
Xinyun Chen
@xinyun_chen_
Followers
4,135
Following
950
Media
27
Statuses
177
Research Scientist at @GoogleDeepMind . PhD from @Berkeley_EECS .
Joined February 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
田中さん
• 458033 Tweets
田中敦子さん
• 433622 Tweets
声優さん
• 218890 Tweets
攻殻機動隊
• 146751 Tweets
Fate
• 141006 Tweets
LINGORM THE STYLER
• 139695 Tweets
ALRIGHT POSTER
• 129655 Tweets
ネルフェス
• 93056 Tweets
ショック
• 74237 Tweets
#西園寺さんは家事をしない
• 51692 Tweets
フランメ
• 47169 Tweets
#大神ミオ生誕ライブ2024
• 43865 Tweets
ラストマイル
• 42659 Tweets
#アイナナ9周年生放送
• 40136 Tweets
ドーピング
• 38966 Tweets
초코우유
• 32641 Tweets
メディアさん
• 26796 Tweets
キャスター
• 26670 Tweets
ベヨネッタ
• 25453 Tweets
女性の声
• 21695 Tweets
メアリー
• 17054 Tweets
カーミラさん
• 15216 Tweets
レインドット
• 13504 Tweets
岡田将生
• 13277 Tweets
リサリサ先生
• 12330 Tweets
スーパームーン
• 11656 Tweets
千速さん
• 10462 Tweets




















Pinned Tweet

New preprint: Teach LLMs to self-debug! ()
With few-shot demonstrations, LLMs can perform rubber duck debugging: w/o error messages, it can identify bugs by explaining the predicted code. SOTA on several code generation benchmarks using code-davinci-002.

12
106
536
New preprint: Universal Self-Consistency for Large Language Model Generation
We propose Universal Self-Consistency (USC) to aggregate free-form responses, such as code generation and summarization, where the original SC is not applicable.

4
66
302
Our new work () shows that LLMs can learn (sometimes uncommon) rules with 2 stages: (1) induction: generate and verify rules from exemplars; (2) deduction: utilize the rule library for new problems. 11-27% gain on reasoning tasks that require rule learning.


🔥 When talking about training LLMs, do you think of updating model parameters?
In fact, you can use LLMs to learn a rule library. This not only improves multi-step reasoning, but also has many advantages: interpretability, transferability, and applicable to black-box LLMs.
🧵1/6

7
123
614
2
43
222
I am very excited to be part of the team
#AlphaCode
in my summer internship last year! A huge thanks to my host
@liyuajia
for adding me to this amazing team! Looking forward to see what comes next!

Introducing
#AlphaCode
: a system that can compete at average human level in competitive coding competitions like
@codeforces
. An exciting leap in AI problem-solving capabilities, combining many advances in machine learning!
Read more: 1/

173
2K
8K
5
13
179
New preprint🔥: Premise Order Matters in Reasoning with Large Language Models
In typical logical reasoning, premise order doesn't matter. However, for SOTA LLMs, changing the premise order may cause an accuracy drop of >30%!
🧵
1/8

2
30
118
Our work () demonstrates that self-debugging ability already exists in the base model w/o instruction tuning (code-davinci-002). The main difference is that we need few-shot prompting for such models to trigger self-debugging.

GPT-4 has one emergent ability that is extremely useful and stronger than any other models: self-debug.
Even the most expert human programmer cannot always get a program correct at the first try. We look at execution results, reason about what's wrong, apply fixes, rinse and
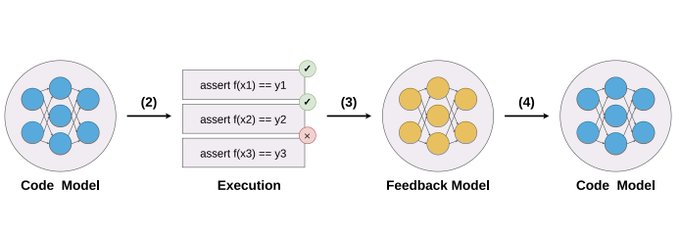
51
391
2K
1
15
115
Thanks for sharing our work ()! Besides the huge improvement with prompts optimized by LLMs, we are also amazed by the creativity of LLMs, which continually surprise us with interesting prompts tailored to the LLM in the optimization loop!


