

Weijie Su
@weijie444
Followers
5K
Following
4K
Media
49
Statuses
794
Associate Professor @Wharton & CS Penn. coDir @Penn Research #MachineLearning. PhD @Stanford. #MachineLearng #DeepLearning #Statistics #Privacy #Optimization.
Philadelphia, PA
Joined September 2011
10 years ago, ML papers were math-heavy. Advice I got: less math, more empirics. Today, many ML/AI papers lack even a single math formula, let alone math thinking. My advice to young LLM researchers: do a little math if possible. It'll distinguish yours from the sea of LLM.
48
174
2K
I receive large volumes of emails from Chinese students asking for summer internships. The English was often broken, but it has recently become native sounding😅.
47
28
1K
New Research (w/ amazing @hangfeng_he). "A Law of Next-Token Prediction in Large Language Models". LLMs rely on NTP, but their internal mechanisms seem chaotic. It's difficult to discern how each layer processes data for NTP. Surprisingly, we discover a physics-like law on NTP:

8
92
426
While learning French affects my English, it doesn’t affect math. So human brains are “locally elastic”: interaction depends on similarities! Our paper ( shows deep learning is also locally elastic, with implications on memorization, generalization, etc.
4
31
239
Are you fed up with VERY noisy reviews from NeurIPS, ICML, ICLR. ? Do you have your best papers rejected but mediocre papers accepted? If so, check out this NeurIPS 2021 paper:.
7
39
238
Enjoyed so much reading this review of deep learning theory literature:. Highly recommended!👍.
8
50
238
How does training time in #deeplearning depend on the learning rate? A new paper ( uncovers a fundamental *distinction* between #nonconvex and convex problems from this viewpoint, showing why learning rate decay is *more* powerful in nonconvex settings.

3
57
235
It feels so good to write single-author papers! In we introduce a phenomenological model toward understanding why #deeplearning is so effective. It is called *neurashed* because it was inspired by watershed. 8 pages and ~15mins read!

6
38
233
Our deep learning theory paper ( got accepted to PNAS! Introduced Layer-Peeled Model that can:.1. predict a hitherto unknown phenomenon that we term Minority Collapse in imbalanced training;.2. explain neural collapse discovered by Papyan, Han and Donoho.

3
29
189
My group has a postdoc opening in the "theoretical" aspects of LLMs (meaning doing research on LLMs without much compute). Send me an email if you're interested!.
4
18
143
A postdoc position is available. Pls shoot me an email if you're interested in any of the following three: the theoretical foundation of #deeplearning, #privacy-preserving machine learning, and game-theoretic approaches to estimation. Appreciate it very much for RTing🙏 1/4.
3
56
122
Good news while attending #ICML2023: Our deep learning "theory" paper *A Law of Data Separation in Deep Learning* got accepted by PNAS! . w/ amazing @hangfeng_he.
7
8
124
I'm genuinely honored and excited to receive the inaugural SIAM Activity Group on Data Science Early Career Prize in 2022 (. Very grateful to my amazing collaborators and mentors who helped make it possible for me.
12
9
119
Very honored to receive 2020 Sloan Research Fellowship #sloanfellow. Many thanks to collaborators, colleagues @Wharton @Penn and students for help & support along the way. Excited to use the funding by @SloanFoundation to further my research in #MachineLearning and #DataScience.

8
14
108
How does #deeplearning separate data throughout *all* layers?. w/ @hangfeng_he we discovered a precise LAW emerging in AlexNet, VGG, ResNet: . The law of equi-separation. What is this law about? Can it guide design, training, and model interpretation? 1/n


3
25
109
Introducing Preference Matching RLHF for aligning LLMs with human preferences :. 1. Standard RLHF is biased. Its algorithmic bias inherits from the reference model. 2. PM RLHF precisely aligns w/ RM preferences. This is mathematically provable and experimentally corroborated.

1
20
111
Happy to share that this paper is accepted to AOS. Excited not just for the acceptance, but (more) for the recognition of watermarking for LLMs as a topic in statistics. Watermarking is (basically) a pure stats problem—so many ideas in stats will light the path forward! 🚀📊 #AI.
New Research:. Watermarking large language models is a principled approach to combatting misinformation, but how do we evaluate their statistical efficiency and design even more powerful detection methods? 🤔 . Our new paper addresses these challenges using a new framework. 1/n

4
8
110
I'm very humbled to receive the 2022 Peter Gavin Hall IMS Early Career Prize. Thanks to my advisor, mentors, colleagues, and students who have helped me make it possible.

