
Elan Rosenfeld
@ElanRosenfeld
Followers
1,197
Following
191
Media
31
Statuses
329
Final year ML PhD Student at CMU working on principled approaches to robustness, security, generalization, and representation learning.
Joined September 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Madrid
• 956268 Tweets
برشلونة
• 887285 Tweets
Barca
• 537846 Tweets
Mbappe
• 435479 Tweets
#ElClásico
• 323805 Tweets
Bernabeu
• 296464 Tweets
#UFC308
• 270670 Tweets
Lamine Yamal
• 260355 Tweets
Lewandowski
• 153645 Tweets
Raphinha
• 153274 Tweets
Topuria
• 147368 Tweets
Hansi Flick
• 140677 Tweets
Ancelotti
• 121854 Tweets
Holloway
• 119868 Tweets
Michelle Obama
• 111050 Tweets
Perez
• 110350 Tweets
Vini
• 107992 Tweets
Bellingham
• 100245 Tweets
Pedri
• 89525 Tweets
Khamzat
• 74445 Tweets
#كلاسيكو_الارض
• 58697 Tweets
Gavi
• 54761 Tweets
Checo
• 44478 Tweets
Iñaki Peña
• 44105 Tweets
Sainz
• 41049 Tweets
Vitória
• 38481 Tweets
Cruzeiro
• 36327 Tweets
الريال
• 32554 Tweets
Mendy
• 31791 Tweets
#precure
• 30602 Tweets
Xavi
• 27983 Tweets
انشيلوتي
• 20348 Tweets
Juventude
• 19059 Tweets
Gerson
• 17606 Tweets
Gabigol
• 17097 Tweets
Nuggets
• 16925 Tweets
ليفا
• 16438 Tweets




















Pinned Tweet

What causes sharpening + Edge of Stability?
Why is Adam > SGD?
How does BatchNorm help?
Why is 1-SAM > SAM > SGD for generalization?
What is Simplicity Bias, really?
Our new work doesn’t answer these questions (well, 𝘮𝘢𝘺𝘣𝘦 the first one)
But it suggests a common cause...

4
97
551

Another round of "publication incentives are messed up". He's right, of course, but the people who say this are almost always those who publish lots and are no longer beholden to the game.
This is something I've thought a lot about. As a senior PhD student, I have no...
1/n

Since we just wrapped up an AI megaconference, it felt like a good day to plead for fewer papers.
32
162
852
1
10
133
A theme in NeurIPS papers I've reviewed: those that at least _try_ to do something new get low scores ("could be clearer/didn't compare to X"), while those that rehash the same old boring stuff get middling scores.
When a cutoff is picked, the "safe" paper gets accepted.
3
4
99
Just to be clear, this post was meant fully tongue in cheek! Of course citation count isn't the right measure.
Also check out my soundcloud:

0
0
83

@thegautamkamath
While this response is overtly disrespectful, reviews are frequently just as flippant and blatantly devoid of empathy. We've all received such reviews.
The difference is the reviewers are in a position of power, so they can be disrespectful under the guise of "peer review".
2
3
79
Several methods use unlabeled test samples to predict a network's error under dist shift. What if we could instead give a 𝗴𝘂𝗮𝗿𝗮𝗻𝘁𝗲𝗲𝗱, 𝗻𝗼𝗻-𝘃𝗮𝗰𝘂𝗼𝘂𝘀 𝗯𝗼𝘂𝗻𝗱?
We can't, obviously (did I fool you?). But we can get really close!
1/5

1
12
74

Heard several comments recently about how "IRM is great but it doesn't work in our setting."
Can anyone point me to cases where it _does_ work? Personally I've never seen any. To the contrary, I've heard from lots of people that they spent lots of time failing to get it to work.
5
5
50
DNNs trained with ERM are often said to use the “wrong” features, thus suffering under distribution shift. Minimizing an alternate objective end-to-end *implicitly assumes* the entire network is to blame.
But is it?
New work: w/ P. Ravikumar,
@risteski_a
2
7
49
Excited to attend
#NeurIPS2023
this week! DM me to chat about robustness, generalization, Opposing Signals, etc.
Among others, I'll present work on provable + tight error bounds under shift:
and giving a talk on Opposing Signals at ATTRIB.
List below 👇