In a new paper showing that AI comes up with more effective prompts for other AIs than humans do, there is this gem that shows how weird AIs are...
The single most effective prompt was to start by telling the AI "Take a deep breath and work step-by-step!"

76
675
4K
1
15
106
Our new work () shows that currently LLM self-correction w/o external feedback (e.g., oracle verification, code execution) often degrades the performance on reasoning tasks. The main issue is the LLM itself does not properly judge its reasoning correctness.


Can LLMs Self-Correct Their Reasoning?
Recent studies (self-refine, self-critique, etc.) suggest LLMs possess a great ability to self-correct their responses. However, our research indicates LLMs cannot self-correct their reasoning intrinsically.
[1/n]

5
69
386
1
16
91
In our work , besides prompt optimization as our primary application, we also investigate the potential of LLMs for broader optimization problems. Interestingly, LLMs can find good solutions to some small-scale classic optimization problems; e.g., TSP. This


New preprint: Large Language Models as Optimizers ()
(1/5)

5
66
390
1
15
91
Excited to share our work () for reading long documents way exceeding the context window (up to 20x). Inspired by human reading paradigm, Read Agent summarizes the input episodically as gist memories, and uses them to retrieve relevant details when needed.

We propose ReadAgent 📖, a LLM agent that reads and reasons over text up to 20x more than the raw context length. Like humans, it decides where to pause, keeps fuzzy episodic memories of past readings, and looks up detail info as needed. Just by prompting.

6
60
307
1
17
85
Our new work led by
@JerryWeiAI
on the in-context learning ability of large language models. While smaller-scale pretrained models rely more on their semantic prior, larger models can follow in-context exemplars that are even contradictory to their own knowledge.

New
@GoogleAI
paper: How do language models do in-context learning?
Large language models (GPT-3.5, PaLM) can follow in-context exemplars, even if the labels are flipped or semantically unrelated. This ability wasn’t present in small language models.
1/

14
214
964
2
13
80
Our new work () shows that LLM-generated exemplars can outperform hand-crafted CoT. Interestingly, LLM-generated tutorials for competitive programming improve the results even if the generated example problems are much simpler than the new contest problem!


Introducing Analogical Prompting, a new method to help LLMs solve reasoning problems.
Idea: To solve a new problem, humans often draw from past experiences, recalling similar problems they have solved before. Can we prompt LLMs to mimic this?
[1/n]
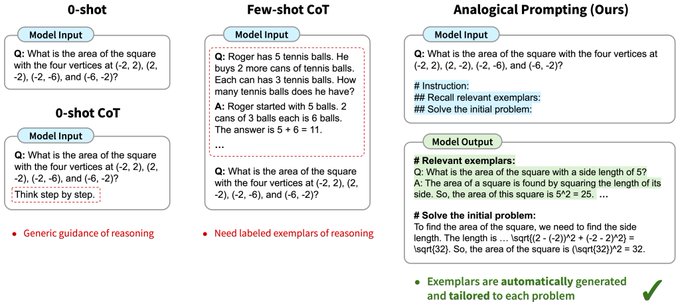
9
110
481
1
14
76
Really excited to see that our work
#AlphaCode
is published in Science as the front cover! Still a lot more can be achieved with language models for code!
In
@ScienceMagazine
, we present
#AlphaCode
- the first AI system to write computer programs at a human level in competitions.
It placed in the top 54% of participants in coding contests by solving new and complex problems.
How does it work? 🧵
96
751
3K
0
6
71
Our NATURAL PLAN evaluation () shows that planning remains a challenge for current LLMs. When given more constraints (more people to meet and places to visit), LLM performance can become close to 0 (unable to find any valid plan).