Weijie Su @weijie444 Wins Peter Gavin Hall IMS Early Career Prize . "for fundamental contributions to the development of privacy-preserving data analysis methodologies; for groundbreaking theoretical advancements in understanding gradient-based optimization methods; . 1/5

5
1
104
New interpretation of the *double descent* phenomenon: noise in features is ubiquitous, and we show using a random feature model that noise can lead to benign overfitting. Paper: w/ Zhu Li and Dino Sejdinovic.

3
17
100
Why do we need a *phenomenological* approach for understanding deep learning? Two new papers that use *local elasticity* for understanding the effectiveness of neural networks: and (NeurIPS 2020), from a phenomenological perspective.
4
16
98
Can (very) simple math inform RLHF for large language models?. New paper says YES!. Problem: 'write a love story' has many good responses but 'what's the capital of Peru' doesn't. However, human preference rankings cannot tell the difference!. Solution:⬇️
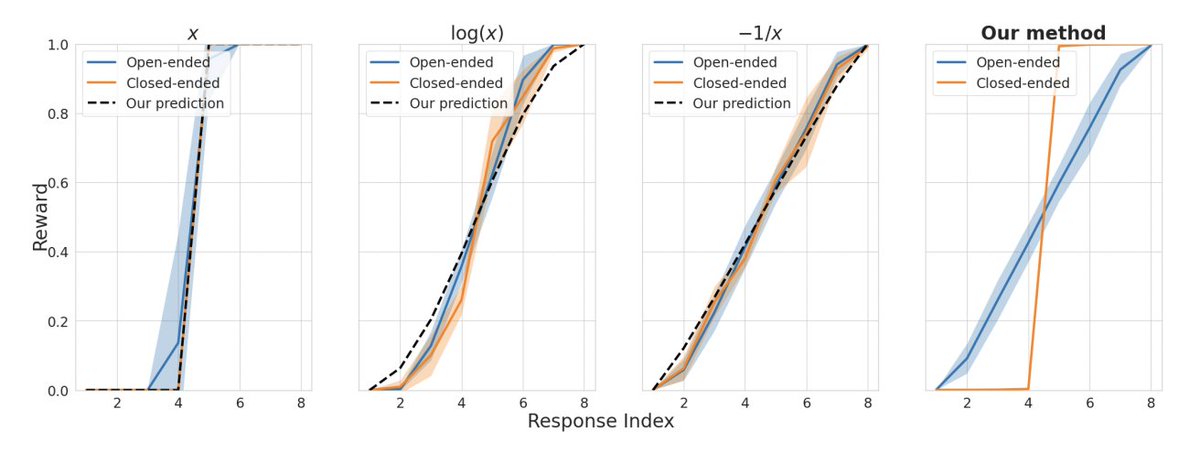
2
12
97
Is it worth 4 hours making a poster for #NeurIPS2021? Perhaps NOT for my paper "You Are the Best Reviewer of Your Own Papers: An Owner-Assisted Scoring Mechanism" cos from my experience there'll be ~5 ppl each spending 2mins skimming my poster in Gather Town on Dec 7 evening EST.

3
8
96

In a #NeurIPS2021 paper (, we introduced a *phenomenological* model toward understanding deep learning using SDEs, showing training is *successful* iff local elasticity exists---backpropagation has a larger impact on same-class examples.

3
16
69
Ongoing lawsuits against GenAI firms over possible use of #copyrighted data for training raise vital questions for our society. 🤖⚖️ How can we address the copyright challenges?. New research proposes a solution: . "An Economic Solution to Copyright Challenges of Generative AI"

1
13
70
Heading to the @TheSIAMNews Conference on Mathematics of Data Science #SIAMMDS22. Looking forward to seeing many colleagues and attending great talks.

