

Minqi Jiang
@MinqiJiang
Followers
3K
Following
7K
Media
84
Statuses
802
Autocurricula can produce more general agents. but can be expensive to run 💸. Today, we're releasing minimax, a JAX library for RL autocurricula with 120x faster baselines. Runs that took 1 week now take < 3 hours. Paper:
6
85
462
🧬 For ACCEL, we made an interactive paper to accompany the typical PDF we all know and love. "Figure 1" is a demo that lets you challenge our agents by designing your own environments! Now you can also view agents from many training runs simultaneously.
2
51
234
I'm stoked to have joined @GoogleDeepMind, where I'm working with @egrefen, @SianGooding, and others (not on here) to create helpful, open-ended agents. I'll also be at NeurIPS next week. Feel free to reach out if you want to chat open-ended learning or PhDs @UCL_DARK!.
34
12
231
We have open sourced our recent algorithms for Unsupervised Environment Design! These algorithms produce adaptive curricula that result in robust RL agents. This codebase includes our implementations of ACCEL, Robust PLR, and PAIRED.
1
41
210
Scam alert: TIL the researcher who plagiarized my work did the same on all 3 of his other papers (all in 2022). He takes a published algorithm, makes a tiny, inconsequential modification, and presents it as if it were the original. When people said AI was the new web3. 📄📄📈😵.
12
10
175
RL trains agents to solve environments. Unsupervised Environment Design instead "trains" environments to induce better agents. PAIRED elegantly formulates this as a multi-agent game, and now you can join the fun: I'm happy to share PAIRED in PyTorch 🔥.
3
38
176
Excited to share Prioritized Level Replay: a simple + effective way to improve generalization and sample efficiency of deep RL agents in procedurally-generated environments, where layout and dynamics can differ per episode. We call these variations "levels."

1
36
156
Playing with stable diffusion. Like Codex/Copilot, much more an assistant than a replacement to human creators. It can't generate things perfectly from scratch and needs lots of guidance from the artist, eg img masks + prompts. Innovating the "Contextual Input UI" is key.
4
12
155
Pleased to announce that our paper on Prioritized Level Replay (PLR) provides a new state-of-the-art on @OpenAI Procgen, attaining over 70% gains in test returns over plain PPO. Paper: Code: A quick thread on how this works.

3
39
155
Very happy to say I passed my PhD viva last night. I'm deeply grateful to my advisors @_rockt and @egrefen for their mentorship thru the years, and for giving me nearly limitless freedom to pursue the ideas that interested me. A once in a lifetime opportunity. Thank you!.

Congratulations Dr @MinqiJiang! @_rockt and I are so proud of the first PhD graduate from @UCL_DARK 🥰

21
5
156
🏎️ Replay-Guided Adversarial Environment Design. Prioritized Level Replay (PLR) is secretly a form of unsupervised environment design. This leads to new theory improving PLR + impressive zero-shot transfer, like driving the Nürburgring Grand Prix. paper:
5
22
129
Delighted to introduce WordCraft, a fast, text-based environment based on @AlchemyGame to enable rapid experimental iteration on new RL methods using commonsense knowledge. Work done with amazing collaborators: @jelennal_, @nntsn, @PMinervini, @_rockt, @shimon8282, Phil Torr.

2
26
112
❄️ Curricula make it easier for RL agents to learn hard tasks + be robust to outlier scenarios like driving on an icy racetrack. But there's one BIG gotcha: Curricula cause covariate shifts w.r.t. the true environment distribution! This can be harmful. 📜
2
27
109
Interested in learning about how auto-curricula can be used to produce more robust RL agents? Come chat with us at our poster session on "Replay-Guided Adversarial Environment Design" tomorrow at @NeurIPSConf 2021: 👇 And scan the QR code for the paper!

Meta AI researchers will present Replay-Guided Adversarial Environment Design tomorrow at #NeurIPS2021.
2
18
87
If you're interested in teaching deep reinforcement-learning agents to communicate with each other, check out my open-source PyTorch implementation of the classic RIAL and DIAL models by @j_foerst, @iassael, @NandoDF, and @shimon8282:
0
23
72
LLMs will soon replace research scientists not only in generating ideas and writing research papers, but also in attending virtual poster sessions. You don't have to like it, but that's what truly end-to-end learning looks like.