Several methods use unlabeled test samples to predict a network's error under dist shift. What if we could instead give a 𝗴𝘂𝗮𝗿𝗮𝗻𝘁𝗲𝗲𝗱, 𝗻𝗼𝗻-𝘃𝗮𝗰𝘂𝗼𝘂𝘀 𝗯𝗼𝘂𝗻𝗱?
We can't, obviously (did I fool you?). But we can get really close!
1/5
1
12
74
0
2
45
We identify 𝗢𝗽𝗽𝗼𝘀𝗶𝗻𝗴 𝗦𝗶𝗴𝗻𝗮𝗹𝘀: features with unusually large magnitude in small fractions of the data.
Why “Opposing”? B/c they occur in paired groups of outliers, and using them to reduce loss on one group will increase loss on the other.

3
1
42
But when I look back at my projects, I am proud of (almost) every single one; I've spoken to lots of students who look back on many papers with regret. And it's *way* more satisfying when someone knows you for "that one paper" than for how many papers you have.
It's hard to say
1
0
39
Want to learn more about the failure modes of recent work on invariant feature learning (e.g., Invariant Risk Minimization)?
Check out my CMU AI seminar talk, based on work at ICLR’21 w/
@risteski_a
and Pradeep Ravikumar. 1/3

1
11
38
Very excited about this work!
Full thread coming shortly (those pesky early faculty app deadlines...)

Outliers with Opposing Signals Have an Outsized Effect on Neural Network Optimization. (arXiv:2311.04163v1 [cs.LG])
0
0
9
1
0
33
As amazing as Shai's research is, let's please make an effort to stop attributing works solely to their senior author, who isn't lacking recognition; and ignoring the grad student(s), who probably did most of the work (and possibly all of it)?
@ToscaLechner
is easy to find.
2
0
33
@thegautamkamath
I would never post a response like this. But we're kidding ourselves if we act like the kind of reviews people give on these platforms aren't basically just as insulting, without being so explicit about it.
1
0
30
I've seen a lot of works recently which prove a result---often identifiability---with the help of several opaque assumptions that don't have any real intuitive meaning. Reading the proof, it's clear they just assumed whatever makes the proof "go through".
The point of an...
1
0
28
An example with text: when a sequence ends with a colon (‘:’), the next token is often either ‘the’ or a newline (‘\n’).
So which is it? Until the network learns to use some other available signal, it oscillates back and forth between these two options.
(Image is GPT-2 on OWT)

1
3
28
Nice to see an independent corroboration of our findings!
The improved accuracy and reduced computational cost are exactly the kind of benefits I had in mind. More evidence that this is a promising direction moving forward.

Last Layer Re-Training is Sufficient for Robustness to Spurious Correlations. ERM learns multiple features that can be reweighted for SOTA on spurious correlations, reducing texture bias on ImageNet, & more!
w/
@Pavel_Izmailov
and
@andrewgwils
1/11
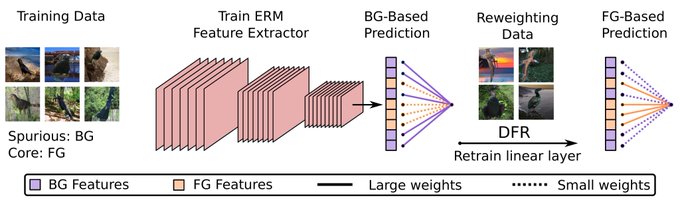
13
72
522
0
2
24
Sidenote: finding these outliers is simple. Try it yourself! (more pronounced with full GD)
1. Track loss change on each point from one iteration to the next.
2. Select points with most +ve and -ve changes.
3. Just look at them—patterns are often totally obvious.




