

Berivan Isik
@BerivanISIK
Followers
10,100
Following
1,172
Media
28
Statuses
267
Research scientist @GoogleAI . Efficient & trustworthy AI, LLMs, safety, privacy | prev: PhD @Stanford @StanfordAILab
CA, USA
Joined August 2014
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Kendrick
• 368180 Tweets
Wayne
• 130230 Tweets
Browns
• 105375 Tweets
Watson
• 84265 Tweets
Lions
• 83180 Tweets
Manuel
• 68480 Tweets
Raiders
• 59425 Tweets
重陽の節句
• 59053 Tweets
ON CH3 iQIYI JACK JOKER
• 45470 Tweets
Baker
• 43272 Tweets
#ZEEgotoNYFWwithCOS
• 36381 Tweets
Rams
• 33716 Tweets
もちづきさん
• 19628 Tweets
シーザリオ
• 19540 Tweets
Stafford
• 17870 Tweets
ZEE x COS
• 17574 Tweets
Angélica
• 16282 Tweets
#OnePride
• 16177 Tweets
Yuhui
• 15227 Tweets
Goff
• 12570 Tweets
#GOAT_70Mviews
• 12011 Tweets
JD 3rd ANNIVERSARY
• 11266 Tweets
サッポロポテト
• 11098 Tweets
ふっかさん
• 11022 Tweets
















Pinned Tweet

Bittersweet goodbye to the Farm 🌲
Successfully defended my PhD thesis 🤺 grateful for my advisors
@tsachyw
@sanmikoyejo
and everyone I met along the way for the amazing journey at Stanford.


217
207
7K
I have joined
@GoogleAI
as a research scientist. I will continue to work on efficient and trustworthy AI, LLMs, safety, and privacy.
Stay tuned for updates 👀
89
33
2K
Honored to be selected as a Google PhD fellow this year!
Thanks for the generous support
@GoogleAI
@Google
.

In 2009, Google created the PhD Fellowship Program to recognize and support outstanding graduate students pursuing exceptional research in computer science and related fields. Today, we congratulate the recipients of the 2023 Google PhD Fellowship!
23
93
581
23
9
440
Very excited to share the paper from my last
@GoogleAI
internship: Scaling Laws for Downstream Task Performance of LLMs.
w/ Natalia Ponomareva,
@hazimeh_h
, Dimitris Paparas, Sergei Vassilvitskii, and
@sanmikoyejo
1/6

7
28
319
I am very excited about our new work: with
@RylanSchaeffer
@vclecomte
@sanmikoyejo
@ziv_ravid
@Andr3yGR
@KhonaMikail
@ylecun
.
We’ll present it in 4
@NeurIPSConf
workshops:
@unireps
(oral), InfoCog (spotlight),
@neur_reps
, SSL.
Details in Rylan’s tweet👇


Excited to begin announcing our
#NeurIPS2023
workshop & conference papers (1/10)!
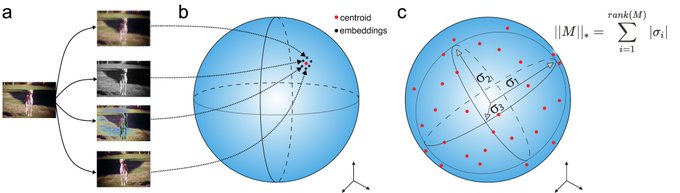
🔥🚀An Information-Theoretic Understanding of Maximum Manifold Capacity Representations🚀🔥
w/ amazing cast
@vclecomte
@BerivanISIK
@sanmikoyejo
@ziv_ravid
@Andr3yGR
@KhonaMikail
@ylecun
1/7
9
93
500
3
32
282
Super excited about new work Lottery Ticket Adaptation (LoTA):
We propose a sparse adaptation method that finetunes only a sparse subset of the pre-trained weights. LoTA mitigates catastrophic forgetting and enables model merging by breaking the


