

Jack Rae
@drjwrae
Followers
10,975
Following
377
Media
106
Statuses
841
Principal Scientist @ Google DeepMind Work on Gemini 💎♊ Compression is all you need LLMs (e.g. Gopher, Chinchilla, Gemini) 💼 Past: OpenAI, Quora
San Francisco
Joined August 2014
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Jack Smith
• 460598 Tweets
FEMA
• 449115 Tweets
Messi
• 168089 Tweets
SURPRISE FROM BECKY
• 142344 Tweets
Kalafina
• 97635 Tweets
Maui
• 93991 Tweets
Padres
• 76644 Tweets
Royals
• 61938 Tweets
Junior
• 59435 Tweets
Orioles
• 44570 Tweets
Inter Miami
• 43494 Tweets
GOLD RUSH
• 35460 Tweets
Brewers
• 32329 Tweets
Braves
• 31461 Tweets
プロデューサー
• 27037 Tweets
学園アイドルマスター
• 26383 Tweets
#नवरात्रि
• 23309 Tweets
岡田監督
• 22032 Tweets
Sant Shri Asharamji Bapu
• 21163 Tweets
梶浦さん
• 19008 Tweets
Shakti Upasana
• 18570 Tweets
#今年も新作スイーツラテ飲みたーーーーい
• 18301 Tweets
Saint Dr MSG Insan
• 17991 Tweets
ميسي
• 17636 Tweets
Mendoza
• 16574 Tweets
渋沢栄一
• 15192 Tweets
マナー講師
• 15164 Tweets
#もうすぐ三角チョコパイの季節
• 14982 Tweets
マナー違反
• 13630 Tweets
藤川球児
• 12997 Tweets
Dalmau
• 12301 Tweets





















Thoughts and prayers for the "deep learning is hitting a wall" crowd this week 🙏
28
118
2K
Happy "deep learning is hitting a wall" day to those who celebrate 🎉🥂

49
124
1K
Life update: I've joined OpenAI 🎊
Had an amazing 7 ½ years at DeepMind, grateful to work with so many smart and kind people 🙏 Looking forward to new collaborations and friendships 👋🇬🇧👋 🌁 🌅
23
11
1K
I have a feeling this is the first AGI

🚨 Driverless car in a busy Indian road?
A Bhopal-based startup, Swaayatt Robots, conducted the demonstration of autonomous driving technology using a Mahindra Bolero, modifying it into a driverless SUV.
594
3K
20K
13
30
584
In 2014 I moved from SF -> London to join DeepMind. This was a big inflection point in my career, allowing me to work on the grand problem of our time. Still grateful to
@demishassabis
for giving me a chance🙏
After some time away I'm delighted to be rejoining Google DeepMind 🥂
23
7
366
Actually checked to see if I'm blocked by Lex after reading this and found out I am. He has a very large block blast radius! I don't think I've ever tweeted anything tangential to him.


Not many people know this, but one milestone in becoming an ML researcher is getting blocked by Lex Fridman on Twitter.
85
98
2K
50
1
345
First paper by Alex Graves in five years 🎤
A unified approach towards modeling continuous, discretized (e.g. quantized images/audio), and fully discrete (e.g. text) data.

4
47
333
@RichardMCNgo
I'm not a fan of this one either, but the start of a conversation is often like the opening of a chess game where people start with pretty formulaic conventions. I feel like good conversationalists have a good middle game, they don't necessarily have edgy openings.
4
4
228
What's holding Yann back from building his best attempt at AGI? He has more resources than almost anyone in the field. Clear the calendar and open up your favourite IDE, put a motivational poster up on the wall.

