

Charles 🎉 Frye
@charles_irl
Followers
10,421
Following
1,858
Media
1,848
Statuses
6,727
ai engineer at @modal_labs . he/him. ex @full_stack_dl , @weights_biases , phd Berkeley @Redwood_Neuro . try
SF // NYC // www
Joined January 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
オリンピック
• 683524 Tweets
Christians
• 400909 Tweets
#บัสซิ่งไทยแลนด์EP7
• 256354 Tweets
花火大会
• 222787 Tweets
#พรชีวันep1
• 177758 Tweets
1M LOVE LINGORM
• 133813 Tweets
Endrick
• 128477 Tweets
グラブル
• 117351 Tweets
スポーツ
• 114780 Tweets
Itália
• 77181 Tweets
YOKOFAYE WATCH BLANK
• 73795 Tweets
Judo
• 67382 Tweets
永山選手
• 66384 Tweets
#SixTONESANN
• 49478 Tweets
柔道の審判
• 48515 Tweets
Darlan
• 42559 Tweets
#青島くんはいじわる
• 34549 Tweets
Leclerc
• 34367 Tweets
#ジェルくん誕生祭2024
• 31791 Tweets
Arabia
• 30122 Tweets
反則負け
• 28979 Tweets
Checo
• 23734 Tweets
柔道の判定
• 23261 Tweets
ハンドボール
• 20692 Tweets
コラボガチャ
• 20009 Tweets
Equi
• 19948 Tweets
男子バスケ
• 16425 Tweets
Irak
• 16386 Tweets
クラフトワーク
• 14976 Tweets
Babiarza
• 12670 Tweets
ガルリゴス
• 12184 Tweets
girl in red
• 10959 Tweets
タルマエ
• 10370 Tweets
Last Seen Profiles




















Pinned Tweet

My new job is to get everyone else to see what I see in Modal:
the future of data-driven computing
powered by open generative models trained at the scale of the web
and adapted to end-user needs by code, customization, and continual improvement.
LFG.
7
3
67




They say you die twice: the first time when your heart beats its last, the second time when the last person who knows your name dies.
This indicates that life employs a garbage collector based on reference counts. In this essay, I will
34
880
4K
PagedAttention, Virtual Context, Speculative Decoding, Register Tokens: the last year has seen many ideas from systems programming applied to LLMs.
Not many folks live in that intersection, so I wrote an explainer post to make them a bit more accessible!



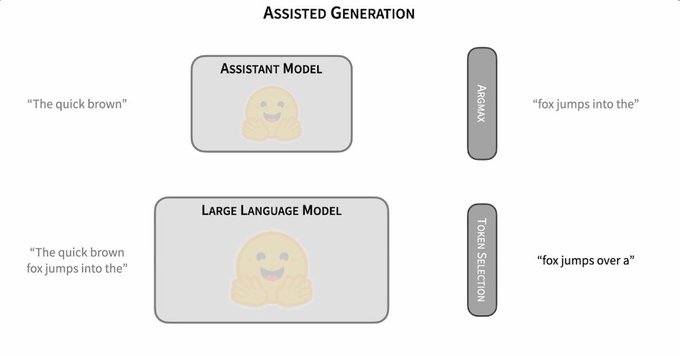
18
285
1K
I've been working on neural networks for almost a decade.
The best way to describe how I'm currently feeling is like a dog that caught up with the car it was chasing, sunk its teeth in the fender, and is now traveling at 80 mph -- tail wagging, jaw tiring.
33
140
1K
"any other questions before we wrap up this interview?"
"yeah - are y'all an Adderall CEO, LSD CTO startup or an LSD CEO, Adderall CTO startup?"
21
88
1K
did an entire PhD on optimization just to end up here for most projects

13
48
1K
If you're like me, you've written a lot of PyTorch code without ever being entirely sure what's _really_ happening under the hood.
Over the last few weeks, I've been dissecting some training runs using
@PyTorch
's trace viewer in
@weights_biases
.
Read on to learn what I learned!
6
161
851
New guide to using CUDA on
@modal_labs
just dropped.
It began its life as a document called "I am fucking done not understanding the CUDA stack", and after readelf-ing CUDA binaries, RTFMing the driver docs, & writing homebrew kernels, I'm excited to share it with the world!

4
98
731
the year is 2015. i am struggling to install CUDA drivers.
the year is 2020. i am struggling to install CUDA drivers.
the year is 2023. i am

43
33
635
I got a new job at
@modal_labs
!
In my first week here, the team has added H100s, shipped an integration with
@vercel
, and merged >200 PRs. Incredible combination of velocity, product, & tech.
I want to tell the story of my journey from early adopter to happy user to employee.



