

Markus Wulfmeier
@m_wulfmeier
Followers
12,117
Following
1,511
Media
257
Statuses
2,236
Large-Scale Decision Making @GoogleDeepMind - European @ELLISforEurope - imitation, interaction, transfer - priors: @oxfordrobots @berkeley_ai @ETH @MIT
London, England
Joined December 2015
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Florida
• 247253 Tweets
Bivol
• 122300 Tweets
#precure
• 91485 Tweets
Nico
• 64803 Tweets
Oregon
• 62644 Tweets
#AEWWrestleDream
• 54793 Tweets
Penn State
• 37740 Tweets
#仮面ライダーガヴ
• 36799 Tweets
Burke
• 36057 Tweets
Tennessee
• 35842 Tweets
Dick Cheney
• 30765 Tweets
Dennis Quaid
• 29620 Tweets
マンホール
• 28138 Tweets
#ブンブンジャー
• 27907 Tweets
Ohio State
• 26556 Tweets
#UFCVegas98
• 23300 Tweets
ワコール
• 21076 Tweets
まゆちゃん
• 14927 Tweets
いろはちゃん
• 14864 Tweets
Willow
• 11509 Tweets
ヴァレン
• 11447 Tweets
Ole Miss
• 11230 Tweets
マッドレックス様
• 10371 Tweets




















Pinned Tweet

Imitation is the foundation of
#LLM
training.
And it is a
#ReinforcementLearning
problem!
Compared to supervised learning, RL -here inverse RL- better exploits sequential structure, online data and further extracts rewards.
Beyond thrilled for our
@GoogleDeepMind
paper!
A


11
63
354
Looks like the new generation of students is better prepared for the age of Gemini/ChatGPT based review...

5
263
4K
State-of-the-art exploration in reinforcement learning.
10
66
468
After long nights and sacrificed weekends, many chats with colleagues and friends, I have finally completed this (much too long) post on
#MachineLearning
and Structure for Mobile
#Robots

10
153
455
Trying to get a better grasp of transfer in reinforcement learning? Look no further!
Over the last couple of years we have created a survey and taxonomy with colleagues
@GoogleDeepMind
1/N 🧵 👇


2
92
418
Our team at Berkeley AI Research (BAIR) is launching a blog, with weekly posts describing cutting-edge ML research
4
95
277
Thanks everyone for the congratulations!
Now seems a good time to announce that after continung my postdoc in Oxford until August, I will be joining
@DeepMindAI
as research scientist. Looking forward to new challenges and working together towards more capable autonomous systems!


14
5
236
Let's see how far we get this time...
Bought during my PhD (ie many years ago) and stopped reading at least 3 times. Now after the ICLR deadline it's time again.
Any opinions?
(The book, not my inability to complete it)

41
3
210
It's back! We're accepting internship applications again!
@GoogleDeepMind
Looking forward to working again with many incredible junior researchers (& engineers)!
Please reach out with any questions!

4
34
203
Fantastic new machine learning book by John Winn, Christopher Bishop, Thomas Diethe! (this is already largely accessible online for free)
Great interface, engagingly written, very intuitive & build on examples
0
49
190
Deep RL opening another door! 🤖⚽
It's amazing what dynamic, interactive behaviours emerge from training for quite simple objectives in a complex world.
Thrilled that the paper is public and incredibly proud of our team!
Add. coverage on
@60Minutes


Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
investigated the application of Deep Reinforcement Learning (Deep RL) for low-cost, miniature humanoid hardware in a dynamic environment, showing the method can synthesize sophisticated and safe
39
317
1K
3
21
164
Cannot think of a better place (and a better model 😉) to embody AI in the physical world! We're hiring
@GoogleDeepMind
#Robotics
. Reach out with any qs

3
18
159
Gooal! Our work on autonomous, vision-based robot soccer is coming to
#CoRL2024
!
(using large-scale multi-agent RL in simulation with NeRF based rendering and lifelong learning via Replay across Experiments)
Paper
Videos
Catch up
4
20
154
Lets move these robots out of the lab! (check out the end of our paper for initial steps)
In particular, onboard egocentric vision instead of external sensors can go a long way.
Have a look at how the robot learns to control its head to keep track of everything!

