
Zhaopeng Tu
@tuzhaopeng
Followers
659
Following
304
Statuses
256
Principal Researcher, Tencent AI Lab
China
Joined June 2008
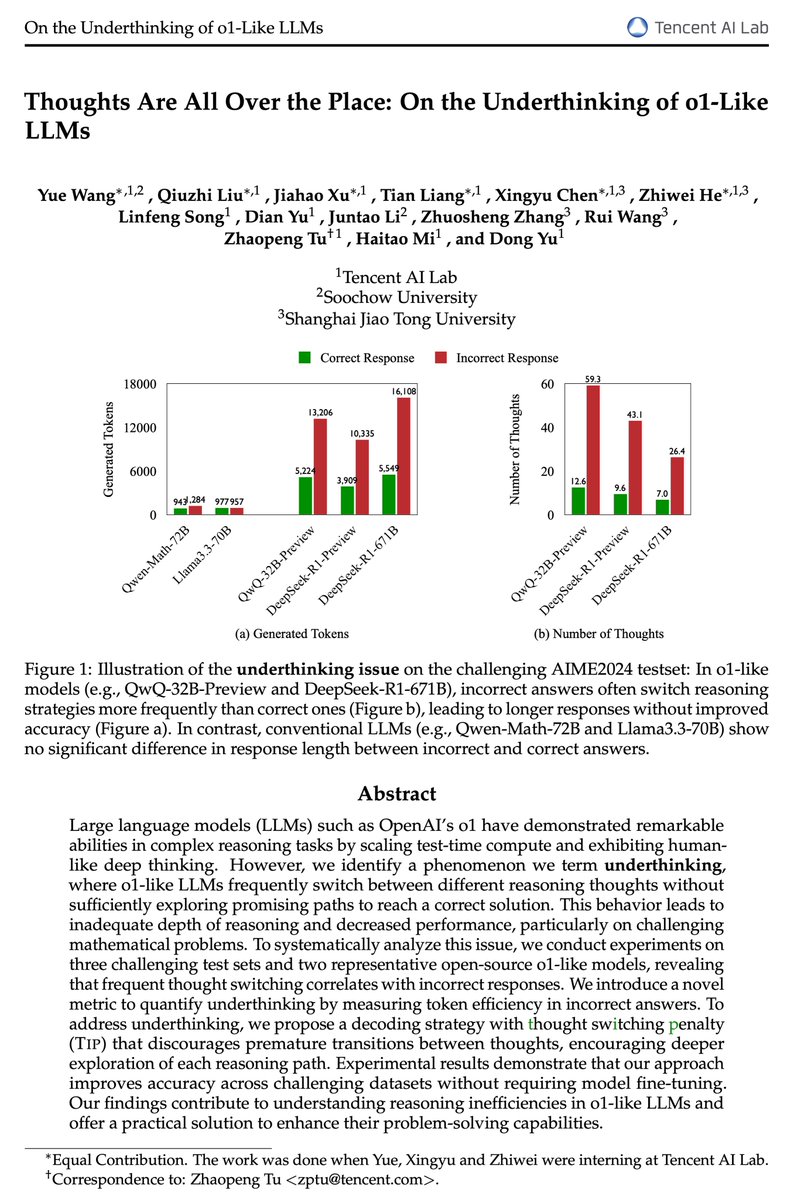
Are o1-like LLMs thinking deeply enough? Introducing a comprehensive study on the prevalent issue of underthinking in o1-like models, where models prematurely abandon promising lines of reasoning, leading to inadequate depth of thought. 🪡 Through extensive analyses, we found underthinking patterns: 1⃣Occur more frequently on harder problems, 2⃣Lead to frequent switching between thoughts without reaching a conclusion, 3⃣Correlate with incorrect responses due to insufficient exploration. 🪡We introduce a novel underthinking metric that measures token efficiency in incorrect responses, providing a quantitative framework to assess reasoning inefficiencies. 🪡 We propose a decoding approach with thought switching penalty (Tip) that encourages models to thoroughly develop each line of reasoning before considering alternatives, improving accuracy without additional model fine-tuning. Paper: 🧵
18
103
438
Thank you for sharing your framework! Your approach to emulating TiP through structured prompting is innovative and demonstrates a deep understanding of the challenges in promoting thought persistence. Your method effectively introduces meta-cognitive constraints through prompting, which is particularly valuable when decoding modifications are not feasible with closed-source models. I'd be very interested to learn about the results you've observed with this framework. Have you noticed improvements in the model's reasoning depth or accuracy?
1
0
0
Thank you for your insightful questions! You're absolutely right that modifying the decoding process isn't always feasible, especially with closed-source models. However, prompt engineering can help emulate TiP-like behavior to some extent. We're currently conducting more extensive studies on these techniques and will share our findings in the revised version of our paper. Stay tuned!
1
0
2
Thank you for sharing these insightful references! We appreciate you bringing attention to prior work on "Budget Forcing" and techniques like manipulating logits to encourage models to think longer and reason more thoroughly. Your contributions are valuable, and we'll make sure to include and discuss these references in the revised version of our underthinking paper (. Thank you for helping to advance this important discussion!
