

Simo Ryu
@cloneofsimo
Followers
5,153
Following
476
Media
488
Statuses
1,649
I like cats, math and codes cloneofsimo @gmail .com
Seoul, Korea
Joined May 2022
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Iran
• 570177 Tweets
Kyle
• 305733 Tweets
アザラシ幼稚園
• 122796 Tweets
FELIX
• 103760 Tweets
Mascherano
• 81081 Tweets
Emily
• 78192 Tweets
pastor
• 74422 Tweets
RAGE
• 63341 Tweets
#SmackDown
• 56256 Tweets
コスサミ
• 52905 Tweets
#Lollapalooza
• 48052 Tweets
Angola
• 42441 Tweets
#SKZpalooza
• 40803 Tweets
残高不足
• 37620 Tweets
STRAY KIDS DOMINATE LOLLA
• 32700 Tweets
FGOフェス
• 30877 Tweets
ロッキン
• 28573 Tweets
Lamar
• 27673 Tweets
Aerosmith
• 24074 Tweets
ムビチケ
• 23255 Tweets
Bianca
• 17740 Tweets
Mahomes
• 17378 Tweets
Bloodline
• 16887 Tweets
オベロン
• 15498 Tweets
はちみつの日
• 12013 Tweets
英霊博装
• 11700 Tweets




















Pinned Tweet

Proud to finally showcase the 1024x1024 version of AuraFlow (the next generation of lavenderflow)! Truly open, largest text2image model out there with (arguably) SoTA level performance!
1/n

29
97
562
Friendly reminder in case yall forgot: why is torch + cuda stack so incredibly popular and user friendly that it dominates all of ai market?

40
61
1K

Yes. Yes!!!! Everyone read this material three times!


Has someone created materials around “fundamentals of ML for AI Engineers”, not focused on building models but things like evaluations, error analysis, etc
Maybe something already exists? I don’t want to do it lol - looking for a resource I can share with people
36
31
367
7
92
644
INSANE new model! This just wracked GLIGEN and sketch guided diffusion at the same time... 🤯

13
84
412
If you want to train everything from scratch,
1. Train VAE
2. Train CLIP
3. Train LLM
4. Using 3, train captioner based on CLIP.
5. Finetune dense captioner
6. Relabel text image pair
7. Train unet based on 1,6
8. Train pixel decoder
9. Train LLM for upsample caption

11
66
409
So year ago I introduced LoRA (which was at the time little known even to the LLM community, it was well before LLAMA / Peft) to image generation space.
Little did I realize year later thousands of deepfake waifu LoRAs would be flooding on the web... 🫥

My model is now ready to make thousands of consistent generations...
It's technically known as a LoRA (Low-Rank Adaptation), with SDXL as the base (foundation) model.
From here, two options are possible:
(i) Utilize your LoRA model independently,
(ii) Or blend this LoRA with

3
11
123
19
29
347
This paper and their model is insane. Highly likely that these attention layers can be transferred to other fine-tuned models as well, which is truly groundbreaking feature for the SD community.

6
59
353
As a gpu-poor I hope this works at scale. 1.8k $ can you believe this?

4
41
350
Did you know SDXL can be implemented with 520 lines of code in single file?
If you thought diffuser's unet code is now too big to understand in an hour, and wanted very limited but fully diffusers-compatible refactor of SDXL unet, this is for you

9
53
300
To fellow solo-working-outsider bros... Don't let comment like this discourage you.
There is *a lot* to do. We *all* need your help.
Ask for grants if you don't have compute (h100s cost like < 3$ / hour anyways, prove in small scale and reach out), like
@FAL
, or Google TPU

@tilmanbayer
@faustsoli
einstein was able to advance the field just with a pen and paper even when he wasnt able to verify his theories through experiment at the time. you cant do that in ai, at all
3
0
9
6
32
298
Work like these are just precisely what makes research in generative modeling exciting, such great idea!

