

Srini Iyer
@sriniiyer88
Followers
1K
Following
638
Media
18
Statuses
139
Research Scientist at Facebook AI Research
Seattle, WA
Joined February 2012
New paper! Byte-Level models are finally competitive with tokenizer-based models with better inference efficiency and robustness! Dynamic patching is the answer! Read all about it here: https://t.co/GJSiFtugju (1/n)
1
22
86
Turns out, if you teach llamas how to self-reflect and backtrack from wrong reasoning paths, it does extra well on math reasoning! - MATH 500: 65.8% ➡️ 81.8% - AMC 23: 37.5% ➡️ 64.4% - AIME 24: 10% ➡️ 30% Amazing work by @danieljwkim, can be a nice long weekend read!

Can we improve Llama 3’s reasoning abilities through post-training only? Introducing ASTRO, our new framework that teaches LLMs to perform in-context search and generate long CoT to solve math problems, via SFT and RL. Work done at @aiatmeta. 📄 Paper: https://t.co/PdzwNVqkJ2
1
13
65
This is exciting! Check out our new step-by-step playbook that shows how to do MoT on top of your existing transformer implementation! Also, MoT is now in TMLR! Huge congrats to @liang_weixin, @VictoriaLinML and others!

🎉 Excited to share: "𝐌𝐢𝐱𝐭𝐮𝐫𝐞-𝐨𝐟-𝐓𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐞𝐫𝐬 (𝐌𝐨𝐓)" has been officially accepted to TMLR (March 2025) and the code is now open-sourced! 📌 GitHub repo: https://t.co/KiDbxpDWt0 📄 Paper: https://t.co/KQoZ3cunEf How can we reduce pretraining costs for


1
1
4

We just released model weights for our 1B & 8B-parameter BLT: Byte Latent Transformer, token-less model with sig. improvements in inference efficiency and robustness Model on @huggingface: https://t.co/vMyZOpZy3M Code: https://t.co/iKoyxKG40l Paper: https://t.co/FLBRnHLl5d

12
78
469

By popular demand (see our GH issues 😅), we're releasing 1B and 8B weights for our BLT models! We're also hard at work at adding BLT to HF transformers! Model Weights: https://t.co/gfqg5ADYkg Code + Instructions for loading weights:
github.com
Code for BLT research paper. Contribute to facebookresearch/blt development by creating an account on GitHub.
0
6
19
🚀 Meta FAIR is releasing several new research artifacts on our road to advanced machine intelligence (AMI). These latest advancements are transforming our understanding of perception. 1️⃣ Meta Perception Encoder: A large-scale vision encoder that excels across several image &
55
224
971

Excited to share that we are open sourcing BLT model weights by popular demand(Code was open sourced already): https://t.co/qSYqfYqsZr
https://t.co/YCWzfh7vnb paper:
ai.meta.com
Meta FAIR is releasing several new research artifacts that advance our understanding of perception and support our goal of achieving advanced machine intelligence (AMI).
2
6
26
0
0
3
BLT model weights are out! Responding to popular demand, we just open-sourced model weights for our 1B and 8B BLT models for the research community to play with! https://t.co/XQsYrM9GqK Hoping to see many new and improved BLT based architectures this year!
huggingface.co
3
21
71
We're hiring PhD interns for Summer 2025 in Seattle to work with us on improving BLT even more! If this is something that excites you, reach out to me on dm/email asap!

New from Meta FAIR �� Byte Latent Transformer: Patches Scale Better Than Tokens introduces BLT, which for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency & robustness. Paper ➡️ https://t.co/0iamZCRnMN

4
29
315
BLT related post by Meta AI - eliminate all tokenization once and for all!
New from Meta FAIR — Byte Latent Transformer: Patches Scale Better Than Tokens introduces BLT, which for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency & robustness. Paper ➡️ https://t.co/0iamZCRnMN
0
3
10

Meta's Byte Latent Transformer (BLT) paper looks like the real-deal. Outperforming tokenization models even up to their tested 8B param model size. 2025 may be the year we say goodbye to tokenization.