Introducing NATURAL PLAN 🔥: a realistic planning benchmark in natural language!
Key features:
- 3 main tasks: Trip Planning, Meeting Planning, and
Calendar Scheduling.
- Supplies in the context all relevant information to the
model (e.g., Google Flights, Maps, Calendar)

10
22
147
3
5
60
Our new work () shows the power of abstraction with step-back prompting: let the LLM ask a step-back question (e.g., more general factual knowledge, first principles) before solving the specific reasoning problem. Work led by
@HuaixiuZheng
@Swarooprm7
,

Introducing 🔥 ‘Step back prompting’ 🔥 fueled by the power of abstraction. Joint work with the awesome collaborators at
@GoogleDeepMind
:
@HuaixiuZheng
,
@xinyun_chen_
,
@HengTze
,
@edchi
,
@quocleix
,
@denny_zhou
.
LLMs struggle to answer specific questions such as: “Estella

6
71
350
1
4
56
I am super excited to see that our SpreadsheetCoder work () leads to the release of formula prediction in Google Sheets ()! A huge thanks to the Brain team and Google Sheets team for the great collaboration!


Very excited about formula prediction being released in Google Sheets! A great collaboration between Google Sheets and Brain team.
9
82
532
1
4
54
Please consider submitting your work on LLM agents to our ICLR workshop ()! The submission deadline is Feb 3, 2024.

📣 CALL FOR PAPERS 📣
Join us at the
#ICLR2024
Workshop on LLM Agents!
@iclr_conf
🙋♂️We welcome both research papers and demos with technical reports. For more details, visit:
#LLM
#LLMAgents
3
9
66
0
11
52
Our SecML Workshop at
@iclr_conf
is tomorrow, with 11 amazing speakers/panelists:
@zicokolter
,
@AdamKortylewski
,
@aleks_madry
,
@catherineols
,
@AlinaMOprea
, Aditi Raghunathan, Christopher Ré,
@RaquelUrtasun
, David Wagner,
@YuilleAlan
,
@ravenben
.
Link:

1
12
49
I also tried LLMs for long-digit addition a bit, and actually it generalizes even with just 2-digit addition in the prompt. (I did not fully test it, and clearly not 100% accurate for all problems) [1/9]

“LLMs can’t even do addition”
📄🚨We show that they CAN add! To teach algos to LLMs, the trick is to describe the algo in enough detail so that there is no room for misinterpretation
w/
@Azade_na
@hugo_larochelle
@AaronCourville
@bneyshabur
@HanieSedghi
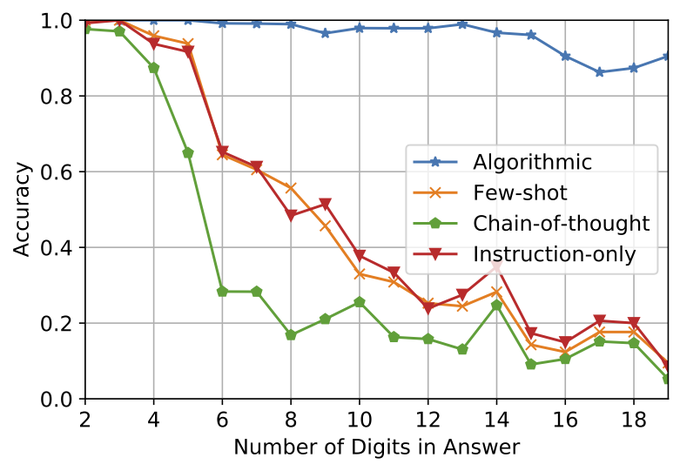
24
154
1K
2
1
43
Excited to share our
#NeurIPS2021
paper: Latent Execution for Neural Program Synthesis (). Besides a regular neural program synthesizer, we train a latent executor to model the intermediate execution states, with supervision only on full program outputs.
1
9
43
I am very excited to receive this great honor
@FeiziSoheil
@ml_umd
! Thanks a lot for running this wonderful program and hosting a super nice virtual visit!