Generative Agents: Interactive Simulacra of Human Behavior. abs: .project page:
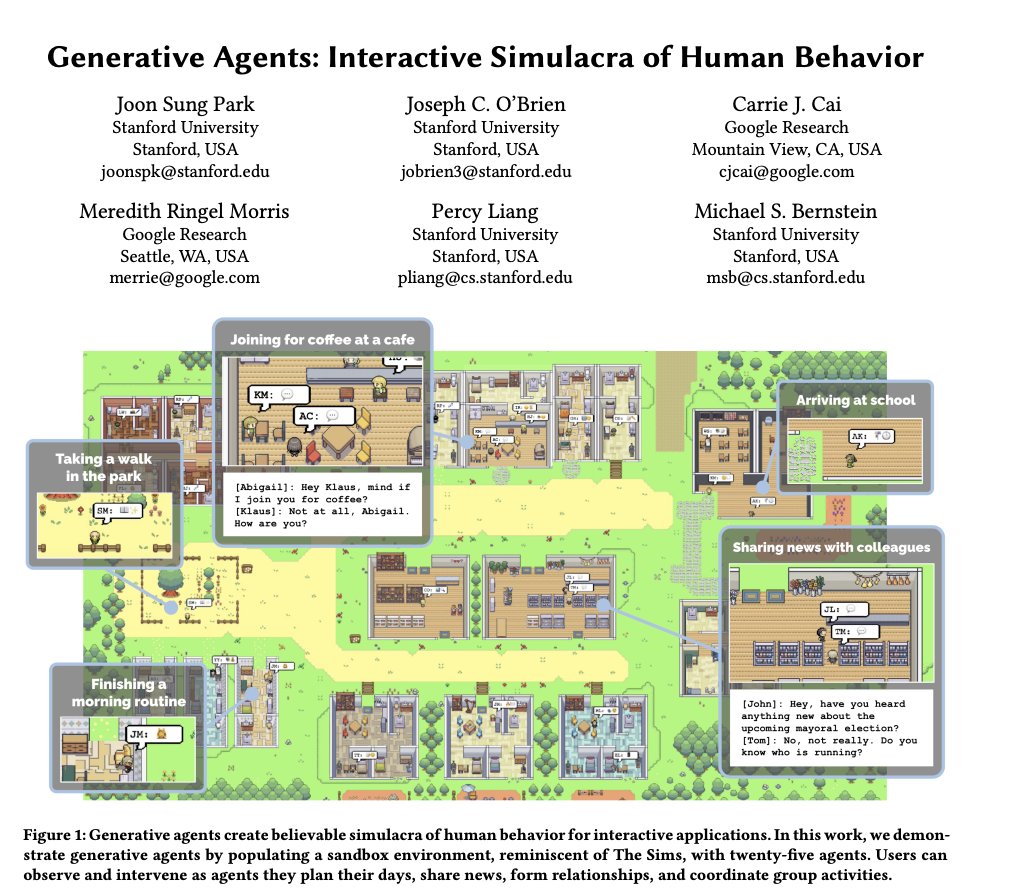
1
9
65
Humans might be stochastic parrots like LLMs some of the time—but unlike these models, most people hold inherent values, which cannot be hijacked through a simple prompt injection. What are ChatGPT's values? Is it possible to specify this?


6
7
64
Multi-agent RL just got 12,500x faster, and the gap between what research is possible in industry and academia, smaller.

Crazy times. Anyways, excited to unveil JaxMARL! JaxMARL provides popular Multi-Agent RL environments and algorithms in pure JAX, enabling an end-to-end training speed up of up to 12,500x!. Co-led w/ @alexrutherford0 @benjamin_ellis3 @MatteoGallici. Post:

2
6
61
Our team at @GoogleDeepMind is building autonomous agents that have the potential to help billions of users. If you're excited about creating the future of human-AI interaction with an exceptional group of people, consider joining us as a research engineer.
Exciting news! We're looking for one more person, ideally with a few years industry experience in a similar role, to join the @GoogleDeepMind Autonomous Assistants team in London as a Senior or Staff Research Engineer. If you're interested, read on! [1/6]
2
7
55
Collaborating with famous researchers.



3
3
51
Pretty obvious that mainstream tech AI discourse is falling into the same failure mode that plagued “web3”: Magical thinking that equates the present version of the technology with some idealized or exaggerated sci-fi form. Many industry-led incentives leading to this outcome.
0
3
52
Come by and chat about environment design, open-ended learning, and ACCEL at Poster 919! #icml2022

0
5
49
Extremely excited to be putting together this workshop focused on open-ended agent-environment co-evolution with an amazing bunch of co-organizers. If you are working on open-endedness, consider sharing your work at ALOE 2022. 🌱.

