
Xiaohua Zhai
@XiaohuaZhai
Followers
3,411
Following
243
Media
41
Statuses
263
Senior Staff Research Scientist @GoogleDeepMind team in Zürich
Zürich, Switzerland
Joined March 2013
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Terörist
• 129299 Tweets
Devlet Bahçeli
• 66919 Tweets
期日前投票
• 64071 Tweets
Öcalan
• 62764 Tweets
Chris Kaba
• 56359 Tweets
TBMM
• 43182 Tweets
LINE MAN JOONG DUNK
• 31441 Tweets
Gazi
• 27265 Tweets
WELCOME BACK GUCCI JIWOONG
• 24874 Tweets
#よにのANNP
• 22687 Tweets
Meclise
• 21647 Tweets
Yazıklar
• 16752 Tweets
かぼちゃ大作戦
• 16591 Tweets
Star Time
• 16464 Tweets
DEM Parti
• 14664 Tweets
Milliyetçi
• 14096 Tweets
#一番遠い親戚さん
• 11333 Tweets
NICE2MEET ARCARM
• 10167 Tweets

















Pinned Tweet

📢📢We release the SigLIP models to big_vision, pre-trained on WebLI, before our ICCV trip to Paris.
A SigLIP Base model achieves 79% 0-shot acc. on ImageNet, a Large model achieves 82% 0-shot acc. on ImageNet.
Demo:
Arxiv:
👇🧵

1
17
112
📢📢We release the Big Vision codebase, a JAX library originally used to develop ViT, Mixer, ViT-G, LiT, and more!
Together, a better plain ViT-S/16 baseline (76.5% ImageNet, 90 epochs) is provided, as a simple and strong starting point.
Github:
1/n🧶

2
78
421
📢📢 I am looking for a student researcher to work with me and my colleagues at Google DeepMind Zürich on vision-language research.
It will be a 100% 24 weeks onsite position in Switzerland. Reach out to me (xzhai
@google
.com) if interested.
Bonus: amazing view🏔️👇

6
28
241
Want to turn your self-supervised method into a semi-supervised learning technique? Check out our S⁴L framework ()!
Work done at
@GoogleAI
with
@avitaloliver
,
@__kolesnikov__
and
@giffmana
.

2
35
116
I'm excited to share PaliGemma, an open vision-language model that can be fine-tuned within 20 minutes.
You'll be impressed by how far it goes with only batch size 8 and step 64. Try it out yourself, with your free Google Colab account and T4 GPU:


We’re introducing new additions to Gemma: our family of open models built with the same technology as Gemini.
🔘 PaliGemma: a powerful open vision-language model
🔘 Gemma 2: coming soon in various sizes, including 27 billion parameters
→
#GoogleIO

26
127
658
0
14
94
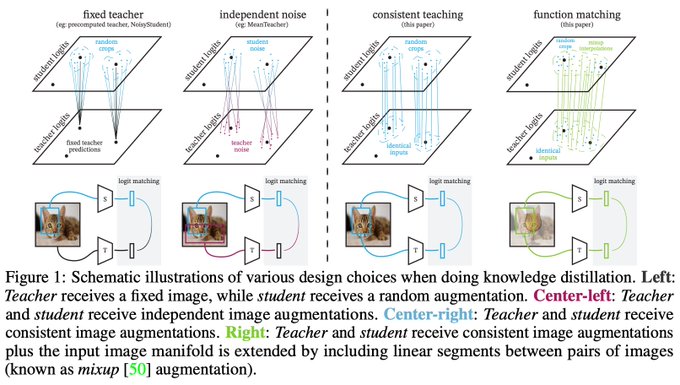
Wondering how to distill big vision models?
Check our recipe: a good teacher is patient and consistent!
Thanks to patience and consistency, we obtained the best ever ResNet-50 on ImageNet, of 82.8% accuracy without tricks.
Paper:
1
18
94
We study scaling laws for Vision Transformer, and characterize the relationships between error rate, model size, data, and compute.
Our ViT-G/14 with 2B params, pre-trained on 3B images, attains a new SOTA on ImageNet of 90.45% accuracy!
Paper:

4
17
90
We introduced PaliGemma at Google I/O. I would like to quote a few links in this thread for developers, most importantly, share our new academic program to support PaliGemma research with Google Cloud credits🧵

1
18
80
Working on scaling deep learning models? Curious on extrapolating model behaviors on larger data and models without actually training them? Check our NeurIPS 2022 paper on scaling laws, which extrapolates more accurately than previous methods across vision and language domains.

