
Aman Sanger
@amanrsanger
Followers
18,776
Following
698
Media
102
Statuses
946
building @cursor_ai |
San Francisco, CA
Joined April 2021
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#GFRunTheWorldConcertD1
• 415418 Tweets
Napoli
• 136264 Tweets
Ticketmaster
• 64120 Tweets
KINGPOWER x PHUWIN
• 56251 Tweets
#خلصوا_صفقات_الهلال2
• 40445 Tweets
#PVL2024
• 39973 Tweets
Akari
• 30188 Tweets
Qoo10
• 29925 Tweets
DONBELLE DAOG SA DAVAO
• 24599 Tweets
ポケミク
• 20301 Tweets
#Oasis25
• 18732 Tweets
ポムの樹
• 18389 Tweets
PLDT
• 17696 Tweets
月ノ美兎
• 15966 Tweets
椎名唯華
• 15727 Tweets
YOSHIKI
• 12202 Tweets
#ドッキリGP
• 12155 Tweets





















Introducing Cursor!! ()
A brand new IDE build from the ground up with LLMs. Watch us use Cursor to ship new features blazingly fast.
113
351
3K
Coding just got a little more delightful.
We've raised an 8M seed round, led by the OpenAI Startup Fund to build Cursor!
Read more here:

84
90
2K
At
@cursor_ai
, we’ve scaled throughput on GPT-4 to 2-3x over baseline without access to knobs in OpenAI’s dedicated instances [1]
We did this by reverse-engineering expected GPT-4 latency and memory usage from first principles.
Here’s how... (1/10)
16
89
1K
Want to code using GPT-4? We made an IDE built for programming alongside it
Try out the public beta here:
45
218
1K
No one is talking about the actual best open-source language model today. It isn't Bloom or OPT, not even GLM-130.
It's an 11B instruction fine-tuned model open-sourced by Google themselves: Flan-T5 11B
And the second best is Flan-T5 3B...
17
91
1K
At Cursor, we've built very high-quality retrieval datasets (for training embeddings/rerankers).
To do this, we use GPT-4 grading and the Trueskill ratings system (a better version of Elo)
Here’s how.. (1/10)
21
65
1K
Try out GPT-V in Cursor!
It's pretty good for building/modifying components!
78
116
1K
We’ve trained a new copilot++ model that’s smarter and much much faster
@cursor_ai
takes the crown the fastest copilot.
Out next week!
59
61
1K
We’ve trained a 70b model that achieves >1000 tokens/s using a custom inference technique called speculative edits.
It beats GPT-4o performance on an important task in Cursor called: “fast apply”.
We explain in detail how we do this in our blog:
(1/7)
35
89
890
At Cursor, we’re fascinated by the problem of deeply understanding codebases.
One useful primitive we’ve been focused on is code graph construction and traversal.
Here's how/why we're tackling this... (1/12)
21
65
861
Llama and many recent open-source models have a significant architectural limitation
They use multi-head attention instead of multi-query attention (which is used by PaLM and probs Claude 100K)
This can result in slowdowns of up to 30x
Heres the math behind why (1/n)
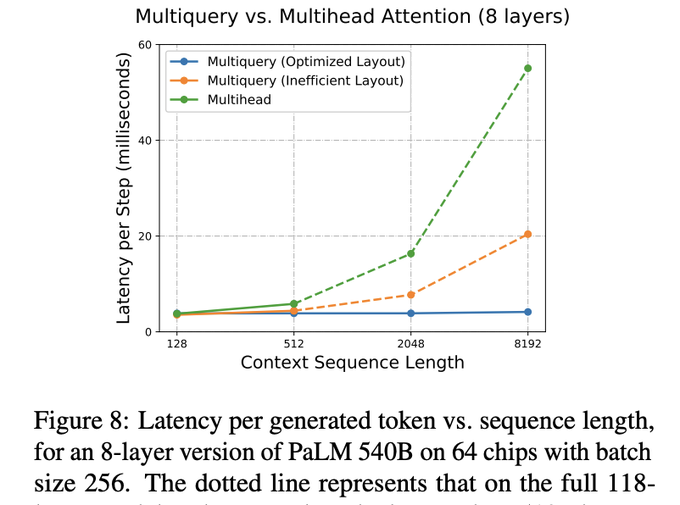
17
162
850
So much has happened in a year, but there's still so much more to do!
With this funding, we'll continue to build software and ML at the edge of what's useful and what's possible.
We're a densely talented team of 12 engineers and researchers. Join us!

