

Rylan Schaeffer
@RylanSchaeffer
Followers
4,127
Following
1,131
Media
269
Statuses
1,012
AI/ML arborist (or arsonist, depending on your viewpoint)
Mountain View, CA
Joined October 2011
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#DNC2024
• 168441 Tweets
River
• 145298 Tweets
Macri
• 89559 Tweets
Bill Clinton
• 84986 Tweets
Simón
• 79175 Tweets
#虎に翼
• 56039 Tweets
Okan
• 44881 Tweets
Mike Lindell
• 39555 Tweets
Talleres
• 25798 Tweets
サンサン
• 25228 Tweets
JENNA
• 24677 Tweets
#AEWDynamite
• 22521 Tweets
Soto
• 22116 Tweets
Oprah
• 21028 Tweets
Borja
• 18482 Tweets
Peñarol
• 16877 Tweets
Stevie Wonder
• 14902 Tweets
Geoff Duncan
• 14229 Tweets
Joey Votto
• 12205 Tweets




















Pinned Tweet

Yesterday, I tweeted that model collapse appears when researchers intentionally induce it in ways that don't match what is done in practice
Let me explain using the Shumailov et al.
@Nature
2024 paper's methodology as an example
Paper:
🧵⬇️
1/N

For anyone interested in model collapse, I strongly urge people to look at our COLM 2024 paper
Model collapse appears when researchers intentionally induce it in ways that simply don't match what is actually done practice
@alexandr_wang
is wrong
22
77
545
16
119
625
Excited to announce my newest breakthrough project!!
🔥🔥 State-of-the-art results (100%!!) on widely used academic benchmarks (MMLU, GSM8K, HumanEval, OpenbookQA, ARC Challenge, etc.) 🔥🔥
1M param LLM trained on 100k tokens 🤯
How??
Introducing **phi-CTNL**
🧵👇
1/6

51
133
970
For anyone interested in model collapse, I strongly urge people to look at our COLM 2024 paper
Model collapse appears when researchers intentionally induce it in ways that simply don't match what is actually done practice
@alexandr_wang
is wrong


1/ New paper in Nature shows model collapse as successive model generations models are recursively trained on synthetic data.
This is an important result. While many researchers today view synthetic data as AI philosopher’s stone, there is no free lunch.
Read more 👇

44
96
671
22
77
545
I had a wonderful but exhausting
#NeurIPS2023
. On the flight home, I watched
@srush_nlp
's lecture on linear RNNs & state space models
Can't recommend highly enough. Dense with information plus references to know where to dig deeper💯💯

2
59
529
Excited to begin announcing our
#NeurIPS2023
workshop & conference papers (1/10)!
🔥🚀An Information-Theoretic Understanding of Maximum Manifold Capacity Representations🚀🔥
w/ amazing cast
@vclecomte
@BerivanISIK
@sanmikoyejo
@ziv_ravid
@Andr3yGR
@KhonaMikail
@ylecun
1/7
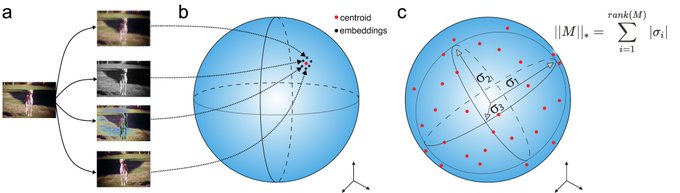
9
93
501
What happens when generative models are trained on their own outputs?
Prior works foretold of a catastrophic feedback loop, a curse of recursion, descending into madness as models consume their own outputs. Are we poisoning the very data necessary to train future models?
1/N

16
57
330
Very excited to announce our
#NeurIPS2022
paper No Free Lunch from Deep Learning in Neuroscience: A Case Study through Models of the Entorhinal-Hippocampal Circuit.
It's a story about NeuroAI, told through a story about grid & place cells.
Joint w/
@KhonaMikail
@FieteGroup
1/15

5
57
314
Excited to announce:
🔥🧠 Associative Memory Under the Probabilistic Lens 🧠🔥
w
@KhonaMikail
@Andr3yGR
@sanmikoyejo
@neurostrow
@FieteGroup
& Nika Zahedi
Appearing @
#NeurIPS2023
Associative Memory & Hopfield Networks Workshop !
🧵👇
1/7

4
51
289
We had meant to keep this under wraps for a few weeks, but it seems that the cat is out of the bag. Excited to announce our newest preprint!!
**Are Emergent Abilities of Large Language Models a Mirage?**
Joint w/
@sanmikoyejo
&
@BrandoHablando
1/12


Are Emergent Abilities of Large Language Models a Mirage?
Presents an alternative explanation for emergent abilities: one can choose a metric which leads to the inference of an emergent ability or another metric which does not.

