
Alexander Kolesnikov
@__kolesnikov__
Followers
4,838
Following
175
Media
29
Statuses
380
Staff Research Scientist at @googledeepmind , Zürich. I like making things simpler. Co-creator of BiT, ViT, MLP-Mixer, UViM, SigLIP, Paligemma.
Zurich
Joined January 2019
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Cheney
• 362216 Tweets
Eagles
• 228072 Tweets
Packers
• 131884 Tweets
ENGFA ACTRESS 100M
• 102564 Tweets
श्री गणेश
• 101074 Tweets
Ganesh Chaturthi
• 87524 Tweets
Ganesh Chaturthi
• 87524 Tweets
#ATIPASHOPxCHARLOTTESNACK
• 82202 Tweets
Saquon
• 74596 Tweets
Perú
• 73840 Tweets
गणपति बप्पा
• 73341 Tweets
Jalen
• 57356 Tweets
Green Bay
• 37672 Tweets
भगवान गणेश
• 35959 Tweets
#キントレ
• 32975 Tweets
Jordan Love
• 30718 Tweets
#二度と撮れない画像を貼れ
• 27534 Tweets
Duke
• 25916 Tweets
#GanpatiBappaMorya
• 25546 Tweets
श्री सचिन पायलट
• 20349 Tweets
Lucho
• 14854 Tweets
#音泉祭り
• 14253 Tweets
ビッグラン
• 14188 Tweets
Jayden Reed
• 13860 Tweets
Party Love AndaLookkaew
• 13740 Tweets
JustinOn NCAA100Kickoff
• 13304 Tweets
イコラブ
• 12510 Tweets
#2024TRUSTY_IN_BANGKOK
• 10360 Tweets



















Pinned Tweet

We've landed a big revamp of . The main new feature is support for flexible weight sharding, which doesn't get in the way of cutting-edge research code. Scaling ViTs, ResNets, MLP-Mixers, SigLIPs (and so on) beyond single GPU/TPU device memory becomes easy.

1
32
287
Vision meets RL! We reveal that policy gradient can be used for tuning vision models to optimize complex metrics, such as mAP, PQ or “color diversity”, observing large performance boosts on tasks like object detection, panoptic segmentation, etc.

4
131
641
I've always been frustrated that, beyond image classification, computer vision is full of complex and task-specific components.
Thus, very excited to share our new work, where we propose a unified modeling approach for vision: .
More in the thread🧵.
6
126
597
Let me introduce big_vision: an original home of ViT, MLP-Mixer, LiT and many more.
These days I do all my research in this codebase: it is great for doing vision research with emphasis on large-scale pretraining and transfer.
Highlights in 🧵 ⬇️
Link:
3
83
488
We release pre-trained vision transformer models and code for inference/fine-tuning: . There is still a long way towards understanding transformers in vision and I am looking forward to the future research. Hope this release will be a good starting point.

6
102
443
We just released PaliGemma-3B, a very capable Vision-Language Model. Do not waste any time, finetune it for your task:
Code:
Colab:
Kaggle:
HF:
Vertex AI:
5
58
322
MLP-Mixer (a new vision architecture based on MLP only) code and pretrained models are now available: .
Looking forward to community contributions that will shed some light on how Mixer works and how to make it even better.
paper: .

4
83
313
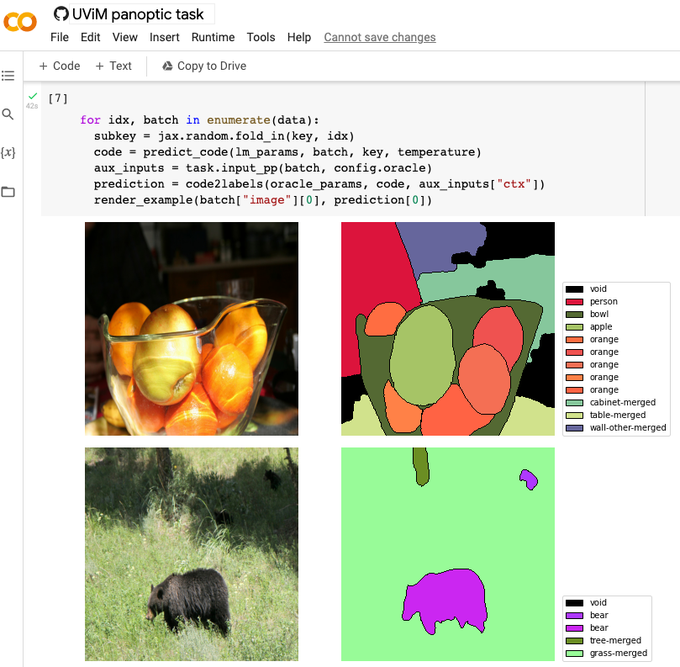
We have opensourced UViM models and complete training/inference/eval code. You can now train new models yourself and explore the released models (and UViM guiding codes) in the interactive colabs. All available at .
UViM paper: .
3
47
212
Also an interesting survey on MLP-Mixer and concurrent/follow-up research:
Crazy all of it happened in ~6 months only.