1
29
295
Personally, i feel very good today.
Achievement Unlocked: successfully train very large diffusion model from scratch, entirely on my own codebase! (of course, not like SD3 papers codebase is out or anything..)
12
14
279
YES!!!! TOOK 26 hours to make this happen: conditional D3PM implementation with pytorch. Let's accelerate discrete diffusion research!!! 👏I believe this is the only torch implementation of it out there!
Less than 400 LOC!
paper:


5
41
276
Here is a cool little hack I found with AnimateDiff: instead of just sampling, by introducing variance-preserving self-correlation in time axis, you can achieve "lesser flickering motion". corr = [0.9, 0.7, 0.2, 0.0(Just sampling)].
7
39
265
babe wake up, new muP paper dropped
And holy smokes does this look promising!

10
54
346
So over the course of this year and last year I've learnt a whole lot on scaling, especially regarding what correct parameterization is when width / batch size / data size scales up.
Objective is both training stability & optimal hyperparameter transfer.
I thought I would share

5
40
254
So you've had your fun with
@karpathy
's mingpt. Now its time to scale : introducing min-max-gpt: really small codebase that scales with help of
@MSFTDeepSpeed
. No huggingface accelerate, transformer. Just deepspeed + torch: maximum hackability

7
35
248
Wondered how SD3 was trained? Me too 😅, but I tried my best to replicate that today!
Scalable transformer based rectified flow, following SD3's logit-normal sampler and llama-dit architecture.
Enjoy!
9
43
228
Hi, this is Lavenderflow-5.6B-v0.0
✅MMDiT, muP, CFM, FSDP, recaped, 768x768, T5
✅No strings attached, completely-open-every-step-of-the-way
✅Not SoTA😅(hey it was trained by one grad-student under total 3 weeks of development.) Severely undertrained!

13
32
227
Again, the paper im advocating here is from openai, and is referenced all the time and frankly one of the paper all large scale practitioner should read. the math here isn't complicated and nothing here is either controversial nor task dependent.

12
20
224
Whats cool about implementing your own ZeRO distributed optimizer is you get to touch every single aspect of your optimizer, both regarding implementation and sharding strategy, as well as its performance optimization.
For example, you now don't have to rely on fused apex-like

4
18
221
I've managed to fine-tune Kandinsky 2.1 model. I think I'm the first one to get it done (because there is no doc on the repo and model structure is rather strange, and really not trivial to fine-tune). Model itself is really good as the FID promised.


16
24
218
5.6B param SD3 replication TODO:
1. find dudes with lot of compute: ✅
2. check MMDiT scales upto 5B : ✅
3. download, deduplicate 120M dataset : ✅
4. preprocess VAE: ✅
5. (Won't do aesth filtering!!) ✅
6. recaption with BLIP-3 or sth + T5 emb ✅
7. gpus go brr LETS GOOO⌛️⌛️

10
16
210
At this point just so many SD related techs are getting pumped in its near impossible to catch up 🤣 either way, here goes another controlnet like model from tencet

3
31
201
Lavenderflow-pretrained-256x256-6.8B Hybrid MMDiT just reached 0.597 on GenEval! 🥳
It took me and
@isidentical
less than 7 weeks of part-time effort + 4k h100 hours to get to SDXL-level (and this is just pretrained model) Does two of us worth 1B valuation?


7
13
202
I've ported t2i-adapter to be compatible to diffusers library, go ahead and use them! Example with Anythingv3 model + LoRA + T2I Adapter. (all with diffusers!)

7
34
192

Ok, my 5.4 B freaking-absolute-overkill ImageNet 1K rectified flow model is now finished. this is trained for 320K steps, with bs 128, meaning its SIGNIFICANTLY undertrained. However, it is lookin *very good* for its training budget. Also training was very stable, 0-loss-spike!
6
10
182
Finally, on-par quality with Dreambooth, updated + optimized PTI CLI, SVD distillation CLI, flexible dataset and CLIP metrics utilities, wandb logging, v0.1.0 is finally out!

6
28
179
Uhh excuse me wtf LLAMA3 ranking 1st????? in lmsys arena in English? Kudos to team
@AIatMeta
, based AF 👏👏 for open sourcing literal GPT-4 level model, (almost) no strings attached🥳

6
19
177
Worked on this weekend: open-sourced f16-c32 VAE
(will release tommorow or something, but its a quite large model lol)
vibe checks out btw:
left is ground truth, right is reconstructed.
The trick was to use zero-init modulation (like DiT), groupnorm, latent upsamping, and


5
22
172
Fun fact: AuraFlow was < 800 LoC and < one month of training. Code is just open. It's just deepspeed and MDS.
You don't need bloated codebases to make a good model!

