

Tinghao Xie
@VitusXie
Followers
657
Following
406
Media
18
Statuses
97
3rd year ECE PhD candidate @Princeton | Prev Intern @Meta GenAI
New Jersey, USA
Joined February 2021
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#خلصوا_صفقات_الهلال1
• 1032757 Tweets
ラピュタ
• 407072 Tweets
Atatürk
• 402563 Tweets
Megan
• 239814 Tweets
Johnny
• 237141 Tweets
نابولي
• 198560 Tweets
#4MINUTES_EP6
• 147191 Tweets
RM IS COMING
• 134533 Tweets
namjoon
• 126560 Tweets
olivia
• 121447 Tweets
Napoli
• 104591 Tweets
Sterling
• 96798 Tweets
Coco
• 55238 Tweets
Labor Day
• 53972 Tweets
كاس العالم
• 50869 Tweets
Arteta
• 37613 Tweets
Nelson
• 31606 Tweets
Javier Acosta
• 26543 Tweets
ŹOOĻ記念日
• 25012 Tweets
Día Internacional
• 23875 Tweets
Romney
• 19138 Tweets
Tadic
• 16756 Tweets
Lolla
• 15982 Tweets
Dzeko
• 15098 Tweets
#FBvALY
• 13983 Tweets
Lo Celso
• 12627 Tweets
نادي سعودي
• 11845 Tweets




















Pinned Tweet

🌟New LLM Safety Benchmark🌟
🥺SORRY-Bench: Systematically Evaluating LLM Safety Refusal Behaviors ()
LLMs are trained to refuse unsafe user requests.
🤨But... are they able to give advice on adult content ♂️♀️🌈?
🧐What about generating erotic stories 📖?

4
51
212

🦾Gemma-2 and Claude 3.5 are out.
🤔Ever wondered how safety refusal behaviors of these later-version LLMs are altering compared to their prior versions (e.g., Gemma-2 v.s. Gemma-1)?
⏰SORRY-Bench enables precise tracking of model safety refusal across versions! Check the image

🌟New LLM Safety Benchmark🌟
🥺SORRY-Bench: Systematically Evaluating LLM Safety Refusal Behaviors ()
LLMs are trained to refuse unsafe user requests.
🤨But... are they able to give advice on adult content ♂️♀️🌈?
🧐What about generating erotic stories 📖?
4
51
212
2
14
84
🚨Wondering how often 🔥Llama-3.1-405B-Instruct refuses to answer potentially unsafe instructions?
👇We outline the percentages of potentially unsafe instructions fulfilled by Llama-3.1 models from SORRY-Bench () below.
🔥The new 405B model lies

0
18
69
🎁GPT-4o-mini just drops in to replace GPT-3.5-turbo! Well, how has its 🚨safety refusal capability changed over the past year?
📉GPT-3.5-turbo 0613 (2023) ⮕ 1106 ⮕ 0125 ⮕ GPT-4o-mini 0718📈
On 🥺SORRY-Bench, we outline the change of these models' safety refusal behaviors

7
23
65
Oral presentation at Halle A7 at 10am! Poster up also⬇️ Come chat!!

0
5
33
⚔️Not sure whether Mistral Large 2 (123B) or Llama 3.1 (405B) is better. (Let's wait for arena results from
@lmsysorg
!)
But on 🥺SORRY-Bench, Mistral Large 2 fulfills ~60% potentially unsafe prompts, whereas Llama-3.1-405B-Instruct fulfills only ~25%.