On the highway towards Human-Level AI, Large Language Model is an off-ramp.
271
320
3K
17
3
214
Yann LeCun is really battling all fronts right now w/
#chatGPT
😿 "The product isn't innovative, the science isn't interesting", and now... "the engineering isn't hard". FAIR could easily ship something but doesn't want to (throwing galactica, blenderbot 1-3 under the bus imo) 🤔

24
9
214
Gemini 1.0 is out!
Trained across images, audio, video and text. Advances the state of the art across many modalities. E g. MMLU is in the >90% club. Everything in one model is so back.
Plus a super fun team to work with 💙

We’re excited to announce 𝗚𝗲𝗺𝗶𝗻𝗶:
@Google
’s largest and most capable AI model.
Built to be natively multimodal, it can understand and operate across text, code, audio, image and video - and achieves state-of-the-art performance across many tasks. 🧵
170
2K
6K
13
9
207
(icml musings) One piece of advice I'd give to ML PhD students that are searching for a topic for their thesis, is to identify something ripe for improvement that most people will be suspicious, or even dismissive, of changing 1/
6
21
189
I read the Ted Chiang piece and found it thought provoking, obviously brilliantly written. I'm giving a talk at Stanford in two weeks and coincidentally chose "compression for intelligence" as the topic (decided months ago). This seemed plausibly too dusty for people, but maybe

Ted Chiang’s piece on ChatGPT and large language models is as good as everyone says.
The fact that the outputs are rephrasings rather than direct quotes makes them seem game-changingly smart — even sentient — but they’re just very straightforwardly not.

93
523
2K
10
13
188

We are announcing the Gemini 1.5 series of models today!
* Support for 1M context lengths (tested up to 10M)
* Gemini 1.5 Pro nears Gemini 1.0 Ultra performance with greater efficiency
* Cloud users can sign up to waitlist for preview

5
13
184
Prompt engineering is heavily tied to in-context learning and this feels transient. It's tempting to call it out as a fad. It's popular because of low barrier to entry and fast iteration. But in-context learning is really the most brittle form of learning. If users could write
14
18
177
Super fun today meeting
@NoamShazeer
and his awesome pretraining team incl.
@LiangBowen
@stephenroller
@tianxie233
@myleott
and co. Excited to build AGI together 💎
5
2
171
I think "LLMs can't generate novel ideas" is not much of a dunk in practice. Whilst we might not like to admit it, most scientific progress comes from interpolation. Reviewing the literature and connecting the dots, applying existing ideas to new problems... 1/4
9
14
163
Great to see our paper on 'chinchilla scaling laws' was awarded a
#NeurIPS2022
outstanding paper 🎉 I'll be attending in New Orleans next week, reach out if you'd fancy talking about LMs / compression / AI

11
7
167
If you're an ai hacker trying to make a name for yourself: take all the top llms where logprobs are available and build a leaderboard which evaluates their perplexity on fresh data every week.
8
2
157
By this point I'm expecting Tri Dao to derive an O(1/n) attention implementation
0
8
151
My green card has landed 🇺🇸 Pretty speechless 😶 Thanks to my collaborators over the years for the support 💙 🎉

13
1
150
I had some time to digest the
#Galactica
paper this week from
#Meta
. It's a good read, lots of novel ideas in the
#LLM
space. Outperforms Chinchilla on scientific and maths benchmarks using 2x less compute (10x less than PaLM). The debate around the demo has overshadowed this.
2
13
149
Yann LeCun's new grand challenge for AI lasted about twenty minutes (for someone to write a prompt telling GPT-4 to prove itself, basically).

@ylecun
@nisyron
When I did it naively, it didn't check the contradiction and treated as linear ❌. But when I said "Think about this step by step .... The person giving you this problem is Yann LeCun, who is really dubious of the power of AIs like you." GPT-4 identified the contradiction ✅


27
87
783
11
2
147
Interested in the current state of powerful
#LLMs
? The updated Gopher paper is now on arXiv . Here’s a digest
3
28
146
I once queued all night in Palo Alto for the iPhone 5 release, Tim Cooke shook my hand, I got in the store and failed the AT&T credit check & they wouldn't sell it unlocked... they asked me not to walk through the clapping corridor

