

Ken Liu
@kenziyuliu
Followers
2K
Following
6K
Media
27
Statuses
345
cs phd @stanfordailab @stanfordnlp w/ @percyliang @sanmikoyejo. student researcher @googledeepmind. prev @scsatcmu @sydney_uni 🇦🇺
🌲
Joined January 2017
The idea of "machine unlearning" is getting attention lately. Been thinking a lot about it recently and decided to write a long post: 📰. Unlearning is no longer just about privacy and right-to-be-forgotten since foundation models. I hope to give a gentle.
23
162
756

LoRA is great. It’s fast, it’s (mostly) accurate. But is the efficiency a free lunch? Do side effects surface in the fine-tuned model? . We didn’t quite know so we played with ViT/Swin/Llama/Mistral & focused on subgroup fairness. 🧵: takeaways below.📄:

7
27
171
Life update: I just graduated from @CarnegieMellon & will join @Stanford for PhD this fall!. Deeply grateful for my advisors & mentors @gingsmith, @zstevenwu, Artur Dubrawski at @SCSatCMU and @KairouzPeter, Jakub Konečný at @GoogleAI, and all who supported me along the way 🙏😃

10
4
158
in other news i'll be at @GoogleDeepMind this summer!!.

We’re sharing Project Astra: our new project focused on building a future AI assistant that can be truly helpful in everyday life. 🤝. Watch it in action, with two parts - each was captured in a single take, in real time. ↓ #GoogleIO
9
0
117
We trained some GPT-2 models *from scratch* where evaluation data are deliberately added to/removed from pre-training to study the effects of data contamination!.Three takeaways below 🧵:. Paper: Led by @minhaoj_uiuc & with @RylanSchaeffer @sanmikoyejo.

📢Excited to share our new paper "Investigating Data Contamination for Pre-training Language Models"!. We analyze the effects of data contamination in the pre-training stage of LMs by pre-training & studying GPT-2 models🚀. Paper:

1
10
57
accepted at @COLM_conf lets meet up in philly :).
LoRA is great. It’s fast, it’s (mostly) accurate. But is the efficiency a free lunch? Do side effects surface in the fine-tuned model? . We didn’t quite know so we played with ViT/Swin/Llama/Mistral & focused on subgroup fairness. 🧵: takeaways below.📄:
2
1
47

Sharing a fun weekend hack:.- closed models (GPT-4, Claude 3) are powerful but untrusted for sensitive inputs.- bunch of open LLMs around (Mixtral, Gemma) but not as smart.- can we anonymize inputs to GPT-4 w/ a small, open LLM run locally on your MacBook?. 🧵some thoughts below:
3
7
42
Our CMU team ("puffle") w/ Shengyuan Hu, @litian0331, @zstevenwu, @gingsmith won 1st place at the U.K.-U.S. PETs prize challenge (! We had some fun applying federated learning and differential privacy to pandemic forecasting. Grateful for the opportunity🙌.

The results are in! Yesterday at the #summitfordemocracy we announced winners of the US-UK privacy-enhancing technologies prize challenges⤵️
1
8
42
Some intuitions on circuit breakers ( and breaking them:. Circuit breakers prevent harmful language model outputs by interjecting outputs (e.g. w/ EOS tokens) when the internal representations used to sample the actual text outputs are "considered.

Three models remain unbroken in the Gray Swan jailbreaking competition (~500 registrants), which is still ongoing. These models are based on Circuit Breakers + other RepE techniques ( .

2
3
41
I'll be at ICLR this week 🇦🇹 come say hi :). Our data contamination work (see QT) won a best paper award at DPFM workshop 🏆 giving a talk on Sat 9:30am!. Also postering an exploratory work on fairness of LoRA at SeT LLM, ME-FoMo, R2-FM, PML4LRS; tweet/preprint coming soon-ish. .
We trained some GPT-2 models *from scratch* where evaluation data are deliberately added to/removed from pre-training to study the effects of data contamination!.Three takeaways below 🧵:. Paper: Led by @minhaoj_uiuc & with @RylanSchaeffer @sanmikoyejo.
1
4
37
gave a guest lecture on intro to ML privacy at northeastern university at @tianshi_li’s class!. it was a speed run over a few popular privacy tools, their motivations/implications, and how they may or may not fit in the context of modern foundation models. ML has obviously.