Proud to finally showcase the 1024x1024 version of AuraFlow (the next generation of lavenderflow)! Truly open, largest text2image model out there with (arguably) SoTA level performance!
1/n
29
97
562
4
15
172
Cannot emphasize this enough, but you only have to train LoRA once and you can apply them anywhere. Below case is with , which is pretty awesome model. Configs from

5
12
168
Normal people's hobby : listening to music, sports, video games...
Me : speedrun pretraining 5B T2I DiT from scratch under 3 weeks
RELEASING SOON!!!!! (btw this is pretrained ver, gotta train on hi-res)
8
15
170
Did you know Imagenet fits on your apple watch's RAM?
introducing imagenet.int8: 5GB, Cropped, VAEed, quantized version of imagenet, 26x compression in total, preprocessed in StreamingDataset format.
Enjoy.

13
25
165
In a equal compute budget, using larger batch almost always implies worse performance.
Rationale for using larger batch-size should always be for sake of faster convergence in equal *time*, not better performance in equal compute budget

8
14
159
Final model 512x512 aesthetic training 😍
btw Its been an absolute wild run. I've learned SO DAMN much from this process. Not a lot of people get to make foundation model from scratch with such freedom. Im so glad
@burkaygur
from
@FAL
offered me such collaboration!!


7
8
158
SD3 replication TODO:
1. find dudes with lot of compute: ✅
2. check MMDiT scales upto 5B : ✅
3. download, deduplicate 120M dataset : ✅
4. preprocess VAE: ✅
5. aesthetic filter with HPSv2
6. recaption with BLIP-3 or sth + T5 emb
7. gpus go brr -> fail multiple times
8
9
155
AuraFlow got a lot more attention than I thought! First time is the hardest, we'll only get better from now.
My plan for next version.
* Much better Encoder-Decoder, with higher spatial compression ratio, such as stable cascade-level compression (im looking at this btw
11
7
152
But to be honest, there's been tons of low-rank, quantized gradient-approximation for efficient allgathers that the paper didn't mention for some reason. Like, not citing PowerSGD?? this? …Like man totally not cool 🙄
fig from psgd


GaLore
Memory-Efficient LLM Training by Gradient Low-Rank Projection
Training Large Language Models (LLMs) presents significant memory challenges, predominantly due to the growing size of weights and optimizer states. Common memory-reduction approaches, such as low-rank
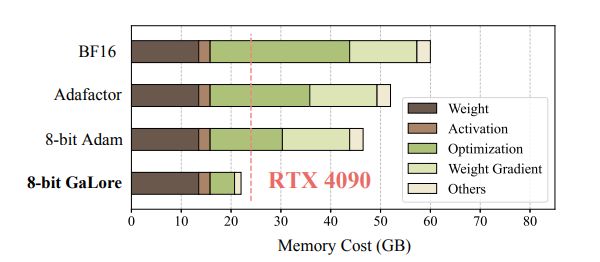
17
168
869
3
25
148
So Lavenderflow 6.8B *just* reached Dalle-3 level on GenEval, but I suspect this was lucky run. Still, its going somewhere close to Dalle-3 (and SD3-8B) which makes me happy. Going to do Parti-prompts GPT-V eval soon!!!
(+ GenEval is not a solid nor comprehensive benchmark so i


4
11
139
Something I learned from training 1024x1024 diffusion models... USE MULTI_SCALE_LOSS from simple-diffusion. Seriously. I've just used 4x4_loss + 1/4 * MSE, and it works great!!! btw it takes quite an activation so maybe fused kernel for it would be great

5
14
135
Its really cool high quality compressed model, especially thinking that they achieved this with single a100 machine! +1 for awesome demo page as well.

1
24
131
Ok hear me out, what if I told you absolute bare minimal implementation of FSDP is just 140 LoC?
My next toy project is *sane* FSDP framework that any child can understand and build on. Maximal hackability, minimal abstraction.
* Keeping the params in contiguous row-major

2
15
129
I managed to get it work! 2 Step, No progressive distillation as promised, reasonable quality for dumb unet structure and 10 min of training. I think this is the only implementation out there (given its like 4 days old) Not bad!

