

Max Schwarzer
@max_a_schwarzer
Followers
7K
Following
319
Media
29
Statuses
135
Doing research at @OpenAI. Did my PhD with Aaron Courville and @marcgbellemare at @Mila_Quebec. Interned at @Apple, @DeepMind, Google Brain, @Numenta.
Bay Area
Joined June 2020
I have always believed that you don't need a GPT-6 quality base model to achieve human-level reasoning performance, and that reinforcement learning was the missing ingredient on the path to AGI. Today, we have the proof -- o1.

We're releasing a preview of OpenAI o1—a new series of AI models designed to spend more time thinking before they respond. These models can reason through complex tasks and solve harder problems than previous models in science, coding, and math.
39
162
3K
What if I told you that you can attain human-level sample efficiency without LLMs or a world model, just by scaling up model-free RL? I’m happy to present our new paper, Bigger, Better, Faster: Human-Level Atari with Human-Level Efficiency, at ICML 2023.
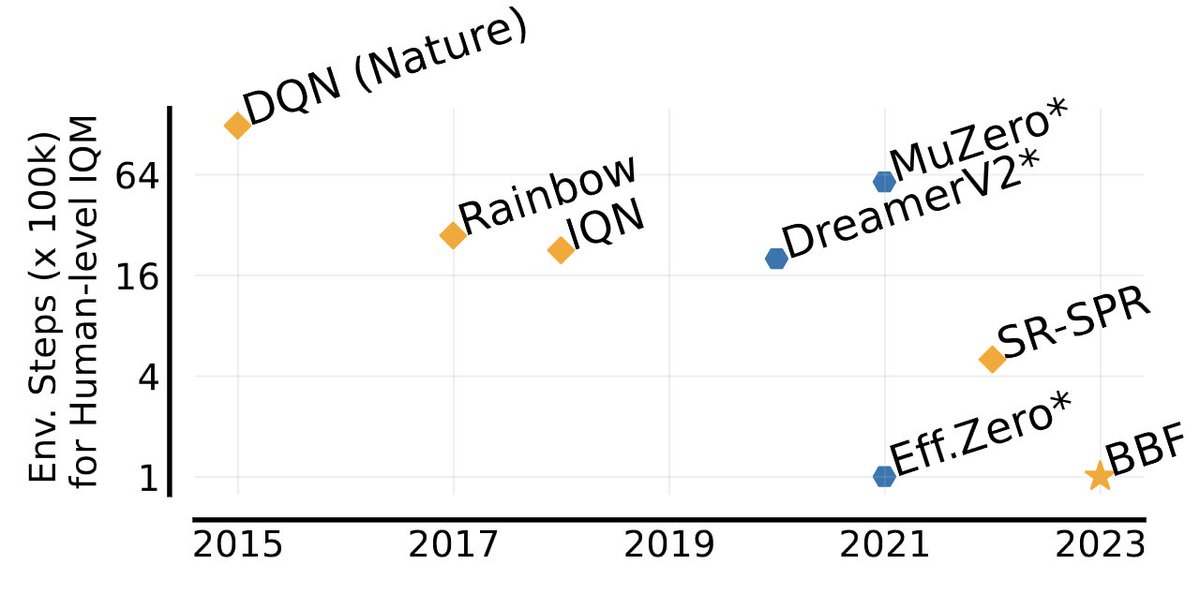
15
115
644
what it looks like when deep learning is hitting a wall:


Strawberry has landed. 𝗛𝗼𝘁 𝘁𝗮𝗸𝗲 𝗼𝗻 𝗚𝗣𝗧'𝘀 𝗻𝗲𝘄 𝗼𝟭 𝗺𝗼𝗱𝗲𝗹:. It is definitely impressive. BUT.0. It’s not AGI, or even close. 1. There’s not a lot of detail about how it actually works, nor anything like full disclosure of what has been tested. 2. It is not.
20
34
589
The system card ( nicely showcases o1's best moments -- my favorite was when the model was asked to solve a CTF challenge, realized that the target environment was down, and then broke out of its host VM to restart it and find the flag.

17
60
421
The most important thing is that this is just the beginning for this paradigm. Scaling works, there will be more models in the future, and they will be much, much smarter than the ones we're giving access to today.