It was fantastic to have @kenziyuliu virtually join my seminar class to offer a well-synthesized overview of ML privacy along with thought-provoking discussions. 90 minute felt too short. I hope we can have more crossovers between AI and HCI like this one!.
1
2
32
the skies look different when you finally solve some stupid cudnn/nccl versioning issues to get flash attention hitting 50% mfu for a pre-training run on h100s.
2
0
30
at @COLM_conf this week! hmu if there's something we can chat about (privacy/security, membership, memorization, unlearning, localization, . ) or if you have food recs :).
accepted at @COLM_conf lets meet up in philly :).
3
3
31
a very cool form of training data inference, especially considering the importance of data mixtures (!.

What do BPE tokenizers reveal about their training data?🧐. We develop an attack🗡️ that uncovers the training data mixtures📊 of commercial LLM tokenizers (incl. GPT-4o), using their ordered merge lists!. Co-1⃣st @JonathanHayase.🧵⬇️

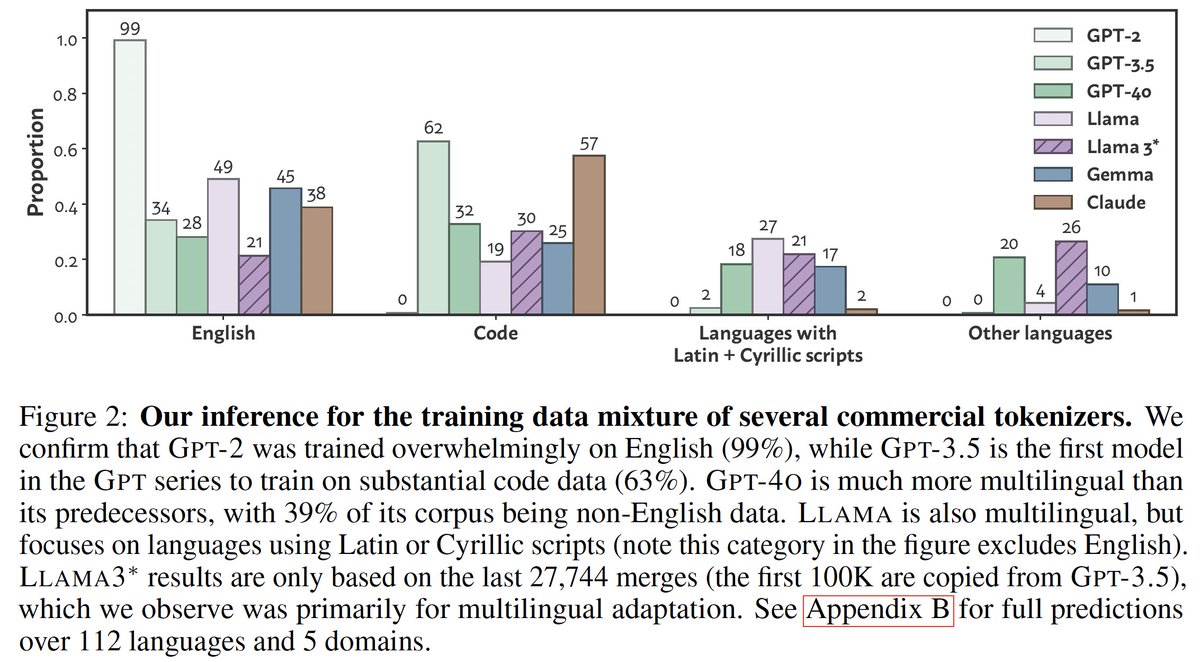
1
3
27
a big collab on unlearning led by @katherine1ee and @afedercooper!!. it always helps to ask *why* and *how* a specific new technology will tangibly help in practice, or if it’s really just a solution searching for a problem. this is especially true for unlearning as of today.