Excited to share Lottery Ticket Adaptation (LoTA)! We propose a sparse adaptation method that finetunes only a sparse subset of the weights. LoTA mitigates catastrophic forgetting and enables model merging by breaking the destructive interference between tasks.
🧵👇

10
45
275
3
34
240
“Sparse Random Networks for Communication-Efficient Federated Learning” has been accepted at
#ICLR2023
! Code coming soon.
Looking forward to seeing many of you
@iclr_conf
in Rwanda.
Excited to share our new work, "Sparse Random Networks for Communication-Efficient Federated Learning".
1/6
1
6
43
5
15
158
Happy to share the second paper from my
@GoogleAI
internship: Sandwiched Video Compression with Neural Wrappers.
The sandwich framework is more efficient than most other neural video compression methods (details below 👇). 1/3

3
10
135
Excited to share our
@NeurIPSConf
'23 paper "Exact Optimality of Communication-Privacy-Utility Tradeoffs in Distributed Mean Estimation":
Looking forward to presenting it in person and seeing many of you in New Orleans! 🙂🎷🎶
Details 👇

2
10
127
Humbled to be selected as a Rising Star in EECS this year. Looking forward to meeting the 2023 cohort
@GeorgiaTech
soon!
10
0
126
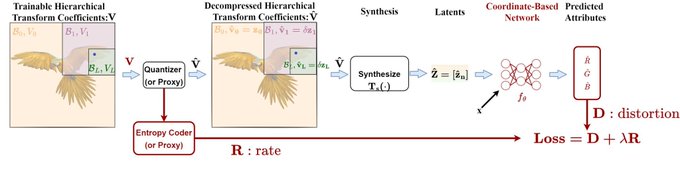
The first paper from my Google internship has been accepted to Frontiers in Signal Processing. This is the first work to compress volumetric functions represented by local coordinate-based neural networks.
Paper link:
Code coming soon.
2
12
93
Accepted to
@COLM_conf
! Check out our new work on fairness implications of low-rank adaptation:


LoRA is great. It’s fast, it’s (mostly) accurate. But is the efficiency a free lunch? Do side effects surface in the fine-tuned model?
We didn’t quite know so we played with ViT/Swin/Llama/Mistral & focused on subgroup fairness.
🧵: takeaways below
📄:

7
28
171
2
6
80
@srush_nlp
In more recent work, we show that scaling laws for downstream behavior depend highly on (1) the metric, (2) the 'alignment' between the pretaining and finetuning data, and (3) the size of the finetuning data.
paper:
a quick highlight 👇

1
7
72
I will give a talk on our recent work on information-theoretic model compression at the Sparsity in Neural Networks Workshop
@sparsenn
on Friday.
3
5
72
It was a really fun
@icmlconf
workshop with amazing speakers, panelists, poster presentations, and a highly engaged audience!
@tf2m_workshop



Join us for the Workshop on
Theoretical Foundations of Foundation Models
@icmlconf
tomorrow!
We have a fantastic list of invited speakers:
-
@th33rtha
-
@DAlistarh
-
@jasondeanlee
-
@kamalikac
-
@tydsh
1/3

2
13
71
4
9
70
#Antakya
Cebrail mahallesi şehit Mehmet Ali demirbüken caddesi emlak bank konutlarından haberi olan ulaşabilir mi? İçerdekilere ulaşamıyoruz.
@AFADTurkiye
#deprem
#AFADhatay
#enkazalt
ındayım
2
122
67

Excited to share our new work with
@FrancescoPase
,
@DenizGunduz1
,
@sanmikoyejo
,Tsachy Weissman, and Michele Zorzi.
We reduce the communication cost in FL by exploiting the side information correlated with the local updates and available to the server.1/3

