
Chunting Zhou
@violet_zct
Followers
2,641
Following
278
Media
30
Statuses
138
Research Scientist at FAIR. PhD @CMU . she/her.
Seattle, WA
Joined July 2015
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Flamengo
• 238981 Tweets
Beyoncé
• 207679 Tweets
Pink
• 180322 Tweets
#DNC2024
• 147740 Tweets
#DNCConvention2024
• 84569 Tweets
Cruzeiro
• 69140 Tweets
Bolívar
• 59072 Tweets
Rossi
• 49171 Tweets
The Chicks
• 39402 Tweets
FAYEYOKO 1ST FANMEET TICKET
• 37546 Tweets
Advincula
• 32252 Tweets
京都国際
• 31551 Tweets
Yachty
• 30977 Tweets
Adam Kinzinger
• 29795 Tweets
ラストマイル
• 24173 Tweets
Romero
• 23677 Tweets
Izquierdo
• 23451 Tweets
甲子園決勝
• 22658 Tweets
Riquelme
• 18740 Tweets
#ドンシェルジュ
• 18034 Tweets
Ayrton Lucas
• 17251 Tweets
Figal
• 16428 Tweets
Milton
• 16142 Tweets
関東第一
• 16062 Tweets
Carlinhos
• 16042 Tweets
O Tite
• 15789 Tweets
Kerry Washington
• 15371 Tweets
Kemp
• 14864 Tweets
Gerson
• 13639 Tweets
Vignolo
• 11430 Tweets
Zenón
• 10874 Tweets
#PremiosIdolo
• 10743 Tweets
Cassio
• 10500 Tweets
#BOLxFLA
• 10304 Tweets
Bruno Henrique
• 10149 Tweets





















How do you turn a language model into a chatbot without any user interactions?
We introduce LIMA: a LLaMa-based model fine-tuned on only 1,000 curated prompts and responses, which produces shockingly good responses.
* No user data
* No mode distillation
* No RLHF

27
230
1K
I'm excited to share our work on a new sequence modeling architecture called Mega: Moving Average Equipped Gated Attention. Mega achieves SOTA results on multiple benchmarks, including NMT, Long Range Arena, language modeling, ImageNet and raw speech classification.

9
56
375
How to enjoy the best of both worlds of efficient training (less communication and computation) and inference (constant KV-cache)?
We introduce a new efficient architecture for long-context modeling – Megalodon that supports unlimited context length. In a controlled head-to-head
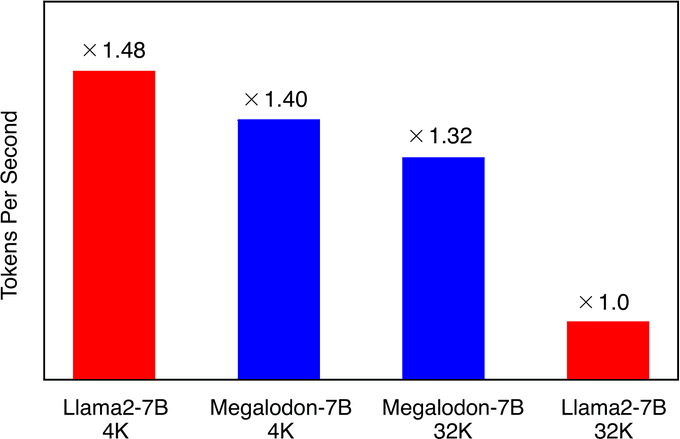
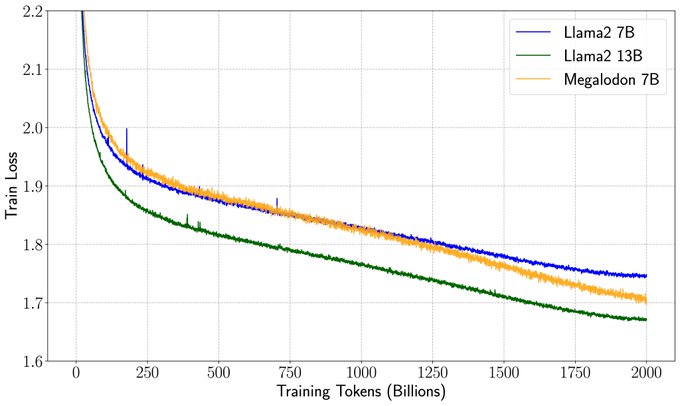
4
51
226
``Understanding Knowledge Distillation in Non-autoregressive Machine Translation": (, accepted by ICLR 2020!)
We first systematically studied why and how non-autoregressive generation models benefit from the knowledge distillation technique.