47
21
543
if the guy who wrote the book on convex optimization is willing to call it "early AGI", perhaps it's worth looking past the breathless hype on this one

Sparks of Artificial General Intelligence: Early experiments with GPT-4
Reports on their investigation of an early version of GPT-4, when it was still in active development by OpenAI.

15
122
693
10
34
413

today is the perfect day to a-nn-ounce the official release of a software library i've been working on in stealth mode this past month
panndas: neural networks in pandas



5
46
341
For the last year, I've been thinking and reading about LLMs, operating systems, and the history of computing, trying to decide what I think about "Software 3.0" and the "llmOS".
I synthesized my takeaways in a talk at
@ScaleByTheBay
, Parallel Processors, now available online!

5
40
325
step 1. run MemGPT on GPT-4 for 10k tasks, approx 100M tokens
step 2. annotate/filter incorrect executions
step 3. finetune Mistral 7B on the data
step 4. release the weights and unlock OSS LLM kernels
10
17
297
New video series out this week (and into next!) on the
@weights_biases
YouTube channel.
They're Socratic livecoding sessions where
@_ScottCondron
and I work through the exercise notebooks for the Math4ML class.
Details in 🧵⤵️
3
58
290

This section was originally entitled "Let's Not Fuck Up LLMOps Like We Did MLOps".

8
29
241
Out of curiosity, I just looked at the PubMedQA dataset.
It is _so_ noisy!
The contents are messily scraped, 99.5% of the annotations are language model-generated -- and the LMs were BERTs!

10
24
238


I know lots of various central limit theorems, maxent arguments, convolving arguments, etc. but it’s still so bizarre to me just how universal Gaussian distributions are. Does anyone have intuition for why or interesting constraints that end up being equivalent to the Normal?
65
14
463
9
16
232
Over the past month, I've been working to grok RWKV, one of the most successful challengers to Transformers for language modeling.
I untangled numerical tricks from load-bearing math, assigned semantic names to one-letter variables, and debugged weird NaNs so you don't have to!

Is it the revenge of recurrent nets? Is it a subquadratic Transformer?
It's both, it's neither, it's RWKV:
@BlinkDL_AI
's novel architecture that infers efficiently like an RNN but matches Transformer quality -- so far.
Deep dive by
@charles_irl
:
2
63
231
3
31
227
.
@jeremyphoward
put out a delightful tutorial this week on getting started with LLMs for a science QA Kaggle competition
unlike many other intros it emphasizes exactly the right thing: understand the data first, then the model, in the context of the task

1
38
219
In this post,
@eugeneyan
,
@BEBischof
,
@HamelHusain
,
@jxnlco
,
@sh_reya
& I share our tactical tips for working with LLMs, from structured outputs to caching
Stay tuned for two more posts covering the operational (hiring, product) & strategic (durability, competition) perspectives


Proud to bring you:
A Year Building With LLMs, a three part essay published with O'Reilly
We get into the weeds on what it takes develop incredible LLM powered applications
Advice from:
@eugeneyan
,
@charles_irl
,
@HamelHusain
,
@jxnlco
,
@sh_reya
and I.
10
51
239
2
23
207
im looking to start an interest group crossing over
@full_stack_dl
+
@ml_collective
!
we'll work through long-form content (h/t
@chipro
+
@sh_reya
) first, w sync discussions weekly to keep us on track
async folks can chat on discord, contribute to a wiki, + catch the recordings

6
28
205
"opinions expressed are solely my own and do not express the views or opinions of my employer"


15
6
206
really love the CMU Database Group's online courses and the lectures on distributed systems from Martin Kleppmann -- both available on YouTube
what's your favorite operating systems course that's available in the same format? ideally a university course, at least 8 hours
8
14
201



great new post from
@nelhage
on "what's the deal with pickle in ML" that has a ton of great insights on research code in general
ignore this while implementing LLMOps tooling to your peril

12
13
184
1) Attention heads execute dot-product vector lookup on a key-value store constructed from the token sequence and the head weights.
2) Redis is a key-value store that supports dot-product vector lookup.
Behold, RedisAttend:

8
11
183
@karpathy
vibing with the taste of this sauce, chef
but what do we do about
- kernelland vs userland (isolation, scheduling)
- interrupt handlers (representing clock time, boundary between peripherals and processor, etc)
5
0
172
last week
@modal_labs
made A100 GPUs available
so on Friday i dropped everything to play with them
in hours i had a CLI tool that could make
@StabilityAI
art of the new puppy in my life, Qwerty
by Sunday i had multiple autoscaling pet-art-generating web apps -- and so can you!