Announcing the first Agent Learning in Open-Endedness (ALOE) Workshop at #ICLR2022! . We're calling for papers across many fields: If you work on open-ended learning, consider submitting. Paper deadline is February 25, 2022, AoE.

0
8
51
Something intensely funny about frontier AI labs spending > $100M to train models, but base public benchmarks on evals put together by poor grad students. (These benchmarks have been pivotal, but prob worth paying the marginal cost to clean them up.).

Frontier models capping out at ~90% on MMLU isn't a sign of AI hitting a wall. It's a sign that a lot of MMLU questions are busted. The field desperately needs better evals.

0
2
50
Great fun chatting with @MLStreetTalk about our recent work, led by @MarcRigter, on training more robust world models using exploration and automatic curricula.

Hung out with @MinqiJiang and @MarcRigter earlier and we discussed their paper "Reward-free curricula for training robust world models" - it was a banger 😍
0
2
48
Regret—the diff b/w optimal performance and the AI agent's own performance—is a very effective fitness function for evolutionary search of environments that most challenge the agent. The result: An auto-curriculum that quickly evolves complex envs and an agent that solves them!.

Evolving Curricula with Regret-Based Environment Design. Website: Paper: TL;DR: We introduce a new open-ended RL algorithm that produces complex levels and a robust agent that can solve them (e.g. below). Highlights ⬇️! [1/N]
2
5
47
LAPO is now open sourced and a spotlight at @iclr_conf . Learn latent world models and policies directly from video observations. No action labels required. Congrats, @schmidtdominik_!.

The code + new results for LAPO, an ⚡ICLR Spotlight⚡ (w/ @MinqiJiang) are now out ‼️. LAPO learns world models and policies directly from video, without any action labels, enabling training of agents from web-scale video data alone. Links below ⤵️
2
5
43
The difference between open-ended novelty search and objective-based optimization.

Thinking about tools and the value they create and imo “what use case does this unlock” is 100x more valuable to answer than “what problem does this solve”.
0
12
41
On my way to ICLR :) I’ll be in Vienna for the whole week. Looking forward to discussing and debating ideas around synthetic data, open-ended agents, and what lies beyond chat. I’ll also be at a few posters 👇.
2
3
40
"The first principle is that you must not fool yourself, and you are the easiest person to fool." . This remains the best advice, and it's more applicable than ever.
1
3
41
Very excited that ALOE will take place *in person* at NeurIPS 2023!.
🌱 The 2nd Agent Learning in Open-Endedness Workshop will be held at NeurIPS 2023 (Dec 10–16) in magnificent New Orleans. ⚜️. If your research considers learning in open-ended settings, consider submitting your work (by 11:59 PM Sept. 29th, AoE).
0
6
39
The Dartmouth Proposal is where our field began. I turned to it when writing our position piece on the central importance of open-ended learning in the age of large, generative models. For a weekend read, the latest version is now in the Royal Society:

McCarthy, Minsky, Rochester, and Shannon's "Dartmouth Summer Research Project on AI" proposal from 1956 almost reads like an LLM x Open-Endedness research agenda: How Can a Computer be Programmed to Use Language, Neuron Nets, Self-Improvement, Randomness and Creativity.
1
8
36
@BlackHC @LangChainAI LangChain/ReAct are prompt engineering. Toolformer uses prompts to generate examples of tool use, but also intros a new way to filter these for further training. It’s an LLM generating its own training data—a more compelling idea imo. Closely related to
0
2
37
@y0b1byte Great list! I'm similarly optimistic about deep RL having a heyday with a few more years of work. A few more for the list:. MuZero applied to video compression: And of course the recent alignment work for LLMs:.
0
3
34
Dominik did some truly amazing work during his brief stint as an MSc student at @UCL_DARK. I'm lucky to have advised him on this project (largely his brainchild). If you're interested in open-ended learning, keep an eye out for @schmidtdominik_, and give him a follow.
Extremely excited to announce new work (w/ @MinqiJiang) on learning RL policies and world models purely from action-free videos. 🌶️🌶️. LAPO learns a latent representation for actions from observation alone and then derives a policy from it. Paper:


0
4
33
New exponential just dropped.