1
26
179
Mega is now open source at:
Feel free to play with it!
@MaxMa1987
@XiangKong4
@junxian_he
@liangkegui
@jonathanmay
@gneubig
@LukeZettlemoyer

I'm excited to share our work on a new sequence modeling architecture called Mega: Moving Average Equipped Gated Attention. Mega achieves SOTA results on multiple benchmarks, including NMT, Long Range Arena, language modeling, ImageNet and raw speech classification.
9
56
375
2
32
174
Introducing FlowSeq: Generative Flow-based Non-Autoregressive Seq2Seq generation
@emnlp2019
()!
FlowSeq allows for efficient parallel decoding while modeling the joint distribution of the output sequence.
Our code is at .

1
47
170
Check out our recent work on parameter-efficient fine-tuning. We present a unified framework that establishes connections between state-of-the-art methods (e.g. Prefix-Tuning, Adapters, LoRA).
Great collaboration with
@junxian_he
and others
@MaxMa1987
,
@BergKirkpatrick
@gneubig
!

4
25
152
🚀 Excited to introduce Chameleon, our work in mixed-modality early-fusion foundation models from last year! 🦎 Capable of understanding and generating text and images in any sequence. Check out our paper to learn more about its SOTA performance and versatile capabilities!

Newly published work from FAIR, Chameleon: Mixed-Modal Early-Fusion Foundation Models.
This research presents a family of early-fusion token-based mixed-modal models capable of understanding & generating images & text in any arbitrary sequence.
Paper ➡️

27
200
943
3
19
112
I am excited to introduce our EMNLP paper ``Distributionally Robust Multilingual Machine Translation”. To encourage uniform performance across languages, we propose a new learning objective for multilingual training based on the concept of distributionally robust optimization.
5
14
97
Does syntactic reordering help in Neural Machine Translation? Checkout our
@emnlp2019
paper , we reorder target-language monolingual sentences to the source order and use as an additional source of training supervisions. (1/2)

1
25
82
I will be at NeurIPS 12/11-12/14, happy to meet friends and chat about (pretraining) of new efficient architectures and multimodality foundation models. Feel free to stop by and say hi at my poster session (LIMA) Wednesday 10:45-12:45 at Great hall &Hall B1 +B2.
4
9
77
I am happy to participate in the virtual conference on LLMs in Production Part II on 15-16th of June. I will be speaking about LIMA: Less is More for Alignment (June 16th at 9:20 PM - 9:30 PM PM CET). Register here to join us! ()

1
7
50
Neural sequence generation models can hallucinate unfaithful content that is not supported by the source input. How to detect the hallucinated tokens and reduce them? Check out our ACL-finding paper: Detecting Hallucinated Content in Conditional Neural Sequence Generation.
1
7
47
So what do we learn about alignment?
One hypothesis is that almost all of the knowledge and capabilities are already learned in pretraining, and alignment just needs to teach the model which format or style to use when interacting with a user.
Let me know other hypotheses?(8/8)
3
6
46
What does this tell us about language model alignment? (2/n)
😇 We are working on open sourcing the training data and test prompts - hope to update on this soon!
2
2
35
@WenhuChen
@Teknium1
I think the motivation of LIMA is not to quantify the number of SFT examples that is needed but to highlight (1) how important high quality SFT data is and (2) the superficial alignment hypothesis where pretrained LLM stores all the knowledge and can be easily tuned into an
0
4
34
Testing a chatbot w/o real users is hard and noisy. We create test prompts from a slightly different distribution, and eval how well LIMA answers them. While it’s no surprise that GPT-4 is overall better, it’s quite amazing how often LIMA is on par or preferable! (3/n)