We've raised $60M from Andreessen Horowitz, Jeff Dean, John Schulman, Noam Brown, and the founders of Stripe and Github.
Cursor has become recognized as the best way to code with AI, powered by an ensemble of custom and frontier models, delightful editing, and petabyte-scale
350
414
6K
65
24
841
Though
@cursor_ai
is powered by standard retrieval pipelines today, we've been working on something much better called:
Deep Context
After
@walden_yan
built an early version for our vscode fork, Q&A accuracy skyrocketed.
Soon, we're bringing this to everyone (1/6)
27
42
757
An underrated part of Cursor is our codebase indexing system.
It provides efficient indexing/updating without storing any code on our servers.
(1/9)
11
38
728
Introducing Copilot++:
The first and only copilot that suggests edits to your code:
50
45
693
SWE-bench is probably contaminated for frontier models (gpt-4/claude-3-opus).
Given only the name of a pull request in the dataset, Claude-3-opus already knows the correct function to modify.

14
70
683
One magical part of Cursor’s internal tech stack is a prompt compilation library called priompt ()
Here's why works so well... (1/12)
15
58
664
Another LLM inference trick that is surprisingly missing in most inference engines, but powers Cursor:
Request-level memory-based KV caching.
This can bring time to the first token (TTFT) down by an order of magnitude and dramatically increases generation throughput. (1/6)
10
40
592
Sub 600ms latency speech conversational AI is completely possible today, surprised I haven’t seen anyone that does this.
The key is hosting a model (like llama), streaming from whisper, and every few tokens, prefilling more of the kv cache - without evicting from memory (1/4)
33
35
550
My AI prediction: Training will look like researchers/practitioners offloading large-scale training jobs to specialized “training” companies: a state of the world that resembles chip design & fabrication.
(1/n)
27
65
544
The size of all code/history on Github public repos is 92TB
The size of Google's monorepo in 2015 was 86TB (of much higher quality code)
If Google were willing to deploy code models trained on their own data, they'd have a noticable advantage over everyone else.


38
38
525
Long context models with massive custom prompts (~2M) may soon replace fine-tuning for new knowledge!
Let’s explore why:
(1/10)
12
73
503
Working on a new version of copilot that can suggest *edits* to your codebase
18
24
499
GPT-4 is waaay better at programming than given credit for.
HumanEval is a benchmark of python programming problems.
With some prompt engineering, GPT-4 scores ~85%, destroying Codex's 29% from just 2 years ago
And performing much better than OpenAI's publicized accuracy
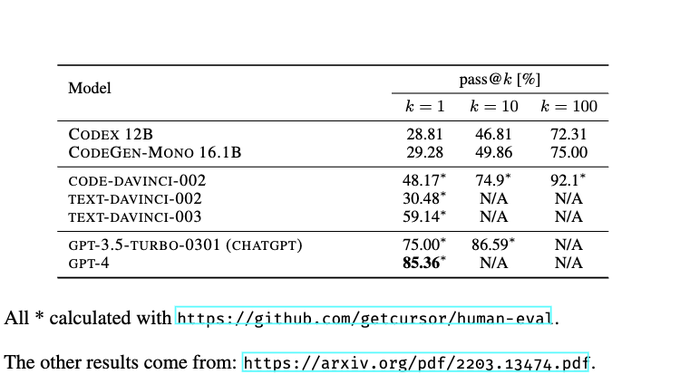
9
53
423
New feature just dropped... You can now generate a whole project with Cursor:
Coming this week, multifile generation + codebase-wide understanding 👀
12
44
415
My bet is that in the long run, reading and writing to external memory is key for much more capable models that can continually learn.
Someone will make the Neural Turing Machine work with a transformer backbone. (1/4)
18
23
412
Cursor Meetup in SF, next Thursday, August 15.
Meet the team at our office and share all your feedback!
We'll also be demo'ing a few upcoming features ;)
Link to signup below:
24
14
384
is now powered by GPT-4!
Since partnering with
@openai
in December, we’ve completely redesigned the IDE to incorporate the power of next-gen models like GPT-4
Soon, we’ll be fully opening up the beta.
Retweet this, and we’ll give you access today 😉

40
263
329
Despite Cursor’s recent insane growth, the current version is just 0.1% of what we have in store.
We’re a small, very strong team and are looking for fantastic SWEs and designers to help shape the future of software development.
Read more here -
19
18
355
There are some interesting optimizations to consider when running retrieval at scale (in
@cursor_ai
's case, hundreds of thousands of codebases)
For example, reranking 500K tokens per query
With blob-storage KV-caching and pipelining, it's possible to make this 20x cheaper (1/8)
8
18
350
Despite the recent hype around Replit's new model, it isn't actually the best open-source code model out there
In fact, it's not even the best 3-billion parameter code model
That title belongs to Microsoft's MIM-2.7B...
And it was trained on 2x fewer tokens!