6
16
125
Reminder, my friends.
Tomorrow you will be gifted with SD3, 2B ver.
However,
It will be tiny.
It will be closed source
It will require "license".
.
.
.
Mine won't.
Mine will be LARGE AF.
training code? its ALREADY OPEN.
mine will be MIT at best, AL2 at worst.

10
8
124
moon is high, model is 44k steps in, I stopped the run to check on everything and use multi-nodes, didn't expect *anything* at all.... However, safe to say, i've trained my FIRST ever 5.6B Text2Image MMDiT from scratch!!!
14
2
121

Fully fine-tuning SDXL on OW Kiriko images. This took about 10 min. Can you believe this is fine-tuned Base model? BASE????
@StabilityAI
is simply incredible.


9
14
118
Did we just get another open sourced text2img model?
0
18
116
Incredible analysis on CFG, best ive read so far, by Karras (again). CFG reduces diversity, but makes the prediction 'sharper', thus giving the illusion of better result
However method "autoguidance" has been (unfortunately) been widely used before :P

3
14
115
"bUt iT woN't Be aS goOd wiTH yoUR teeNy coMpUte"
nah i dont care im not raising cash bro, gaining this experience of handling 100M-scale dataset, pretraining billion-scale vision model from scratch, post-hoc analysis... *all as a hobby in my free time*, is what matters 😎
11
2
112
One YOLO decision I made on AuraFlow is it DOES NOT HAVE clip & croppings conditions as global conditioner, and it ONLY has one Pile-XL T5 encoder as the input.
This way, the way image gets generated ONLY stems from the single textual embedding and nothing else, you will be able

10
10
111
Cool work, have a look! Interesting to see they tie the "probability" of discrete representation to, well, the probability of the dataset : Variational Inference itself.

1
23
108
So this might be the current best usable form of encoder based inversion for SD 2.X models, Really good in terms of fidelity, but NC license is bit sad.

7
23
109
Larger model being more sample efficient is arguably single most important rationale behind large-scale training. LLAMA3 made us forget that.



3
13
107
Well, well, ain't this exciting.


Google presents Mixture-of-Depths
Dynamically allocating compute in transformer-based language models
Same performance w/ a fraction of the FLOPs per forward pass

6
91
613
1
9
101
Im not cherry picking, im really not. I mean its just... so funny
btw the model has been officially renamed to AuraDiffusion!

9
6
101
Math is,,, incredible. I just fixed the learning rate faithful to muP suggested, now gradient norm is much more stable, my depression is cured, eyesight have improved, posture is better, and cured cancer.


7
1
99
... we depart from common practice and do not freeze the image encoder. However, the challenges outlined in LiT remain. In order to avoid destructive supervision signal from the initially unaligned language model, we use a slow linear warm-up for the image encoder’s learningrate

4
9
99
Unlike Controlnet, T2i-adapter is lightweight, generalizable out-of-the-box, and is vey fast. It also does generate additional feature per-timestep. However, it seems to be less strict than Controlnet, thus one might prefer controlnet for truly fine-grained control.


6
11
95
Friendly reminder that this is truely open source t2i model!
Every line of code to reproduce this model has always been open sourced from very beginning!
(But it requires a lot of vram to run this code. You need substantial modification to save a lot


2
9
97
Today I realized that weight normalization of EDM2 (by Karras again, damn) is kinda just Riemannian optimization. Projecting gradient to tangent space of hypersphere is precisely the Riemannian gradient, and normalization after update is just retraction on the oblique manifold.

3
11
98
This is the "real" stable diffusion moment for LLMs. Goodbye llama.