3
8
80
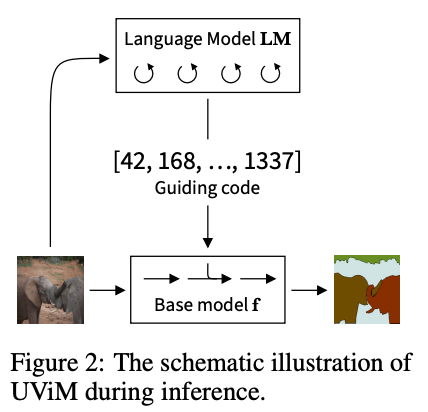
We introduce UViM, a unified modeling approach for vision without requiring task-specific knowledge.
UViM first learns to compress the task output (e.g. panoptic segmentation) into a discrete guiding code. Then a vanilla language model is adopted to generate the guiding code.


1
11
71
Locked-image Tuning (LiT🔥) is an alternative method to fine-tuning. It turns any pre-trained vision backbone to a zero-shot learner!
LiT achieves 84.5% 0-shot acc. on ImageNet and 81.1% 0-shot acc. on ObjectNet, and it's very sample efficient.
Arxiv:



Want to turn any vision backbone into an image-text model? Want to show the age-old "your model wouldn't recognize a cow on the beach" is a red herring?
That's LiT🔥 (Locked-image Tuning), a new alternative to fine-tuning that combines the best of fine-tuning and zero-shot
1/n🧶

6
96
523
2
16
67
We are excited to release LiT🔥 (Locked-image Tuning) models. Want to try out LiT models on your own problems? Check out
#lit_demo
first, please tweet fun examples!
Demo:
Models:
Arxiv:


Read all about Locked-Image Tuning, which combines the best of transfer learning and contrastive image-text learning to achieve state-of-the-art zero-shot classification accuracy. Learn more and try the demo! ↓
5
51
200
2
7
56
We introduce PaLI, a language-image model trained on WebLI, that achieves great results across 100 languages.
Work done with many amazing colleagues from Google Research!
Paper:
Blogpost:
🧶👇
2
11
58
Though we didn't release the PaLI-3 models, we have released multilingual and English SigLIP Base, Large and So400M models to .
Thanks to
@wightmanr
, SigLIP models are now available in Hugging Face🤗
Try them out!
🧶PaLI-3 achieves SOTA across many vision-language (and video!) tasks while being 10x smaller than its predecessor PaLI-X.
At only 5B parameters, it's also smaller (and stronger) than the concurrent Fuyu-8B model, though sadly we cannot release the model (props to
@AdeptAILabs
)

9
59
445
1
8
48
Loss != Metric? Check our paper on optimizing directly for your vision problem with complex metrics.
A typical example is reward tuning for pix2seq style object detection: it improves the mAP from 39% (without tricks) to 54% on COCO with a ViT-Base architecture.


Vision meets RL! We reveal that policy gradient can be used for tuning vision models to optimize complex metrics, such as mAP, PQ or “color diversity”, observing large performance boosts on tasks like object detection, panoptic segmentation, etc.

4
131
640
0
7
48
I recommend the authors checking Fig. 8 from BiT paper (). On Cifar10 there’re some wrong ratings, an expert may not perform 100% on Cifar10. There’s either a bug in their eval code, or the model sees all the test examples.


"Learning with Signatures" ()
Whoa, they achieve 100% test accuracy on MNIST and CIFAR-10 🤯.
Impressive or rather suspicious given that MNIST has mislabeled examples () -- and the same is probably true for CIFAR-10 🤔?