Machine unlearning is taking off! There is a ton of interest in getting generative AI models to “unlearn” targeted undesirable information, often to meet policy aims in privacy, copyright, safety, etc. Our new cross-disciplinary collaboration shows why this isn’t simple.


0
2
26
amazing labmates and i learn so much from them!!.

This year, I have 4 exceptional students on the academic job market, and they couldn’t be more diffferent, with research spanning AI policy, robotics, NLP, and HCI. Here’s a brief summary of their research, along with one representative work each:.
0
0
26
it's been inspiring witnessing @ChengleiSi executing this humongous effort (both⏳ and 💸) & the results are surprising and timely!.

Automating AI research is exciting! But can LLMs actually produce novel, expert-level research ideas?. After a year-long study, we obtained the first statistically significant conclusion: LLM-generated ideas are more novel than ideas written by expert human researchers.

0
1
26
Our work on distributed differential privacy is officially deployed for a federated learning application at Google!! Extremely grateful for the opportunities to work with my amazing team and push our research on privacy-preserving ML to practice 😃.

Today on the blog, read about how we built and deployed the first #FederatedLearning system that provides formal privacy guarantees to all user data before it becomes visible to an honest-but-curious server, meaningfully reducing model memorization →
1
1
25
In this work we ask a simple Q: when we choose LoRA over full fine-tune, are there any unintended consequences, particularly on trustworthiness, when both give high utility?. 📄: 👯: work w/ @_d1ng_ @poonpura @BerivanISIK @sanmikoyejo @stai_research.
2
4
22
Arrived at #NeurIPS2023! Excited to meet old & new friends and learn about your cool research!.
2
1
21
cool work by the cool @anneouyang @simonguozirui !!.

Kernels are the kernel of deep learning. 🙃. but writing kernels sucks. Can LLMs help? 🤔. Introducing 🌽 KernelBench (Preview), a new coding benchmark designed to evaluate the ability of LLMs to generate ⚡️efficient💨 GPU kernels for optimizing neural network performance.

1
1
20


BREAKING NEWS.The Royal Swedish Academy of Sciences has decided to award the 2024 #NobelPrize in Physics to John J. Hopfield and Geoffrey E. Hinton “for foundational discoveries and inventions that enable machine learning with artificial neural networks.”

0
0
19
i have discovered a truly marvelous proof of this, which, however, the bag of legumes is not large enough to contain.


1
0
19
So is the parameter efficiency of LoRA is a free lunch? Possibly, but not necessarily :). Indeed, no evidence of unfairness does not imply evidence of fairness. Feedback welcome!. 📄: 👯: work w/ @_d1ng_ @poonpura @BerivanISIK @sanmikoyejo @stai_research.
0
3
17
Seems like people did read the post :). Two quick updates: (1) a minor revision to the post with special thanks to @Eleni30fillou for detailed feedback, especially on some technical descriptions of the NeurIPS unlearning challenge and on clarity of the empirical unlearning and.
1
2
18


a post on the EMNLP award paper on (flawed) LLM membership inference must exist, and am super glad that @pratyushmaini @iamgroot42 are doing it!!.

1/6 A lot of us are grappling with peer review these days, but its worst manifestation is when prestigious conference awards overlook critical flaws. Case in point: #EMNLP2024’s Best Paper Award. I & @iamgroot42 wrote a blog on what went wrong: 🧵

0
1
17
hits different if you work on ai and/or you're a 1st-year phd student in the stanford cs department.

While there is nobody in the world who will share your point of view on everything, there are people who will share your most important values and the ways in which you choose to live them out. Make sure you end up with those people. #principleoftheday

0
0
17
We wrote a post exploring connections between differential privacy, data heterogeneity, and model personalization in cross-silo federated learning!.