📢 Introducing MPT: a new family of open-source commercially usable LLMs from
@MosaicML
. Trained on 1T tokens of text+code, MPT models match and - in many ways - surpass LLaMa-7B. This release includes 4 models: MPT-Base, Instruct, Chat, & StoryWriter (🧵)

22
215
1K
2
4
96
How did I not know this before? download model from hf to local visible directory via
pip install hf_transfer
export HF_HUB_ENABLE_HF_TRANSFER=True
huggingface-cli download TheBloke/Yi-34B-Chat-AWQ --local-dir ./yiawq
NO JOKE 100x speedup
3
6
97
If you binarize the MNIST, and run d3pm, it is literally discrete diffusion on QR-code space lol🤪
1
1
95
a gray cat playing a saxophone is inside a large, transparent water tank strapped to the belly of a massive mecha robot, which is stomping down a bustling san francisco street, the mecha has large metal legs and arms with glowing joints and wires, towering over buildings and

10
8
95
This is pretty interesting I never knew wtf. Kahan Summation compensates for lost precision, allowing *not* keeping master weight in full precision & Adam variables in much lower precision
... this free lunch is not in torch's FSDP nor DeepSpeed?

7
10
93
First looks on training 0.9B IN1k model, 67k steps in, im already getting pretty decent quality images!! minRF is damn scalable with help of
@MSFTDeepSpeed
!
👉
[ rectified flow, muP, SDXL vae, MMDiT, cfg = 7.0!]

4
5
93
Wait does this mean we will soon have VLM running on vLLM doing LLVM optimization for LLMs?

5
11
93

I wrote a little literature review (of sort) on this topic.
How does one do f(QK^T)V efficiently, in general?
Feedbacks are appreciated.


Still, the pattern 𝚗𝚘𝚗-𝚕𝚒𝚗𝚎𝚊𝚛𝚒𝚝𝚢(𝙺 𝚀^𝚃) 𝚅 should really have a more general solution than "write your own cuda kernel based on flash-attention".
1
0
15
6
10
90
Huh, so it looks like triton's Flash Attention is significantly faster than torch's integrated SDPA flashattention (which is much faster than naive attention). This was done on 3070 Ti GPU

4
15
82
btw Qwen2 has arena-hard of 48 (imo toughest, most relevant benchmark out there) puts it right besides gemini, gpt4, and claude.
...only except that its truly open (apache2.0), 128k, multilingual, and 70B!! What a day!


💗Hello Qwen2!
Happy to share the Qwen2 models to you all!
📖 BLOG:
🤗 HF collection:
🤖
💻 GitHub:
We have base and Instruct models of 5 sizes, Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B,

38
150
614
4
8
84
Cool paper from google!
Exciting idea to use multiple latent per cross attention. There might be a room for correlated optimization, where some tokens being injected share multiple common embeddings.i.e., inject another common token t_s during optimizatio

1
21
83
Text2characters... Absolute madmans doing insane works... looks like they will be releasing code as well
3
16
83
Recently, Karras demonstrated post-hoc ema method, where he was able to "simulate" arbitrary ema decaying factor after the training by saving two copies of ema and clever math.
I took a deep breath to understand it, and wrote a tutorial + working example!

1
12
80
Now that my 5.4B model is stably training (pun intended), next goal is to deduplicate wds + filter + recaption.
I've done my job on deduplication multiple times before, but here is my best attempt yet, fully following SD3's approach with SSCD emb
Enjoy!

8
10
80
Nice! um v0.2 eta this week friday maybe if I grind enough???


9
2
81
*reads nemo*
*realize 0.4 is the best MFU you will ever get, realistically*
💀*Inner soul dies with hopelessness*
HEY NVIDIA, WHATS THE POINT OF 60% OF THE CORES IF 0.4 IS THE BEST YOUR BEST ENGINEERS CAN EVERY REALLY GET?????

9
3
80
Lucky enough to collaborate with
@huggingface
's diffusers team (more like watching them implement🤣 I wrote no code) and... huge updates! Now LoRA is officially integrated with diffusers! There are major difference from my implementations, very simple to use!