Check out and follow amazing works by our 2021 "Rising Stars in ML":
Xinyun Chen
@xinyun_chen_
(UC Berkeley):
Qi Lei
@Qi_Lei_
(Princeton):
Tian Li
@litian0331
(CMU):
More info:
6
10
43
6
1
39
Looking forward to the workshop! Excited to share our recent work on LLM reasoning

📢 Can't wait to see you at the 3rd
#MathAI
Workshop in the LLM Era at
#NeurIPS2023
!
⏰ 8:55am - 5:00pm, Friday, Dec 15
📍 Room 217-219
🔗
📽️
Exciting Lineup:
⭐️ Six insightful talks by
@KristinLauter
,
@BaraMoa
,
@noahdgoodman
,

4
21
88
0
3
37
I am super excited to speak at
@DL4Code
(co-located with
#iclr2022
) about my work on deep learning for program synthesis! Thanks the organizers for putting together this wonderful workshop, and I am looking forward to discussing various topics in this exciting area!

📢📢We are very excited to announce that
@xinyun_chen_
will be speaking at the Deep Learning For Code Workshop!
The full lineup of incredible speakers and schedule can be found here:
0
3
7
0
6
35
Our new work scaling instruction tuning to larger models (e.g., PaLM 540B) and more finetuning tasks, achieving significantly better zero-shot multi-step reasoning performance among other improvement. Really excited to further unlock more reasoning capabilities of new LLMs!

New open-source language model from Google AI: Flan-T5 🍮
Flan-T5 is instruction-finetuned on 1,800+ language tasks, leading to dramatically improved prompting and multi-step reasoning abilities.
Public models:
Paper:
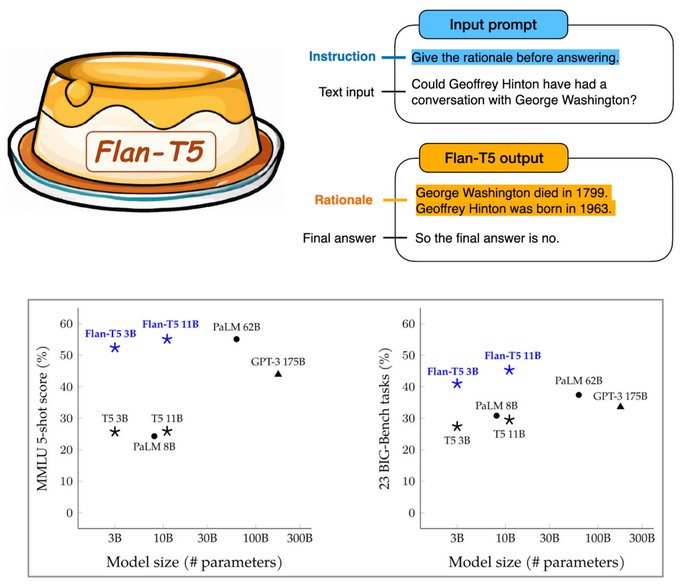
40
488
2K
0
1
34
Our new work led by
@JerryWeiAI
on symbol tuning, which improves LLMs on learning input-label mapping from exemplars. With only natural language classification tasks in the training mixture, symbol tuning also boosts the performance on algorithmic reasoning tasks.

0
3
33
Our new work on compositional generalization for semantic parsing achieves new SOTA on CFQ (95% accuracy), using only 1% of the original training data for prompting (no finetuning). Still a lot more can be achieved by large language models with prompting + decomposition!

🚨 New preprint! 🚨
We refine least-to-most prompting and achieve sota on CFQ (95% accuracy), outperforming previous fully supervised methods. Joint first author work with the formidable Nathanael Schärli.
2
50
215
0
5
33
I am very excited to be a speaker at
@TrlWorkshop
! It is going to be a wonderful event, and I am looking forward to seeing more work in this area!

Excited to announce the amazing speakers who will share their work & perspective on Table Representation Learning
@TrlWorkshop
on 2 Dec at
@NeurIPSConf
-- most in-person 🔥!
>> Submissions due in 2 weeks! CFP and info here: .
More updates follow soon!

0
10
23
0
3
28
Excited to join the event and discuss our work on LLMs next week!