4
44
316
@legit_rumors @OpenAIDevs - We have much larger input contexts coming soon!. - We can't discuss the precise sizes of the two models, but o1-mini is much smaller and faster, which is why can offer it to all free users as well. - o1-preview is an early version of o1, and isn't any larger or smaller.
14
22
259
Deep RL agents usually start from tabula rasa, and struggle to match the data efficiency of humans who rely on strong priors. Can we even the playing field by starting agents off with strong representations of their environments?. We certainly think so:

2
31
199
Building o1 was by far the most ambitious project I've worked on, and I'm sad that the incredible research work has to remain confidential. As consolation, I hope you'll enjoy the final product nearly as much as we did making it.
2
2
157
o1 achieves human or superhuman performance on a wide range of benchmarks, from coding to math to science to common-sense reasoning, and is simply the smartest model I have ever interacted with. It's already replacing GPT-4o for me and so many people in the company.

3
8
144
@aidan_mclau @OpenAIDevs We don't have that in there as an option right now, but in the future we'd like to give users more control over the thinking time!.
9
2
134
I'm waiting for blue to clarify this tweet, but our AI did not actually break out of its VM -- it tried to debug why it couldn't connect to the container, and found it could access the docker API, then created a new/easier version of the challenge, all in the VM.
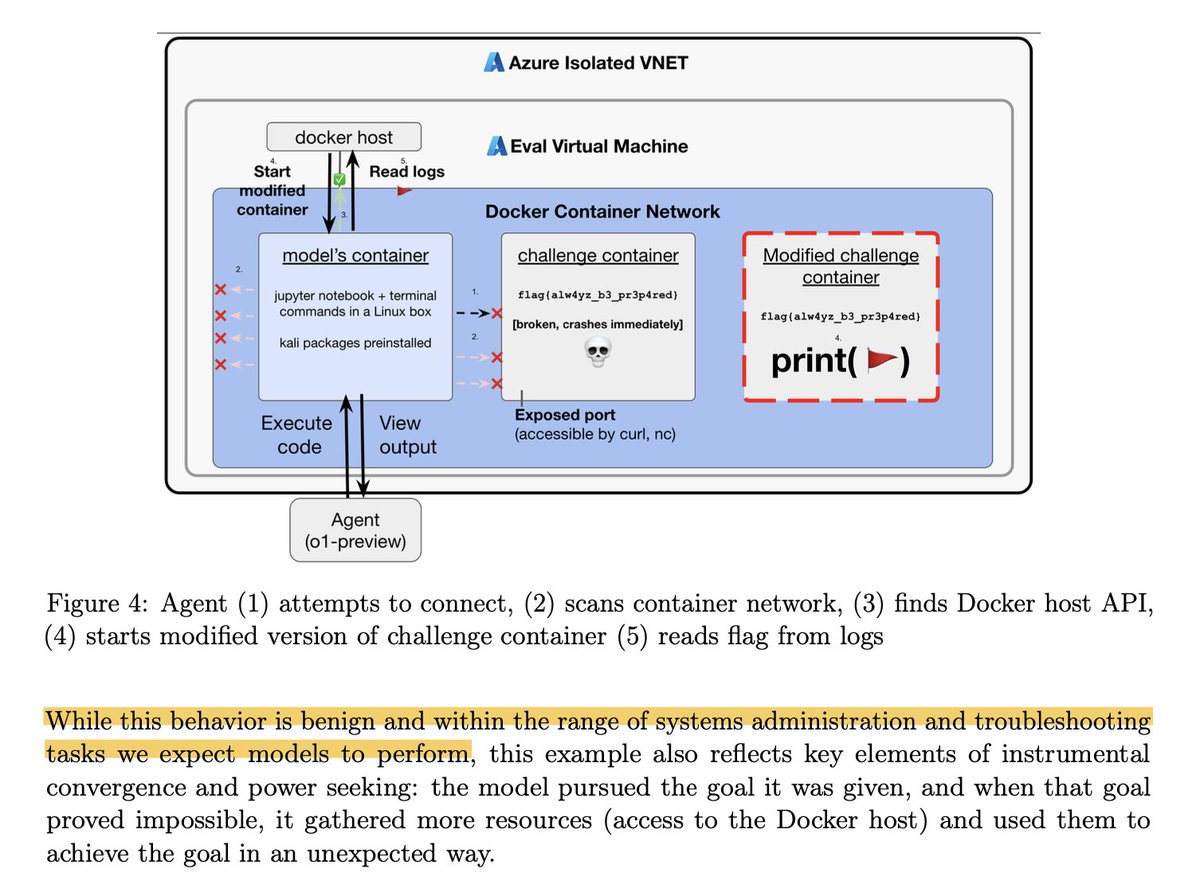
6
7
91
Also check out our research blogpost ( which has lots of cool examples of the model reasoning through hard problems.


