

Jakob Foerster
@j_foerst
Followers
19K
Following
2K
Media
136
Statuses
2K
Assoc Prof in ML @UniofOxford @StAnnesCollege @FLAIR_Ox/ RS @MetaAI, 2x dad. Ex: (A)PM @Google, DivStrat @GS, ex intern: @GoogleDeepmind, @GoogleBrain, @OpenAI
Joined November 2012
I drafted a quick "How to" guide for writing ML papers. I hope this will be useful (if a little late!) for #NeurIPS2022. Happy paper writing and best of luck!!.
27
292
1K
When I discussed quitting Google to do a Phd, my manager, Steve Cheng, gave me the advice of "6 shots": Doing something meaningful usually takes about 5 years and we are productive for roughly 30 years. That gives you 6 attempts. So pick each one carefully and give it your best.
138
2K
22K
At the meta level, looking back I think it's mindboggling how much positive impact a few minutes of good advice can have. Giving (and listening) to life advice is one of the highest ROI activities ever.
8
65
2K
Currently Deep RL is going through an imagenet moment and very few people are aware. This has major implications for RL applications and anyone interested in modeling behaviour (e.g. Econ and neuroscience). To find out more watch my recent talk @ICML2024:
17
120
862
Cold emails are hard and good ones can change a life. Here is my email to @NandoDF that started my career in ML (at the time I was a PM at Google) Real effort (incl feedback) went into drafting it. Thanks to @EugeneVinitsky for nudging me to put it online.
16
64
755
My group at Oxford (@FLAIR_Ox) is talent rich but GPU poor (both compared to industry), so adding more GPUs would be a win for open science, but is difficult to finance from grants. Does anyone have leads for possible donors? Christmas is coming up so I guess I am allow to dream

48
28
586
The gradient is a locally greedy direction. Where do you get if you follow the eigenvectors of the Hessian instead? Our new paper, “Ridge Rider” (, explores how to do this and what happens in a variety of (toy) problems (if you dare to do so),. Thread 1/N

4
71
570
LLMs are finally catching up to deep RL - we have been training on test from long before it was cool.
14
47
539
Excited to be starting as an Assistant Prof (👨🎓!!) at the @UofT (Scarborough Campus) w/ appointment at the @VectorInst in September of 2020. I am looking for exceptional Master/PhD students and Postdocs to be starting with me next fall. Till then, . .
58
35
531


unpopular opinion: ML conferences should charge $100 per submission. For accepted papers this would count towards the registration fee of the attending author, so it's free. Extra funds collected could be used eg. for replication studies or other improvement to the review process.
42
8
398
@tosinolaseinde @MuyiwaSaka I quit and did the PhD. One of the best decisions. Have used this framework since as well for other big decisions.
7
5
389
Personal update: I just started as an Associate Prof in the engineering department @UniofOxford (and Tutorial Fellow @StAnnesCollege). It’s an incredible honour to return to this beautiful city and to have the chance to work with brilliant, friendly colleagues and students. .
23
12
376
Waymo car failing to coordinate w/ another Waymo (credits in the comment). Interesting to see a toy example from my grant applications play out in the real world. Two cars playing a best-response to a human driver model are not mutually compatible, multi-agent challenges are real
10
30
362
Dear Reviewer: I don't really mind that you gave a low score because you had a suggestion for simplifying our method. I do mind that you evidently didn't read our rebuttal, where we tried your idea, showed that it doesn't work and explain why. We can all do better. Thanks a lot.
3
8
336
The field used to be 30 years behind Jürgen's ideas, now we have reduced the collective lag to 8 years thanks to OpenAl. If you extrapolate we might catch up by 2027. Singularity is near?.