The surge in #OpenEndedness research on arXiv marks a burgeoning interest in the field!. The ascent is largely propelled by the trailblazing contributions of visionaries like @kenneth0stanley, @jeffclune, and @joelbot3000, whose work continues to pave new pathways.
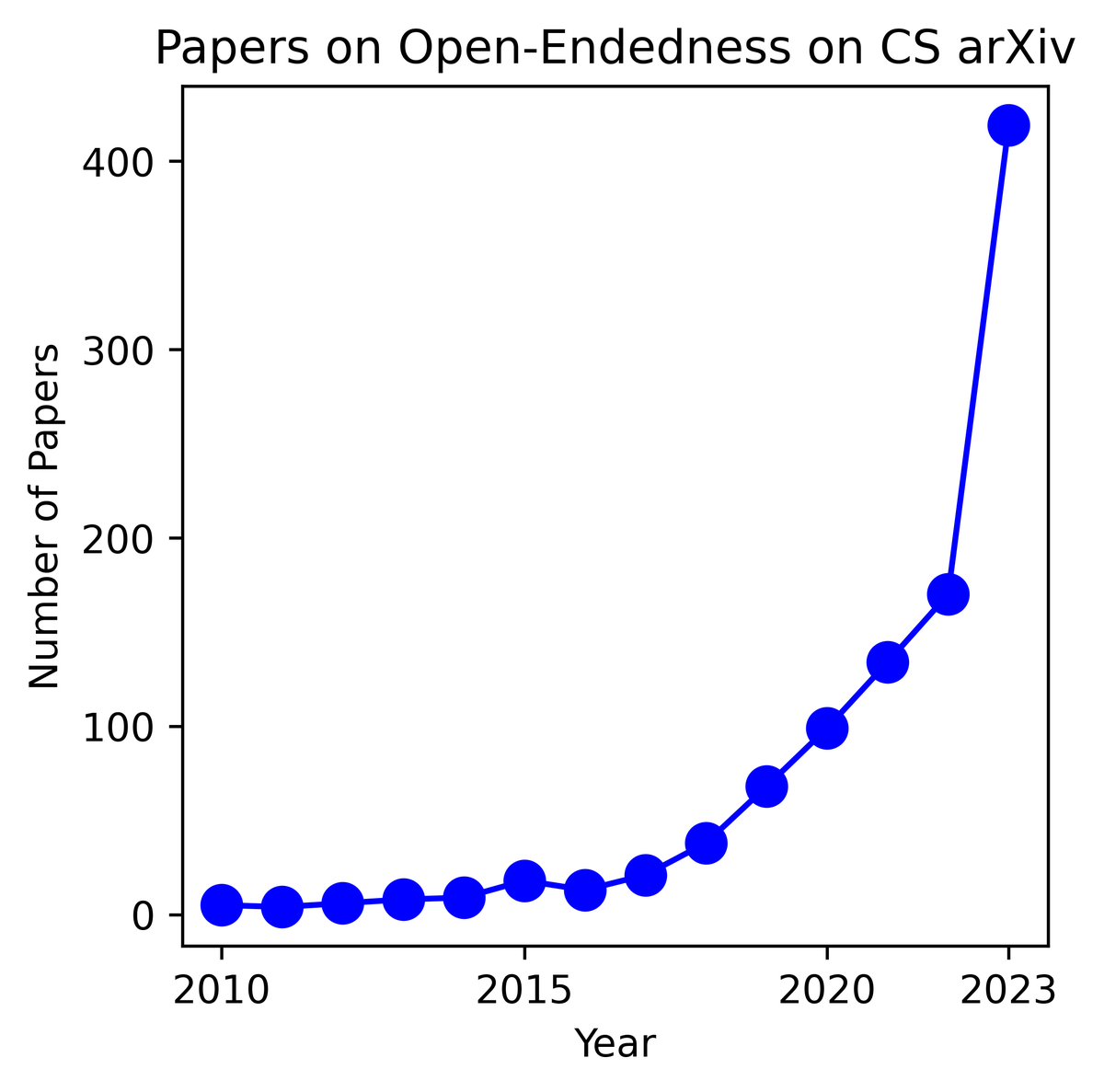
0
1
33
A rising wave of research centered on auto-curriculum learning features 2.0 programs that search for their own training data. This data might be real data found online or synthetic samples from a simulator or large generative model, lik a world model.
1
4
29

Had a lot of fun chatting with @kanjun and @joshalbrecht about producing more general agents via adaptive curricula and open-ended learning!.

