent speaker conversion results using VQ-VAE + diffusion models! Sampling only takes a few seconds on a GPU.
3
17
118
Super excited to see what cool things people do with this.

Point·E: A System for Generating 3D Point Clouds from Complex Prompts
abs:
github:

7
72
354
6
10
105
So RNNs are just really deep networks. We now seem to be good at training really deep networks, i.e. LLMs, with layer norm and residual connections. Has anybody gone back to see if LSTM/GRU/other tricks are still necessary for RNNs, versus just a residual RNN?
17
2
104
Happy to share my latest hobby project: representing 3D shapes as oblique decision trees. Surprisingly, this representation has a few neat properties that might make it useful!
Blog:
Github:
5
11
100
This is something I always wanted to investigate, but never had time to. It would seem that MAML (and presumably Reptile as well) learn useful features in the outer loop, rather than learning how to learn useful features in the inner loop.

Rapid Learning or Feature Reuse? Meta-learning algorithms on standard benchmarks have much more feature reuse than rapid learning! This also gives us a way to simplify MAML -- (Almost) No Inner Loop (A)NIL. With Aniruddh Raghu
@maithra_raghu
Samy Bengio.

9
163
603
1
13
100
JoJoGAN works so well because GANs trained on real faces can project stylized faces onto the manifold of real faces zero-shot. I wonder why this is the case, and what other domains would have this property.

3
5
95
Finally a real-life application of CycleGAN!

0
13
93
Wrote an incredibly concise and easy-to-use implementation of MAML in PyTorch. Just plug in any nn.Module.

0
23
88
If there's one thing I'm remembered for, let it be popularizing the use of corgis in generative modeling research.
3
2
85
Announcing my own compression challenge. My program achieves 10x compression, but I will accept any winners who achieve at least 9x compression. I will pay $2,000 to the first person to solve this before May 29, 2024, at 12:00PM, PST.

11
8
76
@ak92501
This is ridiculous. None of these are novel contributions and they don't reference any of the many past works that apply diffusion to inpainting.

4
5
78

One use case I'm excited about is telling a story with images. In this example, we use the model to create a character and then immerse her in a visually-consistent, fictional world. 2/8




2
3
75
I hope GAN researchers remember that faces aren't the only images on the internet and at least start using ImageNet again...
4
6
76
My latest vacation project was Bezier MNIST: a vector graphics version of the MNIST character dataset. Earlier this week I made an algorithm to convert images to Bezier curves, and now I applied it to all of MNIST!

1
3
75
PyTorch should always tell you every shape of every argument whenever a function raises a shape error.
3
0
72
A neat thing about this model is that it can produce multiple consistent views of a 3D object, allowing us to reconstruct 3D models of complex shapes. 5/8
6
3
70
Vaguely inspired by Netflix's "Is It Cake?", I had DALL•E 2 generate some cake ideas.
2
12
69
Idea for AI startup: film & analyze everything I do in my home, then instantly answer queries like "where did I put my scissors?"
8
3
68

It continues to astound me that the built-in PyTorch Transformer isn't really used/usable in any serious projects. They should consider updating the standard library, since this is such a crucial building block.
7
2
62
DDIMs are generative models with a latent space that is never learned or explicitly defined--it's implicitly created from the data distribution. Mind-bending stuff.
1
10
66
I just read this paper as someone familiar with RL but not so much with video compression. Some thoughts and questions in thread...
MuZero with Self-competition for Rate Control in VP9 Video Compression
abs:
MuZero-based rate control achieves an average 6.28% reduction in size of the compressed videos for the same delivered video quality level (measured as PSNR BD-rate)



0
5
39
1
6
64
New blog post on three of my recent ML research projects that _didn't_ pan out. Negative results can be informative, and I think the ideas are still interesting!
1
11
62
Turning a NeRF into a textured mesh is an interesting way to explore what the model is actually learning. In this case, it's clear what the training camera angles don't cover.
1
6
59
I'm surprised how few people realize it's possible to underfit and overfit at the same time.
2
2
60
Hypothesis: RL can learn to play N-dimensional Pong for all N.
1
12
60
Working on a new kind of discrete VAE that can generate good samples without any auto-regressive prior. Here's samples and test set reconstructions on MNIST with a 60-bit(!!!) prior:

4
0
60

I investigated this in 2017 and even at the time it looked encouraging. Glad to see it make a comeback.