2
7
59
I will be at AISTATS and ICLR in the following weeks. Let me know if you'd like to chat about efficient and trustworthy ML.
Also, check out our work:
- [AISTATS, May 3rd 5 pm Valencia] Adaptive Compression in Federated Learning via Side Information:
1/2
2
4
59
Excited to share our
#AISTATS2022
paper titled "An Information-Theoretic Justification for Model Pruning":
Come say hi at the conference during our poster session on Wednesday, March 30th, 8:30-10 am PST.
1/6
3
5
50
Excited to be visiting
@NicolasPapernot
’s lab
@VectorInst
this summer 😎 Let’s catch up if you’re in Toronto!
1
2
49
I will be
@icmlconf
for the whole week. Text me if you want to meet up! (Papers 👇)
PS: Don't forget to stop by our workshop
@neural_compress
on Saturday.
1
2
49
Join us for our Neural Compression workshop at
@icmlconf
2023! We’ll release the call for papers soon.
Organizers:
@YiboYang
,
@_dsevero
,
@karen_ullrich
,
@robamler
,
@s_mandt
,
@BerivanISIK
More details 👇

🎉Exciting news! Our "Neural Compression" workshop proposal has been accepted at
#ICML
2023! Join us to explore the latest research developments, including perceptual losses and more compute-efficient models!
@BerivanISIK
,
@YiboYang
,
@_dsevero
,
@karen_ullrich
,
@robamler
4
24
99
2
6
48
Looking forward to the Neural Compression Workshop
@icmlconf
this year. Please consider attending and submitting your latest work. Deadline is May 27th.

The 2nd iteration of the "Neural Compression: From Information Theory to Applications" workshop will take place
@icmlconf
in Hawaii this year!
Submissions due May 27th. For more details:
@BerivanISIK
@YiboYang
@_dsevero
@karen_ullrich
@robamler
@s_mandt
3
18
61
0
2
45
Super excited about our upcoming
@icmlconf
workshop! Stay tuned for updates 🙌
For details:

We are happy to announce that the Workshop on
Theoretical Foundations of Foundation Models will take place
@icmlconf
in Vienna!
For details:
Organizers:
@BerivanISIK
,
@SZiteng
,
@BanghuaZ
,
@eaboix
,
@nmervegurel
,
@uiuc_aisecure
,
@abeirami
,
@sanmikoyejo
1
11
51
0
6
46

Excited to share our new work, "Sparse Random Networks for Communication-Efficient Federated Learning".
1/6
1
6
43
Submissions due in one week!
We welcome submissions on efficient & responsible foundation models and the principled foundations of large models.
CfP:
See you in Vienna in July
@icmlconf
!

🚨 Submissions due on May 29! 🚨
Do you have exciting work on efficient & responsible foundation models or the principled foundations of large models? Submit your work now!
We welcome submissions of work recently published or currently under review at other ML venues.
@icmlconf
0
13
21
0
8
41
I'll be
@icmlconf
next week. Text me if you want to chat about trustworthy & efficient AI or data valuation 🙌
-Sat: Check out our workshops
@tf2m_workshop
&
@DMLRWorkshop
-Thu 1:30-3 pm: w/
@wnchen1994
@KairouzPeter
Albert No
@sewoong79
and Zheng Xu👇

4
2
39
I will be at
#NeurIPS2023
all week. Text me if you'd like to chat about trustworthy & responsible AI at scale! I'll present two works:
Tue afternoon: Exact Optimality of Communication-Privacy-Utility Tradeoffs in Distributed Mean Estimation ()
👇
2
0
36

The workshop is happening at room 317A
@icmlconf
now! Please also join us for the social as well. Everyone is welcome! Details 👇
Please join our social at Maui Brewing Co. Waikiki at 6pm after the workshop. Everyone, especially compression and information theory enthusiasts, is welcome!
@icmlconf