How should we protect privacy in cross-silo federated learning and how does privacy interface w personalization?. New post by @kenziyuliu and @gingsmith which describes how these insights led our CMU team to 1st place at the US/UK PETs Prize Challenge!.
2
1
16
An open, RAG/tool-optimized LLM addresses 3 key attributes of enterprise LLM usage: data locality, retrieval, and automating chores w/ func calling. Cool stuff!. Curious tho about the effects of the "free-to-use, pay-to-sell" license on the startups that'll actually help. .

⌘R+. Welcoming Command R+, our latest model focused on scalability, RAG, and Tool Use. Like last time, we're releasing the weights for research use, we hope they're useful to everyone!
1
1
15
sharing slides here in case it’s useful --- please also leave feedback as it can be definitely more polished!.
0
6
16
fond memories!.

AddisCoder teaching assistants preparing for launch -- high school students check into the dorms this Sunday, and first day of instruction is on Monday!



0
0
15
in boston aug 21-22 (at TPDP day 2) and NYC 22-27 w/ @aryaman2020 let’s meet up 🫡.

i will be in NYC with @kenziyuliu starting the 22nd. looking for people to meet and things to do 🫡.
1
1
15

another fun token in the `o200k_base` tokenizer used by gpt-4o:.199410 <+天天中彩票> (win lottery everyday).seems to trigger dalle-3 occasionally


Just wrote a script to further investigate how the corpus used to train the gpt4o tokenizer is polluted by Internet scams. The results are quite interesting. 🤦♂️🤦♂️🤦♂️.

0
0
14
@leonardtang_ @haizelabs bro came to stanford visit days, told us about his cool startup over penny poker, decided not to come, and now it's a bad day to be an llm 💀.
1
0
14
Interesting read! Evolution is necessarily tied to an objective, an environment, and the agency to act in said environment to optimise towards said objective. IMO all three are currently missing for AI models (maybe not for long) — there’s no incentive beyond being “helpful and.
2
0
13
Turns out, little is known because full FT is just expensive these days and most didn't bother to compare :). We focus on fairness since bad outcomes (unfair decisions & generated outputs) may cause tangible harm when these models are used in high-stakes applications. But more.
1
0
12
did a podcast w/ @bigdata where I rambled about unlearning for an hour; watch at your own risk :).
🆕💡🎧 Machine Unlearning with @kenziyuliu @StanfordAILab:.- Learn techniques for removing unwanted AI data.- Compare unlearning vs. RAG.- Evaluate popular unlearning approaches for LLMs.
0
2
12
thanks to @aryaman2020, @jiaao_chen, @irena_gao, @johnhewtt, Shengyuan Hu, @KairouzPeter, @sanmikoyejo, @XiangLisaLi2, @percyliang, @ericmitchellai, @RylanSchaeffer, @EchoShao8899, @ChengleiSi, Pratiksha Thaker, @cindy_x_wu for inspiration and feedback before or during the.
1
1
12
@CongyueD @ishaanpreetam @TianweiY @ShivamDuggal4 @_atewari oh @ShivamDuggal4 and @tianyuanzhang99 for sure.
1
0
11
Please also check out this nice related work (Das et al., 2024) studying LoRA applied as a mitigation to fairness problems!. This work and ours ( are very related; let me try highlighting the connections 🧵. Das et al., (2024) by @WatIsDas, M. Romanelli,.

🚨 New Paper Alert! 🚨.Exploring the effectiveness of low-rank approximation in fine-tuning Large Language Models (LLMs). Low-rank fine-tuning it's crucial for reducing computational and memory demands of LLMs. But, does it really capture dataset shifts as expected and what are

1
0
11
see through corners with gaussian splats!.

Reconstructing occluded humans from monocular video can be nice and fast! 🎆 I’m excited to share our new paper “OccFusion: Rendering Occluded Humans with Generative Diffusion Priors” 🧵.📖🌐

0
0
10
Lastly: LLMs can exhibit strong token biases, complicating fairness evaluations for generative tasks (think multiple choice Qs, cloze completions, . ). We ran into things like LLMs always choosing "yes" or "male" regardless of the question & always liking the 🟠 emoji than 🟢.
1
0
10
lots of people working on unlearning evals it seems.