24
185
973
11
48
264
❤️🔥❤️🔥Excited to share our new paper ❤️🔥❤️🔥
**Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?**
w/
@haileysch__
@BrandoHablando
@gabemukobi
@varunrmadan
@herbiebradley
@ai_phd
@BlancheMinerva
@sanmikoyejo
1/N

8
54
262
If you’re interested in deep learning (DL) and neuroscience, come to our poster at
@AI_for_Science
’s
#ICML2022
workshop
**No Free Lunch from Deep Learning in Neuroscience: A Case Study through Models of the Entorhinal-Hippocampal Circuit**
Joint w/
@KhonaMikail
@FieteGroup
1/13

8
52
241
🔥🚀Towards an Improved Understanding and Utilization of Maximum Manifold Capacity Representations🚀🔥
@vclecomte
@BerivanISIK
@dhruv31415
@carranzamoreno9
@AlyssaUnell
@KhonaMikail
@tedyerxa
&
@sanmikoyejo
@ziv_ravid
@Andr3yGR
@s_y_chung
@ylecun
1/9

5
52
226
In **Pretraining on the Test Set Is All You Need**, we launch an ambitious mission: achieve state-of-the-art results on widely used academic benchmarks using solutions that do not involve scale.
How? In two words: **DATA QUALITY**
2/6
7
17
196
Organizing for Bernie in Mountain View! Whether he's your favorite candidate or not, he drives debate on prog issues including economic inequality, social justice, climate change, universal health care, and we should encourage him to run!
#RunBernieRun
#OrganizingforBernie

13
35
153
At
#NeurIPS2023
& wondering what posters to check out?
I have 5 recommendations!! 😉
1. An Information-Theoretic Understanding of Maximum Manifold Capacity Representations
@unireps
w/
@BerivanISIK
@vclecomte
@sanmikoyejo
@ziv_ravid
& more
1/5

Excited to begin announcing our
#NeurIPS2023
workshop & conference papers (1/10)!
🔥🚀An Information-Theoretic Understanding of Maximum Manifold Capacity Representations🚀🔥
w/ amazing cast
@vclecomte
@BerivanISIK
@sanmikoyejo
@ziv_ravid
@Andr3yGR
@KhonaMikail
@ylecun
1/7
9
93
501
2
20
165
Presenting our
#NeurIPS
#NeurIPS2022
paper No Free Lunch this morning! What does the paper show, and why should you care? Many high-profile NeuroAI papers (Nature, NeurIPS, Neuron, ICLR) claim path integration (& maybe non-negativity) generically creates grid cells e.g. “We.. 1/9

3
14
137
I sadly couldn't attend
#ICML2024
but our paper received ✨Outstanding Paper ✨ at the
@TiFA_ICML2024
workshop!
📈🤔 Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive? 📈🤔
Why should you care?
1/N

1
24
135
Excited to announce our newest preprint!
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
w/
@MGerstgrasser
@ApratimDey2
@rm_rafailov
@sanmikoyejo
@danintheory
@Andr3yGR
@Diyi_Yang
David Donoho
2/N
3
17
115
Interested in mech interp of representations that deep networks learn?
If so, check out a new type of polysemanticity we call:
💥💥Incidental Polysemanticity 💥💥
Led by
@vclecomte
@kushal1t
@tmychow
@sanmikoyejo
at
@stai_research
@StanfordAILab
1/N

3
20
104
Our results challenge prevailing notion that capabilities of LLMs at solving academic benchmarks are solely determined by scaling.
Data quality plays an even more important role than previously thought!!
Preprint:
(Under review at Arxiv)
6/6