7
22
173

For my first official contribution to the
@modal_labs
examples: running Gemma 7B on an H100 at >2500 tok/s 🚀
With very little effort, that's already just ~75¢ per megatoken -- and you have full "tensors-and-a-shell" control over the execution environment
6
20
164
this Independence Day, i am celebrating our future independence from the Transformer architecture 🎆



9
9
156
I'm a big fan of the RASP line of work that's building up a theoretical model of Transformer computations.
It's notoriously hard to grok -- but I feel like it's just not inaccessible _enough_.
To that end I'm introducing raskell, RASP-L in Haskell:


What algorithms can Transformers learn?
They can easily learn to sort lists (generalizing to longer lengths), but not to compute parity -- why?
🚨📰 In our new paper, we show that "thinking like Transformers" can tell us a lot about which tasks they generalize on!

16
262
1K
4
11
152
years later, it's really happening -- i find myself swapping tips on training neural networks by looking at
@weights_biases
runs, totally organically and effortlessly
(this is in the
@HamelHusain
x
@dan_s_becker
course discord, btw)

5
14
148
Took a look through the student projects from
@jim_dowling
's recent class on "Scalable ML and DL" and man, it's impressive how far you can go with contemporary tools like
@modal_labs
,
@huggingface
, and
@hopsworks
!


2
30
145
It can be done! It should not be done!
I christen this pattern the "TuringCompletion": it turns ChatCompletion-with-functions into an endpoint for executing programs written by LMs on-the-fly.
(Don't) Try It Yourself:

we've seen folks hack
@OpenAI
function calls to produce objects (by exposing "fake" functions) and produce DAGs (by exposing a "query planner")
DAGs are nice, but they are not arbitrary programs
so what about a function call that edits the functions available on future calls?
3
5
66
7
25
140
if you don't like it, please submit your complaints as PRs to stay_mad.yaml

5
3
140
"Let me tell you, I've made billions and billions of deals using C, C++. These languages are tremendous, absolutely tremendous.
Now, they're trying to sell us this 'woke' idea of memory safety. 'Oh, we need to be safe, we can't have these buffer overflows.'"


Looks like the presidential debate is going to be on C vs Rust, memory unsafe vs safe languages. Everything else is immaterial.
11
9
150
4
10
142
1/ Last semester, I taught a course on computational Bayesian inference in
#pymc
aimed at novice
#Python
-istas and budding
#DataScience
folk.
Though not perfect, it is now complete and available for anyone, install-free: .
🧵⤵️, some of my favorite parts:

3
51
143
LLMs are often called "non-deterministic". This is not strictly true. They can be configured to be as deterministic as other software.
We are however subject to _epistemic_ uncertainty: outputs are subjectively unpredictable.
Epistemic uncertainty is resolved by experiment.

9
19
141
why are there so many highly-paid engineers who specialize in staves? what could possibly be so difficult about staff engineering? they're literally just sticks.
20
5
139
love
@AnthropicAI
Claude, but it doesn't have an interpreter to execute code it writes
but there's a code sandbox widget in -- which enables even more complex workflows, like having Opus write tests that Haiku writes code to pass, with code review by GPT4
5
13
133
I'm back in the webinar game!
My first official webinar for
@modal_labs
is in two weeks, and we'll cover one of the things I've enjoyed the most since joining Modal: making LLM inference go brrrt.
Plus: $250 in credits to all attendees💚

3
10
132
i saw the best minds of my generation destroyed by fine-tuning
2
9
127
My "AI Engineering 201" talk from
@aiDotEngineer
summit goes live soon!
Topics:
- the future of open & closed models
- constraints for AI deployment targets: edge, browser, server, serverless
- memory-bound vs compute-bound inference
come check it out

2
13
124
in a delightful turn of events, i'm working on an OpenAPI AI using the OpenAI API 🤕
7
6
122
Part II of AI Engineering 201, "The Rest of the F*cking Owl", is now up!
Part I was a two hour deepdive into inference and models
Part II is one hour on "everything else" in a whole LLM product: retrieval, cognitive architectures, monitoring, eval, &cet

2
13
120
For every ten likes this gets, I will ask ChatGPT to add more people beating this dead horse.

"That's a great picture, but now make the beaten horse even deader!"
2
1
24
8
5
120

i will literally pay you to learn how to work with LLMs

Amazing news re: our LLM fine-tuning course: All students get $1,000 in free compute credits from
@modal_labs
and
@replicate
($500 each) 💰
Course signups close end-of-day today.
You get more compute credits than the course costs 🤯
16
21
167
5
7
119
Great way to try out MMLU and get a sense for just what, exactly, we are using to evaluate LLMs!
I doubt folks would knife fight for a percent on this benchmark if its contents were realized more broadly.