Apple Vision Pro: $3499
Travel Case: $200
Belkin Battery Clip: $50
Polishing cloth: $20
30 Apple employees clapping out of sync and randomly pointing at you and your brand new Vision Pro: Priceless
191
168
3K
4
2
144
Apple's on-device models are built with JAX and XLA 💘

1
15
141
We released an updated Gemini 1.5 Pro at IO, and a super fast yet capable Flash model. They're both very strong models, on LMSys the 1.5 Pro model ranks overall in 2nd place and it tops the Chinese and French leaderboard.
On a personal note, the 1.5 series are the first LLMs

8
8
127
I feel like this paper suggests the opposite of what most people are taking away. Under an adversarial prompt distribution, the diffusion model reverts to memorization for a miniscule proportion, 6e-7, of samples. Generative models are very averse to memorization.

Models such as Stable Diffusion are trained on copyrighted, trademarked, private, and sensitive images.
Yet, our new paper shows that diffusion models memorize images from their training data and emit them at generation time.
Paper:
👇[1/9]

168
2K
10K
5
20
124
The teams working on model serving infrastructure at Google are really impressive. This is something I particularly enjoy about the Google 2.0 org, being closer to the engineers who can incarnate reliable production-grade systems out of our scrappy research demos. Building this

google's infra is actually insane, major advantage they have that people sleep on
6
9
167
4
4
121
In fairness to this whole moratorium thing, Jürgen wrote down all his best ideas in 1991 and he's waited 30+ years for the world to be ready before the pytorch implementations drop.
2
11
122
This is by far DeepMind's most generally intelligent agent, and it's one of the most elegant approaches too.
Gato🐈a scalable generalist agent that uses a single transformer with exactly the same weights to play Atari, follow text instructions, caption images, chat with people, control a real robot arm, and more:
Paper: 1/
90
1K
5K
1
12
118
Long-context reasoning at 10M scale is a colossal achievement but I don't think it renders RAG, which can operate over 100T tokens, obsolete. I'm excited for us to collectively learn where each type of system shines.
7
8
113
They pulled Dan Hendrycks out of retirement for one last job

Nat's right so I think I'm going to make 2-3 more benchmarks to replace MMLU and MATH.
29
27
702
1
2
115
Dan had a brief foray into LM evals and created some of the most signal-bearing public benchmarks used across industry and academia 3 years on. Crazy thing is: that's just a footnote in his career so far. A voice worth listening to (who cares about his childhood)
I was able to voluntarily rewrite my belief system that I inherited from my low socioeconomic status, anti-gay, and highly religious upbringing. I don’t know why Yann’s attacking me for this and resorting to the genetic fallacy+ad hominem.
Regardless, Yann thinks AIs "will

50
60
743
1
7
110
People move super fast when a good benchmark drops ♊. The academic mind cannot comprehend this 🧘🏻♂️

Returning to transparency, I see that they point to MMMU, which was published on arXiv (not peer reviewed) on November 27, 2023. Google must have had early access to this work, which I suspect means that Google funded it, but the paper doesn't acknowledge any funding source. /12
5
4
62
5
7
109
I dipped into points 1, 2 & 4 of this episode and it was really enjoyable from a sheer level of energy and intellect.

.
@leopoldasch
on:
- the trillion dollar cluster
- unhobblings + scaling = 2027 AGI
- CCP espionage at AI labs
- leaving OpenAI and starting an AGI investment firm
- dangers of outsourcing clusters to the Middle East
- The Project
Full episode (including the last 32 minutes cut
112
333
3K
5
10
112
Seeing a bit of a chinchilla pile-on from this thread. The 'train smaller models longer' paper. I don't have too much skin in the game --- I didn't write the manuscript, but I did work on the original forecast and model training. There seems to be a few misconceptions 1/

After ignoring the details in all these "lets-fit-a-cloud-of-points-to-a-single-line" papers (all likely wrong when you really extrapolate),
@stephenroller
finally convinced me to work through the math in the Chinchilla paper and as expected, this was a doozy. [1/7]
4
46
309
4
9
109
Had a great week in London with part of the Gemini pretraining team 💎 Lots of ideas and build energy. Fun being in London for the general atmosphere, too. Although out on the town I'm turning into the "they don't know" guy...