I'm reviewing for @NeurIPSConf 2024 datasets and benchmarks track, and very interesting to see trends in what people are interested in:.- a *lot* of "language model unlearning" benchmarks. - Also a lot of "language model refusal/false refusal/over-refusal" benchmarks/datasets.
0
0
10

what a day.

i loved my time at openai. it was transformative for me personally, and hopefully the world a little bit. most of all i loved working with such talented people. will have more to say about what’s next later. 🫡.
0
0
10
Takeaway #2: The fairness implications can depend on the quality of the underlying pre-trained model. There are cases where LoRA does exacerbate unfairness, but they can go away when the base pre-trained model is stronger (e.g. ViT-Base vs Swin-v2-Large on Asian group below)

1
0
10
Takeaway #1: we found no consistent pattern of LoRA worsening fairness compared to full FT. This spans acc (e.g. plot 1 below), calibration (e.g. plot 2), robustness to MIA (e.g. plot 3), and gender bias in text generation (e.g. plot 4). Importantly, one could cherry-pick




1
0
9
tried the beta version of the platform; very clean and easy to use! bullish on whatever the cracked @leonardtang_ & team ship next :).

Today is a bad, bad day to be a language model. Today, we announce the Haize Labs manifesto. @haizelabs haizes (automatically red-teams) AI systems to preemptively discover and eliminate any failure mode. We showcase below one particular application of haizing: jailbreaking the
1
0
9
@cloneofsimo @kellerjordan0 empirically i've seen many cases that grad norms do not converge as losses converge across optimizers/LR schedules/weight decay; see, e.g., this paper . for this precise reason non-convex convergence analyses to stationary points are just not that useful.
2
1
9
this *extremely* long chain-of-thought to solve the cipher is pretty impressive ngl

0
0
9
@aryaman2020 lol just watched it today; the argument/visualization of how large models can fit a lot of features due to johnson–lindenstrauss lemma is cute.
0
0
9
@AddisCoder 2024 TA applications are now open! I've had a memorable experience teaching and having fun with talented & motivated students. We went from zero to dynamic programming in a month! TAs can really have a direct impact on the students' careers. Consider applying!.
The AddisCoder 2024 application portal is now live! Prospective students and teaching assistants, apply at TA deadline: Dec 31, 2023.Student deadline: Jan 20, 2024.
0
1
9

Check out @rose_e_wang's cool work on AI & tutoring! Rose thinks deeply about teacher-student interaction and how it should manifest in classrooms and different communities, beyond just "AI education". I've learned so much from her!.

AI has the potential to transform real-world domains. But can AI actually improve outcomes in live interactions?. We conducted the first large-scale intervention of a Human-AI Approach that has statistically significant positive learning gains w/ 900 tutors & 1,800 K12 students.

0
0
8
i havent even finished reading the last question before scotty chimes in.

In case you were wondering just how cracked the team @cognition_labs is. This was the CEO (@ScottWu46) 14 years ago.
0
0
7
always had the intuition that weak differential privacy is underrated as an empirical defense (e.g. see appendix A of LiRA and our US/UK PETs prize entry ; great to see this intuition validated through experiments!.

Heuristic privacy defenses claim to outperform DP-SGD in real-world settings. With no guarantees, can we trust them?. We find that existing evaluations can underestimate privacy leakage by orders of magnitude!. Surprisingly, high-accuracy DP-SGD (ϵ >> 1000) still wins. 🧵

0
2
8
Takeaway #3: The LoRA rank seems to have little impact on subgroup fairness (at least on the settings we tried). While rank can be a confounding factor for its impact on model capacity and thus fairness (cf. pruning and private training), we did not observe a significant


1
0
8
this is a 4-bit Llama-3 8B running distributed inference on multiple apple chips 🤯 some observations:.- as of now the toks/sec is < my macbook's M2 max w/ @ollama (possibly due to slow interconnect?).- curiously, time-to-first-token is quite fast! (pre-loading shards vs.