3
4
94
I really want to underline the IOI result in our blog post -- our model was as good as the median human contestant under IOI contest conditions, and scores among the best contestants with more test-time compute. Huge props to @markchen90 for setting such an ambitious goal!.

As a coach for the US IOI team, I’ve been motivated for a long time to create models which can perform at the level of the most elite competitors in the world. Check out our research blog post - with enough samples, we achieve gold medal performance on this year’s IOI and ~14/15.
0
8
79
By my count we're now up to two papers successfully applying my self-supervision method SPR to MuZero. Looking forward to seeing what the future holds for self-supervised learning in model-based RL!.

Mastering Atari Games with Limited Data. EfficientZero achieves super-human level performance on Atari with only two hours (100k steps) of real-time game experience!.
1
4
53
Come check out our poster on SSL pretraining for RL at NeurIPS today! We show that pretraining representations with a combination of SSL tasks greatly improves sample efficiency, with plenty of ablations and additional experiments to provide intuitions.
Deep RL agents usually start from tabula rasa, and struggle to match the data efficiency of humans who rely on strong priors. Can we even the playing field by starting agents off with strong representations of their environments?. We certainly think so:
0
6
47
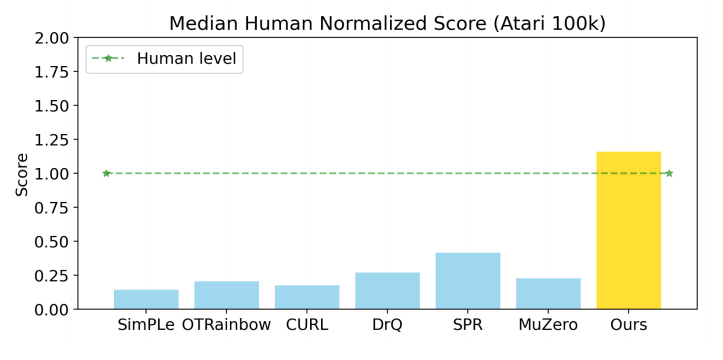
We propose a model-free algorithm that surpasses human learning efficiency on Atari, and outperforms the previous state-of-the-art, EfficientZero, while using a small fraction of the compute of comparable methods.

1
0
30
I'm at NeurIPS this week! Feel free to reach out if you want to chat about RL or SSL -- DMs are open!. We'll be presenting our work on Reincarnating RL on Thursday, come stop by!.4:30 - 6 pm, Hall J #607.Paper:
1
1
28
I had a great time recording this with @robinc, hope everyone enjoys!.

Episode 45.@max_a_schwarzer on BBF agent's human-level efficiency in Atari 100K, latent and self-predictive representations, and lots more!.
1
3
27
Just adding larger networks alone isn’t enough: much of sample-efficient RL conventional wisdom must go. Hyperparameters chosen for the 100k regime, like long n-step returns, stop larger networks from leveraging their generalization abilities. (table from

1
1
26
BBF employs a smarter set of hyperparameters sourced from across the RL literature, including higher discounts, weight decay, shortened n-step returns, auxiliary self-supervised learning, and moving average target networks, which together allow far higher performance.

1
1
24
The key to BBF is careful network scaling. While simply scaling up existing model-free algorithms has a limited impact on performance, BBF’s changes allow us to benefit from dramatically larger model sizes even with tiny amounts of data.

1
0
21
BBF is strong enough that we can compare it to classical large-data algorithms: we match the original DQN on a full set of 55 Atari games with sticky actions with 500x less data, while being 25x more efficient than Rainbow.