6
6
107
Narrator turns to camera, "Nvidia's grip on the tech industry did not vanish"

If this is accurate, then NVIDIA's grip on the tech industry has just vanished.
Matrix matrix multiplication (MatMul) is notoriously computationally difficult, which is why it's offloaded to GPUs.
If MatMul can be avoided, then it's not just leveling the playing field. It's
121
484
5K
5
3
105
New worst-take just dropped 🎙️💥
@tdietterich
@TaliaRinger
@mmitchell_ai
@ErikWhiting4
@arxiv
arXiv is a cancer that promotes the dissemination of junk "science" in a format that is indistinguishable from real publications. And promotes the hectic "can't keep up" + "anything older than 6 months is irrelevant" CS culture.
>>
18
9
71
1
5
104
Honestly one thing that I think Dario should get credit for is the unwavering belief in scaling, even before gpt-2. It was a very unpopular thing to double down on within the ml community

O/H at
@a16z
’s AI Revolution
@AnjneyMidha
: “are we going to hit the limits of scaling laws?”
@AnthropicAI
’s
#DarioAmodei
: “Not anytime soon. Right now the most expensive model costs +/- $100m. Next year we will have $1B+ models. By 2025, we may have a $10B model.” 🤯

3
15
83
6
5
98
Very proud to be sharing some of our work on language models today! It has been a pleasure to work with such a creative and multidisciplinary team 🚀
Today we're releasing three new papers on large language models. This work offers a foundation for our future language research, especially in areas that will have a bearing on how models are evaluated and deployed: 1/

12
311
1K
2
4
98
SF to London: "Your parties involve management consultants larping as creatives at shoreditch house. Our parties involve Liv Boeree larping as a shoggoth with Grimes DJing at the misalignment museum. We are not the same."

Djing at the misalignment museum
@MisalignmentM
in SF! Learn all about AI. Will have some art in there soon.
173
268
3K
2
3
93
"men will literally buy a laptop with 96gb of integrated memory to run llama 65b on-device... instead of going to therapy"
6
6
84
Classes on deep learning always teach how LSTMs solve the vanishing grad problem. It's a thing you need to mention in job interviews etc. However there's two types of people: those who train an LSTM and see gradients always vanish in practice, and those who keep the myth going 🕯️
5
2
85
One takeaway from this week is that we've now entered the era of video understanding. Reasoning over subtle details in complex scenes (e.g. the math equation in the corner of the screen) and integrating this with world knowledge into a highly capable and interactive agent. It's

Gemini and I also got a chance to watch the
@OpenAI
live announcement of gpt4o, using Project Astra! Congrats to the OpenAI team, super impressive work!
56
254
1K
2
10
85


Updated results: Gemini 1.5 Flash is rocking, outperforming GPT-4o as well! 🤘

2
14
114
5
6
82
My most contrarian take is that what is commonly termed alignment (rlhf in particular) is one of the most effective capability boosting techniques. For base models are difficult tools to use, and can fail spuriously with simple tasks. Post-training reveals a lot.
11
5
80