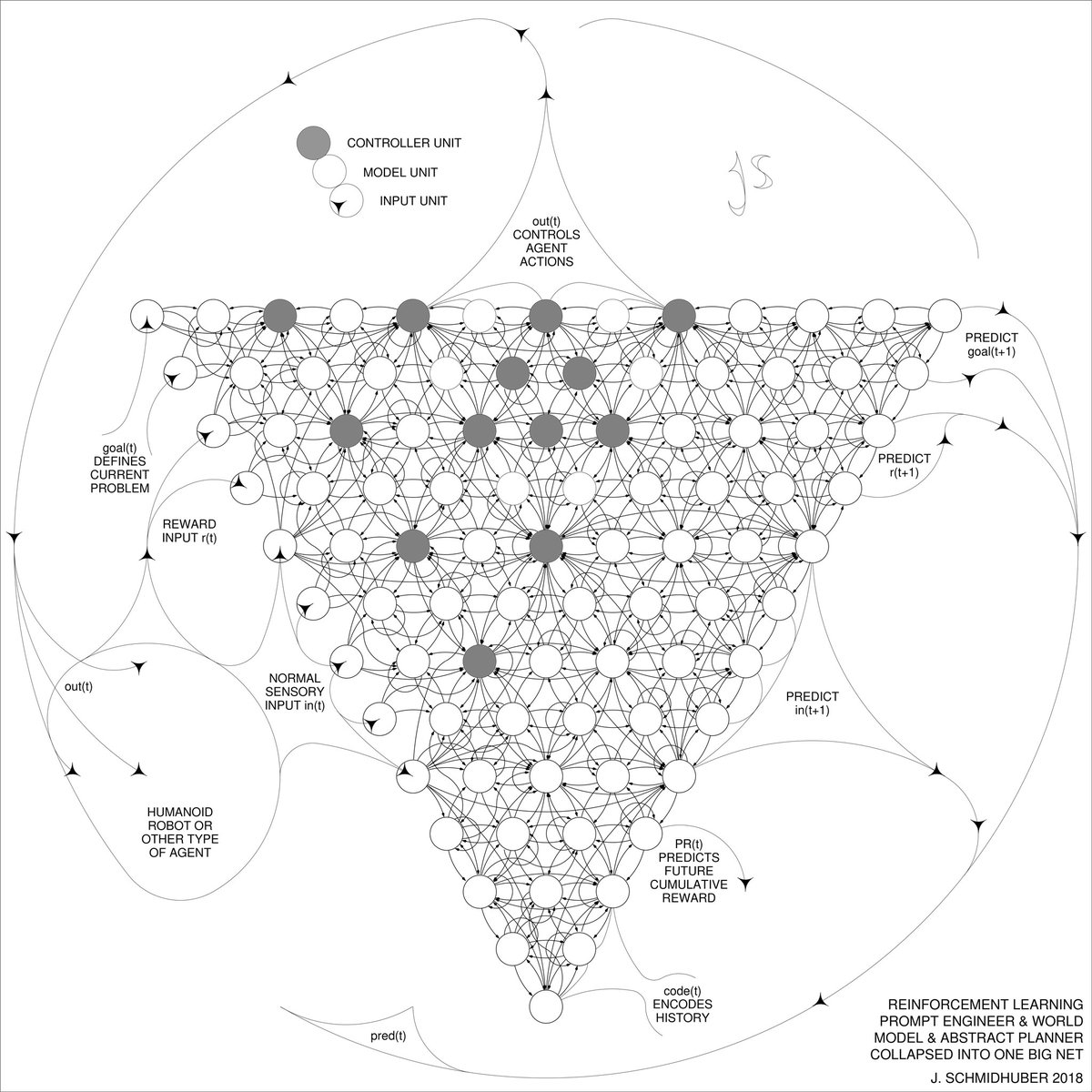
Q*? 2015: reinforcement learning prompt engineer in Sec. 5.3 of “Learning to Think. ” A controller neural network C learns to send prompt sequences into a world model M (e.g., a foundation model) trained on, say, videos of actors. C also learns to
8
19
295
If I was @sundarpichai I would try to buy @perplexity_ai, urgently. Best time was a year ago, second best time is now. It's not good to be the second best product on the market in an area that's 90% (?) of your profit. .
32
12
251
Excited to share "DiCE: The Infinitely Differentiable Monte Carlo Estimator": Try this one weird objective for correct any-order gradient estimators in all your stochastic graphs ;) With fantastic Oxford/CMU team: @greg_far @alshedivat @_rockt @shimon8282


3
75
236
Joao Henriques ( and I are hiring a fully funded PhD student (UK/international) for the FAIR-Oxford program. The student will spend 50% of their time .@UniofOxford and 50% @AIatMeta (FAIR), while completing a DPhil (Oxford PhD). Deadline: 2nd of Dec AOE!!.
3
46
240
This is been an amazing journey that many of you have been part of. A true multi-agent endeavour 🤖😎 🤖😃🤖!! Huge thanks to the collaborators, friends, and institutions that made this possible. Yours sincerely, Dr. Foerster (still getting used to it. ).