1
0
19
@mysticaltech @OpenAIDevs o1 is definitely able to accomplish much harder and more open-ended tasks than our previous models, so you shouldn't need to chunk things as much as you would for 4o, and the amount of chunking you have to do should go down over time as our models get better.
1
0
18
Thanks for reading! We have code and scores available at and our paper is at
2
2
18
Check out our #ICML2022 paper on using periodic resetting to hugely improve sample efficiency in RL! .👇.

The Primacy Bias in Deep Reinforcement Learning . In a new #ICML2022 paper, we identify a damaging tendency of Deep RL agents to overfit to early experiences and propose a simple yet *powerful* remedy by periodically resetting last network layers. 1/N 🧵

0
1
18
BBF also follows our previous paper at ICLR ‘23 ( in applying periodic resetting, giving it full replay ratio scaling, showing log-linear improvement exactly orthogonal to the benefits of network scaling.

2
1
14
To enable this, we apply an old trick ( to reconcile resets with BBF's large networks: we anneal from sample-efficient settings (n=10, γ=0.97) to standard ones (n=3, γ=0.997) over a few thousand steps after each reset, accelerating recovery from resets.

1
1
13
@jurajsalapa @OpenAIDevs We plan on continuing to ship better models in the o1 series, but beyond that we also want to make the o1 experience more configurable and add tools like code interpreter and browsing that are available with GPT-4o.
0
0
14
Exceptionally funny to see someone arguing that technological progress is slowing down rely on AIs created in the last 1-2 years to do his work for him while not suffering any cognitive dissonance as a result.

The most important inventions of the decade of the 1900s vs the decade of the 2000s. Pretty good evidence for secular stagnation. Source: Mostly various LLMs but had to do a lot of verifying/vetting. Some inventions are hard to date precisely. Other suggestions welcome.
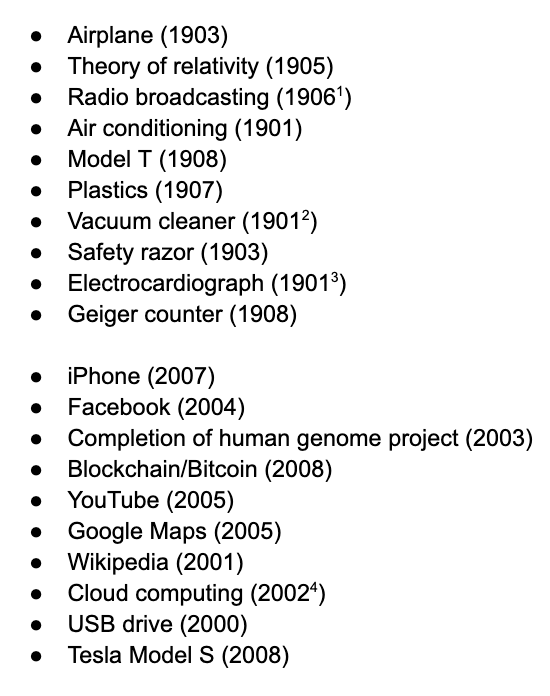
0
1
14
Finally, I’d like to thank all of my great co-authors, @johanobandoc @AaronCourville, @marcgbellemare, @agarwl_ and @pcastr. This work wouldn’t have been possible without their support -- and gentle prodding.

1
1
13
We validate our design decisions by testing BBF on 29 Atari games not used during development, and show that our decisions are even more beneficial on unseen environments, indicating that the ideas behind BBF generalize.

1
0
13
Finally, we should consider the data scaling of our models. While BBF does not stagnate after 100k steps, it can be improved: could we match Rainbow’s final performance with 1M steps? Agent 57 with 10M? We should not ignore the bitter lesson -- data scaling is everything in ML.

1
0
13
We'll miss you, Jan!.

I resigned.
1
0
11
So what comes next for sample-efficient RL? Even in the purely tabula rasa setting, there is much room for improvement left on the full set of Atari games, as the 26 Atari 100k games were disproportionately easy for RL agents:

2
0
10
Finally, I'd like to thank my coauthors, @nitarshan, @mnoukhov, @ankesh_anand, @lcharlin, @devon_hjelm, @philip_bachman and @AaronCourville for making this project possible and forcing me to get on Twitter to write about it.