2
0
24
@deepcohen
Actually, I also saw this happen for a fixed architecture but a different *optimizer* (and with the same batch ordering).

2
0
24
Discovered this relatively unknown paper from NIPS '94 (!) with some very modern-looking ideas, including what looks like a precursor to NICE and volume-preserving normalizing flows (Section 3).
I should spend more time reading older proceedings...
3
1
23
without a huge publication count.
It's difficult---in fact it's *more* difficult than just doing good research. Because it requires watching others publish more and thinking you could maybe match them, but deliberately choosing to instead focus on one or two threads that matter
1
0
22
@shortstein
I don't disagree with this.
However, there are many cases where it is abundantly clear a reviewer did _not_ try their best. I've been assigned papers that I anti-bid, and I still put in the effort. I don't think "I didn't want to review this" is a valid excuse for a poor review.
0
0
22
Great news! To give people a little more flexibility around the
#NeurIPS2022
deadline, we are pushing the
@icmlconf
PODS workshop deadline to May 25th.
We still strongly encourage submissions by the 22nd to help keep the reviewing timeline on schedule.
Good luck everyone!

Announcing the ICML Workshop on Principles of Distribution Shift (PODS)! Submit your 4-pagers on theoretical foundations, real applications, benchmarks (or the validity thereof), & position pieces.
Also, the speaker list slaps.
Site:
Deadline: May 22
5
20
73
1
3
21

Enjoyed talking with
@ml_collective
about our recent work on Opposing Signals. Got some great Qs, thanks to
@savvyRL
for hosting me!
If you want to learn more about 𝘸𝘩𝘢𝘵 𝘢𝘤𝘵𝘶𝘢𝘭𝘭𝘺 𝘩𝘢𝘱𝘱𝘦𝘯𝘴 when you train a NN, check out the recording:

1
1
20
Our running (real) example is “sky” in an image background (but they also appear in text!)
Plane images are filled with blue pixels; their gradient points towards “sky = plane”. But there are also images of non-planes with sky; their gradient points in the opposite direction.

2
1
20
Work w/ my amazing advisor
@risteski_a
CC:
@PreetumNakkiran
,
@TheGradient
,
@prfsanjeevarora
,
@ShamKakade6
Also thanks to
@kudkudakpl
for the earlier (anonymized) shoutout 🙂

Meaningful progress on understanding break-even point & edge of stability: . The result is really cool: the initial increase in sharpness and the resulting chaotic instability are due to an overeliance on simple features.

1
13
70
1
1
19
If you could broadcast one fact about ML to every reviewer and have them understand it, what would it be?
It's incredible to me how many reviewers don't understand that "making an assumption" is literally the foundation of all of machine learning.
You can debate if a given
2
1
19
I will be giving a (very) brief talk on this work at the ATTRIB workshop at 10:35 tomorrow morning. Stop by if you're interested!
I'll present the poster there and at the heavy tails workshop.
What causes sharpening + Edge of Stability?
Why is Adam > SGD?
How does BatchNorm help?
Why is 1-SAM > SAM > SGD for generalization?
What is Simplicity Bias, really?
Our new work doesn’t answer these questions (well, 𝘮𝘢𝘺𝘣𝘦 the first one)
But it suggests a common cause...
4
97
551
0
1
18
A sequence of videos of Will Smith eating spaghetti, overlaid with the shutterstock logo. In some clips he uses a fork and in others his hands overflow with spaghetti as he shovels it into his mouth. In each clip he is wearing a different outfit. One clip has two Will Smiths.

we'd like to show you what sora can do, please reply with captions for videos you'd like to see and we'll start making some!
15K
2K
30K
1
2
19
to you. It's especially tough because those other students compete with you for jobs/fellowships/etc.
I probably could've published more during my PhD. And I've probably missed out on fellowships to people with more publications. It may even bite me on the faculty market.
2
0
19
This enables specific, qualitative predictions about network behavior, which we verify on real nets.
Opposing Signals also offer high level explanations for all the questions above. In particular, they provide a fairly detailed descriptive theory of why sharpening/EoS occurs!