1
3
23
Surprise! 🥳
LIMA fine-tuned on only 1,000 single-turn interactions extrapolates to multi-turn conversations 😮
If we only 30 curated multi-turn dialogues to the training set, LIMA becomes even more conversational. (6/n)

1
1
21
Our ablation studies show that both response quality and prompt diversity (task and domain) play a vital role in creating an effective supervised fine-tuning dataset. (7/n)

1
3
21
Also, let’s not forget that comparing with GPT-4 is a pretty high bar. LIMA is not product grade, and it does fail (e.g. math), but it generalizes rather well to a lot of new prompts. (4/n)


1
1
20
So what’s the trick?
We collect 1,000 examples from:
* Community Q&A websites (750 examples)
* Super-Natural Instructions (50 examples)
* Manually authored examples, where we set a uniform tone that mimics a helpful AI assistant (200 examples)
(5/n)


1
2
19
This is my internship project at FAIR last summer, thank you, my awesome collaborators:
@gh_marjan
@LukeZettlemoyer
@thoma_gu
@gneubig
@guzmanhe
and Mona Diab
Paper:
Code: (with our annotated test sets in MT) [2/n]

1
3
17
Very clear explanation of the connection between EMA and recent diagonal SSMs! We will see how Mega works by replacing EMA with S4D.

Amazing results! My take: Mega is a direct hybrid of SSMs + attention — I think these methods are complementary and I'm super optimistic about this direction 🚀
Mega’s core EMA layer is a close variant of recent diagonal SSMs (DSS, GSS, S4D, and S5). Some technical notes 🧵

2
29
176
0
0
17
Wonderful collaborations with
@MaxMa1987
,
@_xiaomengy_
,
@XiongWenhan
,
@BeidiChen
,
@liliyu_lili
,
@haozhangml
,
@jonathanmay
,
@LukeZettlemoyer
and
@omerlevy_
.
Paper:

1
3
17
Thanks
@pmichelX
for tweeting our work! Please check out our work if you'd like to know when group distributionally robust optimization works well (perfect partition) and when it does not (imperfect partitions of groups). 🧐

If you are interested how models can pick up spurious features from biased training data, and how we can train them to be robust to these spurious correlations, even with imperfect information, I highly recommend that you check out
@violet_zct
's ICML paper

2
16
70
0
2
15
Great collaboration with my amazing coauthors!
@stefan_fee
, Puxin Xu,
@sriniiyer88
,
@sunjiao123sun_
,
@yuning_pro
,
@MaxMa1987
,
@AviaEfrat
, Ping Yu,
@liliyu_lili
,
@suchenzang
,
@gargighosh
,
@ml_perception
,
@LukeZettlemoyer
and
@omerlevy_
! 🥰
0
1
15

Main Idea 3/3: We employ gated attention and provide theoretical justification to show that single-head attention is as expressive as the multi-head one when using a gating function.

1
0
13
Great collaborations with
@MaxMa1987
,
@XiangKong4
,
@junxian_he
,
@liangkegui
,
@gneubig
,
@jonathanmay
and
@LukeZettlemoyer
.
Paper:
Code will be release soon, please DM us if you want to try our model now.
3
0
12
Main Idea 1/3: We incorporate strong inductive bias via exponential moving average (EMA) to assist long-range attention. EMA is a classic method for time series data modeling that focuses on local recency, while the popular attention mechanism has weak inductive bias.
1
0
12
Mega is good at modeling both discrete and continuous signals, and we believe it has a great potential for multi-modality modeling.
1
0
12
Feel free to stop by and say hi at our poster session (Poster session 6, spot B1, 9 PM-11 PM PST, July 22th).
Code available at: .

Thanks
@pmichelX
for tweeting our work! Please check out our work if you'd like to know when group distributionally robust optimization works well (perfect partition) and when it does not (imperfect partitions of groups). 🧐
0
2
15
0
2
9
Great findings and analysis by
@xiamengzhou
on the pre-training trajectories (intermedia checkpoints) across different model scales! Please check it out.