Learning to (Learn at Test Time): RNNs with Expressive Hidden States
- Performs Linear-time RNN by propagating the gradient to the next step, i.e., test-time training
- Achieves better perplexity than Mamba

7
82
413
2
7
61
Everyone seems excited about Mamba. What I can't glean is whether anybody has tried evals other than log-loss. Do we have a strong reason to believe these models actually compete with Transformers on realistic tasks?
6
3
57
As a totally hacky and preliminary demo, check out the web app I made for my VQVAE + diffusion voice changer!
I'd say it works reasonably well for me 50% of the time. Curious to see what you all can make it do!
1
7
57
It's kind of mind-blowing that NeRF using COLMAP camera estimation is better at reconstructing scenes than COLMAP itself.
2
3
55
Speaking of consistent characters, how about becoming movie stars? Here, the model is able to depict me and
@gabeeegoooh
as detectives in a stunning movie poster. Note how our names and the movie title are rendered properly! 3/8


3
2
53
What we really want is algorithms that use lots of knowledge and reasoning to choose what to explore, how to act, how to attribute credit, etc. Results on single games do not look like this at all. 5/5
6
4
54
Getting scooped on a really good idea sucks, but sometimes I have to remind myself that nothing is as bad as being forgotten as the inventor of calculus.
4
2
54
The model can also compose ideas across images, e.g. here it is able to add the OpenAI logo to a photo of a coaster. 4/8

1
4
52
I'm reading this 2011 paper on parallelizable pseudorandom number generators, and it contains some surprisingly good knowledge for someone with no background in cryptography.

2
5
54
There's something unsettling about SimCLR. The paper shows that the network, at some intermediate layer, has more relevant information to classification than it does right before the output layer used for the contrastive loss. Why should this be the case?
3
5
53
I have now learned that it's a fallacy to equate occupancy with efficiency! It's possible to fully utilize the hardware with low occupancy by leaning on instruction-level parallelism.
@cHHillee
pointed me to this very elucidating slide deck:
TIL that matrix multiplications are rather inefficient on my 6-year-old NVIDIA Titan X, achieving only 25% occupancy even with optimized kernels. I noticed this while writing my own matmul kernel in pure PTX, where I bumped up against some annoying hardware constraints. 1/6
4
3
126
1
4
50
I've learned that whenever I write PyTorch code with scatter_ and gather, there's a 90% chance it will have a bug.
8
1
48
NeRFs are periodic functions, so this is what happens if you render a scene without clamping to the bounds of the model.

4
0
49
I thought the codefusion paper was too good to be true. How could such a tiny model learn to write _any_ meaningful code? The thing they didn't mention in the abstract is that they use a pretrained CodeT5 encoder, which is much larger than the entire rest of their architecture.
3
6
47
I feel deceived and blindsided. Apparently, Snoop didn't actually quit weed! WTF
3
1
46
My wife's summary of my workday:
1. Fix a bunch of bugs
2. Introduce one bug that breaks everything
3. Launch a bunch of experiments to run overnight
4. Realize the bug from step 2 the next day
1
0
47
RL has its own "five second rule": "if it happened more than 5 seconds ago...it doesn't matter?"
1
3
45

By generating multiple images and context, and leveraging the model's amazing text rendering capabilities, we can do neat things like create custom fonts. 6/8


2
0
43
Anybody else find it a bit surprising how many independent video models are suddenly dropping?
7
2
41
Guys, I finally figured out what Ava said to Kyoko in Ex Machina.

2
1
43
Solution to my compression challenge. The files were encrypted -- simple as that.
Encrypted files "look like noise", but they _do_ have structure and _can_ be compressed--if you are willing to invest lifetimes of compute into it!

