

Yujia Qin
@TsingYoga
Followers
4K
Following
180
Statuses
259
ByteDancer, Multimodal Agent, THU (16-20 BS in EE, 20-24 PhD in CS)
Beijing
Joined February 2019
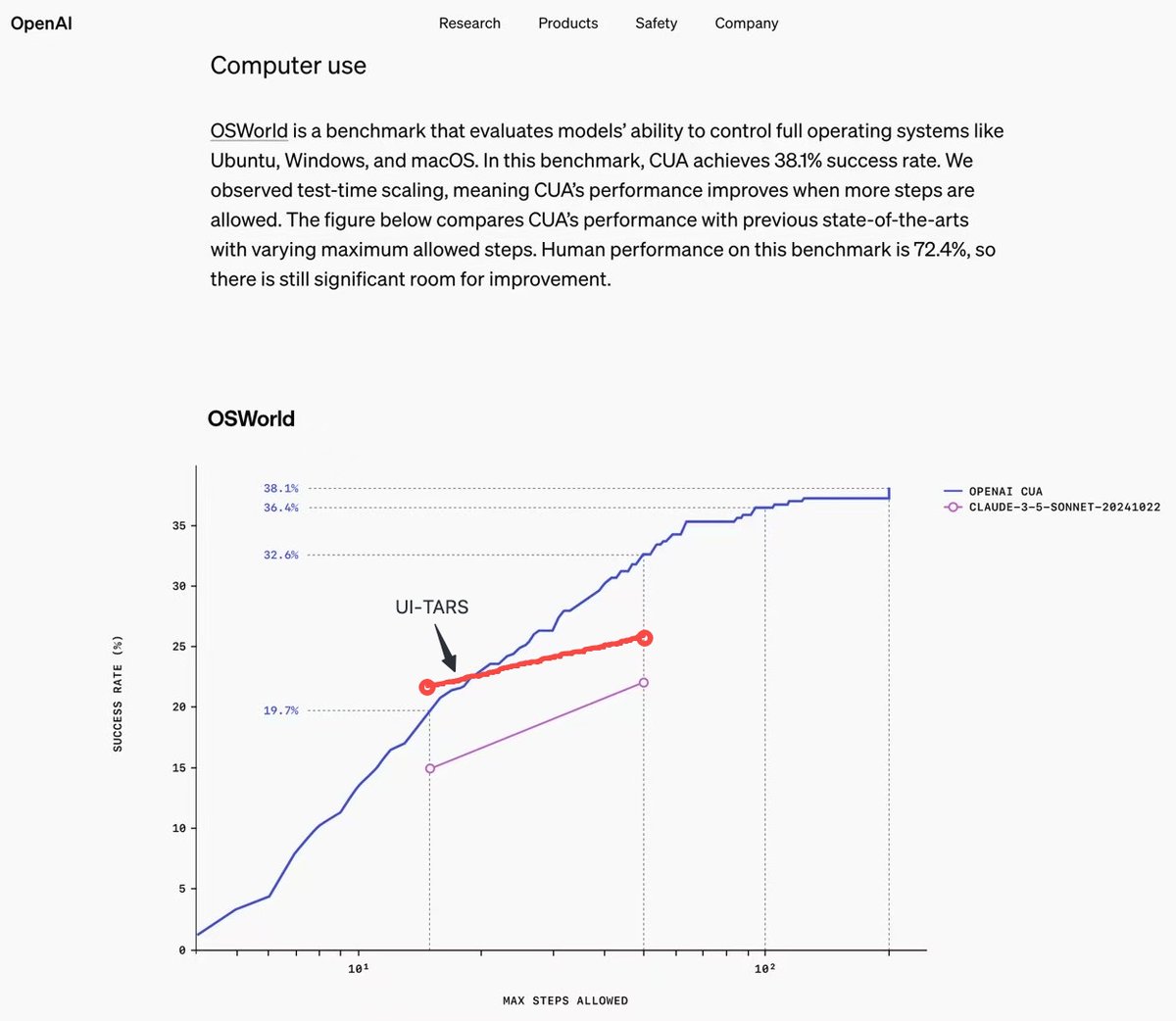
🥳Introducing UI-TARS, a vision-language model outperforming Claude Computer-Use and GPT-4o on 10+ GUI Agent Benchmarks (OSWorld, Android World, VisualWebBench, M-Mind2web, Screenspot-v1-v2-Pro, AndroidControl...)🧵 🫡One More Thing!! The paper, model, and Desktop APP are open-sourced!🎁 Just try it! Arxiv: Model: APP:
7
34
148
RT @GeZhang86038849: M-A-P‘s Chinese New Year gift to the Open-Source Community. LLaMA moment of music foundation model! The first open-sou…
0
1
0
RT @gneubig: OpenAI Operator mainly benchmarked on OSWorld and and WebArena. I did some (agent-assisted) research and summarized the top o…
0
10
0
RT @qinzytech: Do NOT overhype OpenAI Operator We show some failure modes that indicates it is almost surely below a college-level compute…
0
34
0
😊Low-key update from Doubao VLM team. Kudos to all the teammates. Our recently released UI-TARS is Qwen2-vl based for research / open-source uses (2B / 7B / 72B, SFT / DPO). 💪We will soon have much better computer-use API in the future, based on internal models, stay tuned for the update!

1
2
17
From the demo, it seems the scroll down broke. Our model decides to scroll down, but the interface does not change much. So our model is continually deciding to scroll down (that's the reason why the model "stuck"). It seems the APP interface is not working, we are fixing the API, thanks for your valuable feedback!
3
0
7
Lastly, check out some interesting demo and exp results~ Also, feel the grounding ability here:




0
2
4
Check out our latest GUI Agent -> UI-TARS 🥳 A vision-language model surpasses GPT-4o & Claude Computer-Use Paper, code, model ckpt, desktop APP are now open-sourced~


9
39
188
RT @denny_zhou: any benchmark—including ARC-AGI—can be rapidly solved, as long as the task provides a clear evaluation metric that can be u…
0
74
0
RT @Qinyu_01: 🎉 RepoAgent v0.1.5 is Live! It’s been a highly requested feature during EMNLP 2024, and now we’re excited to announce the ne…
0
4
0