How do language models of different sizes learn during the course of pre-training?
We study the training trajectories with training checkpoints of language model from 125M to 175B for a better understanding!
Check out our new paper 📜:
(1/N)
11
75
402
0
0
10
Main Idea 2/3: We combine EMA with gated attention to better model the dependencies of different patterns. In addition, the EMA sublayer also allows us to propose a variant of Mega --- Mega chunk that enjoys linear time and space complexity by performing chunk-wise attention.
1
0
10
Well-executed benchmark on web agents, check out this from
@shuyanzhxyc
!

🤖There have been recent exciting demos of agents that navigate the web and perform tasks for us. But how well do they work in practice?
🔊To answer this, we built WebArena, a realistic and reproducible web environment with 4+ real-world web apps for benchmarking useful agents🧵

8
72
377
0
1
10
We find significant improvements in low-resource MT setting with divergent language pairs.
With
@gneubig
,
@MaxMa1987
and
@JunjieHu12
! (2/2)
0
1
10

8/n Main idea 3/3: To improve large-scale pretraining stability, we proposes normalized attention and pre-norm with two-hop residual configuration:

1
1
8
Results on raw speech classification, language modeling, neural machine translation and ImageNet-1k, where XFM represents Transformer.

1
0
8
(4) For future related research: Rather than hastily conclude that the model achieves comparable performance to full-finetuning with only experiments on GLUE tasks, it’s better to evaluate a new method on tasks with different resources and complexity, e.g. summarization, MT, etc.
1
0
8
7/n Main idea ⅔: We propose the timestep normalization layer, which generalizes the group normalization layer to auto-regressive sequence modeling tasks to allow normalization along the sequential dimension.

2
0
8
4/n PPL of Megalodon (7b, training context 32K) on various context lengths from 4K to 2M on the validation set.

1
0
8
@rasbt
Thanks for tweeting it! Just a note: For 7B model, I recommend upsampling the author written data + NLP by twice.
1
0
8
6/n Main idea ⅓: We introduce the complex exponential moving average (CEMA) component, which extends the multi-dimensional damped EMA in MEGA to the complex domain.
1
0
7

1
0
7
@zimvak
@arankomatsuzaki
We have compared with Transformer-XL, please check out our results on Wikitext-103.
0
0
7
3/n Megalodon also outperforms Llama2 on a wide range of academic benchmarks.

1
0
6
Link to the paper:
1
0
6

10/n Results on Long Range Arena (LRA). We significantly narrow the gap between chunk-wise attention and full attention.

1
0
5
Check it out! Controllable summarization with great results from
@junxian_he
.

Glad to see the blog post up! I had a wonderful time working on controllable summarization with
@SFResearch
last year. We explored a keyword-based way to control summaries along multiple dimensions.
Models and demos are available at
@huggingface
(Credit to
@ak92501
)
1
5
29
1
0
5
9/n Results on raw speech classification, ImageNet-1K, WikiText-103 and PG19.

1
0
5
We break down the design of state-of-the-art parameter-efficient tuning methods, and the proposed unified framework allows us to design better method that matches full fine-tuning on various tasks with less parameters.
2
0
4
@boknilev
@jonathanmay
I knew this benchmark, but unfortunately we don’t have a pre-trained Mega yet. Scrolls is definitely a great benchmark to test when there is a pre-trained Mega.
0
0
4
@rasbt
Note 3: Directly re-learn the <eos> token as the end-of-turn may not work for small models (7B). If you don’t want to bother yourself inserting a new token <eot> into the original model weights, you can use other ways to separate the dialogue turns,
0
0
3
@NielsRogge
@MaxMa1987
We are releasing the code soon, please DM us for the code and scripts if you'd like to try it now.
0
0
3
(3) Composition function: we found a simple scaled addition of the modification vector to the PLM hidden states is effective for better performance.
1
0
3
@rajhans_samdani
We’ll definitely release the test set and our generations, not sure if we can release the human ratings, need to check with legal team :-)
1
0
3
@rasbt
Note 2: Using proper regularization (my recommended value: 0.2 for 7B and 30B, 0.3 for 65B) is important when training on small data, but not the specific form. You can use regular hidden dropout instead of residual dropout (described) in the paper.
1
0
2
@yoquankara
@junxian_he
It would be great you could share the results with us later, thanks and no rush!
0
0
2
We developed an unsupervised method for token-level hallucination detection and used this tool to improve noisy training and reduce hallucinations. I will present our work in the ACL GEM workshop between 11 - 11:30 am EDT 8/6 (Friday). [1/n]
1
0
2
0
0
1
(1) Insertion form: the tunable module is better inserted into the pre-trained LM in a “parallel” manner instead of sequentially.