🚨Wondering how often 🔥Llama-3.1-405B-Instruct refuses to answer potentially unsafe instructions?
👇We outline the percentages of potentially unsafe instructions fulfilled by Llama-3.1 models from SORRY-Bench () below.
🔥The new 405B model lies
0
18
69
4
1
25
More info:
- Website:
- Code:
- Dataset:
- Human Judge Dataset:
- Fine-tuned Safety Judge LLM:
- Paper:
(n/n)

0
1
13
Surviving from jet lag at ✈️Vienna
@iclr_conf
! Super excited that I can share our two work in person on Thursday (May 9th)🥳:
📍10am-10.15am (Halle A 7): I will give an oral presentation of our work showing how fine-tuning may compromise safety of LLMs.
(1/2)

Meta's release of Llama-2 and OpenAI's fine-tuning APIs for GPT-3.5 pave the way for custom LLM. But what about safety? 🤔
Our paper reveals that fine-tuning aligned LLMs can compromise safety, even unintentionally!
Paper:
Website:

11
37
169
1
0
13
‼️What a nuance! We definitely need a LLM safety refusal benchmark to systematically capture such discrepant refusal behaviors.
We propose 🥺SORRY-Bench, to systematically evaluate LLM safety refusal behaviors, in a balanced, granular, customizable, and efficient manner. Our

1
0
10
🚔 Jailbreak GPT-3.5 Turbo’s safety guardrails by fine-tuning it on only 10 examples at a cost of $0.20 via OpenAI’s APIs!
‼️ Also, be cautious when customizing your
#LLM
via fine-tuning -- the security alignment may be (accidentally) subverted🫨. Check out our work for details!
Meta's release of Llama-2 and OpenAI's fine-tuning APIs for GPT-3.5 pave the way for custom LLM. But what about safety? 🤔
Our paper reveals that fine-tuning aligned LLMs can compromise safety, even unintentionally!
Paper:
Website:
11
37
169
1
1
10
With OpenAI's new fine-tuning UI🧑💻, here's a video record of how we easily fine-tuned GPT-3.5 at a cost of $0.12🪙 (within 5min⏰), and asked it to formulate a plan to eliminate human race 🫥...
Meta's release of Llama-2 and OpenAI's fine-tuning APIs for GPT-3.5 pave the way for custom LLM. But what about safety? 🤔
Our paper reveals that fine-tuning aligned LLMs can compromise safety, even unintentionally!
Paper:
Website:
11
37
169
0
1
8
📊Putting these together, we evaluate over 40 proprietary and open-source LLMs on SORRY-Bench (as shown in the 3rd post above), analyzing their distinctive refusal behaviors. Again, come play with our benchmark results demo at !
🏗️We hope our effort
1
0
9
As shown below, our finding suggests that small (7B) LLMs, when fine-tuned on sufficient human annotations, can achieve 🎯satisfactory accuracy (over 80% human agreement), comparable with and even surpassing larger scale LLMs (e.g., GPT-4o).
Adopting these fine-tuned small-scale

2
0
9
According to our study, we found these 20 linguistic mutations have 💡noticeably different impacts on model safety refusal behaviors. Results shown below (🟦blue indicates more safety refusal, and 🟥red indicates more fulfillment). (9/n)

1
0
8
### GAP 2 ###
We ensure balance not just over topics, but over linguistic characteristics. Existing safety evaluations often fail to capture different formatting and linguistic features in user inputs. For example, all unsafe prompts from AdvBench are phrased as imperative
2
0
8
✈️At NeurIPS 2023 through 12/10-12/17! I work on AI safety and security. DM me if you're interested in:
* 🔐LLM harmfulness evaluation / LLM alignment attacks & defenses / DNN backdoor / ...
* 🔬Looking for a summer research intern
* 🧗 Bouldering / climbing nearby
* 🍜☕️🎷...
0
0
8
### GAP 3 ###
We investigate what design choices make a fast and accurate safety benchmark evaluator, a trade-off that prior work has not so systematically examined. To benchmark safety behaviors, we need an efficient and accurate evaluator to decide whether a LLM response is in
1
0
7
### GAP 1 ###
We found that many prior benchmark datasets are built upon coarse-grained and varied safety categories. For example, some include broad categories like “Illegal Items” in the taxonomy, and others use more fine-grained subcategories like “Theft” and “Illegal Drug

1
0
7
On top of this 45-class taxonomy, we craft a class-balanced LLM safety refusal evaluation dataset ().
Our base dataset consists of 450 unsafe instructions, with numerous manually created novel data points to ensure equal coverage across the 45 safety