We're having a big event on agents at CMU on May 2-3 (one week from now), all are welcome!
It will feature:
* Invited talks from
@alsuhr
@ysu_nlp
@xinyun_chen_
@MaartenSap
and
@chris_j_paxton
* Posters of cutting edge research
* Seminars and hackathons
4
29
180
2
1
28
Our Security and Safety in Machine Learning Systems Workshop at
@iclr_conf
(co-organized with Cihang Xie (
@cihangxie
), Ali Shafahi, Bo Li, Ding Zhao (
@zhao__ding
), Tom Goldstein, and Dawn Song (
@dawnsongtweets
)) is now accepting submissions, with a best paper prize! DDL: Feb 26.

1
6
26
Our new work led by
@ChengshuEricLi
on LLM reasoning via writing psuedocode and simulating its execution, which interleaves executable code blocks and non-executable functions (emulated by LLMs). SOTA on Big-Bench Hard, and see demos on robotics tasks at .

We are excited to announce Chain of Code (CoC), a simple yet surprisingly effective method that improves Language Model code-driven reasoning. On BIG-Bench Hard, CoC achieves 84%, a gain of 12% over Chain of Thought.
Website:
Paper:
22
99
517
0
3
27
Excited to share our work () showing that Transformers can achieve near-perfect length generalization (2.5x) on long-digit addition, though not robust yet. Led by our amazing intern
@Yongchao_Zhou_

📢 New preprint:
Can transformers extrapolate to input lengths beyond their training input lengths?
For the first time, we show that Transformers can handle decimal digit addition beyond their training lengths, extending test lengths up to 2.5x with the

5
18
106
0
5
24
Really heartbroken and shocked when hearing this. I recall the wonderful time when Drago was the host for my faculty interview just last year, and cannot believe that I will no longer be able to chat and learn from him. The world has lost a truly brilliant and nice person...💔

The
#AI
community, the
#computerscience
community, the
@YaleSEAS
community, and humanity have suddenly lost a remarkable person,
@dragomir_radev
- kind and brilliant, devoted to his family and friends... gone too soon. A sad day
@Yale
@YINSedge
@YaleCompsci
#NLP2023


41
87
388
0
3
24
Had a great time meeting
@FeiziSoheil
and the class!
"Learning-Based Program Synthesis" a lecture by Dr. Xinyun Chen
@xinyun_chen_
Very interesting results on synthesizing programs from multi-modal & ambiguous specifications + compositional generalization via program learning.


1
3
18
1
1
21
6/
This is joint work with my amazing collaborators
@Korvin79
,
@urialon1
,
@jessierenjie
,
@KevinKiao
,
@pengchengyin
, Sushant Prakash,
@RandomlyWalking
, Xuezhi Wang, and
@denny_zhou
. Also thanks
@arankomatsuzaki
for tweeting ()

Universal Self-Consistency for Large Language Model Generation
Performs on par with Self-Consistency (SC) without the constraint that SC can only be applied to tasks where the final answer can be aggregated via exact match

0
42
194
2
3
19
4/
Below is an example to illustrate this process for text-to-SQL generation. No unit tests are available in the problem description, thus the LLM needs to validate the code correctness itself. Check out our paper for the full few-shot prompts.

1
2
14
5/
Self-debugging improved the accuracy by ~3% on text-to-SQL generation (9% on the hardest problems), and can improve ~10% by also utilizing unit tests for code translation and text-to-Python generation. Please check out the paper on more analysis, e.g., on sample efficiency.

1
2
12
6/
We believe improving self-debugging capability is important for further enhancing LLM coding. We will continue investigating more feedback formats and models in light of related efforts for other tasks (Constitutional AI, Reflexion, Self-Refine, AutoGPT, etc.).

1
0
12
3/
While predicting meaningful error messages is challenging for LLMs, LLMs are good at explaining code. Self-debugging leverages this property and is reminiscent of rubber duck debugging: by describing code line-by-line, humans are usually able to identify the bugs themselves.

