
linghui
@linghui35877581
Followers
4
Following
250
Statuses
199
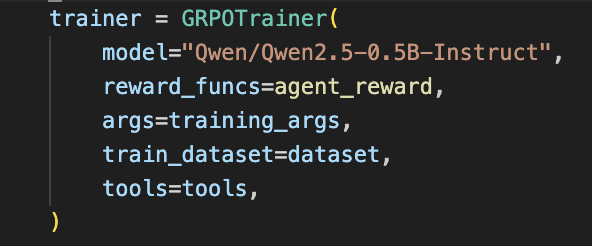
RT @QGallouedec: Train an agent with GRPO? Yes, it works! I've made a small demo example if you're interested!

0
46
0
RT @zzlccc: 🚨There May Not be Aha Moment in R1-Zero-like Training: A common belief about the recent R1-Zero-like t…
0
68
0
RT @priontific: MLX-GRPO trainer prototype by @ActuallyIsaak is functional! 🥳 I've got to do some deeper investigating here, but... initia…
0
7
0
RT @hahahahohohe: After whole day effort succeeded at running GRPO training of qwen 0.5B on a free colab T4 gpu, but it's suuuper slooow lol
0
1
0
RT @KevinQHLin: Exciting progress in AI community over the recent weeks! LLMs -- DeepSeek-R1 (Reasoning), MiniMax-01 (Long context) LMMs -…
0
4
0
RT @xiangyue96: We are also exploring something similar. But one different thing we observed from our experiments was that the length of th…
0
17
0
RT @denny_zhou: any benchmark—including ARC-AGI—can be rapidly solved, as long as the task provides a clear evaluation metric that can be u…
0
74
0
RT @natolambert: For those trying to understand DeepSeeks Group Relative Policy Optimization (GRPO): GRPO is just PPO without a value funct…
0
128
0
RT @knmnyn: 📣Hey #LLM processing folks (#NLProc , @iclr_conf folks), please RT and spread the word! Reasoning and planning are🔥topics in…
0
9
0
RT @WenhuChen: I spent the weekend reading some recent great math+reasoning papers: 1. AceMath ( 2. rStar-Math (htt…
0
163
0
RT @denny_zhou: Identifying what to scale is crucial for building LLMs. What’s your favorite inference-time scaling? 1. Scaling self-consi…
0
32
0
RT @xpasky: Quick primer for non-wizards about the post-MCTS LLM reasoning future (I'm kinda PRIME-pilled rn): How will LLMs learn to reas…
0
47
0
RT @lifan__yuan: How to unlock advanced reasoning via scalable RL? 🚀Introducing PRIME (Process Reinforcement through Implicit Rewards) and…
0
176
0
RT @denny_zhou: After "the bitter lesson", people love talking about that search and learning are the two methods that can scale arbitraril…
0
15
0
RT @ysu_nlp: My 2024 predictions (agents, multimodality, synthetic data, sparsity) all came true, but those were generic and somewhat obvio…
0
49
0
RT @Francis_YAO_: My 2024 product of the year: Gemini Deep Research. I understand many of you may not be aware of it, but it is definitely…
0
61
0
RT @ZheqingZhu: Introducing Pokee AI's E-commerce Agent - Now Beta on Shopify! One-click install AI search, chatbot and recommendation to y…
0
1
0