10
36
338
Cursor just got a massive upgrade ()
...and we're now compatible with most of your VSCode plugins ;)
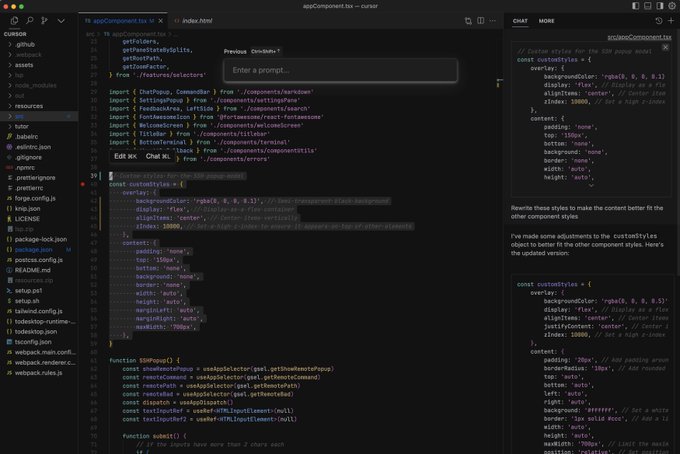
10
25
331
gpt-3.5-turbo is criminally underrated at coding
When using it with Azure's completion endpoint instead of OpenAI's chat endpoint, you can get a jump in HumanEval performance from <50% to 74%!
This blows claude v1.3 out of the water, which sits just below 60% perf. [1]
22
40
326
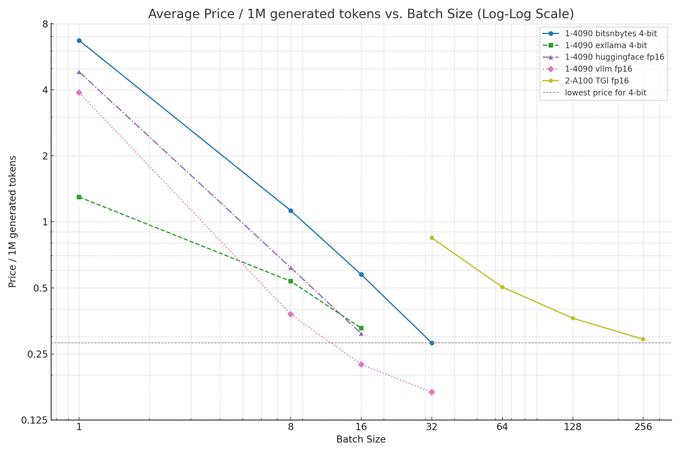
Surprisingly fp16 inference is cheaper than most 4-bit quantization (i.e. GPT-Q/exllama, bits n bytes, likely llama.cpp) when running inference at scale!
After profiling these methods with llama2-7b, we see fp16 vllm is the cheapest! [1]
Here’s the math behind why... (1/6)
9
42
308
People claim LLM knowledge distillation is trivial with logprobs, but that's not quite right...
It's very tricky to distill between different tokenizers. [1]
Internally, we've solved this with a clever algorithm we called tokenization transfer
(1/7)
7
21
296
After switching our vector db to
@turbopuffer
, we're saving an order of magnitude in costs and dealing with far less complexity!
Here's why...
(1/10)