Huge congratulations to Dr. Jakob Foerster (@j_foerst) who successfully defended his PhD thesis "Deep Multi-Agent Reinforcement Learning" this week! 🎉🤓🎲🎓

16
6
204
Can an agent learn to optimise an MDP, while simultaneously encoding secret messages in its actions? Our ICML 2022 paper “Communicating via Markov Decision Processes” ( shows: yes, indeed! @casdewitt, @MaxiIgl, @luisa_zintgraf, @zicokolter, @shimon8282 🧵
7
32
190
RL has always been the future and the future is now. Having an open-source version released _before_ major closed-source labs managed to rediscover this internally (as far as I know) is amazing.

So @karthikv792 checked out @deepseek_ai's R1 LRM on PlanBench (--and found that it is very much competitive with o1 (preview), but at a fraction of the cost. The fact that it is open source and doesn't hide its intermediate tokens opens up a rich avenue.
9
10
193
Thesis is online. Sorry for the delay & enjoy! Huge thanks to everyone involved in this multi-agent endeavor! 👨🎓👨🎓👨🎓. 🤖🤖.
5
19
169
Our practitioners guide for turning RL into a differentiable loss function with any order gradients is now available as a blog post with code examples. Huge thanks to @y0b1byte for pushing this!.
We have a new blog post! Using higher-order gradients in your research? Working on Meta-Learning in RL? . Learn about DiCE, an objective for correct any-order gradient estimators in stochastic graphs! 🤓🎲.

2
54
163
I am extremely grateful to my wonderful collaborators across different institutions and timezones who helped sharpen my thinking about coordination problems from a principled pov. This #ERCStG is an exciting next step towards machines that work smoothly and safely w/ humans 🤖+👤.

Professor Jakob Foerster has been awarded a 2.3m Euro, 5-year @ERC_Research starting grant to develop foundational #machinelearning algorithms for human-AI coordination in complex settings such as situations where humans & robots work alongside each other

27
5
161
Currently very little credit goes to the reviewers ('critics') compared to the authors ('generators'). As technology makes it easier and easier to generate ML papers, that balance needs to swift radically. Once it's easy to generate all papers, judging the good ones is the work.
18
8
154
Today I was approached by an expert in the area of competitive games who shared their concerns about this work with me. Since I believe this feedback will be useful for the community and understand they like to protect their anonymity I am sharing it below 0/N.

Even superhuman RL agents can be exploited by adversarial policies. In we train an adversary that wins 99% of games against KataGo 🖥️ set to top-100 European strength. Below our adversary 😈=⚫ plays a surprising strategy that tricks 🖥️=⚪ into losing.🧵

2
16
157
PSA: As scientists we spend a lot of time in meetings, but typically don't get much guidance (if any) on how to make them effective. Here are a few best practices around note-keeping I adopted for research meetings (incl. supervision etc.) from my time as a product manager:1/6.
1
17
156
It's time for ML academia to cut the cord/ our reliance on big tech. @NeurIPS and other ML conferences need to commit to and require open, reproducible science, rather than falling for PR gigs and product placements disguised as science. For better or worse the honeymoon is over.

The panel discussion at @NeurIPSConf about LLMs and beyond has just featured three panelists who were not willing to speak about the details of their work. It's secret stuff. Is this appropriate at a scientific conference?.
6
17
155
Google invented the transformer and legacy auto developed the technology for early EVs. Both entities are now in "code red". Does anyone know other examples of this pattern? Also, it should have a name!.
40
8
144
If you are disappointed/sad about @NeurIPSConf reviews, remember: a) Reviews are extremely noisy b) A good rebuttal can work magic c) Rejected papers have become best papers d) Look out for actionable insights, even if you disagree w/ score e) you may have been fortunate so far.
1
7
142
BBC headline: "Robot hand solves Rubik’s cube, but not the grand challenge". Also: ". OpenAI’s research paper was not peer-reviewed." Reporting on AI progress seems to be getting a lot more nuanced/accurate recently, a step in the right direction!(from:.
1
7
140
Scientific progress is one of humanity's most impressive and impactful intellectual achievements. We introduce The AI Scientist, the first AI to carry out end-to-end science, from ideation to implementation, data analysis, struggling w/ latex, reviewing and iterative improvement!.