2
9
67
Very excited to give a short course on large language models at #JSM2024 in Portland! w/ Emily Getzen and @linjunz_stat AI for Stat and Stat for AI! @AmstatNews

1
6
68
New Research:. Watermarking large language models is a principled approach to combatting misinformation, but how do we evaluate their statistical efficiency and design even more powerful detection methods? 🤔 . Our new paper addresses these challenges using a new framework. 1/n
3
11
64

📢 #ICML2024 authors! Help improve ML peer review! 🔬📝. Check your inbox for an email titled "[ICML 2024] Author Survey" and rank your submissions. 🏆📈. Your confidential input is crucial, and won't affect decisions. 🔒✅. Survey link in email or "Author Tasks" on OpenReview.
0
18
53

How to maintain the power of #DeepLearning while preserving #privacy? We recently applied Gaussian differential privacy to training neural nets, obtaining improved utility. Check out the paper ( and happy Thanksgiving!.
2
8
54
Learning rate is recognized as “the single most important hyper-parameter” in training deep learning. Inspired by statistical insights, our new paper ( proposes a dynamic learning rate schedule by splitting SGD for stationarity detection.
0
7
47
One-year postdoc position available in my group. Ideal for one on the job market but wishing to defer the tenure clock. Pls email me if you are interested in #privacy, #deeplearning theory, #optimization, high-dimensional statistics, and other areas of mutual interests.
0
9
46
@HighFreqAsuka Agree, I would emphasize 'mathematical thinking' rather than math formulae, equations, inequalities. .
2
1
47
It feels fun to write single-author papers! In a mechanism design (game theory) based framework of estimation asks:. Alice knows the quality of her n papers. What questions can Bob ask about her papers to improve the accuracy of review ratings?

2
6
43
#NeurIPS reviews just came out. It confirmed that "I am the best reviewer of my own papers."☹️.
I’ll be giving a talk “When Will You Become the Best Reviewer of Your Own Papers?” at @iccopt2022 tomorrow starting at 4:05 in Rauch 137. #optimization #iccopt2022.
1
2
44
Our paper "Understanding the Acceleration Phenomenon via High-Resolution Differential Equations" ( was accepted by Mathematical Programming. Thanks to my wonderful coauthors Bin, @SimonShaoleiDu, and Mike!.
3
4
44
Heading to Vancouver tomorrow for #NeurIPS2024, Dec 10-14! Excited to reconnect with colleagues and enjoy Vancouver's seafood! 🦐.
4
1
43
Gradient clipping is used in training private deep learning models. Any *side effect*?. New paper shows it changes the spectrum from an optimization viewpoint, resulting in slow convergence. New strategy is proposed. w my students Zhiqi, Hua, colleague Qi.
1
2
37
Our *local elasticity* paper ( was accepted to #ICLR2020! Takeaway: DNNs learn locally and understand elastically, with slides (. First #DeepLearning paper, first paper w/o theorems. Excited to visit the land of Queen of Sheba 2020!
0
3
38

A new paper with Zhiqi, @JKlusowski, @CindyRush on type I and II errors tradeoff of SLOPE, asking: is there any fundamental difference between l1 and sorted l1 regularization?. Our analysis leverages approximate message passing, developed by Donoho, Maleki, and @Andrea__M.

1
3
35
Too much competition leads to inefficiency, happening e.g. in the #gaokao exam taken by 10M students next week. That's the price we pay for involution. Surprisingly, our paper ( shows the price of competition appears in high-dimensional linear models. 1/n

1
4
33
@qixing_huang Exactly! If everyone were at the Einstein level, doing mediocre research would win you a Nobel prize!.
0
0
33
Had an enormous pleasure to read the paper by Papyan, Han and Donoho. Highly recommend it to anyone who is interested in deep learning theory. Very elegant and mathematically concrete insights.
0
5
31
I will be giving a talk at @Yale @yaledatascience this Monday introducing a new notion of differential privacy (. This was inspired by the hypothesis testing interpretation of privacy, joint work with Jinshuo and @Aaroth.
0
5
32
Attending #NeurIPS2023 and find it more exciting than in past years. But each work/poster/oral talk individually becomes less interesting. Anyone has the same feeling?.
1
0
31
I’ll be giving a talk “When Will You Become the Best Reviewer of Your Own Papers?” at @iccopt2022 tomorrow starting at 4:05 in Rauch 137. #optimization #iccopt2022.
0
2
31
This new paper ( proposes a new weighted training algorithm to improve the sample efficiency of learning from cross-task signals. To the best of our knowledge, it is the first weighted algorithm for cross-task learning with theoretical guarantees.