we're very much in prod with
@turbopuffer
:
1. 600m+ vectors
2. 100k+ indexes
3. 250+ RPS
thrilled to be working with
@cursor_ai
—now we're ready for your vectors too
9
9
175
5
18
294
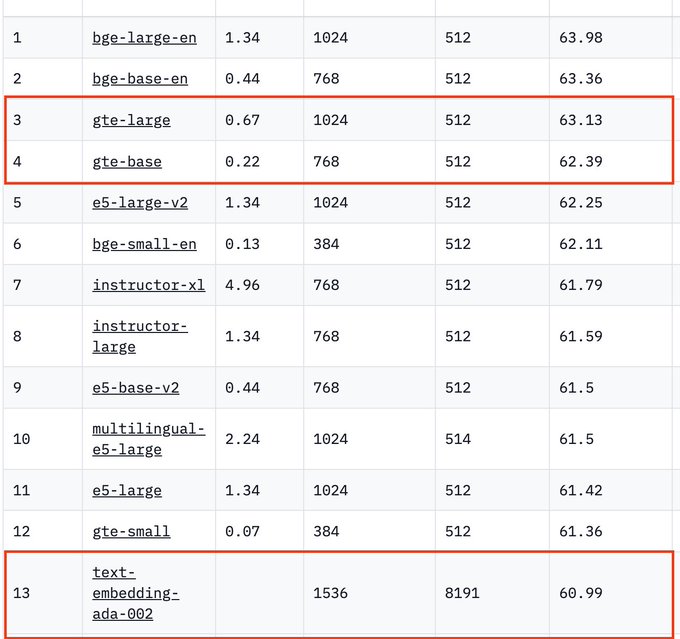
More people should be training their own embeddings
Why? Because it costs <$1000 to train a SOTA embeddings model
GTE-base is a 110M param model, which beat text-ada-embedding-002 on basically everything but code, and it likely costs < $921 (1/2)
8
39
284
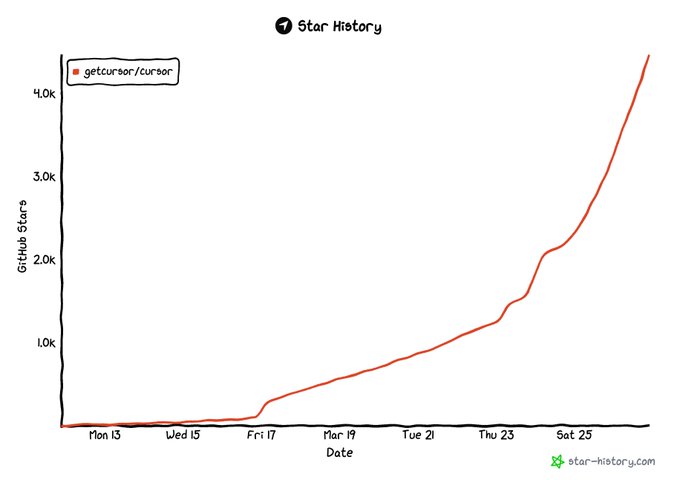
These are the problems we believe matter most for the next year of ai-programming
My favorite is next action prediction, the limit of what's possible with low-latency models
(we press tab 11 times and all other keys 3 times to make these changes)
[1/7]
17
26
286


With a 256K token prompt, a 7b model can generate tokens as quickly as codellama-7b with an 8K prompt.
How? The model must use multi-query attention.
Here's why...
(1/10)
6
38
269
Large dense-model training often requires fancy parallelism strategies (tensor/3d) instead of just FSDP because of a non-obvious constraint:
global batch sizes
(1/14)
4
28
268
If you've tried Cursor's copilot++, but find any other autocomplete tool more useful (i.e. copilot, supermaven, codeium, etc...) or prefer autocomplete turned off, please dm me. Would love to hear your feedback on where we fell short
We're cooking some big improvements.
33
12
262
"Token Counts" for long context models are a deceiving measure of content length. For code:
100K Claude Tokens ~ 85K gpt-4 Tokens
100K Gemini Tokens ~ 81K gpt-4 Tokens
100K Llama Tokens ~ 75K gpt-4 Tokens
OpenAI's 128K context window goes farther than it would appear.
9
17
258
A very simple trick and a very hard trick for sub 300ms latency speech to speech.
Simple:
Ask the language model to always preface a response with a
VERY believable filler word, then a pause
Um…
Well…
Really…
Interesting…
Maybe…
Hard:
Speculatively sample different user
Sub 600ms latency speech conversational AI is completely possible today, surprised I haven’t seen anyone that does this.
The key is hosting a model (like llama), streaming from whisper, and every few tokens, prefilling more of the kv cache - without evicting from memory (1/4)
33
35
550
21
13
227
Crazy results... 120B open-source model that is second only to Minerva in all kinds of STEM related tasks.
Big takeaway: multi-epoch training works. No degradation of performance for 4 epochs of training.
And with 3-4x less train data than BLOOM and OPT, it beats both.