Football players can tackle, get up, kick and chase a ball in one seamless motion. How could robots master these motor skills? ⚽
We trained AI agents to demonstrate these agile behaviours using end-to-end reinforcement learning.
Find out more:
87
652
3K
4
24
145
Can deep reinforcement learning enable autonomous
#robots
🤖🦿 to play real-world soccer ⚽️?
Thrilled to share our latest step towards learning multi-agent robot soccer purely with onboard computation and sensing. We're extending prior motion capture
6
29
126



Ever wondered how to tune your hyperparameters while training RL agents? w/o running thousands of experiments in parallel? And even combine them?
Check out our work @
#CoRL2021
on training mixture agents which combines components with diverse architectures, distributions, etc



1
15
109

Excited to announce our newest work in hierarchical reinforcement learning. We design a robust off-policy learning framework which provides an easy transition from training flat Gaussian policies, to mixture policies, to option policies.
Thread 🔽




1
25
108
The
@oxfordrobots
blog is finally online ! Every few weeks you're going to find a new piece of research in
#robotics
and
#machinelearning
from our group.
Starting with some amazing work on using
#deeplearning
for 3D detection in LIDAR data!
@UniofOxford

0
45
107
Representation matters!
I'm excited to share (slightly delayed) our newest work discussing what is a 'good' representation for
#ReinforcementLearning
in
#Robotics
.




2
28
106
Preparing
#ReinforcementLearning
lectures in
@GoogleColab
is fantastic!
Very interactive, easy to debug and visualise. Plus free cloud GPUs/TPUs!
I wish this would have been available when I was learning about the field nearly a decade ago!
2
8
106
Looking forward to my (just begun) short-time postdoc at the Oxford Robotics Institute. Proud to be working with this incredible team on tasks in LfD, RL and lifelong learning (etc) to increase robustness and reduce the effort of training robots
#robotics
#machinelearning
3
2
102
Reinforcement Learning is not about maximising a reward, it is about self-guided data collection!
8
9
99
Need a new, easy-to-use RL algorithm?
(Which is essentially DQN but for continuous control Tasks!)
DecQN was accepted at
#ICLR2023
In our recent paper, we show that a minor variation of DQN actually solves many continuous control problems from state or pixels on par with state-of-the-art actor critic methods such as (D4PG, DMPO, SAC, DrQv2, DreamerV2, ...).

2
13
90
2
14
91
In our recent paper, we show that a minor variation of DQN actually solves many continuous control problems from state or pixels on par with state-of-the-art actor critic methods such as (D4PG, DMPO, SAC, DrQv2, DreamerV2, ...).
2
13
90
Finally finished my slides for the International Symposium on
#RobotLearning
tomorrow morning at the
@UTokyo_News_en
.
Looking forward to covering two recent projects as examples of the role of
#ReinforcementLearning
in the age of Gemini, ChatGPT and friends.
Thank you



5
4
88

Our 🌎-scale Inverse RL paper is finally out! Thrilled to share this multi-year project on route recommendation.
Understanding preferences is much harder than behaviour: not just WHAT but WHY!
We address the challenge via IRL on massive scale (100s Ms states, samples, params)!


3
14
85
Model Params - Inverse RL
Hundreds
Thousands
Millions
Billions
...

Imitation is the foundation of
#LLM
training.
And it is a
#ReinforcementLearning
problem!
Compared to supervised learning, RL -here inverse RL- better exploits sequential structure, online data and further extracts rewards.
Beyond thrilled for our
@GoogleDeepMind
paper!
A
11
63
354
2
17
78
Sutton's and Barto’s
#ReinforcementLearning
book has had a massive, exciting update. If anyone has not yet had a look, I highly recommend it, both as quick refresher or full intro to a sub-field.
1
11
78
Leslie Kaelbling's wonderful 'Learning to achieve goals' paper is a really nice example of ideas taking time to gain traction.


3
4
73
Imagine you only have to run your
#FoundationModel
once! Offline and before any interaction with users.
This is possible due to the compositionality and graph structure underlying routes in Google Maps!