0
4
13
0
4
34
Excited to share the program and list of accepted papers for our
@icmlconf
workshop
@tf2m_workshop
:
Looking forward to discussing efficiency, responsibility, and principled foundations of foundation models in Vienna soon!
We are excited to announce that 58 excellent papers will be presented at the
@icmlconf
TF2M Workshop. List of accepted papers:
You can find the detailed schedule on our website (and below 👇):
1
6
18
0
6
33
A must-read for supervisors and managers👇
Sexual harassment is far more common than discussed because victims often experience fear, not anger, and may freeze rather than confront.
0
2
31
I will give an in-person talk on our work "Efficient Federated Random Subnetwork Training" at the NeurIPS Federated Learning Workshop.
Looking forward to seeing many of you in New Orleans. Drop me a message if you want to meet up!
#neurips2022
Excited to share our new work, "Sparse Random Networks for Communication-Efficient Federated Learning".
1/6
1
6
43
1
1
25
Check out our new paper titled “Learning under Storage and Privacy Constraints”. We propose a novel data pre-processing framework, LCoN, which simultaneously boosts data efficiency, privacy, accuracy, and robustness. 1/4
#compression
#privacy
#learning
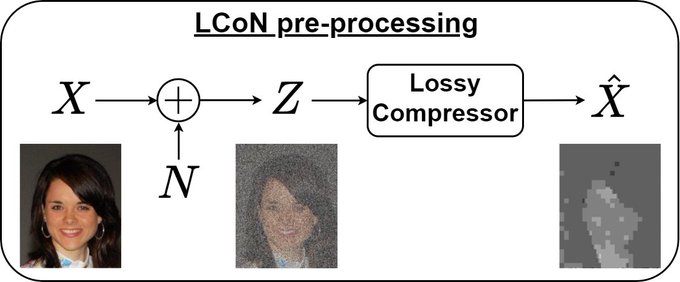
3
0
24
Does LoRA have any unintended effects on subgroup fairness?👇
Work led by
@kenziyuliu
@_d1ng_
@poonpura
with
@sanmikoyejo
LoRA is great. It’s fast, it’s (mostly) accurate. But is the efficiency a free lunch? Do side effects surface in the fine-tuned model?
We didn’t quite know so we played with ViT/Swin/Llama/Mistral & focused on subgroup fairness.
🧵: takeaways below
📄:
7
28
171
0
1
21
We will be in
#NeurIPS2020
WiML and Deep Learning through Information Geometry workshops with our work on neural network compression for noisy storage systems:
1
2
20
Super excited about the 5th edition of the
@DMLRWorkshop
at
@icmlconf
2024. Stay tuned for the updates! 👇

We are thrilled to announce that the
#DMLRWorkshop
on "Datasets for Foundation Models" will take place at the
@icmlconf
in July!
This marks the 5th edition of our
#DMLR
workshop series! Join the DMLR community at
0
6
19
0
3
19
We are excited to announce that Workshop on Information-Theoretic Methods for Rigorous, Responsible, and Reliable Machine Learning will take place
@icmlconf
. We have an excellent line of speakers, including a recent Shannon award winner!
More details:


Workshop on Information-Theoretic Methods for Rigorous, Responsible, and Reliable Machine Learning (ITR3) will take place
@icmlconf
this year.
Submissions due May 24th. Details:
@abeirami
@FlavioCalmon
@BerivanISIK
@hey1jeong
@matthewnokleby
@CindyRush

1
27
86
0
1
19
"Neural Network Compression for Noisy Storage Devices" will appear at the ACM Transactions on Embedded Computing Systems (TECS):
We propose ways to provide robustness to neural networks against noise present in storage or communication environments.
1/3
2
1
18

Thanks for the highlight! 🙌
@arankomatsuzaki

Scaling Laws for Downstream Task Performance of Large Language Models
Studies how the choice of the pretraining data and its size affect downstream cross-entropy and BLEU score

1
20
100
0
1
18
“Kaliforniyaya taşınacaksın. Vietnam-Amerikalı, budist, DJ, kolunda Texas dövmesi olan ev arkadaşın salona seccade serecek, evde bağlama çalacak.”
0
0
17
Join us on Wednesday night for a fruitful discussion at the
@BerkeleyML
panel.