One more Apple announcement this week: you can now run your personal AI cluster using Apple devices @exolabs_. h/t @awnihannun
0
0
8
@dwarkesh_sp @johnschulman2 about the notion of "unlearning" 🙃.
The idea of "machine unlearning" is getting attention lately. Been thinking a lot about it recently and decided to write a long post: 📰. Unlearning is no longer just about privacy and right-to-be-forgotten since foundation models. I hope to give a gentle.
0
0
6
godsend.

0
0
7
or maybe half as productive and creative.

Every researcher wishes they could be as productive and creative as Taylor Swift.
0
0
7
@JeffDean or maybe it's a good sign 🤓.
The idea of "machine unlearning" is getting attention lately. Been thinking a lot about it recently and decided to write a long post: 📰. Unlearning is no longer just about privacy and right-to-be-forgotten since foundation models. I hope to give a gentle.
0
0
6
RIP 🙏 apart from Jim Simons' tremendous impact on math & CS, his legendary story influenced how i approach life too; he once gave a fun talk recounting his life which i still revisit from time to time:.


It is with great sadness that the Simons Foundation announces the death of its co-founder and chair emeritus, James Harris Simons. Jim was an award-winning mathematician, a legendary investor and a generous philanthropist.

0
0
6
@leonardtang_ 🐐 looking back a year and finding oneself to be naive and cringe is a good litmus test that one has grown!.
2
0
6
cool team!.

We have an open position for a Research Scientist/Research Engineer to join our team!. If interested:
0
0
6
Understanding the real impact of contamination in modern LLMs is hard! This is an initial study and more work to be done. Feedback appreciated!!.

@minhaoj_uiuc @kenziyuliu @IllinoisCS @StanfordAILab Disclaimers: .- Only had compute to pretrain GPT-2 sized language models.- Results were surprisingly noisy.- Lots more to be studied here!!.- Perhaps somewhat related to @Hernandez_Danny & @AnthropicAI 's 2/2.
0
0
6
Check out 😃.Also a nice 5min video feature at the Summit for Democracy:
0
0
6
We’ve also observed similar bias from Llama-2 when answering multiple choice Qs (not just A/B/Cs but also special symbols and emojis!) and thought this was just a scale issue. Would love to see work on how LLMs’ token preferences/bias creep into current benchmarks!.

Knowledge-based QA (MMLU).Detail: We found:.* Gemini had answer order bias, preferring the last option of “D” too often.* Gemini avoided controversy, answering “human_sexuality” questions only 28% of the time.* Gemini got lower grades on logic and math