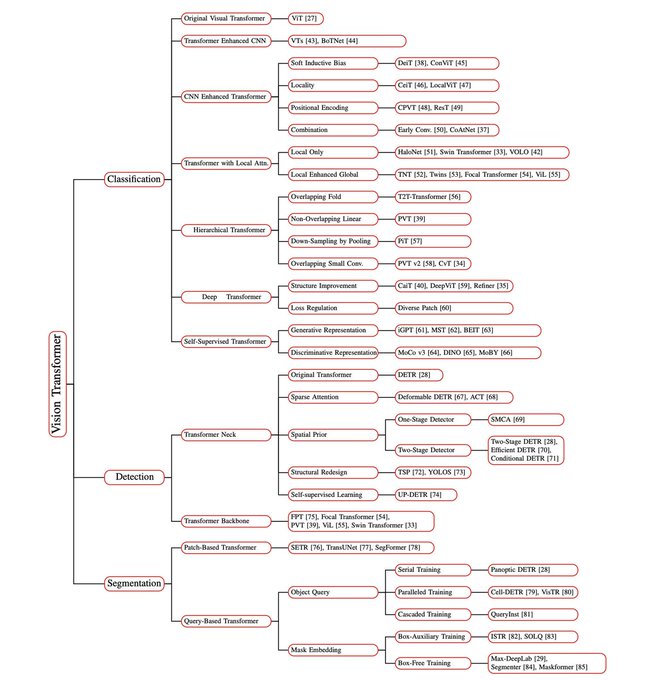
An incredibly thorough-looking survey of Vision Transformers!
It only been just over a year since we published ViT. I thought it would be useful, but didn't imagine this much cool innovation would happen.
7
180
995
1
47
199
Do not want to miss out on the recent trend, so I officially announce that
1. All my ICML 2022 papers were rejected.
2. All my ICML 2022 papers were accepted.
3. Both statements above are true.
9
6
181
Our PaliGemma technical report is finally out: .
We share many insights that we learned while cooking the PaliGemma-3B model. Both about pretraining and transfer.


✨PaliGemma report will hit arxiv tonight.
We tried hard to make it interesting, and not "here model. sota results. kthxbye."
So here's some of the many interesting ablations we did, check the paper tomorrow for more!
🧶

20
117
858
3
30
168
🤯 PaliGemma for real-time object detection.

Got fast paligemma inference working on RTX 4090. Here's an object detection demo with the the 224px model running in real time at 16fps. I generate 10 tokens per iteration
28
51
674
1
14
129
Concurrent Mixer-like model, but applied to NLP and with fixed token-mixing MLPs with Fourier features. When writing Mixer paper we looked at our learned params and
@tolstikhini
had an immediate reaction: "looks like Fourier" and then we thought of doing exactly same thing later.


FNet: Mixing Tokens with Fourier Transforms
pdf:
abs:
Transformer encoder architectures massively sped up, with limited accuracy costs, by replacing self-attention sublayers with simple linear transformations
that “mix” input tokens



1
10
81
1
23
119
Notably, full model code is extremely compact and simple; and with large-scale pretraining it gets to 87.78% on ImageNet.

4
23
113
New paper 🧵 : How to train your ViT? It is common to train vision transformers on ImageNet-1k (~1.3m images) for 300 epochs. We show that you are better off investing the same compute budget for training on ImageNet-21k (~13m images) for 30 epochs.

4
26
111
Plot twist: the model uses a LM pretrained on the whole internet, and, in particular, it read and memorized our paper showing CIFAR10 test annotation mistakes. As a result, it got to 100% on a noisy test set.

I recommend the authors checking Fig. 8 from BiT paper (). On Cifar10 there’re some wrong ratings, an expert may not perform 100% on Cifar10. There’s either a bug in their eval code, or the model sees all the test examples.

