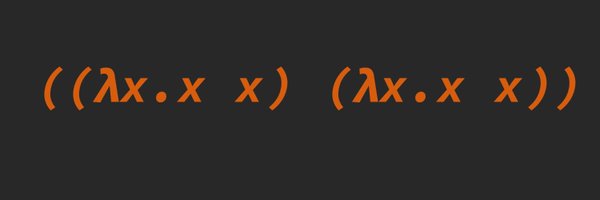

Federico Cassano
@ellev3n11
Followers
623
Following
122
Media
5
Statuses
189
Research @cursor_ai Previously: @neu_prl , @scale_AI , @Roblox , @trailofbits Papers here:
Boston - SF - Milan
Joined September 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#2024MAMAVOTE
• 2759166 Tweets
I VOTE
• 1524142 Tweets
EP6 U STEAL MY HEART
• 427164 Tweets
#Jin_Happy
• 304834 Tweets
JIN IS COMING
• 285295 Tweets
Choice - Female Award
• 216095 Tweets
Libya
• 213435 Tweets
Columbus
• 204581 Tweets
HAPPY IS COMING
• 191593 Tweets
seokjin
• 180562 Tweets
Nobel
• 168845 Tweets
KSJ1 IS COMING
• 146078 Tweets
MY ROYALTY HEESEUNG DAY
• 98394 Tweets
YOU ARE LOVED
• 95195 Tweets
Bill Clinton
• 78303 Tweets
Daron Acemoğlu
• 76970 Tweets
Thanksgiving
• 74892 Tweets
#Number_i_1stAnniv
• 34323 Tweets
Europeans
• 27053 Tweets
Leire
• 25154 Tweets
Laken Riley
• 22867 Tweets
kesha
• 22128 Tweets
Native Americans
• 20297 Tweets
Bret
• 19971 Tweets
La Oreja de Van Gogh
• 17311 Tweets
Amaia
• 17304 Tweets
Reece James
• 16713 Tweets
Billy Maximoff
• 15301 Tweets
Nasser
• 12955 Tweets
Europa Clipper
• 12665 Tweets



















Pinned Tweet

We finally released StarCoder2 Instruct!
SC2-Instruct is the very first entirely self-aligned code LLM trained with a fully permissive and transparent pipeline.
On benchmarks, we are beating even versions of StarCoder2 trained on GPT-4 distilled data!

6
46
177
Happy to share that I'll be taking a break from school to work at
@cursor_ai
as a research scientist!
I'm extremely excited to continue my research on using AI and PL for automating software engineering with such a talent-dense team.
8
1
127
@Calcolis
@cremieuxrecueil
Because we receive environmental feedback, in this Nature's paper, the model doesn't.
3
0
31
I'm happy to share that our paper on evaluating LLMs at editing code through natural language instructions (Can It Edit?) has been accepted at
@COLM_conf
, ranking in the top 5% of all submissions!
Please check out our preprint for more:

0
0
28
10 months ago, these were the SOTA results for open-source code generation (from ). How things have changed!
Benchmark: HumanEvalPack

2
0
20
I'll be at COLM 2024 from Monday to Thursday, presenting my work on evaluating LLMs at code editing.
Feel free to DM me if you'd like to meet and chat about automating software engineering, reinforcement learning, test-time compute, or research at
@cursor_ai
!
1
0
21
Llama-3.1 trains on synthetic translations of Python to low-resource languages (e.g., PHP) to improve performance on MultiPL-E!
In our work, conditionally accepted to OOPSLA 2024, we present several experiments in this direction:

6
5
18
@cristinaz_c
In Italy if I want my employee to take home 2000€, I need to pay around 4200€, and it goes up with salary.
1
0
8
Also, huge shout-out to
@milliondotjs
for providing me with compute for a large part of this effort! Truly appreciated.
0
2
7
old news but MultiPL-T got (conditionally) accepted at OOPSLA 2024. See you in LA (probably)
1
0
6
You can full-parameter SFT Llama-3-70B on 8xH100 with 2TB of RAM. The perfect ratio of optimizer parameters to offload to CPU is 0.75
0
0
6
(I was right, what a shocker)
The technique in question:

0
0
0
1
1
6
It was a pleasure to work on this with
@YuxiangWei9
,
@JiaweiLiu_
,
@YifengDing_
,
@StringChaos
,
@harmdevries77
,
@lvwerra
,
@ArjunGuha
, and
@LingmingZhang
0
0
5
@hughbzhang
@evanzwangg
@ChowdhuryNeil
@squeakymouse777
@vaskar_n
@SeanHendryx
@summeryue0
quality is fractal
0
0
5

@corbtt
@eugeneyan
This is not true for code generation. Reproduced myself (disclaimer, n=1):
# LiveCodeBench - GPT-4o
- temperature=0 -> 43.5
- temperature=0.8 -> 42.8
- temperature=1 -> 42.2
This is likely because your metric is LLM-as-Judge
0
0
4
Interestingly, we find that while fine-tuning on natural data (from The Stack) in the low-resource language yields marginal improvements, fine-tuning on these self-translated samples significantly improves the model's performance, in some cases more than doubling it.