2
15
69
No better word than 'excitement' 🎉👀🤖⚽
Our robot soccer work has finally been published in
@SciRobotics
!
@GoogleDeepMind
RL for controller design is an extremely capable and flexible approach (eg incorporate large multimodal models in the future)!
Soccer players have to master a range of dynamic skills, from turning and kicking to chasing a ball. How could robots do the same? ⚽
We trained our AI agents to demonstrate a range of agile behaviors using reinforcement learning.
Here’s how. 🧵
132
522
2K
2
8
69
The proceedings for the Conference on Robot Learning
#CoRL2018
#CoRL
are finally online.
Lots of
#sim2real
,
#transferlearning
and
#reinforcementlearning
!
Good luck getting any work done this week!
2
21
65
Great repository providing basic
#python
code for many standard task in
#robotics
:
#localisation
,
#mapping
,
#SLAM
,
#motionplanning
,
#control
by
@Atsushi_twi
#hashtagoverload
1
26
63
It feels strange to see all this amazing legacy Google Brain work as part of DeepMind!
An incredible privilege to have all this talent, old and new friends, under the same (metaphorical) roof!
0
4
63
And there it is: The robot car dataset! 20tb of camera, lidar, etc. and the paper
#Robotics
Oxford RobotCar Dataset
1 Year, 1000km: The Oxford RobotCar Dataset
robotcar-dataset.robots.ox.ac.uk
2
30
62
AlphaGoZero is 'thinking fast and slow' !
Post from David Barber (UCL) on Expert Iteration:
Seems like I'm a bit late to the party for realising the overlap of combining Deep Learning and MCTS to Kahneman's 'Thinking fast and slow'!

3
17
59
Best one-sentence advise you have received as junior researcher?
Mine: 'Start with the baseline and benchmark every change!'
4
6
58
Once more incredibly proud of this team!
Using
#MuJoCo
? Have a look!
We’ve acquired the MuJoCo physics simulator () and are making it free for all, to support research everywhere. MuJoCo is a fast, powerful, easy-to-use, and soon to be open-source simulation tool, designed for robotics research:
84
2K
6K
0
3
56
Reinforcement learning has found a completely new role in the age of LLMs, VLMs and VLAs. Better catch up on the best ways for adaptation and transfer via RL!

The Gemini era is here. Thrilled to launch Gemini 1.0, our most capable & general AI model. Built to be natively multimodal, it can understand many types of info. Efficient & flexible, it comes in 3 sizes each best-in-class & optimized for different uses

405
2K
11K
1
4
56

Our work on learning cost-functions for motion planning in
#autonomousdriving
is finally online
#Robotics
#ML
#LfD
0
11
54
Just finished Peter Feibelman's 'A PhD Is Not Enough!'. A great guide emphasising some of the aspects one easily tends to overlook during the time as PhD / postdoc. 1/x
1
11
53
Our work on "TACO: Learning Task Decomposition via Temporal Alignment for Control" got accepted to
#icml18
#robotics
#modularlearning
@KyriacosShiarli
,
@markus_with_k
, Sasha Salter,
@shimon8282
,
@IngmarPosner

0
8
53
Reinforcement learning is most useful if a) demonstrations are hard to get and b) a system is hard to model.
( a) no imitation, b) no MPC etc)
Excited to share Mohak's internship report and the 'Box o Flows' enabling us to ask questions in this space!

1
8
51
Extremely exciting news:
@BostonDynamics
and
@Hyundai
launching the Boston Dynamics AI Institute!
Congratulations Marc Raibert et al!
0
7
50
Continual learning and transfer between tasks is one of the most relevant/fascinating directions in current ML research (for me). It's a broad field and hard to keep up with the progress. So, I'm even more happy for this intuitive figure in
@DeepMindAI
s 'Progress & Compress'

0
4
50
Learning fast and slow 🤖🧠⏳
Highly excited that our (long-term) work on more flexible
#ReinforcementLearning
and
#TransferLearning
is finally public.
Two separate processes enable fast, coarse adaptation and slow, but better final performance.
1/n 🧵



2
8
49
Personal takeaway from the Bayesian deep learning session: 'You never go full Bayesian'
#NIPS2017
#nevergofullbayesian

3
12
49
Fascinating, how your reaction when finding a paper published about an idea you had depends on your connection to the field.
Field of expertise: No, I’m too slow!
Field of exploration: Yes, I’m on the right track!
2
1
48
It's a common joke in
#MachineLearning
and
#ArtificialIntelligence
that 'X is all you need' or that it is 'unreasonably effective'.
The powerful underlying idea is 'simplicity'. If we truly only need x then our methods become clearer and we can accelerate further progress.
🧵
1
9
47
Reward shaping in
#reinforcementlearning
is a pain! I need a couple of papers to visualize this pain for a slide.
What are your favorite examples?
(Our own dirty laundry: 9 shaping terms for the humanoid
#robot
soccer work)
13
3
47
Congratulations to everyone who submitted a paper to
#ICLR2022
yesterday!
Also: Congratulations to everyone who made a last minute call to instead improve their paper and submit to a future conference!
These decisions are hard but important. Your future self might thank you!