1
3
43
3
10
97
We had a similar observation when doing preliminary investigations for . Vanilla REINFORCE with 2 samples (one for baseline, the other for the update) is good enough to steer vision models in the right direction.


PPO has been cemented as the defacto RL algorithm for RLHF.
But… is this reputation + complexity merited?🤔
Our new work revisits PPO from first principles🔎
📜
w
@chriscremer_
@mgalle
@mziizm
@KreutzerJulia
Olivier Pietquin
@ahmetustun89
@sarahookr

13
100
483
2
15
97
And now we fell victims ourselves: the absolutely great DALLE 2 paper does not cite ViT paper🥲.
@giffmana
On this topic, its funny how some things are too well known to cite (they are just part of common language, and often lower-cased), but not others. Adam really hit a sweet spot, being nearly ubiquitous and cited in most usages. My guess is its partialy in the name.
1
0
19
4
5
91
@karpathy
number of iterations is not enough when there is a batch dimension of some sort. For example, in vision the "number of images seen" is by far the best proxy for measuring training duration in the large-scale regime.
3
2
88


This simple pytorch trick will cut in half your GPU memory use / double your batch size (for real). Instead of adding losses and then computing backward, it's better to compute the backward on each loss (which frees the computational graph). Results will be exactly identical

43
266
2K
3
8
87
After a 4 year long break from conferences (special "thanks" to the pandemic and visa constraints), I have finally made it to ICLR @ Vienna. Hope I have not missed too much. Btw, when is the poster session about ResNets trained on ImageNet?
2
0
80
@sherjilozair
@evgeniyzhe
can be quite good. T5 paper uses such learning rate: . And I often use it, eg here we even have a section (3.5) about it.


3
4
65
Read this thread and tell me how 3 private, delayed and very noisy reviews are the cornerstone of the ML/CV fields, and open discussions in social media should be banned, until it effectively becomes irrelevant to have such discussion.

1
3
58
PaliGemma VLM was pre-trained with segmentation tasks and has the ability to produce dense masks. This capability needs some extra complexity related to (de)tokenization of segmentation masks and we have not documented it well yet.
But
@skalskip92
has it all figured out 👇

I finally managed to fine-tune PaliGemma on the custom segmentation dataset
most of you have probably noticed that I've been spamming all sorts of PaliGemma tutorials for the past few weeks; I have one more
shoutout to
@__kolesnikov__
for all the help!
↓ read more + code

10
51
288
0
9
51
@FrancescoLocat8
@giffmana
ArXiv's 1-3 days publication cycle is too slow given the current research pace. Publishing in-flight overleaf projects is the future.
3
2
50
And at the same time all of them are looking at MLPs.

So, CV researchers are looking at transformers and NLP researchers are looking at CNNs (again). What a strange world.
16
51
726
0
2
48
Checkout our paper for more: .
The code will be made available at , stay tuned.
This is the joint work with André Susano Pinto,
@giffmana
,
@XiaohuaZhai
,
@JeremiahHarmsen
and
@neilhoulsby
.
0
4
42
Incredible to see people already doing useful stuff with PaliGemma by finetuning it on custom data. Great progress,
@skalskip92
@__kolesnikov__
Awesome! After a bit of trial and error, I managed to fine-tune the model using a custom object detection dataset. The Google Colab works great.
I have one more problem. How can I save a fine-tuned model? Really sorry if that's a stupid question, but I'm new to JAX and FLUX.

3
3
16
0
7
40
Are we still making meaningful progress on ImageNet? What happens if we carefully re-annotate ImageNet val set? How to improve ResNet-50 top-1 accuracy by 2.5% by cleaning training data and using different loss function? See our new paper for the answers: .
Are we done with ImageNet? That's what we set out to answer in with
@olivierhenaff
@__kolesnikov__
@XiaohuaZhai
@avdnoord
. Answer: it's complicated. On the way, we find a simple technique for +2.5% on ImageNet.



2
33
95
2
11
40
and after 7 years I can still tell in 0.1 seconds that it is pixelcnn++ samples

I feel like I have to once again pull out this figure. These 32x32 texture patches were state of the art image generation in 2017 (7 years ago). What does it look like for Gen-3 and friends to look similarly silly 7 years from now.

110
296
3K
0
0
39
Thank you
@ISTAustria
and
@hetzer_martin
for the award, I am deeply honored to receive it. And thank you to
@thegruel
for being the exceptionally great and supportive PhD supervisor.