Learn about RL environment and curriculum design, open-endedness, emergent communication, and much more with @MinqiJiang from UCL!.
0
6
31


We believe methods like PLR will play a key role in unlocking the potential for self-supervised RL. Stay tuned for some interesting developments in this direction. In the meantime, you can checkout our. ICML camera-ready: Code:
0
6
30
It is the end of the 22nd century. In the aftermath of the AI singularity, humans rebuild a greener, less techno-centric planet with the help of hyper-intelligent, GMO dinosaurs. (Concept art by @OpenAI DALL-E)



3
2
27
Prediction: A significant (at least 1:00 of playback) of a Billboard 100 song will be generated or ghostwritten by a deep learning model by the end of 2025. This will lead to US federal case precedent establishing the handling of pre-existing IP in AI-generated content.
3
1
30
@rabois @hunterwalk @dbasic @semil Colin Huang is a clear counterexample. Former Google eng + pm who took $PDD from 0 to $29B in ~3 years.

3
2
29
Now that Q-Learning is trending, I gotta say I called this one.
It's going to be a very exciting week for RL.
1
0
29
Come MiniHack the Planet with us! This new gym-compatible RL environment lets you create open-ended worlds by tapping the full universe of diverse entities and rich dynamics offered by the NetHack runtime. Amazing work led by @samveIyan!.
Progress in #reinforcementlearning research requires training & test environments that challenge current state-of-the-art methods. We created MiniHack, an open source sandbox based on the game NetHack, to help tackle more complex RL problems. Learn more:.
1
8
27
@m_wulfmeier 💯 It’s why RL in some form or another will continue to matter. It’s entirely complementary to large pre-trained models. @egrefen, @_rockt, and I wrote at length about this view here, which might interest you:
1
5
26
If your research helps AI systems never stop learning, the ALOE Workshop is a great place to share your work. Especially great for those who want to get high-quality feedback or share ideas ahead of ICLR (or from a NeurIPS rejection) with a diverse community of researchers.
⏰Only 1 week until the ALOE 2023 submission deadline! . 🌿Submit your work related to open-endedness in ML, and join a growing community of researchers at NeurIPS 2023 in New Orleans, USA. 📄Submissions can be up to 8 pages in NeurIPS or ICLR format:.
0
3
27
If you find yourself unable to sleep this Tuesday evening, come check out our poster and talk on PLR from 2am - 7am BST at @icmlconf 😅.

Prioritized Level Replay. Poster: Spotlight: - Minqi Jiang (@MinqiJiang), Edward Grefenstette (@egrefen), Tim Rocktäschel (@_rockt).
0
4
26
Congrats @jparkerholder! (and @_rockt ) Big catches for DM. Looking forward to seeing how the ideas we've explored together in the last couple years cross pollinate there. Open-endedness means you'll open source the code right? ;).
1
1
26
If you're attending @NeurIPSConf and interested in open-ended curriculum learning, exploration, and environment design, let's chat!.
Members of @UCL_DARK are excited to present 8 conference papers at #NeurIPS2022. Here is the full schedule of all @UCL_DARK's activities (see for all links). We look forward to seeing you New Orleans! 🇺🇸. Check out the 🧵 on individual papers below 👇


1
2
26
Growing evidence shows deep nets are bottlenecked on data. More high-quality data → better generality. In 2.0, this data is provided upfront, moving the manual step from coding to data curation. Can the software also produce its own data?.
1
4
25
Impressive new results on training large-scale Transformer-based policies for fast k-shot adaptation in XLand (2.0!) + featuring old collaborators @_rockt and @jparkerholder.

I’m super excited to share our work on AdA: An Adaptive Agent capable of hypothesis-driven exploration which solves challenging unseen tasks with just a handful of experience, at a similar timescale to humans. See the thread for more details 👇 [1/N]
2
3
25
More awesome work led by the always impressive @_samvelyan + @PaglieriDavide, using a minimax-regret criterion for evolving diverse field positions that are adversarial yet solvable for SoTA Google Football agents. (As cool as it is, this is only a teaser for what is to come.).
Uncovering vulnerabilities in multi-agent systems with the power of Open-Endedness! . Introducing MADRID: Multi-Agent Diagnostics for Robustness via Illuminated Diversity ⚽️. Paper: Site: Code: 🔜. Here's what it's all about: 🧵👇

0
5
25
Would love to see a compendium of spikes. A few other examples that immediately come to mind: .- Experience replay (Lin, 1992).- Diffusion probabilistic models (Sohl-Dickstein et al, 2015).- Associative scans (Blelloch, 1990).