*It doesn't matter much.*
Vast majority of the papers won't matter in the long run. Your career will be shaped only by a few good ones. Instead of getting an "okay" paper accepted, it could be a blessing in disguise to revise and strengthen your paper.
Fig credit: Bill Freeman
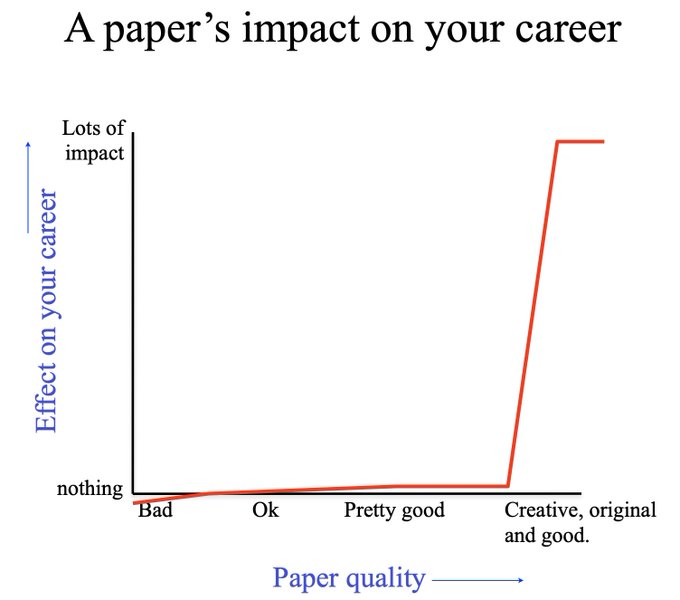
3
30
214
1
4
47
The best ideas are obvious in hindsight:
Reinforcement learning speedup by using reward-predicting LSTMs and saliency methods for credit assignment.

1
9
47
A truly fantastic
#ICRA2023
@ieee_ras_icra
this year! Hope everyone is enjoying the last day and our typically beautiful London weather.

1
11
47
Never underestimate the impact of a single idea!

20 years ago this week Sergey Brin and Larry Page published the CS paper that birthed Google: (credit: Stanford University)

5
338
572
1
8
47
Obvious trend in deep learning paper titles these days: be as bold as possible...

3
6
47
This is so impressive!

2.8 million images were used to build a grid of Block-NeRFs and create the largest neural scene representation to date, capable of rendering an entire neighborhood in San Francisco. Dive in to the latest research from Waymo and Google Research:
21
206
1K
3
6
46
Proud to announce our recent work on compositional, hierarchical models to strengthen
#transfer
between related tasks while mitigating negative interference. We considerably improve
#dataefficiency
for reinforcement learning on physical
#robots
(reducing training time by weeks)
Data-efficiency is one of the principal challenges for applying reinforcement learning on physical systems. We use hierarchical models to strengthen transfer while mitigating negative interference - saving weeks of training time for physical robots.
1
124
354
2
6
46
Software engineers ignoring libraries, inventors reinventing wheels & researchers not reading papers.
Repeated training of models completely from scratch should seem similarly hilarious.
2
7
44
One of the most exciting parts of the recent
#dalle2
enthusiasm is the creativity behind all those prompts!


1
4
42
Reinforcement learning to generate truly useful real world controllers. What are your favorite examples?
7
5
43
The end of machine learning research...
... or the
#arxiv
server has finally become sentient!

1
7
43
Very interesting work on Q-function hyperparameter optimization for RL from Théo Vincent, Fabian Wahren,
@Jan_R_Peters
,
@_bbelousov
, Carlo D’Eramo
Wonder how this perspective might interact with
@timseyde
's hyperparameter mixture policies?
4
10
42
Using reinforcement learning to generate deployable controllers? We have a simple trick to improve performance for many off-policy RL algorithms.
Development commonly includes large numbers of experiments to adapt algorithms, parameters, etc. Why waste the generated experience?