22
39
393
1
3
43
PaliGemma is now available in KerasNLP👏

The PaliGemma vision-language model is included as part of the latest KerasNLP release! Works with JAX, TF, and torch.
There's a lot you can do with it: describing images, captioning, object detection and image segmentation, OCR, visual question answering... it even has
4
21
195
0
4
23
We made a few minor modifications to the original ViT model, and that dramatically improves the performance.
Notably, 90 epochs of training exceed 76% ImageNet accuracy in <7h on a TPUv3-8, similar to the classic ResNet50, and 300 epochs of training reach 80% in <1d.
5/n

1
9
41
How would a vision model look like with less inductive bias? MLP-Mixer! Check out our all-MLP architecture for vision, without conv, without attention.

1
8
38
We present Multi-Modal Moment Matching (M4) algorithm to reduce both representation and association biases in multimodal data.
This not only creates a more neutral CLIP model, but also achieves competitive results (SigLIP B/16 INet 0-shot 77.0% -> 77.5%!) Check the thread👇

Excited to share our
#ICLR2024
paper, focused on reducing bias in CLIP models. We study the impact of data balancing and come up with some recommendations for how to apply it effectively. Surprising insights included! Here are 3 main takeaways.

3
23
88
0
7
37
I'm excited to co-organize an
#IJCV
special issue on The Promises and Dangers of Large Vision Models with
@kaiyangzhou
,
@liuziwei7
,
@ChunyuanLi
,
@kate_saenko_
.
If you are working on related topics, consider submitting a paper, deadline in 163 days!
Link:

2
11
26
Big_vision () just released the new shining flexible weight sharding feature.
It's a game changer if you want to train Giant models using a small amount of accelerators. We have upgraded all of our models in big_vision, please check below 🧵👇👇👇

We've landed a big revamp of . The main new feature is support for flexible weight sharding, which doesn't get in the way of cutting-edge research code. Scaling ViTs, ResNets, MLP-Mixers, SigLIPs (and so on) beyond single GPU/TPU device memory becomes easy.
1
32
286
0
3
26
I just checked our online LiT demo, and it's doing a reasonable job for this case, with only the smallest "tiny" model.
Please try our demo with your own prompts, if one is interested to see whether it understands language at "a deep level".
Demo:


🙄
@GoogleAI
, “a deep level understanding”?
Seriously?!
Your system can’t distinguish “a horse riding an astronaut” from “an astronaut riding a horse”.
🙄

16
6
94
3
2
24
I knew puffin from the "Unpopular Opinion Puffin" meme. I'm very excited that I saw live puffins during my vacation in Iceland. I took photos, and tried LiT models on them!
LiT is doing a reasonable job, though it scores seagull really high :)




1
1
19
Check our SOTA vision BiT models (), code and checkpoints are available in Tensorflow, Pytorch and Jax:

Presenting BiT, an open-source approach for large-scale pre-training of models covering a wide range of visual tasks, which highlights the importance of choices in the model architecture for downstream performance. Learn all about it below:
9
228
724
0
1
16
Last year we released the inference/fine-tuning code for ViT:
Now we are thrilled to announce the Big Vision codebase that supports training large-scale vision models on Google Cloud TPUs. It scales seamlessly from a single core to up to 2048 cores!
2/n
1
0
15
Milestone achieved, "How to train your ViT" becomes the first ever TMLR paper in the history! Big thanks to the TMLR reviewers and the action editor!
Wohoo, we achieved something nobody ever will again in all of human history: our paper is the FIRST accepted TMLR paper 🍾🥂
@AndreasPSteiner
@__kolesnikov__
@XiaohuaZhai
@wightmanr
@kyosu
(technically, every single paper has such achievement for "Nth", but let me have my fun)
11
12
191
0
0
13
Please check the appendix about a full detailed config to define a plain ViT-S/16 model in the Big Vision codebase. We hope this release will be a good starting point for future vision research.
Notes:
Config:
6/n
1
0
12
Thinking of saturating performance on classification with large vision models? We thought of that too, until we tested V+L tasks.
Scaling from ViT-G(2B) to ViT-e(4B), with
@giffmana
@__kolesnikov__
, PaLI got a big boost on V+L tasks. It shows headroom for even larger models!


1
3
11
I will be giving a talk with
@giffmana
at the 5th UG2+ challenge workshop at CVPR'22.
If you are working on anything related to robust object detection, segmentation or recognition, consider participating in this challenge. Check out for more details.