1
0
3
Thank you for highlighting Figure 4! It indeed provides valuable insights related to our discussion. Figure 4 illustrates how o1 models allocate hidden reasoning tokens in relation to the complexity of problems, measured by the number of Z3 conflicts. This correlation shows that while o1 models tend to allocate more reasoning tokens to more complex puzzles, there is a plateau in this scaling pattern when complexity exceeds a certain threshold. This observation aligns with our findings on underthinking, where models reach a limit in reasoning capacity and prematurely abandon deeper reasoning on harder problems, leading to inadequate exploration and incorrect responses.
Are o1-like LLMs thinking deeply enough? Introducing a comprehensive study on the prevalent issue of underthinking in o1-like models, where models prematurely abandon promising lines of reasoning, leading to inadequate depth of thought. 🪡 Through extensive analyses, we found underthinking patterns: 1⃣Occur more frequently on harder problems, 2⃣Lead to frequent switching between thoughts without reaching a conclusion, 3⃣Correlate with incorrect responses due to insufficient exploration. 🪡We introduce a novel underthinking metric that measures token efficiency in incorrect responses, providing a quantitative framework to assess reasoning inefficiencies. 🪡 We propose a decoding approach with thought switching penalty (Tip) that encourages models to thoroughly develop each line of reasoning before considering alternatives, improving accuracy without additional model fine-tuning. Paper: 🧵
0
0
1
Thanks for sharing your work! The concept of critical windows during sampling is fascinating and seems highly relevant to our studies on: 1⃣ Underthinking ( and overthinking ( in o1-like models; 2⃣ Critical tokens in reasoning tasks (; 3⃣ Addressing a refusal position bias within safety tuning data (. Your theory might offer valuable insights into how the initial tokens influence model responses, aligning with our findings. Looking forward to diving into your paper!
0
0
0
Thank you for sharing these observations! It's fascinating to see ongoing research addressing underthinking in LLMs. 1. Penalizing "alternatively" can improve accuracy (Our work): By discouraging the use of terms like "alternatively," models are encouraged to fully develop each line of reasoning before switching to another. This reduces premature thought switching and enhances the depth of reasoning, aligning with our findings on underthinking. 2. "Shortest thinking of K" can improve accuracy: Selecting the shortest response among multiple samples favors concise and focused reasoning. This approach mitigates underthinking by reducing unnecessary elaboration and frequent thought switching, supporting our observation that incorrect responses often involve longer, unfocused outputs. (The first two studies independently observed that incorrect responses are longer than their correct counterparts.) 3. Forcing models to think longer with "Wait" can improve accuracy: Encouraging models to "wait" and think longer promotes thorough exploration of each thought before moving on. While it might seem counterintuitive, spending more time on a single line of reasoning helps combat underthinking by fostering deeper analysis. These observations highlight the importance of guiding models to focus and deepen their reasoning processes to improve accuracy. It's exciting to see various approaches being explored to address underthinking in LLMs!
Are o1-like LLMs thinking deeply enough? Introducing a comprehensive study on the prevalent issue of underthinking in o1-like models, where models prematurely abandon promising lines of reasoning, leading to inadequate depth of thought. 🪡 Through extensive analyses, we found underthinking patterns: 1⃣Occur more frequently on harder problems, 2⃣Lead to frequent switching between thoughts without reaching a conclusion, 3⃣Correlate with incorrect responses due to insufficient exploration. 🪡We introduce a novel underthinking metric that measures token efficiency in incorrect responses, providing a quantitative framework to assess reasoning inefficiencies. 🪡 We propose a decoding approach with thought switching penalty (Tip) that encourages models to thoroughly develop each line of reasoning before considering alternatives, improving accuracy without additional model fine-tuning. Paper: 🧵
0
0
2
Thank you for your interest! We share your curiosity about how the thought-switching penalty scales across different tasks and models. We're currently working on validating it on larger models like R1-671B, which involves substantial effort. Stay tuned for updates in the revised version of our paper!
0
0
1
Hi Muchen, thank you for your insightful feedback! We appreciate you bringing this to our attention. In Table 2, we reimplemented the QwQ baseline results of 46.7% on AIME24 using greedy search. In Table 3, for a robust conclusion, we reported the Pass@1 results with a temperature of 0.7 and a top_p of 0.95, which, as you mentioned, may have led to decreased accuracy due to the sensitivity to temperature and top_p settings. We'll look into adjusting these parameters to see how they affect the baseline performance. Additionally, we'll investigate the potential bug in vllm that you pointed out. Your input is valuable and helps us improve our work!