4
6
41
Looking forward to discussing embodied AI and robotics
@imperialcollege
this Thursday.
My talk will cover the role of '
#ReinforcementLearning
in the Age of Large Data'. And while the data generation side should be quite trivial to many, expect some discussions around why we
4
3
42
Here are all the videos from
#CoRL2017
from Vincent's mail!
Day 1:
Day 2:
Day 3:


@markus_with_k
ooh, thanks! That has Wednesday, not sure about Monday (they're unlisted vids so can't find via search) but Tues+Wed will keep me entertained for a while in any case :)
0
0
0
2
18
42
Pleased to announce the
#NIPS17
Workshop on 'Challenges in Robot Learning'
#robotlearning
#ml
#robotics
0
11
42
It's happening!
Introducing MuJoCo 2.1.1!
This version includes the top feature request:
#MuJoCo
now runs on ARM, including Apple Silicon. And yes, MuJoCo on the M1 Max is lightning fast.
Visit GitHub and read the changelog for more details:

4
74
445
0
0
41
Exciting new 'walker' domain!

I taught a hand how to walk using machine learning.
Has science gone too far?
140
1K
8K
0
3
40
Does this mean it needs to be cited 'for everything' ?
2
3
40
I'll try to share the full slides later!
But for now, here is the work that was covered plus take aways.
Thanks again everyone, really enjoyed the questions!

Finally finished my slides for the International Symposium on
#RobotLearning
tomorrow morning at the
@UTokyo_News_en
.
Looking forward to covering two recent projects as examples of the role of
#ReinforcementLearning
in the age of Gemini, ChatGPT and friends.
Thank you
5
4
88
0
2
40
Missed the
#NeurIPS2022
deadline?
Working in
#Robotics
and
#MachineLearning
?
Now is your chance! Make use of the additional days until the 15th of June and submit to
#CoRL2022
@corl_conf
!

0
8
38
0
10
39


These quadruped 'dance-off's have become a regular thing at robotics conferences.
Exciting times we live in!

#ANYmal
hopping around with
#SpotMini
and
#MIT
Mini Cheetah at
#ICRA2019
🤖🐇
@BostonDynamics
@MIT
@ieee_ras_icra
3
37
104
2
6
38

Working in
#ReinforcementLearning
for continuous Control or
#Robotics
?
You've probably repeatedly seen bang-bang behaviour emerging (which can quickly break your robot).
@timseyde
is asking why and what it means for us when designing algorithms and environments.


2
10
37
Realise how much you, your colleagues, and your lab depends on
#arxiv
?
Maybe consider ?

Due to the continuing, unplanned outage of , there will not be an announcement today. We sincerely apologize for the inconvenience.
8
24
61
1
8
36
'Evolutionarily speaking, brains are not for rational thinking, linguistic communication, or even for perceiving the world. The most fundamental reason any organism has a brain is to help it stay alive.'
@anilkseth
@NautilusMag
3
4
36
Had a great time teaching at the IFI summer school (
@UZH_en
) on Advances in
#ReinforcementLearning
and
#KnowledgeTransfer
together with
@abhishekunique7
Hopefully at some point again in person in Zurich as well!
(slides to follow soon.)

0
4
36
Great experience with
#ICLR2024
!
Pure joy of working with our team
@GoogleDeepMind
leading to two accepted papers! Fantastic work by Dhruva Tirumala &
@BarnesMJ
!
Something for
#RL
(lifelong learning) and for
#IRL
(world-scale models!!); both heavily data-centric!
Thread 🧵👇
1
4
36
Glad of how robotics, computer vision and machine learning as fields move towards (even) more open access. Conferences & workshops have become more (virtually) open throughout the last years.
@RoboticsSciSys
is going to be live streamed this year!
0
8
36
Great to see this survey on successes of deep
#reinforcementlearning
for
#robot
deployment! There is much more to come over the next years.
Shameless self-plug, Dhruva's paper finally occupies that last free cell in table 2. Bingo!

2
8
37
Peer review of preprints via Twitter. Welcome to the future of academic publication cycles!

A nice critique of our work from
@shimon8282
. Though I think we did acknowledge some of the issues, I agree that there's a lot more work to be done!
3
10
76
1
7
36