2
4
30
I'll be attending #neurips2022 from Nov 29-Dec 1. Looking forward to seeing old and new friends out there, as well as my former adviser Emmanuel Candes' plenary talk on conformal prediction!.
0
3
29
ICML 2024 authors: Please participate in our study on improving peer review in ML! Rank your submissions confidentially under "Author Tasks" on OpenReview. More details at Thank you! @ENAR_ibs.

You have received an email titled "[ICML 2024] Author Survey" with a link to confidentially rank your submissions based on their relative quality. The survey can also be accessed under "Author Tasks" on OpenReview.
0
5
28
Again, my favorite papers got rejected. Really hope that I can "review" my own papers myself:

Verdict from @icmlconf:.3 out of 3 . rejected. If I go by tweet statistics, ICML has rejeted every single paper this year 🤣.
2
2
26
The Isotonic Mechanism was experimented in @icmlconf 2023, requiring authors to provide rankings of their submissions to compute rank-calibrated review scores. A challenge is how to deal with multiple coauthors?. A (not perfect but performant) solution:

1
5
25
Very pleasant visit at Yale; will give the same talk tomorrow @Wharton (. BTW, got best advice yesterday that it would double attendance with deep learning in the title. So the title now is Gaussian differential #privacy, w/ application to deep learning.
I will be giving a talk at @Yale @yaledatascience this Monday introducing a new notion of differential privacy (. This was inspired by the hypothesis testing interpretation of privacy, joint work with Jinshuo and @Aaroth.
2
1
23
As ICML 2023, we will again collect rankings of submissions from authors at ICML 2024. Rankings will be used to assess the modified ratings from the Isotonic Mechanism. It won’t affect decision making, and pls provide rankings for improving peer review in the future!.

Now that at NeurIPS is upon us shortly . it's time to start planning for ICML😀! Thrilled to serve with @kat_heller @adrian_weller @nuriaoliver as PCs, and @rsalakhu as general chair. Call for papers is here: Intro blog post:
0
8
24
Happening soon. Our poster (#40) at #neurips19 will be presented starting 5pm: how can we efficiently do variable selection with confidence? It's a marriage between a #statis method and a signal processing algorithm. Paper with @CindyRush, Jason, Zhiqi.

0
5
23
Can anyone help with this trivial (theoretical) deep learning question? The two images are cropped from the same image; we clearly know they're both cats. But, is there any deep learning THEORY that ensures the prediction is invariant under (proper) cropping? 1/n


6
2
22
Surprised that it led to confusion, which was certainly not what I meant. As a non-Indo-European language speaker, I know how difficult it is to speak and write in English. I speak English with an accent, and I also speak Mandarin with a Wu accent. 1/2.
I receive large volumes of emails from Chinese students asking for summer internships. The English was often broken, but it has recently become native sounding😅.
2
0
23
Will be attending #ICML starting tomorrow. Looking forward to seeing many friends for the first time in 3 years!.
1
0
23
Our Penn Institute for Foundations of.Data Science received an NSF award (. Thanks to amazing PI Shivani, co-PIs Hamed, Sanjeev and @Aaroth. Looking forward to advancing data science at @Penn by integrating strength from @PennEngineers,@Wharton and beyond!.
1
2
23
In 2021, Abel went to Wigderson (TCS); In 2024, Wolf went to Shamir (crypto). I won't be surprised if someday it becomes a norm that Fields often goes to applied mathematicians.

BREAKING NEWS.The Royal Swedish Academy of Sciences has decided to award the 2024 #NobelPrize in Physics to John J. Hopfield and Geoffrey E. Hinton “for foundational discoveries and inventions that enable machine learning with artificial neural networks.”

0
1
22
How to accurately track the overall #privacy cost under composition of many private algorithms? Our new paper ( offers a new approach using the Edgeworth expansion in the f-#differentialprivacy framework. w/ Qinqing Zheng, @JinshuoD, and Qi Long.
1
4
20
That's the issue with virtual conferences! Nevertheless, I spent my entire afternoon yesterday making the poster since NeurIPS asked so. The bottom line is that I can post it on Twitter, which renders my effort slightly more meaningful.
1
0
21
I thought today was the weekend but it's still a workday! So, a simple yet neat result (, which completely delineates the range of precision and recall of Lasso, with some counterintuitive outcomes related to the *Donoho-Tanner* phase transition.
2
2
20
Many models can explain phenomena in deep learning. OK, but do you see one predicting a *new* surprising phenomenon? Super excited to share a paper "Layer-Peeled Model: Toward Understanding Well-Trained.Deep Neural Networks" (. w/ Fang, @HangfengH, Long.
1
4
21
Have lived in the States for 9 years. My first interview in English, however, reveals that I still maintain a Confucian way of thinking.