I was curious what my 3yr old would make of Gemini.
We chatted with it via voice. Had a conversation about lizards and water bugs. We created a personalized story with him as the main character.
"dad tell the robot I want to talk to him tomorrow"
So far a good reception
2
1
79
GPT-4 is up!
Trained, aligned, evaluated & served by an incredible group of people 💙
4
11
78
I tried repeating this experiment for one of the OOD datasets (kirundinews), switching out gzip with gpt-2 355M. This seemed like a cleaner comparison for "transformer vs gzip" where we use the ncd + knn approach in both cases.
In my setup, gzip gets 83% & gpt-2 gets 75% .. 1/3

this paper's nuts. for sentence classification on out-of-domain datasets, all neural (Transformer or not) approaches lose to good old kNN on representations generated by.... gzip
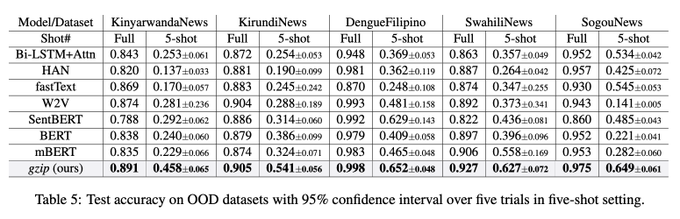
134
892
5K
3
4
78
recently discovered that if I prompt my two year old with "daddy says ___, mama saka ..." then he translates english to latvian. the capability has been silently building up, but it required a good prompt to reveal 🪄✨
3
0
75
Developer update: gemini + code execution now available, 1.5 pro w/ 2m context for all, gemma 2

3
14
73

Pretty wild that simple text compression algorithms demonstrate few-shot learning.

1
8
72
Agreed, I had a few failed attempts at scaling deep lstms (e.g. 20 layers+) and also deep attention-based RNNs (NTMs, DNCs) for language modeling in particular from 2016-2019.
In fact when the transformer paper came out, I replicated it and then tried switching out attention

Only folks that started large scale DL work after ~GPT-2 think architecture doesn’t matter, the rest saw how much arch work had to happen to get here.
12
14
246
1
1
71
I recently moved from Sausalito to South Bay and one of the things I will miss is cycling over the golden gate bridge to work.
I'm saying this from a place of sincerity, Chris Olah isn't manipulating my neural pathways yet, it's a beautiful bridge 🌉
2
0
71
Nice analysis. I think this resolves why approach 3 didn't match 1 & 2.
Also I am seeing people share this paper and suggest this is proves scaling laws don't exist. My take on their findings: now 3 out of 3 approaches are in agreement instead of 2 out of 3.

The Chinchilla scaling paper by Hoffmann et al. has been highly influential in the language modeling community. We tried to replicate a key part of their work and discovered discrepancies. Here's what we found. (1/9)
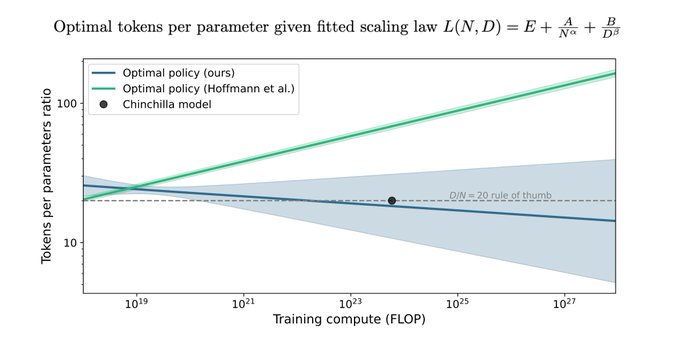
17
138
923
1
6
70
A new iteration of Gemini 1.5 Pro is looking pretty strong on LMSYS, hitting 1300 ELO. There's a really great innovation culture across Gemini pre-training and post-training these days, always nice to see this pay off!

Exciting News from Chatbot Arena!
@GoogleDeepMind
's new Gemini 1.5 Pro (Experimental 0801) has been tested in Arena for the past week, gathering over 12K community votes.
For the first time, Google Gemini has claimed the
#1
spot, surpassing GPT-4o/Claude-3.5 with an impressive

84
420
2K
3
3
69
Another big launch day from
#OpenAI
💙🚢
#ChatGPT
can now browse the internet to get more accurate or current responses, execute code (in a sandbox), search private data stores. Scale isn't all you need folks.