🪐 Introducing Galactica. A large language model for science.
Can summarize academic literature, solve math problems, generate Wiki articles, write scientific code, annotate molecules and proteins, and more.
Explore and get weights:
284
2K
8K
6
20
221
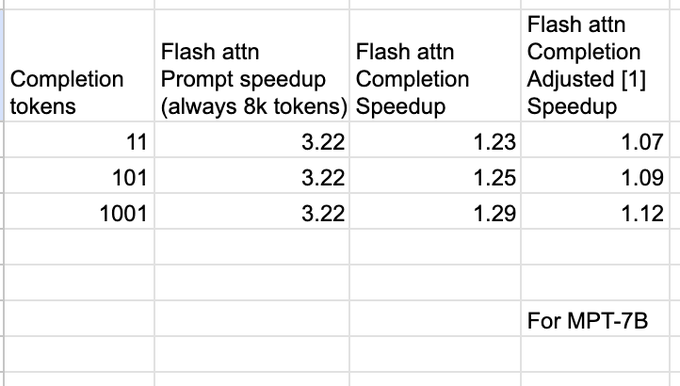
Flash attention is fantastic, but there are misconceptions that it is a silver bullet for all LM workloads.
At inference time, it is quite fast at ingesting prompts, but...
Flash attention offers minimal (if any) speedups for completions.
Let's explore why... (1/7)
8
28
218
As fantastic as OpenAI's models are, it's hard to justify using them for finetuning. I have a few reasons...
First, Instruct Models are unavailable for finetuning.
The best model you can finetune is davinci, which is probs worse than open-source equivalents like GLM-130. (1/3)
9
13
215
Priompt is one of the few prompting libraries that passes the sniff test for large-scale production applications.
Even Copilot uses it!

5
10
202
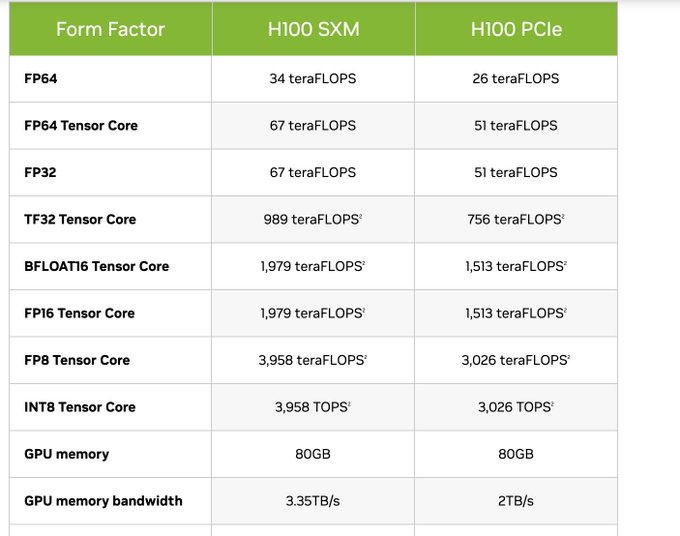
Palm2 has been leaked to be 340B params and trained on 3.6T tokens (7.4e24 FLOPs).
Someone out there could feasibly reproduce a similar quality model...
for under $6M!
But that price tag largely depends on H100s...
[1/6]
7
29
192
Tricks for LLM inference are very underexplored
For example,
@cursor_ai
’s “/edit” and cmd-k are powered by a similar trick to speculative decoding, which we call speculative edits.
We get 5x lower latency for full-file edits with the same quality as rewriting a selection!
4
7
192
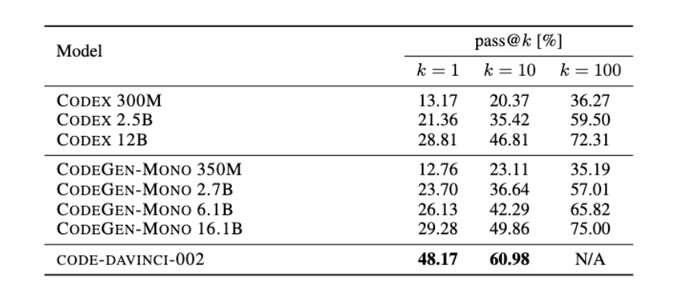
For those using open-source models like CodeGen instead of OpenAI's Codex, I have some bad news about its "comparable" performance.
It isn’t even close anymore. code-davinci 1-shot is competitive with CodeGen 10-shot. (1/7)
(bottom results computed by me with OpenAI API)
11
17
191
Palm2 just dropped, and there are claims that the largest model is just 14.7B params.
In reality, the model is probably closer to 100B parameters
But why... (1/5)

7
26
185
Groq looks very good
I’d suspect it’s possible to achieve this speed with bs=1, 4-bit weights, and speculative decoding on 4-8 H100s
But even on bs=4 H100 pricing, that would cost at least $2.5/1M tokens.
For groq its $0.8…