@MinqiJiang introduced me to the concept of the spike. It's not cool to have a highly cited paper because maybe someone else would have written the same one. What's cool is to have a spike in citations which means you're way ahead of the curve.
3
0
25
I hope interactive demos accompanying RL research become a common practice. ONNX + TensorFlow.js make sharing and running deep RL agents in the browser straightforward. What is missing 👀: an easy way to compile an RL env for the browser—which seems very doable for many envs.
2
3
23
This project drew inspiration from interactive publications + demos like from @hardmaru, many beautiful works in @distillpub, and the excellent TeachMyAgent web env from @clementromac et al, which was foundational to our demo:.
2
4
23
Fun recap of some impressive results of applying unsupervised environment design to generate autocurricula over game levels in competitive two-player settings. Great work led by @_samvelyan and featured in ICLR 2023:

New Video - DeepMind-Like Gaming AI: Incredible Driving Skills!.
0
4
23
A nice bite-sized summary of recent efforts from my collaborators and myself in developing more principled autocurricula. Conceptually refactoring PLR as Unsupervised Environment Design (from @MichaelD1729) led to many further insights + algorithmic advances + collaborations.
If after 3 years of @MichaelD1729's work on Unsupervised Environment Design (leading to & you are still using domain randomization (DR) for training more robust agents, consider PLR as a drop-in replacement!

1
2
24

0
3
24
Without a doubt my favorite part of NeurIPS this year.
Q: Why is it an exciting time to do research in open-ended learning?. A: Because of all of you! 🫵 (well said, @jeffclune). Thanks to all who took part in the ALOE Workshop. It truly felt like a special community today. See you next year!




0
0
23

Count me lucky to work with such creative and talented colleagues.

0
1
23
Mika drove this project, scaling replay-guided UED to 2-player competitive games, to an awesome finish. Check out his deep dive on MAESTRO, which will be presented at ICLR 2023.
I’m excited to share our latest #ICLR2023 paper . 🏎️ MAESTRO: Open-Ended Environment Design for Multi-Agent Reinforcement Learning 🏎. Paper: .Website: . Highlights: 👇
1
7
23
Nice single file implementations of recent, scalable autocurricula algorithms from friends at @FLAIR_Ox.

🔧 Looking to easily develop RL novel autocurricula methods?.⚡ Want clean, blazingly fast, and readily-modifiable baselines?. Presenting JaxUED: a simple and clean RL autocurricula library written in Jax!
0
1
22
One thing open-endedness and AGI have in common: The set of proposed definitions for each will continue to grow tirelessly over time (you might even say, open-endedly).
3
3
21
minimax features strong baseline implementations of minimax regret-based autocurricula like PAIRED, PLR, and ACCEL as well as new parallel and multi-device versions + abstractions that make it easy to experiment with different curriculum designs.
If after 3 years of @MichaelD1729's work on Unsupervised Environment Design (leading to & you are still using domain randomization (DR) for training more robust agents, consider PLR as a drop-in replacement!
1
3
21
We call this emerging approach Software²: Data is dynamically generated by the software itself, bootstrapping to general capabilities in a potentially open-ended way. This echos the Von Neumann architecture where software at rest is data: In Software², data in motion is software.

1
3
20
Fantastic new work led by the talented @MarcRigter showing how we can generate minimax-regret autocurricula for training general world models. The method is principled and worked well on pretty much the first attempt.

How do we create robust agents that generalise well to a wide range of different environments and future tasks?. Our new #ICLR paper poses this problem as learning a robust world model.
0
2
20
@togelius Some video games become sufficient simulations of real-world settings, and gameplay data is used for human-in-the-loop training of highly robust A.I.'s. This changes the role of "gaming" from entertainment to a valuable form of work. We'll see new jobs like "A.I. trainer.".
1
0
18
PLR FTW :).
Given the vastness of XLand 2.0, it is challenging for an agent to learn effectively by sampling tasks uniformly. We make use of Prioritized Level Replay, a regret-based approach to automatically select tasks at the frontier of agent capabilities. [4/N]

0
4
19

Yeah. so about that. (The @UCL_DARK thesis template since last year. We're working on it. 🫡 🤣)


Lot of pitches this week for "perpetual data machines". Either laundering self-generated data or attributing prescience to reward models. Just want to caution that is a common trap smart people fall for.
1
0
19
🚩 I see your red-teaming and raise you ✨Rainbow Teaming✨ 🌈. This fantastic work, led by @_samvelyan, @sharathraparthy, and @_andreilupu is one of my favorite applications of the ideas behind open-ended learning to date.
We employ Quality-Diversity, an evolutionary search framework, to iteratively populate an archive—a discrete grid spanning the dimensions of interest for diversity (e.g. Risk Category & Attack Style)—with prompts increasingly more effective at eliciting undesirable behaviours.