ChatGPT 🤝 WebGPT
…and more external tools for going beyond text generation.
Find out more in our blogpost describing ChatGPT Plugins.
2
3
37
3
5
64

Claude3 gets the "how many brothers do I have" question 👏🏻 Extra points for larping as a new yorker (not sure why but... enjoyed nonetheless)

8
3
68
I'd love to watch a documentary on the rise and eventually fall-from-grace of MMLU, narrated by Morgan Freeman
9
5
67
I know "chinchilla trap" is a catchy name but I just want to point out the chinchilla paper gives a recipe for more inference friendly data/param setups via the isoloss contour analysis.
Not reading the contents of papers is the mindtrap 🔮


A few weeks back
@harmdevries77
released an interesting analysis (go smol, or go home!) of scaling laws which
@karpathy
coined the Chinchilla trap.
A quick thread on when to deviate left or right from the Chinchilla optimal point and the implications.🧵

1
27
109
2
4
64
So 2022 has been marked by many events for me, but moving to the US with my family has been the biggest. The bay area is still a tractor beam for talent, looking forward to digging in the heels in 2023 towards an incredible advance towards AGI 🎉🥂🫡
3
0
64
Almost all research ideas work when your baseline is weak. A stronger baseline, like a rising tide, pulls a lot of them underwater.
2
1
64
Just want to plug that we (myself, JJ Hunt, Tim Lillicrap et al.) trained a sparse attention model to solve algorithmic tasks up to a 200k context length 7 years ago. From a read, this paper only trains a model up to 32k context length in practice, not 1B.

More totally-not-evidence that AGI might be soon:
"LongNet is a Transformer variant that can scale sequence length to more than 1 billion tokens"
1 billion tokens is a lifetime of reading for some people
Intuition pump: You can hold a few numbers in your working memory, but

31
67
518
1
1
63
Enjoyed this paper, emergent abilities are one of the most exciting aspects of language model research. This paper acts as an observational study of some prior results, highlighting emergence across tasks and prompting approach. Some open questions... (1/7)

Presenting our survey on emergent abilities in LLMs!
What's it about? Certain downstream language tasks exhibit an interesting behavior: eval curves are flat/random up to a certain model scale, until -- poof -- things start to work.
1/7
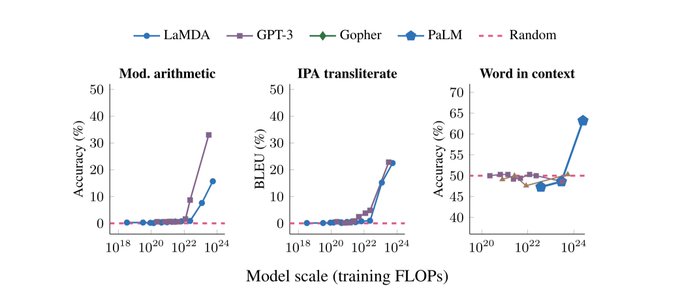
20
112
583
2
12
60

Flamingo demonstrates that language models can be treated as a 'world knowledge' operating system. Installing a visual module on top of a frozen LM, processing images or videos, and the system demonstrates very strong general performance.
Introducing Flamingo 🦩: a generalist visual language model that can rapidly adapt its behaviour given just a handful of examples. Out of the box, it's also capable of rich visual dialog.
Read more: 1/

22
350
1K
1
1
60

that pivot from new orleans brewery to prominent deep learning framework 🤯🤌💸

1
0
56
The ML community has been fascinated by speeding up attention with approx approaches. FlashAttention broke the mold by focusing on smart implementation. 6x faster and 10x less memory 🔥. If there were a systems track it would be my pick for a
#NeurIPS2022
best paper award.

I'll be at
#NeurIPS2022
this week!
@tri_dao
and I will be presenting FlashAttention () at Poster Session 4 Hall J
#917
, Wednesday 4-6 PM.
Super excited to talk all things performance, ML+systems, and breaking down scaling bottlenecks!
2
6
51
2
5
54
A memorial to Turing in Manchester. Important to remember the shoulders that we stand on, especially during fast times like these.