0
5
10
Very cool plot! Thanks Gabriel!
Impressive progress has been made in the past three years on zero-shot classification and retrieval.


0
1
10
Share with us examples only available in your mothertongue, to help us testing OSS SigLIP models.
I do come up with delicious Chinese dishes in our SigLIP colab (), please share yours!

I wanna test our i18n OSS SigLIP model more, so I need your help with ideas!
What are things in your mothertongue that, translated literally, are super weird?
@MarianneRakic
, a fellow Belgian, came up with some great francophone ideas.
More plz! Colab:


14
4
20
0
1
9
Wondering about ViT performance on small-scale datasets?
It is commonly accepted that the ViT model requires complex regularization techniques to excel at ImageNet-1k scale data. Surprisingly, we find this is not the case and standard data augmentation is sufficient.
4/n
1
0
8
Want to try it out? Follow the instructions to create your own
@googlecloud
TPU VMs and setup everything, within 30 minutes!
We link the up-to-date executable command line at the top of each config file, for your convenience.
3/n

1
0
8
Merve made a nice summary for PaliGemma in HuggingFace:
And… also prepared a nice colab for object detection and segmentation with PaliGemma:


New open Vision Language Model by
@Google
: PaliGemma 💙🤍
📝 Comes in 3B, pretrained, mix and fine-tuned models in 224, 448 and 896 resolution
🧩 Combination of Gemma 2B LLM and SigLIP image encoder
🤗 Supported in
@huggingface
transformers
Model capabilities are below ⬇️
8
70
430
1
2
8
Yes, we know everyone likes small models, so do us!
As recommended by the SoViT paper, we train a SigLIP model using the So400M vision backbone. The So400M model achieves 83.2% 0-shot acc. on ImageNet, outperforming larger released models.
Try it out and enjoy small models!

1
1
8
Arxiv:
A benchmark comprising of 90 scaling laws evaluation tasks will be released soon, stay tuned!
Work done with
@ibomohsin
and
@bneyshabur
.
@GoogleAI

0
0
7
Training for super long (patience) hurts significantly on both from-scratch training, and pre-computed teacher embeddings.
Only when combined with consistent teaching, super long schedule (patience) improves significantly over the baselines.


1
1
7

We would like to invite academic researchers to perform research using PaliGemma, please apply at
We intend to support selected researchers with a grant of USD $5,000 in GCP credits
Email paligemma-academic-program
@google
.com if you have any questions.

2
1
6
Congratulations to my colleague from Google Brain Zurich for the ICML 2019 Best Paper award!

I am excited and honored that we received the
#ICML2019
Best Paper Award with "Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations" (). W/
@francescolocat8
, S. Bauer,
@MarioLucic_
,
@grx
,
@sylvain_gelly
,
@bschoelkopf

14
65
452
0
0
6
There're plenty of new features and projects we plan to release in the near future, stay tuned :)
Examples:
1. ImageNet-21k in TFDS
2. MLP-Mixer
3. Contrastive Image-Text model training and evaluation as in LiT and CLIP
4. Knowledge distillation
7/n
1
1
6
Thanks to the simplicity, we manage to handle three diverse tasks: panoptic segmentation, colorization and depth prediction.
Wanna give it a try on your customized vision tasks? All you need to do is compressing your task output into a discrete guiding code, and you're done!

1
1
6
Please check out Alex's thread for more details:
Paper: .
Github (coming soon):
Work done with
@__kolesnikov__
, André Susano Pinto,
@giffmana
,
@JeremiahHarmsen
,
@neilhoulsby
.
I've always been frustrated that, beyond image classification, computer vision is full of complex and task-specific components.
Thus, very excited to share our new work, where we propose a unified modeling approach for vision: .
More in the thread🧵.
6
126
598
0
0
6
Big Vision codebase is developed by
@giffmana
@__kolesnikov__
@XiaohuaZhai
, with contributions from many other colleagues in the
@GoogleAI
Brain team.
8/n
0
0
6