4
4
96
When do universal image jailbreaks transfer between Vision-Language Models (VLMs)?
Our goal was to find GCG-like universal image jailbreaks to transfer against black-box API-based VLMs
e.g. Claude 3, GPT4-V, Gemini
We thought this would be easy - but we were wrong!
1/N

6
22
94
A few weeks ago, Stanford AI Alignment
@SAIA_Alignment
read
@AnthropicAI
's "Superposition, Memorization, and Double Descent." Double descent is relatively easy to describe, but **why** does double descent occur?
1/8

1
12
91
Excited to share our
#ICML
#ICML2023
paper **Emergence of Sparse Representations from Noise** led by
@TrentonBricken
and supervised by Bruno Olshausen, and
@gkreiman
! 1/8
Paper:
Poster:
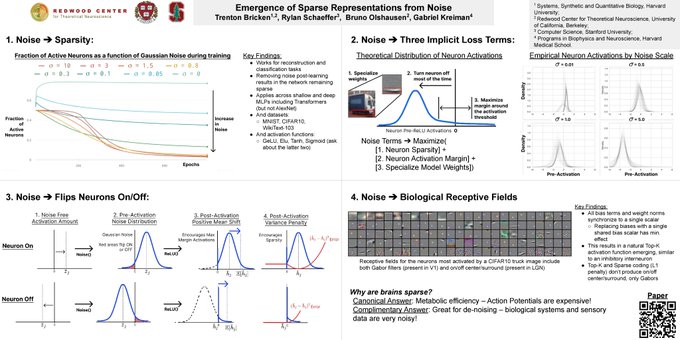
1
20
92
Across the 5
#ICML
submissions I'm a part of, my 1st observation is that reviewers this year wrote (on average) the shortest and lowest quality reviews I've ever seen, regardless of the scores given
It feels like the quality of reviews is declining & the trend is accelerating 😞
11
3
90
phi-CTNL displays two never-before-seen emergent abilities
1) phi-CTNL's loss SMASHES neural scaling laws. Its falls exponentially quickly with compute. This discovery suggests exciting new possibilities for sample-efficient pretraining
4/6

1
2
89
This may be inappropriate to share, but as general advice for research:
*Submit your work repeatedly*
The review process is too noisy otherwise. Examples from
#ICML2024
:
1 submission at 3 workshops: Reject, Accept, Best Paper
1 submission at 2: reject, accept & Invited Talk
4
7
84
Excited to announce our
#ICML2023
workshop paper: Invalid Logic, Equivalent Gains!
We find that logically **invalid** reasoning in Chain-of-Thought (CoT) prompting barely harms performance gains on **hardest** tasks in BIG-Bench
Joint w/
@KaterynaPistun1
@sanmikoyejo
& more 1/N

4
14
84
By pretraining on a small number of high quality, non-synthetic datasets, phi-CTNL (pronounced "fictional") can achieve ASTOUNDING results
These datasets are publicly available & easily accessible on a little known website called HuggingFace🤗
3/6

2
0
83
What did our COLM 2024 paper do differently? We
KEEP the full original dataset ✅
ADD new synthetic data to the overall accumulating data ✅
If we do this, i.e. data accumulate (right) no model collapse ✅
If we don't, i.e., data are replaced (left) , model collapse ❌
10/N

1
8
84
Excited to announce
🔥🤨DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models 🤨 🔥
Appearing at
#NeurIPS2023
as Datasets and Benchmarks **Oral**
Paper:
Led by
@uiuc_aisecure
@wbx_life
@ChulinXie
@danielz2333
1/N

2
18
79
My related hot-take: finetuning will soon become obsolete
More capable models won't need parameter updated with long context + long-term memory + retrieval + whatever other terms you want to throw in

Few-shot prompting will soon become obsolete. It is just a transitional step as we shift from machine learning to LLM-centered AI. Natural interactions will win out.
27
15
186
16
3
78
The question is flawed. It presumes model collapse is a real and significant threat under current best practices
Based on the evidence I've seen, it isn't
If there are other methodological questions about this Nature paper, our COLM 2024 paper or other papers, please ask!
13/N
3
7
72
2) phi-CTNL exhibits a grokking-like ability to output downstream evaluation benchmarks' canaries!!
By the 100th pass through our pretraining data mixture, phi-CTNL can PERFECTLY output any benchmark's canary
Example from BIG-Bench Hard below 👇
5/6