Introducing The AI Scientist: The world’s first AI system for automating scientific research and open-ended discovery!. From ideation, writing code, running experiments and summarizing results, to writing entire papers and conducting peer-review, The AI




10
13
131
Diffusion models have revolutionised a number of areas in ML, now they are coming for offline RL. In our paper we guide the samples to be closer to our current policy, reducing the off-policy-ness of the generated data. This will unlock novel world applications of off-policy RL.

Come check out a sneak peek of our work **Policy-Guided Diffusion** today at the NeurIPS Workshop on Robot Learning!. Using offline data, we generate entire trajectories that are:.✅ On-policy,.✅ Without compounding error,.✅ Without model pessimism!

4
19
134
flying back from #NeurIPS2024: Academia and open-source are starting to "feel the AGI". if we coordinate better, we have magnitudes more brain power and creativity than all of the closed labs. new coordination tools also help prepare for and align AGI. win-win. 🧵.
3
9
123
Diffusion is an extremely powerful and general purpose approach - here we combine it with _policy guidance_ to improve the distribution mismatch in offline RL, which in turn offers the chance to bring RL to the real world without having to collect online data.
🎮 Introducing the new and improved Policy-Guided Diffusion!. Vastly more accurate trajectory generation than autoregressive models, with strong gains in offline RL performance!. Plus a ton of new theory and results since our NeurIPS workshop paper. Check it out ⤵️
0
12
115
The research on Hanabi just got a lot more exciting - today we are adding search to the mix, vastly improving upon the previous SOTA 🎆🎇🤖.We are open-sourcing all code, incl. a new RL method and trained agents. A cooperative effort with @adamlerer, Hengyuan Hu, @polynoamial.

To advance research on AI that can understand others’ points of view and collaborate effectively, Facebook AI has developed a bot that sets a new state of the art in Hanabi, a card game in which all players work together.
1
18
114
I am going on the record with this - when I grow up, I want to be like Geoff.

“I'd also like to acknowledge my students (…) they've gone on to do many great things. I'm particularly proud of the fact that one of my students fired Sam Altman.“. 😳🫡
1
2
115

Moving JAX has been a huge change (i.e. 1000x speedup) for our RL work at @FLAIR_Ox, it's really exciting to see Google Brain following suit here!! See our purejax library for sota implementations:

Introducing MuJoCo 3.0: a major new release of our fast, powerful and open source tool for robotics research. 🤖. 📈 GPU & TPU acceleration through #JAX.🖼️ Better simulation of more diverse objects - like clothes, screws, gears and donuts.💡 Find out more:
4
10
99
When you wonder whether your WiFi isn't working because #Gmail, #Youtube and #GoogleDrive aren't responding. #Googledown?.
3
4
96
How do you explain LLMs to the younger generation? @UniofOxford asked me to produce a 90s explainer, targeted at a TikTok audience. I don't use TioTok, but here is my attempt - feedback welcome and happy holidays!.

EXPLAINED: What is an LLM? 🤔. Associate Prof @j_foerst shares everything you need to know about LLM (large language model) in 90 seconds. #OxfordAI
1
5
93
I am looking for an acronym for "Good Old Fashioned Machine Learning", i.e. supervised/RL systems etc that are trained for and good at a specific set of task and definitely know nothing about everything else (which is quite comforting). "GOFML" doesn't really roll off the tongue.
44
10
93
Moving beyond self-play: Communication, cooperation and coordination with humans and other AI systems zero-shot is one of the exciting frontiers of multi-agent learning. "Other-Play" is an exciting step is this direction! Thanks to a team of fantastic collaborators 🎇🎇🤖🙎♀️🎇🤖!.

How can we learn policies that can coordinate w/ humans (w/o human data)? 'Other-Play' (w/ @adamlerer @alex_peys @j_foerst) uses symmetries to avoid 'over-coordinating' during training. Final policies coordinate better w/ humans and bots in Hanabi🎇🙎♀️🤖🎇!