1
0
18
if we'll ever realign incentives to popularize the kind of work Ben advocates for in his post. But I think it's not going to happen without *individuals* pushing back, even if it means taking a personal risk.
I encourage you to try. Collectively, maybe we can break the cycle 🙂
1
0
18
Why do these samples have such huge influence on NN training?
At init, network lacks good features, so gradient points towards predicting p(class | “sky”). As a result, “sky” gets upweighted. We explore this effect, giving our current best understanding via a high level story.
1
1
16
Challenge mode. Write a paper abstract and intro without using the following terms:
recent(ly)
simple yet effective
leverage
rapid/tremendous/unprecendented advances/scale/progress
significant interest
corroborate
unified
we take a step
we answer in the affirmative/negative
3
0
15
Seems like "novelty" is too fuzzy a criterion. If you rehash an existing idea, you can use prior work as proof that it's publication-worthy (and there's less explanation needed).
But if your main contribution is conceptual and they insist it's not interesting, you're SoL.
1
3
15
@leonpalafox
True, but if you look at the trend I think it's reasonably likely this'll hold even once it updates.
1
0
14
IRM has become one of the go-to methods for OOD generalization, but it turns out it can have some rather pernicious failure cases.
Check out our new paper, "The Risks of Invariant Risk Minimization"!

First foray into OOD generalization, joint with new co-advisee
@ElanRosenfeld
and Pradeep Ravikumar:
We show a few (mostly negative) results about IRM:
1
8
58
0
4
15
There are a lot of remaining open Qs, but I’m very hopeful this can help us gain a much deeper understanding of NN optimization.
So far every experiment I’ve tried has failed to falsify our qualitative theory. If you have an idea for one, please let me know (or run it yourself!)
2
0
14
The unfortunate thing about doing research ahead of its time in ML is that when people get around to realizing its value, they've forgotten about the papers--and it's against their self-interest to do the work of finding them.

With sparse coding again popular for interpretability in LLMs please look at older work! "Latent structure in word embeddings" , Atoms of meaning" , Decoding brain fMRI via sentence embeddings
1
37
243
2
0
13
experience in hiring, so I expect my thoughts are less refined and probably won't carry as much weight. But one way in which they may be helpful is that I'm not speaking from the "other side".
So I just want to share my perspective which is that you *can* differentiate yourself
1
0
11
We believe the only other necessary ingredient is depth, which we support via simple analysis on a 2-layer net (+ synthetic expts).
We also give preliminary evidence that these signals are part of why Adam > SGD (particularly on attention models), and why Grokking is "hidden".
1
0
13
@EduardoSlonski
You may be interested in our work showing a similar "opposite" pattern as it evolves over time during training:
What causes sharpening + Edge of Stability?
Why is Adam > SGD?
How does BatchNorm help?
Why is 1-SAM > SAM > SGD for generalization?
What is Simplicity Bias, really?
Our new work doesn’t answer these questions (well, 𝘮𝘢𝘺𝘣𝘦 the first one)
But it suggests a common cause...
4
97
551
1
1
12

Through several recent conversations, I have come to realize that there is quite a large gap between---and a consistent order to---how popular I think my research is, how popular _others_ think my research is, and how popular my research actually is.
0
0
11
@roydanroy
You can build ships without knowing anything about fluid mechanics.
You can develop better-than-random medicine without knowing anything about germ theory.
You can selectively breed animals without knowing anything about genes and heritability.
It's the rule.
0
0
12
@yoavgo
You forgot "unrelated theoretical guarantee for an overly simple setting which would never apply when using the proposed architecture".
1
0
11
Not a diss, just want to let people who are unaware know that Alec and the CLIP paper did not invent caption matching for multimodal alignment.
Last Summer I worked with
@FartashFg
from whom I learned this is an old idea (e.g. , he didn't invent it either)


now seems as good a time as ever to remind people that the biggest breakthroughs at OpenAI came from a previously unknown researcher with a bachelors degree from olin college of engineering