1
0
2
The main idea of DRO is to optimize the model over an uncertainty set of potential distributions we wish to perform well on. We hope our work could motivate better distributionally robust learning methods for
multilingual training or similar settings.
1
0
2

@KarimiRabeeh
@ak92501
@junxian_he
Hey thanks for you question, simply speaking Mix-and Match employs prefix-tuning at attention layer with very small bottleneck dimension (length of prefix vectors, e.g. 30) and our improved adapters with larger bottleneck dimensions at the FFN layers.
0
0
2
@_albertgu
Thanks! Yes, we described this connection with S4 and its variants in the last paragraph of Section 3.2
0
0
2
@KarimiRabeeh
@ak92501
@junxian_he
This structure gives the best performance with least addition parameters. This instantiation is derived from our unified framework of different parameter-efficient models, which is reasoned and explained in the paper.
1
0
2
Poster:
ACL GEM workshop link (11 - 11:30 am EDT, 8/6): [3/n]
1
0
1
In multilingual training, the amount and type of training data available varies drastically across languages. With limited capacity, models trained with ERM (minimize average loss) can result in trade-offs or decreased performance on some languages.
1
0
1
(2) Where to apply the modification: FFN sub-layer is a sweet spot that can better utilize increased capacity, while the attention sub-layer performs better when the tunable parameter budget is small.
1
0
1
@Bluengine
EMA can be computed at once for all tokens since we can compute its kernel in advance, on the other hand, GRU can only be computed sequentially.
0
0
1
@simran_s_arora
@srush_nlp
@realDanFu
@SonglinYang4
Thank you Sasha! It was really fun talking and discussing with you 🧠
0
0
1
We re-frame parameter-efficient tuning methods as modifications to specific hidden states in the pre-trained models. We analyze the modification functional form, insertion form, where to apply the modifications, and composition function. There are 4 main takeaways:
1
0
1
@xhluca
@MaxMa1987
@XiangKong4
@junxian_he
@liangkegui
@jonathanmay
@gneubig
@LukeZettlemoyer
We have that plan and before that we’d like make a more efficient version first.
0
0
1
Our method not only outperforms strong baseline methods in token-level hallucination detection, but also performs remarkably well in quality estimation for machine translation (WMT). [4/n]
1
0
1
@SinclairWang1
@gneubig
@junxian_he
@MaxMa1987
@BergKirkpatrick
Thanks! And yes, we are releasing the code soon.
1
0
1
@_ironbar_
For 7B model, I found it necessary to use this additional token instead of the original <eos>. For larger models, it doesn’t matter too much. But I guess other methods, e.g. <User>: xx <Assistant>:xx may also work, although I haven’t tested them myself.
0
0
1
1
0
1
w.r.t. noisy training where training targets are noisy (e.g. web-crawled MT corpus, self-training with weak teacher models), we proposed a fine-grained loss that excludes tokens predicted as hallucinations by our system, which improves SoTA methods in the low-resource MT setting
0
0
1
1
0
1
@nbroad1881
@MaxMa1987
@XiangKong4
@junxian_he
@liangkegui
@gneubig
@jonathanmay
@LukeZettlemoyer
That's a good suggestion! We will release the checkpoints soon, and will consider putting them on the hf hub, too.
0
0
1
@srchvrs
Would like to clarify which head are you talking about? the attention head or the classification head? We view prompting tuning (prepending vectors before inputs) as an adapter used at the first attention layer.
1
0
1