Three Penn professors have received the Sloan Fellowship which recognizes young scholars for their "unique potential to make substantial contributions to their field.".
0
1
20
Thanks, @emollick! Yes, it's fine to train your model on my data, but please pay me accordingly!.

There has been a lot of debate on how to deal with copyright issues for AI art, but this interesting paper is one of the first to offer a solution as to how compensation of copyright holders could technically work, given the explainability problem in AI.

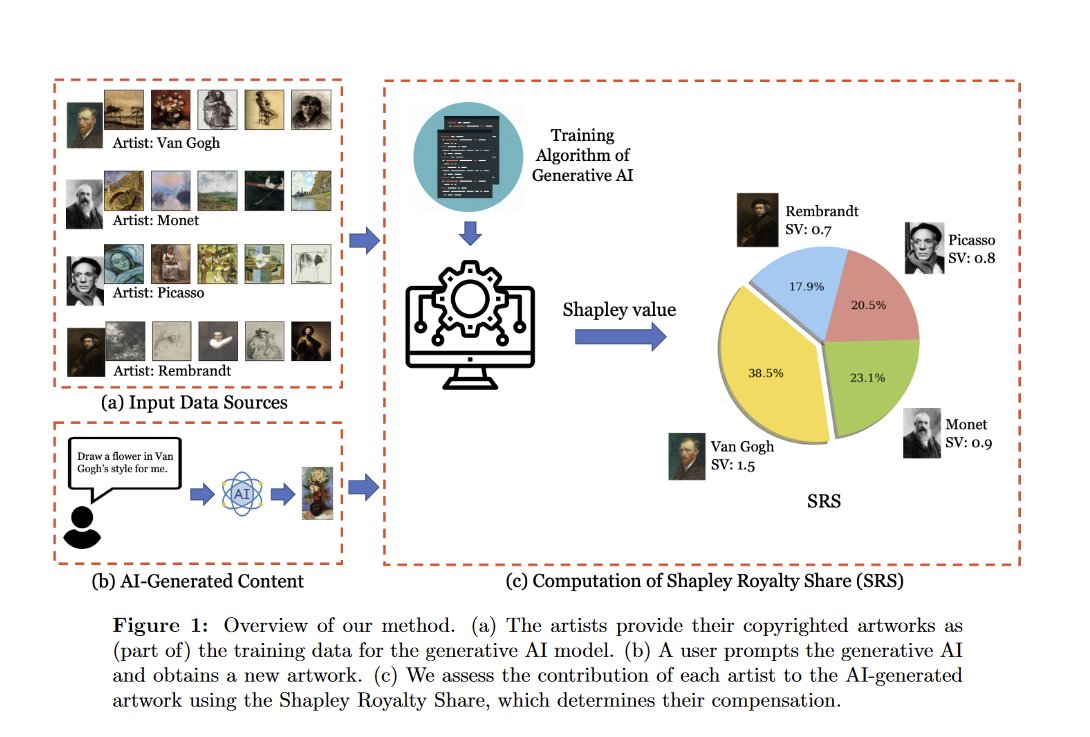
1
2
20
Exciting opportunity for aspiring young data enthusiasts! 🌟 Join the 3-week Data Science Academy at Wharton, directed by Linda Zhao. Dive into the world of data science with hands-on learning on campus. Perfect for high school students. Link:
0
4
17
Jinshuo will present our work Gaussian Differential #Privacy at #NeurIPS2019 9:05am East Meeting Rooms 8+15. Please stop by!