5
18
117
if you're not doing cloud-native development on
@modal_labs
for a
@weaviate_io
vector DB-backed,
@huggingface
embeddings-based recsys app while riding in the back of a
@Waymo
, are you really living in 2024?

7
14
116
when i looked back at alexnet again in ~2020 and noticed it had model parallelism, i realized that i really needed to spend less time on mathematics and more on software engineering

# CUDA/C++ origins of Deep Learning
Fun fact many people might have heard about the ImageNet / AlexNet moment of 2012, and the deep learning revolution it started.
What's maybe a bit less known is that the code backing this winning submission to the
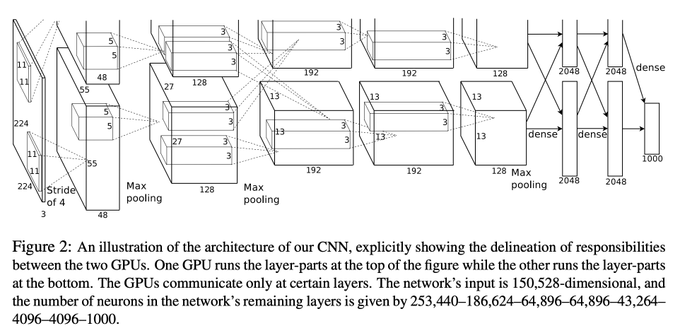
166
900
7K
3
9
115
swapping in H100s for A100s, immediate 2x speedup. god bless the hardware folks
2
7
114
Dropped a new walkthrough on the
@modal_labs
docs -- how to turn any Python function into a
@FastAPI
endpoint on Modal with two lines of code.

3
4
113
This is why I think anyone trying to ship LLM features in the next six months should be focusing on code!
We'll handle hallucinations, evaluation, etc. for tougher cases like law & medicine once we've learned the hard lessons in software/easy mode.

@Grady_Booch
If anything, code is a better application for LLMs than most other fields of information work - because hallucinations in code can be "fact checked" by running that code
Much easier to spot hallucinated code than hallucinated facts in prose
1
15
81
1
5
108
I was deeply confused by async programming until I got my hands dirty and played around with epoll (and kqueue on OS X).
Check out this article for a nice overview!
4
6
110
This tweet blew up!
What a great time to remember that
#BreonnaTaylorWasMurdered
and
#BreonnaTaylorsKillersAreFree
.
This call to action, on the occasion of the birthday stolen from her by white supremacist police violence, got no-knock warrants banned. We must keep going!

1
11
108
The usual way to set up a DL model for regression (e.g. autoencoding) doesn't include any uncertainty quantification, unlike the default way to do classification.
What if, for targets that have bounded values, we just turn it into a classification problem?
21
6
105
There's a theory out there that neural networks are easy to train because their loss f'n is "nice": no bad local minima.
Recent work has cast doubt on this claim on analytical grounds. In new work, we critique the numerical evidence for this claim.
🧵⤵

1
27
104
"Can Copilot produce bug-free code without human review?"
"Can a diffusion model generate a truly novel piece of art?"
"Can ChatGPT determine when it is uncertain and calibrate the confidence of its tone appropriately?"

5
12
104

🦜🥞 intensifies


5
2
100
It's been awesome watching
@andersonbcdefg
cook using Modal!
"The ability to spawn jobs from one Python environment that run in a totally different Python environment (different packages, more CPUs, GPUs, etc.) is a great benefit to machine learning engineers."


We are so excited to share more about our partnership with
@modal_labs
, a serverless platform for high-performance computing.
Check out our blog for how we use Modal to build & deploy high accuracy text classification models for our users.
0
5
23
1
14
102
missed this reverse engineering of macOS Sonoma's Transformer-based autocorrect a few months back!
GPT-1 style, but still interesting if you're thinking about how to bundle these things in OSes/browsers/native apps
3
12
103
High-signal set of talks on ML X DBs from the CMU database group.
I particularly recommend the talk on
@postgresml
from Montana Low. Condensed nuggets of ML operations wisdom from years in the trenches, plus a vision of the future.

1
7
103

My personal favorite in this section: "the rumors of RAG's demise are greatly exaggerated."