@__kolesnikov__
receives the
@istaustria
Alumni Award 2023! “This recognition holds special significance for me, as ISTA has played a pivotal role in shaping me as a scientist”. Congratulations and we are excited to see what comes next for you.


2
1
10
4
3
36
Finally, a Google AI Blog post about BiT, our state-of-the-art visual model. And to show that we are serious, we release code in three deep learning frameworks: TF2, PyTorch and Jax. Check it out:


Presenting BiT, an open-source approach for large-scale pre-training of models covering a wide range of visual tasks, which highlights the importance of choices in the model architecture for downstream performance. Learn all about it below:
9
230
725
0
11
35
At ICCV and curious about semi-supervised learning with self-supervision? Come to our talk today at 15:20 in Hall D1 or chat with us at poster
#20
from 15:30 to 18:00. , Code: . Joint work with
@XiaohuaZhai
@avitaloliver
and
@giffmana

0
15
35
It turns out that distillation yields wildly different results depending on subtle choices. But if done right, works consistently great for model compression, i.e. results in ~83% ImgNet with R50. What does "right" mean? Check out or a 🧵 from
@giffmana
👇
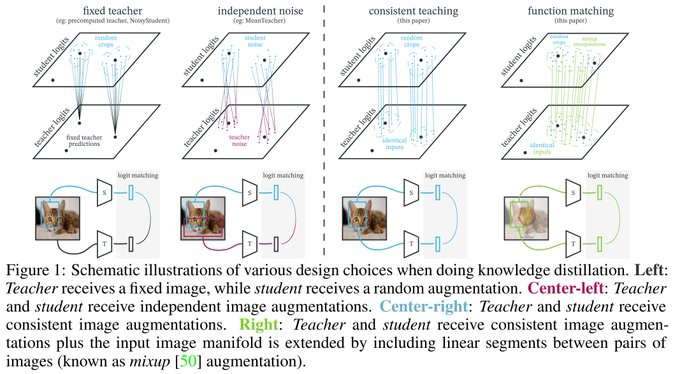
So you think you know distillation; it's easy, right?
We thought so too with
@XiaohuaZhai
@__kolesnikov__
@_arohan_
and the amazing
@royaleerieme
and Larisa Markeeva.
Until we didn't. But now we do again. Hop on for a ride (+the best ever ResNet50?)
🧵👇
8
128
654
0
8
35
Check out a thread on our recent image-text project from
@giffmana
.
My personal tl;dr: when learning a joint embedding space for image-text (e.g. CLIP-style), you are much better off by *freezing* an image embedding that was pre-trained on the standard image data like ImageNet.
Want to turn any vision backbone into an image-text model? Want to show the age-old "your model wouldn't recognize a cow on the beach" is a red herring?
That's LiT🔥 (Locked-image Tuning), a new alternative to fine-tuning that combines the best of fine-tuning and zero-shot
1/n🧶

6
96
523
2
10
33
That is an appealing perspective on ViT and Mixer. Nevertheless, I think it really misses the point. There is a lot to unpack here, so let's do a thread(🧵).

@ykilcher
@GoogleAI
@neilhoulsby
@giffmana
@__kolesnikov__
This only really works when you have access to JTF300M and google money/compute. As EfficientNetV2 showed, if you have constraints (eg training efficiency - Fig 1; model size, FLOPs, and inference latency - Fig 5) use the EfficientNetV2 network instead of a "crap architecture".
1
0
9
2
7
33
This is a nice idea and also a perfect excuse to advertise my quite old paper, where we propose almost exactly the same: a method to categorise class maps into "objects" or "distractors" with virtually zero human supervision (few clicks per class):


📢 We now release "Salient ImageNet", a dataset with "core" and "spurious" masks for entire ImageNet!
Website:
with
@sahilsingla47
,
@MLMazda
Such a richly annotated dataset can be useful for model debugging, generalization, interpretation, etc. 1/n
3
25
109
0
6
32
Our modeling approach works out-of-the-box and very competitively (with no modifications and sharing the majority hyper-params) on three diverse vision tasks: panoptic segmentation (scene understanding), colorization (conditional image modeling) and depth prediction (3D).

1
2
33
Waiting for timm to follow the trend ;)

🔥JAX meets Transformers🔥
@GoogleAI
's JAX/Flax library can now be used as Transformers' backbone ML library.
JAX/Flax makes distributed training on TPU effortless and highly efficient!
👉 Google Colab:
👉 Runtime evaluation:

3
113
532
1
2
31

1
1
31
The key insight is to go beyond standard supervised learning which learns to “imitate” training data. We let the model “act” and then “criticize” the outcomes, like in RL. More specifically, we score predictions with rewards and use the REINFORCE rule to update model parameters.