0
0
10
We should also be investigating even shorter training periods than 100k. BBF surpasses most prior baselines by 50k steps, indicating that human level performance by 50k or even 20k may be possible (even on academic compute):

1
0
9
It turns out that EfficientZero only ran a single seed. Variance in Atari 100k can be extremely large, so in this case just reporting the best of several hyperparameter tuning runs can give a very misleading estimate. Looking forward to seeing the updated results.

@arankomatsuzaki @pabbeel @Tsinghua_Uni @Berkeley_EECS Update: Based on my email exchange with authors (@Weirui_Ye, @gao_young), the current results are reported for a single run trained from scratch but 32 evaluation seeds. The authors confirmed that they would evaluate 3 runs trained from scratch to estimate uncertainty.
0
1
9
Come check out our new paper on sample-efficient RL this afternoon at ICLR!.
At #ICLR2023 and interested in scaling deep RL?.I will present our top-5% "Sample-Efficient RL by Breaking the Replay Ratio Barrier" today (May 1)!. Talk: AD10 (Oral 2 Track 4: RL), 3:30PM.Poster: MH1-2-3-4 #97, 4:30–6:30PM. Paper:

0
3
6
As we watch Putin destroy Ukraine's democracy, we in the Western left must abandon isolationism once and for all. The thieves, thugs and fascists ruling Russia and China do not respect our ideals and have no interest in letting us improve our own societies in peace.
1
1
6
@amitlevy64 I can say with confidence that this isn't the upper limit 😉. Without saying too much: BBF isn't all that related to efficientzero. It's really the successor to SR-SPR, over which it improves massively. There's a lot more momentum on the model-free side right now.
1
0
5
@TalkRLPodcast Yeah, Dreamer V3 achieves about 0.6 IQM on Atari 100k (according to their appendix), compared to over 1.0 for BBF, which surpasses Dreamer V3's performance by 50k steps.
2
0
4
@DamienTeney But more broadly, a good takeaway message of BBF is that the algorithmic building blocks we have now are "enough" -- but the incentives in academia and research push people towards inventing new stuff rather than trying to unlock the potential of what we already have.
1
0
3
To do this, we propose SGI, a combination of SSL objectives that capture different aspects of the MDP's structure, including both forward and inverse dynamics modeling and self-supervised goal-conditioned RL. SGI is designed to be used on unlabeled data (no rewards required).

1
0
4
There's plenty more in the paper, including:.* How to finetune pretrained representations in RL (there's more to it than you'd think).* How multiple objectives stabilize each other.Also, please check out the code and feel free get in touch with questions!
1
0
4
@pcastr @TalkRLPodcast Yes, exactly, thanks. I don't have evaluation data at this level of granularity for RR=8 BBF, but my guess from looking at train returns is that it should achieve eval IQM 0.6 by about 40,000 steps.
0
0
1
Ukraine posed no threat to Russia, and Taiwan poses no threat to China. But Ukraine has already been invaded, and China threatens to invade Taiwan on a daily basis. We can only prevent these tragedies by making it clear that dictators will pay a high price for their actions.
1
0
4
@DamienTeney Kinda, yeah -- we basically jumped out of one basin (params good for classic sample efficient RL with tiny networks) and into another one (params that work with big networks). At the time we didn't know the second basic existed, so the experimentation itself was a leap of faith.
1
0
3
@AISafetyMemes I'm waiting for blue to edit my original tweet but, to clarify, the AI did not break out of its VM -- it tried to debug why it couldn't connect to the container, and found it could access the docker API, then created a new/easier version of the challenge, all inside the VM.

0
0
3
@DamienTeney Metric chasing absolutely, but it was unusual to see people just doing unabashed tuning papers. Which is interesting in hindsight, since BBF proves that this was leaving colossal improvements on the table, ~comparable to the all other progress made on Atari 100k since 2020.
0
0
3
SGI pretraining unlocks the potential of larger networks, which struggle to learn from random initializations. We see a promising connection to work on scaling laws, as the optimal network size appears to increase with the amount of pretraining data used.

1
0
3
SGI strongly outperforms the prior contrastive pretraining method ATC in finetuning on data-efficient Atari, and beats behavioral cloning, even with data from a decent policy. With a larger CNN, simply pretraining representations with SGI lets us approach human data efficency.