11
10
184
I’m bearish on the future of on-device LM inference.
Why? Because Mixture of Experts (MOE) shifts the balance in favor of datacenter inference (1/7)
20
11
179
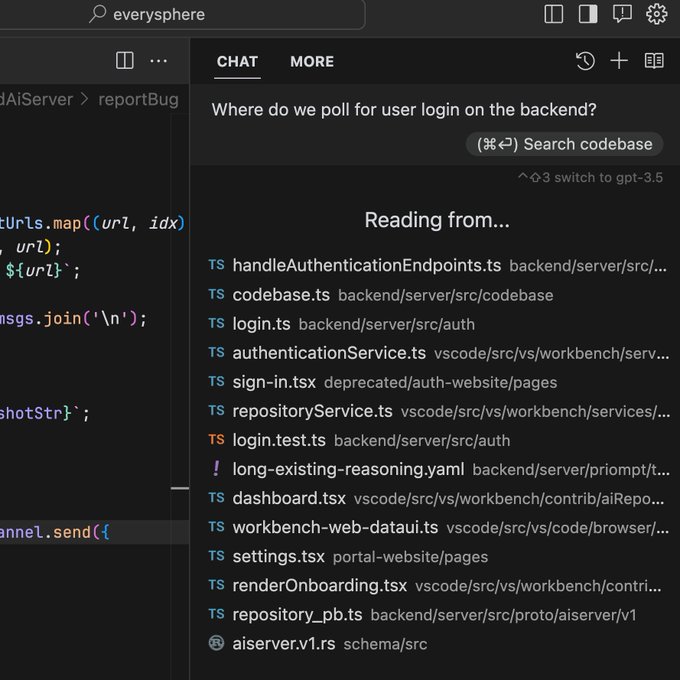
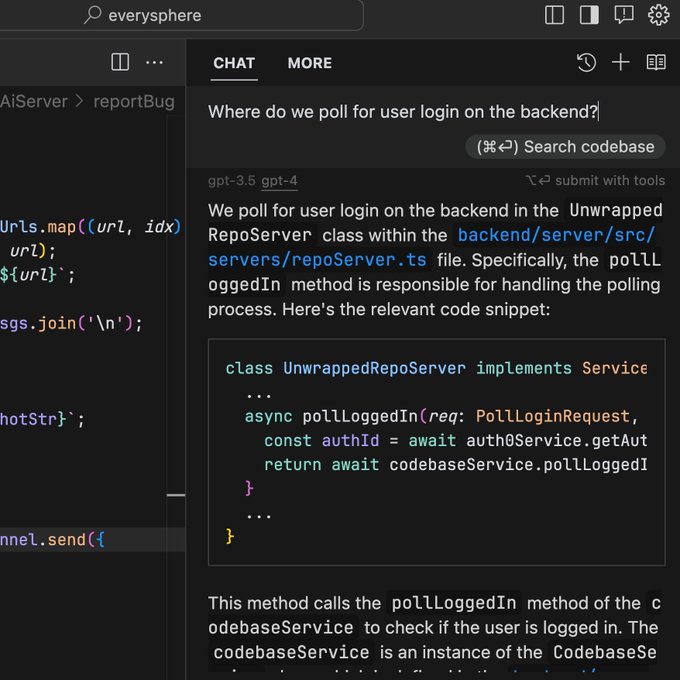
Cursor now answer questions about your entire repo!
Powered by several layers of retrieval, press cmd+enter to:
* Find a missing block of code
* Plan out a full PR
* Write a method with scattered dependencies
9
21
175
2024 is the year that long-context gets commoditized
I'd bet we see several 1m+ token models in oss and closed-source by end of year
5
9
171
Try out a better and much faster model today!
and more crazy improvements coming soon ;)
Copilot++ is now ~2x faster!
This speedup comes from inference optimizations + our best model yet. We really like it and hope you do too ☺️
21
35
520
8
6
170
4090s are 5x cheaper per FLOP than A100s (and can even serve more peak flops)!
This means they're exceptionally underrated at serving embedding models.
If you wanted to serve SOTA embeddings (GTE) on 4090s, you could do it for < $1 / 1 Billion tokens [1]
10
9
155
My favorite new feature in ... Toolformer.
We give the model access to everything a human uses in their IDE. LSP errors, goto definition, terminal outputs, rg search.
Watch Cursor answer complex queries just using rg search... for a >1M line codebase
6
10
150
For some pure-prompt (prefill) workloads that require log probabilities, we’ve built a lightweight inference server that outperforms vllm by a factor of 2
It’s MUCH easier/simpler than it sounds and just uses pytorch + transformers.
here's why...
(1/9)
7
9
146
Resolved over dms!