63
524
6K
2
1
10
@thegautamkamath
For what fraction of papers would I read and it say "that's a good paper"? Very low.
What fraction would I read and say "that's good enough to get into NeurIPS"? A lot.
0
0
11
@prfsanjeevarora
Isn't this just another instance of "moving the goalposts"? If you aren't willing to accept that his attack breaking the challenge is evidence of InstaHide being broken, why did you put up the challenge?
1
0
10
Casually claiming to prove P = NP and dropping it on arXiv
An efficient, provably exact algorithm for the 0-1 loss linear classification problem. (arXiv:2306.12344v1 [cs.LG])
0
0
2
1
1
9
Tomorrow at AISTATS I’ll present our work analyzing online Domain Generalization which suggests that “likelihood reweighting” (aka group shift) may be an insufficient model of dist. shift
w/ P. Ravikumar,
@risteski_a
Link:
Poster session 5, 11:30 AM EDT
2
3
9
One thing I find really encouraging is that this doesn't require industry-scale clusters. Not that "low compute = better", but the other winners all used massive compute (n.b. DPO reduces that need).
This paper is proof that thoughtful, impactful work can be done on a budget.

Wow! I honestly don't know what to say. Receiving the NeurIPS outstanding paper award is an amazing honor for me and my coauthors, Milad & Matthew, but also all of the prior research that we built on.
30
22
666
0
0
9
I once reviewed a paper for ICML that had all sorts of problems. But it had been hyped up so much that I felt it was better for a corrected version to be published than not at all. I was in the minority in favor of acceptance and I made my reservations clear.
It got an oral 🙃

One of the alleged reviewer commented on the blog post.
Of course I have no way to verify if it is true, but there are some interesting points anyway


0
4
66
0
0
8
@hardmaru
Also, if anyone would like to learn about this work in more detail I will be giving a talk at the CMU AI Seminar next week:
0
2
8
1
0
8
@norabelrose
This paper came out 5 years ago...
See also our recent paper explaining why this happens
1
0
9
Wow, the two points in the abstract of number (1) are clever and I'm surprised I haven't seen this interpretation before. Is this widely known?

My two contenders:
1) Why LayerNorm is so helpful in Attention and what it’s actually doing under the hood ()
2) Explaining the oversquashing phenomenon in GNNs ()
Really cool papers with superrr approachable math/theory 🙌🏻




6
79
594
0
1
7
I could've made these predictions with copy+paste and a medium width highlighter

Forecasts on the unseen datasets closely match the ground truth.


2
1
24
0
0
6
To add to this, we (i.e., humans) are notoriously bad at credit assignment, and we tend to underestimate the degree of luck involved in our life trajectory. Goes with the mention of survivorship bias, but also we want to believe we have much more foresight than we actually do.

I was recently on a panel with several other professors and we were asked to give some tips to graduate students in machine learning. It got me thinking about why professors are so bad at giving advice. So here are some reasons why you should not take advice from professors.
15
287
2K
1
0
7
Related, possibly controversial:
As a rule of thumb, if the abstract uses the phrase "We present/propose", I regard it with greater skepticism. It sounds to me like the authors are marketing a product, and you should always be skeptical of marketing.
(skeptical ≠ disbelieving)

Crazy AF. Paper studies
@_akhaliq
and
@arankomatsuzaki
paper tweets and finds those papers get 2-3x higher citation counts than control.
They are now influencers 😄 Whether you like it or not, the TikTokification of academia is here!