7
1
42


Has anybody tried scaling up LPIPS since the original work ~5 years ago. It seems like we could get a much better metric with modern backbones and a larger dataset of judgements.
6
0
40
Just read this paper. My main question is why you'd inpaint a ball instead of outpainting a panorama, since I think they can accomplish the same thing.
Paper:

7
1
39
This massive neural net has been training for over two months with mostly unsupervised learning. Time for RL to begin.

0
2
40
I got a parking ticket in the Bay Area. You know what that means! I scraped ticket data from the online payment website. I estimate that all the tickets add up to between $79M and $130M.



4
1
39
💜

I deeply regret my participation in the board's actions. I never intended to harm OpenAI. I love everything we've built together and I will do everything I can to reunite the company.
7K
4K
33K
2
2
39
So what is my guess about how this model works? My best guess is that an image diffusion model is fine-tuned to produce multi-view images, possibly with an additional depth channel, and then a novel second stage produces a NeRF quickly from this output.
3
2
38
In this example, we can see just how well the model does at rendering a complex image. It uses two separate chat bubbles for the messages, renders a ton of text correctly all at once, and almost perfectly depicts a QWERTY keyboard. 7/8

2
1
36

Discreetly scanned this purse-that-looks-like-a-snail in Florence, today. Lots of other stuff in that store I wish I had grabbed too.
5
1
38
Give this a read; it may blow your mind.
6
8
38
Amazing work! This is a very important moment for RL.

New paper - CURL: Contrastive Unsupervised Representations for RL! We use the simplest form of contrastive learning (instance-based) as an auxiliary task in model-free RL. SoTA by *significant* margin on DMControl and Atari for data-efficiency.
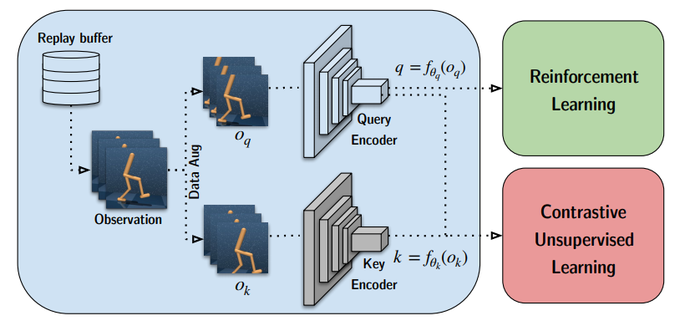
11
240
1K
1
6
37
Latest learning Blender experiment: I created a corgi and animated it "walking".
2
0
38
Thanks to Aran, I never need to tweet my own papers!
Diffusion Models Beat GANs on Image Synthesis
Achieves 3.85 FID on ImageNet 512×512 and matches BigGAN-deep even with as few as 25 forward passes per sample, all while maintaining better coverage of the distribution.

8
111
612
1
1
37
There are so many parallels between GPU programming and distributed systems design. In both cases, you have to think about synchronization, communication overhead, locality, and parallelism. The only substantial difference is reasoning about hardware failures.
2
4
35
Just wasted a day or two because optimizer.load_state_dict() also resets an optimizer's hyperparameters. I was wondering why all my resumed runs with changed LR and other HPs did not change significantly.
2
0
36



Revived µniverse and trained some of my newer Python agents on it. Satisfying results.

4
2
37
Some fun with inpainting (note the unchanged part of the image).




2
4
36
@marwanmattar
Some of the best ML researchers I've ever met do not have PhDs--or any degree, for that matter. It's your choice as a company how you want to filter candidates, but there are likely better ways.

0
3
35
Noticed this 2018 NeurIPS paper, which doesn't actually train any neural networks. Instead, it learns decision trees with sparse linear SVMs at the branches.
1
0
34
@rasbt
Disclaimer: I was an author on that paper. Yes, diffusion models will really shine for most use cases. GANs might still be better for very narrow domains, but otherwise wouldn't be my first choice.
3
2
34
I sometimes work on small-scale ML projects on vacation. It's always a reminder that you can still have interesting ideas and iterate on them with only a single GPU.
1
0
34