0
2
3

Gm. Woke up to a new paper on Byte Latent Transformers (BLT). Now you can increase model size without increasing inference compute by tweaking *patch sizes*. Great day for LLMs. Full article: https://t.co/ZLZIf0i7vb

3
3
12

Meta AI's Byte Latent Transformer (BLT) is revolutionizing the tokenization process, enhancing scalability and efficiency. This model could redefine how we approach natural language processing, paving the way for more streamlined AI applications. Exciting times ahead for tech
1
1
3

[13 Dec 2024] Meta BLT: Tokenizer-free, Byte-level LLM https://t.co/JyB3XgAkU3 a few months ago @karpathy noted that tokenizers are the root of all evils in llm flaws. Could @AIatMeta have finally cracked the algorithm to process byte-level data directly (enabling all kinds of


META JUST KILLED TOKENIZATION !!! A few hours ago they released "Byte Latent Transformer". A tokenizer free architecture that dynamically encodes Bytes into Patches and achieves better inference efficiency and robustness! (I was just talking about how we need dynamic



7
7
41

Pretty cool work on tokenization-less transformer from Meta! > Byte Latent Transformer (BLT), byte-level LLM architecture, matches tokenization-based LLM performance > BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. >
2
5
22

Been waiting for this one, a strong step in removing tokenization from LLMs. Congrats to the team!
New paper! Byte-Level models are finally competitive with tokenizer-based models with better inference efficiency and robustness! Dynamic patching is the answer! Read all about it here: https://t.co/GJSiFtugju (1/n)
0
3
19

This could be one of the biggest AI papers of the year, if it really works as well as they report in this paper. It's hard to overstate how impactful ending the tyranny of tokenizers would be for AI. I'm very eager to see the open source implementations and replications.

🚀 Introducing the Byte Latent Transformer (BLT) – An LLM architecture that scales better than Llama 3 using byte-patches instead of tokens 🤯 Paper 📄 https://t.co/5QGrlJdK0y Code 🛠️ https://t.co/jCdDI5BXwe

3
3
16

Llamas ... Tokenizer Free?! USING ENTROPY STEERING?!?!! sometimes the universe conspires to make a paper just for you and it feels wonderful when it happens.
🚀 Introducing the Byte Latent Transformer (BLT) – An LLM architecture that scales better than Llama 3 using byte-patches instead of tokens 🤯 Paper 📄 https://t.co/5QGrlJdK0y Code 🛠️ https://t.co/jCdDI5BXwe
12
36
709


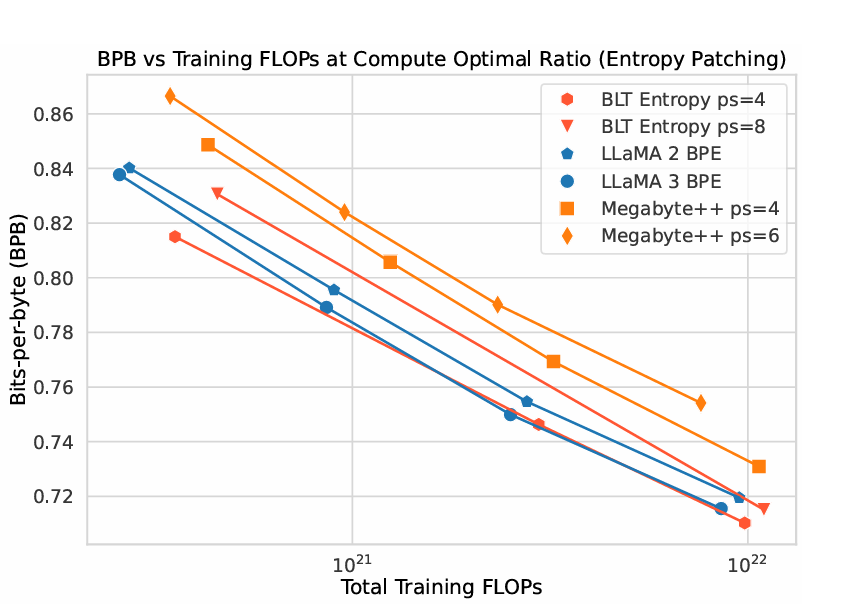
We scaled up Megabyte and ended up with a BLT! A pure byte-level model, has a steeper scaling law than the BPE-based models. With up to 8B parameters, BLT matches Llama 3 on general NLP tasks—plus it excels on long-tail data and can manipulate substrings more effectively. The
🚀 Introducing the Byte Latent Transformer (BLT) – An LLM architecture that scales better than Llama 3 using byte-patches instead of tokens 🤯 Paper 📄 https://t.co/5QGrlJdK0y Code 🛠️ https://t.co/jCdDI5BXwe
0
10
70