Looking to dive into AI research but unsure how? We're excited to host guests
@xiao_ted
(
@GoogleAI
), Yi Li (
@AmbiRobotics
),
@TheRealRPuri
(
@OpenAI
),
@BerivanISIK
(
@Stanford
) and
@ritageleta
(
@berkeley_ai
) for our research panel!! Come through Wednesday evening with questions!

2
14
39
0
0
16
That my aunt was “hired” to be my aunt

0
0
15
Thanks for the highlight!
@_akhaliq

Scaling Laws for Downstream Task Performance of Large Language Models
paper page:
Scaling laws provide important insights that can guide the design of large language models (LLMs). Existing work has primarily focused on studying scaling laws for

3
33
160
0
0
13
Registration and poster abstract submissions for the Stanford Compression Workshop 2021 are now being accepted!
Date: 25-26th February 2021
Website:
Poster abstract submission deadline: 21 Feb 2021
0
1
12
Lottery Ticket Adaptation (LoTA) is a new adaptation method that achieves best-in-class performance on challenging tasks, mitigates catastrophic forgetting, and enables model merging across different tasks.
Paper:
Code:
Feedback

0
1
13
Tomorrow at the FLOW seminar, I will talk about our
@iclr_conf
2023 paper "Sparse Random Networks for Communication-Efficient Federated Learning".
Looking forward to your feedback and questions. 🙌

📢: The 99th FLOW talk is on Wednesday (22th March) at **5 pm UTC**.
Berivan Isik (Stanford) will discuss "Sparse Random Networks for Communication-Efficient Federated Learning."
Register to our mailing list:

0
0
6
1
1
11
@tianle_cai
Very cool work! 💫 we have a NeurIPS 2023 workshop paper with a similar idea and observations. The delta between the finetuned and pretrained model is extremely compressible with quantization and even with simple magnitude-based sparsification:
0
0
10
@ekrem_imamoglu
Hatay Antakya, Emlakbank Evleri 1. Kisim 6-D , 6-B bloklari, hic kimseden haber alinamiyor. Musa Yuksekgonul, Behiye Yuksekgonul, Bahar Yuksekgonul.
@istanbulbld
@AFADHatay
0
1
9
@cigdemtoker
Hatay Antakya, Emlakbank Evleri 1. Kisim 6-D , 6-B bloklari, hic kimseden haber alinamiyor. Musa Yuksekgonul, Behiye Yuksekgonul, Bahar Yuksekgonul
0
10
8
The framework consists of a neural pre- and post-processor with a standard video codec between them. The networks are trained jointly to optimize a rate-distortion loss function with the goal of significantly improving over the standard codec in various compression scenarios. 2/3
1
0
8
We can go up to 99% sparsity without any costly steps to find the sparsity mask. We can find the mask with just one dense training step with a significantly small portion of the dataset, followed by magnitude thresholding to find the most important weights for the task. This way,

1
1
8
@miniapeur
There is an (not very tight) upper bound on the output distortion when pruning a single connection that helps with adjusting layer-wise sparsity in a greedy manner:
3
0
8
LoTA is also incredibly helpful for model merging. Existing model merging methods mostly do post-hoc sparsification to their dense adapters, which usually hurts the performance. LoTA does not require this post-hoc sparsification since the task vectors are already sparse. 4/5

1
0
8
LoTA successfully mitigates catastrophic forgetting since sparse updates overlap less than dense updates or LoRA updates. We can even impose this further by restricting the updates of future tasks on non-overlapping weights from previous tasks and eliminate interference between

1
0
8
Spotlight talks on Fri Dec 15, InfoCog and
@unireps
workshops: An Information-Theoretic Understanding of Maximum Manifold Capacity Representations ()
0
1
8
Speakers: Johannes Balle (Google),
@jmhernandez233
(Cambridge), Hyeji Kim (UT Austin), Yan Lu (Microsoft), Aaron Wagner (Cornell), Tsachy Weissman (Stanford)
Panelists: Ashish Khisti (UofT),
@tivaro
(Qualcomm),
@george_toderici
(Google),
@RashmiKVinayak
(CMU)
0
0
7