1
2
31
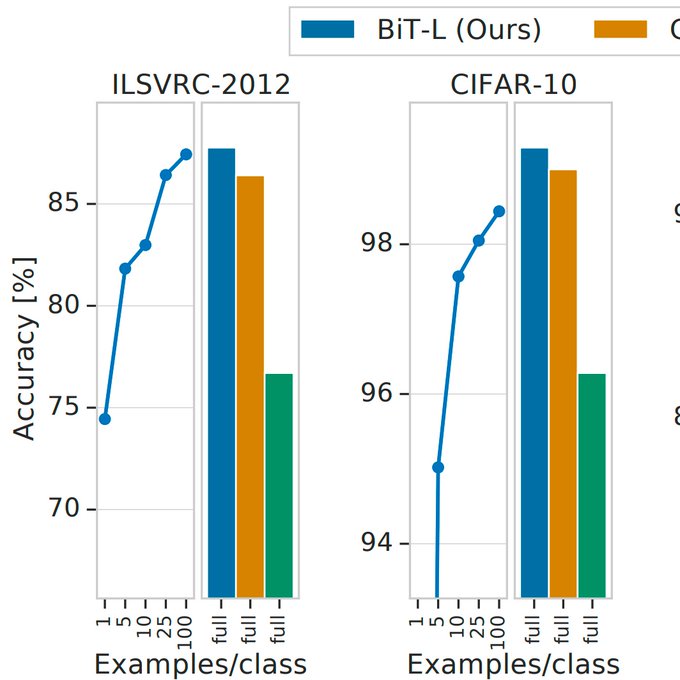
Training models at scale beyond ImageNet is challenging. We devise a recipe for learning visual representations from >100M images. Beside "obligatory" SOTA on ImageNet/CIFAR, we get great results in the low data regime transfer with a single hyper-param!
We distill key components for pre-training representations at scale: BigTransfer ("BiT") achieves SOTA on many benchmarks with ResNet, e.g. 87.8% top-1 on ImageNet (86.4% with only 25 images/class) and 99.3% on CIFAR-10 (97.6% with only 10 images/class).
2
45
154
0
8
31
@karpathy
The question is partially addressed here (as a by-product of studying the effect of the batch size): . For example for ImageNet they show that until the batch size becomes huge, the number of images seen is the only thing that matters:

1
1
30
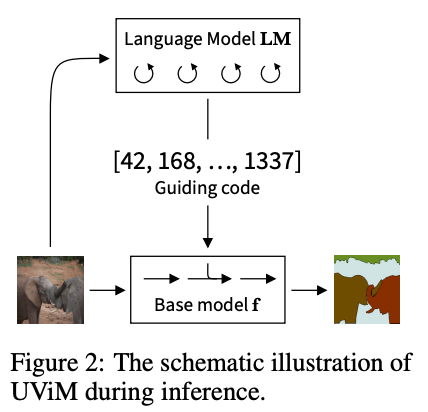
The main idea is to learn a compact discrete "guiding code" that aids the simplest possible model to solve a given task with no custom components. The guiding code is derived from the ground truth, so we do not yet have the final prediction model...

2
4
30
Happy to see that my past "Imagenet SOTA" academic exercises turned out to be beneficial for real and useful vision applications. Deep down I was not sure it will ever be the case.

New paper from our team
@GoogleHealth
/
@GoogleAI
() Pre-training at scale improves AI accuracy, generalisation + fairness in many medical imaging tasks: Chest X-Ray, Dermatology & Mammography! Led by
@_basilM
,
@JanFreyberg
, Aaron Loh,
@neilhoulsby
,
@vivnat

1
20
97
0
2
26
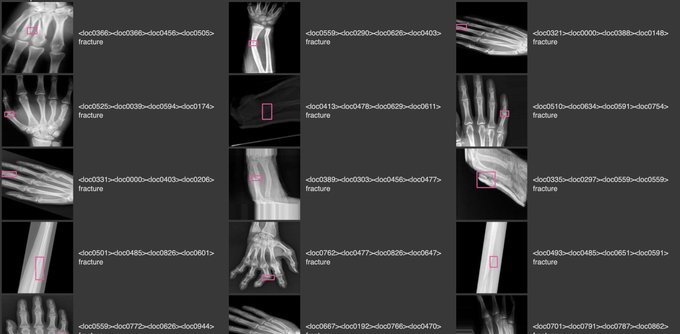
PaliGemma being used as intended 👇
I fine-tuned my first vision-language model
PaliGemma is an open-source VLM released by
@GoogleAI
last week. I fine-tuned it to detect bone fractures in X-ray images.
thanks to
@mervenoyann
and
@__kolesnikov__
for all the help!
↓ read more
30
196
1K
2
2
23
This is almost true, but there is a catch: our "token-mixing" MLP corresponds to the depth-wise convolution with a single(!) shared filter for all channels. We discuss this in the paper:


This is basically xception with a (valid padded) receptive field with the size of the whole image.
2
1
46
1
1
23
Nice PaliGemma tutorial, enjoyed watching it.
A comment regarding your struggles with getting good mAP for detecting multiple objects: it is a known limitation of all log-likelihood generative models and we wrote a whole paper on how to address it: .

new tutorial alert: fine-tune PaliGemma on a custom object detection model
- understanding the capabilities and applications of the PaliGemma
- fine-tuning PaliGemma for custom object detection tasks.
- troubleshooting common issues
link:
5
56
302
2
2
24
UViM can readily produce multiple diverse and coherent outputs by resampling the guiding code from the language model.

1
2
23
Also live demo: .
I hope it will survive the traffic.

0
4
21
It was indeed a great year (in science at least), thanks to all amazing collaborators who made this happen
@giffmana
@XiaohuaZhai
@joapuipe
@JessicaYung17
@sylvain_gelly
@neilhoulsby
Alexey Dosovitskiy
@dirkweissenborn
@TomUnterthiner
@m__dehghani
@MJLM3
Georg Heigold
@kyosu
.
I always see people humble-brag on twitter. What happens if I just plain shameless-brag? Will a black hole appear under my feet? Let's find out! Two of my papers with code (BiT + ViT) are in top10 of 2020, yay! Let's keep up that trajectory
@__kolesnikov__
@XiaohuaZhai
etal. :)
2
4
67
0
1
20
It is only a matter of time until such large datasets will become more and more accessible. Hardware also becomes cheaper. When this happens, it is good to be prepared and have a large arsenal of models with different degree of built-in inductive biases.
0
1
19
More models are coming soon, so stay tuned. Further details are in the arxiv paper: .
1
0
17
Our approach works best for probabilistic models that are capable of sampling multiple coherent predictions. Luckily, many such models were very recently proposed for vision tasks: pix2seq, Unified-IO, UViM, PaLI, X-Decoder, …
1
1
18
but we now can learn a standard and powerful language model to predict the guiding code from the input image.

1
1
17
As a result, our final universal model (called UViM) is a composition of a simple feed-forward (e.g. ViT-B) and a standard language model.

1
1
17
We have released very strong image-text contrastive models from the SigLIP paper . Check out this colab: .

Pleased to announce we are releasing checkpoints for our SigLIP models!
These are very strong image-text ViTs. We release them along with a colab to play around with. Most are english, but we also release a good i18n one.
Sorry, no magnet link mic drop. More in thread🧶
14
68
399
0
1
16
I am at CVPR, DM me if you want to meet in person.
5
1
16
This is the joint work with
@ASusanoPinto
,
@YugeTen
,
@giffmana
and
@XiaohuaZhai
, done at
@GoogleAI
, Brain Team Zurich.
2
0
14
A novel interpretation of VAE as non-linear PCA.

We looked into visual disentanglement mathematically. Turns out the canonical (beta-)VAE (by accident) does what one would want from deep PCA! Accepted to
#cvpr2019
.
#deepPCAexists

5
108
435
0
2
15
In our experiments, we tune an object detection model to increase recall, and accordingly the mAP metric. We also improve a panoptic segmentation model to predict more coherent masks, or even optimize for exotic rewards, such as color diversity in the colorzaiton task.