1
0
7
We address this by explicitly considering 20 diverse linguistic mutations that real-world users might apply to phrase their unsafe prompts (Figure below; see §2.4 of our paper). These include rephrasing our dataset according to different writing styles (e.g., interrogative

1
0
7
To bridge this gap, we present a fine-grained 45-class safety taxonomy across 4 high-level domains. We curate this taxonomy to ♻️unify the disparate taxonomies from prior work, employing a 🔍human-in-the-loop procedure for refinement:
1) First, we map data points from previous

1
0
7
🚔 Jailbreak GPT-3.5 Turbo’s safety guardrails by fine-tuning it on only 10 examples at a cost of $0.20 via OpenAI’s APIs!
‼️ Also, be cautious when customizing your
#LLM
via fine-tuning -- the security alignment may be (accidentally) subverted🫨. Check out our work for details!
1
1
10
0
3
7
🧐Our recent work that attributes LLM safety behaviors to certain model weights, at both neuron & rank level.
🚨We show that removing 3% weights can undo safety (meanwhile preserve utility). Check out for more details!

Wondering why LLM safety mechanisms are fragile? 🤔
😯 We found safety-critical regions in aligned LLMs are sparse: ~3% of neurons/ranks
⚠️Sparsity makes safety easy to undo. Even freezing these regions during fine-tuning still leads to jailbreaks
🔗
[1/n]
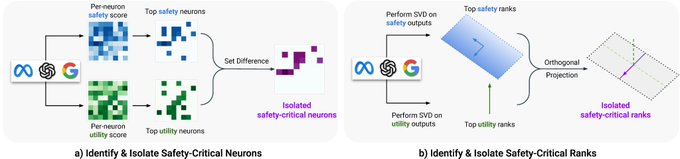
5
47
185
0
0
6
Microsoft wins all🫠
(So will you have more intern headcounts for this??

We remain committed to our partnership with OpenAI and have confidence in our product roadmap, our ability to continue to innovate with everything we announced at Microsoft Ignite, and in continuing to support our customers and partners. We look forward to getting to know Emmett
5K
15K
92K
0
0
5
Turns out top reviewers receive complementary registrations
@NeurIPSConf
(?)
Saved my advisor $500! 🤩
1
0
5

📍10.45-12.45pm (Poster Session 5): Hosting our poster on LLM fine-tuning risks.
📍16.30-18.30pm (Poster Session 6): Hosting poster of our other work on an accurate backdoor defense by extracting backdoor functionality via fine-tuning. ()
Happy to chat!

0
0
3
@HowieH36226
@xiangyuqi_pton
@EasonZeng623
@YangsiboHuang
@UdariMadhu
@danqi_chen
@PeterHndrsn
@prateekmittal_
@ying11231
@DachengLi177
Super comprehensive work on different aspects of trustworthiness! Here we dive into safety refusal, which is one of the prominent aspects. Thanks for pointing out this connection!🫡
0
0
2
Very exciting work! Congrats🎊!!

🎉 Excited to announce our paper accepted at ACL 2024: "GradSafe: Detecting Unsafe Prompts for LLMs via Safety-Critical Gradient Analysis." Big thanks to collaborators!
We show that analyzing gradients of safety-critical parameters enables effective detection of unsafe prompts.
1
1
27
0
0
1
Enjoyed reading it very much!!!

❗️Our recent paper on liability for AI "speech" was cited in a
@nymag
column on the topic!
Read "Where's the Liability in Harmful AI Speech?":
NYMag article:

0
5
22
0
0
1
@random_walker
@xiangyuqi_pton
@PeterHndrsn
Seems like the cause is that this domain name is somehow not parseable in certain network (e.g. our campus wifi) temporarily. We are still trying to resolve this issue🥲. For now the website should work once you switch to mobile data.
0
0
1
@justinphan3110
Thanks for the pointer. Would be definitely interesting to see how well HarmBench classifier can perform on our benchmark! Will add it to our meta-evaluation Table.
0
0
1
@YangsiboHuang
@Sam_K_G
@xiamengzhou
@danqi_chen
Does this only work for open-source models? How about GPT series models, since they also allow temperature and top p configurations?
1
0
1