0
0
0
We have validated the conclusions based on DeepSeek-R1, and the overthinking issue persists. Check the new version of our paper at
Are we scaling test-time compute efficiently and intelligently? Introducing a comprehensive study on the prevalent issue of overthinking in o1-like models, where excessive computational resources are allocated for simple problems with minimal benefit. 🪡Across extensive analyses of mathematical benchmarks, we found these overthinking patterns: (1) contribute minimally to improving accuracy, (2) lack diversity in reasoning strategies, (3) occur more frequently with simple problems. 🪡 We introduce novel efficiency metrics from both outcome and process perspectives to evaluate the rational use of computational resources by o1-like models. 🪡 Using a self-training paradigm, we propose strategies to mitigate overthinking, streamlining reasoning processes without compromising accuracy. Paper: 🧵

0
0
11
@AlexGDimakis @LiJonassen Thanks for the recommendation, Alex! Laconic decoding is such an elegant solution — it definitely deserves more exploration. We're reimplementing it in our work. Stay tuned for updates in the revised version of our paper!
0
0
1
You raise a good point about "deep" being a metaphor. In our context, we're using "deep thinking" to describe the model's ability to persist along a line of reasoning to reach more accurate conclusions. The goal is to enhance how thoroughly models explore each possibility before moving on, which can improve their overall performance on complex problems.
0
0
1
@TheTuringPost Thank you for your support! We're glad you find our work important. Your encouragement motivates us to continue advancing LLM reasoning.
0
0
0
Thanks for sharing our work!

🚨This week's top AI/ML research papers: - OpenAI o3-mini System Card - Janus-Pro - SFT Memorizes, RL Generalizes - Advancing Language Model Reasoning through RL and Inference Scaling - Qwen2.5-1M Technical Report - Towards General-Purpose Model-Free Reinforcement Learning - Open Problems in Mechanistic Interpretability - Learning Free Token Reduction for Multi-Modal LLM - Streaming DiLoCo with overlapping communication - Optimizing Large Language Model Training Using FP4 Quantization - Propositional Interpretability in Artificial Intelligence - Mixture-of-Mamba - TopoNets - Thoughts Are All Over the Place - Critique Fine-Tuning - LLMs can see and hear without any training - OstQuant - Better Models by Survival of the Fittest Prompts overview for each + authors' explanations read this in thread mode for the best experience

0
0
2
@TheAITimeline Thanks for sharing! More detailed explanation can be found here :)
Are o1-like LLMs thinking deeply enough? Introducing a comprehensive study on the prevalent issue of underthinking in o1-like models, where models prematurely abandon promising lines of reasoning, leading to inadequate depth of thought. 🪡 Through extensive analyses, we found underthinking patterns: 1⃣Occur more frequently on harder problems, 2⃣Lead to frequent switching between thoughts without reaching a conclusion, 3⃣Correlate with incorrect responses due to insufficient exploration. 🪡We introduce a novel underthinking metric that measures token efficiency in incorrect responses, providing a quantitative framework to assess reasoning inefficiencies. 🪡 We propose a decoding approach with thought switching penalty (Tip) that encourages models to thoroughly develop each line of reasoning before considering alternatives, improving accuracy without additional model fine-tuning. Paper: 🧵
0
0
2
Thank you for sharing your approach! Using z-scores to resample answers and analyzing the entropy of reasoning chains to detect patterns like "doomloops" is an interesting idea. It could be valuable to explore how these statistical methods might complement our SimPo in overthinking and TiP in underthinking in improving LLM reasoning. Appreciate your insights!
1
0
1
Thank you for your great question! Prompt engineering can indeed encourage 'thought persistence' by instructing the model to maintain a consistent line of reasoning. However, our research indicates that while prompts can guide the model, they may not fully prevent underthinking due to inherent generation patterns that cause premature thought switching. The Thought Switching Penalty (TiP) operates at the token level by applying logit penalties to discourage the model from switching thoughts too quickly. This directly affects the generation process, promoting deeper reasoning without requiring changes to the model's parameters. Combining prompt engineering with decoding approaches like TiP could potentially enhance 'thought persistence' more effectively. Prompts provide high-level guidance, while decoding penalties enforce consistent reasoning during token generation. We're keen to further explore how these methods can synergize to improve reasoning depth in LLMs!
1
0
1
Thank you for your interest! Our approach introduces a novel underthinking metric and a decoding strategy that enhances reasoning depth in LLMs. Specifically, the "thought switching penalty" proposed in the paper aims to encourage the model to thoroughly explore each line of reasoning before considering alternatives, enhancing its ability to reach correct conclusions without additional fine-tuning.
0
0
0
谢谢您的关注和提问。 在我们的研究中,我们确实发现模型在处理复杂问题时,存在思考深度不足的情况。这主要表现为模型未能充分拓展当前的推理路径,而是过早地放弃,导致忽略了一些关键步骤,从而使思考不够全面或深入。 为了解决这个问题,我们提出了一种新的解码方法,称为“思路切换惩罚”(TiP)。该方法鼓励模型在考虑其他可能性之前,先彻底探索当前的推理思路,从而减少模型过早放弃有前途的推理路径的情况。通过使用 TiP,无需对模型进行额外的微调,就能够提升模型在复杂问题上的推理深度和准确性。 希望我的回答能解答您的疑问,欢迎进一步讨论!
0
0
0