

Vinh Q. Tran
@vqctran
Followers
1,263
Following
290
Media
2
Statuses
115
research scientist @GoogleDeepMind , all thoughts my own, he/him
Brooklyn, NY
Joined March 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Zuckerberg
• 666299 Tweets
Oasis
• 604496 Tweets
Switch
• 298503 Tweets
Shadow
• 226169 Tweets
ニンダイ
• 140822 Tweets
Franco
• 96694 Tweets
Mikel Merino
• 64220 Tweets
リメイク
• 57160 Tweets
Logan
• 53553 Tweets
Capcom
• 52812 Tweets
Sancho
• 52420 Tweets
Fórmula 1
• 48392 Tweets
Sterling
• 47467 Tweets
グレイセス
• 43437 Tweets
アトリエ
• 42944 Tweets
Toney
• 36086 Tweets
テイルズ
• 32335 Tweets
ときメモ
• 26456 Tweets
幻想水滸伝
• 21057 Tweets
Pizza Tower
• 18453 Tweets
ルーンファクトリー
• 18334 Tweets
#湊あくあ生放送
• 17018 Tweets
ピザタワー
• 15862 Tweets
Keith Lee
• 13695 Tweets
軌跡シリーズ
• 13262 Tweets
コーヒートーク
• 12574 Tweets
ルンファク
• 12382 Tweets
#JayShah
• 11610 Tweets
#الاهلي_الفتح
• 11218 Tweets
Power Stone
• 11169 Tweets
ストレイチルドレン
• 10470 Tweets




















Officially became a Research Scientist this week!! IMO a title doesn't mean much, but never would I have thought I'd be in this position when I first joined Google to visualize distributed systems ~8 years ago. (1/2)
17
1
194
This was a phenomenon we were well aware of when building DSI, but sadly, I suspect this doesn't work in the general case. This paper only looks at datasets answerable with Wikipedia pages, where URLs are generally reformatted versions of their answers / the entity. 1/2

Large Language Models are Built-in Autoregressive Search Engines
When providing a few Query-URL pairs as in-context demonstrations, LLMs can generate Web URLs where ~90% of the corresponding documents contain correct answers to open-domain questions.

2
31
187
2
9
58
Led by our student researcher
@rpradeep42
, our new preprint answers the
#1
question we receive about DSI & Generative Retrieval, and represents what we currently understand about the paradigm. IMO it's a must read for those looking to do research or application in this area. 1/n
How Does Generative Retrieval Scale to Millions of Passages?
Finds that the use of synthetic queries as a document representation strategy is the only approach that remained effective as they scaled up the corpus size using MS MARCO passages.

1
49
192
1
4
39
A few months ago, we launched the first production Charformer model for Jigsaw's Perspective API. Today, I'm happy to share our latest technical report outlining our techniques and experiments that made this release possible.
Paper:

2
3
31

excited to see our hard work on this go out soon!! so happy to be a part of the Bard team

1/ In 2021, we shared next-gen language + conversation capabilities powered by our Language Model for Dialogue Applications (LaMDA). Coming soon: Bard, a new experimental conversational
#GoogleAI
service powered by LaMDA.
739
3K
15K
0
1
23
Why is simple next-token prediction so effective for pretraining LLMs? It’s more than just learning word statistics! In this work, we show that language has a fractal structure and so predicting the next word actually requires anticipating the patterns at all granularities. (!!)

How is next-token prediction capable of such intelligent behavior? I’m very excited to share our work, where we study the fractal structure of language. TLDR: thinking of next-token prediction in language as “word statistics” is a big oversimplification!