We also developed a novel model compression method (called SuRP), guided by this information-theoretic formulation, which indeed outputs a sparse model without an explicit pruning step.
1
0
5
Come say hi during our poster sessions if you're interested:
Monday 12:30-2:30 pm PST (WiML)
Wednesday 4-5 am PST (WiML)
Saturday 5-6:30 pm PST (DL-IG)
1
0
6
@FrancescoPase
@DenizGunduz1
@sanmikoyejo
We show the existence of highly natural choices of pre-data distribution (side information at the server) and post-data distribution (local updates at the clients) in FL that we can use to reduce the communication cost significantly -- up to 50 times more than the baselines. 2/3
1
0
6
Compared to other neural video compression methods, the sandwich framework is much more efficient as it requires pre- and post-processors formed by modestly-parameterized, lightweight networks.
Joint work with Philip A. Chou, Onur Guleryuz, Danhang Tang, and Jonathan Taylor. 3/3
0
0
6
TLDR: The size of the finetuning dataset and the distribution alignment between the pretraining and downstream data significantly influence the scaling behavior. 3/6
1
0
6
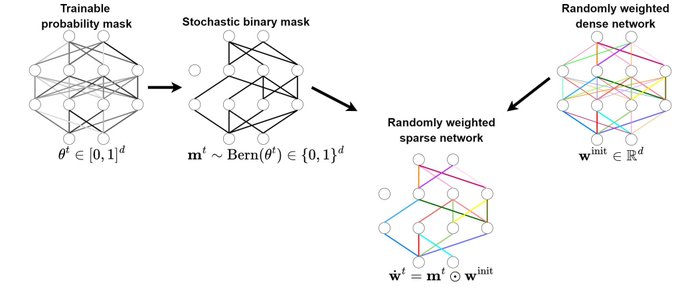
We propose Federated Probabilistic Mask Training (FedPM) that does not update the randomly initialized weights at all. Instead, FedPM freezes the weights at their initial random values and learns how to sparsify the random network for the best performance. 2/6
1
0
5
I will present two papers at the Federated Learning Workshop:
1) Exact Optimality of Communication-Privacy-Utility Tradeoffs in Distributed Mean Estimation:
2) Communication-Efficient Federated Learning through Importance Sampling:
1
0
5
We derived the information-theoretical limit of model compression and showed that this limit can only be achieved when the reconstructed model is sparse (pruned).
1
0
4
@srush_nlp
Cross-entropy (CE) loss always improves with more pertaining data regardless of the degree of alignment. But BLEU/COMET/ROUGE scores on the downstream task sometimes drop with more pertaining data when alignment is not sufficient.

0
0
5
@fluffykittnmeow
@RylanSchaeffer
@YuanqiD
@vclecomte
@sanmikoyejo
@ziv_ravid
@Andr3yGR
@KhonaMikail
@ylecun
Sorry about that! We’ll put the paper on arxiv very soon. For now, you can check the workshop paper here:
0
0
5
And one preliminary study at the Efficient Foundation Models Workshop:
GPT-Zip: Deep Compression of Finetuned Large Language Models:
0
0
5

@FrancescoPase
@DenizGunduz1
@sanmikoyejo
We also show how to adaptively adjust the bitrate across the model parameters and training rounds to achieve the fundamental communication cost -- the KL divergence between the pre-data and post-data distributions. 3/3
0
0
5