0
5
19
PLR closely relates to some recent theories suggesting prediction errors drive human play, and dopamine’s role in driving structure learning via reward-prediction errors. via @Marc_M_Andersen, @aroepstorff: via @gershbrain: .
2
5
19

Our method, Prioritized Level Replay builds on this insight to induce auto-curricula by selectively sampling previously visited levels for playing again, favoring those with the highest, recent value losses. This simple method improves both sample efficiency *and* generalization.
1
4
17
Software² rests on a form of *generalized exploration* for active data collection. Automatic curriculum learning, large generative models, and human-in-the-loop interfaces for shaping new data like @DynabenchAI, @griddlyai, and @AestheticBot_22, are all key enablers.

1
1
17
Really excited to hear @kenneth0stanley speak at @aloeworkshop 2022!.
Kicking off our speaker spotlights is @kenneth0stanley, a pioneer of open-endedness in ML. He co-authored Why Greatness Cannot Be Planned w/ @joelbot3000 (also speaking). They argue open-ended search can lead to better solutions than direct optimization.

0
2
17
Agents creating their own tasks isn't a new idea (@SchmidhuberAI's Artificial Curiosity and @jeffclune's AI-GAs) What is: The simultaneous maturation of auto-curricula, gen models, and human-in-the-loop on a web of billions: fertile soil to grow the next generation of computing.
1
2
16
Super excited about this work! @Bam4d's Griddly is now a @reactjs component. We think it can change the game for sharing r̴e̴p̴r̴o̴d̴u̴c̴i̴b̴l̴e̴ fully-interactive RL research results.

We’re excited to announce GriddlyJS - A Web IDE for Reinforcement Learning! . Design 🎨, build ⚒️, debug 🐛RL environments, record human trajectories 👲, and run policies 🤖 directly in your browser 🕸! . Check it out here: Paper:
0
2
17
Mamba seems like the critical takeoff point for open-source SSMs, and large pretrained SSMs more broadly.
0
0
17
Like the roadways, the Internet is becoming a mixed autonomy sys, w/ both human + agentic AI participants. There are many Q’s of HCI, machine theory of mind, and multi-agent dynamics. This open source project by @mindjimmy + @zhengyaojiang makes it easier to ask those questions.

Introducing ChatArena 🏟 - a Python library of multi-agent language game environments that facilitates communication and collaboration between multiple large language models (LLMs)! 🌐🤖. Check out our GitHub repo: #ChatArena #NLP #AI #LLM 1/8 🧵
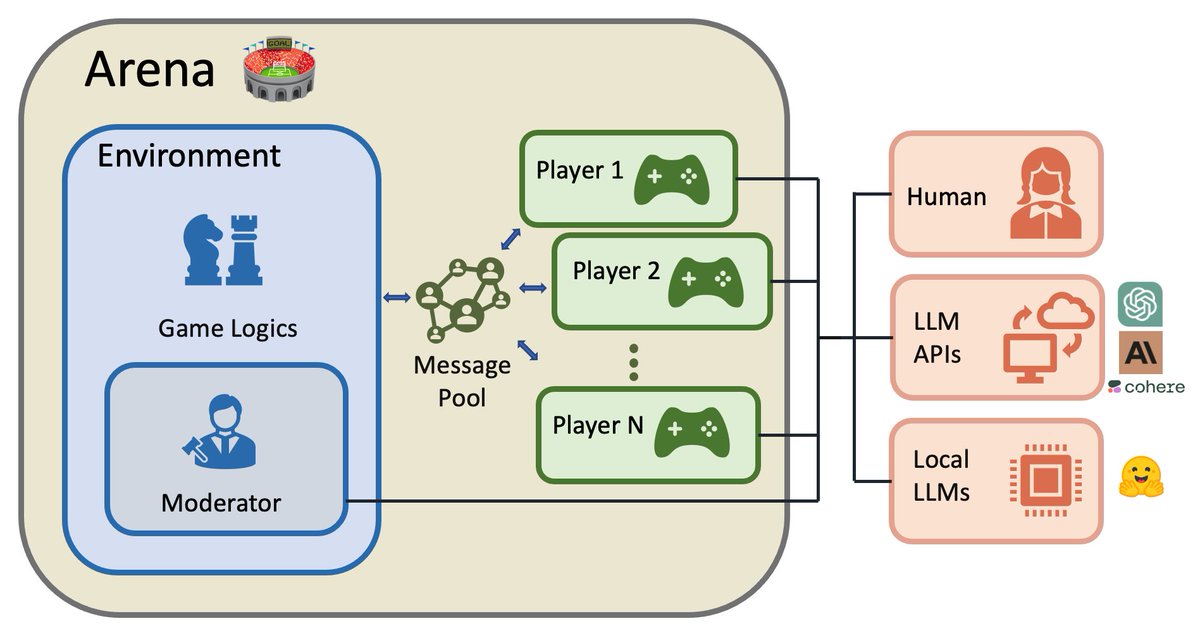
0
2
16
We test the generalization of agents trained via our “replay-guided” methods to those trained via replay-free baselines in a maze domain, and show improved zero-shot transfer to challenging human-designed mazes.
2
3
15
Cool work from @ishitamed showing that we can redesign PAIRED to match state-of-the-art UED algorithms in producing more general agents.