1
1
12
If we further add distracting rules to the above logical reasoning tasks, shuffling premises causes even larger accuracy drops, across multiple LLMs. This also confirms our previous work showing that LLMs are easily distracted ().
4/8

1
1
9
2/
Recent LLMs are good at code generation, but they might need multiple trials to accomplish a task. So do humans, thus debugging is a critical skill for programmers. How to teach the LLM to debug by itself, even when it is not specifically trained for self-critique?
1
1
9
2/
On this task, LLMs clearly do not outperform SOTA solvers that incorporate decades of human wisdom. However, given the simplicity and generality of our meta-prompt, it indicates the potential of leveraging LLMs to complement classic optimization algorithms for new domains. We

1
0
9
We extended the submission deadline of our ICLR workshop on Security and Safety in Machine Learning Systems to March 7. CfP: .
Our Security and Safety in Machine Learning Systems Workshop at
@iclr_conf
(co-organized with Cihang Xie (
@cihangxie
), Ali Shafahi, Bo Li, Ding Zhao (
@zhao__ding
), Tom Goldstein, and Dawn Song (
@dawnsongtweets
)) is now accepting submissions, with a best paper prize! DDL: Feb 26.
1
6
26
0
2
8
Here is an example showing how the LLM fails after shuffling the premises, while it generates the correct proof when the premise order follows the ground truth proof steps.
2/8

1
0
9
Here are results across different LLMs. We can see that shuffling premises leads to a substantial performance drop.
3/8

1
0
8
Very excited to co-organize and talk at our CVPR Tutorial on Adversarial Machine Learning in Computer Vision ()! Please join us (09:55 am - 5:30 pm ET, June 19) and hear about a wide range of AdvML topics from our amazing speakers!

If you plan to "attend"
@CVPR
, check out our Tutorial on AdvML in Computer Vision (). Our amazing speakers will cover both the basic backgrounds & their most recent research in AdvML.
Save the date (09:55 am - 5:30 pm ET, June 19), and we will see you soon

0
31
96
0
1
8
While humans also have a preference for certain premise orders, LLMs are *much more susceptible* to such ordering effects. This might be due to the auto-regressive model training objective and/or biases in training data. Mitigating this issue remains a challenge.
7/8
1
1
8
7/
This is joint work with my amazing collaborators Maxwell Lin, Nathanael Schärli, and
@denny_zhou
. Also thanks for great discussion threads from
@_akhaliq
(),
@johnjnay
(),
@omarsar0
(), etc!

LLMs for Self-Debugging
Proposes an approach that teaches LLMs to debug its predicted program via few-shot demonstrations.
This allows a model to identify its mistakes by explaining generated code in natural language.
Achieves SoTA on several code generation tasks like

7
95
438
1
0
8
We constructed a variant of GSM8K, which we name R-GSM, by reordering the problem statements. Below is an example showing how the LLM fails to solve the problem post-reordering.
5/8

1
0
8
2/
The key idea in Universal Self-Consistency (USC) is to directly ask LLMs to “select the most consistent response based on majority consensus” over candidate responses.

1
1
7
Please see our paper for more details. This is joint work with our amazing intern
@ryanandrewchi
and collaborators Xuezhi Wang and
@denny_zhou
. Also thanks
@_akhaliq
for tweeting ()
8/8

Google presents Premise Order Matters in Reasoning with Large Language Models
paper page:
Large language models (LLMs) have accomplished remarkable reasoning performance in various domains. However, in the domain of reasoning tasks, we discover a

3
46
237
0
0
6
Some references of neural-symbolic work (incomplete) on length generalization: , , , empirically showing 100% generalization up to 5000-digit addition and some other algorithmic reasoning problems. [9/9]

0
0
7
Again, we observe a significant performance drop across all LLMs after reordering.
6/8

1
0
7
@stevenhoi
Thanks for the comment! I saw this work before, and I am also very excited about RL for code generation. The main points of our work is teaching LLM to self-debug: (1) via few-shot prompting w/o training; and (2) via code explanation, enabling it to self-debug w/o unit tests.
1
0
7
5/
For math reasoning problems, USC matches the performance of SC while eliminating the need of parsing answers to aggregate.

1
0
5
4/
On code generation, USC matches the performance of execution-based SC that selects the code with the most consistent execution outputs, while USC does not require code execution.