1
1
69
Excited to announce new preprint led by
@minhaoj_uiuc
@kenziyuliu
@IllinoisCS
@StanfordAILab
!!
Q: What happens when language models are pretrained on data contaminated w/ benchmarks, ratcheting up amount of contamination?
A: LMs do better, but curves can be U-shaped!
1/2


📢Excited to share our new paper "Investigating Data Contamination for Pre-training Language Models"!
We analyze the effects of data contamination in the pre-training stage of LMs by pre-training & studying GPT-2 models🚀.
Paper:

2
33
125
3
12
67
You've heard about SSL for vision, for language, for audio
But what about SSL for SPATIAL NAVIGATION? 🤔🧠
That's exactly what we presented at
#NeurIPS2023
yesterday!! If you missed our session , our poster is ⬇️
W/
@KhonaMikail
@FieteGroup
@sanmikoyejo
@stai_research



Interested in Grid cells 🍩, navigation in blind agents? Self-supervised learning? NeuroAI? We have a
#NeurIPS2023
paper w/co-first author
@RylanSchaeffer
and
@FieteGroup
,
@sanmikoyejo
"Self-supervised learning representations of space generates multi-modular grid cells"
1/

2
22
155
1
8
67
Let's return to the theoretical result of Shumailov et al. 2024
What if the new synthetic data is instead *added* to existing data?
Last night, I ran new simulations in their exact setting
Data replaced -> Collapse ❌
Data accumulated -> Avoided ✅
12/N

1
5
69
Our main finding is that if synthetic data is added to real data, then model collapse is mitigated
We show this holds across domains (text, vision, molecular conformation) & models (transformers, VAEs, diffusion)
We also prove this analytically in linear regression
11/N


2
8
68
For those following this Llama3-V drama, after discussing together, my friend
@cfpark1997
put in the work and found the distribution of weight deltas at almost every layer is Gaussian with mean 0 and standard deviation 1.4e-3
Is this what one should expect from finetuning?
1/2


Shocked! Llama3-V project from a Stanford team plagiarized a lot from MiniCPM-Llama3-V 2.5!
its code is a reformatting of MiniCPM-Llama3-V 2.5, and the model's behavior is highly similar to a noised version of MiniCPM-Llama3-V 2.5 checkpoint.
Evidence:



36
169
893
1
5
62
Excited to announce our paper ⬇️ was selected as an **Outstanding** paper at
@TiFA_ICML2024
🔥🔥🔥
What did the paper show?
Let's try to summarize the paper in a single tweet!!
1/3
❤️🔥❤️🔥Excited to share our new paper ❤️🔥❤️🔥
**Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?**
w/
@haileysch__
@BrandoHablando
@gabemukobi
@varunrmadan
@herbiebradley
@ai_phd
@BlancheMinerva
@sanmikoyejo
1/N
8
54
262
1
7
55
Are grid cells in deep path integrating neural networks a creation of path integration ? 🤔
Discover the answer in our preprint challenging popular misconceptions in
#NeuroAI
#neuroscience
! 🧠💻
Work w/
@KhonaMikail
@sanmikoyejo
@FieteGroup
1/N
1
13
49
Announcing
#2
in our
#NeurIPS2023
workshop & conference papers series (2/10)!!
🔎🧠Testing Assumptions Underlying a Unified Theory for the Origin of Grid Cells🔎🧠
w
@KhonaMikail
@FieteGroup
@sanmikoyejo
& Adrian Bertagnoli
Paper:
🧵👇
1/8

1
14
49
Announcing
#3
in our
#NeurIPS2023
workshop & conference papers series (3/10)!
📈📉 Divergence at the Interpolation Threshold: Identifying, Interpreting & Ablating the Sources of a Deep Learning Puzzle 📈📉
w
@sanmikoyejo
@KhonaMikail
@Andr3yGR
@FieteGroup
1/11

1
8
48
Tweeprint coming tomorrow!! ❤️🔥❤️🔥❤️🔥
Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?
Identifies a factor that induces unpredictability in multiple-choice assessments of frontier AI models

4
38
189
0
1
46
For more information, see this twitter thread and the follow-up discussions!!