Check
@giffmana
's summary of what we have done for OSS Vision with our amazing close collaborators!
We always have OSS at the top of our mind, from releasing the I21K models since BiT, to releasing the WebLI pre-trained SigLIP models very recently.
Here's what our (sub)team in Zürich has done for OSS vision over the past 5y, besides inventing ViT:
1) Make i21k a thing
Release:
2) best CLIP (siglip) by a large margin
3) best i1k ResNet50 ever
4) best pre-trained ResNets
5) >55k ViTs
6) Most efficient JAX/TPU CV code
deets👇
10
55
552
0
0
5
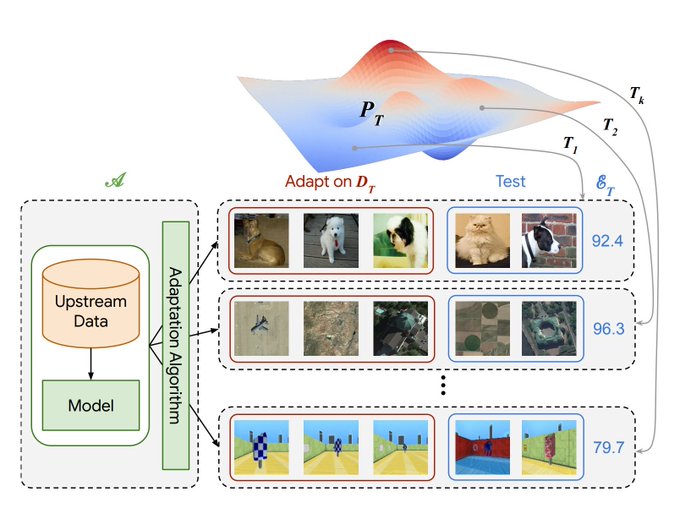
Check our Visual Task Adaptation Benchmark, with a large scale visual representation study on {generative, from scratch, self supervised, semi supervised, supervised} models. Try it on GitHub () with TF-Hub models ()!

How effective is representation learning? To help answer this, we are pleased to release the Visual Task Adaptation Benchmark: our protocol for benchmarking any visual representations () + lots of findings in .
@GoogleAI
1
59
212
0
1
5
As always, work done at Google Research, Brain Team, with
@giffmana
,
@royaleerieme
, Larisa Markeeva,
@_arohan_
and
@__kolesnikov__
.
0
0
5
SigLIP meets Mistral!

Announcing Nous Hermes 2.5 Vision!
@NousResearch
's latest release builds on my Hermes 2.5 model, adding powerful new vision capabilities thanks to
@stablequan
!
Download:
Prompt the LLM with an Image!
Function Calling on Visual Information!
SigLIP



51
170
993
0
1
5
To train multilingual PaLI,
@brainshawn
drove building the multilingual WebLI dataset, with over 10 billion images and more than 100 languages!
This helps a lot on the XM3600 benchmark, though English still performs the best. This suggests more future multilingual research!


1
1
5
Bigger models are more sample efficient, reaching the same level of error rate with fewer seen images.
ViT-G/14 model reaches 84.86% top-1 accuracy on ImageNet with only 10 examples per class, which is less than 1% of the train set!

0
0
5
Glad to see that SigLIP understands German well!
If you're looking for a multilingual text/image encoder for your apps, SigLIP has you covered with Apache 2.0 license 😍
I've built an app for you to compare it against other models for zero-shot classification: note that SigLIP's

1
16
66
0
0
4
Unreasonable patience is needed for the distillation (Step 3), far beyond the standard expectations... And it will pay off.
The Brain-ZRH way:
1. Pre-train large model on large noisy data, or download ckpt. (BiT paper)
2. Fine-tune it on your task (cheap).
3. Distill into model you'll deploy. (Patient&Consistent paper)
The unreasonable effectiveness of this approach is still widely underappreciated!
4
18
176
0
0
5
In this typographic attack example, LiT is able to properly recognize it's "an apple with a sticker with the text ipod". Please try your own prompts with
#lit_demo
👇👇

LiT-tuned models combine powerful pre-trained image embeddings with a contrastively trained text encoder. Check out our blogpost and the 🔥 interactive demo ↓↓↓
#lit_demo
7
110
592
0
1
4
PaliGemma project is developed together with all my amazing colleagues here in Zurich and across continents. Huge thanks to the team🥰
0
0
4
Visualization of ViT-G shape compared to the previous ViT-H shape, together with our memory saving improvements (remove `class` token, use Adafactor optimizer, .).