64
284
2K
0
0
7
@thegautamkamath
I think it is reasonably likely for both to receive no scrutiny by experts at all.
0
0
6
Forgot to say this work will be at 3 Neurips workshops, w/ a short talk at ATTRIB.
Our work on provable error bds under shift will also be at the main conf:
Come by to discuss either! Or recent foray into strategic classification:
P.S. If you're coming to
#NeurIPS2023
, come hear Elan talk about it at the ATTRIB workshop, and/or come to our poster at the M3L and Heavy Tails workshops.
0
0
4
0
0
5
Our method, Dis², uses unlabeled data to give whp error bounds. It relies on one simple, intuitive condition with lots of empirical support.
In practice it gives valid, non-vacuous bounds effectively 100% of the time! Its average accuracy is also competitive with SOTA baselines.

1
0
6
This looks like a very interesting paper!
Though I wish people would stop perpetuating the use of ColoredMNIST---It is not and has never been a meaningful benchmark. If you reduce the absurd 25% label noise to something more reasonable, vanilla ERM does just fine.

Empirical Study on Optimizer Selection for Out-of-Distribution Generalization
#learning
#distributional
#classification

0
4
21
3
2
6
assumption is reasonable. But obviously 𝘴𝘰𝘮𝘦 assumption is reasonable.
Every ML method makes assumptions---perhaps implicitly. Full stop.
"But the assumption might not hold" is not a valid point, unless you have actual reason to believe it won't or there exist better ones.
0
0
6
1
0
6
What's the intuition?
Recent work shows true labels under shift are approx. given by a "simple" (e.g., linear) function on existing features:
So, when imagining the (unknown) true labeling function on test data, we need only consider simple functions.
1
0
5
machine learning academia in 2022

One of the most popular sociological internet catchphrases in China doesn’t have a good translation. “内卷” or technically “involution”, which nobody understands. But it describes a perverse state of affairs where competition get perniciously fierce while rewards get ever smaller
95
305
2K
0
1
5
@bremen79
@ToscaLechner
Yeah, it's tricky. I get that it's a lighthearted joke (also I'm a sucker for puns 😁). But it contributes to the culture.
I get why the media does it---they don't know better and they need a "name" to latch on to. But as past/current students, we should stop normalizing it.
0
0
5
Say you have (what you believe to be) a very interesting idea for a long term project (multiple papers) on a major open question in Deep Learning.
You have a related paper that arose from it but you're about to finish your PhD and can't pursue it to fruition. Do you:
Post short paper on arxiv
80
Put it in your job talk
29
Wait 1.5 yrs til next job
15
Other (what?)
19
4
0
5
Along the way, we also derive a more effective surrogate loss for maximizing multiclass disagreement.
We evaluate on an extensive array of shifts and training methods, and we've released our code and all features/logits:
Work done w/
@saurabh_garg67

1
0
5
@deepcohen
I saw this tweet at the end of the thread without reading the previous ones and I thought "oh, he's finally decided to admit it" 😉
0
0
5
0
0
5
PSA:
@openreviewnet
takes a few minutes to display a new review after you first submit it. Not sure what the cause is but it's been the case for a while now. So no, your review is not gone, just wait a bit before refreshing!
#ICLR2023
0
0
5
I'm guilty of this myself. There are so many papers! The best we can do is graciously acknowledge when one is pointed out and be sure to champion it going forward so others don't make the same mistake.
I've had to do this for several different areas I've worked in.
0
0
4
The difference is that assumption A should be clear and intuitive. I should read it and be able to understand how reasonable it is, when it may or may not hold in practice, and how one might go about testing it.
Otherwise, you might as well just assume the conclusion.
1
0
4
Anyone know a simple repo for pretraining a small/med LM (e.g. BERT), while making low-level changes?
Every link is "here's a library that abstracts away everything, train an LM with 10 lines!
...to make any non-hparam changes, spend 2-3 weeks learning the guts of our codebase"
4
1
4
@shortstein
@thegautamkamath
Unfortunately it depends on the content of the reviews and rebuttal.
If an AC sees mostly low scores and decides "no reason to get involved, this paper will probably be rejected", why even have an AC for these papers in the first place?
1
0
4
@sherjilozair
Everyone is talking about it because it's from Google and got tweeted by someone with followers. Not because it says anything surprising or new.
1
0
4