📢 Exciting News! We're thrilled to announce our latest paper: "Stabilizing Unsupervised Environment Design with a Learned Adversary” 📚🤖 accepted at #CoLLAs 2023 @CoLLAs_Conf as an Oral presentation!. 📄Paper: 💻Code: 1/🧵 👇.
0
2
16
Like living organisms, RL agents are shaped by their environment. How can we improve RL agents by designing the environment instead of the agent? We show that random search, as done by PLR, is surprisingly effective for designing useful environments.
1
2
15
Has anyone benchmarked iteration times for transformer training with JAX vs. torch.compile()?.
1
0
16
This is an amazing team and mission. The impact of real-world ML for ML systems like this could have huge compounding effects. Congrats @zhengyaojiang, @YuxiangJWu, and @schmidtdominik_!.

A major life update: We ( @YuxiangJWu @schmidtdominik_) are launching Weco AI, a startup that is building AutoML Agents driven by LLMs!. Since last year, generative AIs have completely changed the way I work, yet I still feel like I've only scratched the surface. I'm so eager to.
0
0
14
minimax centers on speed and modularity. Modularity: You can easily switch out the different pieces and experiment with new ideas. Speed: More results faster. We tensorized everything, including the environment logic, so it's all compiled for hardware acceleration on GPU/TPU.

1
2
15
This theoretically unifies PLR with other unsupervised environment design (UED) methods like PAIRED, resulting in a version called Robust PLR (PLR⊥), and a replay-based version of PAIRED, called REPAIRED—each provably resulting in a minimax regret policy at equilibrium.

1
1
14
Random thought: Gemini = "G" mini. Seems apt, as it organizes all the knowledge on the web (like the big G), but compressed into the weights of a neural network.

0
1
13
The big takeaway: The order of visiting training levels has a huge impact on both sample efficiency + generalization. Simply sampling the next training level based on value-loss-based estimates of the learning potential of replaying each level leads to these significant gains.

1
6
14
@chrisantha_f Looks like a truly fantastic application of open-ended, self-referential evolution. You might be interested in this recent work from @_chris_lu_ et al that performs some theoretical analysis of evolution with a self-referential parameterization.
2
0
15
🏗 The codebase contains a how-to for integrating your own environments. We can't wait to see what exciting new ideas come out of this open source effort!. Congrats to my collaborators for getting this out there! @MichaelD1729 @jparkerholder @samveIyan @j_foerst @egrefen @_rockt.
0
1
15
Hard to imagine a better opportunity if you are thinking of pursuing a PhD in ML. Apply!.
🧵THREAD 🧵.Are you looking to do a 4 year Industry/Academia PhD? I am looking for 1 student to pioneer our new FAIR-Oxford PhD programme, spending 50% if their time at @UniofOxford, and 50% at @facebookai (FAIR) while completing a DPhil (Oxford PhD). Interested? Read on… 1/9.
0
0
15