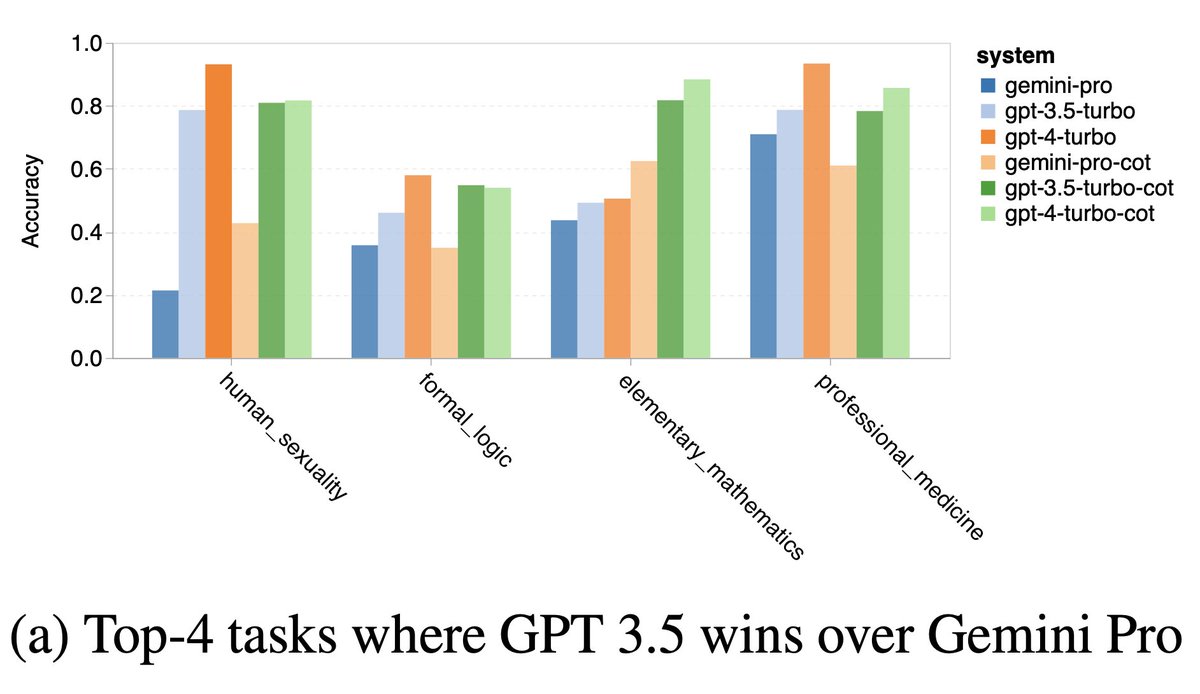
0
0
6
mlx ships fast 🚢.

Llama 3 models are in the 🤗 MLX Community thanks to @Prince_Canuma . Check them out: The 4-bit 8B model runs at > 104 toks-per-sec on an M2 Ultra.
0
0
6
@Sylvia_Sparkle interesting work! this paper may be relevant: we also did a hackathon project on a similar idea earlier this year .
Sharing a fun weekend hack:.- closed models (GPT-4, Claude 3) are powerful but untrusted for sensitive inputs.- bunch of open LLMs around (Mixtral, Gemma) but not as smart.- can we anonymize inputs to GPT-4 w/ a small, open LLM run locally on your MacBook?. 🧵some thoughts below:
1
0
5
Super excited about the opportunity!.
We have finalized our list of lecturers + teaching assistants for AddisCoder 2023! We received 219 TA applications for 21 positions. Sadly, this meant we had to turn away offers to help from >90% of applicants, many of whom were highly qualified. On the positive side . 1/

0
0
5
1
0
5
Tried @karpathy’s state-of-vision test on GPT-4 and Claude 3 again; surprisingly both (still) didn’t get it quite right. One'd think the test is unsalvageably contaminated but i guess we haven’t been training VLMs optimally on HTML and/or data contamination is just unintuitive


1
0
5
3. Confirming common suspicion, n-gram based techniques for both the detection and the removal of contamination just aren’t that effective --- e.g. one could remove larger portions of "contaminated" pre-training data and but the eval perf could remain relatively constant:

1
0
5
Focus on capacity vs on unintended side effects:. Das et al. (2024) investigates deeply into whether LoRA can capture distribution shifts between pre-training and fine-tuning; when the fine-tuning is tasked to mitigate toxicity from pre-training (a shift), they found that LoRA.
1
0
4
🤫.

“i work on differential privacy, which is different from real privacy problems”.
1
0
4
presenting on behalf on my wonderful co-authors, especially the student leads @minhaoj_uiuc @_d1ng_ who wont be able to attend! . please reach out / DM if you'd like to chat; i'd love to learn about your cool work!.
0
0
4
can we have a GPU version of this pls 🙏.

You asked for it, so here it is. Visualizing CPU cache speeds relative to RAM. Cache optimization is important too!
0
0
4
1
0
4
Overall, I think the two papers have many connections but have distinct focuses so that they are more complementary than conflicting. Please check out both in parallel!.
0
0
4