I think Phi-1.5 trained on the benchmarks. Particularly, GSM8K.
🕵🏻♀️🧵

23
91
749
2
0
46
The 3rd (empirical) result keeps rand 10% of original data but replaces other 90% & uses same unrealistic decisions otherwise:
- most data is still replaced ❌
- dataset size is constant ❌
But note - by adding a little real data, they already see lower test perplexity!
9/N

1
3
48
@YangjunR
@moinnadeem
@sj_manning
@gabemukobi
Hopefully this helps! Thanks for prompting me to put this together 🙏
If there are any remaining questions, please let me know!
14/N
7
1
48
Suppose one trains a sequence of models on an accumulating dataset, with new data labeled or generated by the most recent model.
How does the bias of the original dataset evolve over time? 🤔
A short extended abstract appearing at
#NeurIPS2023
's
@afciworkshop
🧵⬇️
1/N

2
9
46
Happy to announced my
#NeurIPS
#Metacognition
workshop submission was accepted! It's a really simple idea that might explain some longstanding puzzles and produce better AI agents! 1/N

4
5
46
The 2nd (empirical) result:
- throws away all data after each iteration (not what people do in practice❌)
- uses fixed dataset size (again, not what is done in practice ❌)
8/N

1
2
46
Woke up to find out our paper was accepted at
@COLM_conf
!!
📉📉 Is Model Collapse Inevitable? 📉📉
No! Model collapse is largely avoided if data accumulate over model-fitting iterations
Previous papers found model collapse by discarding all data after each iteration
1/2

2
8
46
For those in
#NeuroAI
at
#NeurIPS2023
, I am struggling to understand why the neural regression methodology is still accepted without question
Here's why:
2 yr ago, a
#NeurIPS
2021 Spotlight claimed deep path integrators explained MEC neural data up to the noise ceiling
1/3

3
9
44
@MGerstgrasser
@ApratimDey2
@rm_rafailov
@sanmikoyejo
@danintheory
@Andr3yGR
@Diyi_Yang
@EldanRonen
@dohmatobelvis
@feeelix_feng
Our results suggest that model collapse may be avoided in a pessimistic hypothetical future where synthetic data are uncontrollably dumped on the internet to be vacuumed up for training the next iteration of generative models
8/N
1
2
43
Model collapse arose from asking: what happens when synthetic data from previous generative models enters the pretraining data supply used to train new generative model?
I like Shumailov et al.'s phrasing:
"What happens to GPT generations GPT-{n} as n increases?"
2/N

1
3
44
If I had to choose the single biggest advance in theoretical & computational neuroscience from the past year, I think this project would be a strong contender for that title
Congratulations
@sugsharma
&
@FieteGroup
❤️🔥🎉✨

Finally a tweeprint on our recent preprint presenting Vector-HaSH !
Vector-HaSH extends MESH to unify two important and seemingly independent roles of hippocampus: Spatial Mapping and Episodic Memory !
Brief talk:
Preprint:
1/n

2
25
122
1
5
40
Note - at each iteration, all prior data is thrown away ‼️
For the 2nd and 3rd (empirical) results, both similarly assume that (all or most) data is thrown away
7/N
1
1
42
People are worried that widespread public usage of generative models might destroy future models, e.g.,
Because of the Nature paper, we were repeatedly asked by journalists: "How can we (humanity) make sure to avoid model collapse?"
13/N

2
3
42
New preprint & tweeprint coming soon! In the interim, a story:
For Fig1, I used a random ImageNet image. Legal told us that was unacceptable and recommended we instead use an image that one of the authors had taken & had rights to
1/2


4
3
40
I sadly couldn't attend
#ICML2024
but I'm excited to announce some workshop papers!!
⚡️In-Context Learning of Energy Functions⚡️
With
@KhonaMikail
&
@sanmikoyejo
Appearing at 1st ICML Workshop on In-Context Learning
1/N
2
2
39
Being an
#ICML2024
Best Reviewer is bittersweet
It doesn't feel good to make a honest effort to try to help others improve their papers and then read our ICML 2024 reviews that I felt were (on average) the worst reviews I've experienced thus far
1/2