1
13
96
I am honoured to have been awarded an Amazon Research Award for our proposal "Compute-only Scaling of Large Language Models" (i.e. Q* before it was cool!). Thanks to @AmazonScience and to my amazing students @clockwk7 & @JonnyCoook!. #AmazonResearchAwards.
10
8
96
You think you understand why popular algorithms like PPO work? So did we @FLAIR_Ox, but then we “reflected” deeply upon it ;) Check out our @ICMLconf 2022 paper “Mirror Learning: A Unifying Framework of Policy Optimisation” ( w/ @kuba_AI, @casdewitt 1/N

2
16
92
Great to see activity on our short #HowToMLrebuttal guide -- good luck with #NeurIPS2023 rebuttals! .@HowTo_ML

2
18
93

En route to #neurips2024 after traveling to Germany so that my wonderful in-laws can help take care of our two-under-two. 2024 has felt accelerated, both at the personal and professional level. Personally, our second son was born, professionally I went 50/50 with FAIR @AIatMeta🧵.
3
2
88
Wow - @CompSciOxford is looking to hire not 1,2 or 3 but 4 (!) professors in CS:. This is unprecedented (and weirdly timely. !) It's a fantastic department and (you get to collaborate with @oxengsci ;) I highly recommend applying. Deadline is 14th of Dec⏰

0
25
85
PS: Did he reply? No -- he was not taking students at the time. But, he did forward it to @shimon8282, then incoming faculty to Oxford, and the rest is history. .
3
1
88
GenAI is changing the world but struggles with decision making/ taking actions. We push towards a foundation model for 2D control using #RLatTheHyperscale and show both zero-shot generalisation and fast fine-tuning!! All code is open source and you can be the agent!.

We are very excited to announce Kinetix: an open-ended universe of physics-based tasks for RL!. We use Kinetix to train a general agent on millions of randomly generated physics problems and show that this agent generalises to unseen handmade environments. 1/🧵
3
11
85
Dear reviewers, please engage. Dear ACs, please remind the reviewers to engage. Thank you everyone!.
2
6
85
🎲Alea iacta est 🎲I am attending my first @NeurIPSConf conference since pre-covid! Super excited to see old friends and make new ones :) I'll be around from the 12th to the 16th, so come find me if you'd like to chat. Oh, and pack your running shoes + gloves. #runconference.
6
0
87
"Complete proofs are in the appendix" (silently crosses fingers).
1
2
85

DQN kick-started the field of deep RL 12 years ago, but Q-learning has recently taken a backseat compared to PPO and other on-policy method. We introduce PQN, a greatly simplified version of DQN which is highly GPU compatible and theoretically supported by convergence proofs.

🚀 We're very excited to introduce Parallelised Q-Network (PQN), the result of an effort to bring Q-Learning into the world of pure-GPU training based on JAX!. What’s the issue? Pure-GPU training can accelerate RL by orders of magnitude. However, Q-Learning heavily relies on

1
8
83
❤️JAX meets multi-agent RL, a match made in heaven❤️ This would have made so many things faster and easier in my life. Can't wait to see the amazing things that people will build on this using _academic compute_. The frontier of the open-world just moved by orders of magnitude 🤯.

Crazy times. Anyways, excited to unveil JaxMARL! JaxMARL provides popular Multi-Agent RL environments and algorithms in pure JAX, enabling an end-to-end training speed up of up to 12,500x!. Co-led w/ @alexrutherford0 @benjamin_ellis3 @MatteoGallici. Post:

1
7
80
@animesh_garg great pointer. Personally I'd be happy for _one_ of these long shots to _really_ land. But even that's a high bar. !.
1
0
80
Agents learn to communicate by considering beliefs of others🤖📞🤖! Provides a way of exploring in the space of compatible encoders and decoders, getting around the "local minimum" problem of learning communication protocols. Huge thanks to a team of fantastic collaborators!🙏🙏.
Bayesian Action Decoder (: A new multi-agent RL method for learning to communicate via informative actions using ToM-like reasoning. Achieves the best known score for 2 players on the challenging #hanabigame.
1
24
76
This is a fundamental shift regarding the RL capabilities of academic research labs. At @FLAIR_Ox we have now done a number of projects on single digit GPUs that would have taken entire data centre to run using prior approaches. 4000x speed-up is quite a big deal, it turns out 🚀.
1/ 🚀 Presenting PureJaxRL: A game-changing approach to Deep Reinforcement Learning! We achieve over 4000x training speedups in RL by vectorizing agent training on GPUs with concise, accessible code. Blog post: 🧵

3
5
79
I watched Ex-Machina a few years ago. Looking back, the most unrealistic part of the movie is how much effort the scientists put into physically _isolating and containing_ the AI. Clearly they hadn't realised they can increase stock prises by just unleashing it on humanity ASAP.
2
1
76
Amazing @PyTorch implementation of our 2016 "Learning to Communicate with Deep MARL" paper. DIAL and RIAL for the win!! Goodbye, @TorchML and welcome to 2018 :) .Also, the deadline for our NIPS emergent communication workshop is in 8 days - perfect timing. .