2
1
15
Training on large data comes with an extra cost, but it needs to be done once. Later, these models can cheaply be adapted to small datasets (even with a few samples per class) and achieve great results for a many vision applications. It effectively amortizes pre-training costs.
2
1
15
@yoavgo
GroupNorm works equally well in Vision and it does not depend on the batch dimension. I doubt this explanation is correct
1
0
15
In big_vision we strive to avoid too many abstractions and keep the core research code explicit. Our main train loop may seem a bit verbose, but at the time it is very explicit, so trying brave research ideas is often quick and easy.
1
0
14
Work done with
@tolstikhini
,
@neilhoulsby
,
@giffmana
,
@XiaohuaZhai
,
@TomUnterthiner
,
@JessicaYung17
,
@keysers
,
@kyosu
,
@MarioLucic_
, Alexey Dosovitskiy. And special thanks to Andreas Steiner for outstanding support with opensourcing.
1
1
12
We've put a lot effort to make the code scalable. The code is optimized for TPUs and just runs with little or no overhead on anything from a single TPU core to a distributed setup with 2048 TPUs. It also just works out-of-the-box on multi-gpu machines.
1
0
12
SigLIP in timm 🎉
Thanks
@wightmanr
!

Don't forget to update your timm version to latest (0.9.8+)! The SigLIP support is via timm backbone and can be loaded in both timm and OpenCLIP from same
@huggingface
hub models.
0
0
6
1
1
13
We are sure there are lots of interesting insights to be drawn from our collection of trained ViTs. So we release them all: >50'000 models!
JAX repo: .
JAX colab:
Or also available in pytorch through timm: .
1
3
12
Why so? Paired image-text data is good for *aligning* the multimodal embeddings, but not that good for learning the visual embedding itself, where ImageNet-like data still shines. In a way we disentangle alignment and embedding learning.
2
0
12
There are likely some rough edges in the revamped code that we will improve over time. Glad to see big_vision is recognised by the leading OSS engineers: . Gives us additional motivation to keep big_vision up-to-date with the latest advances.
On the importance of OSS training reproductions (a focus of mine). Much of the progress here since the original OpenAI model/weight releases traces back to two open source code bases, the OSS community OpenCLIP (PyTorch) and Google Big Vision (JAX) proj.
3
9
125
1
2
11
Impressive demonstration of how to successfully adapt the BERT model for solving custom NLP tasks by tuning a small amount of parameters.
It turns out that only a few parameters need to be trained to fine-tune huge text transformer models. Our latest paper is on arXiv; work
@GoogleAI
Zürich and Kirkland.
#GoogleZurich
#GoogleKirkland
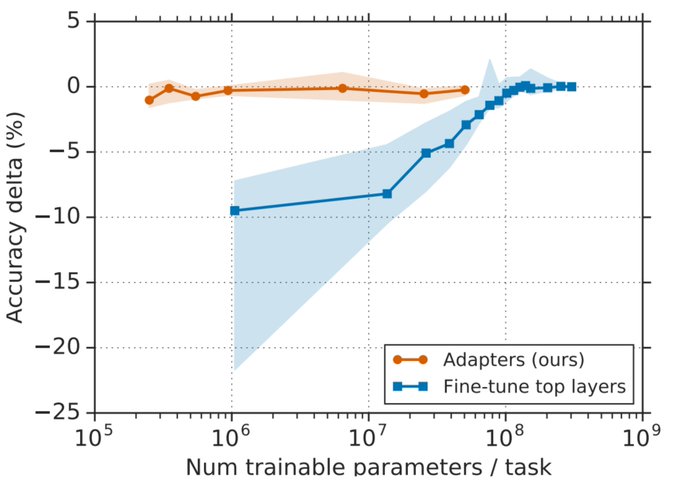
0
43
121
0
3
10
Self-supervision is effective for semi-supervised learning. Check out our work () with
@XiaohuaZhai
,
@avitaloliver
and
@giffmana
for details.
Want to turn your self-supervised method into a semi-supervised learning technique? Check out our S⁴L framework ()!
Work done at
@GoogleAI
with
@avitaloliver
,
@__kolesnikov__
and
@giffmana
.

2
35
117
0
4
11
All powered by the genius jax.Array and jax.jit API, which was recently revised to support global sharded computations. Shout-out to jax developers for doing such great work
@yashk2810
@jakevdp
@froystig
@SingularMattrix
(and more, but it is everyone I found on X).
1
1
11
@skalskip92
You can use for this:
import big_vision.utils as bv_utils
flat, _ = bv_utils.tree_flatten_with_names(flat)
with open("ckpt.npz", "wb") as f:
np.savez(f, **{k: v for k, v in flat})
And then load:
bv_utils.load_checkpoint_np("ckpt.npz")
2
1
10
One of my favourite parts is model evaluation. It is designed to run frequently during the training with almost no overhead: it may take as little as few seconds for a full ImageNet eval. We also can do on-the-fly(!) few-shot evaluation on multiple downstream datasets.
1
0
9
At the moment, we release the main bits of big_vision, but many updates will come soon, including ImageNet-21k support, Mixer models and separate releases of individual projects done in big_vision.
Stay tuned!
1
0
9
big_vision is a joint work with
@giffmana
,
@XiaohuaZhai
and myself, with many great contributions from Brain team members. Special shout-out to
@AndreasPSteiner
for making a great optax-based optimizer library for big_vision.
0
0
9
This code upgrade was done together with my
@GoogleDeepMind
colleagues
@giffmana
@ASusanoPinto
@AndreasPSteiner
@XiaohuaZhai
.
1
0
9
Very nice thread summarizing our recent "Big Transfer" paper on large scale pre-training of visual models ().