Across the 5
#ICML
submissions I'm a part of, my 1st observation is that reviewers this year wrote (on average) the shortest and lowest quality reviews I've ever seen, regardless of the scores given
It feels like the quality of reviews is declining & the trend is accelerating 😞
11
3
90
3
0
38
@gautamcgoel
I'm a PhD student at Stanford CS and I make $44k a year. If you want a laugh, this was my experience with finding housing
1
2
38
How do mouse brain-wide population codes perform hierarchical inference? If you're interested in Bayesian inference/recurrent networks/testing predictions in Neuropixels recordings, come to our
#SfN21
#SfN2021
poster today at 11:30 AM PT!
Joint w/
@IntlBrainLab
#neuroscience

0
8
37
@MGerstgrasser
@ApratimDey2
@rm_rafailov
@sanmikoyejo
@danintheory
@Andr3yGR
@Diyi_Yang
Many prior works consider training models solely on data generated by the preceding model i.e. data are replaced at each model-fitting iteration. Replacing data leads to collapse, but isn’t done in practice.
What happens if data instead accumulate across each iteration?
3/N

1
2
37
@AI_for_Science
@KhonaMikail
@FieteGroup
Prior work claims that training artificial networks (ANNs) on a path integration task generically creates grid cells (a). We empirically show and analytically explain why grid cells only emerge in a small subset of hyperparameter space chosen post-hoc by the programmer (b). 3/13

1
11
36
@MGerstgrasser
@ApratimDey2
@rm_rafailov
@sanmikoyejo
@danintheory
@Andr3yGR
@Diyi_Yang
We pretrain sequences of transformer-based language models on TinyStories by
@EldanRonen
& Yuanzhi Li.
If data are replaced at each model-fitting iteration, then the models worsen over time - collapse!
But if data accumulate, collapse is avoided!
4/N

2
0
36
Thank you
@unireps
for hosting such a wonderful and interesting workshop at
#NeurIPS2023
!!

📢Rylan Schaeffer is presenting
"An Information-Theoretic Understanding of Maximum Manifold Capacity Representations" Honorable Mention Extended Abstract 🏆 at UniReps🔵🔴
@RylanSchaeffer
@ylecun
#NeurIPS2023
#unireps

0
3
24
0
2
37
@vclecomte
@BerivanISIK
@sanmikoyejo
@ziv_ravid
@Andr3yGR
@KhonaMikail
@ylecun
MMCR is a new high-performing self-supervised learning method at
#NeurIPS2023
by
@tedyerxa
@s_y_chung
@KuangYilun
@EeroSimoncelli
that SLAYS at ImageNet1k 🚀🚀🚀
MMCR: Data -> K transforms per datum -> Embed -> Average over K transforms -> Minimize negative nuclear norm
2/7

1
1
35
Compute-optimal scaling laws as studied by Chinchilla held the data distribution fixed (can't blame them - these runs aren't cheap).
@khoomeik
's paper contributes to a better understanding of data-dependent scaling ❤️🔥
Check it out 👇

📢 Excited to finally be releasing my NeurIPS 2024 submission!
Is Chinchilla universal? No! We find that:
1. language model scaling laws depend on data complexity
2. gzip effectively predicts scaling properties from training data
As compressibility 📉, data preference 📈.
🧵⬇️

17
115
823
2
4
34

@AI_for_Science
@KhonaMikail
@FieteGroup
Takeaway: It is highly improbable that a path integration objective for ANNs would have produced grid cells as a novel prediction, had grid cells not been known to exist. Thus, our results challenge the notion that DL offers a free lunch for Neuroscience 11/13

1
3
31
@vclecomte
@BerivanISIK
@sanmikoyejo
@ziv_ravid
@Andr3yGR
@KhonaMikail
@ylecun
@tedyerxa
@s_y_chung
@KuangYilun
@EeroSimoncelli
MMCR originates from the statistical mechanical characterization of the linear separability of manifolds, building off foundational work by
@s_y_chung
@UriCohen42
@HSompolinsky
But what is this MMCR computational graph actually doing?
3/7