14
108
523
1
3
22
Congratulations Yi and
@RekaAILabs
on the launch!! Going from zero to the most multimodal model to date in 6 months is insane 😮

It’s been a short 6 months since I left Google Brain and it has been a uniquely challenging yet interesting experience to build everything from the ground up in an entirely new environment (e.g., the wilderness)
Today, we’re excited to announce the first version of the
84
140
1K
1
3
21
the most powerful truly open source model right now, brb using it in all the papers
New open source Flan-UL2 20B checkpoints :)
- Truly open source 😎 No forms! 🤭 Apache license 🔥
- Best OS model on MMLU/Big-Bench hard 🤩
- Better than Flan-T5 XXL & competitive to Flan-PaLM 62B.
- Size ceiling of Flan family just got higher!
Blog:
51
346
2K
0
2
18
2023: take care of new kidney, bake a perfect canelé, grow a Vietnamese herb garden, make one new close friend, first author one great paper
0
0
17
fun fact: I was working on DSI right after being released from the hospital for losing all remaining kidney function -- semantic ids were thought of and implemented from a dialysis chair!

i don't remember which neurips it was but once there was a copycat DSI paper that made minor modifications on DSI and won a best paper award at neurips.
the interesting thing was DSI was accepted at the same neurips so it was surely funny.
1
1
9
0
1
10
Super excited to share this work coming out of our group at
@GoogleAI
. We show that by training a single Transformer model to map from doc content to doc id, we can parameterize an entire retrieval system E2E -- without the need for dual encoders and/or external (MIPS) indices!

1
0
10
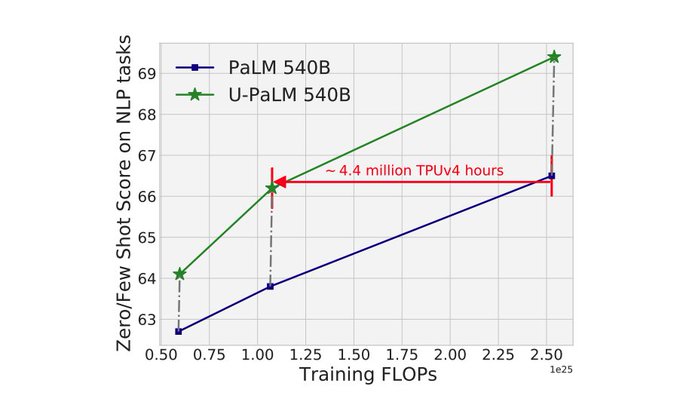
Super exciting result from Yi, Mostafa and colleagues. As hyper-optimized as LLMs are these days, UL2 is really showing how much more there is still to be had beyond purely scaling.
1
3
10
This is such an exciting work from Mahesh's group, really demonstrates the potential of the techniques developed in DSI in other domains!

Happy to share our recent work "Recommender Systems with Generative Retrieval"!
Joint work with
@shashank_r12
,
@_nikhilmehta
,
@YiTayML
,
@vqctran
and other awesome colleagues at Google Brain, Research, and YouTube.
Preprint:
#GenerativeAI
🧵 (1/n)

13
72
476
0
1
9
btw check out these sweet zero-shot haiku-ish poems written by U-PaLM :D

0
1
9
Awesome video by
@ykilcher
covering our recent paper!

🔥New Video on Differentiable Search Index🔥
This paper trains a Transformer to *directly predict docIDs* given a search query. This means the model weights themselves are the index. What does it mean? And how viable is this for real applications? Watch:

2
39
223
0
0
9
Been wild to hear from Yi how things in the wild are, definitely worth a read!
Long overdue but here's a new blogpost on training LLMs in the wilderness from the ground up 😄🧐
In this blog post, I discuss:
1. Experiences in procuring compute & variance in different compute providers. Our biggest finding/surprise is that variance is super high and it's

44
254
2K
1
0
8
excited to see the culmination of everyone’s hard work go out and happy to have been along for the ride! this is only the beginning
We're expanding access to Bard in US + UK with more countries ahead, it's an early experiment that lets you collaborate with generative AI. Hope Bard sparks more creativity and curiosity, and will get better with feedback. Sign up:
831
2K
9K
0
2
8
Passages from Wikipedia are also highly entity-centric, making this mapping easier, and less about memorization. In comparison, generative retrieval works like DSI intend to index arbitrary corpuses of documents. 2/2
1
0
8
Happy to announce that Charformer is now powering
@Jigsaw
Perspective API's new multilingual toxicity detection models!
paper:
link:

1
0
7
to live, eat, and breathe the new york summer with friends and loved ones, what more could you ask for really
0
0
6
Woah congrats Yi and
@RekaAILabs
!
We’re coming out of stealth with $58M in funding to build generative models and advance AI research at
@RekaAILabs
🔥🚀
Language models and their multimodal counterparts are already ubiquitous and massively impactful everywhere.
That said, we are still at the beginning of this

94
75
925
1
0
4
Not only this, but small fluctuations in Hurst between models turn out to be stronger predictors of downstream performance on challenging zero- and few-shot tasks (BBH, MMLU, GSM8K) than perplexity alone! (Ppl reported in terms of bits-per-byte, BPB.)
So, can we combine H with BPB to predict downstream performance? Yes: take the average H + 1/BPB (we invert BPB so that higher values are better). This simple average predicts downstream performance much better than perplexity-based BPB alone; especially in Big Bench Hard (BBH)!