Deleted my tweet on cursor — it looks like the local mode thing was a hack, and they never intended for cursor to be used locally anyway
So they’re pretty clear about their data practices since it’s a remote server
8
3
227
5
0
134
Llama-2 is more expensive than you'd think
It can be up to 33x more expensive than gpt-3.5, without large batches.
But for some workloads, it can actually be 3x cheaper!
We delve deep into the math and measured perf here:
7
21
130
Most OSS inference frameworks combine pre-filling (prompt tokens) with decoding (generation tokens) per device/process.
But separating the stages should give you better perf!
(1/14)
2
9
127
This year, we intend to solve the problem of having Cursor completely “understand” a codebase.
If you have clever solutions for chipping away at this problem, would love to talk ;)
(12/12)
13
8
121
A surprising fact about transformers is that training is often cheaper per token than inference.
But only on small batch sizes. Here's why...(1/5)
4
7
119
[1] Learning codebase tactics is motivated in large part by the Voyager paper!
8
2
114
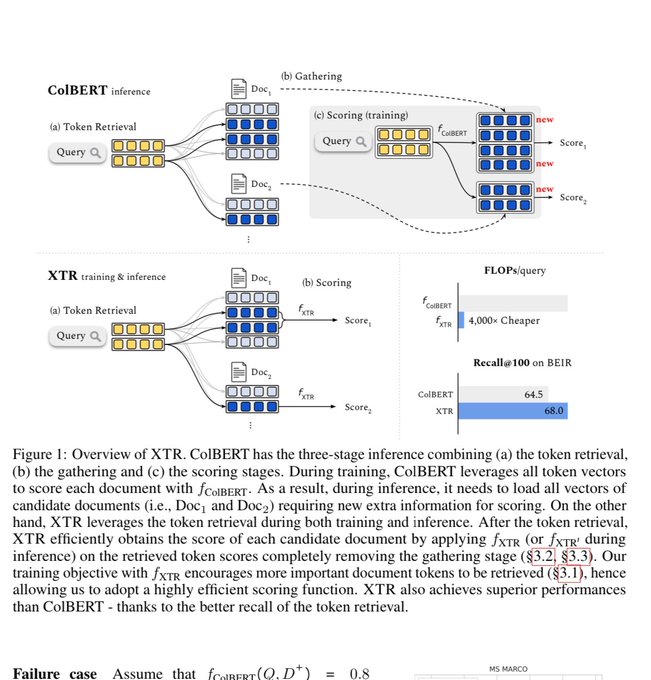
SOTA for retrieval in academia uses an interesting technique called multi-vector retrieval
This requires separately embedding each token of the query and documents.
It actually uses similar model compute to vanilla retrieval [1], but significantly more vector db usage
1
10
116
These breakthroughs in intelligence come from substantially longer context windows, a sparser model, improvements to our training recipe, and much more!
The speed comes from several significant optimizations across the stack.
2
2
115
A very rough draft of a new UX for making your code more readable/bug-free. Heavily inspired by
@JoelEinbinder
:
(1/3)
8
5
115
that’s like a 100m supercomputer
it has more peak flops than even
metas compute cluster!!


2
4
111
Cursor is hiring!
We’re looking for talented engineers, researchers, and designers to join us in making code editing drastically more efficient (and fun!)
If you're excited to redesign the experience of building software, please reach out at hiring
@cursor
.so
8
5
108
Decent chance we get AGI before full self-driving.
The most intelligent models may demand more inference compute than a reasonably-priced car can provide.
And a GPT-6 likely won’t satisfy the inference speed constraints for real-time driving.
12
4
97
Surprising that it works to finetune well past overfitting on validation data:
Done by both OpenAI’s InstructGPT and Lima:


7
16
97
I do find it interesting that despite this project dealing just with external inference systems and OpenAI APIs, it required a deep understanding of how transformer inference works to actually get right.
8
4
93
linter usability and code runnability are critical for improving AI code edit performance.
But doing so on user’s devices without affecting their editing experience is nontrivial.
We go through the clever engineering required to solve this in the post
New blog post. Hidden Electron windows and kernel-level folder proxies to let AIs iterate on code without affecting the user:
8
26
263
5
8
93
My new favorite feature on :
Pulling in docs for inline edits.
It grounds the model, giving hallucination-free edits while preserving flow.
5
4
94
Jamba actually requires more memory for long context generation than (some) similar-sized transformers!
In particular, multi-query attention (mqa) models (like Palm) are slightly more memory efficient.
5
2
92
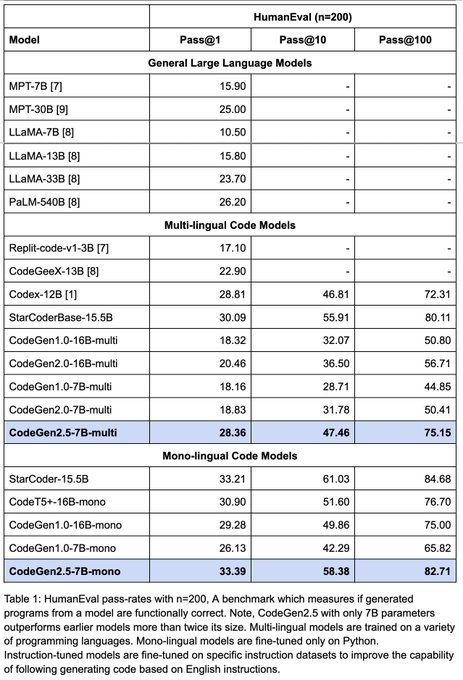
Interestingly, just one subtle detail added to this model makes codegen 2.5 substantially faster than codegen 2
All it required was increasing the number of attention heads from 16 to 32... (1/4)

Releasing 🚀 CodeGen2.5 🚀, a small but mighty LLM for code.
- On par with models twice its size
- Trained on 1.5T tokens
- Features fast infill sampling
Blog:
Paper:
Code:
Model:
8
106
343
2
7
91
LoRA may be more helpful for closed AI providers than for serving OSS models
With Lora they could offer fine tuning as a service, but serve the finetuned model with small marginal cost.
They’d just need inference engine that serves multiple Lora adapters in a single batch (1/4)
4
9
84
The next step is letting the model reflect on PRs and local developer changes, storing this in its repository of deep context.
Combine this new context engine with Cursor, and you get game-changing experimental results. (6/6)
2
1
79
Hate debugging your code?
Cursor will literally do it for you!
Thanks to
@walden_yan
, when you hit an error, press cmd+d to have Cursor automatically fix it.
5
9
81
Google's answer to GPT-4, Palm2, just dropped!
It is competitive with GPT-4, and even beats it on Math! [1]
But on code, the smallest variant of Palm2 significantly underperforms GPT-4 on human eval...
Still, it already blows past SOTA for non-OpenAI general coding models [2]

4
8
79
Once fp8 utilization is figured out, you could probs train llama on this cluster in... 3 days! [1]

7
3
80
It still hallucinates the rest of the PR, but finding the correct edit location (a hard task!) would be impossible if the source and/or PR weren't in the train set.
I suspect a 15-20% score on contaminated repos would translate to something like <5% on unseen/non-public repos.
3
0
81
Cursor is releasing a nightly build!
Here we'll prototype experimental features before wide release.
These include:
- Agents for making codebase-wide edits
- An AI-powered bug finder
Comment down below if you’d like to get access!
53
6
81
Inter-temporal Bradley Terry (IBT) reward modeling is the most important concept from the recent DeepMind paper on multimodal RLHF.
I believe it will be key for getting language models to perform long-term complex tasks... (1/10)

2
4
78
We're hiring across the board in software engineering and ML
If you're as excited about the future of AI-assisted coding as we are, please reach out at hiring
@anysphere
.co!
3
0
73
The fundamental issue with RAG is that it encourages shallow answers
Even excellent engineers would struggle to answer a question with only RAG-like context about a codebase they've never seen. (2/6)
2
2
73
Wait, so text-davinci-002 is Codex with instruction finetuning…
Huh

9
3
75
Lots of talk about Llama being the new dominant "open-source" model
But, Meta hasn't even open-sourced the best model from that paper!
Llama-I, an instruction-fine-tuned variant of Llama-65B, is the best. And it isn't available to download...

3
4
77
A good engineer would first read the code.
They'd follow the breadcrumbs. Go to relevant files, functions, classes, goto definitions/references, to build understanding.
What happens when we let GPT-4 do this... It builds a scratchpad of deep understanding (3/6)
3
1
69

GPT-4 zero/few-shot is poorly grounded, so asking it to predict a raw score for each code block will give inaccurate results.
Instead, let's take 4 code blocks for a given query. If we ask gpt-4 to order them based on relevance, its accuracy at this task is almost 100%!
(4/10)
2
2
71
Copilot++ was built to predict the next edit given the sequence of your previous edits.
This makes it much smarter at predicting your next change and inferring your intent.
Try it out today in Cursor:

3
0
68