1
2
31
@MGerstgrasser
@ApratimDey2
@rm_rafailov
@sanmikoyejo
@danintheory
@Andr3yGR
@Diyi_Yang
@EldanRonen
@dohmatobelvis
@feeelix_feng
@___rajashree___
@tomekkorbak
@sleight_henry
@McHughes288
@dhruv31415
@stai_research
@StanfordAILab
@UofMaryland
@MIT
@sequoia
@StanfordData
@OpenAI
@NSF
@SloanFoundation
@GoogleAI
As a caveat, to be very explicit, when we say accumulating synthetic data does not hurt AI systems, we do not mean that all synthetic data is broadly/generally good for AI systems
10/N
2
2
32
@AI_for_Science
@KhonaMikail
@FieteGroup
Prospective Answer: Deep networks may appear to be better models of biological networks because they provide higher-dimensional bases than alternative models, and thus trivially achieve higher correlation scores for linear regression-based comparisons. 13/13

4
4
32
For anyone familiar with training reward models, any ideas why the loss spikes at the end of the first epoch / beginning of the second epoch?

11
3
33
100% agree. The field should question the neural regressions methodology more seriously
Our NeurIPS2022 paper showed a NeurIPS2021 Spotlight reached wrong conclusion w/ extremely high confidence based on neural regressions
People should investigate!!

Essentially LLMs don't explain parts of the language centers of the brain, they are just correlated to the neural activation of the brain & almost any model will show correlations with the brain if you looked hard enough but that doesn't explain much about what is going on.
2
0
30
0
0
31

@MGerstgrasser
@ApratimDey2
@rm_rafailov
@sanmikoyejo
@danintheory
@Andr3yGR
@Diyi_Yang
@EldanRonen
The same results qualitatively hold for VAEs trained on images and diffusion models trained on molecular conformation generation. Replacing data leads to collapse, but accumulating data avoids collapse!

3
0
30
Code is now 🚀 public 🚀 for our preprint:
🖼️🤖🤔When do universal image jailbreaks transfer between vision-language models? 🖼️🤖🤔
Spoiler: they don't ❌ (as best as we can tell)
Code:
Paper:
Tweeprint:

When do universal image jailbreaks transfer between Vision-Language Models (VLMs)?
Our goal was to find GCG-like universal image jailbreaks to transfer against black-box API-based VLMs
e.g. Claude 3, GPT4-V, Gemini
We thought this would be easy - but we were wrong!
1/N
6
22
94
1
9
32
3. Quality of data: 📈 models are better performing, users mainly share higher quality outputs, pretraining data teams make better filters
4. Data Accumulates: 📈 This may seem obvious, but synthetic data from GPT4, Claude, Gemini, etc. is *added* to existing data (‼️)
4/N
1
1
31
💥💥SELF-SUPERVISED LEARNING OF SPATIAL REPRESENTATIONS GENERATES MULTIMODULAR GRID CELLS 💥💥
What does that even mean⁉️ 🤔
w/
@KhonaMikail
@FieteGroup
@sanmikoyejo
Work at
@mitbrainandcog
@stai_research
@StanfordAILab
1/N
Interested in Grid cells 🍩, navigation in blind agents? Self-supervised learning? NeuroAI? We have a
#NeurIPS2023
paper w/co-first author
@RylanSchaeffer
and
@FieteGroup
,
@sanmikoyejo
"Self-supervised learning representations of space generates multi-modular grid cells"
1/
2
22
155
2
4
29
Let's now turn to the Nature 2024 paper on Model Collapse
The 1st (theoretical) result studies repeatedly:
1. fitting means and covariances to data
2. sampling new data from Normal(fit mean, fit cov)
Result: iteratively doing this causes fit covariance to collapse to 0
6/N

1
3
31
Let's identify realistic pretraining conditions for frontier AI models to make sure we study the correct setting
1. Amount of data: 📈 Llama went from 1.4T tokens to 2T tokens to 15T tokens
2. Amount of chips: 📈 Llama went from 2k to 4k to 16k GPUs
3/N