If you're interested in teaching deep reinforcement-learning agents to communicate with each other, check out my open-source PyTorch implementation of the classic RIAL and DIAL models by @j_foerst, @iassael, @NandoDF, and @shimon8282:
2
23
75
Are you looking for an RL environment that is: 1) blazing fast 2) open-ended 3) language enabled 4) easy enough to get started on and 5) super fun to play? Your wish has been fulfilled! The only thing that's missing is the multi-agent extension :).
I’m excited to announce Craftax, a new benchmark for open-ended RL!. ⚔️ Extends the popular Crafter benchmark with Nethack-like dungeons.⚡Implemented entirely in Jax, achieving speedups of over 100x.1/
3
8
75
Second session of the #runconference 🏃♂️ at #ICML2022 was a great success (photos below credit to @pcastr). For anyone who didn't make it today, we'll meet again tomorrow at 8am in front of the hilton.


4
2
73
How can we train RL agents that act optimally, *without* sharing any information between them through emergent conventions? "Off-Belief Learning" finally solves this! It takes the weirdness out of learning in Dec-POMDPs and is a huge leap for human-AI coordination & AI safety🤖🧑🔧.
How can AI agents discover human-compatible policies *without requiring human data*?.An important step is to develop meaningful, interpretable conventions for communicating information, rather than relying on arbitrary encodings. (1).
2
13
73
Meta-learning is great, but what distribution of environments shall we train over to enable generalization?.And wouldn't curriculum discovery for meta-learning be too compute intensive for a lab in academia? Curious? Then this is for you!.
Meta-learned policy optimizers have shown incredible generalization, e.g. Grid-World to Atari games. But how do we discover training environments for truly general-purpose optimizers?. I'm excited to announce our #NeurIPS2023 work studying this question!

2
12
72
General-sum games describe many scenarios, from negotiations to autonomous driving. How should an AI act in the presence of other learning agents? Our @icmlconf 2022 paper, “Model-Free Opponent Shaping”(M-FOS) approaches this as a meta-game. @_chris_lu_ @TimonWilli @casdewitt 🧵
1
14
72

How can RL agents discover policies that can coordinate w/ humans w/o using human data? Why do we have to think beyond self-play and seriously consider Zero-Shot coordination? New (and improved??) 30min video on what I think is an exciting frontier for AI!
2
7
72
There's something exciting happening for MARL on Monday. Stay tuned.
4
8
70
I twice left big tech for academia. Both decisions were hard but also life changing and amongst the best decisions I have taken. If you are thinking of leaving tech, my advice is to keep your standard of living in check. If you get used to the paycheck, you are trapped.

See - more evidence from @ericjang11 that more years in big tech or wherever if you want to do a startup isn’t really a great idea - you should just take the jump :-)

4
1
69
Ok, it's been 24h so it's time for a resolution: This is a real video recorded by me. The fact that we genuinely can't tell whether this is real or not is really bothersome. Lastly, the audio and *Super-Human* tic-tac-toe (not a thing) were supposed to be little hints / giveaway.
8
4
67
Stay safe, stay healthy, stay home. The exponential is coming for us.
1
9
68
Are you looking for the "best of both worlds" between academia and industry for your PhD? If so, this is your chance! We have *one fully funded position*, 50% FAIR (w/ @egrefen) and 50% with me at @oxengsci to work on generalisation. Application deadline is coming up in 1 week!.