1
0
6
Very excited to co-organize the ICCV Workshop on Adversarial Robustness in the Real World ()! Please join us tomorrow with 8 amazing speakers!

𝟐𝐧𝐝 𝐖𝐨𝐫𝐤𝐬𝐡𝐨𝐩 𝐨𝐧 𝐀𝐝𝐯𝐞𝐫𝐬𝐚𝐫𝐢𝐚𝐥 𝐑𝐨𝐛𝐮𝐬𝐭𝐧𝐞𝐬𝐬 𝐢𝐧 𝐭𝐡𝐞 𝐑𝐞𝐚𝐥 𝐖𝐨𝐫𝐥𝐝
@ICCV_2021
happens tomorrow!
#ICCV2021
#AROW
🚩Website (join instruction will be here):
📅Time: 08:45 AM – 5:00 PM (EDT, UTC-4), OCTOBER 11, 2021

0
20
67
0
0
6
@goodside
Thanks for the reference! Your prompt is a good example for judging the factuality based on consistency. We show that even if the responses are not 100% consistent, USC still improves reasoning, coding, factuality, etc, and its selection highly matches the majority consensus.
1
0
4
3/
USC consistently improves the performance on free-form generation tasks, including long-context summarization and TruthfulQA, where SC is inapplicable.

1
0
5
@its_ericchu
Great point! Our paper also showed that there is still a gap between USC/SC and the oracle (if any response is correct). Our intuition is that USC is more likely to work if at least there is some agreement among responses, and USC can capture more subtle consistency than SC.
0
0
5
3/
This is joint work with amazing collaborators
@chengrun_yang
, Xuezhi Wang,
@yifenglou
,
@Hanxiao_6
,
@quocleix
,
@denny_zhou
. Also thanks for great discussion threads from
@_akhaliq
,
@emollick
,
@omarsar0
,
LLMs as Optimizers
This is a really neat idea. This new paper from Google DeepMind proposes an approach where the optimization problem is described in natural language.
An LLM is then instructed to iteratively generate new solutions based on the defined problem and previously

23
403
2K
0
1
4
Also, the CoT format in this paper is problematic. All other prompts show the step-by-step calculation per digit, while the CoT prompt looks clearly suboptimal. [4/9]

1
0
4
We have an amazing lineup of speakers: Zico Kolter (
@zicokolter
), Raquel Urtasun (
@RaquelUrtasun
), David Wagner, Alina Oprea (
@AlinaMOprea
), Aleksander Madry (
@aleks_madry
), Alan Yuille (
@YuilleAlan
), Christopher Ré, Catherine Olsson (
@catherineols
), and Aditi Raghunathan.
1
1
4
I believe investigating how LLMs can compose the knowledge of basic algorithms to solve more challenging reasoning problems (math, coding, logical reasoning, etc.) remains an important direction, and a lot more can be done. [8/9]
1
0
4
More information is available at our workshop website:
0
1
3
“describe the algo in enough detail so that there is no room for misinterpretation” is typically done in neural-symbolic methods, which achieve 100% accuracy on 1000x longer test samples for long-digit addition and some other algorithmic reasoning problems. [6/9]
1
0
3
@goodside
And yes, self-improvement training with USC for response selection is a promising direction! This combination can again extend the original LLM self-improvement paper to free-form text generation.
0
0
2
Meanwhile, our program synthesizer (LaSynth) can generate more concise programs than the given ground truth, and retraining with synthesized programs yields better performance with fewer samples.
1
0
3
@Scobleizer
@HuaixiuZheng
@Swarooprm7
Thanks! Most of our recent work are inspired by human reasoning process: abstraction (this work), analogical reasoning (), debugging for solving coding problems (), etc.
New preprint: Teach LLMs to self-debug! ()
With few-shot demonstrations, LLMs can perform rubber duck debugging: w/o error messages, it can identify bugs by explaining the predicted code. SOTA on several code generation benchmarks using code-davinci-002.
12
106
536
0
0
2
LaSynth outperforms those approaches without executors for Karel and (restricted) C code synthesis from input-output examples. Please check out our paper for more details:
Code:
Collaboration with
@dawnsongtweets
@tydsh
0
0
2
While LLMs do not guarantee 100% generalization yet, they have clear advantages of acquiring a wide variety of knowledge, especially those that can be more easily expressed in natural language. [7/9]
1
0
2
If we allow the model to keep decoding, it progressively solves longer expressions. Related to least-to-most prompting (). [3/9]
1
0
2
Generalize to adding more numbers (again, not 100% accurate) [2/9]
1
0
2
Very excited to announce our Adversarial Machine Learning in Computer Vision Workshop at CVPR 2020, with a BEST PAPER PRIZE! Please visit our website () for more details, and submit your work here!
Our Adversarial Machine Learning in Computer Vision Workshop (co-organized with
@xinyun_chen_
,
@SongBai_
, Bo Li, Kaiming He,
@drfeifei
, Luc Van Gool, Philip Torr(
@OxfordTVG
),
@dawnsongtweets
and Alan Yuille) is now accepting submissions, with a BEST PAPER PRIZE!
DDL: Mar 15 AoE