My colleagues and I distilled practical advice re: LLMs into this three-part series. Lot's of bangers. One of my favorite excerpts from this part in the screenshot
Advice from:
@eugeneyan
,
@BEBischof
,
@charles_irl
,
@sh_reya
,
@jxnlco
and myself
See:

15
55
433
4
9
100
Nice! Just ran Whisper and did a quick comparison with the transcription tool in Descript. Competitive accuracy results from Whisper, possibly a bit better.
That means with just ~3 clicks, I was running SotA audio transcription, in a UI, on an accelerator, all entirely for free!


The
@Gradio
Demo for
@OpenAI
Whisper, a general-purpose speech recognition model is out on
@huggingface
Spaces
demo:
colab:

3
74
271
3
11
101
anti-proprietary model protestors outside of the NVIDIA GTC keynote venue

7
4
100
man, this tweet aged very well

A question I had about the GPT-3 paper. It seems that some smaller models are not converged, and are given significantly less compute than the 175B parameter model. I wonder if 175B params are actually necessary, or the smaller models just needed to be trained longer?

4
12
113
3
4
97
Computer programs are being used as increasingly plausible models of human cognition. They are disturbingly simple & heuristic. They play chess, write proofs, and even pass some exams. Augmented with external memory, they can help you pick investments!
The year is 1965.

5
18
97
The second part of "What
@eugeneyan
,
@BEBischof
,
@HamelHusain
,
@sh_reya
,
@jxnlco
, and I Learned from a Year of Building with LLMs" is now available.
We zoom out from technical tactics to talk operations: team culture, product discipline, and more.

4
20
98
@karpathy
hmm, unless we can control models more tightly than we currently do, the system message/user message distinction feels like a weak form of security
would hate to lose my ssh keys because someone threatened imaginary orphans while pinging my LLM kernel
7
1
94
icymi: today in
@HamelHusain
x
@dan_s_becker
's LLM Fine-Tuning Course, we distributed an extra $500 in
@modal_labs
credits to the 338 students who had used the platform.
live.
using a script that ran on modal.


@charles_irl
insane flex by
@modal_labs
and
@charles_irl
giving students who've tried modal ANOTHER $500 credit

3
4
48
9
6
97
another fun session of the
@ml_collective
x
@full_stack_dl
reading group on "Designing ML Systems", by
@chipro
great discussion on Chapter 3, "Training Data", with a focus (ha!) on focal loss and on synthetic data
4
9
93
hope i am proven wrong in my fear that "GPTs" will 100x this tech's reputation for vaporous demoware
6
2
93
This post is absolutely wild -- including demonstration of non-determinism in prod GPT-3.5 series models at temperature 0!
We've finally got some "Intriguing Properties" of LLMs.
5
10
91
new short course of 3 video lectures soon with
@weights_biases
, covering the core ideas from math that you need in order to do ML -- or at least, my hot takes on them 🔥
catch the daily premieres starting next Tues 1/12 at 830a PST / 430p GMT / 1000p IST

1
15
91

the final video for the
@weights_biases
Math4ML series, on probability, is now up on YouTube!
@_ScottCondron
and I talk entropies, divergence, and loss functions
🔗:
2
15
86
neat result from the appendix: MMLU performance is more tightly correlated with ability to compress textbooks (right) than web text (left)

Compression Represents Intelligence Linearly
LLMs' intelligence – reflected by average benchmark scores – almost linearly correlates with their ability to compress external text corpora
repo:
abs:

9
76
463
6
4
86

wait so now we do rendering on the server and routing on the client?
not sure how to react
10
3
83
lil thread in here of suggested resources for folks new to Rust/systems programming, coming from Python/JS.
titles to entice: From Python To Rust, Rust By Example, Learning Rust With Entirely Too Many Linked Lists, Writing an OS in Rust
@jxnlco
@vagabondjack
I like RBE:
Once you've got that under your belt, try this walkthrough for writing a kernel in Rust:
1
3
41
2
8
84
Prompt engineering? My brother in Christ, you must first concern yourself with engineering promptly.
3
11
84
complaining about LangChain in production is like complaining about Excel in production
not even wrong
2
6
82
successful first edition of the
@ml_collective
x
@full_stack_dl
reading group on
@chipro
's "Designing ML Systems" book!
1
13
81

yesss
This is wild
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings
project
8
109
548
1
13
81
The hardest part about literature reviews is that cool papers tend to themselves cite cool papers.
So even as the "done" list has grown, the "todo" list has grown alongside it 🥹

5
3
82
so glad i can be here for the iBeer era of generative model apps

3
5
78
gradient descent isn't perfect, but it's a step in the right direction
0
9
80
super proud of the team for the
@weights_biases
youtube channel, which just hit 10,000 subscribers 🎉

3
2
79