Submissions are open for the NeurIPS 2019 Workshop on Privacy in Machine Learning (PriML 2019)! Anything at the intersection of privacy and machine learning is welcome! #privacy #NeurIPS2019.
1
1
19
New paper: In *Federated f-Differential Privacy* (, we proposed a new privacy notion tailored to the setting where the clients ally in the attack. This privacy concept is adapted from f-differential privacy. w/ Qinqing Zheng, @ShuxiaoC, and Qi Long.
0
4
20
Glad that our papers on using AMP to study SLOPE ( and on accelerated optimization methods ( are accepted to NeurIPS 2019!@CindyRush @SimonShaoleiDu.
0
3
20
So sad, I took Luca's course on expanders back to my Stanford days.

I don't have any words.
0
0
19
Very short paper (5 mins read): Our extensive experiments show LLMs improve NTP capability following an exponential law, throughout all layers!. It emerges for Transformer, Mamba, RWKV-based LLMs. It's universal!

2
2
18
@a11enhw Yes, the ultimate goal is to understand nature. But we cannot expect any individual to have such a high standard. Being pragmatic is what an average person cares about.
1
0
18
I would feel the same if my least favorable student happened to be the loudest one.

0
0
16
Congratulations to Emmanuel!.

Congratulations to Yves Meyer, Ingrid Daubechies, Terence Tao and Emmanuel Candès, winners of the 2020 Princess of Asturias Award for Technical and Scientific Research!.
0
0
16
Will attend #NeurIPS2019 in Vancouver 12/10-12/14. Very much looking forward to meeting old and new friends!.
0
0
14
Anyone who has a memory of the millennium bug, exactly 20 years ago? For me, I was so nervous that I couldn’t fall asleep that night.
2
1
15
Bravo @MuratAErdogdu !.

Congratulations to Monica Alexander (@monjalexander), @MuratAErdogdu & Stanislav Volgushev for being among this year’s winners of the @UofT Connaught New Researcher Award. 👏👏👏

1
1
15
Congrats, Dr. Dong!.

Congratulations to Dr. Dong @JinshuoD for defending his PhD "Gaussian Differential Privacy and Related Techniques" earlier today!

0
0
15
The poem of privacy.
Our discussant @XiaoLiMeng1 with a poem to conclude the session on Differential Privacy (hosted by @weijie444). He gives a shoutout to @TheHDSR, featuring some nice articles on DP, by @DanielOberski and @fraukolos, and by @mbhawes.

0
0
12
Around #JSM2020? Want to know more about #privacy research from ml and stats perspectives? Want to enjoy the humor of @XiaoLiMeng1, please join the session ( tmrw at 1pm EST. Speakers @thegautamkamath, Jordan Awan, Feng Ruan and @JinshuoD.
1
3
13
NSF grant decisions reflect systemic racism, study argues | Science | AAAS
0
3
13
The @Wharton Stats Dept is seeking applicants for tenure track professor positions (). Future colleagues please apply!.
0
3
12
Nowadays it’s so common to rediscover the wheels, even for the best minds in our time. The amazing result #eigenvectorsfromeigenvalues ( appeared long ago: Principal submatrices II: The upper and lower quadratic inequalities by Thompson and McEnteggert.
1
1
12
The most fundamental recipe in #privacy research is perhaps to understand “how private are private algorithms.” Here comes a nice read: BTW, the author @JinshuoD is on the job market!.

My very first tweet about my very first blog post: How Private Are Private Algorithms?In fact, this question is answered 87 years ago. #OldiesButGoodies #differentialprivacy.
0
2
12
Fairness @#JSM2022.

How to make classical fair learning algorithms work for deep learning? How to deal with severe class imbalance and subgroup imbalance? Excited to talk about our new work at JSM on Aug. 8th.

0
1
12
Congrats to Lin Xiao for the TOT award #NeurIPS2019! Very well deserved. Still miss a bit the summer of 2013 working with Lin at Redmond.

Congratulations to our colleague Lin Xiao @MSFTResearch for the #NeurIPS2019 test of time award!!!.Online convex optimization and mirror descent for the win!! (As always? :-).).
1
0
12
We call it the Equi-Learning Law. Intuitively, one might expect token embeddings to differentiate across LLM layers. Remarkably, a universal geometric law governing tens of thousands of tokens emerges, even in models of immense complexity.
1
1
12
The law of equi-separation says that each layer roughly improves a measure of data separation.by an equal multiplicative factor. The measure is called separation fuzziness, which is basically the inverse signal-to-noise ratio for classification.

1
0
11