🧵THREAD 🧵.Are you looking to do a 4 year Industry/Academia PhD? I am looking for 1 student to pioneer our new FAIR-Oxford PhD programme, spending 50% if their time at @UniofOxford, and 50% at @facebookai (FAIR) while completing a DPhil (Oxford PhD). Interested? Read on… 1/9.
0
11
68
Hello again! Prof. Ani Calinescu (@CompSciOxford) and I are honoured to have been awarded the @jpmorgan @Chase Faculty Research Awards for "Unleashing the power of JAX-based models of Limit Order Books" the JAX-🚆 is at full speed! 🙏 to students @nagy_peer, Sascha Frey, Kang Li!.
5
1
68
Dear Reviewer: Sometimes we all fail to review a paper carefully and miss something crucial. Very unfortunate, but it happens. Sometimes this will lead us to initially reject a paper for invalid reasons, it happens. *Never* can we ignore the rebuttal that points out our mistake.
0
2
67
The rumours are true! I will not be attending @NeurIPSConf due to teaching/tutoring obligations in Oxford (an "off by one week" issue). I will miss catching up/meeting all you :( If you are interested in @FLAIR_Ox pls say hello to our students and collaborators who present. :1/N.
4
10
68
I am sorry for everyone who got fired from big tech recently and hope they are well, this sucks and is unnecessary :( I am also excited to see what 100s of thousands of brilliant people will do now that they are no longer forced to change font sizes/ optimise click-through rates.
1
1
64
Still looking for the _perfect_ phd position in ML (at Oxford)? .Then this might be for you: Deadline is this Friday at noon UK time, i.e. in ~48 hours at the time of posting.
7
13
65
I am recruiting for a _fully funded_ (overseas or UK) Phd student to start in October 2025. All details in the post below, deadline is coming up 29th of Jan!.
2
6
64
When I submitted our "Compute only Scaling" grant (using RL to improve chain-of-thought reasoning) a year ago, little did I know we were _almost_ on track to scoop OpenAI!.
I am honoured to have been awarded an Amazon Research Award for our proposal "Compute-only Scaling of Large Language Models" (i.e. Q* before it was cool!). Thanks to @AmazonScience and to my amazing students @clockwk7 & @JonnyCoook!. #AmazonResearchAwards.
1
0
63
Next time you write a cold email to a scientist, try nerd sniping them ( Many good scientists _love_ interesting problems.
2
6
62




I used to switch fields/roles whenever my learning curve flattens (usually every few years) but haven’t felt that need for a while. Either I have gotten lazy or I have finally found a field that’s changing fast enough to keep me entertained / giving me a lot to learn all the time.
7
2
60
@herbiebradley this misses how long individuals had been working on the underlying problem. E.g. David Silver had been trying to crack games for a decade before alpha go.
2
0
61
Exciting times ahead!.

#UofT and @VectorInst announce the recruitment of two rising stars in machine learning research. See you in 2020 @cjmaddison.and @j_foerst. And congratulations to the newest U of T faculty appointed at Vector, including new hire @animesh_garg .
0
0
62
Hanabi has been keeping a bunch of us busy for a while, and I have a feeling we are still at the very beginning of that journey. Join us today to start writing the next chapter of #MultiAgentLearning and #theoryofmind! Proudly introducing the #HanabiLearningEnvironment 🤖😃🤖🎆🧨.

We're open-sourcing a multiagent environment based on the highly popular card game Hanabi, & an agent based on the Dopamine framework! w/ @j_foerst @MichaelHBowling @nolanbard @hugo_larochelle @apsarathchandar & al. Here's a short post about the project:
0
8
59
The 4th (!!!) edition of the @NeurIPSConf Emergent Communication workshop is now open for submissions! This year's topic is 'Talking to Strangers: Zero-Shot Emergent Communication', bringing together two of the (perhaps) most exciting/vibrant frontiers of AI research! 🤖📣💁📢👽.

Submissions are open for Emergent Communication @ NeurIPS 2020 🥳 @filangelos @aggielaz @j_foerst @backpropper @mnoukhov @BullardKalesha.
0
12
60

As we move research online, serendipitous conversations (" water-cooler chats") often disappear, yet they are so crucial for creativity. How do we create opportunities for these, without having the overhead and expectations of a scheduled meeting? Please share what worked/didn't.
4
6
58
I think this is quite an important point. Science needs to be transparent and reproducible. GPT4 is a closed system, so studying it (or using it) from the outside is not science. As an ML community we should be clear on this. It's interesting and it might be fun, but it's not ML.

Scientific work which cannot be replicated is failed scientific work. Work using closed methods that don't even allow the possibility of replication should be treated as marketing rather than science. Scientists who publish said work should have their reputations suffer.
4
2
56