1
1
25
1
1
5
!!!

0
0
5
Specifically, we use a strong LM (PaLM2-L) to derive fractal parameters for language in various domains, and establish that language is (1) self-similar across timescales and (2) long-range dependent (Hurst ≈ 0.7). We show that this value is robust between 12 different LLMs.
1
0
4
"I would never wish to incorporate this technology into my work at all. I strongly feel that this is an insult to life itself." -miyazaki

“Why Studio Ghibli movies can’t be made with AI.”
Source: YouTube ()
Excellent video by Dami Lee. An excerpt:
11
34
200
0
0
4
1
0
4
Beyond fractals, the possibility of more sophisticated upstream metrics than NLL/PPL is super interesting. Be sure to check out Ibrahim’s thread for a closer look, and the paper for the full details! Truly and deeply enjoyed collaborating on this with
@ibomohsin
and
@m__dehghani
.
0
0
4
1
0
4
@GoogleAI
The result is a proof-of-concept that performs surprisingly well -- sometimes outperforming dual encoders on a retrieval task over the NQ corpus of 300K docs. Lots of work left to do, but IMO this is a promising first result for an exciting new paradigm.
0
0
3
AI will continue to improve, become more useful for more people, and might even create beautiful things, but people will always cherish the productions of the human spirit
0
0
2
@madmaxbr5
@YiTayML
@GoogleAI
This is like the original DSI paper were we directly train a Transformer on inputs->docid, but we find that the best inputs are synthetic queries generated from the contents of the document/passage itself (among other things.)
0
0
3
google


0
1
3
Some of the most fun I’ve had was doing research with Yi at Google, excited to see how your next adventure plays out and congrats! 😄
Over the past 3.3 years at Google, I have been blessed with so many wonderful friendships and experiences.
I have grown so much. However, it’s time to move on to a new adventure!
I wrote a blogpost about my wonderful experience here:
65
63
990
1
0
3
@LukaszBorchmann
@AiParticles
@arankomatsuzaki
@ytay017
@seb_ruder
@GoogleAI
Thanks for pointing this out! This is indeed not true anymore for the current version of the model, we've updated the preprint and it should be up on Monday
1
0
2
4. Is this because the corpus is too big to encode in the parameters of the model? Surprisingly, performance maxes out at 3B parameters, and does slightly worse at 11B. More research is needed to unlock the power of larger language models. 5/n
1
0
2
Please see the paper for more intuitions, analysis, and nuance. Shout out to great collaborators
@rpradeep42
,
@kaihuibj
,
@_j_ai
, Adam D. Lelkes,
@HongleiZhuang
,
@lintool
, &
@metzlerd
! n/n
0
0
2
1
0
1
3. After establishing these best practices, we scale up corpus size, and observe that the paradigm significantly struggles past 1M passages. Previously proposed techniques that seem to work only work because they add on more parameters, and lose to scaling up naive methods. 4/n
1
0
1
@DevSeth44
Very interesting. We did a similar, but very basic, analysis of degradation under human-readable obfuscation when building the latest generation of Jigsaw Perspective API ()
0
0
1
1. We ablate several techniques in the literature and find that document representation is the most important factor, and by ablating for the right one we happen to set a new SOTA result for small corpus retrieval (NQ, 100k docs), without the need for any fancy methods (lol) 2/n
1
0
1
2. On MS MARCO passages, using synthetic queries generated from the passages as the document representation is the *only* technique necessary for retrieval performance (+ appropriate model scale). This is competitive with SOTA dual encoders (i.e. GTR) on the 100k subset. 3/n
1
0
1