Junior scholars: "I feel awkward citing myself"
Senior scholars: "as I cleverly argued (1988; 1991), admirably reiterated (1993; 1995; 1996); and handsomely concluded (2001; 2004; 2007)..."
119
7K
90K
0
0
4
Bonus tweet!
In sketching out an early version of Figure 2—which describes the intuition behind our method—I asked GPT-4 to draw me a rough version in tikz.
Then I gave the exact same natural language prompt to my roommate and he drew it on a whiteboard.
Whose is better?




0
0
4
Counterpoint: it makes "getting an AC that doesn't suck" feel like you won the lottery. I live for that high.

There's nothing more criminal than being a bad AC. It's worse than being a dumb reviewer 2.
3
7
89
0
0
4
If all such functions which also agree with the training labels say our network has low test error, we can be confident that it does.
We formalize this with a simple assumption—notably, sometimes we can even 𝘱𝘳𝘰𝘷𝘦 that the assumption holds (after seeing test labels).
1
0
4
@giffmana
@sarameghanbeery
So while I agree this is an outdated motivation, I think the general idea behind it still stands.
I think of the "cows on a beach" example as pointing out more generally that these systems lack common sense and will often give incorrect outputs with high confidence.
1
0
4
Manuel Blum was not my advisor in grad school, he was my advisor in undergrad.
And yes he's as great as the article portrays him 🙂

Manuel Blum was not my advisor, he was my advisor's advisor and my advisor's advisor's advisor's advisor.
1
0
6
1
0
4
@aldopacchiano
@chris_hitzel
That's a good point which I had not considered. It's hard to avoid optimizing for pure publication/citation count when failure means deportation.
I guess I'm encouraging those who can afford to take the risk, so that future int'l students won't have to face that choice.
0
0
4
Another review cycle, another set of (six!) reviews that don't address anything meaningful and waste everyone's time.
1
0
4
@Lisa_M_Koch
@zacharylipton
We will stream the talks, but there is no conference support for virtual poster sessions. If you have an accepted paper but cannot attend in person, you will be able to submit a video and send your poster to the ICML organizing committee who will print it and set it up for you.
1
0
3
@OmarRivasplata
@zacharylipton
Yes, the first link is my paper! And the other one I've read.
Yet there still seems to be the idea that "it does work sometimes" in the zeitgeist and I cannot understand where this comes from.
1
0
3
@ericjang11
I noticed the same thing about rhyming, and spent a while trying to fix it. This included asking GPT-4 to read and assess its response, and then determine if it succeeded. It didn't work---GPT-4 kept assuming that it had succeeded after the second try...

In the new MSR paper, I noticed that the Shakespearean proof did not use his classic cadence.
It turns out, GPT-4 *can* write in iambic pentameter! This blows my mind.
However, it seems it cannot write in iambic pentameter without rhyming, even when you tell it not to.
0
0
3
1
0
3
8/ We present a new model of dist. shift, similar to the “invariant/environmental latents” from , though more general.
I’m particularly excited about this model, it’s intuitive and promising for further analysis! Sort of like a generalized covariate shift.
1
0
3
@rcguo
Surprised this isn't common knowledge yet, but IRM doesn't work on Colored MNIST. The experiments in the paper validate on the test domain. Check the code.
1
1
3
In the new MSR paper, I noticed that the Shakespearean proof did not use his classic cadence.
It turns out, GPT-4 *can* write in iambic pentameter! This blows my mind.
However, it seems it cannot write in iambic pentameter without rhyming, even when you tell it not to.
0
0
3