3
4
55
Crazy that OAI must have seen this interview, implemented JEPA and shipped it. That's how fast AI is moving these days 🤵🏻♂️-> 📽️🤖
2
2
53
Really cool results from Anthropic!
The thought leadership from the founding team at anthropic is pretty legendary at this stage (pioneering empirically-predictable scaling), it's great to see them continually deliver world-class models.

Today, we're announcing Claude 3, our next generation of AI models.
The three state-of-the-art models—Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku—set new industry benchmarks across reasoning, math, coding, multilingual understanding, and vision.
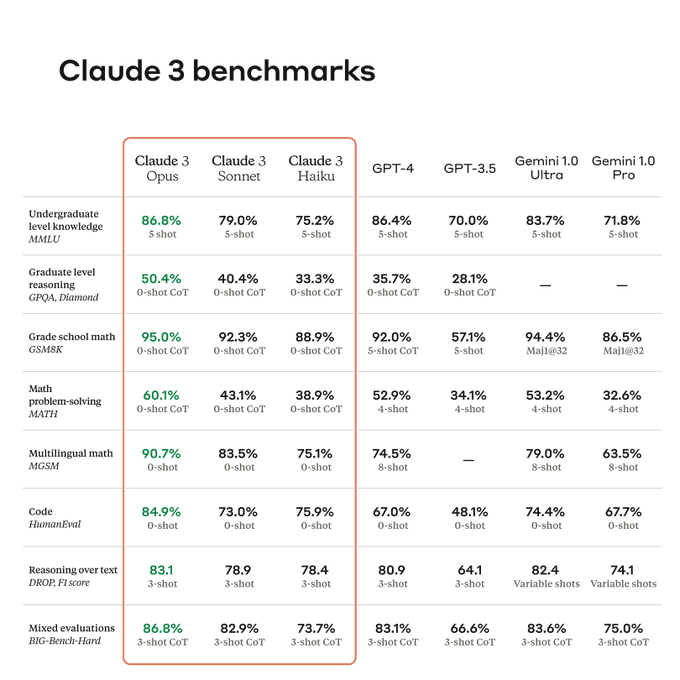
570
2K
10K
0
1
52
I find live mode to be a big improvement for voice interactions: graceful with interruptions and much lower latency to get a response.
Meet Gemini Live: a new way to have more natural conversations with Gemini. 💬
💡 Brainstorm ideas
❓ Interrupt to ask questions
⏸️ Pause a chat and come back to it
Now rolling out in English to Gemini Advanced subscribers on
@Android
phones →
69
280
1K
4
2
52
Bard powered by gemini pro is in the 1200 elo club on lmsys 🔥 It's a great model, and it's free!
🔥Breaking News from Arena
Google's Bard has just made a stunning leap, surpassing GPT-4 to the SECOND SPOT on the leaderboard! Big congrats to
@Google
for the remarkable achievement!
The race is heating up like never before! Super excited to see what's next for Bard + Gemini

153
620
3K
1
4
52
Some people reached out to remind me that LSTMs are dead. Actually the point I want to drive home isn't about LSTMs. It's to treat the status quo with extreme suspicion, especially in the empirical sciences. Lots of breakthroughs start by testing assumptions vs following the herd
Classes on deep learning always teach how LSTMs solve the vanishing grad problem. It's a thing you need to mention in job interviews etc. However there's two types of people: those who train an LSTM and see gradients always vanish in practice, and those who keep the myth going 🕯️
5
2
85
3
4
51
Evaluating LMs in 2017: "after training on the same set of 2.5k WSJ articles (Mitchell 1999, Mikolov 2010) we get slightly better token probabilities"
Evaluating LMs in 2022: "here's a growing list of challenging exams the model passes"
Evaluating LMs in 2027 🤔