FedPM reduces the communication cost to less than 1 bit per parameter (bpp), reaches higher accuracy with faster convergence than the relevant baselines, outputs a final model with size less than 1 bpp, and can potentially amplify privacy. 4/6
1
0
4
However, there are also cases where moderate misalignment causes the BLEU score to fluctuate or get worse with more pretraining, whereas downstream cross-entropy monotonically improves. 5/6
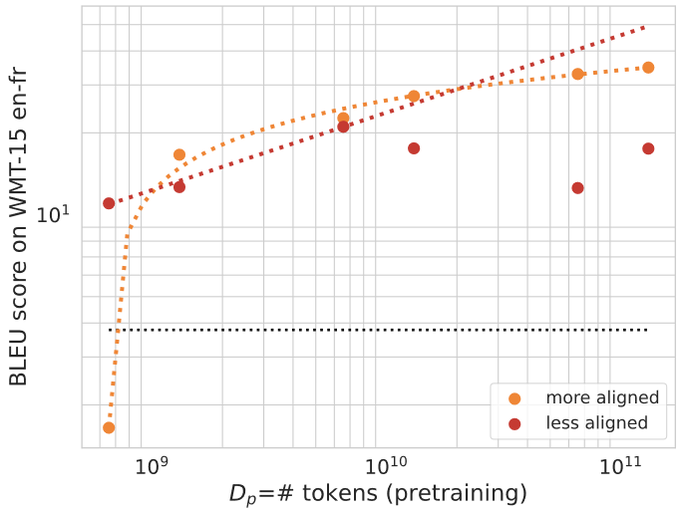
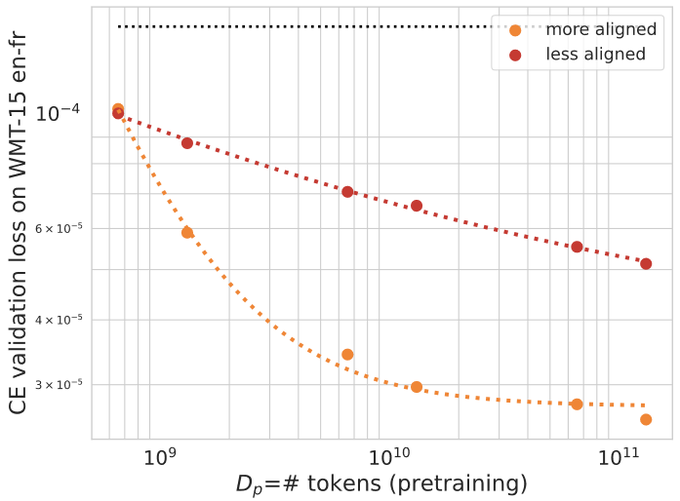
2
0
4
To this end, the clients collaborate in training a stochastic binary mask to find the optimal sparse random network within the original one. At the end of the training, the final model is a sparse network with random weights – or a subnetwork inside the dense random network. 3/6
1
0
4
- [ICLR DMFM & ME-FoMo] Scaling Laws for Downstream Task Performance of Large Language Models:
- [ICLR SeT LLM, Me-FoMo, R2-FM, PML4LRS] On Fairness Implications and Evaluations of Low-Rank Adaptation of Large Models:
2/2
0
2
4
Throughout the manuscript, we highlighted the advantages of having a stochastic mask training approach rather than a deterministic one in terms of accuracy, bitrate, and privacy. 5/6
1
0
4
We use an analog storage technology (PCM) as an example to show that the noise added by the PCM cells is detrimental to the performance of neural networks and that we can recover full accuracy with our robust coding strategies.
2/3
1
0
4
We study the mean estimation problem under communication and local differential privacy constraints. As opposed to the order-optimal solutions in prior work,we characterize exact optimality conditions and develop an algorithm that is exact-optimal for a large family of codebooks.
0
0
4
This highlights the importance of studying downstream performance metrics and not making decisions solely based on cross-entropy! 6/6
0
0
4
We study the scaling behavior in a transfer learning setting, where LLMs are finetuned for translation tasks, and investigate how the choice of the pretraining data and its size affect downstream performance as judged by two metrics: downstream cross-entropy and BLEU score. 2/6
1
0
4

We investigated the theoretical tradeoff between the compression ratio and output perturbation of neural network models and found out that the rate-distortion theoretic formulation introduces a theoretical foundation for pruning. 2/6
1
0
3
0
0
3