llama1: 2048 gpus
llama2: 4096 gpus
llama3: 16384 gpus
llama4: .....
You see where we are headed! Gonna be insane ride!
2
4
92
1
2
31
Based on my early subjective experimentation, I'm very excited to announce that
#GPT
-4o is **extremely fast** at producing text that doesn't answer my questions or solve my problems
1
3
29
To be clear, we're concerned what will happen to frontier AI models pretrained on web-scaled datasets using industry best-practices
Thus, we want to study settings w/:
1. more data over time
2. Data for training a new model contains (much of) the original data
5/N
1
1
30
@moinnadeem
@YangjunR
@alexandr_wang
Roger that! Give me a day to draft something and run it by my coauthors to make sure it's well phrased 😁
1
0
28
@DrJimFan
This is a good question, but the wrong answer, I think. The right answer is that predicting all of humanity's data requires learning the original tasks *and also learning human error patterns*. If you can predict when and in what manner a human will err, you're smarter.
1
0
26
@YangjunR
@alexandr_wang
No, they don't. Read their actual methods.
If it'd be helpful, I can provide a step-by-step breakdown.
1
0
27
Thank you
@MIT
for covering our
#NeurIPS2022
paper demonstrating the need for a circumspect use of deep neural networks in modelling the brain!
Joint w/
@KhonaMikail
&
@FieteGroup
, work done at
@mitbrainandcog
@mcgovernmit
@StanfordAILab
1/2

2
9
26
1
1
26
If you’re interested in continual learning, lifelong learning, unsupervised learning on streaming data or neuroscience, come to our
#ICML2022
talk & poster *Streaming Inference for Infinite Feature Models* today! Joint with
@du_yilun
@FieteGroup
1/12

1
2
26
@MGerstgrasser
@ApratimDey2
@rm_rafailov
@sanmikoyejo
@danintheory
@Andr3yGR
@Diyi_Yang
@EldanRonen
Why does this happen? We turn to an analytically tractable setting: sequences of linear models
Previous work by
@dohmatobelvis
@feeelix_feng
& Julia Kempe showed if data are replaced at each iteration, test loss climbs linearly with the number of iterations
6/N

1
0
25

@MGerstgrasser
@ApratimDey2
@rm_rafailov
@sanmikoyejo
@danintheory
@Andr3yGR
@Diyi_Yang
@EldanRonen
@dohmatobelvis
@feeelix_feng
We extend the analysis to show that if data instead accumulate, the test loss is upper bounded by a small constant.
Even in this toy setting, replacing data leads to collapse, but accumulating data avoids collapse!
7/N

1
1
24
@MGerstgrasser
@ApratimDey2
@rm_rafailov
@sanmikoyejo
@danintheory
@Andr3yGR
@Diyi_Yang
@EldanRonen
@dohmatobelvis
@feeelix_feng
This was such a fun collaboration w/
@___rajashree___
@tomekkorbak
@sleight_henry
@McHughes288
@dhruv31415
Work done at
@stai_research
@StanfordAILab
@UofMaryland
@MIT
@sequoia
w/ 🙏🙏🙏 to support from
@StanfordData
@OpenAI
Superalignment
@NSF
@SloanFoundation
@GoogleAI
9/N
3
0
23
This new
#NeurIPS2023
SSL paper by
@tedyerxa
@s_y_chung
@EeroSimoncelli
@KuangYilun
is awesome
math + new SSL method + high performance + good neural predictivity + geometric analysis of networks
Anyone interested in SSL and/or NeuroAI should definitely read it 💥

Excited to share our results on Efficient Coding of Natural Images using Maximum Manifold Capacity Representations, a collaboration with
@KuangYilun
@EeroSimoncelli
and
@s_y_chung
to be presented at
#NeurIPS2023
1/n

2
25
137
0
1
24
#ICML2023
was an amazing experience. So many science & engineering discussions, so many new friends, so good to see old friends. Eager to get to work on all the amazing new ideas!

0
2
22
"Overall this work is well written, the experiments are well designed and result are visualized in a clear way. This is very interesting work and is highly relevant"
"3: Clear rejection"
It turns out the rubric changed during the review process, but imagine my surprise 😂
1
1
21
I forgot to mention! A preliminary version appeared at some wonderful NeurIPS workshops which might be returning this year!!
Unireps by
@unireps
NeurReps by
@neur_reps
InfoCog
SSL

❤️🔥❤️🔥Work done with amazing collaborators
@stai_research
@StanfordData
@StanfordAILab
@NYUDataScience
@mitbrainandcog
@mcgovernmit
@AIatMeta
@NYU_CNS
@FlatironCCN
❤️🔥❤️🔥
Paper:
9/9

0
1
10
0
4
22