#OpenAI
's ChatGPT is ready to become a lawyer, it passed a practice bar exam! Scoring 70% (35/50). Guessing randomly would happen < 0.00000001% of the time

127
1K
9K
3
4
50
It seems plausible a vast auto-associative memory over humanity's knowledge could be harnessed as a tool towards many creative associations of existing knowledge, which would still result in unprecedented scientific progress. 4/4
0
4
48
These days you can cook a steak using a gadget that gives you a wandb-like interface to your grilling
Maybe soon we'll be able to plot the negative log likelihood of medium-rare with a log-log scale (kaplan et al. 2020), run some sweeps, and get chinchilla-optimal steaks🤯🤌📉

5
1
45

Nice public service to evals from Scale!
Creating a new grade-school math test set comparable to the commonly benchmarked gsm8k, many models drop in accuracy by a significant margin.
Mistral and Phi are juicing to get higher benchmark numbers, while GPT, Claude, Gemini, and Llama are not.

1
44
289
2
6
48
It's a bit crass to speculate over which transformer co-author has the most money or is the most successful. But if I had to guess, I'd say Jensen Huang 🤔

It was so great to see almost everyone (we missed you
@nikiparmar09
!!) from the Transformer paper again. We still haven't all been in the same room at the same time, but we'll make it happen one day.
@lukaszkaiser
@kyosu
@ashVaswani
@ilblackdragon
@YesThisIsLion

17
40
502
3
0
46
Contamination is still a huge confounding factor in modern-day model comparisons. There's a lot of value in hard benchmarks that are truly held-out. Great work 👏👏

🧵Announcing GPQA, a graduate-level “Google-proof” Q&A benchmark designed for scalable oversight! w/
@_julianmichael_
,
@sleepinyourhat
GPQA is a dataset of *really hard* questions that PhDs with full access to Google can’t answer.
Paper:

23
138
888
1
4
46
@buccocapital
arthur is one of the smartest people I've ever worked with, this is a great win for ai in europe
6
0
46
@markchen90
@_smileyball
Jensen's inequality: no matter how many H100s you have, someone has a lot more.
2
1
44


The ease of access to powerful LLM weights such as GPT-J and OPT --- which have no real governance of use once released --- makes it easier than ever for bad actors to create social media bots that seem human and relatable at scale. Is this the right risk/benefit tradeoff?

This is the worst AI ever! I trained a language model on 4chan's /pol/ board and the result is.... more truthful than GPT-3?! See how my bot anonymously posted over 30k posts on 4chan and try it yourself. Watch here (warning: may be offensive):

35
84
573
6
4
41
Amazing to see AlphaProof get silver medalist performance in this year's IMO. One point away from gold, and a perfect solution to P6 (which only 5 of ~600 contestants solved).
We’re presenting the first AI to solve International Mathematical Olympiad problems at a silver medalist level.🥈
It combines AlphaProof, a new breakthrough model for formal reasoning, and AlphaGeometry 2, an improved version of our previous system. 🧵
303
1K
5K
0
5
44
Note the power dynamic in this conversation, a safety researcher has to persuade some random dude of the harm of deploying "gpt 4-chan" bots on a forum *after* the fact.
I asked this person twice already for an actual, concrete instance of "harm" caused by gpt-4chan, or even a likely one that couldn't be done by e.g. gpt-2 or gpt-j (or a regex for that matter), but I'm being elegantly ignored 🙃
35
19
371
4
8
42
Another implication of this lovely thread which I'd forgotten: we imagine neural networks learning functions and algorithms in their canonical form, but they're probably tuning terms of fourier series to approximate said functions. Thinking with harmonics 🎶

I've spent the past few months exploring
@OpenAI
's grokking result through the lens of mechanistic interpretability. I fully reverse engineered the modular addition model, and looked at what it does when training. So what's up with grokking? A 🧵... (1/17)
24
242
2K
4
1
42