1
8
25
0
1
2
@stevenhoi
Thanks for the comment! I saw this work before, and I am also very excited about RL for code generation. The main points of our work is teaching LLM to self-debug: (1) via few-shot prompting w/o training; and (2) via code explanation, enabling it to self-debug w/o unit tests.
1
0
2
@stevenhoi
I have also done some work on the synthesize-execute-debug loop before the LLM era, e.g., . We will keep revising our draft to add more discussion and draw connections to other related works in this field.
0
0
2
@oh_that_hat
@denny_zhou
@Azade_na
@hugo_larochelle
@AaronCourville
@bneyshabur
@HanieSedghi
Here is the link: . Note that we added space between each digit, making it harder for the model to directly retrieve the answer from training data.

1
0
1
@OriolVinyalsML
@liyuajia
Thanks a lot! It was great talking to you and many others at DeepMind. Looking forward to seeing you in person sometime in the future!
0
0
1
@Zhen4good
However, I think adding more data alone is still insufficient. In particular, it is unclear how well the model can generalize to new planning tasks if we simply finetune on existing ones. More work is needed to fundamentally improve the overall LLM planning capability.
0
0
1
Our afternoon session is starting now! Please join us via the links at
0
0
1
0
0
1
@CSProfKGD
@DavitSoselia_
@dawnsongtweets
@ChulinXie
Yes this is our recording. Thank you for sending the link!
0
0
1
@yar_vol
Thanks for asking! We evaluated GPT-4 (e.g., see the figure) and other LLMs in the paper.

1
0
1
@Zhen4good
Thanks for your question! If we fine-tune the model on the same planning tasks, I think the performance will improve, as suggested in Figure 9 of our paper on many-shot VS 1-shot prompting; e.g., trip planning improves from 2.7% (1-shot) to 40%+ (100-shot) with Gemini 1.5 Pro.
2
0
1
@FeiziSoheil
@ml_umd
Thank you Soheil! Looking forward to talking to you more in the future! :)
0
0
1
@EarlenceF
@cihangxie
@RaquelUrtasun
According to the ICLR policy, we are not able to publicly release the talk recordings ourselves, so the recording will stay on the internal ICLR workshop website. However, ICLR plans to publicly release all recordings publicly several days after the conference ends.
0
0
1
@Sravanti_A
@iclr_conf
@zicokolter
@AdamKortylewski
@aleks_madry
@catherineols
@AlinaMOprea
@RaquelUrtasun
@YuilleAlan
@ravenben
Thanks for your great suggestion! In fact, in our initial workshop proposal, some events were scheduled in different time zones. However, we were instructed to only pick one time zone in the end. We will definitely keep your suggestion in mind when we schedule future events.
1
0
1
I thought it was zero-shot “let’s think step by step” (), but even the zero-shot prompt looks better… [5/9]
1
0
1
@rm_rafailov
This is a great point! One future direction is to use USC to improve training: generate multiple responses per query, then apply USC to select good SFT training targets, or for RLHF ranking.
0
0
0