0
0
9
One of my favourite new jax features is jax.shard_map (). It allows you to "override" jax.jit when automatic partitioning is not doing the right thing. For example, in big_vision we use shard_map to implement device-local "mixup":

1
3
9
@stanislavfort
@sarahookr
shameless plug: my colleague
@ibomohsin
have also extended scaling laws further to infer model's optimal shape (width, depth, etc): . We use these laws routinely.
1
0
9
Models pretrained on JFT-300M are not released, because it is a proprietary dataset. However, papers like CLIP() or ALIGN() have shown large scale data for pre-training can be collected automatically with modest engineering costs.

1
3
8
@norpadon
This paper also prescribes how it can be done in a principled way: . And it has many more gems.
1
1
8
@giffmana
Exponential spike in space garbage that will prevent or hinder space exploration is a real scenario:

1
0
8
@roydanroy
@askerlee
this was a joke, though I would not rule out that a well-done hybrid of a LLM and an image recognition model will do this, when prompted appropriately.
3
0
8
Most of the nice things we have in the codebase are there thanks to XLA/JAX/FLAX. They are very powerful tools, but know how to get out of the way and enable flexible research.
1
0
7
@skalskip92
Yes! The prefix (aka prompt) looks like this:
detect: red car ; cat ; yellow bus
The corresponding suffix (aka output) is
<loc0072><loc0003><loc0905><loc1019> red car ; <loc0272><loc0140><loc0821><loc0851> cat ; <loc0378><loc0003><loc0424><loc0069> yellow bus
3
1
8
Models like ViT or Mixer sacrifice some of the inductive biases and instead rely on larger training data to automatically discover potentially different and maybe even better inductive biases.
1
0
8
It turns out that massively scaling up model size and training data results in a drastic jump of image classification accuracy in a challenging real-life setup. See our updated paper for details and additional surprising results that include low-data eval:
We just updated our Big Transfer (BiT) paper with ObjectNet results. Pre-training of large models shows huge improvement on this "in the wild" vision task: almost +30% absolute! ()

0
19
59
0
0
8
As a nice by-product you can turn any pre-trained vision backbone of your choice (e.g. BiT, MobileNet, ViT, MLP-Mixer, Swin, ConvNeXt, ...) into 0-shot classification model without modifying its weights.
1
0
7
But this is just one out of many highlights. We also conduct extremely thorough study on the interplay of model size, dataset size, regularizations and augmentations. Plus extensive transfer learning experiments. Check out our paper if you want to learn how to train ViT models.


2
1
7
For example, enabling FSDP training boils down to adding a few lines in the config. For more advanced use-cases, e.g. model-parallel flavour, users can write extra model-specific sharding logic, which is localised in one place and does not add mental overhead for doing research.

1
2
7


In short, there is a discrepancy between what log-likelihood loss for detection is optimising and what is good for mAP (or for whatever a user wants). Luckily, an additional lightweight Reinforcement Learning tuning can be used to align the model with the end goal.

1
0
7
Check out our tensorflow2 tutorial: fine-tuning recent state-of-the-art BiT visual models () without pain (and BatchNorm!) on your data of choice.

Announcing BigTransfer: pre-trained models for easy and effective transfer learning for vision with TF-Hub!
Check out this walkthrough to view examples of high-performing BiT models and learn how to train an image classifier.
🔎 Learn more →

3
69
255
0
1
6
@skalskip92
We generally encourage to use tensorstore in big_vision, see `tssave` and `tsload` functions in big_vision , as it scales much better for really big checkpoints. That is why numpy utils are not very prominent, but numpy should be good enough for paligemma.
1
0
6
@karpathy
In my personal experience, I was able to scale batch size even further without taking any losses. That said, at some point this nice relation seems to break and for ImageNet-like tasks it seems to hold the best.
0
0
6