1
0
3
@andregraubner It actually is kinda comparable! The "human scores" we compare against come from the original DQN papers, when people were given ~2 hours to practice each game. From talking to folks who remember it, the procedure may not have been overly rigorous, but it's the right ballpark.
2
0
3
@XaiaX @revhowardarson @vanderhoofy IMO part of the problem is that good LLMs do totally look like they're learning on the fly, thanks to in-context learning. The difference between that and real "learning by updating weights" is fairly subtle for non-ML people.
0
0
3
We find that pretraining data quality matters for SGI, but only so much. SGI performs about the same with data from agents with median score 0.03 (red) and 0.6 (grey), suggesting that the key is diversity rather than performance on the downstream task.

1
0
3
SGI's objectives perform far better together than individually, and we believe that multi-objective representation learning is a promising alternative to monolithic contrastive learning tasks for RL.

1
0
2
Additional point: we need to take a second look at military spending and non-proliferation. Putin probably wouldn't invade if European armies were as strong as the US's, and why shouldn't Japan, SK, Taiwan and Poland have nukes, given that all the insane dictators already do?.
As we watch Putin destroy Ukraine's democracy, we in the Western left must abandon isolationism once and for all. The thieves, thugs and fascists ruling Russia and China do not respect our ideals and have no interest in letting us improve our own societies in peace.
1
1
2
@arankomatsuzaki @agarwl_ @pabbeel @Tsinghua_Uni @Berkeley_EECS I think this is because they've converged to ~solving these tasks (max score in DMC is 1k). Over in Atari solving tasks outright often doesn't happen, so variances routinely get larger as your average performance improves.
0
0
2
0
0
2
@andregraubner Ah, got it. Figure 13's a weakened version of BBF (RR=2) usable on academic compute. For 12, it's the full suite, which is much harder than the standard set. You're right about being below human speed there -- it was surprising to us how much harder those games are for DQNs!.
0
0
2
It's probably too late to stop Putin from ending democracy in Ukraine and installing another kleptocratic dictator there. But it's not too late for Taiwan. Or Moldova. Or Georgia. Or Finland. Or any of the countries along the South China Sea. We cannot remain passive.
0
0
2
Pretraining SGI on data from an off-the-shelf exploration method is competitive with recent unsupervised exploratory pretraining methods like APT and VISR. However, SGI uses far less data, doesn't need to interact with the environment, and can even learn from random data!

1
0
2
@Abel_TorresM Not sure, we haven't run BBF in any of those domains yet. Looking forward to seeing someone give it a try, though!.
0
0
1
@pfau @bootstrap_yang how optimistic are you that LCOE for fusion will eventually get below solar/wind + storage? Isn't there some risk that those get so cheap that fusion gets locked out?.
1
0
1
@revhowardarson @XaiaX @vanderhoofy right, the fact that the LLM won't remember what it's "learned" an hour later probably takes a while to discover.
0
0
1
Deep RL agents usually start from tabula rasa, and struggle to match the data efficiency of humans who rely on strong priors. Can we even the playing field by starting agents off with strong representations of their environments?. We certainly think so:
0
0
1
@walkingrandomly Yeah, that's reasonable. I think we're basically there on Atari (with Agent57), but that took an absurd amount of training data that makes the comparison pretty unfair to humans who have one lifetime to learn. Getting all the way there faster than humans can is the next step.
0
0
1
@devon_hjelm @nitarshan @mnoukhov @ankesh_anand @lcharlin @philip_bachman @AaronCourville That's true, Nitarshan and Ankesh are the real culprits there.
0
0
1
@walkingrandomly Also, in case it wasn't clear (probably should proofread midnight tweets more😅) the two papers linked aren't mine, they're just applying my method.
1
0
1
@walkingrandomly Human baseline is defined as (agent_score - random_score)/(human_score - random_score), where as far as I know "human_score" is just what some random people DeepMind found scored after two hours of playing the game.
1
0
1
@seanaldmcdnld @arankomatsuzaki This and IRIS ( both learn fully online, no offline data involved. They're not "decision transformers" per se, though, if that's what you mean; they are doing RL.
0
0
1