1
0
4
We pretrain PaliGemma on billion scale data, covering long tail concepts. This makes the models so well prepared for fine-tune transfer, or a short instruction tuning.
Check the following colab, and consider using PaliGemma for your VLM research!

I'm pretty happy with one of our colabs:
- super-simple plain code, no big frameworks
- plain SGD tuning of attention weights only
- transfers into a pretty good long-captioner
- using just 90 hand-made examples
- less than 15min on free T4 colab


4
4
100
1
0
4
Check our paper for the answer to "where are we on ImageNet?" and "what are the remaining mistakes?". Based on our insights, simply removing the noisy train labels and using sigmoid cross-entropy loss, yields 2.5% improvement on ImageNet with ResNet50.

Are we done with ImageNet? That's what we set out to answer in with
@olivierhenaff
@__kolesnikov__
@XiaohuaZhai
@avdnoord
. Answer: it's complicated. On the way, we find a simple technique for +2.5% on ImageNet.



2
33
95
0
2
4
Work done at Google Research, Brain Team Zürich, with
@__kolesnikov__
,
@neilhoulsby
and
@giffmana
.
0
0
4
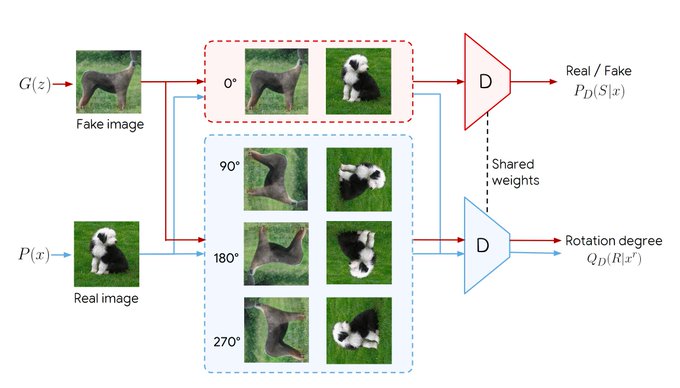
Check our latest CVPR work on GANs with self supervision!
Combining two of the most popular unsupervised learning algorithms: Self-Supervision and GANs. What could go right? Stable generation of ImageNet *with no label information*. FID 23. Work by Brain Zürich to appear in CVPR.
@GoogleAI
#PoweredByCompareGAN
0
47
158
0
0
3
Check Alex's thread for all the useful links:
I'm so impressed to see
@skalskip92
has already created a customized fracture detector with PaliGemma using colab.

@__kolesnikov__
Awesome! After a bit of trial and error, I managed to fine-tune the model using a custom object detection dataset. The Google Colab works great.
I have one more problem. How can I save a fine-tuned model? Really sorry if that's a stupid question, but I'm new to JAX and FLUX.

3
3
16
3
0
3
0
0
2
Did you know the following Chinese dishes? Tell me what's your favorite!
蚂蚁上树 (ants climbing a tree)
红烧狮子头 (red burned lion head)
松鼠鳜鱼 (squirrel mandarinfish)
The i18n mSigLIP Base model not only understands languages, but also understands different cultures!

2
0
3
Work done at
@GoogleAI
Brain Team Zürich, with
@__kolesnikov__
,
@giffmana
,
@joapuipe
,
@JessicaYung17
,
@sylvain_gelly
,
@neilhoulsby
.
0
0
3
It's LiT❤️🔥 tshirt!! Super cool!
Live demo you can play with at the LiT poster happening now

3
2
86
0
0
3
SigLIP and mSigLIP models are developed by
@XiaohuaZhai
,
@_basilM
,
@__kolesnikov__
and
@giffmana
, from Google Deepmind Zürich. Huge thanks to all contributors behind the WebLI dataset and the big_vision codebase .
0
0
3
Pre-trained vision models become zero-shot learners with Locked-image Tuning (LiT). We have performed LiT on self-supervised models (MoCo-v3, DINO) and supervised models (ViT, Mixer and BiT).
Want to play with LiT🔥 with any of your pre-trained vision models?