Fine-tune Stable Diffusion in T4/V100 on a custom image-caption pairs' dataset 🧨 🔥 => memory efficiency
This is enabled by LoRA. With LoRA, the fine-tuned checkpoints are just **3 MBs** in size 🤯 => portability
Know about it👇
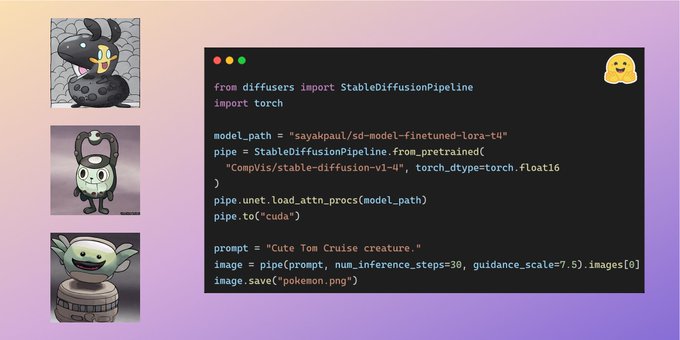
2
43
284
3
15
79
Since the authors didn't upload the code, here is my attempt at Prompt+! (below results is from my impl).
Also further tested out the "correlated extended embedding" idea, which seems to be working (rather it is better or not is unclear)

4
11
79
I made huge blunder last run. I was actually not following important scaling law regarding batch size and was SIGNIFICANTLY undertraining everything... DAMN IT!!!
Literally 5th fundamental mistake I made during training auraflow. htf is this thing SoTA in GenEval?
7
3
78
Even with 16 samples, FINE TUNING PERFORMS SIGNIFICANTLY BETTER THAN ICL!!!
Everyone fine-tune your weights not discrete prompts!😋

3
8
76
Btw, this was done on int8 quantized dataset i shared couple weeks ago, which is 26x smaller than the original dataset!!! Imo clever dataset quantization has a lot to offer.

Ok, my 5.4 B freaking-absolute-overkill ImageNet 1K rectified flow model is now finished. this is trained for 320K steps, with bs 128, meaning its SIGNIFICANTLY undertrained. However, it is lookin *very good* for its training budget. Also training was very stable, 0-loss-spike!
6
10
182
5
2
76
golden apple next to a bronze orange, next to silver grapes
This is quite challenging indeed.. Still slightly better than non-commercial open-weight model out there :)


@cloneofsimo
I've had to do this for specific loras I've trained, and even then you can run into data balance issues. Painful if oranges are usually orange.
BTW, I tried to prompt 'golden apple next to a bronze orange, next to silver grapes' in SD3 Medium and it can only do 1 metal fruit.
0
0
0
3
4
76
last week has been weird.
Team "image is worth tokens"
Team "image is worth pixels"
(IMO, tokens > pixels purely based on hardware utilization POV. progressive diffusion OK as well)

6
11
76
Continuing the journey on f16-c32 AE.... so getting high frequency details is tough... I am trying my best to not use LPIPs/GAN tricks but damn these things are hard to get it right. Help me out with great ideas / literatures....
left is reconstructed, right is input.


9
3
76
"Oh the bitter lesson? Yeah I love the bitter lesson!"
-- gpu rich

4
4
76
Watch my compute optimal 5.4B rectified model go.
I don't have to say this again, but... muP just makes everything easier.

4
3
74
New trick that works insanely well! How would one mitigate spurious correlation that occurs during fine-tuning? Identify the dataset on the region of interest! [1/n]

4
10
72
I wouldn't have come up with using lora for dreambooth if I had beefy A100 gpu to play around 😂Now even the "GPU-rich" uses lora to fine-tune diffusion model.

I prefer to operate in “GPU-Poor” mode.
I don’t agree with the take from the semianalysis piece. Creative breakthroughs often occur under constraints—new systems, models, and methods that can better take advantage of even larger-scale compute

73
136
1K
1
9
72
Ok hear me out, even without upcycling, MoE-MMDiT just started to cross the MMDiT... Now now, let me start the era of time-routed Expert-parallelism diffusion models.

4
2
72

Got my hands on it. Super easy to use, and some findings :
1. Works with Textual inversion, custom models, and LoRA. Incredible flexibility
2. Prompting + Guidance has non-negligible effect here.
3. Sub-second upscaling. Almost free lunch.

1
10
71
chat whare are dtensors am I the only one who *just* heard aboutem???
(wonderful blogpost btw)

6
8
70
Fun stuff: this is also why I stan muP, NTK does not have constant sharpness as width grows, while sharpness stays roughly constantly EoS for muP


Why the fuck is it always my runs at the edge of stability that end up working best?! ugh, I hate it...
24
5
163
2
5
73