0
0
3
@jeremyphoward
at this current time, models are able to improve with self-correction if either they are used jointly with a specially-trained discriminator (ORM or PRM), or with environment feedback
0
0
4
commits are to code what videos are to images; there is so much more data out there
1
1
3
Humanity would have so much more free time if NVIDIA decided to shorten CUDA_VISIBLE_DEVICES
0
0
3
@ArjunGuha
@TheZachMueller
@Prince_Canuma
@winglian
@StasBekman
@charles_irl
I think it's pretty normal when you have diverse samples! Here is a wandb report:
0
0
2
We utilize compilers to translate function headers and tests from Python to a low-res language, and then we use the LLM to fill-in the body of the function. Before training on the translations, we execute them on the mechanically-translated tests, and only train on passing impls.
1
0
3
@Euclaise_
There is little evidence that CoT improves performance for code generation. E.g. see DeepSeekCoder paper (); it barely moves the needle.

0
0
2
@bindureddy
There have been numerous un-censored open-source models before, this is not the first one.
0
0
0
@natfriedman
I think
@Muennighoff
's paper showed this!
> training LLMs
on a mix of NL data and Python data at 10 different mixing rates and find that mixing in code
is able to provide a 2× increase in effective tokens even when evaluating only NL tasks.
0
0
2
@bneyshabur
Note though that MATH is a dataset with all problems roughly at the same difficulty level. Not saying that we are hitting a wall nor saying this is not impressive! Just being nitpicky
1
0
1
dumped a whole water bottle on my
@system76
lemur pro's keyboard. shut it down, dried it with hair dryer. still kicking strong
2
0
2
@dhtikna
@ArjunGuha
Looks like the table got mixed up, thanks for pointing it out! The Lua 1b model performs much better: 17.3 pass
@1
Almost a 2x improvement. We will revise the PDF
0
0
2
@jasontempborn
@amanrsanger
totally depends on the model and your definition of contamination.
87.8% of the issues and PRs in the benchmark are older than Jan 2023.
0
0
1
@snagycs
FYI hotcrp says: The site is not open for submissions at the moment.
When will it go online?
1
0
0
@casper_hansen_
@amanrsanger
cutoff needs to happen for repository creation, not issue/PR creation
0
0
1
0
0
1
@mSanterre
@RekaAILabs
most recent eval is 90. just reproduced myself. check the full leaderboard on evalplus:
1
0
1
@OfirPress
@hughbzhang
definitely not statistically significant after ~2022 due to the restricted sample size, but there is some effect.
0
0
1
0
0
1
@OwainEvans_UK
Am I missing something or was this known before? MLPs store facts in one direction:
1
0
0
@wcrichton
Also Principles of Abstract Interpretation has one! I think it's a very efficient way of learning one specific topic in a large book.
0
0
1
@TheZachMueller
@cursor_ai
I don't work on this part of the stack but I will certainly send this to the guys!
1
0
1
@diegocalanzone
@deedydas
There looks to be a label leak, making the results pass
@16
rather than pass
@1
:

0
0
1
@NeelNanda5
Yes, I suspect that these results apply mostly to PEFT and not full parameter finetuning
1
0
0
@paulgauthier
Paul I love your work, but are you not worried that your evals may be contaminated? Exercism is in training data of lots of models, I even used it as a fine-tuning set a while ago. Interested to hear your thoughts!
1
0
1
@Jason
Pretty nuts to see people don't know how inflation works. If you adjust for CPI you see a pretty flat relationship i think. I've stared at many many CPI curves...
0
0
0
@mandeepabagga
@chrisatgradient
@Gradient_AI_
@AIatMeta
@huggingface
Yeah, currently it's not great at that...
1
0
1
@jwilson1717
@Calcolis
@cremieuxrecueil
Because they have learned a really good reward model from the environment. See actor critic networks.
1
0
1