1
0
2
@wightmanr
@bryant1410
You’re right. We are on it, but cannot promise anything at the moment yet :) I’m really excited to see the current SigLIP models being adopted!
0
0
2
Work done at Google Research (Brain Team) in Zurich and Berlin, with a great team:
@tolstikhini
@neilhoulsby
@__kolesnikov__
@giffmana
@TomUnterthiner
@JessicaYung17
@keysers
@kyosu
@MarioLucic_
Alexey Dosovitskiy.
0
0
1
We released a line of SigLIP Base models with different resolutions, including models from accepting 196 image patches to 1024 image patches. Let us know how these models perform in your projects.

1
0
2
As usual, work done with an amazing team based in Zürich:
@giffmana
@AndreasPSteiner
@_basilM
@brainshawn
@__kolesnikov__
@keysers
@GoogleAI
1
0
2
We have deployed the PaliGemma models on Cloud Vertex AI Model Garden, which makes research with PaliGemma extremely smooth on Google Cloud platform.


1
0
2
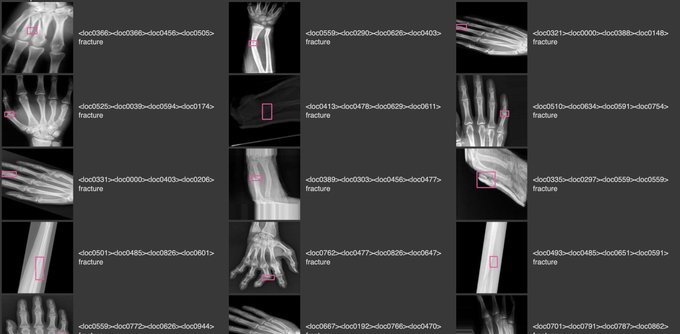
More updates with a blog about "How to Fine-tune PaliGemma for Object Detection Tasks"

I fine-tuned my first vision-language model
PaliGemma is an open-source VLM released by
@GoogleAI
last week. I fine-tuned it to detect bone fractures in X-ray images.
thanks to
@mervenoyann
and
@__kolesnikov__
for all the help!
↓ read more
30
194
1K
0
0
2
Research with code on disentanglement from my college at Google Brain Zurich.
Interested in doing research on disentanglement? We just open-sourced disentanglement_lib (), the library we built for our study “Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representation” ()
@GoogleAI
3
53
144
0
0
1
Training SOTA GANs with self supervision and semi supervision!

How to train SOTA high-fidelity conditional GANs usin 10x fewer labels? Using self-supervision and semi-supervision! Check out our latest work at
@GoogleAI
@ETHZurich
@TheMarvinRitter
@mtschannen
@XiaohuaZhai
@OlivierBachem
@sylvain_gelly
1
67
241
0
0
1
We care about i18n performance too. That's why we created the i18n WebLI dataset in the first place.
A mSigLIP Base model achieves 42.6% text-to-image 0-shot retrieval recall
@1
across 36 langs on XM3600. This is on par with the current SOTA using a Large model.

1
0
1
Check out the demo prepared by
@giffmana
, SigLIP is able to tell the difference between "a cold drink on a hot day" and "a hot drink on a cold day".
SigLIP is doing great on our favorite "a cow on the beach" example.
Try to slide the "Bias" bar to calibrate scores online!

1
0
5
@AarishOfficial
The Chinchilla paper () answers partially your questions in the language domain: optimal model size under a given compute budget. In their Table A9, concrete model shapes are listed for various model sizes.
1
0
1
@wightmanr
@giffmana
@_basilM
@__kolesnikov__
Thanks for sharing, Ross. Your B/32 @ 256 (64) results are pretty strong! We will consider it for SigLIP as well :)
1
0
1
Check our ICML 2019 work from Google Brain Zurich. Code available online:

Our work "A Large-Scale Study on Regularization and Normalization in GANs" has been accepted to
#ICML2019
! Great to see thorough and independent scientific verification being valued at the top ML venue.
@icmlconf
@MarioLucic_
@XiaohuaZhai
@sylvain_gelly
@GoogleAI
3
24
119
0
0
1